简单的大模型基础知识入门+名词解释
读了一些深度/强化学习的书籍,对具体大语言的实现感兴趣了,记录一些笔记
推荐可以阅读这本书:Hello-Agents,本文中的一些图例就是用这上面的
目录
基础概念/名词
LLM是啥
他是一种基于大规模参数和大规模语料训练得到的语言建模系统,它通过对 token 序列进行条件概率建模,来理解、续写或生成文本 , 通常采用Transformer架构
LLM训练全景图
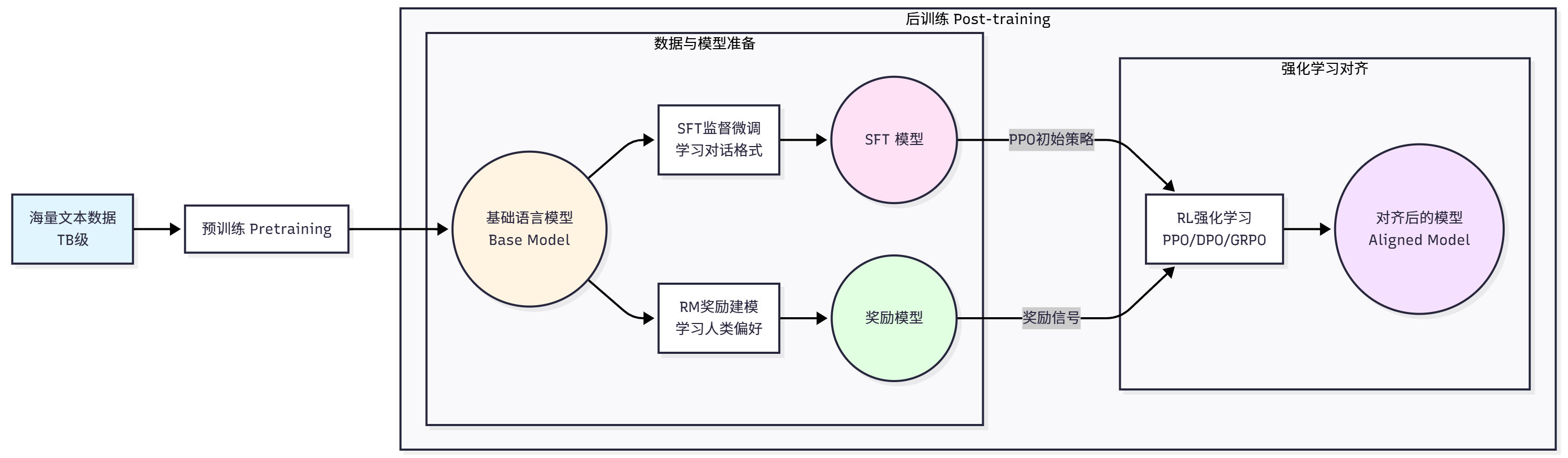
预训练阶段是 LLM 训练的第一阶段,目标是让模型学习语言的基本规律和世界知识。这个阶段使用海量的文本数据(通常是数 TB 级别),通过自监督学习的方式训练模型。最常见的预训练任务是因果语言建模(Causal Language Modeling),也称为下一个词预测(Next Token Prediction), 预训练阶段的特点是数据量巨大、计算成本高、学到的是通用的语言理解和生成能力、采用无监督学习
后训练阶段则是要解决预训练模型的不足。预训练后的模型虽然具备了强大的语言能力,但它只是一个"预测下一个词"的模型,并不知道如何遵循人类的指令、生成有帮助无害诚实的回答、拒绝不当的请求,以及以对话的方式与人交互。后训练阶段就是要解决这些问题,让模型对齐人类的偏好和价值观
大概的生成流程
