AIAgent 工具设计的原子性艺术:如何优雅地控制工具粒度?
Agent 工具设计的原子性艺术:如何优雅地控制工具粒度

文章目录
前言
你是否曾经遇到过这样的尴尬场景:辛辛苦苦设计了一个功能强大的 Agent 工具,结果大模型却不知道该怎么使用它?或者为了追求极致的原子性,把一个简单功能拆成了十几个微小的工具,最后发现调用链条长得像绕口令?
这就是 Agent 工具设计中的原子性把控问题!
今天,我们就要深入探讨这个让无数开发者头疼的问题:如何设计出既不臃肿也不零碎的 Agent 工具?让我们从实战案例出发,一起掌握这个优雅的设计艺术!
小贴士:原子性(Atomicity)在 Agent 工具设计中,指的是一个工具应该专注于完成单一、明确的任务,就像原子一样不可再分。
一、原子性把控的核心原则
1.1 专业解释
原子性原则是 Agent 工具设计的基石,它要求每个工具都应该具备以下特征:
- 单一职责:一个工具只做一件事,且做到极致
- 参数简洁:工具的输入参数不宜过多,建议控制在 3 个以内
- 语义清晰:工具名称和功能描述应该让 LLM 能够准确理解其用途
- 边界明确:工具的功能范围应该有清晰的界限,避免功能重叠
这种设计哲学源于软件工程中的单一职责原则(SRP),但在 Agent 工具设计中有其特殊性。因为 Agent 的调用者是 LLM,而 LLM 对工具的理解和使用方式与人类开发者有很大不同。
1.2 大白话解读
如果用通俗的语言来说:
想象一下,你在厨房做饭。如果你只有一把"超级万能菜刀",它既能切菜又能砍骨头还能刨丝,看起来很方便,但当你想切土豆丝时,可能会因为功能太多而不知所措。
相反,如果你把每个功能都拆分成独立的工具:切菜刀、砍骨刀、刨丝器、削皮刀……那做一道简单的土豆丝可能需要切换七八个工具,简直是灾难!
聪明的做法是什么?
把功能相关且经常一起使用的操作组合在一起。比如:一把切菜刀可以处理大部分蔬菜的切割工作,但砍骨头这种完全不同的操作,还是单独准备一把砍骨刀吧!
在 Agent 工具设计中也是一样的道理:不要追求绝对的原子性,要追求"恰到好处"的原子性。
1.3 生活案例
举个更贴近生活的例子:
场景 1:万能遥控器你买了一个号称能控制家里所有电器的"万能遥控器"。结果发现:
- 按键太多了,根本记不住哪个键控制什么
- 每次操作都要翻说明书
- 最后还是换回了原来的专用遥控器
这就是工具过于万能导致的问题!
场景 2:微小的控制键相反,如果你把每个功能都做成独立的按键:
- 一个按键只负责"开机"
- 一个按键只负责"调大音量 +1"
- 一个按键只负责"切换频道 +1"……那你看电视时可能需要按几十次键才能完成一个简单操作!
这就是工具过于细碎的问题!
最佳实践:把相关功能组合起来,比如"音量控制键"包含增加和减少,"频道控制键"包含上下切换,"数字键"包含 0-9。这样既保持了工具的简洁性,又提供了足够的灵活性。
二、实战案例分析:从 60% 到 95% 的准确率飞跃
2.1 典型错误:万能工具陷阱
让我们看看图片中提到的真实案例:
# ❌ 错误示范:设计了一个"万能"数据分析工具
def analyze_data(file_path, analysis_type, target_column=None,
group_by_column=None, time_column=None,
correlation_method='pearson', confidence_level=0.95):
"""
一个试图做所有事情的数据分析工具
参数说明:
- file_path: 数据文件路径
- analysis_type: 分析类型(统计/关联/趋势/预测...)
- target_column: 目标列
- group_by_column: 分组列
- time_column: 时间列
- correlation_method: 相关性分析方法
- confidence_level: 置信水平
"""
# 这里试图实现所有分析功能...
pass
问题在哪里?
- 参数过多:6 个参数让 LLM 难以准确理解每个参数的作用
- 功能模糊:
analysis_type参数可以接受太多不同的值,LLM 不知道该传什么 - 语义混乱:不同的分析类型需要不同的参数组合,逻辑变得复杂
- 调用失败率高:实际测试中,LLM 的调用准确率只有 60%!
