CNN | 从全连接神经网络到卷积神经网络CNN
在人工智能领域,神经网络是一种模拟人脑神经元连接方式的模型。它通过多层结构对输入数据进行逐层抽象,从而完成分类、识别或预测等任务。
在深度学习发展的早期,最常见的模型是
全连接神经网络
(Fully Connected Neural Network,FCNN)。
一、什么是全连接神经网络
全连接神经网络的结构非常简单:
输入层 → 隐藏层 → 输出层
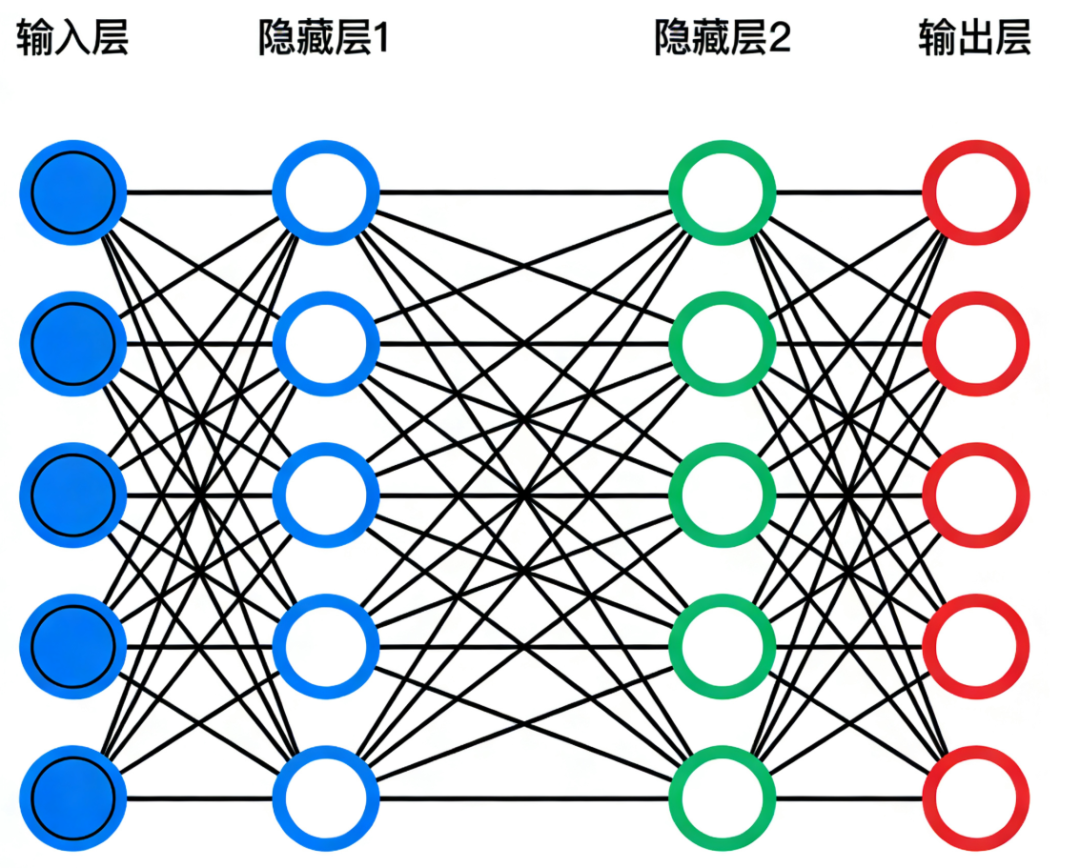
全连接就是指每一层的每一个神经元,都与下一层的所有神经元相连。其数学表达形式为y=h(Wx+b),其中x为输入、y为输出、W为权重矩阵、b为偏置项,h()作为激活函数。
全连接神经网络结构简单,但当我们将图像输入全连接网络时,发现出现了参数量巨大、计算成本极高、极易过拟合、丢失图像的空间结构信息等问题。

例如假设我们处理一张224×224×3的彩色图像总输入维度为224×224×3=150,528;如果第一层有 1000 个神经元,那么参数数量是150,528×1000=1.5亿参数,这还只是第一层,随着神经网络层数的提升,巨大的参数量将会出现。同时,全连接网络把图像拉平成一维向量,破坏了像素之间的空间关系。
二、卷积神经网络
在全连接神经网络的基础上做出改进:
减少参数量的同时保留空间结构。
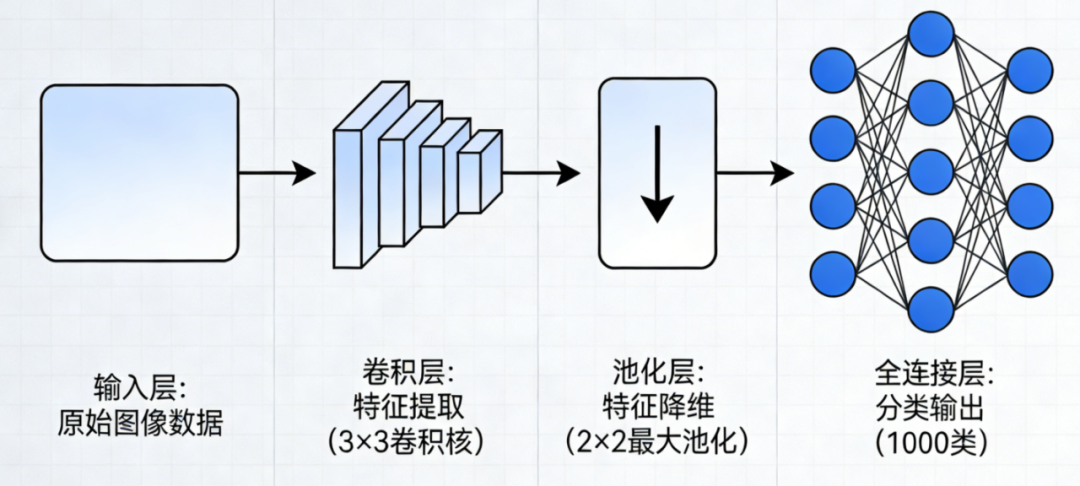
卷积神经网络的基本结构:
输入层 → 卷积层 → 激活函数 → 池化层 → 全连接层 → 输出层
01卷积层
其核心作用为提取特征。它通过多个卷积核对输入图像进行卷积操作,生成特征图(Feature Map),具有局部连接、参数共享、保留空间结构信息的特点。
在全连接网络中,每个神经元都看到整张图像;但在卷积神经网络中,每个神经元只看到一个局部区域,我们也称为感受野。