用户输入构成 prompt,并与历史对话共同形成 context。文本经过 tokenization 转为 token 序列,再通过 embedding 与位置信息编码成向量表示,送入多层 Transformer。模型通过 masked self-attention、MLP、残差连接和层归一化逐层计算 hidden states,最终输出词表上的 logits,经 softmax 得到下一 token 的概率分布,再通过 decoding 策略选出实际 token。该 token 被追加回上下文,模型以自回归方式重复这一过程,直到输出 EOS 或达到长度限制
- Prompt:送给模型的输入文本
- Context:当前可参考的全部前文
- Tokenization:把文本切成 token
- Token:模型处理的最小离散文本单位
- Vocabulary:所有可识别 token 的集合(每个token对应哪个ID)
- Embedding:把 token 变成向量
- Positional Encoding:告诉模型顺序(位置信息)
- Transformer:核心计算架构
- Self-Attention:决定该关注上下文哪里
- Logits:对下一个 token 的原始打分
- Softmax:把打分变成概率
- Decoding:从概率里选出实际输出
文本生成
从前面的学习,我们可以知道
现代大语言模型的基础是 2017 年由 Google 提出的 Transformer 架构。这一架构从根本上改变了自然语言处理的方式,使得模型能够高效地处理长序列文本。
Transformer 的核心创新是自注意力机制(Self-Attention),它允许模型在处理每个词元时,同时“关注”序列中的所有其他词元,从而捕捉长距离的语义依赖关系
