一文搞懂hadoop的HDFS
Hadoop介绍
什么是Hadoop
Hadoop是由Apache基金会所开发的分布式系统基础架构,旨在解决海量数据存储和计算分析问题。狭义上来说,Hadoop是指Apache Hadoop开源框架,包含以下三种核心组件:
- Hadoop HDFS(Hadoop Distributed File System):分布式文件存储系统,解决海量数据存储问题。
- Hadoop Yarn:集群资源管理和任务调度框架,解决资源任务调度问题。
- Hadoop MapReduce:分布式计算框架,解决海量数据计算问题。
广义上来说,Hadoop通常是指围绕Hadoop打造的大数据生态圈,部分技术栈如下图: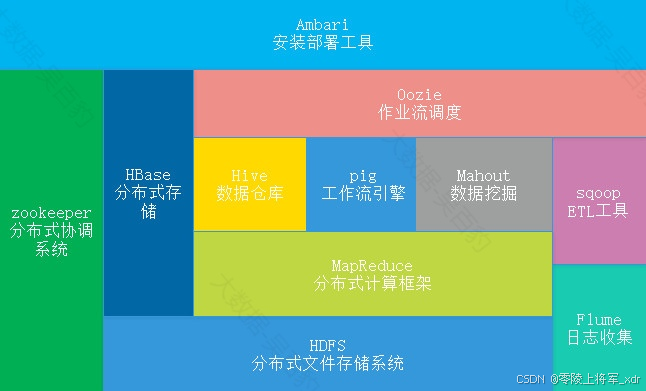
- zookeeper:分布式协调组件。
- HDFS:分布式文件系统。
- MapReduce:分布式计算框架。
- Hive:分布式数据仓库。
- HBase:分布式数据库。
- Flume:日志采集框架。
- Sqoop:数据导入/导出工具。
- pig:工作流引擎。
- Mahout:机器学习算法库。
- oozie:作业流调度工具。
- Ambari:大数据集群管理平台。
Hadoop官网:https://hadoop.apache.org/
大数据技术生态体系
Hadoop发展历史
Hadoop最初是由Doug Cutting和Mike Cafarella于2002年左右创建的,最早起源于Nutch,其最初的目标是构建一个能够处理大规模数据集的分布式文件处理系统。后期,Doug Cutting以Google的GFS(Google File System)和MapReduce为基础,开发了Hadoop Distributed File System(HDFS)和Hadoop MapReduce。2006年,Hadoop成为Apache软件基金会的顶级项目,开始吸引了越来越多的开发者和用户。以下是Hadoop发展历史中的一些重要时间点,了解即可。
- 2002年10月,Doug Cutting和Mike Cafarella创建了开源网页爬虫项目Nutch。
- 2003年10月,Google发表Google File System论文。
- 2004年7月,Doug Cutting和Mike Cafarella在Nutch中实现了类似GFS的功能,即后来HDFS的前身。
- 2004年10月,Google发表了MapReduce论文。
- 2005年2月,Mike Cafarella在Nutch中实现了MapReduce的最初版本。
- 2005年12月,开源搜索项目Nutch移植到新框架,使用MapReduce和HDFS在20个节点稳定运行。
- 2006年1月,Doug Cutting加入雅虎,Yahoo!提供一个专门的团队和资源将Hadoop发展成一个可在网络上运行的系统。
- 2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
- 2006年3月,Yahoo!建设了第一个Hadoop集群用于开发。
- 2006年4月,第一个Apache Hadoop发布。
- 2006年11月,Google发表了Bigtable论文,激起了Hbase的创建。
- 2007年10月,第一个Hadoop用户组会议召开,社区贡献开始急剧上升。
- 2007年,百度开始使用Hadoop做离线处理。
- 2007年,中国移动开始在“大云”研究中使用Hadoop技术。
- 2008年,淘宝开始投入研究基于Hadoop的系统——云梯,并将其用于处理电子商务相关数据。
- 2008年1月,Hadoop成为Apache顶级项目。
- 2008年2月,Yahoo!运行了世界上最大的Hadoop应用,宣布其搜索引擎产品部署在一个拥有1万个内核的Hadoop集群上。
- 2008年4月,在900个节点上运行1TB排序测试集仅需209秒,成为世界最快。
- 2008年8月,第一个Hadoop商业化公司Cloudera成立。
- 2009 年3月,Cloudera推出世界上首个Hadoop发行版——CDH(Cloudera’s Distribution including Apache Hadoop)平台,完全由开放源码软件组成。
- 2009年6月,Cloudera的工程师Tom White编写的《Hadoop权威指南》初版出版,后被誉为Hadoop圣经。
- 2009年7月 ,Hadoop Core项目更名为Hadoop Common;
- 2009年7月 ,MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
- 2009年8月,Hadoop创始人Doug Cutting加入Cloudera担任首席架构师。
- 2009年10月,首届Hadoop World大会在纽约召开。
- 2010年5月,IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
- 2011年3月,Apache Hadoop获得Media Guardian Innovation Awards媒体卫报创新奖
- 2012年3月,企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。
- 2012年8月,另外一个重要的企业适用功能YARN成为Hadoop子项目。
- 2014年2月,Spark逐渐代替MapReduce成为Hadoop的缺省执行引擎,并成为Apache基金会顶级项目。
- 2017年12月,Hadoop 3.0.0版本发布,标志着Hadoop的持续发展和创新。
截止到2024年初,Hadoop最新版本为3.3.6版本,整个Hadoop发行版本中经历了Haoop1.x、2.x、3.x系列版本。目前,Hadoop1.x版本已经被淘汰,Hadoop2.x版本相较于1.x版本引入了Yarn平台,Hadoop3.x版本相较于2.x版本做了优化升级,目前企业中使用主流hadoop版本为hadoop3.x版本。
此外,Hadoop目前发行版本分为开源社区版和商业版。社区版由Apache软件基金会进行维护,商业版Hadoop则是由第三方商业公司在社区版的基础上做了一些修改、整合,并经过各个服务组件的兼容性测试后发布的版本,其中一些著名的商业版包括Cloudera的CDH、Hortonworks的HDP,2018年,Cloudea收购Hortonworks公司。
ClouderaManager的CDH平台:
Ambari的HDP平台:![[图片]](https://i-blog.csdnimg.cn/direct/76d0989b3e1e4ff383ce302dc823eb34.png)
Hadoop优势特点
Hadoop具备如下优势特点:
- 低成本
Hadoop可以由多台廉价普通机器组成,支持TB和PB级别数据存储,并不需要运行在昂贵且高可靠性的硬件上。 - 高可靠、容错性
HDFS中数据存储有多副本支持数据高可靠性,即使一些副本出现故障也能保障数据可使用。MapReduce计算过程中任务失败,可以自动进行任务重新分配进行任务重试。此外,HDFS和Yarn都支持高可用配置,当主节点挂掉时,可以自动选主切换,保证集群可靠性。 - 高扩展性
Hadoop集群可以扩展到上千个节点以支持数据存储和计算,节点多支持数据量大、支持更大并行度的并行计算。 - 高效性
Hadoop可以并行在节点之间动态移动数据,保证各个节点数据动态平衡;基于MapReduce进行数据处理计算时,可以并行处理数据,效率极高。
总之,Hadoop具备高可靠、高容错、高扩展、高效性这些优势在互联网领域中已经得到广泛运用。
HDFS架构核心
HDFS简介
HDFS(Hadoop Distributed File System) 是 Apache Hadoop 项目的一个子项目,设计目的是用于存储海量(例如:TB和PB)文件数据,支持高吞吐读写文件并且高度容错。HDFS将多台普通廉价机器组成分布式集群形成分布式文件系统,提供统一的访问接口,用户可以像访问普通文件系统一样来使用HDFS访问文件。
HDFS有如下特点:
- HDFS适合处理大规模数据,如:TB和PB,可以处理百万规模以上的文件数量,使用场景是一次写入、多次读取场景。
- HDFS将文件线性按字节切分成多个block块进行存储,每个block块默认128M。
- 每个block块默认有3个副本,提高容错性,如果一个副本丢失不可用,后续可以自动恢复。
- HDFS适合大文件写入,不适合大量小文件写入,因为小文件多NameNode要使用更多内存来维护存储文件目录和block信息。此外,读取大量小文件时,文件寻址时间要大于文件读取时间,违反HDFS设计目标。
- HDFS不支持并发写入数据,一个文件只能有一个写,不能多个线程同时写。
- HDFS数据写入后不支持修改,只支持append追加。
HDFS架构
HDFS是一个主从(Master/Slaves)架构,由一个NameNode和一些DataNode组成,下图是HDFS架构: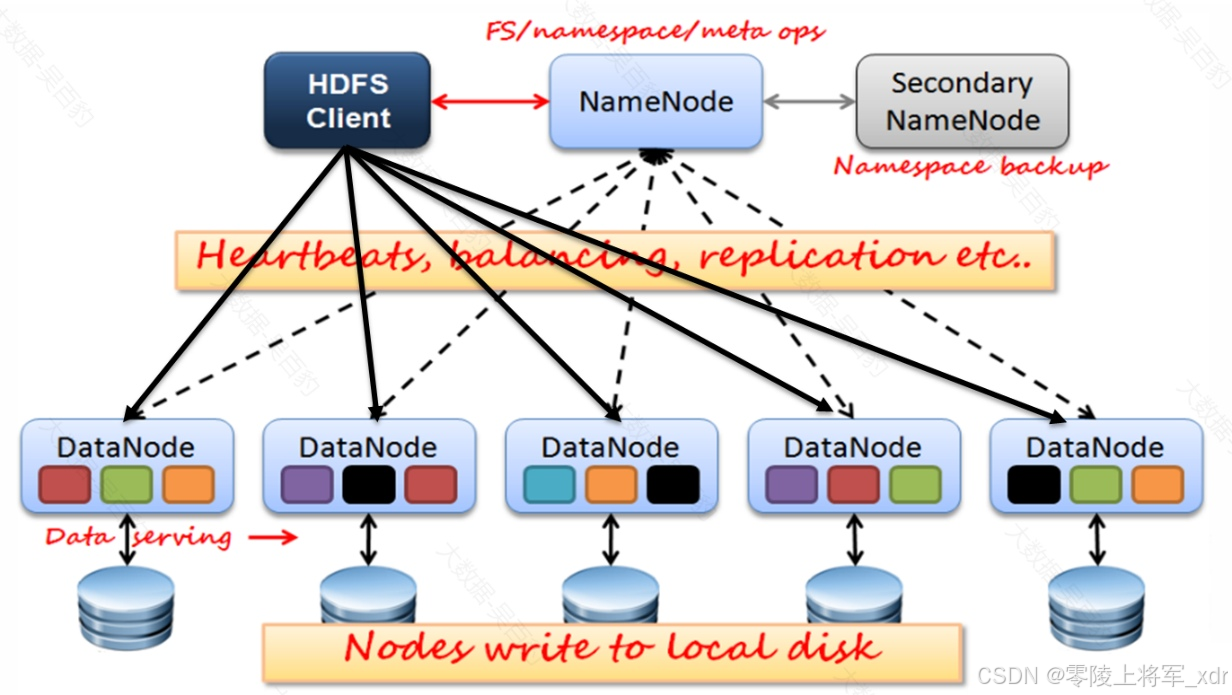
以上架构中包含NameNode、SecondaryNameNode、DataNode 、HDFS Client各角色,下面对各个角色作用进行介绍。
NameNode
NameNode就是主从架构中的Master,是HDFS中的管理者。HDFS中数据文件分布式存储在各个DataNode节点上,NameNode维护和管理文件系统元数据(空间目录树结构、文件、Block信息、访问权限),随着存储文件的增多,NameNode上存储的信息越来越多,NameNode主要通过两个组件实现元数据管理:fsimage(命名空间镜像文件)和editslog(编辑日志)。
- fsimage:HDFS文件系统元数据的镜像文件,其中包含了HDFS文件系统的所有目录和文件相关信息元数据。
- edits:用户操作HDFS的编辑日志文件,存放HDFS文件系统的所有操作事件,文件的所有写操作会被记录到Edits文件中。
fsimage中存储了当前HDFS中文件属性(文件名称、路径、权限关系、副本数、修改、访问时间等),当HDFS启动后,首先会将磁盘中的fsimage加载到内存中,这样可以保证用户HDFS的高效和低延迟。需要注意,fsimage中不记录每个block所在的DataNode信息,这些信息在每次HDFS启动时从DataNode重建,之后DataNode会周期性的通过心跳向NameNode报告block信息。
在NameNode运行期间,客户端对HDFS的操作(文件或目录的创建、重命名、删除)日志都会保存在edits文件中,edits文件保存在磁盘中。当NameNode重启时,会将fsimage内容映射到内存中,然后再一条条执行edits文件中的操作就可以恢复到NameNode重启前的状态,做到不丢失数据。
总结,NameNode作用如下:
- 完全基于内存存储文件元数据、目录结构、文件block的映射信息。
- 提供文件元数据持久化/管理方案。
- 提供副本放置策略。
- 处理客户端读写请求。
SecondaryNameNode
随着操作HDFS的数据变多,久而久之就会造成edits文件变的很大,如果namenode重启后再一条条执行edits日志恢复状态就需要很长时间,导致重启速度慢,所以在NameNode运行的时候就需要将editslog和fsimage定期合并。这个合并操作就由SecondaryNameNode负责。
所以SecondaryNameNode作用就是辅助NameNode定期合并fsimage和editslog,并将合并后的fsimage推送给NameNode。
DataNode
DataNode是主从架构中的Slave,DataNode存储文件block块,Block在DataNode上以文件形式存储在磁盘上,包括2个文件,一个是数据文件本身,一个是元数据(包括block长度、block校验和、时间戳)。当DataNode启动后会向NameNode进行注册,并汇报block列表信息,后续会周期性(参数dfs.blockreport.intervalMsec决定,默认6小时)向NameNode上报所有的块信息。同时,DataNode会每隔3秒与NameNode保持心跳,如果超过10分钟NameNode没有收到某个DataNode的心跳,则认为该节点不可用。
总结,DataNode作用如下:
- 基于本地磁盘存储block数据块。
- 保存block的校验和数据保证block的可靠性。
- 与NameNode保持心跳并汇报block列表信息。
Client
Client是操作HDFS的客户端,作用如下:
- 与NameNode交互,获取文件block位置信息。
- 与DataNode交互,读写文件block数据。
- 文件上传时,负责文件切分成block并上传。
- 可以通过client访问HDFS进行文件操作或管理HDFS。
fsimage和editslog合并
HDFS 中NameNode管理通过fsimage和editslog来管理集群元数据,SecondaryNameNode会负责定期合并fsimage和editslog,以保证HDFS集群重启后快速恢复到之前状态。
合并流程
![[图片]](https://i-blog.csdnimg.cn/direct/ee20bc34e6f8438fad0f38e213cfb5f8.png)
- 当HDFS集群首次启动会在NameNode上创建空的fsimage,对HDFS的操作会记录到edits文件中。
- 当开始进行editslog和fsimage合并时,SecondaryNameNode请求namenode生成新的editslog文件并向其中写日志。
- SecondaryNameNode通过HTTP GET的方式从NameNode下载fsimage和edits文件到本地。
- SecondaryNameNode将fsimage加载到自己的内存,并根据editslog更新内存中的fsimage信息,然后将更新完毕之后的fsimage写到磁盘上。
- SecondaryNameNode通过HTTP PUT将新的fsimage文件发送到NameNode,NameNode将该文件保存为.ckpt的临时文件备用。
- NameNode重命名该临时文件并准备使用,此时NameNode拥有一个新的fsimage文件和一个新的很小的editslog文件(可能不是空的,因为在SecondaryNameNode合并期间可能对元数据进行了读写操作)。
- 后续SecondaryNameNode会按照以上步骤周期性进行editslog和fsimage的合并。
合并时机
默认情况下,SecondaryNameNode每隔1小时执行edits和fsimage合并,通过参数“dfs.namenode.checkpoint.period”进行控制,默认该参数为3600s,即:1小时。
HDFS还会每分钟进行NameNode操作事务数量检查,如果editslog存储的事务(即操作数)到了1000000个也会进行editslog和fsimage的合并。每分钟检查操作事务参数通过dfs.namenode.checkpoint.check.period设置,默认60s,editslog操作数控制参数为dfs.namenode.checkpoint.txns,默认1000000。
安全模式
安全模式工作流程
HDFS启动后的大致工作流程:
- 启动NameNode,NameNode加载fsimage到内存,对内存数据执行edits log日志中的事务操作。
- 文件系统元数据内存镜像加载完毕,进行fsimage和edits log日志的合并,并创建新的fsimage文件和一个空的edits log日志文件。
- NameNode等待DataNode上传block列表信息,直到副本数满足最小副本条件,这个过程NameNode处于安全模式,最小副本条件指整个文件系统中有99.9%的block达到了最小副本数(默认值是1,可设置)。
- 当满足了最小副本条件,再过30秒,NameNode就会退出安全模式。
在NameNode安全模式(safemode)下,操作HDFS有如下特点:
- 对文件系统元数据进行只读操作。
- 当文件的所有block信息具备的情况下,对文件进行只读操作。不允许进行文件修改(写,删除或重命名文件)。
注意事项
NameNode不会持久化block位置信息,DataNode保有各自存储的block列表信息。正常操作时,NameNode在内存中有一个blocks位置的映射信息(所有文件的所有文件块的位置映射信息)。
