AAAI 2026 | AnoStyler:文本驱动风格迁移实现零样本异常图像生成,轻量高效(附代码)

导读
———————————————————————————————————————————
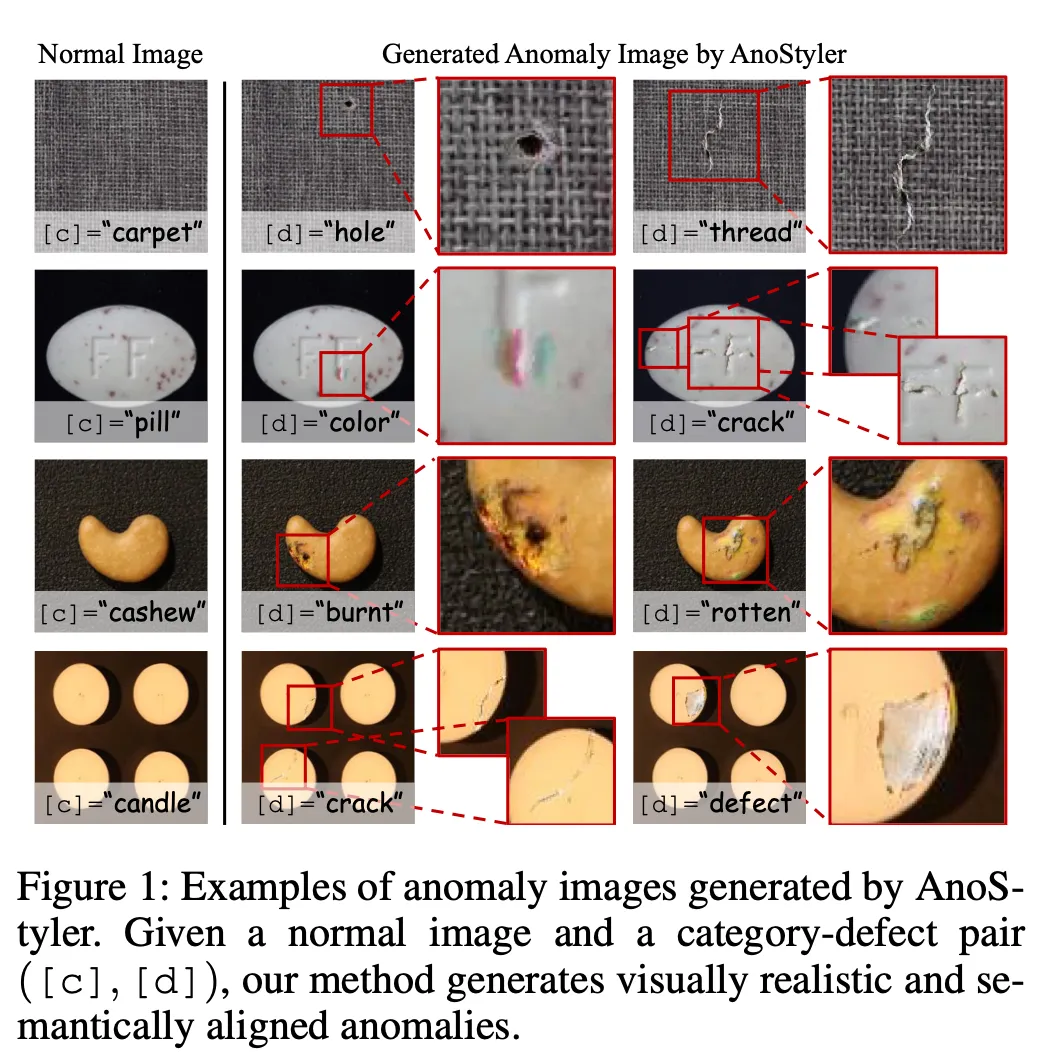
异常检测模型的训练离不开异常样本,但真实工业场景中异常图像极度稀缺。现有异常图像生成方法要么依赖扩散模型等重量级架构(参数量超过1B),要么需要大量正常图像甚至少量真实异常图像,要么生成的异常缺乏视觉真实感。成均馆大学团队换了一个思路:将异常生成重新定义为文本驱动的局部风格迁移——给定一张正常图像、一个类别标签和一个缺陷类型文本,用轻量U-Net在CLIP损失引导下,仅对异常掩码区域进行风格化,生成与文本语义对齐的局部异常。
整个方法零样本(不需要真实异常图像)、单图生成(一张正常图即可)、轻量级(263M参数,9.5 TFLOPs),在MVTec-AD和VisA上的生成质量和下游检测性能在主要指标上超越现有零样本方法,接近甚至超越需要真实异常图像的少样本方法。
论文信息
———————————————————————————————————————————
- 论文标题:AnoStyler: Text-Driven Localized Anomaly Generation via Lightweight Style Transfer
- 作者:Yulim So, Seokho Kang
- 机构:成均馆大学(Sungkyunkwan University)
- 代码:https://github.com/yulimso/AnoStyler
一、异常图像生成为什么重要又困难?