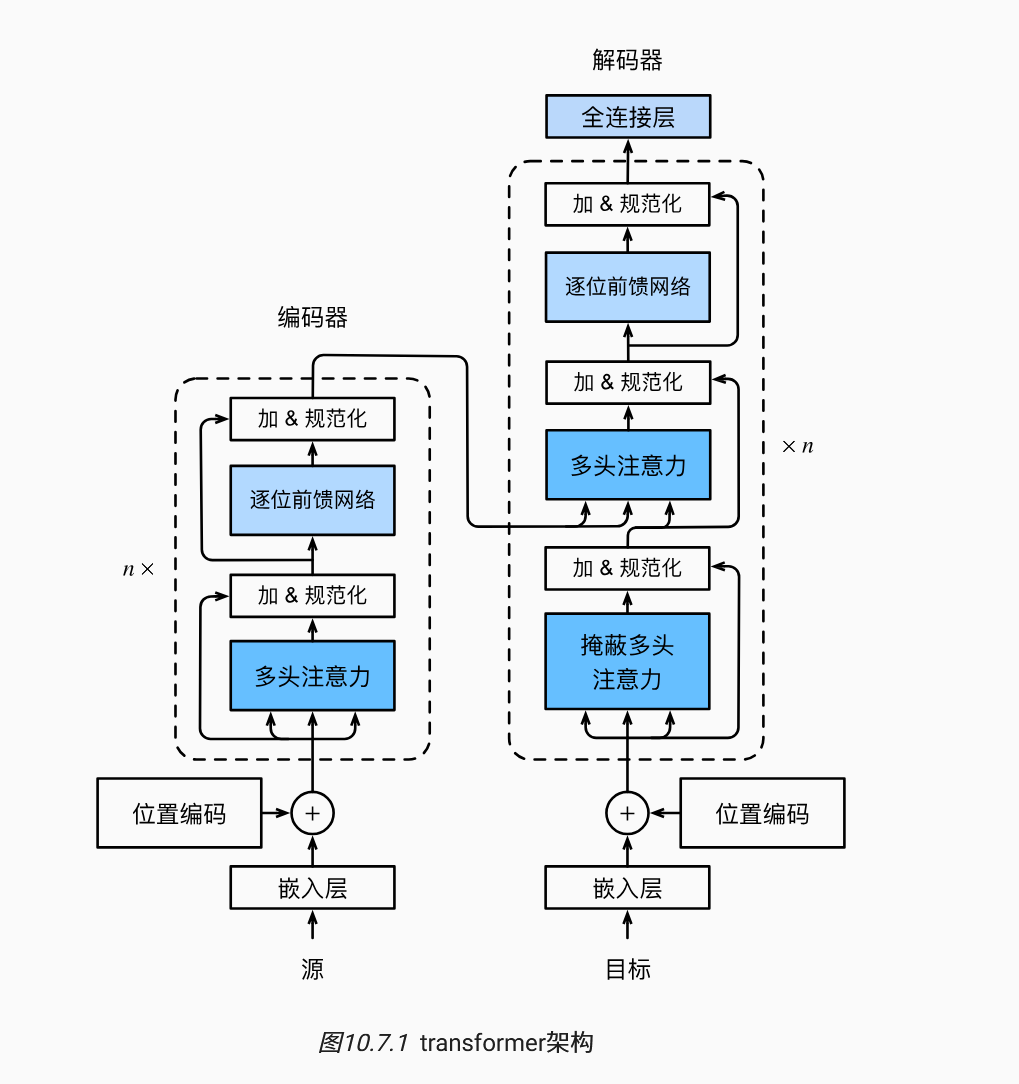
(有些地方我认为不是很恰当,比如说"加&规范化"我觉得翻译成"残差+归一化"好一点)
现在的大语言模型大多采用自回归(Autoregressive)方式生成文本,即 逐个预测下一个 Token,每次预测都基于之前所有的 Token , 简言之,模型将生成整个序列的概率分解为:每个 Token 出现的概率,条件是之前所有 Token 都已知。
这意味着:
- 模型需要“记住”之前的所有内容才能正确预测下一个 Token
- 序列越长,需要维护的“记忆”就越多
- 这种记忆就体现在上下文窗口中
transformer
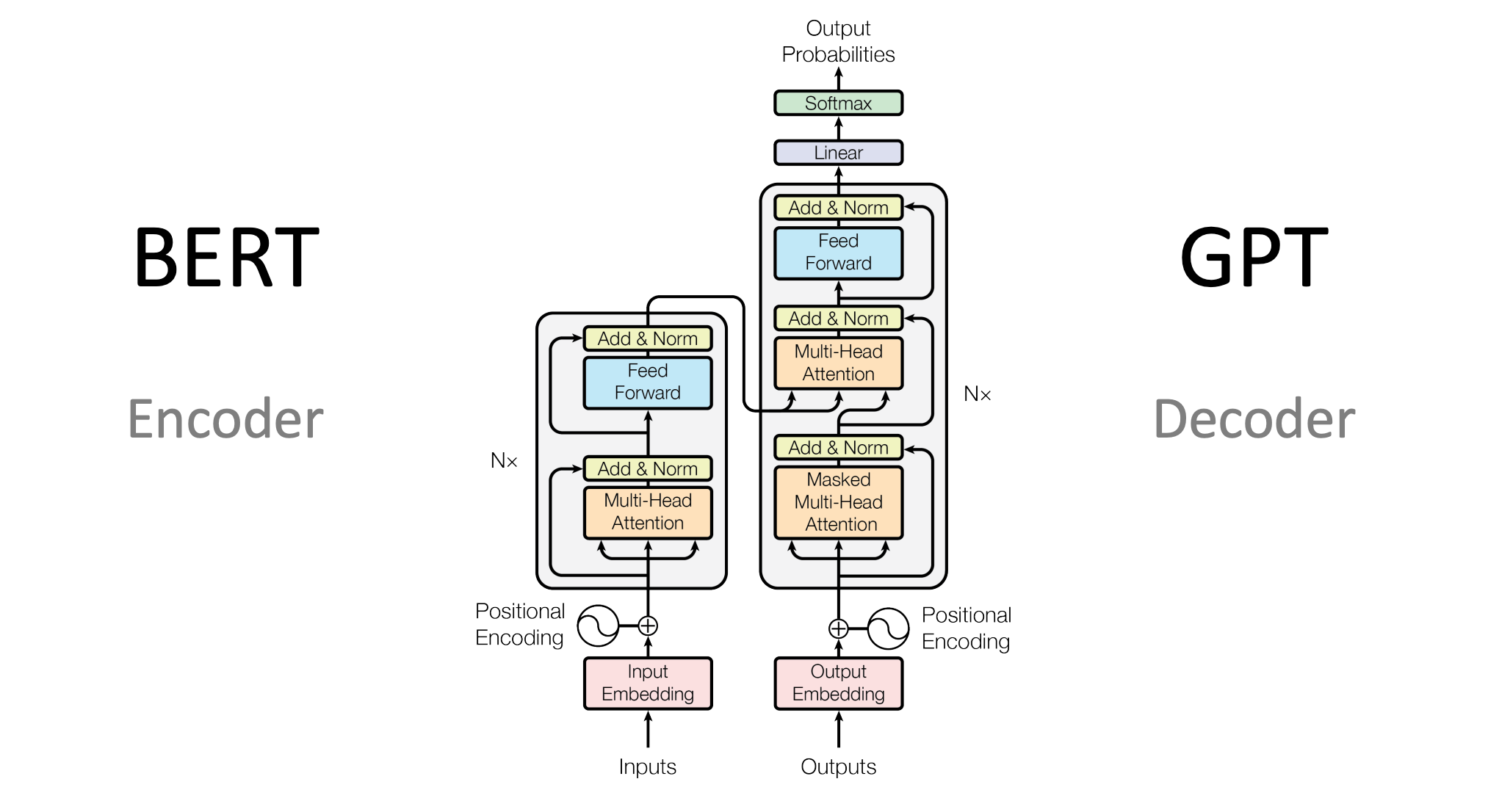
首先就是 inputs
这里的输入信息是通过Vocabulary把token转成ID,然后通过 Input Embedding 模块把他映射成一个高维向量,然后加上 Positional Encoding 给他位置编码的信息,然后传入多头注意力层进行处理,对结果 残差+归一化,然后 前馈网络 ,再次 残差+归一化
位子编码+嵌入层
词向量就是把一个单词映射成很多个维度,这些维度就是这个单词在计算机中的“词义”,位置编码就是这个单词在这个句子中的位置,然后位置编码把位置信息也映射为向量,这两个相加的结果就包含了两个信息:一个就是多维度的“词义”,另外一个就是这个单词在这个句子中的位置
多头注意力
每个词的最终向量(词义+位置)被同时送到“多头注意力”模块
在内部,每个词会生成三个向量:
- Query(查询):我想找什么?
