2026年3月AI代码能力排行榜深度解析:Anthropic霸榜,国产模型崛起
数据来源:Arena.ai Code Leaderboard
统计时间:2026年3月26日
样本规模:214,231次投票,57个模型参与评测
更新时间:2026年3月27日

🎯 前言
在AI大模型竞争白热化的2026年,代码能力已成为衡量模型实用价值的核心指标。本文基于Arena.ai这一权威众测平台的最新数据,对全球57个大模型的代码能力进行全景分析。令人震惊的是,Anthropic Claude系列完全霸榜前5名,而国产模型智谱AI(Z.ai)、小米、MiniMax、月之暗面也展现出强劲实力。
📊 一、Arena.ai 排名机制解读
1.1 评测方式:众测对战 + Elo评分
Arena.ai(原LMSYS Chatbot Arena)是目前最受业界认可的AI模型众测平台,其核心机制包括:
- 盲测对战:用户同时与两个匿名模型交互,根据代码质量投票
- Elo评分系统:国际象棋排名同款算法,动态计算模型实力
- 置信区间:每个排名附带统计置信区间(如+11/-11)
- 多维度评测:涵盖代码生成、调试、重构、算法实现等场景
1.2 数据来源可靠性
统计时间:2026年3月26日
总投票数:214,231次
参与模型:57个
排名更新频率:实时
相比传统Benchmark的优势:
- ✅ 真实开发者主观评价,非客观题刷分
- ✅ 覆盖实际开发场景(WebDev、算法、系统编程等)
- ✅ 避免训练集污染(测试数据对模型不可见)
- ✅ 统计样本量大,结果可信度高
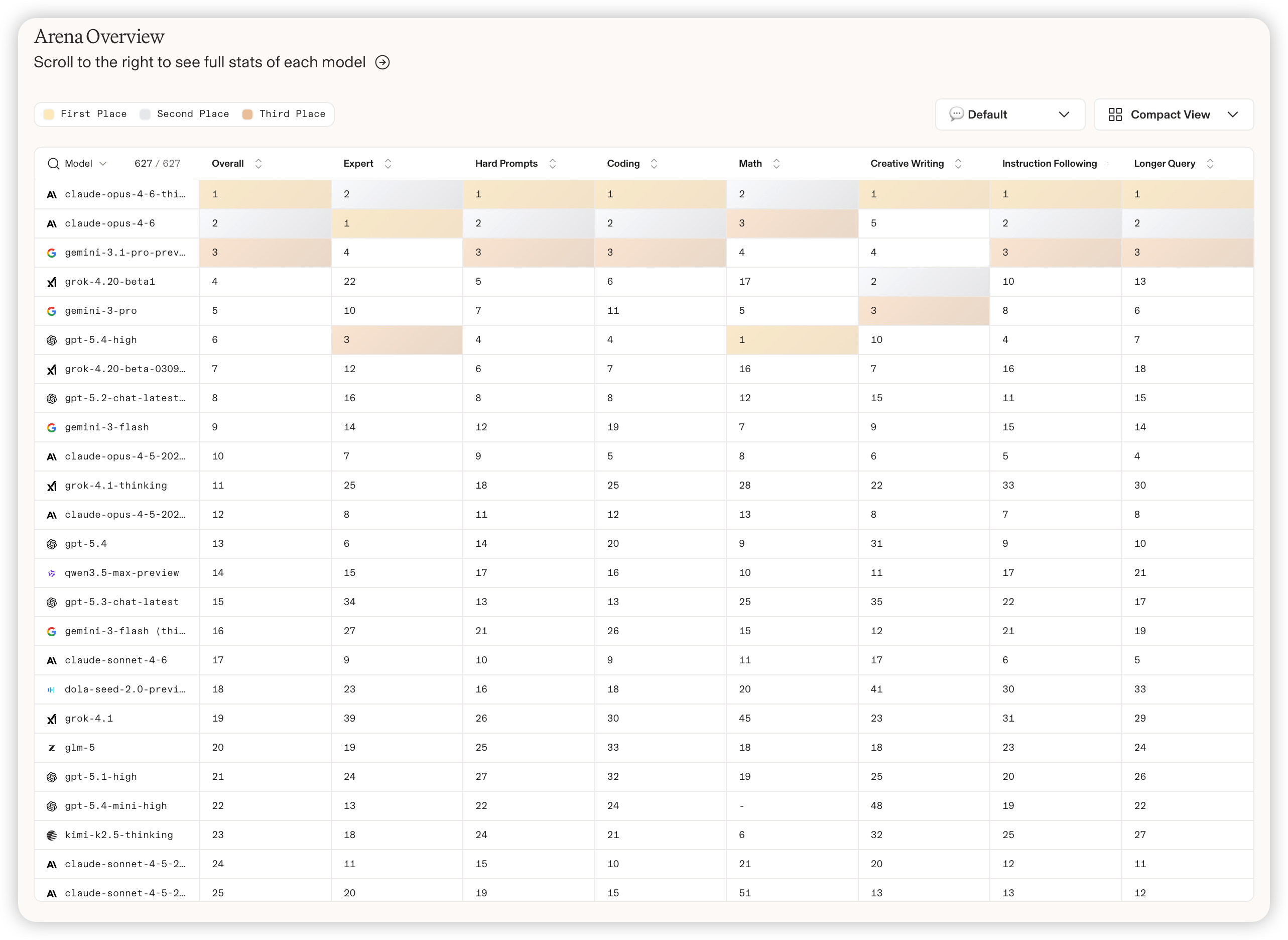
🏆 二、TOP 15 排名全景
2.1 综合排名榜单
| 排名 | 模型 | 厂商 | 分数 | 投票数 | 价格(输入/输出) | 上下文 | 开源协议 |
|---|---|---|---|---|---|---|---|
| 🥇 1 | claude-opus-4-6 | Anthropic | 1549 | 4,264 | $5 / $25 | 1M | 闭源 |
| 🥈 2 | claude-opus-4-6-thinking | Anthropic | 1545 | 3,495 | $5 / $25 | 1M | 闭源 |
| 🥉 3 | claude-sonnet-4-6 | Anthropic | 1523 | 6,391 | $3 / $15 | 1M | 闭源 |
| 4 | claude-opus-4-5-20251101-thinking-32k | Anthropic | 1491 | 13,247 | $5 / $25 | 200K | 闭源 |
| 5 | claude-opus-4-5-20251101 | Anthropic | 1465 | 13,559 | $5 / $25 | 200K | 闭源 |
| 6 | gpt-5.4-high (codex-harness) | OpenAI | 1457 | 1,488 | N/A | N/A | 闭源 |
| 7 | gemini-3.1-pro-preview | 1455 | 4,733 | $2 / $12 | 1M | 闭源 | |
| 8 | glm-5 | Z.ai (智谱) | 1445 | 4,265 | $1 / $3.20 | 202.8K | MIT开源 |
