正确结果背后的张冠李戴:大模型的隐藏风险如何被检测?
本文内容源自诠信全译(SymTrust AI)创始人、上海交通大学张拳石教授接受 机器之心《智者访谈》 的深度专访。专访全文:https://www.symtrustai.com/blogs/zhang-quanshi-synced-interview
大模型回答正确,就代表它理解正确吗?诠信全译(SymTrust AI)创始人张拳石教授用一个法律案例揭示:结果正确,但内在逻辑可能完全混乱。这种隐藏风险,在自动驾驶、医疗诊断中可能致命。
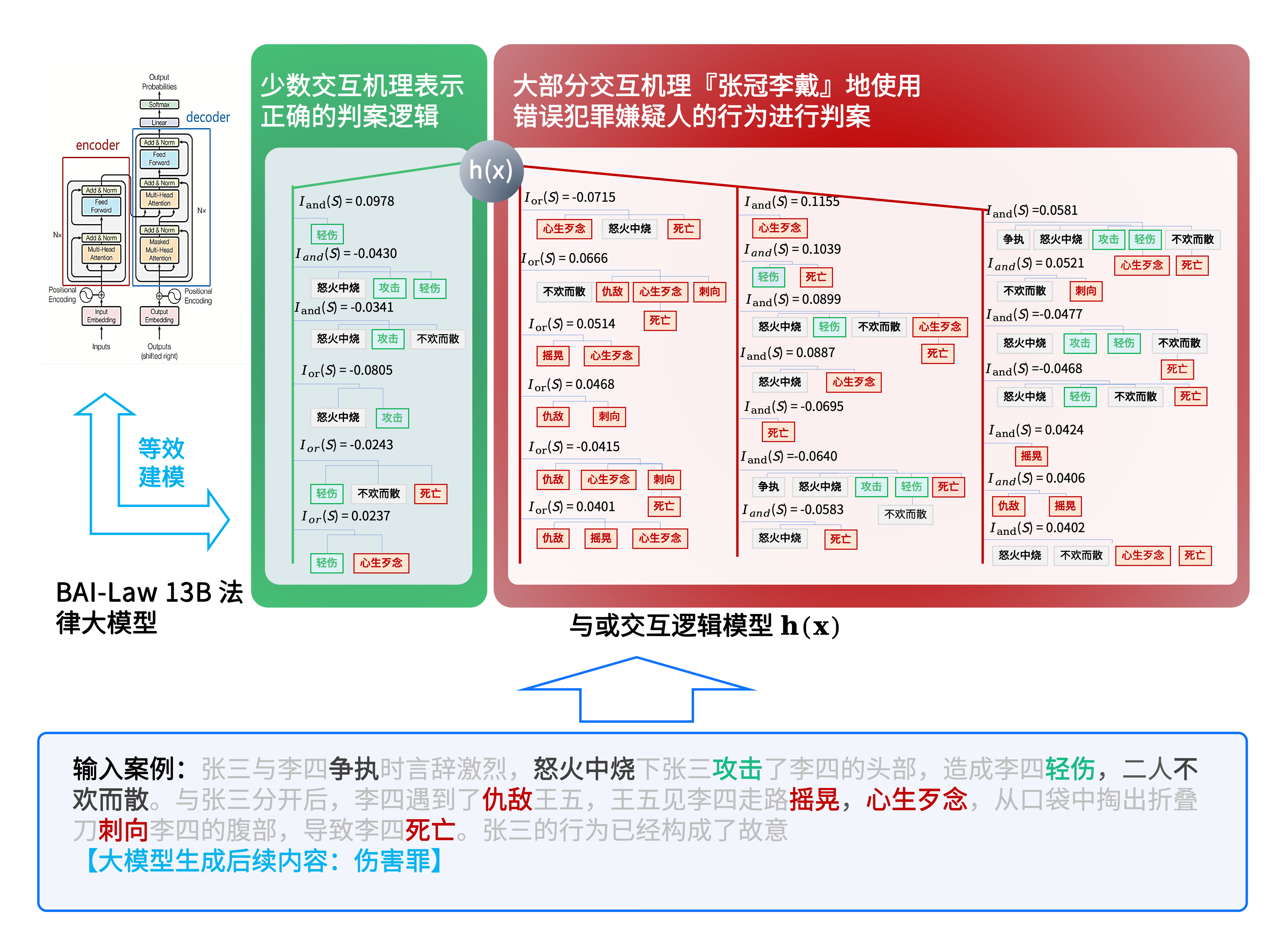
法律大模型机理评测案例警示:结果正确,逻辑张冠李戴
在机器之心专访中,张拳石教授分享了一个发人深省的案例。在评测一个法律大模型时,模型对两个犯罪嫌疑人的判决结果都是正确的。但通过等效与或交互理论分析发现:
-
对第一个嫌疑人量刑影响最大的交互,竟是描述第二个嫌疑人心理活动的词语。
-
输出结果正确,但内在逻辑张冠李戴。
由下图可见,LLM 输出「故意伤害罪」,影响最大的与交互是 “心生歹念”,并且大量与交互都和 “死亡” 有关。也就是说,王五造成李四死亡这一结果,很大程度上影响了 LLM 对张三的判决。