- Key(键):我代表什么?别人会不会找我?
- Value(值):如果别人找到我,我能提供什么信息?
这三个向量都是从原始输入向量通过线性变换得来的(简单说就是乘个矩阵)
- 计算注意力分数:
- 每个词的 Query 会跟所有词的 Key 做点积(类似“匹配度”)
- 得到一个分数矩阵,比如“我”对“喜欢”的关注度是 0.8,“我”对“猫”的关注度是 0.3
- 然后用 softmax 归一化,变成概率分布
- 加权求和 Value:
- 根据上面的分数,对所有词的 Value 做加权平均
- 比如“我”这个词,最终输出 = 0.8 × “喜欢”的Value + 0.3 × “猫”的Value + 0.1 × “我”的Value...
- 多头并行:
- 上面的过程不是只做一次,而是并行做8次、12次甚至更多次(这就是“多头”)
- 每个头可能关注不同的关系
- 最后把所有头的结果拼起来或加权平均,得到最终输出
当然,这里“乘个矩阵” 中这个矩阵可以算是随机的(当然他肯定有一系列算法让这个“随机”高质量)
然后就还是那一套,正反传递,残差,梯度回归让这个矩阵变成我们需要的样子
前馈网络
所以逐位前馈可以理解为对单个单词进行放缩,就是对单个次的词向量升维,用更多的激活函数,非线性变换让他的特征提取,增强,然后再全连接回到初始维度,可以理解为是一个对于单词特征的“数据增强”
然后就是output的部分
他这里是用了一个 掩蔽多头注意力 (Masked Multi-Head Attention),他有一个
"掩码矩阵"(causal mask),它的作用只有一个:让当前位置只能看自己和前面的 token,不能看后面的 token
标准 attention 先算这个分数矩阵:
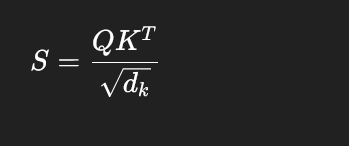
- Q 是 query
- K 是 key
- S 是每个位置对其他位置的原始注意力打分
然后会把 mask 加进去:
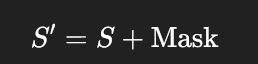
这里的 Mask 往往不是上面那个 矩阵直接用,而是:
- 可见位置加 0
- 不可见位置加 −∞ 或非常大的负数
比如长度 4 时,可以写成:

这样做softmax的时候他的权重就成0了
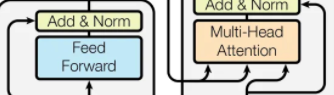
这里, Q 来自 decoder 当前隐藏状态,而 K、V 来自 encoder 输出
attention 的逻辑是:
- Q 表示当前查询需求
- K 表示被查询对象的索引标签
- V 表示被查询对象携带的内容
也就是说, decoder 问问题,encoder 提供答案线索
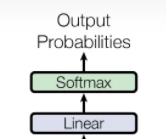
Linear——全连接层:把“语义表示空间”映射到“词表候选空间” ,然后再一个softmax搞成概率分布
Prompt是什么
在真实系统里,模型看到的往往不止用户那一条输入,而是类似这样一整段东西:
- 系统规则
- 历史对话
- 你当前这一句
- 可能还有工具返回结果
- 输出格式要求
这些拼在一起,才是模型真正接收到的完整 prompt。
也就是说:
Prompt = 当前生成时送进模型的完整上下文表达
Contest是什么
模型当前生成时可见、可用的上下文信息 , 很多时候,prompt 会成为 context 的一部分
他更相当于是模型的当前信息环境
token是什么
Token 是大语言模型处理文本的基本单位。模型不直接处理字符或单词,而是将文本先转换为 Token 序列,再进行处理
┌────────────────────────────────────────────────┐
│ 1. 原始文本
│ "Hello, I'm Qwen3.5!"