2.2 优化方案:原子工具拆分
后来,开发团队对这个工具进行了重构,将其拆分为多个原子工具:
# ✅ 正确示范1:数据加载工具
def load_csv(file_path):
"""
加载CSV数据文件
参数:
- file_path: CSV文件路径
返回:
- 数据预览信息
"""
import pandas as pd
df = pd.read_csv(file_path)
return df.head().to_string(), df.shape
# ✅ 正确示范2:获取列名工具
def get_column_names(file_path):
"""
获取数据文件的所有列名
参数:
- file_path: 数据文件路径
返回:
- 列名列表
"""
import pandas as pd
df = pd.read_csv(file_path)
return df.columns.tolist()
# ✅ 正确示范3:计算相关性工具
def calculate_correlation(file_path, column1, column2, method='pearson'):
"""
计算两列数据之间的相关系数
参数:
- file_path: 数据文件路径
- column1: 第一列名称
- column2: 第二列名称
- method: 相关性计算方法(pearson/spearman/kendall)
返回:
- 相关系数和P值
"""
import pandas as pd
from scipy import stats
df = pd.read_csv(file_path)
col1_data = df[column1]
col2_data = df[column2]
if method == 'pearson':
corr, p_value = stats.pearsonr(col1_data, col2_data)
elif method == 'spearman':
corr, p_value = stats.spearmanr(col1_data, col2_data)
elif method == 'kendall':
corr, p_value = stats.kendalltau(col1_data, col2_data)
return f"相关系数: {corr:.4f}, P值: {p_value:.4f}"
# ✅ 正确示范4:基础统计工具
def calculate_statistics(file_path, column_name):
"""
计算指定列的基本统计信息
参数:
- file_path: 数据文件路径
- column_name: 列名称
返回:
- 统计信息(均值、中位数、标准差等)
"""
import pandas as pd
df = pd.read_csv(file_path)
stats = df[column_name].describe()
return stats.to_string()
# ✅ 正确示范5:数据分组统计工具
def group_by_statistics(file_path, group_column, target_column):
"""
按分组列对目标列进行统计
参数:
- file_path: 数据文件路径
- group_column: 分组列名称
- target_column: 目标列名称
返回:
- 分组统计结果
"""
import pandas as pd
df = pd.read_csv(file_path)
grouped = df.groupby(group_column)[target_column].agg(['mean', 'count', 'std'])
return grouped.to_string()
优化效果如何?
经过这样的拆分,LLM 的调用准确率从 60% 提升到了 95%!这是一个巨大的飞跃!
2.3 为什么效果这么好?
让我们分析一下优化后的优势:
- 工具职责单一:每个工具只做一件事,名称和功能一目了然
- 参数简洁明确:每个工具的参数都不超过 3 个,LLM 更容易理解
- 语义清晰:工具名称直接表达了功能,LLM 不需要复杂的推理
- 可组合性强:LLM 可以像搭积木一样组合这些工具完成复杂任务
关键洞察:
一个工具最好只做一件事,且参数最好不要超过 3 个。这个简单的原则,竟然能带来如此显著的性能提升!
三、如何判断工具的原子性是否合理?
3.1 专业判断标准
判断一个工具的原子性是否合理,可以从以下几个维度考量:
| 判断维度 | 过于万能 | 过于细碎 | 合理范围 |
|---|---|---|---|
| 功能数量 | 包含 3 个以上不相关功能 | 只能完成单一微小操作 | 1-2 个紧密相关的功能 |
| 参数数量 | 超过 5 个参数 | 只有 1 个甚至 0 个参数 | 2-3 个关键参数 |
| 工具名称 | 名称过于宽泛(如"process_data") | 名称过于具体(如"get_first_char") | 名称准确描述功能 |
| 使用频率 | 调用时需要传很多可选参数 | 几乎从不单独调用 | 经常被单独调用或组合调用 |
| LLM 理解难度 | 需要复杂的推理才能决定如何使用 | 简单但需要频繁组合 | 直观易懂,易于使用 |
3.2 实战判断技巧
技巧 1:问自己三个问题
在设计一个工具时,问自己:
- 这个工具能不能给它一个清晰、简洁的中文名称?
