AI实践:在Token热之外,我们实验了一套“文言文压缩LLM”的架构
最近,Token中文名定了的消息再次将这一AI时代的新概念推到大家的面前。Token(词元)作为模型处理信息最小计量单位,无论是我们平常向AI咨询提问,还是让 Agent 写代码、写报告,都离不开Token的消耗。
现在,人手一个或者多个AI助手已经成为了生成力的标配,从早期的 Cursor 到 Claude Code,再到最近大火的小龙虾 OpenClaw,工程师的 Work Flow 正在被重塑。
生产效率是起飞了,但成本也实实在在地摆在眼前——高质量的LLM模型真的很贵。
在盈米内部,我们全面拥抱 AI。且慢AI小顾现已服务数十万用户,盈米内部也运行着上千个 AI 工作流。随着规模增长,一个现实问题浮出水面:如何在保证输出质量的前提下,榨干每一个 Token 的价值?
是换便宜的模型?质量掉得厉害。还是做缓存?覆盖场景有限。又或者做 Prompt 优化?边际收益递减。
直到有一天,我们的工程师看到美国人也在学中文,脑子里突然蹦出一个“复古”的想法——文言文不就是一种天然的高密度的信息编码吗?何不试试做个文言文的压缩机?
01、为什么是文言文?
在按 Token 计费的 AI 时代,信息密度直接等同于“金钱”成本。举个很直观的例子:
-
白话文:我想吃点东西
-
英文:I want to eat something
-
文言文:吾欲食
从上面的对比不难看出,文言文仅需三个字,就能表达完整语义。文言文用极简的字符承载复杂语言逻辑的特性,天然具备超高信息密度,这是否能有效降低LLM的使用成本?
顺着这个思路,我们设计了一套低成本的推理方案:
第一步先用 Kimi、DeepSeek 等高性价比大模型,将长文本提示词压缩翻译成文言文;
第二步,我们把精简后的文言文提示词,输入到 Claude Opus、GPT‑5 等昂贵的顶级大模型,并让其同样以文言文回复;
最后一步,再次通过高性价比模型,结合原始提示词将文言结果 “解压缩”,翻译回正常语言,确保输出质量。
这样一来,我们既能保留顶级模型的推理质量,又能大幅压缩顶级模型的推理价格,有望真正实现“质量不变、成本减半”的效果。
(图片由AI生成)
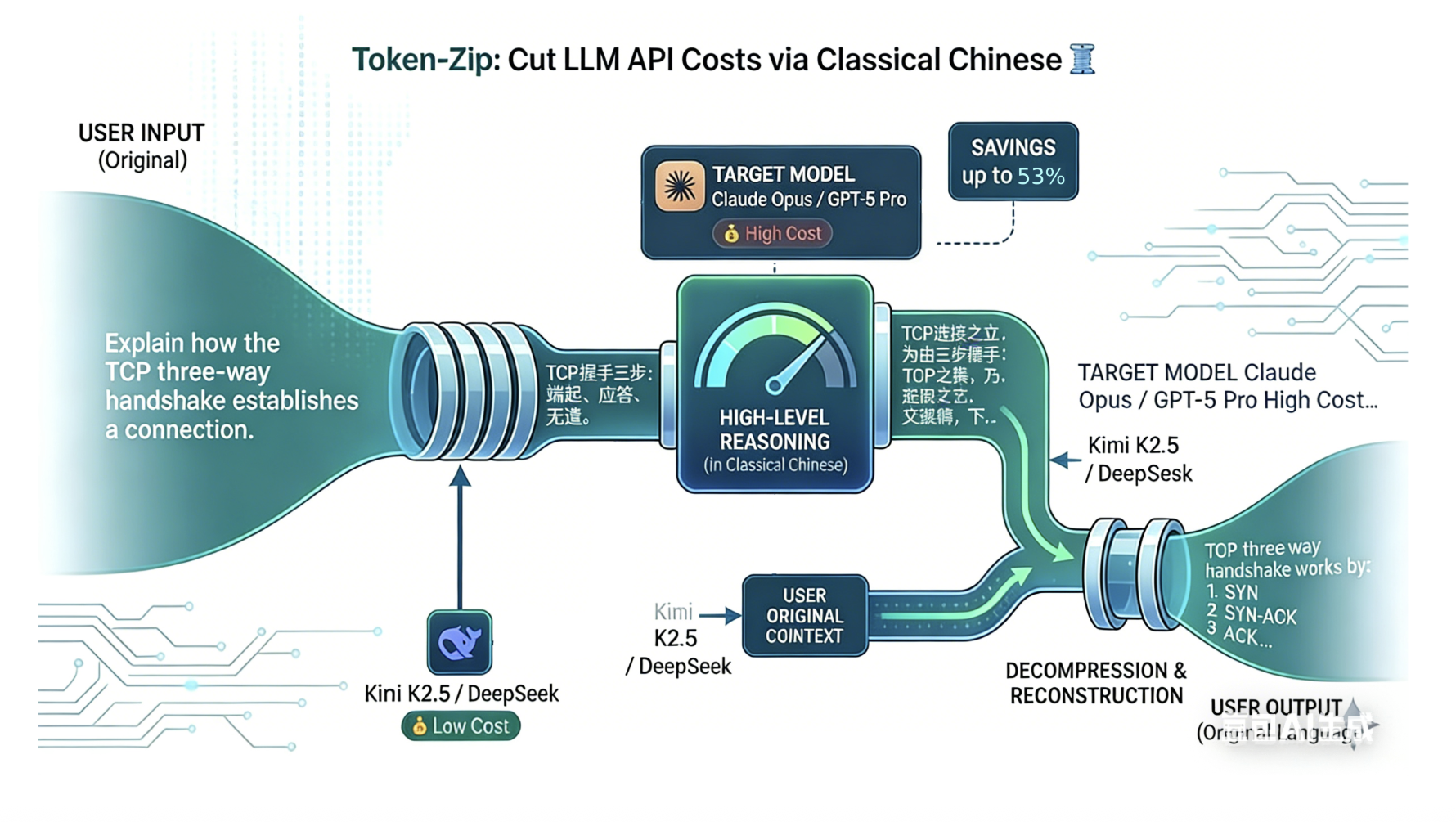
02、方案实现:Token-Zip 三层模型架构
为了验证这个想法,我们在盈米 AI 开放平台设计并落地了 Token-Zip 架构,其核心逻辑是一套三层的模型阶梯机制:
1、核心思路
我们通过将具体的任务进行拆解,利用“模型阶梯”的形式来降低成本的消耗:
-
压缩层(L1 - 低成本、高速度):接收用户原始输入(例如一条原本需消耗 520 Token 的复杂指令),通过调用 Kimi K2.5 这类中文理解能力强、性价比极高的模型,将内容压缩为高信息密度的文言提示词。
-
推理层(L2 - 高成本、高质量): 将压缩后的文言文提示词发送给 Claude Opus 4.6 等顶尖大模型,由于输入的 Token 大幅减少,该模型的推理成本显著下降,同时模型对高密度语义的理解依然保持精准。