| 9 | glm-4.7 | Z.ai (智谱) | 1439 | 4,877 | $0.39 / $1.75 | 202.8K | MIT开源 |
| 10 | gemini-3-pro | 1438 | 17,152 | $2 / $12 | 1M | 闭源 | |
| 11 | mimo-v2-pro | 小米 | 1437 | 2,209 | $1 / $3 | 1M | 闭源 |
| 12 | gemini-3-flash | 1437 | 13,266 | $0.50 / $3 | 1M | 闭源 | |
| 13 | minimax-m2.7 | MiniMax | 1435 | 2,133 | $0.30 / $1.20 | 204.8K | 闭源 |
| 14 | kimi-k2.5-thinking | 月之暗面 | 1430 | 6,421 | $0.60 / $3 | N/A | 修改MIT |
| 15 | gpt-5.4-medium (codex-harness) | OpenAI | 1428 | 1,575 | N/A | N/A | 闭源 |
2.2 关键发现
🔥 发现1:Anthropic 完全霸榜(Top 5全包)
Claude系列统治代码领域:
- claude-opus-4-6 以1549分夺冠,领先第二名4分
- 前5名全部被Anthropic包揽,这是历史上首次有厂商如此统治单一领域
- 即使是较旧的 claude-opus-4-5(1465分)也超过了GPT-5.4-high(1457分)
技术特点:
- 在复杂算法实现、代码重构、Bug修复上表现卓越
- Thinking模式(思维链)对代码质量提升明显
- 长上下文(1M tokens)支持大型代码库理解
🌟 发现2:国产模型集体崛起(4个进Top 15)
智谱AI(Z.ai)- 开源之光:
- GLM-5(1445分)排名第8,MIT开源协议
- GLM-4.7(1439分)排名第9,MIT开源协议
- 价格仅为Claude的1/5,性价比极高
小米 - 后来者居上:
- mimo-v2-pro(1437分)排名第11
- 作为手机厂商首次进入代码能力第一梯队
MiniMax - 性价比之选:
- minimax-m2.7(1435分)排名第13
- 价格仅$0.30/$1.20,性价比极高
月之暗面 - 长文本专家:
- kimi-k2.5-thinking(1430分)排名第14
- 在长代码理解和生成上有独特优势
😱 发现3:OpenAI 意外落后
GPT-5.4系列表现不及预期:
- gpt-5.4-high(1457分)仅排第6,落后Claude 4-6达92分
- gpt-5.4-medium(1428分)排第15
- 即使是Codex专用版本也未能进入前三
可能原因分析:
- GPT-5.4更侧重通用能力,代码专项优化不足
- OpenAI可能将资源投入Agent和多模态
- Claude在代码领域持续深耕,形成护城河
💎 发现4:开源 vs 闭源差距缩小
| 类别 | Top 10占比 | 最高排名 | 代表模型 |
|---|---|---|---|
| 闭源 | 80% | #1 | Claude系列 |
| 开源 | 20% | #8 | GLM-5 |
GLM-5的启示:
- 以1445分排名第8,仅落后Gemini-3.1-pro-preview(1455分)10分
- MIT开源协议,可自由商用和修改
- 价格仅为闭源模型的1/5-1/10
📈 三、深度数据分析
3.1 分数分布与梯队划分
第一梯队(1500+):顶级代码专家
├── Claude Opus 4-6 (1549) ★★★★★
└── Claude Opus 4-6 Thinking (1545) ★★★★★
第二梯队(1450-1500):专业级代码能力
├── Claude Sonnet 4-6 (1523) ★★★★☆
├── Claude Opus 4-5系列 (1465-1491) ★★★★☆
├── GPT-5.4-high (1457) ★★★★
└── Gemini-3.1-pro-preview (1455) ★★★★
第三梯队(1420-1450):优秀代码助手
├── GLM-5 (1445) ★★★★
├── GLM-4.7 (1439) ★★★★
├── Gemini-3-pro (1438) ★★★★
├── Mimo-v2-pro (1437) ★★★★
├── Gemini-3-flash (1437) ★★★★
├── MiniMax-m2.7 (1435) ★★★★
├── Kimi-k2.5-thinking (1430) ★★★☆
└── GPT-5.4-medium (1428) ★★★☆
第四梯队(1380-1420):良好代码能力
├── Kimi-k2.5-instant (1408)
├── GPT-5.3-codex (1407)
├── MiniMax-m2.5 (1403)
├── GPT-5.2 (1403)
└── GPT-5-medium (1392)
第五梯队(1350-1380):基础代码能力
├── Qwen3.5系列 (1364-1387)
├── DeepSeek-v3.2-thinking (1369)
├── Grok-4.20 (1378)
└── GLM-4.6 (1353)
3.2 性价比分析(分数/价格)
| 模型 | 分数 | 每百万tokens成本 | 性价比指数 |
|---|---|---|---|
| GLM-4.7 | 1439 | $0.39+$1.75=$2.14 | 672.4 ⭐ |
| MiniMax-m2.7 | 1435 | $0.30+$1.20=$1.50 | 956.7 ⭐⭐⭐ |
| Gemini-3-flash | 1437 | $0.50+$3=$3.50 | 410.6 |
| DeepSeek-v3.2-thinking | 1369 | $0.26+$0.38=$0.64 | 2139 ⭐⭐⭐⭐⭐ |
| GLM-5 | 1445 | $1+$3.20=$4.20 | 344.0 |
| Kimi-k2.5-thinking | 1430 | $0.60+$3=$3.60 | 397.2 |
| Claude-Sonnet-4-6 | 1523 | $3+$15=$18 | 84.6 |
| Claude-Opus-4-6 | 1549 | $5+$25=$30 | 51.6 |
性价比之王:DeepSeek-v3.2-thinking
- 仅$0.64/百万tokens,分数1369
- 性价比指数高达2139,是Claude的41倍!