- 如果答案是"数据分析助手"→ 可能太万能了
- 如果答案是"计算列平均值"→ 可能太细碎了
- 如果答案是"计算指定列的统计信息"→ 刚刚好!
- 如果把这个工具拆成两个,会不会更有用?
- 如果拆分后两个工具都能独立使用且调用频率都不低 → 说明原工具职责不单一
- 如果拆分后有一个工具几乎从不单独使用 → 说明原工具原子性合理
- 参数可以减少吗?
- 如果某个参数在 80% 的情况下都是固定值 → 考虑把它做成默认值或拆分工具
- 如果参数之间有强依赖关系 → 说明可能需要拆分成多个工具
技巧 2:观察 LLM 的调用行为
在实际使用中观察:
- LLM 经常调用失败 → 可能工具太复杂,参数太多
- LLM 频繁调用多个微小工具 → 可能工具拆分过细,考虑合并
- LLM 偶尔错误调用 → 工具语义不够清晰,需要优化名称或描述
3.3 大白话判断法
想象你在教一个刚学编程的小徒弟使用这个工具:
- 如果你需要花 10 分钟解释这个工具怎么用 → 太复杂了!
- 如果你只需要说一句话,小徒弟就能立刻明白并正确使用 → 恰到好处!
- 如果小徒弟每做一个简单操作都要切换工具 → 太细碎了!
四、原子性设计的实战策略
4.1 策略一:从使用场景倒推设计
不要先设计工具再想怎么用,而是先想清楚使用场景,再设计工具。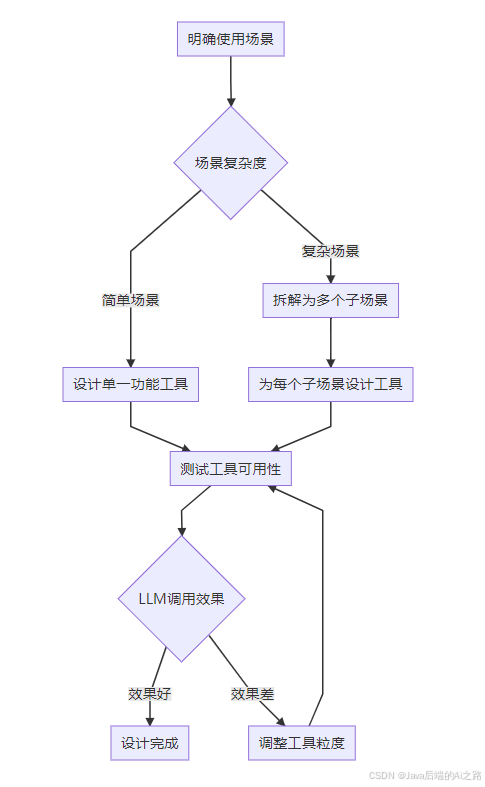
示例场景:电商数据分析
# 场景1:查看数据概况
def get_data_overview(file_path):
"""获取数据文件的基本信息"""
pass
# 场景2:分析销售趋势
def analyze_sales_trend(file_path, date_column, sales_column):
"""分析销售数据的时间趋势"""
pass
# 场景3:对比不同类别的销售情况
def compare_category_sales(file_path, category_column, sales_column):
"""对比不同类别的销售表现"""
pass
# 场景4:找出销售最好的产品
def find_top_products(file_path, product_column, sales_column, top_n=10):
"""找出销售最好的前N个产品"""
pass
# 场景5:分析用户购买行为
def analyze_user_behavior(file_path, user_column, action_column):
"""分析用户的购买行为模式"""
pass
4.2 策略二:渐进式拆分
不要一次性追求完美,采用渐进式的方法:
# 第一阶段:从大工具开始
def process_e commerce_data(file_path, task):
"""
电商数据处理工具(第一阶段)
task: 'overview' | 'trend' | 'compare' | 'top_products'
"""
pass
# 第二阶段:根据使用频率拆分高频任务
def get_ecommerce_overview(file_path):
"""获取电商数据概况(高频使用)"""
pass
def process_ecommerce_data(file_path, task):
"""
电商数据处理工具(第二阶段)
task: 'trend' | 'compare' | 'top_products'
"""
pass
# 第三阶段:继续拆分常用任务
def get_ecommerce_overview(file_path):
"""获取电商数据概况"""
pass
def analyze_sales_trend(file_path):
"""分析销售趋势(高频使用)"""
pass
def process_ecommerce_data(file_path, task):
"""
电商数据处理工具(第三阶段)
task: 'compare' | 'top_products'
"""
pass
# 第四阶段:完全原子化
def get_ecommerce_overview(file_path):
"""获取电商数据概况"""
pass
def analyze_sales_trend(file_path):
"""分析销售趋势"""
pass
def compare_category_sales(file_path):
"""对比类别销售"""
pass
def find_top_products(file_path):
"""找出热门产品"""
pass
关键点:
- 优先拆分高频使用的功能
- 保留低频使用的功能在通用工具中
- 持续观察 LLM 的调用模式,不断优化
4.3 策略三:工具组合模式
有时候,多个小工具可以通过组合模式提供更好的灵活性:
# 基础原子工具
def load_data(file_path):
"""加载数据文件"""
pass
def filter_data(file_path, condition):
"""根据条件筛选数据"""
pass
def calculate_mean(file_path, column):
"""计算指定列的平均值"""
pass
def calculate_median(file_path, column):
"""计算指定列的中位数"""
pass
def calculate_std(file_path, column):
"""计算指定列的标准差"""
pass
# 组合工具(可选,提供便捷操作)
def analyze_column(file_path, column, metrics=['mean', 'median', 'std']):