———————————————————————————————————————————
异常检测模型通常在正常样本上以无监督方式训练,但训练数据中缺乏异常样本会限制模型对真实缺陷的泛化能力。因此,异常图像生成(Anomaly Generation)成为近年来的活跃研究方向——通过合成高质量的异常样本来增强下游检测模型的训练。
现有方法分为两类:
|
类型 |
代表方法 |
输入需求 |
局限 |
|---|---|---|---|
|
少样本 |
DFMGAN, AnoDiff, AnoGen |
大量正常图 + 少量真实异常图 |
依赖真实异常图像,采集成本高 |
|
零样本 |
CutPaste, DRAEM, NSA, RealNet, AnomalyAny |
仅正常图像 |
生成质量差(CutPaste/DRAEM/NSA),或依赖扩散模型,计算开销大(AnomalyAny) |
三个核心痛点:
视觉真实感不足:CutPaste、DRAEM 等手工方法通过剪切粘贴或 Perlin 噪声合成异常,生成的缺陷缺乏真实工业缺陷的纹理和语义特征;
依赖大量数据:少样本方法需要大量正常图像和少量真实异常图像,在异常样本极度稀缺的场景下不可行;
计算资源需求高:AnoDiff、AnoGen、RealNet、AnomalyAny 等基于扩散模型的方法参数量超过 1B,生成单张图像的计算开销大,不适合资源受限场景。
AnoStyler 的切入点是:将异常生成重新定义为文本驱动的局部风格迁移,用轻量级模型在 CLIP 语义空间中引导生成,同时解决真实感、零样本和轻量化三个问题。
二、把异常生成重新定义为风格迁移:AnoStyler 怎么做
———————————————————————————————————————————
AnoStyler 的整体流程分为三步:形状引导的掩码生成 → 双类别提示词生成 → 文本驱动的局部异常风格化。
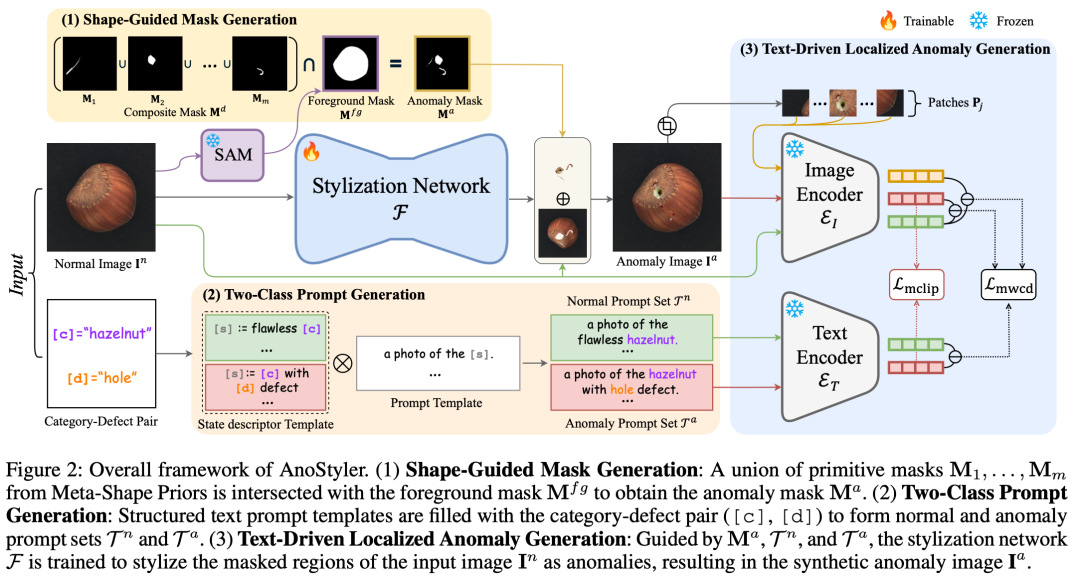
2.1 形状引导的异常掩码生成
异常应该出现在图像的哪个位置、什么形状?AnoStyler 设计了一套与类别无关的轻量掩码生成方案:
- Meta-Shape Priors:定义三种基本几何形状——Line(线状)、Dot(点状)、Freeform(自由形状),分别模拟划痕、点状缺陷和不规则区域。每种形状通过参数化生成(如线状通过连接随机采样点+正弦扰动,点状通过极坐标采样+噪声扰动)。
- 异常区域数量:通过指数衰减的类别分布采样异常区域数量 m(概率 P(m=i) ∝ exp(−αi)),倾向于生成少量异常区域,偶尔允许多区域组合。
- 前景约束:对物体类别(如螺丝、胶囊等),用 SAM(Segment Anything Model, ViT-B)提取前景掩码,将异常区域限制在物体表面;对纹理类别(如地毯、木材等),整个图像即为前景。
最终异常掩码 M^a = M^d ∩ M^{fg},既保证异常形状多样,又约束在合理区域内。
2.2 双类别文本提示词生成
AnoStyler 为每张图像生成两组文本提示词——正常提示集 T^n和 异常提示集 T^a:
-
正常状态描述:如 "a photo of the flawless hazelnut"
-
异常状态描述:如 "a photo of the hazelnut with hole defect"