NameNode在安全模式,DataNode需要上传block列表信息到NameNode。
在安全模式NameNode不会要求DataNode复制或删除block。
新格式化的HDFS不进入安全模式,因为DataNode压根就没有block。
配置信息
| 属性名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| dfs.namenode.replication.min | int | 1 | 写入文件成功的最小副本数 |
| dfs.namenode.replication.min | float | 0.999 | 系统中block达到了最小副本数的比例,之后NameNode会退出安全模式。 |
| dfs.namenode.safemode.extension | int | 30000ms | 系统满足了最小副本条件后再过多久退出安全模式 |
命令操作
通过以下命令查看namenode是否处于安全模式:
hdfs dfsadmin -safemode get
HDFS的前端webUI页面也可以查看NameNode是否处于安全模式,有时候我们希望等待安全模式退出,之后进行文件的读写操作,尤其是在脚本中,此时可以执行命令:
hdfs dfsadmin -safemode wait
当然,以上这个命令不会经常使用,更多的是集群正常启动后会自动退出安全模式。管理员有权在任何时间让namenode进入或退出安全模式,进入安全模式命令如下:
hdfs dfsadmin -safemode enter
以上命令可以让namenode一直处于安全模式,离开安全模式命令如下:
hdfs dfsadmin -safemode leave
Block及副本存放策略
Block块
HDFS存储文件数据时会将文件切分成block,block大小由参数dfs.blocksize决定,在Hadoop1.x中block大小默认为64M ,在Hadoop2.x/3.x中每个block默认大小为128M。
HDFS中块大小不能设置太大,也不能设置太小。如果块设置太大会导致读取block时从磁盘传输数据的时间明显大于寻址时间,导致程序处理数据时变的非常慢;如果块设置过小,大量的块会占用NameNode大量内存来存储元数据,而NameNode内存有限,另一方面,文件块过小会导致寻址时间增大,导致程序一直在找block的开始位置。
在HDFS中平均查找block的寻址时间为10ms,经过测试,block文件寻址时间为block传输时间的1%时机器性能最佳,即block传输时间为1s(10ms/0.01=1000ms=1s)时机器性能最佳,目前磁盘的传输速率普遍为100MB/s,计算出最佳block大小为100M(100MB/s*1s=100MB),由于在计算机领域,计算机使用的是二进制系统,而2的幂次方在二进制系统中具有简单而高效的表示方式,使用这些大小的数据更为方便,如:2的7次方是128,2的8次方是256,以此类推。所以block没有设置为100M,而是设置为了128M。所以HDFS中块大小的设置主要取决于磁盘的传输速率,在实际生产中,如果磁盘传输速率为200MB/s时,一般设置block的大小为256M,如果磁盘传输速率为400MB/s时,一般设置block大小为512M。
此外,需要注意如果一个文件本身是1KB,上传到HDFS中就对应1个Block,该Block大小实际占用1KB,即:Block大小默认128M表示存储一份数据的分片上限大小,一个文件大于128M会切分成多个block进行存储。
Block副本放置策略
HDFS中每个block块有3副本,由参数dfs.replication决定。三个副本会按照副本放置策略进行存储,如下图所示就是一个block有3副本存储情况。![[图片]](https://i-blog.csdnimg.cn/direct/3c05b01bb18d4d1ba6b5c4a29cb1239c.png)
第一个副本:放置在上传文件的DataNode,也就是Client所在节点上;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在与第一个副本不同的机架的节点上。
第三个副本:与第二个副本相同机架的随机节点。
更多副本:随机节点存放。
读写流程
HDFS写文件流程
![[图片]](https://i-blog.csdnimg.cn/direct/4b3c0ff8d08c45fc9563f421e4c25a73.png)
- 客户端会创建DistributedFileSystem对象,DistributedFileSystem会发起对namenode的一个RPC连接,请求创建一个文件,不包含关于block块的请求。namenode会执行各种各样的检查,确保要创建的文件不存在,并且客户端有创建文件的权限。如果检查通过,namenode会创建一个文件(在edits中,同时更新内存状态),否则创建失败,客户端抛异常IOException。
- NN在文件创建后,返回给HDFS Client可以开始上传文件块。
- DistributedFileSystem返回一个FSDataOutputStream对象给客户端用于写数据。FSDataOutputStream封装了一个DFSOutputStream对象负责客户端跟datanode以及namenode的通信。
- 客户端中的FSDataOutputStream对象将数据切分为小的packet数据包(64kb,core-default.xml:file.client-write-packet-size默认值65536),并写入到一个内部队列(“数据队列”)。DataStreamer会读取其中内容,并请求namenode返回一个datanode列表来存储当前block副本。列表中的datanode会形成管线,DataStreamer将数据包发送给管线中的第一个datanode,第一个datanode将接收到的数据发送给第二个datanode,第二个发送给第三个,依次类推。
- FSDataOutputStream维护着一个数据包的队列,这的数据包是需要写入到datanode中的,该队列称为确认队列。当一个数据包在管线中所有datanode中写入完成,就从ack队列中移除该数据包。如果在数据写入期间datanode发生故障,则执行以下操作
- 当block传输完成,DN会向NN汇报block信息,同时Client继续传输下一个block,如果有多个block,则会反复从步骤4开始执行。
- 当客户端完成了数据的传输,调用数据流的close方法。该方法将数据队列中的剩余数据包写到datanode的管线并等待管线的确认。
- 客户端收到管线中所有正常datanode的确认消息后,通知namenode文件写入成功。
HDFS读文件流程
![[图片]](https://i-blog.csdnimg.cn/direct/9dd23010f40f46099f6d53b6d812d004.png)
- 客户端通过FileSystem对象的open方法打开希望读取的文件,DistributedFileSystem对象通过RPC调用namenode,以确保文件起始位置。对于每个block,namenode返回存有该副本的datanode地址。这些datanode根据它们与客户端的距离来排序。如果客户端本身就是一个datanode,并保存有相应block一个副本,会从本地读取这个block数据。
- DistributedFileSystem返回一个FSDataInputStream对象给客户端读取数据。该对象管理着datanode和namenode的I/O,用于给客户端使用。客户端对这个输入调用read方法,存储着文件起始几个block的datanode地址的DFSInputStream连接距离最近的datanode。通过对数据流反复调用read方法,可以将数据从datnaode传输到客户端。到达block的末端时,DFSInputSream关闭与该datanode的连接,然后寻找下一个block的最佳datanode。客户端只需要读取连续的流,并且对于客户端都是透明的。
- 客户端从流中读取数据时,block是按照打开DFSInputStream与datanode新建连接的顺序读取的。它也会根据需要询问namenode来检索下一批数据块的datanode的位置。一旦客户端完成读取,就close掉FSDataInputStream的输入流。
- 在读取数据的时候如果DFSInputStream在与datanode通信时遇到错误,会尝试从这个块的一个最近邻datanode读取数据。同时也记住故障datanode,保证以后不会反复读取该节点上后续的block。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现有损坏的块,DFSInputStream会尝试从其他datanode读取其副本并通知namenode。
- Client下载完block后会验证DN中的MD5,保证块数据的完整性。
HDFS集群搭建与操作
节点基础环境准备
搭建真正分布式HDFS集群至少需要3台Linux节点,这里准备5台Linux节点(这里我们使用的是VMWare虚拟机安装的centos7,也可以直接使用云服务器),节点名称和ip信息如下:
| 节点IP | 节点名称 |
|---|---|
| 192.168.179.4 | node1 |
| 192.168.179.5 | node2 |
| 192.168.179.6 | node3 |
| 192.168.179.7 | node4 |
| 192.168.179.8 | node5 |
这里默认已经创建好以上各个节点,并且每个节点分配资源为4核2G内存,建议每台节点至少给到2核2G,否则可能一些组件不能正常运行问题。下面对这5个节点进行基础配置。
配置各个节点的ip
启动每台节点,在对应的节点路径“/etc/sysconfig/network-scripts”下配置ifg-ens33文件配置IP(注意,不同机器可能此文件名称不同,一般以ifcfg-xxx命名),以配置ip 192.168.179.4为例,ifcfg-ens33配置内容如下:
TYPE=Ethernet
BOOTPROTO=static #使用static配置
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
ONBOOT=yes #开机启用本配置
IPADDR=192.168.179.4 #静态IP
GATEWAY=192.168.179.2 #默认网关
NETMASK=255.255.255.0 #子网掩码
DNS1=192.168.179.2 #DNS配置 可以与默认网关相同
以上其他节点配置只需要修改对应的ip即可,配置完成后,在每个节点上执行如下命令重启网络服务:
systemctl restart network.service
配置主机名
在每台节点上修改/etc/hostname,配置对应的主机名称,参照节点IP与节点名称对照表分别为:node1、node2、node3、node4、node5。配置完成后需要重启各个节点,才能正常显示各个主机名。
关于Centos hostname配置有如下几点建议:
- hostname只允许包含ascii字符里的数字0-9,字母a-zA-Z,连字符-和.,其他都不允许。例如,不允许出现其他标点符号,不允许空格,不允许下划线,不允许中文字符。
- hostanme开头和结尾字符不允许是连字符。
- hostanme强烈建议不要用数字开头,尽管这一条不是强制的。
- hostanme建议用小写字母而不用大写字母。
关闭防火墙
执行如下命令确定各个节点上的防火墙开启情况,需要将各个节点上的防火墙关闭:
#检查防火墙状态
firewall-cmd --state
#临时关闭防火墙(重新开机后又会自动启动)
systemctl stop firewalld 或者systemctl stop firewalld.service
#设置开机不启动防火墙
systemctl disable firewalld
关闭SELinux
SELinux就是Security-Enhanced Linux的简称,安全加强的linux。传统的linux权限是对文件和目录的owner, group和other的rwx进行控制,而SELinux采用的是委任式访问控制,也就是控制一个进程对具体文件系统上面的文件和目录的访问,SELinux规定了很多的规则,来决定哪个进程可以访问哪些文件和目录。虽然SELinux很好用,但是在多数情况我们还是将其关闭,因为在不了解其机制的情况下使用SELinux会导致软件安装或者应用部署失败。
在每台节点/etc/selinux/config中将SELINUX=enforcing改成SELINUX=disabled即可。
配置阿里云yum源
后续为了方便在Linux节点上安装各个软件,我们将yum源改成国内阿里云yum源,这样下载软件速度快一些,每个节点具体操作按照以下步骤进行:
#安装wget,wget是linux最常用的下载命令(有些系统默认安装,可忽略)
yum -y install wget
#备份当前的yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
#下载阿里云的yum源配置
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#清除原来文件缓存,构建新加入的repo结尾文件的缓存
yum clean all
yum makecache
配置完成后,可以在每台节点上安装“vim”命令,方便后续操作:
#在各个节点上安装 vim命令
yum -y install vim
设置Linux 系统显示中文/英文
#查看当前系统语言
echo $LANG
#显示结果如下,说明默认支持显示英文
en_US.UTF-8
#临时修改系统语言为中文,重启节点后恢复英文
LANG="zh_CN.UTF-8"
#如果想要永久修改系统默认语言为中文,需要创建/修改/etc/locale.conf文件,写入以下内容,设置完成后需要重启各节点。
LANG="zh_CN.UTF-8"
设置自动更新时间
后续基于Linux各个节点搭建HDFS时,需要各节点的时间同步,可以通过设置各个节点自动更新时间来保证各个节点时间一致,具体按照以下操作来执行:
- 修改本地时区及ntp服务
yum -y install ntp
rm -rf /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
/usr/sbin/ntpdate -u pool.ntp.org
- 自动同步时间
设置定时任务,每10分钟同步一次,配置/etc/crontab文件,实现自动执行任务。建议直接crontab -e 来写入定时任务。使用crontab -l 查看当前用户定时任务。
#各个节点执行 crontab -e 写入以下内容
*/10 * * * * /usr/sbin/ntpdate -u pool.ntp.org >/dev/null 2>&1
#重启定时任务
service crond restart
#查看日期
date
设置各个节点之间的ip映射
每个节点都有自己的IP和主机名,各个节点默认进行文件传递或通信时需要使用对应的ip进行通信,后续为了方便各个节点之间的通信和文件传递,可以配置各个节点名称与ip之间的映射,节点之间通信时可以直接写对应的主机名称,不必写复杂的ip。每台节点具体操作按照以下操作进行。
进入每台节点的/etc/hosts下,修改hosts文件,vim /etc/hosts:
#在文件后面追加以下内容
192.168.179.4 node1
192.168.179.5 node2
192.168.179.6 node3
192.168.179.7 node4
192.168.179.8 node5
各个节点配置完成后,可以使用ping命令互相测试使用节点名称是否可以正常通信。
[root@node5 ~]# ping node1
PING node1 (192.168.179.4) 56(84) bytes of data.
64 bytes from node1 (192.168.179.4): icmp_seq=1 ttl=64 time=0.892 ms
64 bytes from node1 (192.168.179.4): icmp_seq=2 ttl=64 time=0.415 ms
... ...