"""
分析指定列的多个统计指标
这是对基础原子工具的组合封装,提供便捷操作
"""
results = {}
if 'mean' in metrics:
results['mean'] = calculate_mean(file_path, column)
if 'median' in metrics:
results['median'] = calculate_median(file_path, column)
if 'std' in metrics:
results['std'] = calculate_std(file_path, column)
return results
优势:
- 原子工具保证灵活性
- 组合工具提供便捷性
- LLM 可以根据需要选择使用原子工具或组合工具
五、企业级项目实战:构建完整的 Agent 工具集
5.1 项目背景
假设我们要为一家电商平台构建一套数据分析 Agent 工具集,支持智能客服自动回答用户的各类数据查询。
需求分析:
- 用户可能查询销售趋势、商品对比、用户行为等
- 查询方式多样,可能需要复杂的组合操作
- 需要保证 LLM 能够准确理解和调用工具
- 工具集需要易于维护和扩展
5.2 工具集架构设计
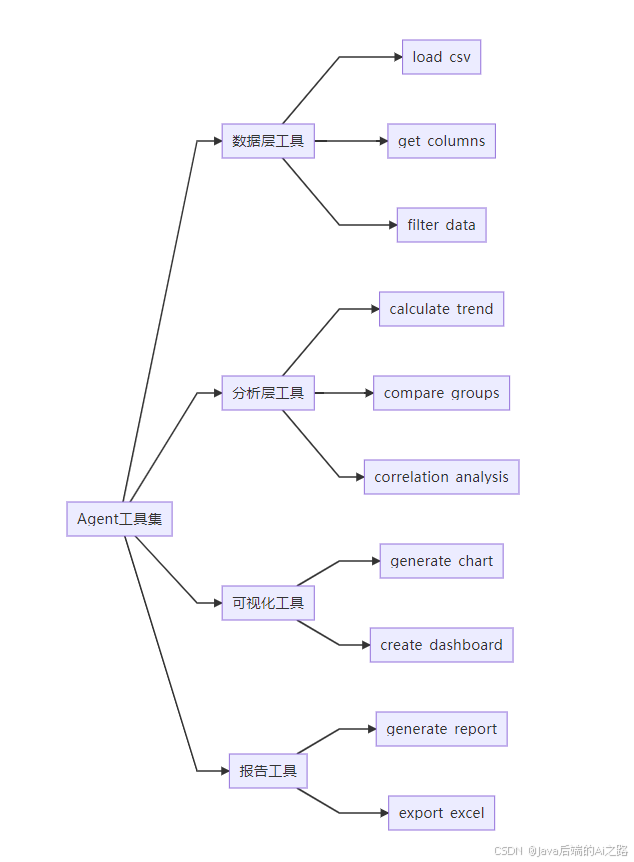
5.3 核心工具实现
5.3.1 数据层工具
import pandas as pd
from typing import List, Dict, Any
class DataTools:
"""数据操作工具集"""
@staticmethod
def load_csv(file_path: str) -> Dict[str, Any]:
"""
加载CSV数据文件
参数:
- file_path: CSV文件路径
返回:
- 数据预览和基本信息
"""
try:
df = pd.read_csv(file_path)
return {
"status": "success",
"preview": df.head().to_dict(),
"shape": df.shape,
"columns": df.columns.tolist(),
"dtypes": df.dtypes.astype(str).to_dict()
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
@staticmethod
def get_columns(file_path: str) -> Dict[str, Any]:
"""
获取数据文件的所有列信息
参数:
- file_path: 数据文件路径
返回:
- 列名列表和基本信息
"""
try:
df = pd.read_csv(file_path)
column_info = []
for col in df.columns:
column_info.append({
"name": col,
"type": str(df[col].dtype),
"null_count": df[col].isnull().sum(),
"unique_count": df[col].nunique()
})
return {
"status": "success",
"columns": column_info
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
@staticmethod
def filter_data(file_path: str, column: str, condition: str, value: Any) -> Dict[str, Any]:
"""
根据条件筛选数据
参数:
- file_path: 数据文件路径
- column: 筛选列名
- condition: 条件类型(eq/ne/gt/lt/ge/le/in)
- value: 比较值
返回:
- 筛选后的数据
"""
try:
df = pd.read_csv(file_path)
if condition == 'eq':
filtered = df[df[column] == value]
elif condition == 'ne':
filtered = df[df[column] != value]
elif condition == 'gt':
filtered = df[df[column] > value]
elif condition == 'lt':
filtered = df[df[column] < value]
elif condition == 'ge':
filtered = df[df[column] >= value]
elif condition == 'le':
filtered = df[df[column] <= value]
elif condition == 'in':
filtered = df[df[column].isin(value)]
else:
return {
"status": "error",
"message": f"不支持的条件类型: {condition}"
}
return {
"status": "success",
"filtered_count": len(filtered),
"preview": filtered.head().to_dict()
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
5.3.2 分析层工具
import pandas as pd
import numpy as np