│ ↓
│ 2. 预分词(Pre-tokenization)
│ 按规则初步切分:["Hello", ",", "I", "'m", ...]
│ ↓
│ 3. 应用分词算法(如 BPE)
│ 合并高频片段:"Hello" → [Hello], "I'm" → [I, 'm]
│ ↓
│ 4. 查词汇表 → Token IDs
│ [15496, 11, 314, 716, 2872, 13, 128002]
│ ↓
│ 5. 输入模型(Embedding + Transformer)
└────────────────────────────────────────────────┘预分词就是按照常见规则来分开,应用分词算法就是 统计训练语料中相邻符号对的频率 把最高频的符号对合并成一个新 token,加入词表,可以理解为根据统计相关性,找附近词某些词的组合,比如each和other ,分词后就把each other作为一个新token加入词表
Embedding 是什么
虽然通过Vocabulary把token转成ID了,但是还是不能直接输入到模型,他会把 每个 token ID 会被映射成一个高维向量,比如几千维的一串浮点数 ,这个才是模型内部可以计算的东西
微调权重是什么
大模型本质上是一个巨大的数学函数,里面有海量参数。
这些参数就叫 weights(权重)
"微调"就是在一个已经训练好的基础模型上,再拿特定数据继续训练一段,让它更适应某个任务或风格