提示词通过预定义的模板填充类别标签 [c] 和缺陷类型 [d] 自动生成,不需要人工设计。多个语义等价的提示词通过 prompt averaging(CLIP 编码后取均值)融合,减少单一提示词的偏差。
2.3 文本驱动的局部异常风格化
核心生成模块是一个轻量 U-Net(3层下采样 + 3层上采样),以正常图像 I^n 为输入,在 CLIP 损失引导下对掩码区域进行风格化,生成异常图像 I^a。
训练目标由四项损失组成:
L = L_mwcd + λ_mclip · L_mclip + λ_c · L_c + λ_tv · L_tv
|
损失 |
作用 |
|---|---|
| L_mwcd
(掩码加权共方向损失) |
引导生成图像的语义从正常状态向异常状态迁移,包含全局方向对齐(L_gdir)和 patch 级方向对齐(L_pdir),异常掩码区域权重更高 |
| L_mclip
(掩码 CLIP 损失) |
确保异常掩码区域的视觉特征与异常文本提示在 CLIP 空间中对齐 |
| L_c
(内容损失) |
保持生成图像与原始正常图像的整体结构一致 |
| L_tv
(全变差损失) |
保证生成图像的空间平滑性 |
生成的最终异常图像通过掩码合成:I^a = F(I^n) ⊙ M^a + I^n ⊙ (1 − M^a) ,即仅掩码内区域被风格化,掩码外保持原图不变。
CLIP 模型(ViT-B/32)的文本编码器和图像编码器在训练中完全冻结,仅 U-Net 可训练。
三、生成质量:零样本方法比肩甚至超越少样本方法
———————————————————————————————————————————
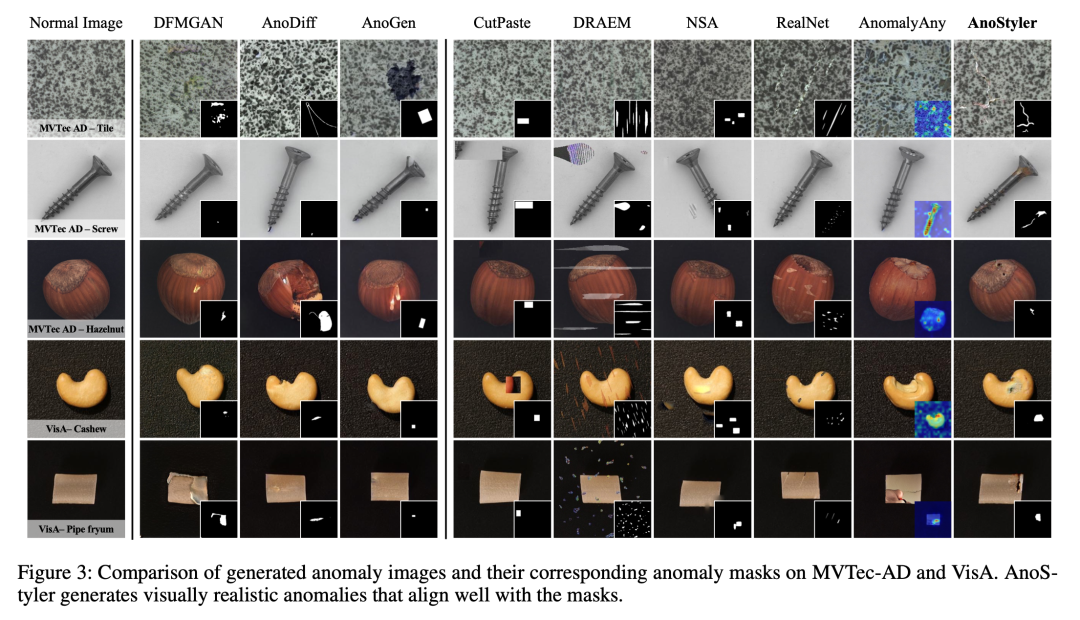
3.1 异常生成质量评估
论文使用两个指标评估生成质量:IS(Inception Score,衡量图像质量)和 IC-L(Intra-Cluster LPIPS,衡量多样性)。每个类别生成 1,000 张异常图像。
MVTec-AD 和 VisA 上的生成质量对比:
|
方法 |
类型 |
MVTec-AD IS |
MVTec-AD IC-L |
VisA IS |
VisA IC-L |
|---|---|---|---|---|---|
|
DFMGAN |
少样本 |
1.72 |
0.20 |
1.48 |
0.28 |
|
AnoDiff |
少样本 |
1.80 |
0.32 |
1.50 |
0.29 |
|
AnoGen |
少样本 |
1.77 |
0.27 |
1.40 |
0.22 |
|
CutPaste |
零样本 |
1.76 |
0.22 |
1.52 |
0.26 |
|
DRAEM |
零样本 |
1.76 |
0.25 |
1.50 |
0.25 |
|
NSA |
零样本 |
1.44 |
0.26 |
1.42 |
0.19 |
|
RealNet |
零样本 |
1.64 |
0.22 |
1.53 |
0.29 |
|
AnomalyAny |
零样本 |
2.02 |
0.33 |
1.41 |
0.19 |
| AnoStyler | 零样本 | 2.04 |
0.32 |
1.55 | 0.32 |
关键发现:
AnoStyler 在 MVTec-AD 上 IS 最高(2.04),IC-L 第二(0.32,与 AnoDiff 并列);在 VisA 上 IS 和 IC-L 均为最高(1.55 / 0.32);
作为零样本方法,AnoStyler 在生成质量上超越了所有需要真实异常图像的少样本方法(DFMGAN、AnoDiff、AnoGen)。
3.2 下游异常检测性能
更关键的评估是:生成的异常图像能否提升下游检测模型的性能?论文按照标准流程,每个类别生成 500 张异常图像训练 U-Net 检测模型,在测试集上评估。
MVTec-AD 下游检测结果(部分指标,%):
|
方法 |
类型 |
I-AUC |
I-AP |
I-F1 |
P-AUC |
P-F1 |
PRO |
|---|---|---|---|---|---|---|---|
|
DFMGAN |
少样本 |
87.2 |
94.8 |
94.7 |
90.0 |
62.1 |
76.3 |
|
AnoDiff |
少样本 |
99.2 |
99.7 |
98.7 |
99.1 |
76.3 |
94.0 |
|
AnoGen |
少样本 |
98.7 |
99.6 |
97.7 |
96.9 |
66.7 |
90.7 |
|
CutPaste |
零样本 |
89.8 |
92.1 |
89.8 |
88.2 |
50.7 |
76.4 |
|
DRAEM |
零样本 |
94.6 |
97.0 |
94.4 |
92.2 |
53.1 |
83.1 |
|
NSA |
零样本 |
93.0 |
95.6 |
91.6 |
92.0 |
52.5 |
82.2 |
|
RealNet |
零样本 |
95.2 |
97.0 |
95.3 |
94.0 |
57.6 |
85.2 |
|
AnomalyAny |
零样本 |
95.2 |
96.9 |
96.3 |
89.0 |
59.9 |
84.7 |
| AnoStyler | 零样本 | 98.0 | 99.0 | 97.0 | 94.4 | 60.7 | 88.3 |
AnoStyler 在 MVTec-AD 的零样本方法中各项指标均为最高,I-AUC 达到 98.0%,比第二名 AnomalyAny/RealNet 的 95.2% 高出 +2.8%;
PRO 达到 88.3%,比第二名 RealNet 的 85.2% 高出 +3.1%;
值得注意的是,AnoStyler 作为零样本方法,检测性能已接近少样本方法 AnoGen(98.7%)和 AnoDiff(99.2%),后两者需要额外的真实异常图像。
VisA 下游检测结果(部分指标,%):
|
方法 |
类型 |
I-AUC |
P-AUC |
PRO |
|---|---|---|---|---|
|
AnoDiff |
少样本 |
86.9 |
93.2 |
79.0 |
|
AnomalyAny |
零样本 |
88.9 |
90.4 |
84.6 |
| AnoStyler | 零样本 | 93.9 | 93.8 | 84.3 |
AnoStyler 在 VisA 上 I-AUC 达到 93.9%,比零样本第二名 AnomalyAny 高出 +5.0%,甚至超越少样本方法 AnoDiff(86.9%)。
四、消融实验:三个损失函数各贡献了什么?