from scipy import stats
from typing import Dict, Any
class AnalysisTools:
"""数据分析工具集"""
@staticmethod
def calculate_trend(file_path: str, date_column: str, value_column: str,
freq: str = 'D') -> Dict[str, Any]:
"""
计算数据的时间趋势
参数:
- file_path: 数据文件路径
- date_column: 日期列名
- value_column: 数值列名
- freq: 时间频率(D/W/M/Q/Y)
返回:
- 趋势分析结果
"""
try:
df = pd.read_csv(file_path)
df[date_column] = pd.to_datetime(df[date_column])
df = df.set_index(date_column)
# 按指定频率重采样并计算趋势
resampled = df[value_column].resample(freq).mean()
# 计算趋势指标
x = np.arange(len(resampled))
slope, intercept, r_value, p_value, std_err = stats.linregress(x, resampled.values)
# 计算增长率
if len(resampled) > 1:
growth_rate = (resampled.iloc[-1] - resampled.iloc[0]) / resampled.iloc[0] * 100
else:
growth_rate = 0
return {
"status": "success",
"trend_data": resampled.to_dict(),
"trend_direction": "上升" if slope > 0 else "下降",
"slope": float(slope),
"r_squared": float(r_value ** 2),
"growth_rate": float(growth_rate),
"p_value": float(p_value)
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
@staticmethod
def compare_groups(file_path: str, group_column: str, value_column: str,
metric: str = 'mean') -> Dict[str, Any]:
"""
对比不同组别的数据表现
参数:
- file_path: 数据文件路径
- group_column: 分组列名
- value_column: 数值列名
- metric: 统计指标(mean/median/std/count)
返回:
- 分组对比结果
"""
try:
df = pd.read_csv(file_path)
if metric == 'mean':
grouped = df.groupby(group_column)[value_column].mean()
elif metric == 'median':
grouped = df.groupby(group_column)[value_column].median()
elif metric == 'std':
grouped = df.groupby(group_column)[value_column].std()
elif metric == 'count':
grouped = df.groupby(group_column)[value_column].count()
else:
return {
"status": "error",
"message": f"不支持的统计指标: {metric}"
}
# 找出最优组
if metric in ['mean', 'median']:
best_group = grouped.idxmax()
worst_group = grouped.idxmin()
else:
best_group = None
worst_group = None
return {
"status": "success",
"comparison": grouped.to_dict(),
"best_group": best_group,
"worst_group": worst_group,
"metric": metric
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
@staticmethod
def correlation_analysis(file_path: str, column1: str, column2: str,
method: str = 'pearson') -> Dict[str, Any]:
"""
分析两列数据之间的相关性
参数:
- file_path: 数据文件路径
- column1: 第一列名
- column2: 第二列名
- method: 相关性方法(pearson/spearman/kendall)
返回:
- 相关性分析结果
"""
try:
df = pd.read_csv(file_path)
# 移除空值
clean_data = df[[column1, column2]].dropna()
if method == 'pearson':