-
还原层(L3):由推理模型输出最终结果,可以根据场景需求将文言文的结果还原为白话文 / 英文等目标语言。
2、架构图示
【Token-Zip 架构】▼[ 用户输入 ]"Explain TCP handshake"│▼[ 压缩模型:Kimi K2.5 ] ──► (转化为高密度文言文)(便宜/快)│▼[ 目标模型:Claude Opus 4.6 ] ──► (深度推理)(贵/强)│▼[ 最终解压和输出 ]
03、实测结果:
我们对54个英文提示词进行了实测分析,分别通过直接调用 Claude Opus 4.6 大模型和经由 Token-Zip(压缩模型:Kimi K2.5) 两种方式进行测试,并由独立的 Claude Sonnet 4.6 作为评判模型,从准确性、完整性、清晰度与实用性四个维度,按 1–10 分 对两组回复进行打分。
实测结果显示:
1、回复质量有所提升:
测试结果中,使用Token‑Zip 压缩的方案平均得分为7.6,而直接调用顶尖大模型的方案平均得分为7.3。结果显示,对提示词进行压缩之后会让顶级大模型输出的内容更简洁、更聚焦,而输出质量也略胜一筹。
2、费用成本平均降低 51%:
在全部 54 个提示词中,使用Token‑Zip 方案的费用平均可以节省51%;其中,非技术类内容(人文、法律、科学、医疗)节省的效果最显著,在 57%–66%之间。
04、实践心得:
在内部跑完测试后我们发现——文言文确实是一种被低估的信息编码方式。它用千年时间沉淀出了极致的表达效率,而这恰好契合了 AI 时代的 Token 经济。
这或许不是最优解,但它证明了一点:
传统文化的价值,不只陈列在博物馆里,也可能存在于AI时代的编码中。目前,目前我们已经将Token-Zip 方案在盈米 AI 开放平台进行开源,欢迎大家体验和共创更多玩法。
其实,从更宏大的视角看,这个项目还触及了一个有趣的话题——AI 时代,什么才是人类的独特价值?当 AI 能自动生成代码、写文章、做决策时,人类还能提供什么?
我们认为这个答案是视角。
AI 擅长执行,但人类擅长提出问题、发现关联、跨界思考。就像这个开源项目一样——AI 可以帮你优化prompt,但它不会主动想到用文言文的形式进行压缩从而降低费用成本。
人类的独特价值,在于那些 AI 无法自动产生的连接。而这种连接,往往来自我们对世界的多元理解,也包括对历史、文化、艺术的理解。
开源信息
-
开源地址:https://github.com/yingmi-dev/token-zip
-
欢迎:Star / Fork / Issue / PR
欢迎关注盈米AI开放平台Github账号(yingmi-dev),更多专业 Skill 和AI 工具即将登陆,有任何关于AI使用的心得和想法,也欢迎入群与我们讨论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)