配置节点之间免密访问
后续搭建HDFS集群时需要Linux各个节点之间免密,节点两两免秘钥的根本原理如下:假设A节点需要免秘钥登录B节点,只要B节点上有A节点的公钥,那么A节点就可以免密登录当前B节点。具体操作步骤如下:
- 安装ssh客户端
需要在每台节点上安装ssh客户端,否则,不能使用ssh命令(最小化安装Liunx,默认没有安装ssh客户端),这里在Centos7系统中默认已经安装,此步骤可以省略:
yum -y install openssh-clients
- 创建.ssh目录
在每台节点执行如下命令,在每台节点的“~”目录下,创建.ssh目录,注意,不要手动创建这个目录,因为有权限问题。
cd ~
ssh localhost
#这里会需要输入节点密码#
exit
- 配置各节点向一台节点通信免密
在每台节点上执行如下命令,给当前节点创建公钥和私钥:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
将node1、node2、node3、node4、node5的公钥copy到node1上,这样这五台节点都可以免密登录到node1。命令如下:
#在node1上执行如下命令,需要输入密码ssh-copy-id node1 #会在当前~/.ssh目录下生成authorized_keys文件,文件中存放当前node1的公钥#
#在node2上执行如下命令,需要输入密码ssh-copy-id node1 #会将node2的公钥追加到node1节点的authorized_keys文件中
#在node3上执行如下命令,需要输入密码ssh-copy-id node1 #会将node3的公钥追加到node1节点的authorized_keys文件中
#在node4上执行如下命令,需要输入密码ssh-copy-id node1 #会将node4的公钥追加到node1节点的authorized_keys文件中
#在node5上执行如下命令,需要输入密码ssh-copy-id node1 #会将node5的公钥追加到node1节点的authorized_keys文件中
- 各节点免密
将node1节点上/.ssh/authorized_keys拷贝到node2、node3、node4、node5各节点的/.ssh/目录下,执行如下命令:
scp ~/.ssh/authorized_keys node2:`pwd`
scp ~/.ssh/authorized_keys node3:`pwd`
scp ~/.ssh/authorized_keys node4:`pwd`
scp ~/.ssh/authorized_keys node5:`pwd
以上node1向各个节点发送文件时需要输入密码,经过以上步骤,节点两两免密完成。
Hadoop集群运行模式
可以参考Hadoop官网进行Hadoop集群搭建,目前Hadoop集群搭建有三种模式:
- 本地模式:单机运行,只能单机测试MapReduce运行任务,生产和测试都不会使用。
- 伪分布式模式:单机运行,一台节点部署所有Hadoop角色,模拟分布式集群环境,具备Hadoop集群所有功能,生产和测试一般不会使用。
- 完全分布式模式:多台服务器部署Hadoop集群,各个角色分布到不同节点上执行,生产和测试环境中经常使用。
HDFS伪分布式集群搭建
安装JDK
按照以下步骤在node1节点上安装JDK8。
- 在node1节点创建/software目录,上传并安装jdk8 rpm包
rpm -ivh /software/jdk-8u181-linux-x64.rpm
以上命令执行完成后,会在每台节点的/user/java下安装jdk8。
2. 配置jdk环境变量
在node1节点上配置jdk的环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
以上配置完成后,最后执行“source /etc/profile”使配置生效。
HDFS伪分布式集群搭建
这里我们在 node1节点上进行HDFS伪分布式集群搭建,按照如下步骤进行搭建即可。
- 下载安装包并解压
我们安装Hadoop3.3.6版本,搭建HDFS集群前,首先需要在官网下载安装包,地址如下:https://hadoop.apache.org/releases.html。下载完成安装包后,上传到node1节点的/software目录下并解压到opt目录下。
#将下载好的hadoop安装包上传到node1节点上
[root@node1 ~]# ls /software/
hadoop-3.3.6.tar.gz
#将安装包解压到/opt目录下
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./hadoop-3.3.6.tar.gz -C /opt
解压之后可以看到Hadoop安装包内容如下:
[root@node1 hadoop-3.3.6]# ll
bin
etc
include
lib
libexec
LICENSE-binary
licenses-binary
LICENSE.txt
logs
NOTICE-binary
NOTICE.txt
README.txt
sbin
share
以上Hadoop解压文件重要目录解释如下:
- bin目录:Hadoop最基本的管理脚本和使用脚本的目录,用户可以直接使用这些脚本管理和使用Hadoop。
- etc目录:Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、works等。
- include:对外提供的编程库头文件,这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
- lib目录:lib目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
- sbin目录:Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
- share目录:存放Hadoop的依赖jar包、文档、和官方案例,对HDFS 操作依赖的jar包都在这里。
- 在node1节点上配置Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile
- 配置hadoop-env.sh
启动伪分布式HDFS集群时会判断$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件中是否配置JAVA_HOME,所以需要在hadoop-env.sh文件加入以下配置(大概在54行有默认注释配置的JAVA_HOME):
#vim /software/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
- 配置core-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改core-site.xml文件,指定HDFS集群数据访问地址及集群数据存放路径。
#vim /software/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><!-- 指定 Hadoop 数据存放的路径 --><property><name>hadoop.tmp.dir</name><value>/opt/data/local_hadoop</value></property></configuration>
- 配置hdfs-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改hdfs-site.xml文件,指定NameNode和SecondaryNameNode节点和端口。
#vim /software/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration><!-- 指定block副本数--><property><name>dfs.replication</name><value>1</value></property><!-- NameNode WebUI访问地址--><property><name>dfs.namenode.http-address</name><value>node1:9870</value></property><!-- SecondaryNameNode WebUI访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>node1:9868</value></property></configuration>
- 配置workers指定DataNode节点
进入 $HADOOP_HOME/etc/hadoop路径下,修改workers配置文件,加入以下内容:
#vim /software/hadoop-3.3.6/etc/hadoop/workers
node1
- 配置start-dfs.sh&stop-dfs.sh
进入 $HADOOP_HOME/sbin路径下,在start-dfs.sh和stop-dfs.sh文件顶部添加操作HDFS的用户为root,防止启动错误。
#分别在start-dfs.sh 和stop-dfs.sh文件顶部添加如下内容HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
格式化并启动HDFS集群
HDFS完全分布式集群搭建完成后,首次使用需要进行格式化,在NameNode节点(node1)上执行如下命令:
#在node1节点上格式化集群
[root@node1 ~]# hdfs namenode -format```
格式化集群完成后就可以在node1节点上执行如下命令启动集群:
```Plain Text
#在node1节点上启动集群
[root@node1 ~]# start-dfs.sh
至此,Hadoop完全分布式搭建完成,可以浏览器访问HDFS WebUI界面,通过此界面方便查看和操作HDFS集群。WebUI访问地址如下,在Hadoop2.x版本中,访问的WEBUI端口为50070,Hadoop3.x 访问WebUi端口是9870。
NameNode WebUI访问地址为:http://node1:9870,需要在window中配置hosts。
SecondaryNameNode WebUI访问地址为:http://node1:9868
停止集群时只需要在NameNode节点上执行stop-dfs.sh命令即可。后续再次启动HDFS集群只需要在NameNode节点执行start-dfs.sh命令,不需要再次格式化集群。
查看集群目录
- 查看NameNode数据目录
可以在hdfs-site.xml中配置“dfs.namenode.name.dir”属性来指定NameNode存储数据的目录,默认NameNode数据存储在${hadoop.tmp.dir}/dfs/name目录,进入“/opt/data/local_hadoop/dfs/name/current”查看相应NameNode存储数据信息:
[root@node1 ~]# ll /opt/data/local_hadoop/dfs/name/current
edits_0000000000000000001-0000000000000000002
edits_inprogress_0000000000000000003
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
一个运行的NameNode如下的目录结构,该目录结构在第一次格式化的时候创建。
![[图片]](https://i-blog.csdnimg.cn/direct/e2177dbc02f540e4ba97a957ae182c23.png)
- in_use.lock文件用于NameNode锁定存储目录。这样就防止其他同时运行的NameNode实例使用相同的存储目录。
- edits表示edits log日志文件。
- fsimage表示文件系统元数据镜像文件。
- seen_txid记录edits操作编号,NameNode在checkpoint之前首先要切换新的edits log文件,在切换时更新seen_txid的值。上次合并fsimage和editslog之后的第一个操作编号。
- VERSION文件是一个Java的属性文件。
![[图片]](https://i-blog.csdnimg.cn/direct/daa5c7e130a24c19baf1da1f281e77b3.png)
- layoutVersion是一个负数,定义了HDFS持久化数据结构的版本。这个版本数字跟hadoop发行的版本无关。当layout改变的时候,该数字减1(比如从-57到-58)。当对HDFDS进行了升级,就会发生layoutVersion的改变。
- namespaceID是该文件系统的唯一标志符,当NameNode第一次格式化的时候生成。
- clusterID是HDFS集群使用的一个唯一标志符,在HDFS联邦的情况下,就看出它的作用了,因为联邦情况下,集群有多个命名空间,不同的命名空间由不同的NameNode管理。
- blockpoolID是block池的唯一标志符,一个NameNode管理一个命名空间,该命名空间中的所有文件存储的block都在block池中。
- cTime标记着当前NameNode创建的时间。对于刚格式化的存储,该值永远是0,但是当文件系统更新的时候,这个值就会更新为一个时间戳。
- storageType表示当前目录存储NameNode内容的数据结构。
- 查看SecondaryNameNode数据目录
可以在hdfs-site.xml中配置“dfs.namenode.checkpoint.dir”属性来指定SecondaryNameNode存储数据的目录,默认SecondaryNameNode数据存储在${hadoop.tmp.dir}/dfs/namesecondary目录,进入“/opt/data/local_hadoop/dfs/namesecondary/current”查看相应SecondaryNameNode存储数据信息:
[root@node1 ~]# ll /opt/data/local_hadoop/dfs/namesecondary/current
edits_0000000000000000001-0000000000000000002
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
fsimage_0000000000000000002
fsimage_0000000000000000002.md5
VERSION
SecondaryNameNode数据目录主要是定期对NameNode中edits和fsimage进行合并,然后将合并数据推送给NameNode。
3. 查看DataNode数据目录
可以在hdfs-site.xml中配置“dfs.datanode.data.dir”属性来指定DataNode存储数据的目录,默认NameNode数据存储在${hadoop.tmp.dir}/dfs/data目录,进入“/opt/data/local_hadoop/dfs/data/current”查看相应DataNode存储Block数据信息:
[root@node1 ~]# ll /opt/data/local_hadoop/dfs/data/current
BP-1620277224-192.168.179.4-1705932038786
VERSION
DataNode关键文件和目录结构如下:![[图片]](https://i-blog.csdnimg.cn/direct/9d0d17624b4c4f288938d8e7ed67b913.png)
- HDFS块数据存储于blk_前缀的文件中,包含了被存储文件原始字节数据的一部分。
- 每个block文件都有一个.meta后缀的元数据文件关联。该文件包含了一个版本和类型信息的头部,后接该block中每个部分的校验和。
- 每个block属于一个block池,每个block池有自己的存储目录,该目录名称就是该池子的ID(跟NameNode的VERSION文件中记录的block池ID一样)。
- 当一个目录中的block达到64个的时候,DataNode会创建一个新的子目录来存放新的block和它们的元数据。这样即使当系统中有大量的block的时候,目录树也不会太深。同时也保证了在每个目录中文件的数量是可管理的,避免了多数操作系统都会碰到的单个目录中的文件个数限制(几十几百上千个)。
- 如果dfs.datanode.data.dir指定了位于在不同的硬盘驱动器上的多个不同的目录,则会通过轮询的方式向目录中写block数据。需要注意的是block的副本不会在同一个DataNode上复制,而是在不同的DataNode节点之间复制。
HDFS完全分布式集群搭建
节点规划
在前面课程中,我们知道Hadoop集群中有Namenode,SecondaryNameNode,DataNode各个角色,这里我们需要搭建HDFS完全分布式集群,在我们现有Linux集群中节点对应角色划分如下: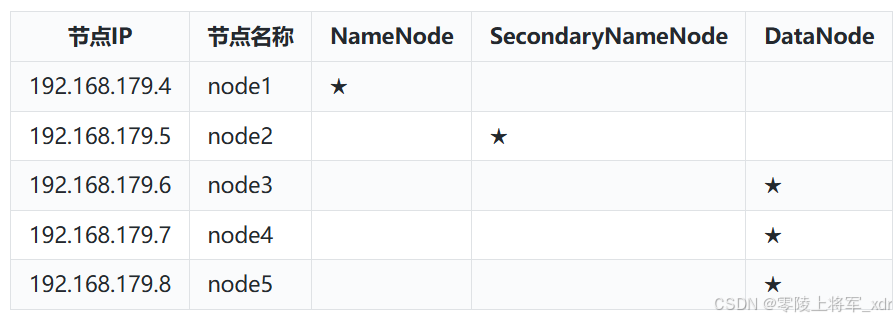
安装JDK
同上,需要各个节点都按照jdk
HDFS完全分布式集群搭建
- 下载安装包并解压
我们安装Hadoop3.3.6版本,此版本目前是比较新的版本,搭建HDFS集群前,首先需要在官网下载安装包,地址如下:https://hadoop.apache.org/releases.html。下载完成安装包后,上传到node1节点的/software目录下并解压,没有此目录,可以先创建此目录。
#将下载好的hadoop安装包上传到node1节点上
[root@node1 ~]# ls /software/
hadoop-3.3.6.tar.gz
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./hadoop-3.3.6.tar.gz
- 在node1节点上配置Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile
- 配置hadoop-env.sh
由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,而Hadoop启动需要读取到JAVA_HOME信息,所有这里需要手动指定。在对应的$HADOOP_HOME/etc/hadoop路径中,找到hadoop-env.sh文件加入以下配置(大概在54行有默认注释配置的JAVA_HOME):
#vim /software/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
- 配置core-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改core-site.xml文件,指定HDFS集群数据访问地址及集群数据存放路径。
#vim /software/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS文件系统访问URI -->
<property>
<name>fs.defaultFS</name>
<value>viewfs://ClusterX</value>
</property>
<!-- 将 /data 目录挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://node1:8020/data</value>
</property>
<!-- 将 /project 目录挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://node1:8020/project</value>
</property>
<!-- 将 /user 目录挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://node2:8020/user</value>
</property>
<!-- 将 /tmp 目录挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://node2:8020/tmp</value>
</property>
<!-- 对于没有配置的路径存放在 /home目录并挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://node2:8020/home</value>
</property>
<!-- 指定 Hadoop 数据存放的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/federation</value>
</property>
</configuration>
以上配置就是配置将不同数据目录交由不同的HDFS集群进行管理以减少元数据所占NN空间,并将各个目录挂载到viewfs中方便统一访问。
- 配置hdfs-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改hdfs-site.xml文件,指定NameNode和SecondaryNameNode节点和端口。在Hadoop Federation联邦中需要指定多个NN及相应SNN地址。
#vim /software/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<!-- block副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 两个NS -->
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<!-- NS1 NameNode 地址和端口号-->
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>node1:8020</value>
</property>
<!-- NS1 NameNode WebUI访问地址-->
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>node1:9870</value>
</property>
<!-- NS1 SecondaryNameNode WebUI访问地址-->
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>node3:9868</value>
</property>
<!-- NS2 NameNode 地址和端口号-->
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>node2:8020</value>
</property>
<!-- NS2 NameNode WebUI访问地址-->
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>node2:9870</value>
</property>
<!-- NS2 SecondaryNameNode WebUI访问地址-->
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>node4:9868</value>
</property>
</configuration>
- 配置workers指定DataNode节点
进入 $HADOOP_HOME/etc/hadoop路径下,修改workers配置文件,加入以下内容:
#vim /software/hadoop-3.3.6/etc/hadoop/workers
node3
node4
node5
- 配置start-dfs.sh&stop-dfs.sh
进入 $HADOOP_HOME/sbin路径下,在start-dfs.sh和stop-dfs.sh文件顶部添加操作HDFS的用户为root,防止启动错误。
#分别在start-dfs.sh 和stop-dfs.sh文件顶部添加如下内容
HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 分发安装包
将node1节点上配置好的hadoop安装包发送到node2~node5节点上。这里由于Hadoop安装包比较大,也可以先将原有hadoop安装包上传到其他节点解压,然后在node1节点上只分发hfds-site.xml 、core-site.xml文件即可。
#在node1节点上执行如下分发命令
[root@node1 ~]# cd /software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node2:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node3:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node4:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node5:/software/
- 在node2、node3、node4、node5节点上配置HADOOP_HOME
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile
格式化并启动HDFS集群
HDFS完全分布式集群搭建完成后,首次使用需要进行格式化,在NameNode节点(node1)上执行如下命令:
#在node1节点上格式化集群
[root@node1 ~]# hdfs namenode -format
格式化集群完成后就可以在node1节点上执行如下命令启动集群:
#在node1节点上启动集群
[root@node1 ~]# start-dfs.sh
至此,Hadoop完全分布式搭建完成,可以浏览器访问HDFS WebUI界面,通过此界面方便查看和操作HDFS集群。WebUI访问地址如下,在Hadoop2.x版本中,访问的WEBUI端口为50070,Hadoop3.x 访问WebUi端口是9870。
NameNode WebUI访问地址为:http://node1:9870,需要在window中配置hosts。
停止集群时只需要在NameNode节点上执行stop-dfs.sh命令即可。后续再次启动HDFS集群只需要在NameNode节点执行start-dfs.sh命令,不需要再次格式化集群。
HDFS集群搭建注意点
在搭建和使用HDFS集群中需要注意如下点:
- HDFS伪分布式集群只是测试,HDFS完全分布式是重点,需要掌握HDFS完全分布式搭建。
- 如果在集群搭建过程中出现错误需要重新格式化集群时,那么需要删除相关配置文件中指定的目录后,再次格式化,不删除先前集群数据目录会导致新的集群格式化不成功或者使用时有问题。
- 无论是伪分布式还是完全分布式集群搭建,格式化集群只需要在集群搭建完成后第一次启动时执行,后续使用HDFS集群不需要格式化,只需要执行start-dfs.sh/stop-dfs.sh 启停集群即可。
- window访问HDFS集群时,如果使用别名而非IP访问,需要在windows “C:\Windows\System32\drivers\etc\hosts”文件中配置ip和别名映射。
HDFS shell操作
基于xshell来操作HDFS时,可以使用HADOOP_HOME/bin/hadoopfs具体命令或者使用HADOOP_HOME/bin/hdfs dfs 具体命令,其中fs也可以使用dfs命令代替,dfs是fs的实现类。
hadoop fs 命令执行后,可以查看操作HDFS用法:![[图片]](https://i-blog.csdnimg.cn/direct/ccb9091987b8426b9f9e154e7e60d639.png)
hadoop fs 命令等价于hdfs dfs ,都可以操作HDFS。![[图片]](https://i-blog.csdnimg.cn/direct/a1886643e5074084a7235b419fe5e14d.png)
下面介绍HDFS中常用的一些操作命令。
help
help主要是查看命令的帮助。
[root@node1 ~]# hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile [-n] <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
... ...