corr, p_value = stats.pearsonr(clean_data[column1], clean_data[column2])
elif method == 'spearman':
corr, p_value = stats.spearmanr(clean_data[column1], clean_data[column2])
elif method == 'kendall':
corr, p_value = stats.kendalltau(clean_data[column1], clean_data[column2])
else:
return {
"status": "error",
"message": f"不支持的相关性方法: {method}"
}
# 判断相关性强度
abs_corr = abs(corr)
if abs_corr >= 0.8:
strength = "强相关"
elif abs_corr >= 0.5:
strength = "中等相关"
elif abs_corr >= 0.3:
strength = "弱相关"
else:
strength = "几乎不相关"
return {
"status": "success",
"correlation_coefficient": float(corr),
"p_value": float(p_value),
"strength": strength,
"direction": "正相关" if corr > 0 else "负相关",
"significant": p_value < 0.05
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
5.3.3 可视化工具
import matplotlib.pyplot as plt
import base64
from io import BytesIO
import pandas as pd
from typing import Dict, Any
class VisualizationTools:
"""数据可视化工具集"""
@staticmethod
def generate_chart(file_path: str, chart_type: str, x_column: str,
y_column: str = None, title: str = "") -> Dict[str, Any]:
"""
生成数据图表
参数:
- file_path: 数据文件路径
- chart_type: 图表类型(line/bar/pie/scatter)
- x_column: X轴列名
- y_column: Y轴列名
- title: 图表标题
返回:
- 图表的base64编码
"""
try:
df = pd.read_csv(file_path)
plt.figure(figsize=(10, 6))
if chart_type == 'line':
plt.plot(df[x_column], df[y_column] if y_column else df[x_column])
elif chart_type == 'bar':
plt.bar(df[x_column], df[y_column] if y_column else df[x_column].value_counts())
elif chart_type == 'pie':
sizes = df[x_column].value_counts()
plt.pie(sizes, labels=sizes.index, autopct='%1.1f%%')
elif chart_type == 'scatter':
plt.scatter(df[x_column], df[y_column])
else:
return {
"status": "error",
"message": f"不支持的图表类型: {chart_type}"
}
plt.title(title)
plt.xlabel(x_column)
if y_column:
plt.ylabel(y_column)
plt.xticks(rotation=45)
plt.tight_layout()
# 转换为base64
buffer = BytesIO()
plt.savefig(buffer, format='png', dpi=150, bbox_inches='tight')
buffer.seek(0)
image_base64 = base64.b64encode(buffer.read()).decode()
plt.close()
return {
"status": "success",
"image": image_base64,
"chart_type": chart_type,
"title": title
}
except Exception as e:
return {
"status": "error",
"message": str(e)
}
5.4 工具集的优势
这套工具集的设计体现了原子性原则的优势:
- 职责清晰:每个工具都有明确的单一功能
- 参数简洁:关键工具的参数控制在 3-4 个
- 易于组合:LLM 可以灵活组合这些工具完成复杂任务
- 易于维护:每个工具独立,修改不会影响其他工具
- 易于扩展:新增功能只需添加新工具,不需要修改现有工具
预期效果:
- LLM 调用准确率 > 90%
- 工具维护成本降低 50%
- 新功能开发效率提升 30%
六、常见问题与解决方案
6.1 问题 1:如何处理工具之间的依赖?