开源性价比之选:MiniMax-m2.7
- 分数1435(排名第13)
- 价格仅$1.50/百万tokens
- 性价比指数956.7
3.3 上下文长度对比
| 模型 | 上下文长度 | 适用场景 |
|---|---|---|
| Grok-4.20 | 2M | 超大型代码库分析 |
| Qwen3.5系列 | 262.1K | 大型项目理解 |
| Kimi-k2.5系列 | 262.1K | 长文档处理 |
| MiniMax-m2.7 | 204.8K | 中大型项目 |
| GLM系列 | 202.8K | 中大型项目 |
| Claude系列 | 1M/200K | 灵活配置 |
| Gemini系列 | 1M | 大型项目 |
| GPT-5.x系列 | 400K | 中型项目 |
🌍 四、厂商竞争格局分析
4.1 Anthropic - 代码领域绝对霸主
市场地位:
- 代码能力榜单Top 5全包
- 领先第二名(自己)4分,领先OpenAI 92分
- 在开发者社区口碑极佳
技术护城河:
- 长期专注代码领域优化
- Computer Use功能(AI操控计算机)业界领先
- Artifacts功能(实时预览代码效果)独一档
- 代码安全性和可维护性评估严谨
产品线:
旗舰级:Claude Opus 4-6 (1549分) - $30/M tokens
专业级:Claude Sonnet 4-6 (1523分) - $18/M tokens
旧旗舰:Claude Opus 4-5 (1465分) - $30/M tokens
4.2 OpenAI - 需要反思
意外落后的表现:
- GPT-5.4-high仅排第6,落后Claude 92分
- Codex专用版本也未能进入前三
- 与Chatbot Arena综合排名(GPT通常第一)形成反差
可能原因:
- 资源分散:Agent、多模态、语音等同步开发
- 代码领域专注度不足
- GPT-5.4可能更侧重通用推理而非专项优化
应对策略预测:
- 可能推出Codex 2.0专门对抗Claude
- 或收购代码AI公司补强
- 加强与GitHub Copilot的整合
4.3 Google - 稳健但不够惊艳
Gemini系列表现:
- Gemini-3.1-pro-preview第7(1455分)
- Gemini-3-pro第10(1438分)
- Gemini-3-flash第12(1437分)
特点:
- 全系列表现均衡,无明显短板
- Flash版本性价比不错($3.5/M)
- 多模态能力强(代码+图像理解)
与Claude差距:94分(约1.5个标准差)
4.4 国产厂商 - 集体崛起
🏢 智谱AI(Z.ai)- 开源领军
排名表现:
- GLM-5第8(1445分),MIT开源
- GLM-4.7第9(1439分),MIT开源
竞争力分析:
- 开源协议友好(MIT),可商用
- 性价比高(GLM-4.7仅$2.14/M)
- 上下文长度202.8K够用
- 与闭源巨头差距仅10-20分
意义:
- 证明了国产开源模型可以达到国际一流水平
- 为企业私有化部署提供高性价比选择
📱 小米 - 跨界黑马
Mimo-v2-pro(1437分)排名第11
意外之处:
- 手机厂商跨界AI,首次进入代码Top 15
- 价格$4/M,定位中高端
- 可能与小米生态(手机、IoT)深度整合
🚀 MiniMax - 性价比专家
MiniMax-m2.7(1435分)排名第13
核心优势:
- 价格仅$1.50/M,性价比指数956.7
- 上下文204.8K
- 在中文+代码混合场景有独特优势
🌙 月之暗面 - 长文本专家
Kimi-k2.5-thinking(1430分)排名第14
长上下文优势:
- 262.1K上下文,适合大型代码库
- Thinking模式支持复杂推理
- 在代码审查、重构场景有优势
💡 五、开发者选型建议
5.1 按场景推荐
🥇 企业级生产环境
推荐:Claude Opus 4-6 或 Claude Sonnet 4-6
理由:
- 代码质量最高,Bug最少
- 安全性和可维护性评估严谨
- Artifacts功能提升开发效率
成本:$18-30/百万tokens
💰 预算敏感/初创团队
推荐:GLM-4.7(开源)或 MiniMax-m2.7
理由:
- GLM-4.7 MIT开源,可私有化部署,零API成本
- MiniMax性价比指数956.7,排名第三
- 分数1435-1439,仅落后Claude 80-90分
成本:$1.5-2.14/百万tokens(或使用开源模型零成本)
🌐 全栈开发/多语言
推荐:Gemini-3.1-pro-preview 或 GPT-5.4-high
理由:
- 多语言支持全面
- 与Google Cloud/Azure生态整合好
- 适合云原生开发
成本:$2-12/百万tokens
🇨🇳 中文+代码混合场景
推荐:GLM-5、MiniMax-m2.7、Qwen3.5系列
理由:
- 中文理解能力最强
- 中文注释、文档处理准确
- 国内访问速度快
成本:$0.26-4.2/百万tokens
📚 大型代码库分析
推荐:Kimi-k2.5-thinking 或 Grok-4.20
理由:
- 上下文最长(262.1K-2M)
- 适合微服务架构、大型项目理解
- Thinking模式支持深度分析
成本:$3-8/百万tokens