-ls
-ls:主要显示目录信息,查看HDFS中某个目录下的文件信息。
[root@node1 ~\]# hdfs dfs -ls
-mkdir
-mkdir 在HDFS中创建目录,还可跟上-p来创建多级目录。
[root@node1 ~]# hdfs dfs -mkdir /hello
[root@node1 ~]# hdfs dfs -mkdir /hello/a/b/cmkdir: `/hello/a/b/c': No such file or directory
[root@node1 ~]# hdfs dfs -mkdir -p /hello/a/b/c
-moveFromLocal
-moveFromLocal:将文件从本地剪切到HDFS目录中。
[root@node1 ~]# vim data.txt
hello zhangsan
hello lisi
hello wangwu
[root@node1 ~]# hdfs dfs -moveFromLocal ./data.txt /hello/
[root@node1 ~]# hdfs dfs -ls /hello
-cat
-cat : 显示HDFS文件内容命令。
[root@node1 ~]# hdfs dfs -cat /hello/data.txt
hello zhangsan
hello lisi
hello wangwu
-appendToFile
-appendToFile :追加一个文件到已经存在的文件末尾。
[root@node1 ~]# vim data2.txt
aaa
bbb
ccc
#将data2.txt文件内容追加到data.txt文件中
[root@node1 ~]# hdfs dfs -appendToFile ./data2.txt /hello/data.txt
[root@node1 ~]# hdfs dfs -cat /hello/data.txt
hello zhangsan
hello lisi
hello wangwu
aaa
bbb
ccc
-chmod
-chmod 给文件赋值权限,文件系统中的用法一样。
[root@node1 ~]# hdfs dfs -ls /hello/data.txt
-rw-r--r-- 3 root supergroup /hello/data.txt
[root@node1 ~]# hdfs dfs -chmod 777 /hello/data.txt
[root@node1 ~]# hdfs dfs -ls /hello/data.txt
-rwxrwxrwx 3 root supergroup /hello/data.txt
-copyFromLocal:
-copyFromLocal: 从本地文件系统中拷贝文件到HDFS路径去。
[root@node1 ~]# vim data3.txt
hello zhangsan
hello lisi
hello wangwu
#将data3.txt拷贝到HDFS中
[root@node1 ~]# hdfs dfs -copyFromLocal ./data3.txt /hello/
[root@node1 ~]# ll
data3.txt
-copyToLocal
-copyToLocal:从HDFS拷贝文件或者目录到本地。
[root@node1 ~]# hdfs dfs -copyToLocal /hello/ ./
[root@node1 ~]# ll
hello
-cp
-cp : 从HDFS的一个路径拷贝到HDFS的另一个路径。
[root@node1 ~]# hdfs dfs -mkdir -p /hello2
[root@node1 ~]# hdfs dfs -cp /hello/data.txt /hello2/
[root@node1 ~]# hdfs dfs -ls /hello2
/hello2/data.txt
-mv
-mv:在HDFS目录中移动文件,将文件移动到某个HDFS目录中。
[root@node1 ~]# hdfs dfs -mkdir -p /hello3
[root@node1 ~]# hdfs dfs -mv /hello2/data.txt /hello3/
[root@node1 ~]# hdfs dfs -ls /hello3//hello3/data.txt```
-get
-get:等同于copyToLocal,将文件从HDFS中下载文件到本地。
```Plain Text
[root@node1 ~]# hdfs dfs -get /hello3 ./
[root@node1 ~]# ll
hello3
-put
-put:等同于copyFromLocal,将本地文件复制上传到HDFS中。
[root@node1 ~]# hdfs dfs -put ./hello3.txt /
-getmerge
-getmerge:合并下载多个文件,比如HDFS的目录 /hello4下有多个文件:a.txt,b.txt,c.txt…,可以通过此命令,将数据合并下载到本地某个目录。
#创建hello4目录,并将对应的a.txt,b.txt,c.txt上传到此目录下
[root@node1 ~]# hdfs dfs -mkdir /hello4
[root@node1 ~]# hdfs dfs -put ./a.txt /hello4
[root@node1 ~]# hdfs dfs -put ./b.txt /hello4
[root@node1 ~]# hdfs dfs -put ./c.txt /hello4
[root@node1 ~]# hdfs dfs -ls /hello4
-rw-r--r-- 3 root supergroup /hello4/a.txt
-rw-r--r-- 3 root supergroup /hello4/b.txt
-rw-r--r-- 3 root supergroup /hello4/c.txt
[root@node1 ~]# hdfs dfs -getmerge /hello4/* ./merge.txt
[root@node1 ~]# ll
-rw-r--r--. 1 root root merge.tx
-tail
-tail:显示一个文件最后1kb数据到控制台。
[root@node1 ~]# hdfs dfs -tail /hello4/merge.txt
aaa
bbb
ccc
-rm
-rm:删除文件或文件夹。可以加上 -r来递归删除目录下的所有数据。
[root@node1 ~]# hdfs dfs -rm /hello4/merge.txt
Deleted /hello4/merge.txt
[root@node1 ~]# hdfs dfs -rm -r /hello/
Deleted /hello
-rmdir
-rmdir:删除空目录,目录必须是空目录才可以。
[root@node1 ~]# hdfs dfs -rmdir /hello2
注意:目录必须是空目录
-du
-du:统计文件夹的大小信息。第一列标示该目录下总文件大小。第二列标示该目录下所有文件在集群上的总存储大小和你的副本数相关,副本数默认是3 ,所以第二列的是第一列的三倍(第二列内容=文件大小*副本数),第三列表示查询的目录。
[root@node1 ~]# hdfs dfs -du /hello4
4 12 /hello4/a.txt
4 12 /hello4/b.txt
4 12 /hello4/c.txt
-setrep
-setrep:设置HDFS中文件的副本数量。
[root@node1 ~]# hdfs dfs -setrep 10 /hello3/data.txt
Replication 10 set: /hello3/data.txt
注意:这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台DataNode,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10
HDFS Api操作
Window环境准备
在window中通过IDEA编写操作HDFS的代码需要Window中配置Hadoop环境变量。首先将Hadoop3.x安装包下载到一个不包括中文、空格的路径中并解压,这里将Hadoop安装包解压下,如下:
然后在Window中配置Hadoop环境变量:
配置完Hadoop环境变量后,还需要将的winutils.exe和hadoop.dll文件放在环境变量bin目录下。此外,hadoop.dll还要复制到“C:\Windows\System32”目录下。
相关资料下载地址:https://github.com/cdarlint/winutils
API操作HDFS
在IDEA中创建项目,项目pom.xml导入依赖如下:
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>3.3.6</hadoop.version>
<slf4j.version>1.7.36</slf4j.version>
<log4j.version>2.17.2</log4j.version>
<junit.version>4.11</junit.version>
</properties><dependencies><!-- 操作 HDFS 所需依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!-- slf4j&log4j 日志相关包 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>${log4j.version}</version></dependency></dependencies>
编写代码如下:
public class TestHDFS {
public static FileSystem fs = null;
public static void main(String[] args) throws IOException, InterruptedException {
Configuration conf = new Configuration(true);
//创建FileSystem对象
fs = FileSystem.get(URI.create("hdfs://node1:8020/"),conf,"root");
//查看HDFS路径文件
listHDFSPathDir("/");
System.out.println("=====================================");
//创建目录
mkdirOnHDFS("/laowu/testdir");
System.out.println("=====================================");
//向HDFS 中上传数据
writeFileToHDFS("./data/test.txt","/laowu/testdir/test.txt");
System.out.println("=====================================");
//重命名HDFS文件
renameHDFSFile("/laowu/testdir/test.txt","/laowu/testdir/new_test.txt");
System.out.println("=====================================");
//查看文件详细信息
getHDFSFileInfos("/laowu/testdir/new_test.txt");
System.out.println("=====================================");
//读取HDFS中的数据
readFileFromHDFS("/laowu/testdir/new_test.txt");
System.out.println("=====================================");
//删除HDFS中的目录或者文件
deleteFileOrDirFromHDFS("/laowu/testdir");
System.out.println("=====================================");
//关闭fs对象
fs.close();
}
private static void listHDFSPathDir(String hdfsPath) throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path(hdfsPath));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath());
}
}
private static void mkdirOnHDFS(String dirpath) throws IOException {
Path path = new Path(dirpath);
//判断目录是否存在if(fs.exists(path)) {
System.out.println("目录" + dirpath + "已经存在");
return;
}
//创建HDFS目录
boolean result = fs.mkdirs(path);
if(result) {
System.out.println("创建目录" + dirpath + "成功");
} else {
System.out.println("创建目录" + dirpath + "失败");
}
}
private static void writeFileToHDFS(String localFilePath, String hdfsFilePath) throws IOException {
//判断HDFS文件是否存在,存在则删除
Path hdfsPath = new Path(hdfsFilePath);
if(fs.exists(hdfsPath)) {
fs.delete(hdfsPath, true);
}
//创建HDFS文件路径
Path path = new Path(hdfsFilePath);
FSDataOutputStream out = fs.create(path);
//读取本地文件写入HDFS路径中
FileReader fr = new FileReader(localFilePath);
BufferedReader br = new BufferedReader(fr);
String newLine = "";
while ((newLine = br.readLine()) != null) {
out.write(newLine.getBytes());
out.write("\n".getBytes());
}
//关闭流对象
out.close();
br.close();
fr.close();
//以上代码也可以调用copyFromLocalFile方法完成//参数解释如下:上传完成是否删除原数据;是否覆盖写入;本地文件路径;写入HDFS文件路径
fs.copyFromLocalFile(false,true,new Path(localFilePath),new Path(hdfsFilePath));
System.out.println("本地文件 ./data/test.txt 写入了HDFS中的"+hdfsFilePath+"文件中");
}
private static void renameHDFSFile(String hdfsOldFilePath,String hdfsNewFilePath) throws IOException {
fs.rename(new Path(hdfsOldFilePath),new Path(hdfsNewFilePath));
System.out.println("成功将"+hdfsOldFilePath+"命名为:"+hdfsNewFilePath);
}
private static void getHDFSFileInfos(String hdfsFilePath) throws IOException {
Path file = new Path(hdfsFilePath);
RemoteIterator<LocatedFileStatus> listFilesIterator = fs.listFiles(file, true);//是否递归while(listFilesIterator.hasNext()){
LocatedFileStatus fileStatus = listFilesIterator.next();
System.out.println("文件详细信息如下:");
System.out.println("权限:" + fileStatus.getPermission());
System.out.println("所有者:" + fileStatus.getOwner());
System.out.println("组:" + fileStatus.getGroup());
System.out.println("大小:" + fileStatus.getLen());
System.out.println("修改时间:" + fileStatus.getModificationTime());
System.out.println("副本数:" + fileStatus.getReplication());
System.out.println("块大小:" + fileStatus.getBlockSize());
System.out.println("文件名:" + fileStatus.getPath().getName());
//获取当前文件block所在节点信息
BlockLocation[] blks = fileStatus.getBlockLocations();
for (BlockLocation nd : blks) {
System.out.println("block信息:"+nd);
}
}
}
private static void readFileFromHDFS(String hdfsFilePath) throws IOException {
//读取HDFS文件
Path path= new Path(hdfsFilePath);
FSDataInputStream in = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String newLine = "";
while((newLine = br.readLine()) != null) {
System.out.println(newLine);
}
//关闭流对象
br.close();
in.close();
}
private static void deleteFileOrDirFromHDFS(String hdfsFileOrDirPath) throws IOException {
//判断HDFS目录或者文件是否存在
Path path = new Path(hdfsFileOrDirPath);
if(!fs.exists(path)) {
System.out.println("HDFS目录或者文件不存在");
return;
}
//第二个参数表示是否递归删除
boolean result = fs.delete(path, true);
if(result){
System.out.println("HDFS目录或者文件 "+path+" 删除成功");
} else {
System.out.println("HDFS目录或者文件 "+path+" 删除成功");
}
}
}
Hadoop Federation 联邦
Federation背景介绍
![[图片]](https://i-blog.csdnimg.cn/direct/ca45febfb5544c5a81274c574b82cc70.png)
从上图中,我们可以很明显地看出现有的HDFS数据管理,数据存储2层分层的结构。也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下。而这些隶属于同一个NameNode,所管理的数据都是在同一个命名空间下的“NS”,以上结构是一个NameNode管理集群中所有元数据信息。
举个例子,一般1GB内存放1,000,000 block元数据。200个节点的集群中每个节点有24TB存储空间,block大小为128MB,能存储大概4千万个block(200241024*1024M/128 约为4千万或更多)。100万需要1G内存存储元数据,4千万大概需要40G内存存储元数据,假设节点数如果更多、存储数据更多的情况下,需要的内存也就越多。
通过以上例子可以看出,单NameNode的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode 成为了性能的瓶颈。这时该怎么办?元数据空间依然还是在不断增大,一味调高NameNode的JVM大小绝对不是一个持久的办法,这时候就诞生了 HDFS Federation 的机制。
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。Federation中文意思为联邦、联盟,HDFS Federation是NameNode的Federation,也就是会有多个NameNode。这些 namenode之间是联合的,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode的命令。![[图片]](https://i-blog.csdnimg.cn/direct/29b78beba081445bb0b6fb451eb14982.png)
- NameNode节点之间是相互独立的联邦的关系,即它们之间不需要协调服务。
- DataNode向集群中所有的NameNode注册,发送心跳和block块列表报告,处理来自NameNode的指令。
- 用户可以使用ViewFs创建个性化的命名空间视图,ViewFs类似于在Unix/Linux系统中的客户端挂载表。
Federation搭建