———————————————————————————————————————————
论文在 MVTec-AD 上逐步添加三个关键损失组件,评估对生成质量和下游检测的影响:
|
配置 |
L_gdir |
L_pdir |
L_mclip |
IS |
IC-L |
I-AUC |
P-AUC |
|---|---|---|---|---|---|---|---|
|
(a) 基线 |
— |
— |
— |
1.70 |
0.25 |
88.2 |
85.7 |
|
(b) +L_gdir |
✓ |
— |
— |
1.86 |
0.29 |
95.2 |
92.5 |
|
(c) +L_pdir |
✓ |
✓ |
— |
1.96 |
0.30 |
96.7 |
93.2 |
|
(d) 完整 |
✓ |
✓ |
✓ |
2.04 | 0.32 | 98.0 | 94.4 |
基线(仅内容损失+全变差损失)生成的异常缺乏真实感,I-AUC 仅 88.2%;
加入全局方向对齐 L_gdir 后 I-AUC 跳升至 95.2%(+7.0%),说明 CLIP 语义引导是核心驱动力;
加入 patch 级方向对齐 L_pdir 进一步提升至 96.7%(+1.5%),细化了局部异常的语义一致性;
加入掩码 CLIP 损失 L_mclip 后达到 98.0%(+1.3%),强化了异常区域的语义聚焦。
计算效率
|
指标 |
AnoStyler |
AnomalyAny |
|---|---|---|
|
总参数量 |
263M |
>1B |
|
单张生成 TFLOPs |
9.5 |
22.8 |
AnoStyler 参数量仅 263M(其中 U-Net 仅 0.61M,SAM 91M,CLIP 编码器 151M,内容损失特征提取器 20M),计算量不到 AnomalyAny 的一半。
五、总结与思考
———————————————————————————————————————————
论文贡献
AnoStyler 将异常图像生成重新定义为文本驱动的局部风格迁移,通过三个设计解决了现有方法的三个痛点:Meta-Shape Priors 提供了与类别无关的多样化掩码生成方案;双类别文本提示 + CLIP 损失引导实现了语义对齐的异常风格化;轻量 U-Net 架构将参数量控制在 263M,计算量仅 9.5 TFLOPs。在 MVTec-AD 和 VisA 上,AnoStyler 作为零样本方法在生成质量和下游检测性能上均超越现有零样本方法,接近少样本方法。
几点思考
1. "风格迁移"视角的价值
将异常生成定义为风格迁移是本文最有启发性的设计选择。相比扩散模型通过噪声去噪过程生成异常,风格迁移天然保持了原图的整体结构,只改变局部的视觉属性,这与工业缺陷的实际特性高度吻合——缺陷通常是局部纹理/颜色/形状的偏离,而非整体结构的改变。
2. 文本提示的灵活性与局限
AnoStyler 依赖类别标签 [c] 和缺陷类型 [d] 的文本输入。论文在 MVTec-AD 上使用了数据集自带的缺陷类型标注,但在 VisA 上所有缺陷统一标记为"defect"。这意味着当缺乏具体缺陷类型信息时,方法仍然可用但可能损失一定的语义精度。实际部署中,缺陷类型的文本描述需要领域知识,这是一个需要权衡的人工成本。
3. 与检测方法的协同空间
AnoStyler 生成的异常图像用于训练下游 U-Net 检测器,但生成和检测是分离的两个阶段。如果将 AnoStyler 与无监督检测方法(如 PatchCore、FoundAD 等)结合,用合成异常做数据增强微调,可能进一步提升检测性能。这种"生成+检测"的流水线在工业部署中有实际价值。
4. 计算效率的实际意义
263M 参数和 9.5 TFLOPs 的生成成本在工业场景中很友好。论文使用单张 RTX 2080Ti(11GB 显存)即可完成所有实验,这意味着 AnoStyler 不需要高端 GPU 即可部署,降低了工业应用的硬件门槛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 22
22 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)