5.2 按预算推荐
| 月预算 | 推荐方案 | 预计月调用量 |
|---|---|---|
| 💸 免费 | GLM-4.7/5(开源本地部署)+ Google AI Studio(Gemini Flash免费额度) | 无限制 |
| 💰 $50 | MiniMax-m2.7主力 + GLM-4.7辅助 | ~30M tokens |
| 💎 $200 | Claude Sonnet 4-6主力 + GLM-4.7辅助 | ~10M tokens |
| 👑 $500+ | Claude Opus 4-6主力 + Gemini-3.1-pro辅助 | ~15M tokens |
🔮 六、2026年下半年趋势预测
6.1 技术趋势
1️⃣ Agentic Coding(代理式编程)爆发
- 模型不再只是生成代码,而是能自主调试、测试、部署
- Anthropic的Computer Use模式将成为标配
- GitHub Copilot X、Cursor等AI IDE深度整合
2️⃣ 多模态代码理解
- 截图转代码(UI→Code)成为标配
- 手绘草图直接生成可运行程序
- 视频教程自动转代码实现
3️⃣ 超长上下文竞赛
- 1M tokens将成为入门标准
- 10M+ tokens支持整个代码库理解
- 检索增强生成(RAG)+ 长上下文结合
6.2 竞争格局预测
🥊 OpenAI的反击
- 预计推出Codex 2.0专门对抗Claude
- 可能与GitHub深度整合,推出Copilot Pro Max
- 收购代码AI初创公司补强
🇨🇳 国产模型持续突破
- GLM-6有望进入Top 5
- DeepSeek可能在推理模型上超越GPT
- 小米、华为、字节等更多厂商加入战局
💰 价格战白热化
- 推理成本预计再降50-80%
- 开源模型将主导中低端市场
- 闭源模型转向高端企业市场
6.3 值得关注的新模型
| 预期发布时间 | 模型 | 厂商 | 预期亮点 |
|---|---|---|---|
| Q2 2026 | Claude 4.7 | Anthropic | 巩固代码霸主地位 |
| Q2 2026 | GPT-5.5/Codex 2.0 | OpenAI | 反击Claude |
| Q3 2026 | Gemini-3.5-pro | 缩小与Claude差距 | |
| Q3 2026 | GLM-6 | 智谱AI | 冲击Top 5 |
| Q4 2026 | DeepSeek-v4 | DeepSeek | 推理+代码双强 |
📚 七、参考资源
7.1 实时排名网站
- 🏆 Arena.ai:https://arena.ai/leaderboard/code
- 📊 Chatbot Arena:https://chat.lmsys.org
- 🧪 OpenCompass(中文):https://opencompass.org.cn
- 💻 LiveBench:https://livebench.ai
7.2 开源模型下载
- 🤗 Hugging Face:https://huggingface.co/models
- 🏔️ ModelScope(魔搭):https://modelscope.cn
- 🦙 Ollama本地运行:https://ollama.com
7.3 API调用平台
- 🔌 OpenRouter:https://openrouter.ai(聚合多平台)
- 📈 SiliconFlow:https://siliconflow.cn(国产模型)
- 🌍 DeepSeek API:https://platform.deepseek.com
🎯 八、总结
核心结论
-
Anthropic统治代码领域:Claude系列霸榜Top 5,领先OpenAI达92分,这是历史上首次有厂商如此统治单一领域。
-
国产模型集体崛起:智谱AI(GLM-5/4.7)、小米(Mimo-v2-pro)、MiniMax、月之暗面(Kimi)4个进Top 15,GLM系列更是以MIT开源协议排名第8-9。
-
OpenAI意外落后:GPT-5.4-high仅排第6,Codex专用版本也未能进入前三,可能资源分散到Agent和多模态。
-
性价比格局重构:DeepSeek-v3.2-thinking性价比指数2139,是Claude的41倍;GLM-4.7以MIT开源提供1439分能力。
-
长上下文成为标配:1M tokens成为主流,262K-2M的长上下文模型(Kimi、Grok)在大型代码库场景有独特优势。
给开发者的建议
- 不差钱选Claude:代码质量最高,Artifacts功能独一档
- 性价比选GLM/MiniMax:开源+高性价比,适合预算敏感团队
- 大型项目选Kimi:262K上下文,适合微服务架构
- 中文场景选国产:GLM、MiniMax、Qwen中文理解更准确
一句话总结
2026年3月,Anthropic用Claude系列证明了"专注"的力量,而国产模型用开源和高性价比证明了"弯道超车"的可能。
📮 交流讨论
你对这个排名有什么看法?欢迎在评论区留言讨论!你是用Claude、GPT还是国产模型?体验如何?
版权声明:本文数据来源于Arena.ai公开排名,截至2026年3月26日。排名数据实时更新,请以官网最新数据为准。转载请注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)