Hadoop Federation机制可以看成将多个HDFS集群进行了统一管理,即:多个HDFS集群中,每个集群都有一个或者多个NameNode,每个NameNode只能属于一个集群且都有自己的NameSpace,集群间的NameSpace相互独立。通过Hadoop Federation机制可以将指定数据存储在不同的集群由不同的NS管理,且可以通过ViewFS进行统一访问。
在node1~node5节点中进行Hadoop Federation集群搭建节点规划如下: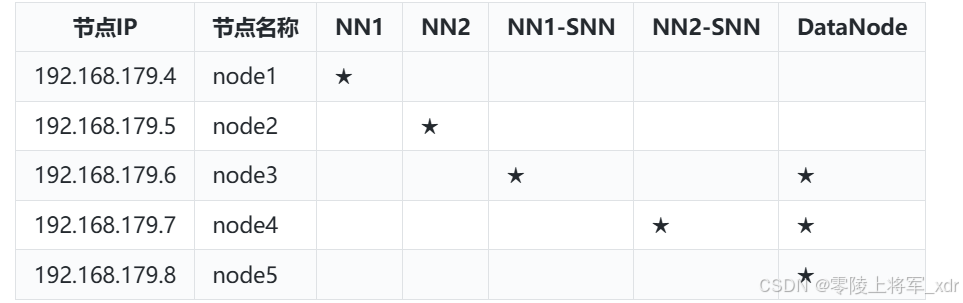
在搭建Hadoop Federation之前,首先将node1~node5节点上之前搭建的Hadoop集群数据目录和安装文件删除,重新进行搭建,搭建步骤如下。
- 下载安装包并解压
我们安装Hadoop3.3.6版本,此版本目前是比较新的版本,搭建HDFS集群前,首先需要在官网下载安装包,地址如下:https://hadoop.apache.org/releases.html。下载完成安装包后,上传到node1节点的/software目录下并解压,没有此目录,可以先创建此目录。
#将下载好的hadoop安装包上传到node1节点上
[root@node1 ~]# ls /software/
hadoop-3.3.6.tar.gz
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./hadoop-3.3.6.tar.gz
- 在node1节点上配置Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile
- 配置hadoop-env.sh
由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,而Hadoop启动需要读取到JAVA_HOME信息,所有这里需要手动指定。在对应的$HADOOP_HOME/etc/hadoop路径中,找到hadoop-env.sh文件加入以下配置(大概在54行有默认注释配置的JAVA_HOME):
#vim /software/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
- 配置core-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改core-site.xml文件,指定HDFS集群数据访问地址及集群数据存放路径。
#vim /software/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS文件系统访问URI -->
<property>
<name>fs.defaultFS</name>
<value>viewfs://ClusterX</value>
</property>
<!-- 将 /data 目录挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://node1:8020/data</value>
</property>
<!-- 将 /project 目录挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://node1:8020/project</value>
</property>
<!-- 将 /user 目录挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://node2:8020/user</value>
</property>
<!-- 将 /tmp 目录挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://node2:8020/tmp</value>
</property>
<!-- 对于没有配置的路径存放在 /home目录并挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://node2:8020/home</value>
</property>
<!-- 指定 Hadoop 数据存放的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/federation</value>
</property>
</configuration>
以上配置就是配置将不同数据目录交由不同的HDFS集群进行管理以减少元数据所占NN空间,并将各个目录挂载到viewfs中方便统一访问。
- 配置hdfs-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改hdfs-site.xml文件,指定NameNode和SecondaryNameNode节点和端口。在Hadoop Federation联邦中需要指定多个NN及相应SNN地址。
#vim /software/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<!-- block副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 两个NS -->
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<!-- NS1 NameNode 地址和端口号-->
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>node1:8020</value>
</property>
<!-- NS1 NameNode WebUI访问地址-->
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>node1:9870</value>
</property>
<!-- NS1 SecondaryNameNode WebUI访问地址-->
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>node3:9868</value>
</property>
<!-- NS2 NameNode 地址和端口号-->
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>node2:8020</value>
</property>
<!-- NS2 NameNode WebUI访问地址-->
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>node2:9870</value>
</property>
<!-- NS2 SecondaryNameNode WebUI访问地址-->
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>node4:9868</value>
</property>
</configuration>
- 配置workers指定DataNode节点
进入 $HADOOP_HOME/etc/hadoop路径下,修改workers配置文件,加入以下内容:
#vim /software/hadoop-3.3.6/etc/hadoop/workers
node3
node4
node5
- 配置start-dfs.sh&stop-dfs.sh
进入 $HADOOP_HOME/sbin路径下,在start-dfs.sh和stop-dfs.sh文件顶部添加操作HDFS的用户为root,防止启动错误。
#分别在start-dfs.sh 和stop-dfs.sh文件顶部添加如下内容
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 分发安装包
将node1节点上配置好的hadoop安装包发送到node2~node5节点上。这里由于Hadoop安装包比较大,也可以先将原有hadoop安装包上传到其他节点解压,然后在node1节点上只分发hfds-site.xml 、core-site.xml文件即可。
#在node1节点上执行如下分发命令
[root@node1 ~]# cd /software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node2:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node3:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node4:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node5:/software/
- 在node2、node3、node4、node5节点上配置HADOOP_HOME
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile
格式化并启动HDFS集群
Hadoop Federation联邦集群搭建完成后需要对两个NameNode进行格式化,在格式化node1和node2上的namenode时候,需要指定clusterId,并且两个格式化的时候这个clusterId要一致,两个namenode具有相同的clusterId,它们在一个集群中,它们是联邦的关系。如下:
#在node1节点上格式化NameNode
[root@node1 ~]# hdfs namenode -format -clusterId viewfs
#在node2节点上格式化NameNode
[root@node1 ~]# hdfs namenode -format -clusterId viewfs
格式化集群完成后就可以在node1/node2 NameNode节点上执行如下命令启动集群:
start-dfs.sh
至此,Hadoop完全分布式搭建完成,可以浏览器访问HDFS WebUI界面,通过此界面方便查看和操作HDFS集群。WebUI访问地址如下,在Hadoop2.x版本中,访问的WEBUI端口为50070,Hadoop3.x 访问WebUi端口是9870。
停止集群时只需要在NameNode节点上执行stop-dfs.sh命令即可。后续再次启动HDFS集群只需要在NameNode节点执行start-dfs.sh命令,不需要再次格式化集群。
集群启动后需要在集群中创建好 /data 、/project、/user、/tmp目录,需要根据配置在不同的集群中创建以上目录。使用如下命令在NameNode中进行创建即可:
#NN1集群中创建
[root@node1 ~]# hdfs dfs -mkdir hdfs://node1:8020/data
[root@node1 ~]# hdfs dfs -mkdir hdfs://node1:8020/project
#NN2集群中创建
[root@node1 ~]# hdfs dfs -mkdir hdfs://node2:8020/user
[root@node1 ~]# hdfs dfs -mkdir hdfs://node2:8020/tmp
创建好目录后,可以通过WebUI观察两个HDFS集群,目录在各自集群中创建,互不影响。
下面将不同的文件数据通过viewfs直接上传到集群中(准备a.txt、b.txt、c.txt、d.txt、e.txt文件),上传数据时可以使用viewfs://ClusterX前缀,也可以不使用该前缀,都可以将数据上传至对应HDFS目录下。
#将a.txt上传到HDFS 集群/data目录下
[root@node1 ~]# hdfs dfs -put a.txt viewfs://ClusterX/data
#将b.txt上传到HDFS 集群/project目录下
[root@node1 ~]# hdfs dfs -put b.txt /project
#将c.txt上传到HDFS 集群/user目录下
[root@node1 ~]# hdfs dfs -put c.txt /user
#将d.txt上传到HDFS 集群/tmp目录下
[root@node1 ~]# hdfs dfs -put d.txt /tmp
#将e.txt上传到HDFS 集群/目录下, 默认会存入/home目录中
[root@node1 ~]# hdfs dfs -put e.txt /xx
#在HDFS集群中创建配置文件中没有指定目录时,会将该目录创建在/home目录中
[root@node1 ~]# hdfs dfs -mkdir /ss
查看HDFS集群中文件及删除文件操作:
#查看a.txt文件
[root@node1 ~]# hdfs dfs -cat /data/a.txt
#删除a.txt文件
[root@node1 ~]# hdfs dfs -rm -r /data/a.txt
Federation问题
HDFS Federation 并没有完全解决单点故障问题。虽然 namenode/namespace 存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个 namenode 挂掉了,其管理的相应的文件便不可以访问。当然Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode 挂掉重启后,用于还原元数据信息,需要手动将挂掉的namenode重新启动。
所以一般集群规模真的很大的时候,会采用HA+Federation 的部署方案。也就是每个联合的namenodes都是HA(High Availablity - 高可用)的。
Hadoop NameNode HA
NameNode HA 背景
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameNode的备份,它只是NameNode的一个助理,协助NameNode工作,SecorndaryNameNode会对fsimage和edits文件进行合并,并推送给NameNode,防止因edits文件过大,导致NameNode重启变慢),这是Hadoop1的不可靠实现。
在Hadoop2中这个问题得以解决,Hadoop2中的高可靠性是指同时启动NameNode,其中一个处于active工作状态,另外一个处于随时待命standby状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Network File System或者Quorum Journal Node。前者是通过Linux共享的文件系统,属于操作系统的配置,后者是Hadoop自身的东西,属于软件的配置。
注意:
NameNode HA 与HDFS Federation都有多个NameNode,当NameNode作用不同,在HDFS Federation联邦机制中多个NameNode解决了内存受限问题,而在NameNode HA中多个NameNode解决了NameNode单点故障问题。
在Hadoop2.x版本中,NameNode HA 支持2个节点,在Hadoop3.x版本中,NameNode高可用可以支持多台节点。
NameNode HA实现原理
NameNode中存储了HDFS中所有元数据信息(包括用户操作元数据和block元数据),在NameNode HA中,当Active NameNode(ANN)挂掉后,StandbyNameNode(SNN)要及时顶上,这就需要将所有的元数据同步到SNN节点。如向HDFS中写入一个文件时,如果元数据同步写入ANN和SNN,那么当SNN挂掉势必会影响ANN,所以元数据需要异步写入ANN和SNN中。如果某时刻ANN刚好挂掉,但却没有及时将元数据异步写入到SNN也会引起数据丢失,所以向SNN同步元数据需要引入第三方存储,在HA方案中叫做“共享存储”。每次向HDFS中写入文件时,需要将edits log同步写入共享存储,这个步骤成功才能认定写文件成功,然后SNN定期从共享存储中同步editslog,以便拥有完整元数据便于ANN挂掉后进行主备切换。
HDFS将Cloudera公司实现的QJM(Quorum Journal Manager)方案作为默认的共享存储实现。在QJM方案中注意如下几点:
基于QJM的共享存储系统主要用于保存Editslog,并不保存FSImage文件,FSImage文件还是在NameNode本地磁盘中。
QJM共享存储采用多个称为JournalNode的节点组成的JournalNode集群来存储EditsLog。每个JournalNode保存同样的EditsLog副本。
每次NameNode写EditsLog时,除了向本地磁盘写入EditsLog外,也会并行的向JournalNode集群中每个JournalNode发送写请求,只要大多数的JournalNode节点返回成功就认为向JournalNode集群中写入EditsLog成功。
如果有2N+1台JournalNode,那么根据大多数的原则,最多可以容忍有N台JournalNode节点挂掉。
NameNode HA 实现原理图如下: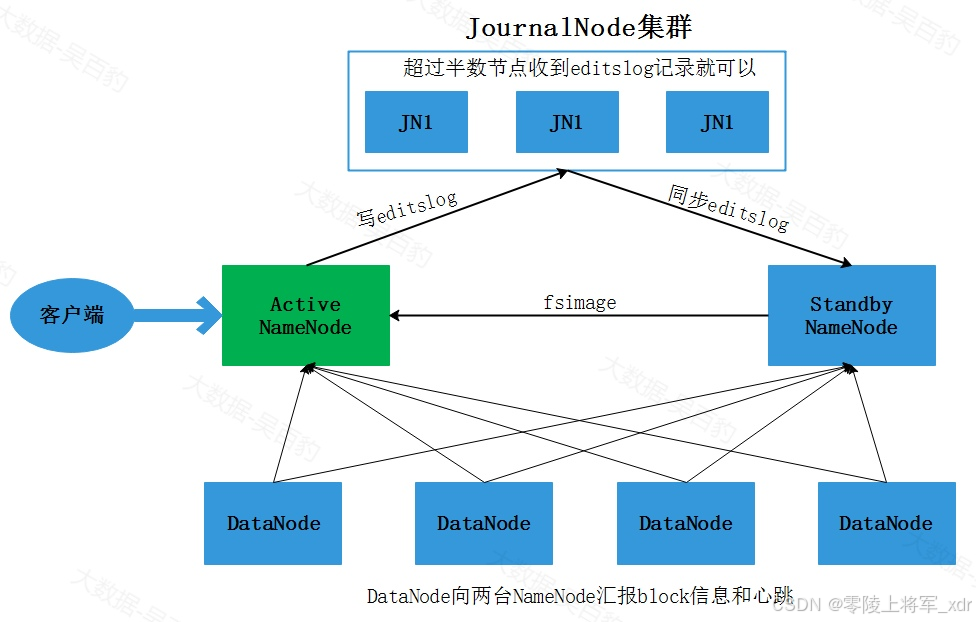
当客户端操作HDFS集群时,Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog。当处 于 Standby 状态的 NameNode 转换为 Active 状态的时候,有可能上一个 Active NameNode 发生了异常退出,那么 JournalNode 集群中各个 JournalNode 上的 EditLog 就可能会处于不一致的状态,所以首先要做的事情就是让 JournalNode 集群中各个节点上的 EditLog 恢复为一致,然后Standby NameNode会从JournalNode集群中同步EditsLog,然后对外提供服务。
注意:在NameNode HA中不再需要SecondaryNameNode角色,该角色被StandbyNameNode替代。
通过Journal Node实现NameNode HA时,可以手动将Standby NameNode切换成Active NameNode,也可以通过自动方式实现NameNode切换。
上图需要手动进行切换StandbyNamenode为Active NameNode,对于高可用场景时效性较低,那么可以通过zookeeper进行协调自动实现NameNode HA,实现代码通过Zookeeper来检测Activate NameNode节点是否挂掉,如果挂掉立即将Standby NameNode切换成Active NameNode,这种方式也是生产环境中常用情况。其原理如下: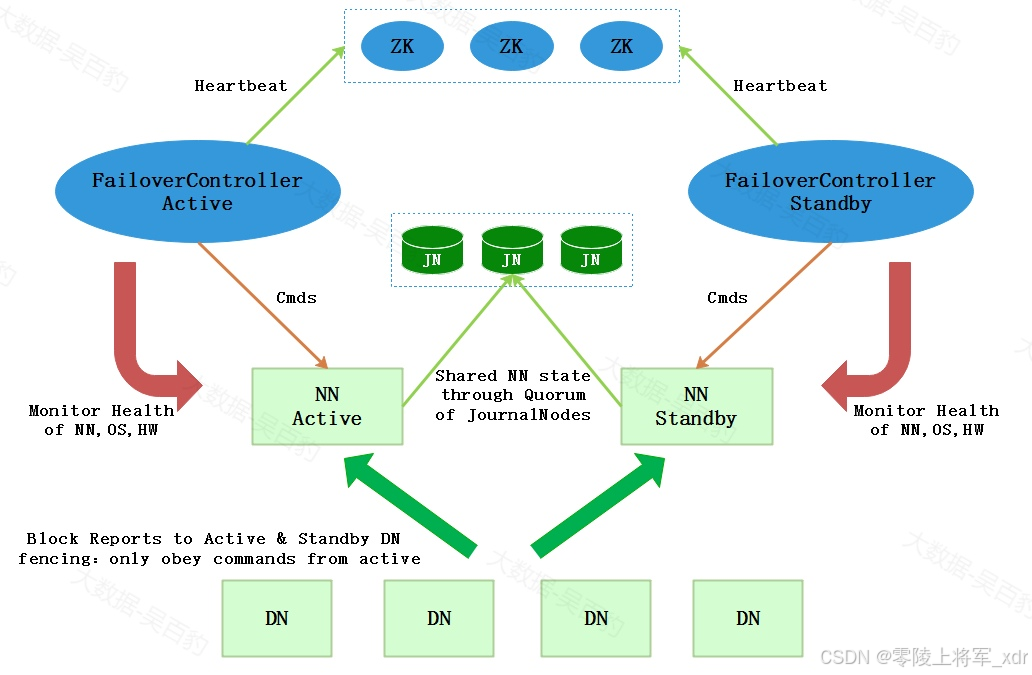
上图中引入了zookeeper作为分布式协调器来完成NameNode自动选主,以上各个角色解释如下:
- AcitveNameNode:主 NameNode,只有主NameNode才能对外提供读写服务。
- Standby NameNode:备用NameNode,定时同步Journal集群中的editslog元数据。
- ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制
- ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换。
- Zookeeper集群:分布式协调器,NameNode选主使用。
- Journal集群:Journal集群作为共享存储系统保存HDFS运行过程中的元数据,ANN和SNN通过Journal集群实现元数据同步。
- DataNode节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
NameNode主备切换流程
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现:
- ZKFailoverController 作为 NameNode 机器上一个独立的进程启动 (在 hdfs 集群中进程名为zkfc),启动的时候会创建 HealthMonitor 和 ActiveStandbyElector这两个主要的内部组件,ZKFailoverController 在创建 HealthMonitor ActiveStandbyElector 的同时,也会向 HealthMonitor 和 ActiveStandbyElector 注册相应的回调方法。
- HealthMonitor 主要负责检测 NameNode 的健康状态,如果检测到 NameNode 的状态发生变化,会回调 ZKFailoverController 的相应方法进行自动的主备选举。
- ActiveStandbyElector 主要负责完成自动的主备选举,内部封装了 Zookeeper 的处理逻辑,一旦 Zookeeper 主备选举完成,会回调 ZKFailoverController 的相应方法来进行 NameNode 的主备状态切换。
NameNode主备切换流程如下:
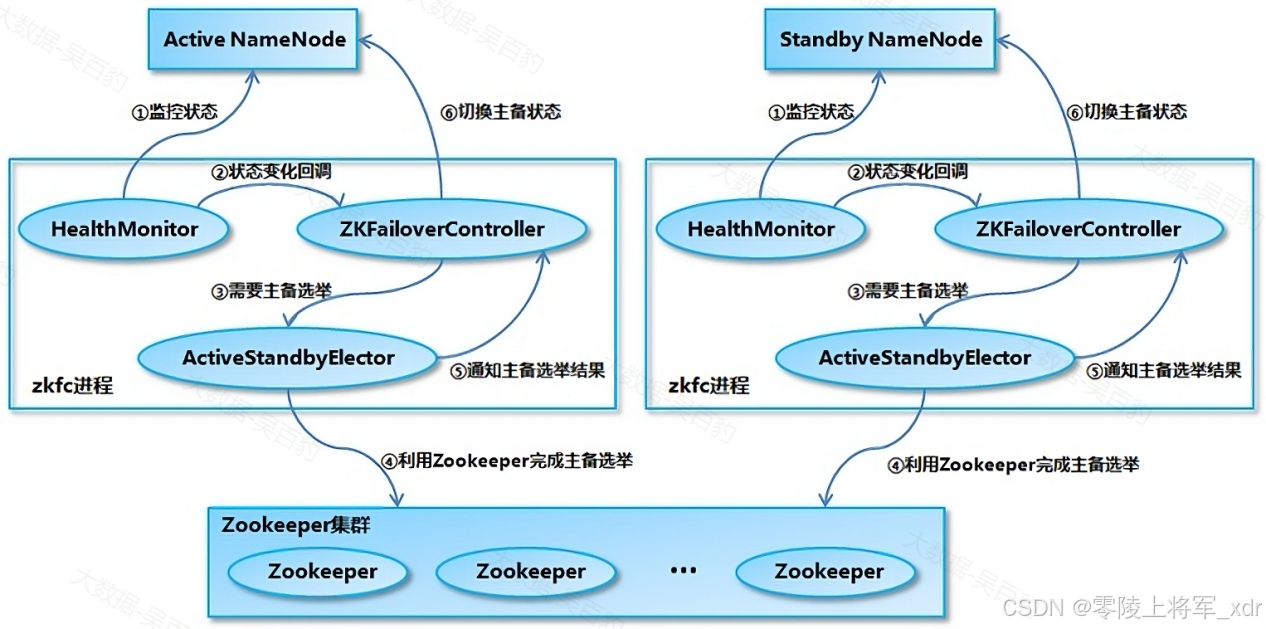
- HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
- HealthMonitor 如果检测到 NameNode的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
- 如果ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector来进行自动的主备选举。
- ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举
- ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的NameNode 成为主 NameNode 或备 NameNode。
- ZKFailoverController 调用对应NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或Standby 状态。
脑裂问题
当网络抖动时,ZKFC检测不到Active NameNode,此时认为NameNode挂掉了,因此将Standby NameNode切换成Active NameNode,而旧的Active NameNode由于网络抖动,接收不到zkfc的切换命令,此时两个NameNode都是Active状态,这就是脑裂问题。那么HDFS HA中如何防止脑裂问题的呢?