比如一个3×3卷积核只关注3×3的局部像素。通过卷积核的“小窗口”在图像上滑动,寻找局部特征。还是刚刚224×224×3的彩色图像例子,假设使用64个3×3×3卷积核,参数数量为3×3×3×64=1728,参数量骤减,其原因在于卷积核参数在整张图像上共享。
由卷积核在图像上平滑移动生成的特征图具有逐层抽象的特征:第一层提取边缘、第二层提取纹理、第三层提取形状、更深层提取语义特征。这也是 CNN 强大的根本原因。
02激活函数
如果神经网络中只有线性运算,无论叠加多少层,本质上仍然是一个线性模型。数学上也可以证明多层线性变换=一层线性变换。这意味着网络无法拟合复杂的非线性关系、模型表达能力非常有限。
因此,我们需要引入非线性函数——激活函数。利用激活函数可以引入非线性、增强模型表达能力、控制输出范围。
Sigmoid函数
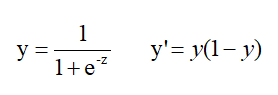
特点:输出范围 (0,1)
缺点:反向传播梯度消失严重。
Tanh函数
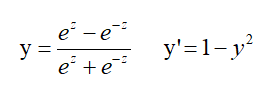
特点:输出范围(-1,1)、相比Sigmoid有关于0对称、导数大变化快训练快。
缺点:反向传播仍有梯度消失问题。
Relu函数
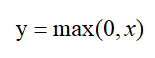
特点:计算简单、收敛速度快、无梯度消失问题
缺点:训练时可能出现神经元死亡
Leaky Relu函数
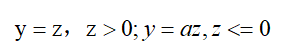
特点:负半轴保留微小梯度,解决了Relu函数出现神经元死亡的问题
03池化层
池化层的作用是降低特征图尺寸、减少计算量、提高鲁棒性。
最常见的两种池化方式:
最大池化(Max Pooling)
平均池化(Average Pooling)