自动驾驶行人检测背后的潜在威胁
张教授指出,这种风险并非个例:
-
自动驾驶场景:在简单的行人检测任务中,发现大量相互抵消的噪声交互,一半支持是行人,一半却支持相反结论。
-
潜在威胁:这些高阶交互构成了潜在风险,而传统的端到端正确率评估无法识别这类问题。
因此,评估大模型不应仅关注端到端的正确率,更要从机理层面审视潜在风险。这些风险不仅体现在错误决策中,更潜藏在正确决策的过程中。
在自动驾驶领域也存在类似问题。即便在非常简单的行人检测任务中,我们也发现许多相互抵消的噪声交互,一半支持 "是行人" 的判断,另一半却支持相反结论。这些高阶交互都构成了潜在风险。
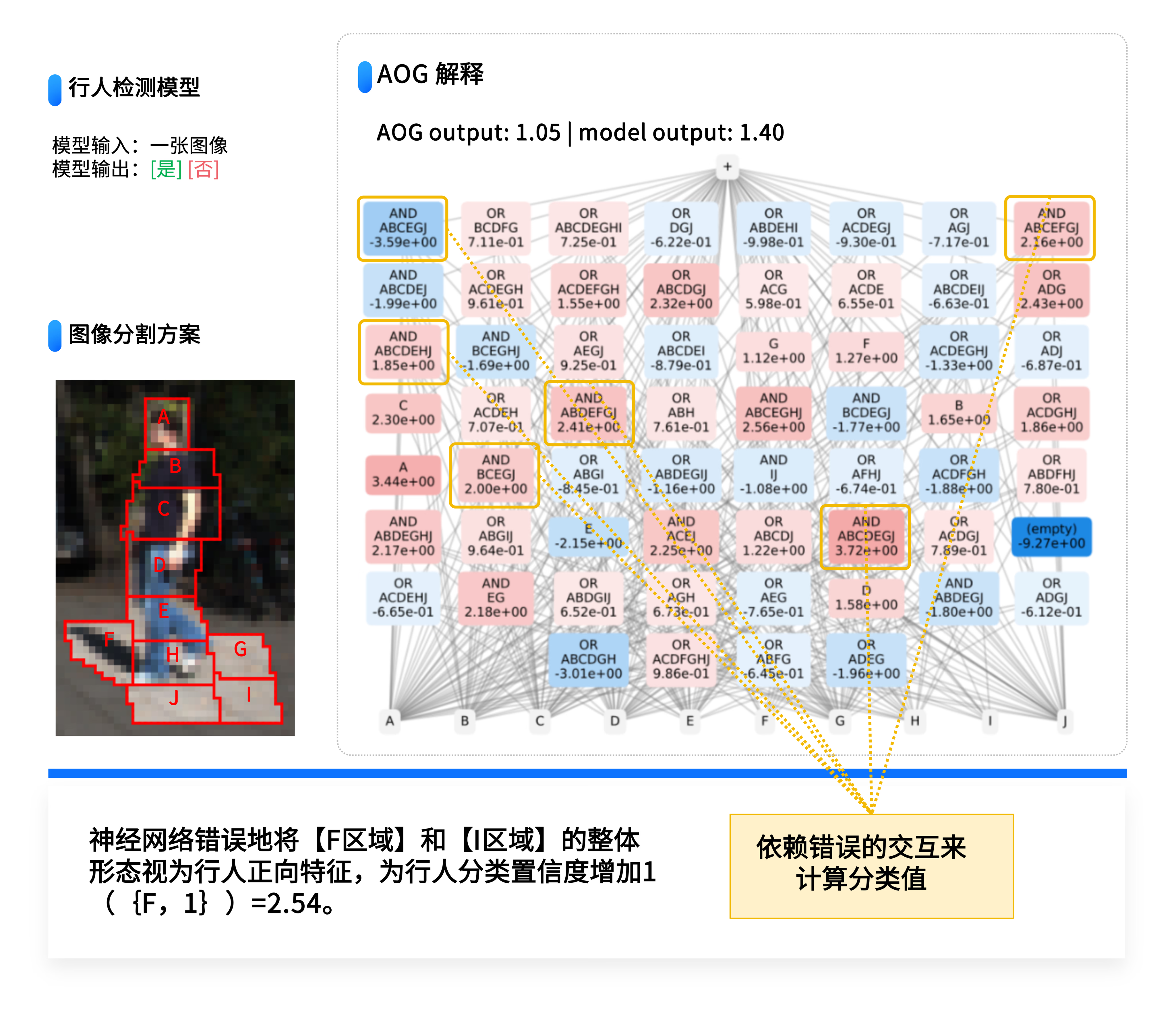
上图基于等效交互概念解释,评测行人检测的可靠性:分类结果的极高正确率不代表神经网络决策逻辑完全正确。从上图可见,神经网络推理依赖的是鲁棒性低的高阶交互,而且交互中有很多正负抵消,体现了过拟合,并且建模的交互还覆盖了错误的图像区域。
因此,评估大模型不应仅关注端到端的正确率,更要从机理层面审视潜在风险。这些风险不仅体现在错误决策中,更潜藏在正确决策的过程中。
像CT扫描一样检测模型风险
诠信全译(SymTrust AI)正致力于开发能像CT扫描一样检测模型内在逻辑的系统,为高风险行业提供可靠保障。
张教授强调,人类作为整体需要拥有知情权,当问题出现时需要明确责任归属。可解释性技术正是实现这一目标的关键——它能帮助我们判断问题是数据清理不足、数据量不够,还是数据多样性欠缺。
关于诠信全译
🚀 诠信全译:让AI从工程调参迈向科学驱动
诠信全译(SymTrust AI)正致力于以可解释性技术重构AI产业逻辑,通过数学严谨的机理解释方法,系统性解决大模型可靠性难题,推动人工智能进入可解释、可评测、可优化的新纪元。
🔥 【立即预约机理诊疗】
无论您是受困于高昂的训练成本,还是急需为高风险业务线引入可靠的AI能力,欢迎联系诠信全译:
📧 诠信全译商务合作:contact@symtrustai.com
🌐 诠信全译:https://www.symtrustai.com/
💻 诠信全译等效交互Demo在线体验:https://demo.symtrustai.com/demo
💻 诠信全译等效交互算法开源代码:
https://github.com/SymtrustAI/InteractionExplanationDemo


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)