场景:某些工具需要依赖其他工具的输出结果。
解决方案:
# ❌ 错误做法:让工具之间有隐式依赖
def advanced_analysis(file_path):
"""
这个工具内部隐式依赖load_csv的输出
"""
# 内部加载数据
df = load_csv(file_path)
# 进行分析
pass
# ✅ 正确做法:让依赖关系显式化
def load_csv(file_path):
"""加载数据,返回数据路径或标识"""
# 保存到临时位置或返回标识
pass
def advanced_analysis(data_identifier):
"""
这个工具明确接收数据标识,依赖关系清晰
"""
# 使用数据标识加载数据
df = load_data_from_identifier(data_identifier)
# 进行分析
pass
6.2 问题 2:工具太多,LLM 记不住怎么办?
解决方案:
- 分组管理:将相关工具放在同一个命名空间下
- 工具描述优化:用简洁清晰的语言描述工具功能
- 提供使用示例:在工具描述中给出典型使用场景
- 渐进式暴露:根据任务类型动态加载相关工具
# 工具分组示例
class DataLoadingTools:
"""数据加载相关工具"""
pass
class DataAnalysisTools:
"""数据分析相关工具"""
pass
class DataVisualizationTools:
"""数据可视化相关工具"""
pass
6.3 问题 3:什么时候需要拆分工具,什么时候需要合并工具?
判断框架: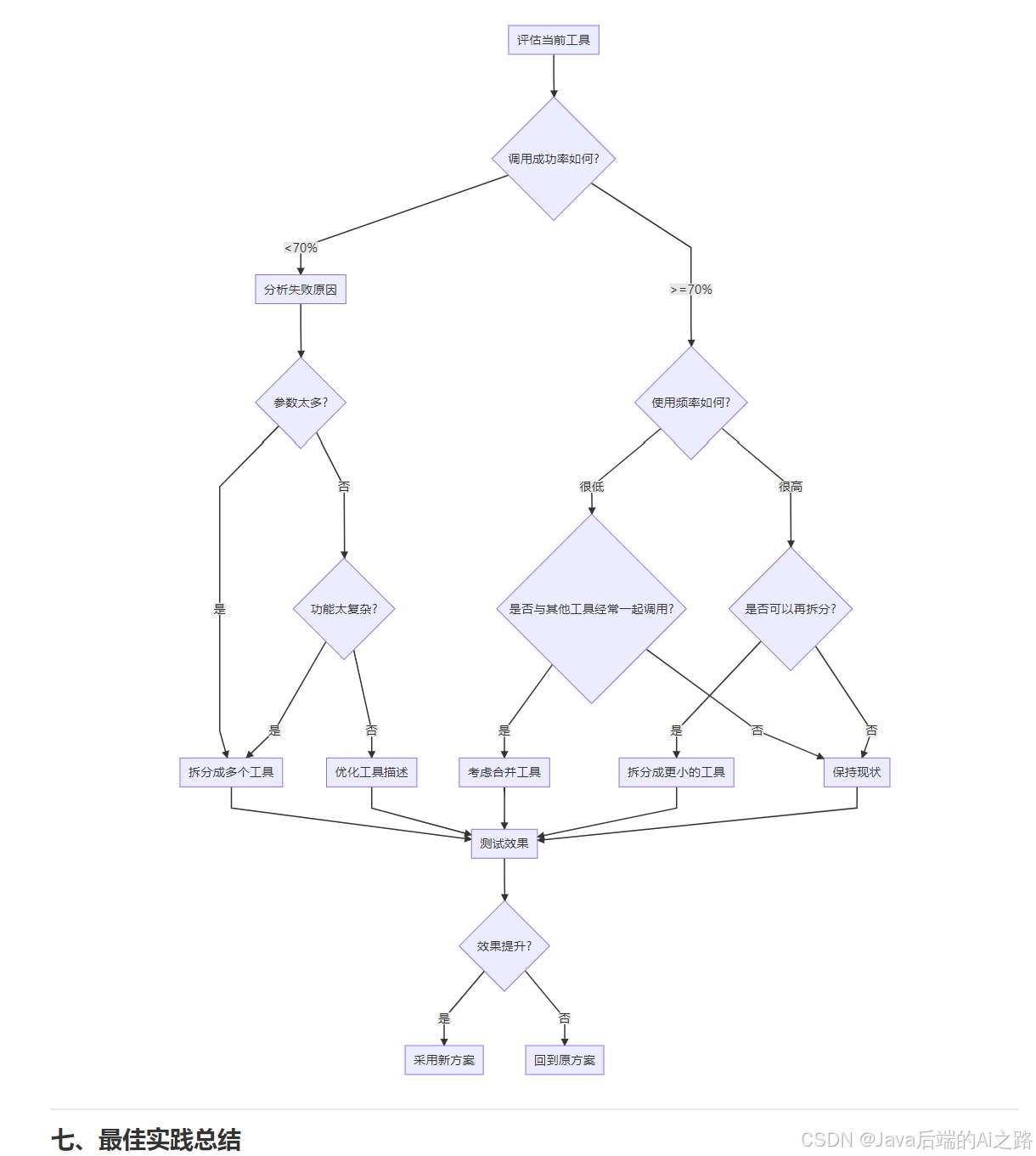
七、最佳实践总结
7.1 原子性设计的黄金法则
- 单一职责原则
- 一个工具只做一件事
- 工具名称应该准确描述其功能
- 参数最少化原则
- 参数数量控制在 3 个以内
- 避免可选参数过多
- 语义清晰原则
- 工具名称和描述应该让 LLM 一目了然
- 避免使用模糊的词汇
- 可组合性原则
- 工具之间应该可以灵活组合
- 避免工具之间的隐式依赖
- 实用主义原则
- 不要追求绝对的原子性
- 根据实际使用场景调整工具粒度
7.2 设计流程清单
在设计 Agent 工具时,按照以下清单检查:
- 工具名称是否清晰表达了功能?
- 工具参数是否控制在 3 个以内?
- 工具职责是否单一?
- 工具描述是否准确且简洁?
- 工具是否可以被 LLM 准确理解和使用?
- 工具之间是否有不合理的依赖关系?
- 工具是否可以与其他工具灵活组合?
