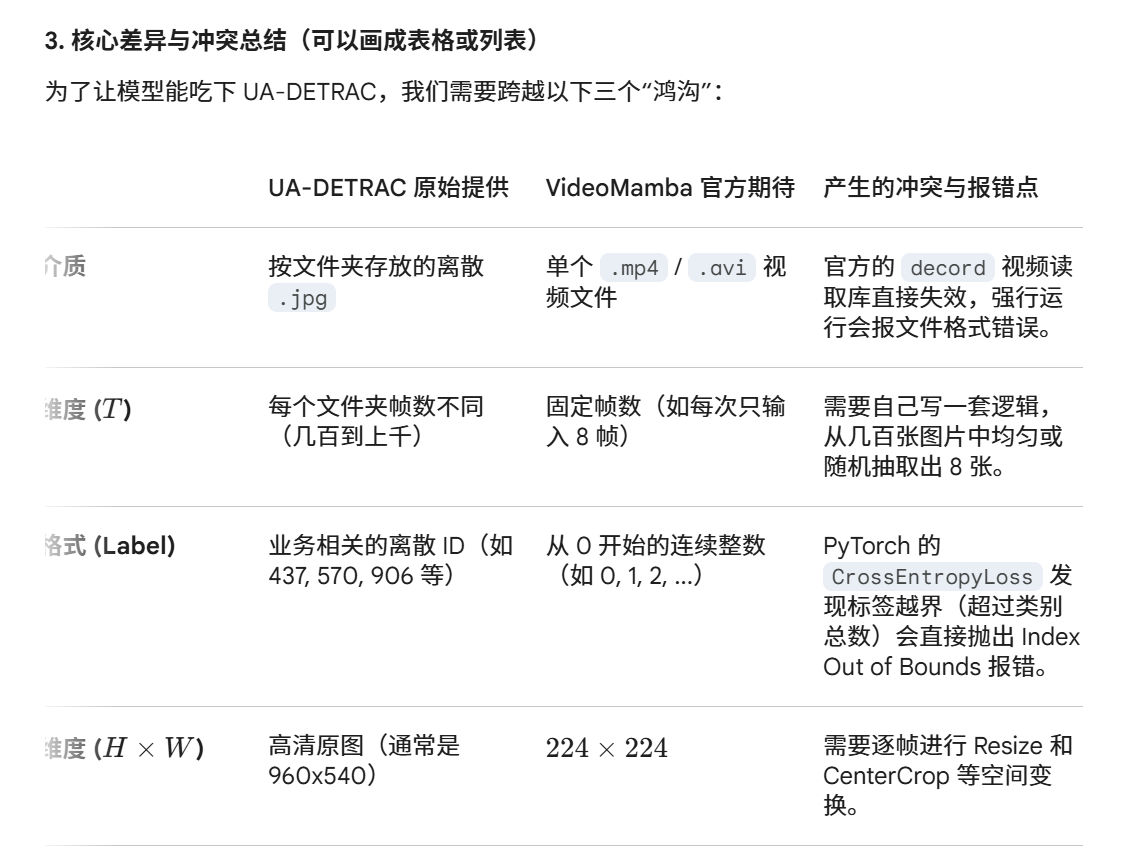
VideoMamba:Pipeline过程记录(UA-DETRAC数据集)
一、数据集
UA-DETRAC数据集:
下载:kaggle网站下载UA-DERRAC.zip,然后上传到远程主机
detrac的数据集目录结构:
UA-DETRAC/
├── DETRAC-Images/ # 所有的图片数据都在这里
│ ├── MVI_20011/ # 每一个文件夹代表一段完整的视频序列
│ │ ├── img00001.jpg
│ │ ├── img00002.jpg
│ │ └── ... (可能包含几百上千张按顺序命名的图片)
│ ├── MVI_20012/
│ └── MVI_...
└── annotations/ # 官方通常提供 XML 标注框
└── ...
数据集非视频数据集,而是帧序列,videomamba它默认你的数据是标准的视频动作识别数据集

二、数据预处理
convert_detrac.py:
数据集预处理脚本,将UA-DETRAC数据集转换为适合视频分类任务使用的CSV标注文件格式
核心功能:
UA-DETRAC原始数据 (XML标注 + 图像帧)
↓
[convert_detrac.py]
↓
train.csv / val.csv (视频级分类标注)2.1 关键配置
BASE_PATH = os.path.dirname(os.path.abspath(__file__))
DATA_ROOT = os.path.join(BASE_PATH, "data/UA-DETRAC/DETRAC-Images") # 图像帧目录
XML_ROOT = os.path.join(BASE_PATH, "data/UA-DETRAC/DETRAC-Train-Annotations-XML") # XML标注目录
OUTPUT_DIR = os.path.join(BASE_PATH, "data/UA-DETRAC/annotations") # 输出CSV目录
VEHICLE_MAP = {'car': 0, 'bus': 1, 'van': 2, 'others': 3} # 车辆类别→数字标签映射2.2 核心函数
![]()
![]()
![]()

2.3 os.path模块概述
1. os.path.join(path1, path2, ...)