HDFS集群初始启动时,Namenode的主备选举是通过 ActiveStandbyElector 来完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的写一致性和临时节点机制,具体的主备选举实现如下:
- 创建锁节点
如果 HealthMonitor 检测到对应的 NameNode 的状态正常,那么表示这个 NameNode 有资格参加 Zookeeper 的主备选举。如果目前还没有进行过主备选举的话,那么相应的 ActiveStandbyElector 就会发起一次主备选举,尝试在 Zookeeper 上创建一个路径为/hadoop-ha/ d f s . n a m e s e r v i c e s / A c t i v e S t a n d b y E l e c t o r L o c k 的临时节点 ( {dfs.nameservices}/ActiveStandbyElectorLock 的临时节点 ( dfs.nameservices/ActiveStandbyElectorLock的临时节点({dfs.nameservices} 为 Hadoop 的配置参数 dfs.nameservices 的值,下同),Zookeeper 的写一致性会保证最终只会有一个 ActiveStandbyElector 创建成功,那么创建成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Active 状态。而创建失败的 ActiveStandbyElector 对应的NameNode成为备用NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Standby 状态。
- 注册 Watcher 监听
不管创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点是否成功,ActiveStandbyElector 随后都会向 Zookeeper 注册一个 Watcher 来监听这个节点的状态变化事件,ActiveStandbyElector 主要关注这个节点的 NodeDeleted 事件。
- 自动触发主备选举
如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点/hadoop-ha/ d f s . n a m e s e r v i c e s / A c t i v e S t a n d b y E l e c t o r L o c k ,这样处于 S t a n d b y 状态的 N a m e N o d e 的 A c t i v e S t a n d b y E l e c t o r 注册的监听器就会收到这个节点的 N o d e D e l e t e d 事件。收到这个事件之后,会马上再次进入到创建 / h a d o o p − h a / {dfs.nameservices}/ActiveStandbyElectorLock,这样处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件。收到这个事件之后,会马上再次进入到创建/hadoop-ha/ dfs.nameservices/ActiveStandbyElectorLock,这样处于Standby状态的NameNode的ActiveStandbyElector注册的监听器就会收到这个节点的NodeDeleted事件。收到这个事件之后,会马上再次进入到创建/hadoop−ha/{dfs.nameservices}/ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换。
以上过程中,Standby NameNode成功创建 Zookeeper 节点/hadoop-ha/ d f s . n a m e s e r v i c e s / A c t i v e S t a n d b y E l e c t o r L o c k 成为 A c t i v e N a m e N o d e 之后,还会创建另外一个路径为 / h a d o o p − h a / {dfs.nameservices}/ActiveStandbyElectorLock 成为Active NameNode之后,还会创建另外一个路径为/hadoop-ha/ dfs.nameservices/ActiveStandbyElectorLock成为ActiveNameNode之后,还会创建另外一个路径为/hadoop−ha/{dfs.nameservices}/ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息。Active NameNode 的ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候 (注意由于/hadoop-ha/ d f s . n a m e s e r v i c e s / A c t i v e S t a n d b y E l e c t o r L o c k 是临时节点,也会随之删除 ) 会一起删除节点 / h a d o o p − h a / {dfs.nameservices}/ActiveStandbyElectorLock 是临时节点,也会随之删除)会一起删除节点/hadoop-ha/ dfs.nameservices/ActiveStandbyElectorLock是临时节点,也会随之删除)会一起删除节点/hadoop−ha/{dfs.nameservices}/ActiveBreadCrumb。但是如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如 Zookeeper 假死),那么由于/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行隔离(fencing)操作以避免出现脑裂问题,fencing操作会通过SSH将旧的Active NameNode进程尝试转换成Standby状态,如果不能转换成Standby状态就直接将对应进程杀死。
NameNode自动HA集群搭建
zookeeper集群搭建
这里搭建zookeeper版本为3.6.3,搭建zookeeper对应的角色分布如下: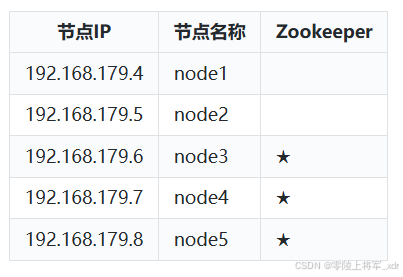
具体搭建步骤如下:
- 上传zookeeper并解压,配置环境变量
将zookeeper安装包上传到node3节点/software目录下并解压:
[root@node3 software]# tar -zxvf ./apache-zookeeper-3.6.3-bin.tar.gz
在node3节点配置环境变量:
#进入vim /etc/profile,在最后加入:
export ZOOKEEPER_HOME=/software/apache-zookeeper-3.6.3-bin/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
- 在node3节点配置zookeeper
进入“$ZOOKEEPER_HOME/conf”修改zoo_sample.cfg为zoo.cfg:
[root@node3 ~]# cd $ZOOKEEPER_HOME/conf
[root@node3 conf]# mv zoo_sample.cfg zoo.cfg
配置zoo.cfg中内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/data/zookeeper
clientPort=2181
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888
- 将配置好的zookeeper发送到node4,node5节点
[root@node3 software]# scp -r apache-zookeeper-3.6.3-bin node4:/software/
[root@node3 software]# scp -r apache-zookeeper-3.6.3-bin node5:/software/
- 各个节点上创建数据目录,并配置zookeeper环境变量
在node3,node4,node5各个节点上创建zoo.cfg中指定的数据目录“/opt/data/zookeeper”。
mkdir -p /opt/data/zookeeper
在node4,node5节点配置zookeeper环境变量
#进入vim /etc/profile,在最后加入:
export ZOOKEEPER_HOME=/software/apache-zookeeper-3.6.3-bin/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
- 各个节点创建节点ID
在node3,node4,node5各个节点路径“/opt/data/zookeeper”中添加myid文件分别写入1,2,3:
#在node3的/opt/data/zookeeper中创建myid文件写入1
#在node4的/opt/data/zookeeper中创建myid文件写入2
#在node5的/opt/data/zookeeper中创建myid文件写入3
- 各个节点启动zookeeper,并检查进程状态
#各个节点启动zookeeper命令
zkServer.sh start
#检查各个节点zookeeper进程状态
zkServer.sh status
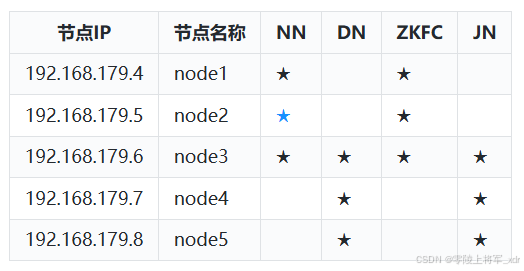
HDFS节点规划
搭建HDFS NameNode HA不再需要原来的SecondaryNameNode角色,对应的角色有NameNode、DataNode、ZKFC、JournalNode在各个节点分布如下:
安装jdk
同上,各个节点都需要安装jdk
HDFS HA集群搭建
在搭建HDFS HA之前,首先将node1~node5节点上之前搭建的Hadoop集群数据目录和安装文件删除,重新进行搭建,搭建步骤如下。
- 各个节点安装HDFS HA自动切换必须的依赖
在HDFS集群搭建完成后,在Namenode HA切换进行故障转移时采用SSH方式进行,底层会使用到fuster包,有可能我们安装Centos7系统没有fuster程序包,导致不能进行NameNode HA 切换,我们可以通过安装Psmisc包达到安装fuster目的,因为此包中包含了fuster程序,安装方式如下,在各个节点上执行如下命令,安装Psmisc包:
yum -y install psmisc
- 下载安装包并解压
我们安装Hadoop3.3.6版本,此版本目前是比较新的版本,搭建HDFS集群前,首先需要在官网下载安装包,地址如下:https://hadoop.apache.org/releases.html。下载完成安装包后,上传到node1节点的/software目录下并解压,没有此目录,可以先创建此目录。
#将下载好的hadoop安装包上传到node1节点上
[root@node1 ~]# ls /software/
hadoop-3.3.6.tar.gz
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./hadoop-3.3.6.tar.gz
- 在node1节点上配置Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile
- 配置hadoop-env.sh
由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,而Hadoop启动需要读取到JAVA_HOME信息,所有这里需要手动指定。在对应的$HADOOP_HOME/etc/hadoop路径中,找到hadoop-env.sh文件加入以下配置(大概在54行有默认注释配置的JAVA_HOME):
#vim /software/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
- 配置core-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改core-site.xml文件,指定HDFS集群数据访问地址及集群数据存放路径。
#vim /software/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<property>
<!-- 为Hadoop 客户端配置默认的高可用路径 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可
namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name
datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>
- 配置hdfs-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改hdfs-site.xml文件,指定NameNode和JournalNode节点和端口。这里配置NameNode节点为3个。
#vim /software/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 解析参数dfs.nameservices值hdfs://mycluster的地址 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster由以下三个namenode支撑 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>node3:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:9870</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:9870</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>node3:9870</value>
</property>
<!-- namenode高可用代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定三台journal node服务器的地址 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<!-- journalnode 存储数据的地方 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<!--启动NN故障自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 当active nn出现故障时,ssh到对应的服务器,将namenode进程kill掉 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
- 配置workers指定DataNode节点
进入 $HADOOP_HOME/etc/hadoop路径下,修改workers配置文件,加入以下内容:
#vim /software/hadoop-3.3.6/etc/hadoop/workers
node3
node4
node5
- 配置start-dfs.sh&stop-dfs.sh
进入 $HADOOP_HOME/sbin路径下,在start-dfs.sh和stop-dfs.sh文件顶部添加操作HDFS的用户为root,防止启动错误。
#分别在start-dfs.sh 和stop-dfs.sh文件顶部添加如下内容
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
- 分发安装包
将node1节点上配置好的hadoop安装包发送到node2~node5节点上。这里由于Hadoop安装包比较大,也可以先将原有hadoop安装包上传到其他节点解压,然后在node1节点上只分发hfds-site.xml 、core-site.xml文件即可。
#在node1节点上执行如下分发命令
[root@node1 ~]# cd /software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node2:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node3:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node4:/software/
[root@node1 software]# scp -r ./hadoop-3.3.6/ node5:/software/
- 在node2、node3、node4、node5节点上配置HADOOP_HOME
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.6/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile
格式化并启动HDFS集群
HDFS HA 集群搭建完成后,首次使用需要进行格式化。步骤如下:
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start
#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode
#在node1中格式化namenode,只有第一次搭建做,以后不用做
[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2、node3上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby
[root@node3 software]# hdfs namenode -bootstrapStandby
以上格式化集群完成后就可以在NameNode节点上执行如下命令启动集群:
#在node1节点上启动集群
[root@node1 ~]# start-dfs.sh
至此,HDFS HA搭建完成,可以浏览器访问HDFS WebUI界面,通过此界面方便查看和操作HDFS集群。
HDFS基准测试
当搭建好HDFS集群后,我们想要了解集群的读写能力,可以通过HDFS基准测试来获取HDFS集群的读写性能。Hadoop 中自带了读写HDFS基准测试的方式,该基准测试需要基于Yarn提交jar运行,所以这里需要先搭建Yarn集群。
注意:这里搭建Yarn非HA模式进行HDFS基准测试使用,后续课程还会讲解Hadoop Yarn HA集群的搭建,所以建议在搭建集群前拍摄快照,方便后续快照回滚。
搭建Yarn集群
Yarn集群中有ResourceManager和NodeManager角色之分,ResourceManager是集群中的主节点,NodeManager是从节点,NodeManager所在节点默认与DataNode节点相同。
这里搭建的Yarn只有一台ResourceManager,Yarn集群角色分布如下: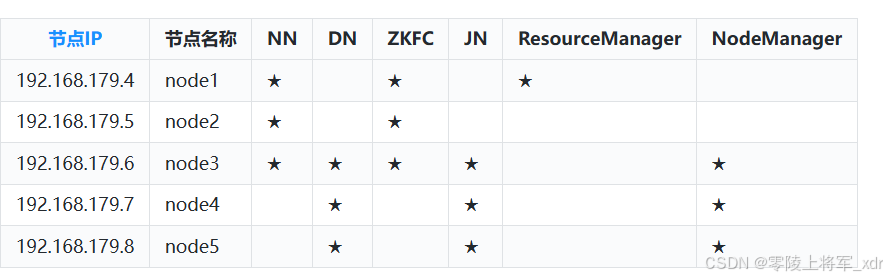
可以按照如下步骤进行Yarn 单ResourceManager角色集群搭建,在现有的HDFS集群配置基础上进行配置即可。
- 配置$HADOOP_HOME/etc/hadoop/core-site.xml
后续为了方便在WebUI中操作HDFS集群,在node1节点上配置$HADOOP_HOME/etc/hadoop/core-site.xml加入如下配置,配置http访问HDFS使用root用户。
<!-- 配置http访问HDFS使用的静态用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
- 配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
在node1节点上配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<!-- MR On yarn 支持数据Shuffle -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- NodeManager 上Container可以继承的环境变量 -->
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置ResourceManager节点 -->
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
- 配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
在node1节点上配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<!-- 指定MapReduce运行时框架为Yarn -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 配置$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh两个文件顶部添加以下参数,防止启动错误
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
- 分发以上配置好的配置文件
将以上node1节点上配置好的yarn-site.xml和mapred-site.xml发送到node2~node5节点上。
[root@node1 ~]# cd $HADOOP_HOME/etc/hadoop
[root@node1 hadoop]# scp ./core-site.xml yarn-site.xml mapred-site.xml node2:`pwd`
[root@node1 hadoop]# scp ./core-site.xml yarn-site.xml mapred-site.xml node3:`pwd`
[root@node1 hadoop]# scp ./core-site.xml yarn-site.xml mapred-site.xml node4:`pwd`
[root@node1 hadoop]# scp ./core-site.xml yarn-site.xml mapred-site.xml node5:`pwd`
将以上node1节点上配置好的start-yarn.sh和stop-yarn.sh发送到node2~node5节点上
[root@node1 ~]# cd $HADOOP_HOME/sbin
[root@node1 sbin]# scp ./start-yarn.sh ./stop-yarn.sh node2:`pwd`
[root@node1 sbin]# scp ./start-yarn.sh ./stop-yarn.sh node3:`pwd`
[root@node1 sbin]# scp ./start-yarn.sh ./stop-yarn.sh node4:`pwd`
[root@node1 sbin]# scp ./start-yarn.sh ./stop-yarn.sh node5:`pwd`
- 启动集群
#node3~node5启动Zookeeper
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
#不启动HDFS集群也可以启动Yarn集群,一般启动Yarn也会启动HDFS集群
[root@node1 ~]# start-dfs.sh
#在node1上启动Yarn集群
[root@node1 ~]# start-yarn.sh
Yarn集群启动成功后,可以访问node1:8088查看Yarn WebUI页面
HDFS基准测试
在运行基准测试之前需要将“junit-xx.jar”放入到提交任务节点的“$HADOOP_HOME/share/hadoop/common”目录下,在执行基准测试时需要使用到该包。
- HDFS基准写测试
在node1节点执行如下命令进行基准写测试:
[root@node1 ~]# hadoop jar /software/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.6-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
以上命令是基于Yarn提交MR 任务向HDFS中写入数据,-nrFiles执行写入的文件数量,-fileSize指定每个写入文件的大小为128M,运行结果如下:
INFO fs.TestDFSIO: ----- TestDFSIO ----- : write INFO fs.TestDFSIO:
Date & time: … INFO fs.TestDFSIO: Number of files: 10
INFO fs.TestDFSIO: Total MBytes processed: 1280 INFO fs.TestDFSIO:
Throughput mb/sec: 6.33 INFO fs.TestDFSIO: Average IO rate mb/sec:
7.73 INFO fs.TestDFSIO: IO rate std deviation: 4.44 INFO fs.TestDFSIO: Test exec time sec: 68.63
以上命令运行后会在HDFS根路径中生成 benchmarks 目录,运行结果参数解释如下:
- Number of files:表示写入的文件个数,也是MapTask个数。
- Total MBytes processed:总共写入HDFS的数据量。
- Throughput mb/sec:每个MapTask 每秒平均吞吐量。
- Average IO rate mb/sec:每个文件的平均每秒IO 速率。
- IO rate std deviation:每个MapTask处理数据速度的方差,越大表示各个MapTask之间性能越不均衡。
- Test exec time sec:测试花费时长。
如果在一台HDFS DataNode上进行任务提交操作,可以看到速度快很多,主要原因是数据上传直接写入本地,经过的网络IO大大减少。
INFO fs.TestDFSIO: Number of files: 10 INFO fs.TestDFSIO:
Total MBytes processed: 1280 INFO fs.TestDFSIO: Throughput
mb/sec: 57.57 INFO fs.TestDFSIO: Average IO rate mb/sec: 59.84 INFO
fs.TestDFSIO: IO rate std deviation: 11.62 INFO fs.TestDFSIO:
Test exec time sec: 25.11
- HDFS基准读测试
在node1节点执行如下命令进行基准读测试(需要先执行写基准测试生成 benchmarks 目录数据):
[root@node1 ~]# hadoop jar /software/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.6-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
以上命令 -nrFiles 读取文件数量,-fileSize指定每个读取文件的大小为128M,运行结果如下:
INFO fs.TestDFSIO: Number of files: 10
INFO fs.TestDFSIO: Total MBytes processed: 1280
INFO fs.TestDFSIO: Throughput mb/sec: 145.01
INFO fs.TestDFSIO: Average IO rate mb/sec: 211.69
INFO fs.TestDFSIO: IO rate std deviation: 161.72
INFO fs.TestDFSIO: Test exec time sec: 41.81
读取数据的速度快于写入数据的主要原因是读取数据时每个task运行到数据所在节点上进行读取处理,相当于是数据本地化读取/写入数据,减少了网络之间数据传递,所以速度快。注意:HDFS 中数据读写和网络、磁盘、节点负载情况都有关系,测试结果可以多次测试获取平均值作为基准测试结果。
HDFS 基准读写测试完成后执行如下命令删除测试数据:
[root@node5 ~]# hdfs dfs -rm -r /benchmarks
HDFS小文件处理
HAR介绍
HDFS中存储小文件时,每个小文件都会对应一个block块,每个block的元数据都会占用NameNode内存,当系统中存储大量小文件时,这些文件的元数据会迅速耗尽NameNode节点的内存资源,从而影响HDFS正常使用,为了解决这个问题,Hadoop Archives(HAR)被引入。
HAR是一种有效的存档工具,能够将多个小文件归档成一个文件,并且在归档后仍然保持了对每个文件的透明访问。通过将文件存储为HDFS块的方式,HDFS存档文件能够降低NameNode内存的使用率,从而减轻了存储大量小文件所带来的压力。
注意:假设小文件数据为1M ,那么会对应到一个block上,但是实际占用磁盘空间是1M ,HAR可以将所有小文件合并归档为一个大的文件,形成少量block存储这些数据,从而减少元数据占用空间。
HAR文件归档
HAR使用语法如下:
$hadoop archive -archiveName name -p <parent> <src>* <dest>
- archiveName :指定要创建的归档文件夹目录的名字,archive的名字扩展名必须是*.har,例如:test.har。
- p:指定要存档文件的父路径,例如:/a/b/c、/a/b/d两个路径下的文件要被归档,那么-p可以指定为/a/b 即:/a/b/c、/a/b/d的父路径,然后再分别指定为c或者d。
- src:指定待归档小文件路径,可以指定多个,空格隔开即可。
- dest:指定归档文件输出路径。
以上HAR命令会转换成MapReduce任务进行文件归档处理,所以需要Yarn环境。按照如下步骤进行文件归档测试。
- 在HDFS中创建/a/b/c 和 /a/b/d 两个路径,并向两个路径中分别创建小文件
#创建路径
[root@node5 ~]# hdfs dfs -mkdir -p /a/b/c
[root@node5 ~]# hdfs dfs -mkdir -p /a/b/d
#向两个路径下写入小文件
[root@node5 ~]# echo 1 > c1.txt
[root@node5 ~]# echo 2 > c2.txt
[root@node5 ~]# echo 3 > c3.txt
[root@node5 ~]# echo 4 > d1.txt
[root@node5 ~]# echo 5 > d2.txt
[root@node5 ~]# echo 6 > d3.txt
#上传小文件到对应路径下
[root@node5 ~]# hdfs dfs -put ./c*.txt /a/b/c
[root@node5 ~]# hdfs dfs -put ./d*.txt /a/b/d
#查看上传的小文件
[root@node5 ~]# hdfs dfs -ls /a/b/c
/a/b/c/c1.txt
/a/b/c/c2.txt
/a/b/c/c3.txt
[root@node5 ~]# hdfs dfs -ls /a/b/d
/a/b/d/d1.txt
/a/b/d/d2.txt
/a/b/d/d3.txt
- 进行小文件归档
#归档 /a/b/c 和 /a/b/d 目录中的小文件到指定目录
[root@node5 ~]# hadoop archive -archiveName test.har -p /a/b c d /archivedir
#查看归档的文件
[root@node5 ~]# hdfs dfs -ls /archivedir/test.har
/archivedir/test.har/_SUCCESS
/archivedir/test.har/_index
/archivedir/test.har/_masterindex
/archivedir/test.har/part-0
以上“_SUCCESS”是标记文件;“_index”和“_masterindex”是索引文件,通过索引文件可以找到对应的原文件;“part-0”是多个原小文件的集合文件。
查询归档文件
可以正常使用HDFS 命令查询归档文件中的数据,如下命令:
#使用 hdfs访问协议访问归档数据
[root@node5 ~]# hdfs dfs -cat /archivedir/test.har/part-0
1
2
3
4
5
6
也可以通过har uri访问协议,访问到数据原来的文件,har uri 访问写法如下:
#schema-hostname格式为hdfs-域名:port
har://schema-hostname:port/archivepath/harfile
如下是通过har uri协议访问har原有文件的命令操作:
#通过har uri访问har文件中打包数据路径及文件信息
[root@node5 ~]# hdfs dfs -ls har://hdfs-node1:8020/archivedir/test.har/
har://hdfs-node1:8020/archivedir/test.har/c
har://hdfs-node1:8020/archivedir/test.har/d
[root@node5 ~]# hdfs dfs -ls har://hdfs-node1:8020/archivedir/test.har/c
har://hdfs-node1:8020/archivedir/test.har/c/c1.txt
har://hdfs-node1:8020/archivedir/test.har/c/c2.txt
har://hdfs-node1:8020/archivedir/test.har/c/c3.txt
[root@node5 ~]# hdfs dfs -ls har://hdfs-node1:8020/archivedir/test.har/d
har://hdfs-node1:8020/archivedir/test.har/d/d1.txt
har://hdfs-node1:8020/archivedir/test.har/d/d2.txt
har://hdfs-node1:8020/archivedir/test.har/d/d3.txt
#通过har uri 访问har文件中的原文件信息
[root@node5 ~]# hdfs dfs -cat har://hdfs-node1:8020/archivedir/test.har/d/d1.txt
注意:har中获取到的原文件信息是根据har中索引文件获取到的,与归档前的源文件目录没有关系。
提取归档文件
可以使用“hdfs dfs -cp ” 来将归档文件提取到新的文件目录中。具体操作如下:
#创建路径
[root@node5 ~]# hdfs dfs -mkdir /newdir
#提取归档文件,这里会将归档的文件按照目录关系提取
[root@node5 ~]# hdfs dfs -cp har://hdfs-node1:8020/archivedir/test.har/* /newdir
#查看提取文件,可以查询到对应的目录和数据文件
[root@node5 ~]# hdfs dfs -ls /newdir
/newdir/c
/newdir/d
HDFS源码
NameNode启动源码
NameNode源码启动类为org.apache.hadoop.hdfs.server.namenode.NameNode,当启动NameNode后会执行该类的main方法,在该类main方法中会创建NameNode对象,代码如下:
public static void main(String argv[]) throws Exception {
... ....