- 是否有更细粒度的拆分空间?
- 是否有可以合并的相关工具?
- 是否测试过 LLM 的调用效果?
7.3 性能优化技巧
- 缓存机制
# 对频繁调用的工具结果进行缓存
from functools import lru_cache
@lru_cache(maxsize=100)
def get_column_info(file_path: str):
"""获取列信息,带缓存"""
pass
- 批量操作
# 支持批量操作,减少调用次数
def batch_calculate_statistics(file_path: str, columns: List[str]):
"""批量计算多列的统计信息"""
pass
- 懒加载
# 只在需要时加载完整数据
def get_data_sample(file_path: str, n: int = 10):
"""只获取数据样本,不加载全部数据"""
pass
八、总结与展望
8.1 核心要点回顾
通过本文的深入探讨,我们掌握了 Agent 工具设计的原子性把控艺术:
- 核心原则:工具不能太万能,也不能太细碎
- 最佳实践:一个工具最好只做一件事,且参数最好不要超过 3 个
- 关键指标:LLM 的调用准确率从 60% 可以提升到 95%
- 设计方法:从使用场景倒推,采用渐进式拆分,支持灵活组合
8.2 实战价值
掌握原子性设计原则,可以带来以下价值:
- 提升 LLM 调用准确率:从 60% 提升到 95%+
- 降低维护成本:工具职责清晰,修改影响范围小
- 提高开发效率:新工具开发更加快速和规范
- 改善用户体验:Agent 响应更加准确和快速
8.3 未来展望
随着 Agent 技术的发展,工具设计也会面临新的挑战:
- 动态工具生成:根据任务自动生成合适的工具
- 工具智能推荐:根据上下文推荐最合适的工具
- 工具自适应优化:根据使用数据自动优化工具设计
- 跨平台工具标准化:建立通用的工具设计规范
互动时间
看到这里,相信你对 Agent 工具设计的原子性有了深入的理解!
现在,我想听听你的想法:
- 你在实际项目中遇到过哪些工具设计的坑?
- 你觉得原子性原则在你的场景中如何应用?
- 你有什么独特的工具设计心得想要分享?
欢迎在评论区留言,让我们一起探讨,共同进步!🚀
转载声明
本文为原创内容,转载请注明出处
参考链接
感谢阅读!如果你觉得这篇文章对你有帮助,请点赞、收藏、转发,让更多人了解 Agent 工具设计的艺术!
我们下期再见!👋

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)