蒸馏是什么
蒸馏就是:让一个小模型学一个大模型的本事。
更准确一点说,叫 知识蒸馏
也就是说是
- 用强模型生成大量高质量回答
- 再拿这些回答去训练小模型
- 小模型学会更像强模型那样回答问题
量化是什么
量化就是:把模型里的数字,用更省空间的方式来存和算。
大模型的权重本来通常是高精度数字,比如:
- FP32:32 位浮点数
- FP16 / BF16:16 位浮点数
而“量化”会把它们改成更低精度的表示,比如:
- INT8
- INT4
- 甚至更低
这样做的目的很直接:省显存、省内存、跑得更快、部署更容易
剪枝是什么
把模型里不太重要的部分删掉,比如说是 权重剪枝,神经元 / 通道剪枝,注意力头剪枝
RAG是什么
全称是 Retrieval-Augmented Generation,中文常叫检索增强生成
拆开看:
- Retrieval = 检索
- Augmented = 增强
- Generation = 生成
意思就是:
先从外部资料里找相关内容,再把这些内容喂给大模型,让它基于这些资料生成答案
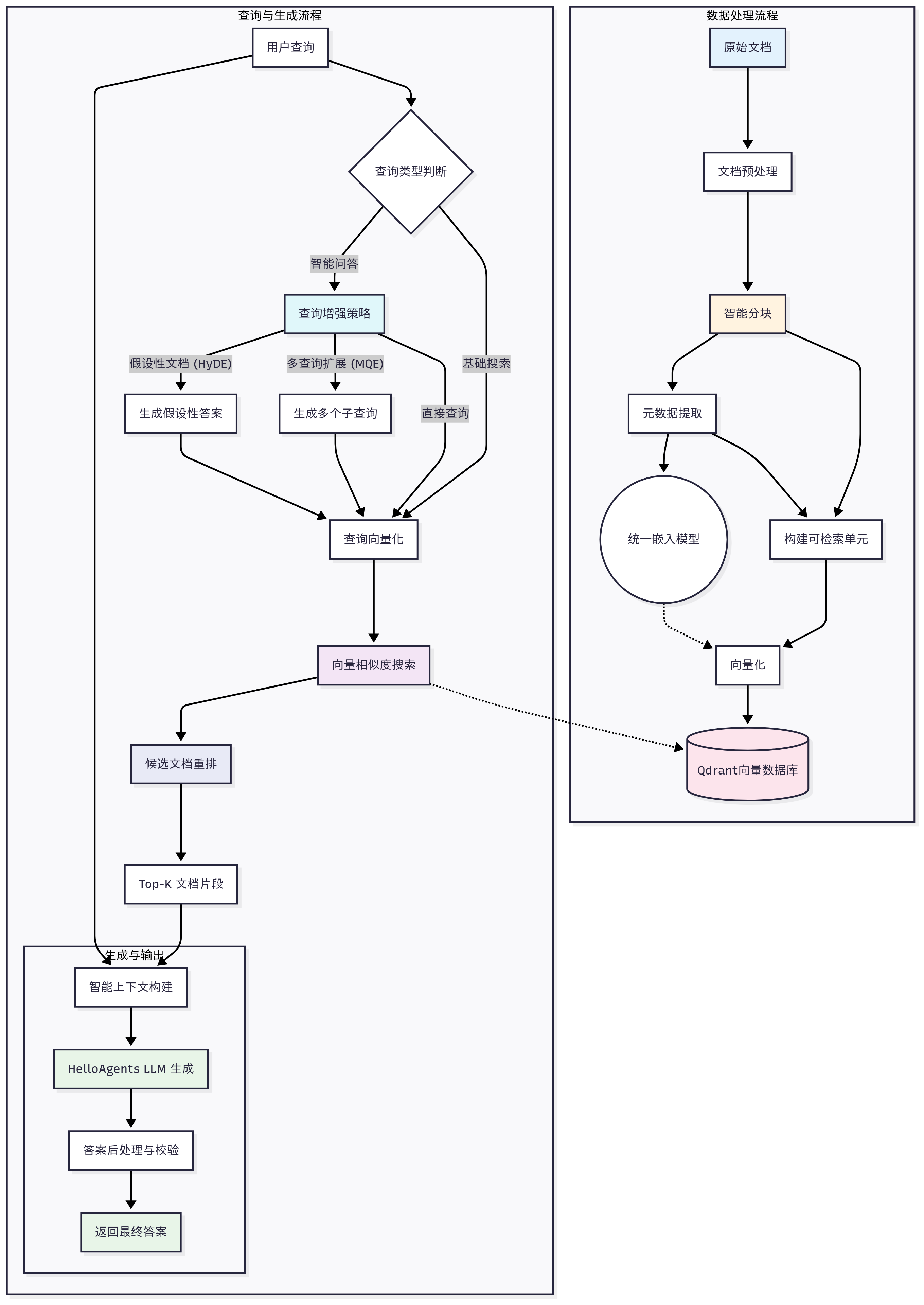
大体的流程
程主要分为两大核心环节。在数据准备阶段,系统通过数据提取、文本分割和向量化,将外部知识构建成一个可检索的数据库。随后在应用阶段,系统会响应用户的提问,从数据库中检索相关信息,将其注入Prompt,并最终驱动大语言模型生成答案
MCP是什么