// createNameNode返回NameNode对象
NameNode namenode = createNameNode(argv, null);
... ...
}
在createNameNode方法中实际上最终返回“new NameNode(conf)”对象,在NameNode构造函数中会执行“initialize(…)”方法来进行NameNode启动流程。NameNode构建方法如下:
public NameNode(Configuration conf) throws IOException {
//这里第二个参数为 “NameNode"
this(conf, NamenodeRole.NAMENODE);
}
this调用到2个参数构造:
public NameNode(Configuration conf) throws IOException {
//这里第二个参数为 “NameNode"
this(conf, NamenodeRole.NAMENODE);
}
在initialize方法中NameNode启动主要经过如下4个过程:
- 启动NameNode HttpServer ,方便用户通过http访问HDFS WebUI
- 加载本地fsimage和editslog
- 创建NameNode RpcServer并启动
- 检测集群是否处于安全模式
initialize方法主要代码实现如下:
protected void initialize(Configuration conf) throws IOException {
... ...
//判断是NameNode角色
if (NamenodeRole.NAMENODE == role) {
//1.启动 NameNode httpserver ,用户可以通过http访问WebUI
startHttpServer(conf);
}
//2.加载本地文件中的镜像文件和editslog到内存中
loadNamesystem(conf);
... ...
//3.createRpcServer 创建 NameNodeRpc服务端
rpcServer = createRpcServer(conf);
... ...
//4.启动CommoneService 进行 NameNode资源检查和安全模式检查
startCommonServices(conf);
... ...
}
下面分别对以上过程进行介绍。
启动NameNode HttpServer
startHttpServer方法主要创建HttpServer ,这样用户就可以通过WebUI来访问NameNode。startHttpServer代码如下:
private void startHttpServer(final Configuration conf) throws IOException {
//getHttpServerBindAddress 中绑定了NameNode的IP和端口 9870
httpServer = new NameNodeHttpServer(conf, this, getHttpServerBindAddress(conf));
//启动Http server
httpServer.start();
httpServer.setStartupProgress(startupProgress);
}
getHttpServerBindAddress(conf)中进行了NameNode节点IP和端口9870绑定并返回InetSocketAddress对象,getHttpServerBindAddress(conf)源码如下:
protected InetSocketAddress getHttpServerBindAddress(Configuration conf) {
//getHttpServerAddress 绑定NameNode IP及端口 9870
InetSocketAddress bindAddress = getHttpServerAddress(conf);
// If DFS_NAMENODE_HTTP_BIND_HOST_KEY exists then it overrides the
// host name portion of DFS_NAMENODE_HTTP_ADDRESS_KEY.
//获取 NameNode host主机
final String bindHost = conf.getTrimmed(DFS_NAMENODE_HTTP_BIND_HOST_KEY);
if (bindHost != null && !bindHost.isEmpty()) {
bindAddress = new InetSocketAddress(bindHost, bindAddress.getPort());
}
return bindAddress;
}
以上源码中getHttpServerAddress会绑定节点IP和端口。
在startHttpServer方法中的httpServer.start()方法进行了HttpServer2封装,Hadoop中使用了自己的Httpserver进行Kerberos认证,最后通过HttpServer2.Builder.build()方法创建了hdfs自己的httpserver并调用start方法进行启动。
httpServer.start()具体源码如下:
void start() throws IOException {
... ...
//Hadoop中封装了自己的Httpserver,形成自己的Httpserver2
HttpServer2.Builder builder = DFSUtil.httpServerTemplateForNNAndJN(conf,
httpAddr, httpsAddr, "hdfs",
DFSConfigKeys.DFS_NAMENODE_KERBEROS_INTERNAL_SPNEGO_PRINCIPAL_KEY,
DFSConfigKeys.DFS_NAMENODE_KEYTAB_FILE_KEY);
... ...
//启动 httpServer 服务
httpServer.start();
... ...
}
加载fsimage和editslog
loadNamesystem(conf)中会加载本地fsimage和editslog,具体源码如下:
protected void loadNamesystem(Configuration conf) throws IOException {
//从磁盘中加载editslog和fsimage
this.namesystem = FSNamesystem.loadFromDisk(conf);
}
loadFromDisk源码如下:
static FSNamesystem loadFromDisk(Configuration conf) throws IOException {
... ...
// 封装FSImage对象
FSImage fsImage = new FSImage(conf,
FSNamesystem.getNamespaceDirs(conf),
FSNamesystem.getNamespaceEditsDirs(conf));
//创建 FSNamesystem 对象,并对该对象中fsimage 属性赋值fsimage
FSNamesystem namesystem = new FSNamesystem(conf, fsImage, false);
... ...
//加载fsImage
namesystem.loadFSImage(startOpt);
.... ...
}
创建NameNode RpcServer并启动
创建NameNode RpcServer的代码如下:
rpcServer = createRpcServer(conf);
//3.createRpcServer 创建 NameNodeRpc服务端和客户端
rpcServer = createRpcServer(conf);
createRpcServer源码如下:
protected NameNodeRpcServer createRpcServer(Configuration conf)
throws IOException {
return new NameNodeRpcServer(conf, this);
}
在“new NameNodeRpcServer(conf, this)”创建nameNodeRpcServer对象中会创建NameNode作为Rpc 服务端和客户端的RpcServer,具体源码如下:
public NameNodeRpcServer(Configuration conf, NameNode nn)
throws IOException {
... ...
serviceRpcServer = new RPC.Builder(conf)
.setProtocol(
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class)
.setInstance(clientNNPbService)
.setBindAddress(bindHost)
.setPort(serviceRpcAddr.getPort())
.setNumHandlers(serviceHandlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager())
.build();
... ..
clientRpcServer = new RPC.Builder(conf)
.setProtocol(
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class)
.setInstance(clientNNPbService)
.setBindAddress(bindHost)
.setPort(rpcAddr.getPort())
.setNumHandlers(handlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager())
.setAlignmentContext(stateIdContext)
.build();
... ...
}
关于NameNode serviceRpcServer和clientRpcServer的启动在后续NameNode资源检测后启动。
检测集群是否处于安全模式
经过前面3个步骤后,会执行如下代码进行资源检查和安全模式检查:
//4.启动CommoneService 进行 NameNode资源检查和安全模式检查
startCommonServices(conf);
startCommonServices方法实现如下:
private void startCommonServices(Configuration conf) throws IOException {
... ...
//启动服务 检测磁盘空间和安全模式
namesystem.startCommonServices(conf, haContext);
... ...
//这里启动的是NameNode RpcServer,会启动Name 作为客户端的clientRpcServer 和作为服务端的serviceRpcServer
rpcServer.start();
... ...
}
以上namesystem.startCommonServices(conf, haContext);主要负责磁盘空间和安全模式检测;rpcServer.start();主要进行NameNode serviceRpcServer和clientRpcServer的启动。
startCommonServices(conf, haContext)方法具体源码如下:
void startCommonServices(Configuration conf, HAContext haContext) throws IOException {
... ...
//nnResourceChecker 对象用于后续检查editslog 目录空间是否足够
nnResourceChecker = new NameNodeResourceChecker(conf);
//检查是否有足够磁盘空间存储数据
checkAvailableResources();
assert !blockManager.isPopulatingReplQueues();
StartupProgress prog = NameNode.getStartupProgress();
//开始进入安全模式
prog.beginPhase(Phase.SAFEMODE);
//获取所有可用的block
long completeBlocksTotal = getCompleteBlocksTotal();
//设置安全模式
prog.setTotal(Phase.SAFEMODE, STEP_AWAITING_REPORTED_BLOCKS,
completeBlocksTotal);
//启动块服务并对DataNode 心跳超时进行判断
blockManager.activate(conf, completeBlocksTotal);
... ...
}
以上代码中nnResourceChecker = new NameNodeResourceChecker(conf);中会设置磁盘空间最小阈值100M,然后执行checkAvailableResources();方法进行检查节点磁盘空间是充足,具体代码如下:
new NameNodeResourceChecker(conf)源码:
public NameNodeResourceChecker(Configuration conf) throws IOException {
... ...
// duReserved 默认为100M
duReserved = conf.getLongBytes(DFSConfigKeys.DFS_NAMENODE_DU_RESERVED_KEY,
DFSConfigKeys.DFS_NAMENODE_DU_RESERVED_DEFAULT);
... ...
}
checkAvailableResources()源码如下:
void checkAvailableResources() {
... ...
//判断磁盘资源是否够用
hasResourcesAvailable = nnResourceChecker.hasAvailableDiskSpace();
... ...
}
其中以上hasAvailableDiskSpace方法实现如下:
public boolean hasAvailableDiskSpace() {
return NameNodeResourcePolicy.areResourcesAvailable(volumes.values(),
minimumRedundantVolumes);
}
该方法如果返回true表示至少有一个配置的磁盘空间满足使用。方法中areResourcesAvailable实现源码如下:
static boolean areResourcesAvailable(
Collection<? extends CheckableNameNodeResource> resources,
int minimumRedundantResources) {
... ...
//检查资源是否充足
for (CheckableNameNodeResource resource : resources) {
if (!resource.isRequired()) {
redundantResourceCount++;
// isResourceAvailable 实现类为 NameNodeResourceChecker.CheckedVolume中的isResourceAvailable 方法
if (!resource.isResourceAvailable()) {
disabledRedundantResourceCount++;
}
} else {
requiredResourceCount++;
if (!resource.isResourceAvailable()) {
// Short circuit - a required resource is not available.
return false;
}
}
}
... ...
}
其中resource.isResourceAvailable()中判断磁盘是否满足最低的100M,返回true表示满足,返回false表示不满足。isResourceAvailable()实现类是NameNodeResourceChecker.CheckedVolume中的isResourceAvailable方法,该方法中进行磁盘空间判断是否满足最低100M,具体判断源码如下:
public boolean isResourceAvailable() {
... ...
//如果磁盘空间小于100M 返回fasle
if (availableSpace < duReserved) {
LOG.warn("Space available on volume '" + volume + "' is "
+ availableSpace +
", which is below the configured reserved amount " + duReserved);
return false;
} else {
return true;
}
... ...
}
检测完磁盘可用空间后,进入安全模式,并进行可用block的检测,进而判断是否退出NameNode安全模式,具体源码在FSNmaesystem.startCommonServices中,如下:
... ...
//开始进入安全模式
prog.beginPhase(Phase.SAFEMODE);
//获取所有可用的block
long completeBlocksTotal = getCompleteBlocksTotal();
//设置安全模式
prog.setTotal(Phase.SAFEMODE, STEP_AWAITING_REPORTED_BLOCKS,
completeBlocksTotal);
//检测DataNode状态及是否退出安全模式
blockManager.activate(conf, completeBlocksTotal);
... ...
以上代码中“blockManager.activate(conf, completeBlocksTotal);”进行block块检测,查看正常可用block数是否满足总block的99.9% 可用,active(conf,completeBlocksTotal)具体源码如下:
public void activate(Configuration conf, long blockTotal) {
... ...
//datanodeManager对象对周期检查DataNode连接情况
datanodeManager.activate(conf);
... ...
//检测 正常 block 情况
bmSafeMode.activate(blockTotal);
... ...
}
datanodeManager.activate(conf)主要进行DataNode节点是否宕机,默认经过10分钟+30s一个DataNode没有向NameNode汇报心跳信息,则该DataNode宕机。datanodeManager.activate(conf)实现源码如下:
void activate(final Configuration conf) {
datanodeAdminManager.activate(conf);
//与DataNode心跳检测
heartbeatManager.activate();
}
heartbeatManager.activate()中activate方法最终调用到Monitor线程的run方法进行DataNode状态监测。
bmSafeMode.activate(blockTotal)进行是否退出安全模式检车,实现源码如下:
void activate(long total) {
... ...
//设置正常可用block,并设置正常退出安全模式阈值为0.999f
setBlockTotal(total);
if (areThresholdsMet()) {//判断是否可以退出安全模式,block和datanode阈值都满足退出
boolean exitResult = leaveSafeMode(false);
Preconditions.checkState(exitResult, "Failed to leave safe mode.");
} else {//进入安全模式
// enter safe mode
status = BMSafeModeStatus.PENDING_THRESHOLD;
initializeReplQueuesIfNecessary();
reportStatus("STATE* Safe mode ON.", true);
lastStatusReport = monotonicNow();
}
... ...
}
其中“setBlockTotal(total);”设置正常可用block的阈值,“areThresholdsMet()”进行可用block是否满足阈值,areThresholdsMet()实现如下:
private boolean areThresholdsMet() {
//如果block和datanode阈值都满足,则为True,否则返回false
... ...
synchronized (this) {
boolean isBlockThresholdMet = (blockSafe >= blockThreshold);
boolean isDatanodeThresholdMet = true;
if (isBlockThresholdMet && datanodeThreshold > 0) {
int datanodeNum = blockManager.getDatanodeManager().
getNumLiveDataNodes();
isDatanodeThresholdMet = (datanodeNum >= datanodeThreshold);
}
return isBlockThresholdMet && isDatanodeThresholdMet;
}
}
DataNode启动源码
DataNode启动源码类为org.apache.hadoop.hdfs.server.datanode.DataNode,该类main方法如下:
public static void secureMain(String args[], SecureResources resources) {
... ...
DataNode datanode = createDataNode(args, null, resources);
... ...
}
createDataNode(args, null, resources)实现如下:
public static void secureMain(String args[], SecureResources resources) {
... ...
DataNode datanode = createDataNode(args, null, resources);
... ...
}
以上代码中instantiateDataNode创建返回了DataNode对象,并在创建DataNode的构造中初始化DataXceiver服务、HttpServer服务、DataNode PRC 服务及向NameNode注册并进行心跳汇报,然后再通过“dn.runDatanodeDaemon();”方法启动DataXceiver服务和DataXceiver服务用于接收客户端写数据和通信。
instantiateDataNode(args, conf, resources);实现代码如下:
public static DataNode instantiateDataNode(String args [], Configuration conf,
SecureResources resources) throws IOException {
... ...
//根据配置获取DataNode 数据存储位置
Collection<StorageLocation> dataLocations = getStorageLocations(conf);
... ...
//创建返回DataNode 对象
return makeInstance(dataLocations, conf, resources);
}
makeInstance方法会携带DataNode 数据存储位置创建DataNode对象。makeInstance源码如下:
static DataNode makeInstance(Collection<StorageLocation> dataDirs,
Configuration conf, SecureResources resources) throws IOException {
... ...
//检查数据目录可用
locations = storageLocationChecker.check(conf, dataDirs);
... ...
//至少配置的一个数据目录可用就返回创建DataNode
return new DataNode(conf, locations, storageLocationChecker, resources);
}
在DataNode 对象的构造中执行了startDataNode方法初始化各种服务及向NameNode注册信息。进入DataNode构造可以看到startDataNode方法:
DataNode(final Configuration conf,
final List<StorageLocation> dataDirs,
final StorageLocationChecker storageLocationChecker,
final SecureResources resources) throws IOException {
... ...
//startDataNode中初始化各种服务及向NameNode 注册信息及保持心跳
startDataNode(dataDirs, resources);
... ...
}
在StartDataNode方法中主要做了如下4个流程:
- 初始化DataXceiver服务,该服务是Datanode接手客户端请求的核心组件。
- 创建HttpServer并启动,方便用户通过WebUI访问DataNode。
- 初始化DataNode Rpc 服务端
- 获取NameNode RpcProxy代理
- DataNode向NameNode注册
- DataNode与NameNode周期心跳和block块汇报
详细源码如下:
void startDataNode(List<StorageLocation> dataDirectories,
SecureResources resources
) throws IOException {
... ...
//1.初始化DataXceiver服务,该服务是 DataNode 接收客户端请求的核心组件
initDataXceiver();
//2.创建HttpServer 并启动,用户可以通过WebUI访问
startInfoServer();
... ...
//3.初始化DataNode PRC 服务端,创建的IPC Server在DataNode对象创建完成后启动
initIpcServer();
... ...
//4.DataNode 向 每个 NameNode 注册并进行周期心跳汇报(5)
blockPoolManager.refreshNamenodes(getConf());
... ...