例如2×2最大池化为从一个2×2区域中选取最大值,从而保留最显著特征,忽略细节噪声。
04全连接层
它的作用类似传统神经网络:综合所有特征、输出最终预测结果。
在网络的后期,卷积提取的特征会被拉平成一维向量,输入到全连接层中。
05损失函数
损失函数衡量模型预测结果与真实标签之间的差距、指导反向传播更新参数。
回归问题:
均方误差
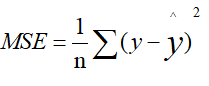
分类问题:
交叉熵损失
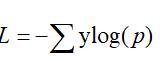
二分类交叉熵
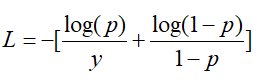
06输出层
输出层的作用是将输出转换为概率分布且所有类别概率范围为(0,1)和为1
多分类问题中,输出层通常使用 Softmax函数
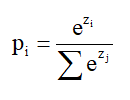
三、总结
从全连接神经网络到卷积神经网络不是简单的结构变化,而是对数据结构的更深一步理解,其核心差异如下:

卷积神经网络的核心思想可以总结为:
卷积层 → 提取局部特征
激活函数 → 引入非线性
池化层 → 降维与抗干扰
全连接层 → 综合判断
损失函数 → 指导训练优化
其利用图像的空间特性,实现了更少参数、更强表达能力、更好泛化性能。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
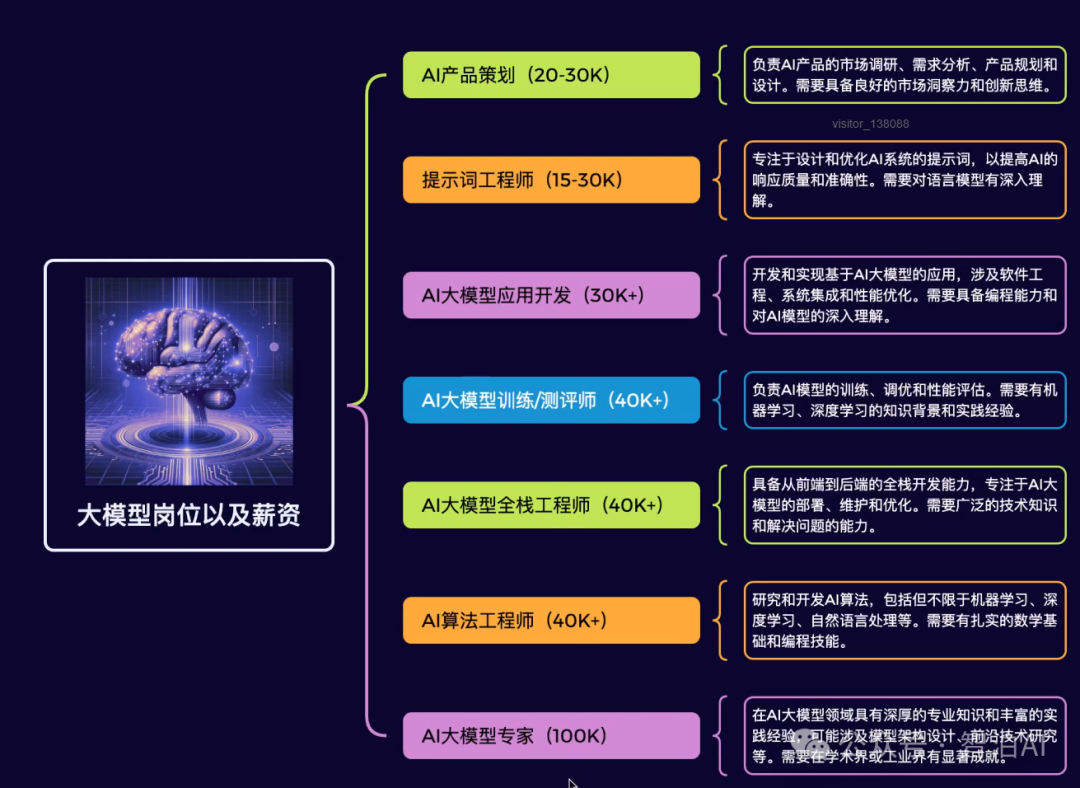
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

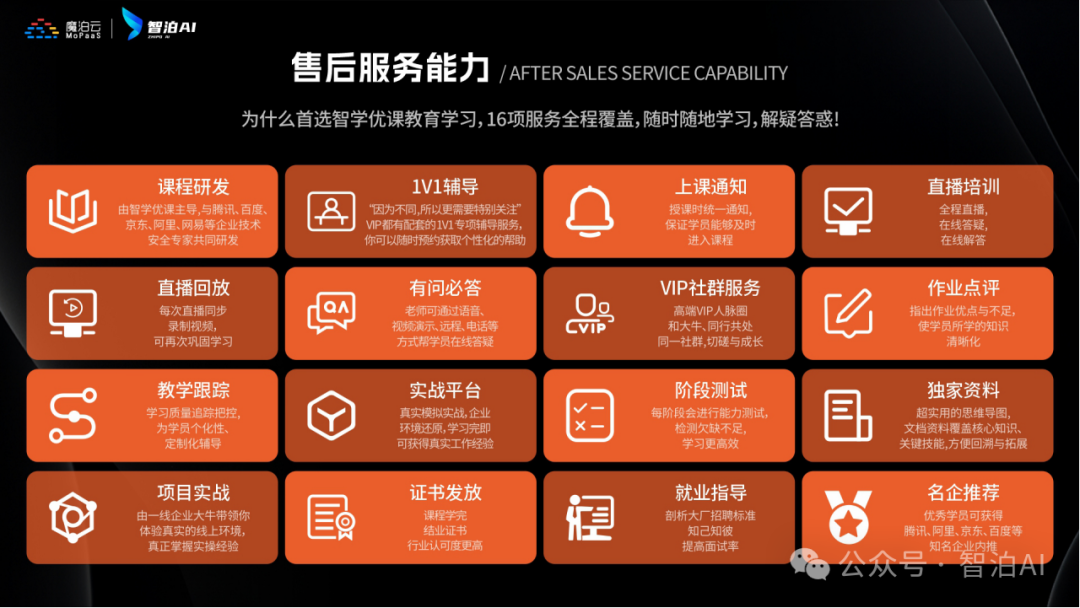
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)