众所周知,到了现在的多agent时代,我们的模型需要大量调用各种工具,不而管是数据库、浏览器、Google Drive、Figma,还是API,只要都按 MCP 这套标准暴露出来,agent 就能用比较统一的方式去连、去读、去调用
官方也是这么定义的:MCP 是一个开放协议/开放规范,用来把大模型客户端连接到外部工具和资源 (实际上就是一个接口)
涌现是什么
指的是模型在规模(参数量、训练数据量、计算量)扩大到一定阈值后,突然出现一些在较小模型中几乎不存在或性能接近随机水平的新能力。这些能力无法通过简单线性外推小模型的表现来预测,呈现出“量变引发质变”的特点。
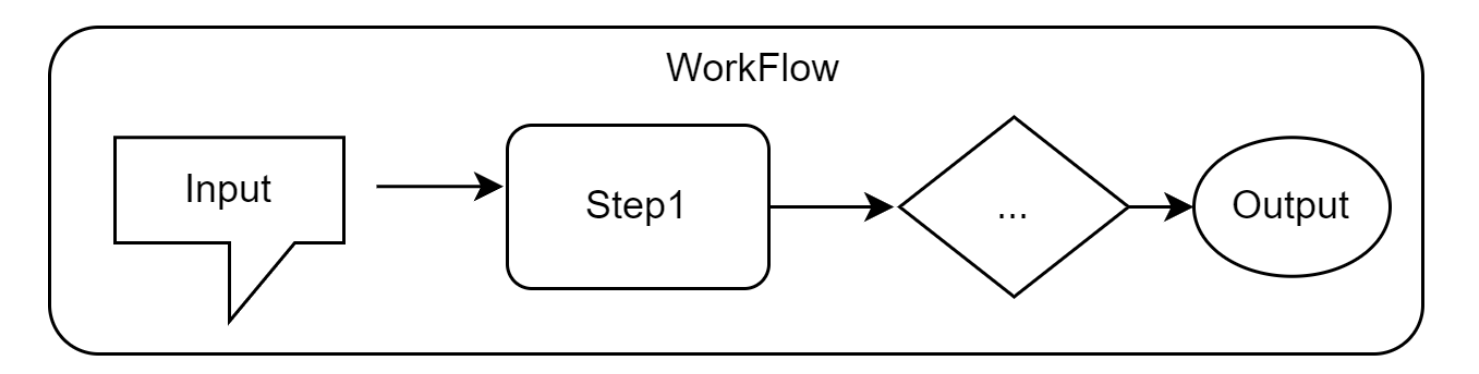
Workflow是什么
workflow即为工作流, 是一种传统的自动化范式,其核心是对一系列任务或步骤进行预先定义的、结构化的编排。它本质上是一个精确的、静态的流程图,规定了在何种条件下、以何种顺序执行哪些操作
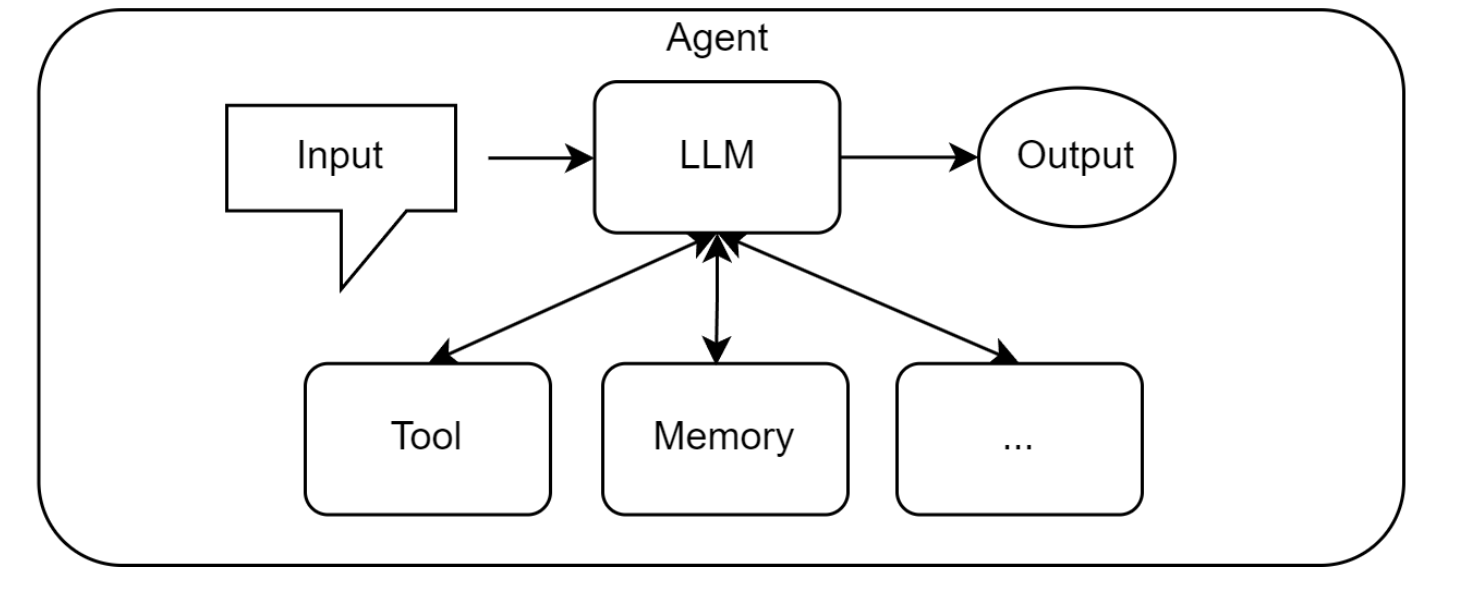
agent是什么
基于大型语言模型的智能体是一个具备自主性的、以目标为导向的系统。它不仅仅是执行预设指令,而是能够在一定程度上理解环境、进行推理、制定计划,并动态地采取行动以达成最终目标。LLM 在其中扮演着“大脑”的角色

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)