}
DataXceiver服务在数据上传部分讲解,下面结合源码介绍其他五个流程。
创建HttpServer
startInfoServer()主要创建httpServer并启动,该服务启动后用户可以通过WebUi访问DataNode。源码如下:
private void startInfoServer()
throws IOException {
... ...
httpServer = new DatanodeHttpServer(getConf(), this, httpServerChannel);
httpServer.start();
... ...
}
其中DatanodeHttpServer构造如下:
public DatanodeHttpServer(final Configuration conf,
final DataNode datanode,
final ServerSocketChannel externalHttpChannel)
throws IOException {
... ...
//hostName方法中设置了hostname和ip 9870
HttpServer2.Builder builder = new HttpServer2.Builder()
.setName("datanode")
.setConf(confForInfoServer)
.setACL(new AccessControlList(conf.get(DFS_ADMIN, " ")))
//设置节点和端口
.hostName(getHostnameForSpnegoPrincipal(confForInfoServer))
.addEndpoint(URI.create("http://localhost:" + proxyPort))
.setFindPort(true);
.... ...
this.infoServer = builder.build();
... ...
this.infoServer.start();
... ...
}
初始化DataNode Rpc服务
initIpcServer()方法中进行DataNode Rpc 服务端的初始化,代码如下:
private void initIpcServer() throws IOException {
InetSocketAddress ipcAddr = NetUtils.createSocketAddr(
... ...
ipcServer = new RPC.Builder(getConf())
.setProtocol(ClientDatanodeProtocolPB.class)
.setInstance(service)
.setBindAddress(ipcAddr.getHostName())
.setPort(ipcAddr.getPort())
.setNumHandlers(
getConf().getInt(DFS_DATANODE_HANDLER_COUNT_KEY,
DFS_DATANODE_HANDLER_COUNT_DEFAULT)).setVerbose(false)
.setSecretManager(blockPoolTokenSecretManager).build();
... ...
}
关于 ipcServer 的启动是在DataNode对象创建完成后,执行“dn.runDatanodeDaemon()”方法中执行的。具体源码位于DataNode.createDataNode方法中:
public static DataNode createDataNode(String args[], Configuration conf,
SecureResources resources) throws IOException {
//创建DataNode对象,并准备必要的DataNode RPC Server对象
DataNode dn = instantiateDataNode(args, conf, resources);
if (dn != null) {
//启动dataXceiverServer 和 ipcServer 服务
dn.runDatanodeDaemon();
}
return dn;
}
获取NameNode Rpc代理
startDataNode中的“blockPoolManager.refreshNamenodes(getConf())”代码主要负责DataNode向每个NameNode注册并进行心跳汇报,refreshNamenodes实现源码如下:
void refreshNamenodes(Configuration conf)
throws IOException {
... ...
//获取所有NameNode地址
newAddressMap =
DFSUtil.getNNServiceRpcAddressesForCluster(conf);
//从 dfs.namenode.lifeline.rpc-address 属性中获取地址,用于 DataNode 向 NameNode 发送心跳和块汇报等信息,默认该属性为空。
newLifelineAddressMap =
DFSUtil.getNNLifelineRpcAddressesForCluster(conf);
... ...
//以上是获取到NameNode通信地址,然后向每个NameNode注册
doRefreshNamenodes(newAddressMap, newLifelineAddressMap);
//以上是获取到NameNode通信地址,然后向每个NameNode注册
doRefreshNamenodes(newAddressMap, newLifelineAddressMap);
}
以上代码中,newAddressMap是获取所有NameNode节点地址,newLifelineAddressMap是从dfs.namenode.lifeline.rpc-address 配置属性中获取地址,默认该属性没有配置。newLifelineAddressMap如果配置了,该获取的地址主要用于DataNode向NameNode发送心跳和block块汇报。
最后执行“doRefreshNamenodes”方法,向每个NameNode节点通信并进行注册。doRefreshNamenodes源码如下:
private void doRefreshNamenodes(
Map<String, Map<String, InetSocketAddress>> addrMap,
Map<String, Map<String, InetSocketAddress>> lifelineAddrMap)
throws IOException {
... ...
//返回 BPOfferService 对象,该对象中bpServices 中包含于所有 NameNode通信的BPServiceActor对象
BPOfferService bpos = createBPOS(nsToAdd, nnIds, addrs,
lifelineAddrs);
... ...
offerServices.add(bpos);
.... ...
//遍历 offerServices,启动服务
startAll();
}
以上代码中,createBPOS方法返回 BPOfferService 对象,该对象中bpServices 中包含于所有 NameNode通信的BPServiceActor对象。createBPOS方法如下:
protected BPOfferService createBPOS(
final String nameserviceId,
List<String> nnIds,
List<InetSocketAddress> nnAddrs,
List<InetSocketAddress> lifelineNnAddrs) {
//返回 BPOfferService 对象,该对象中bpServices 中包含于所有 NameNode通信的BPServiceActor对象
return new BPOfferService(nameserviceId, nnIds, nnAddrs, lifelineNnAddrs,
dn);
}
“new BPOfferService”中进行每个NameNode的遍历,并将负责与NameNode通信的BPServiceActor对象加入到BPOfferService.bpServices这个集合中。new BPOfferService实现如下:
BPOfferService(
final String nameserviceId, List<String> nnIds,
List<InetSocketAddress> nnAddrs,
List<InetSocketAddress> lifelineNnAddrs,
DataNode dn) {
... ...
for (int i = 0; i < nnAddrs.size(); ++i) {
// BPServiceActor 负责 与NameNode 通信:发送心跳到NameNode
this.bpServices.add(new BPServiceActor(nameserviceId, nnIds.get(i),
nnAddrs.get(i), lifelineNnAddrs.get(i), this));
}
... ...
}
注意:BPServiceActor是一个线程,后续会执行相关的run方法,并且在new BPServiceActor对象时,会初始化Scheduler对象,该对象会周期性向NameNode汇报DataNode心跳信息,new BPServiceActor实现源码如下:
class BPServiceActor implements Runnable {
... ...
BPServiceActor(String serviceId, String nnId, InetSocketAddress nnAddr,
InetSocketAddress lifelineNnAddr, BPOfferService bpos) {
... ...
//创建 scheduler 对象,该scheduler对象负责后续周期向NameNode汇报心跳
//传递第一个参数默认为dfs.heartbeat.interval 参数为3s
scheduler = new Scheduler(dnConf.heartBeatInterval,
dnConf.getLifelineIntervalMs(), dnConf.blockReportInterval,
dnConf.outliersReportIntervalMs);
... ...
)
以上代码中scheduler对象负责后续周期向NameNode汇报心跳,默认3秒。
回到doRefreshNamenodes方法的startAll()方法,在该方法中可以看到遍历offerServices中的BPOfferService对象并调用对应的start方法,在start方法中会循环遍历bpServices中的每个BPServiceActor进行启动。具体源码如下:
startAll()方法如下:
synchronized void startAll() throws IOException {
... ...
for (BPOfferService bpos : offerServices) {
bpos.start();
}
... ...
}
以上bpos.start()方法源码如下:
void start() {
for (BPServiceActor actor : bpServices) {
//BPServiceActor 是一个线程,调用run 方法
actor.start();
}
}
当调用BPServiceActor 对象的start方法时,由于BPServiceActor 是一个线程所以会执行到对应的BPServiceActor.run方法,在该run方法中进行连接NameNode注册并与NameNode保持心跳。BPServiceActor.run方法源码如下:
public void run() {
... ...
//获取NameNode RpcProxy 并连接NameNode进行信息注册
connectToNNAndHandshake();
... ...
//DataNode 与NameNode 保持心跳
offerService();
... ...
}
connectToNNAndHandshake()方法的具体实现如下:
private void connectToNNAndHandshake() throws IOException {
... ...
//连接NameNode ,返回bpNamenode为DatanodeProtocolClientSideTranslatorPB对象,该对象中有NameNode Rpc代理
bpNamenode = dn.connectToNN(nnAddr);
//第一步:获取NameNode管理的命名空间,一个集群中可能存在多个NS
NamespaceInfo nsInfo = retrieveNamespaceInfo();
//第二步:向NameNode进行注册
register(nsInfo);
}
以上代码中:“bpNamenode = dn.connectToNN(nnAddr)”连接NameNode ,返回bpNamenode为DatanodeProtocolClientSideTranslatorPB对象,该对象中有NameNode Rpc代理,通过NameNode Rpc代理可以远程调用NameNode的方法。ConnectToNN源码实现如下:
DatanodeProtocolClientSideTranslatorPB connectToNN(
InetSocketAddress nnAddr) throws IOException {
return new DatanodeProtocolClientSideTranslatorPB(nnAddr, getConf());
}
DatanodeProtocolClientSideTranslatorPB的构造中创建了NameNode rpcProxy代理对象:
public DatanodeProtocolClientSideTranslatorPB(InetSocketAddress nameNodeAddr,
Configuration conf) throws IOException {
RPC.setProtocolEngine(conf, DatanodeProtocolPB.class,
ProtobufRpcEngine2.class);
UserGroupInformation ugi = UserGroupInformation.getCurrentUser();
//获取NameNode远程代理对象,
rpcProxy = createNamenode(nameNodeAddr, conf, ugi);
}
以上代码的“createNamenode”中获取NameNode 远程代理对象源码如下:
private static DatanodeProtocolPB createNamenode(
InetSocketAddress nameNodeAddr, Configuration conf,
UserGroupInformation ugi) throws IOException {
//这里返回了 RpcProtocol 对象为DatanodeProtocolPB,该对象表示获取到NameNode远程通信代理对象,DataNode与NameNode通信远程调用方法都在DatanodeProtocolPB 接口中
return RPC.getProxy(DatanodeProtocolPB.class,
RPC.getProtocolVersion(DatanodeProtocolPB.class), nameNodeAddr, ugi,
conf, NetUtils.getSocketFactory(conf, DatanodeProtocolPB.class));
}
可以看到该代码中RPC.getProxy(…)传入的第一个参数是DatanodeProtocolPB.class,表示远程调用NameNode所有方法的接口就是此接口,进入DatanodeProtocolPB.class可以看到有@ProtocolInfo注解:
@ProtocolInfo(
protocolName = "org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol",
protocolVersion = 1)
@InterfaceAudience.Private
public interface DatanodeProtocolPB extends
DatanodeProtocolService.BlockingInterface {
}
以上代码中,@ProtocolInfo注解指定协议的相关信息,protocolName参数指定了协议的名称,protocolVersion参数指定了协议的版本号。指定的 org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol 是一个Java接口,定义了用于DataNode与NameNode之间通信的协议。通常,它定义了一系列方法,这些方法由DataNode实现,用于与NameNode进行通信和执行各种操作。DatanodeProtocolPB也是一个java接口,它实际上是 DatanodeProtocol 接口的一种实现方式。
综上所述,后面通过获取到的NameNode RpcProxy代理对象进行远程调用NameNode相应方法时实际上会找到DatanodeProtocol 接口的实现类,通过查询源码可以看到NameNodeRpcServer类实现了DatanodeProtocol 接口:
public class NameNodeRpcServer implements NamenodeProtocols {
...
}
... ...
public interface NamenodeProtocols
extends ClientProtocol,
DatanodeProtocol,
DatanodeLifelineProtocol,
NamenodeProtocol,
RefreshAuthorizationPolicyProtocol,
ReconfigurationProtocol,
RefreshUserMappingsProtocol,
RefreshCallQueueProtocol,
GenericRefreshProtocol,
GetUserMappingsProtocol,
HAServiceProtocol {
}
所以,当在DataNode端通过NameNode的RpcProxy 远程调用到NameNode相应方法时,会调用到 NameNodeRpcServer 类中相应的实现方法。
Datanode向NameNode注册
继续回到BPSercviceActor.connectToNNAndHandshake方法中,源码如下:
private void connectToNNAndHandshake() throws IOException {
... ...
//连接NameNode ,返回bpNamenode为DatanodeProtocolClientSideTranslatorPB对象,该对象中有NameNode Rpc代理
bpNamenode = dn.connectToNN(nnAddr);
//第一步:获取NameNode管理的命名空间,一个集群中可能存在多个NS
NamespaceInfo nsInfo = retrieveNamespaceInfo();
//第二步:向NameNode进行注册
register(nsInfo);
}
“register(nsInfo)”方法实现DataNode向NameNode进行注册。源码实现如下:
void register(NamespaceInfo nsInfo) throws IOException {
... ...
//准备注册DataNode的信息对象:DatanodeRegistration
DatanodeRegistration newBpRegistration = bpos.createRegistration();
... ...
//向NameNode 注册DataNode,调用的registerDatanode 方法位于 NameNodeRpcServer.java 类中
newBpRegistration = bpNamenode.registerDatanode(newBpRegistration);
... ...
}
“bpNamenode.registerDatanode”的实现如下:
public DatanodeRegistration registerDatanode(DatanodeRegistration registration
) throws IOException {
... ...
//rpcProxy是NameNode远程代理,调用 registerDatanode 方法在
resp = rpcProxy.registerDatanode(NULL_CONTROLLER, builder.build());
... ...
}
以上代码中 “rpcProxy”对象是NameNode远程代理,调用的registerDatanode 方法位于 NameNodeRpcServer.java 类中。
NameNodeRpcServer类中的registerDatanode方法实现源码如下:
//DataNode向NameNode 进行注册
@Override // DatanodeProtocol
public DatanodeRegistration registerDatanode(DatanodeRegistration nodeReg)
throws IOException {
checkNNStartup();
verifySoftwareVersion(nodeReg);
namesystem.registerDatanode(nodeReg);
return nodeReg;
}
以上代码中“namesystem.registerDatanode(nodeReg);”实现如下:
void registerDatanode(DatanodeRegistration nodeReg) throws IOException {
writeLock();
try {
blockManager.registerDatanode(nodeReg);
} finally {
writeUnlock("registerDatanode");
}
}
“blockManager.registerDatanode(nodeReg);”实现源码如下:
public void registerDatanode(DatanodeRegistration nodeReg)
throws IOException {
assert namesystem.hasWriteLock();
datanodeManager.registerDatanode(nodeReg);
bmSafeMode.checkSafeMode();
}
以上代码中“registerDatanode”方法中实现了DataNode向NameNode注册:
public void registerDatanode(DatanodeRegistration nodeReg)
throws DisallowedDatanodeException, UnresolvedTopologyException {
... ...
String hostname = dnAddress.getHostName();//获取DataNode hostname
String ip = dnAddress.getHostAddress();//获取DataNode ip
... ...
nodeReg.setIpAddr(ip);
nodeReg.setPeerHostName(hostname);
... ...
//创建DataNode Description
DatanodeDescriptor nodeDescr
= new DatanodeDescriptor(nodeReg, NetworkTopology.DEFAULT_RACK);
... ...
// register new datanode
addDatanode(nodeDescr);//注册新的DataNode
... ...
//注册也看成一次心跳检测
heartbeatManager.addDatanode(nodeDescr);
... ...
}
以上addDatanode实现如下:
void addDatanode(final DatanodeDescriptor node) {
... ...
synchronized(this) {
//host2DatanodeMap 存储了主机名(host)与数据节点之间的映射关系
//datanodeMap 存储了数据节点(DataNode)的 UUID 与对应的 DatanodeDescriptor 对象之间的映射关系
//将DataNode 加入到 datanodeMap,如果先前有该DataNode节点信息那么先从host2DatanodeMap中移除,后续重新再加入正确节点映射信息
host2DatanodeMap.remove(datanodeMap.put(node.getDatanodeUuid(), node));
}
... ...
}
“datanodeMap.put(node.getDatanodeUuid(), node)”代码就是将DataNode信息加入到dataNodeMap对象中完成DataNode向NameNode注册。
host2DatanodeMap 存储了主机名(host)与数据节点之间的映射关系,而host2DatanodeMap.remove(datanodeMap.put(node.getDatanodeUuid(), node)),表示如果先前host2DatanodeMap中已有对应的DataNode信息,先从host2DatanodeMap中移除,后续再重新加入到host2DatanodeMap中。
DataNode与NameNode周期心跳及block块汇报
回到BpServiceActor中run方法中,除了连接NameNode向DataNode进行注册外,后续还会周期性向NameNode进行心跳和block块汇报。run方法实现如下:
public void run() {
... ...
//获取NameNode RpcProxy 并连接NameNode进行信息注册
connectToNNAndHandshake();
... ...
//DataNode 与NameNode 保持心跳
offerService();
... ...
}
offerService实现代码如下:
private void offerService() throws Exception {
... ...
//判断是否应该进行心跳,默认周期3秒
final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);
... ...
//向NameNode发送心跳信息
resp = sendHeartBeat(requestBlockReportLease);
... ...
}
以上“final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);”代码中会看到每隔3秒进行一次心跳信息汇报。
sendHeartBeat实现源码如下:
HeartbeatResponse sendHeartBeat(boolean requestBlockReportLease)
throws IOException {
... ...
//进行下次心跳时间设置,设置的值为当前时间加上3s
scheduler.scheduleNextHeartbeat();
... ...
//DataNode向NameNode 发送心跳汇报block信息,sendHeartbeat方法
HeartbeatResponse response = bpNamenode.sendHeartbeat(bpRegistration,
reports,
dn.getFSDataset().getCacheCapacity(),
dn.getFSDataset().getCacheUsed(),
dn.getXmitsInProgress(),
dn.getActiveTransferThreadCount(),
numFailedVolumes,
volumeFailureSummary,
requestBlockReportLease,
slowPeers,
slowDisks);
... ...
“scheduler.scheduleNextHeartbeat();”设置下次进行心跳的时间。
bpNamenode.sendHeartbeat(…)最终调用到NameNodeRpcServer中的sendHeartbeat方法进行block块上报。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)