将多个路径组件智能拼接为一个完整路径,自动处理分隔符,示例:
os.path.join('folder', 'subfolder', 'file.txt') # 输出: 'folder/subfolder/file.txt'(Unix)或 'folder\\subfolder\\file.txt'(Windows)
2.os.path.split(path)
将路径拆分为 (head, tail) 元组,tail 是最后一级目录或文件名,示例:
os.path.split('/home/user/file.txt') # 输出: ('/home/user', 'file.txt')
3.os.path.splitext(path)
拆分路径的扩展名,返回 (root, ext) 元组(ext 包含点号)
os.path.splitext('data.json') # 输出: ('data', '.json')
4.os.path.exists(path)
检查路径是否存在(文件或目录均可)
os.path.exists('/etc/passwd') # 返回 True 或 False
5.os.path.dirname(path)
提取路径的目录部分
os.path.dirname('/home/user/file.txt') # 输出: '/home/user'
6.os.path.abspath(path)
将相对路径转为绝对路径
os.path.abspath('./file.txt') # 输出当前目录的绝对路径
解析:
BASE_PATH = os.path.dirname(os.path.abspath(__file__))os.path.abspath(__file__):首先返回当前脚本的绝对路径(包括文件名)
os.path.dirname():提取该路径的目录部分,即去掉文件名
用于动态加载同级目录,再用os.path.join()拼接其他路径
三、构建数据加载器 dataloader
不改变官方的代码,手写脚本文件,将.jpg序列变成模型能吃的 5D Tensor
3.1 完整数据流
原始数据
│
▼
[convert_detrac.py]
│ ├─ 读取XML → 统计主类别 → 映射为0/1/2/3
│ ├─ 过滤短视频(<8帧)
│ └─ 输出: train.csv / val.csv (无表头)
│
▼
[DetracImageDataset.__getitem__]
│ ├─ 解析CSV → 获取folder_name, label
│ ├─ 按clip_len×sample_rate策略抽帧
│ ├─ 逐帧: PIL→Resize→ToTensor→[0,1]
│ ├─ 堆叠+置换: [T,C,H,W]→[C,T,H,W]
│ └─ ImageNet归一化
│
▼
[DataLoader]
│ └─ 批处理: [C,T,H,W]×B → [B,C,T,H,W]
│
▼
[VideoMamba]
│ ├─ 3D Patch Embed: [B,3,T,224,224]→[B,L,C]
│ ├─ 位置编码 + Bidirectional Mamba Blocks
│ └─ [CLS]→Linear→Logits→Loss
│
▼
[训练/推理完成]四、训练脚本
4.1 模块导入说明
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from datasets.detrac_loader import DetracImageDataset # 自定义Dataset
from models.videomamba import videomamba_tiny # VideoMamba模型定义4.2 配置区解析
def train():
# --- 硬件配置 ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 自动检测GPU,若无则使用CPU
# --- 训练超参数 ---
batch_size = 2 # ⚠️ 小batch避免显存溢出(ALLOC_FAILED)
epochs = 30 # 训练轮数
lr = 1e-5 # 学习率:微调时用较小值
# --- 路径配置 ---
BASE = "/home/chenchenyang/pro26/VideoMamba-main"
train_csv = f"{BASE}/data/UA-DETRAC/annotations/train.csv" # 训练集标注
img_prefix = f"{BASE}/data/UA-DETRAC/DETRAC-Images" # 图像根目录
ckpt_path = f"{BASE}/checkpoints/videomamba_t16_k400_f8_res224.pth" # 预训练权重
output_dir = f"{BASE}/outputs/detrac_checkpoints" # 模型保存目录
os.makedirs(output_dir, exist_ok=True)4.3 训练超参数解析
4.3.1 .batch_size(批处理大小)
batch_size表示每次迭代训练时使用的样本数量,在这里代表每次训练迭代中加载视频片段video clip的数量
设置为2意味着每次前向传播和反向传播会处理2个样本
较小的batch_size会降低显存占用,避免GPU内存不足(如提示ALLOC_FAILED错误),但可能导致训练过程波动较大(梯度更新更频繁)
较大的batch_size能稳定梯度估计,但需要更多显存,可能影响模型泛化能力
4.3.2 epochs(训练轮数)
epochs指完整遍历整个训练数据集的次数。
设置为30表示模型会重复学习训练数据30轮。增加epochs可能提升模型性能,但需注意过拟合风险(训练误差持续下降而验证误差上升)。若训练早期验证性能已稳定,可提前停止(Early Stopping)以避免无效训练。
4.3.3 .lr(学习率)
lr(learning rate)控制参数更新的步长。
1e-5(0.00001)是较小的学习率,适合微调预训练模型,避免破坏预训练权重。学习率过大会导致训练不稳定或难以收敛;过小会减慢收敛速度。通常需配合学习率调度策略(如余弦退火、预热)动态调整
4.4 数据准备模块
# --- 数据准备 ---
dataset = DetracImageDataset(train_csv, prefix=img_prefix, mode='train')
num_classes = len(dataset.label_map) # 自动获取类别数
print(f"Detected Number of Classes: {num_classes}")
loader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True, # 训练时打乱顺序
num_workers=2, # 2个子进程加载数据
pin_memory=True # 加速CPU→GPU数据传输
)
4.5 模型加载与权重迁移(迁移学习)
# --- 模型加载 ---
model = videomamba_tiny(num_classes=num_classes) # 创建新模型,分类头适配DETRAC
if os.path.exists(ckpt_path):
print(f"Loading weights from {ckpt_path}")
checkpoint = torch.load(ckpt_path, map_location='cpu') # 先加载到CPU避免显存碎片
state_dict = checkpoint['model'] if 'model' in checkpoint else checkpoint
# 🔹 关键步骤:移除预训练权重的分类头
for k in ['head.weight', 'head.bias']:
if k in state_dict:
del state_dict[k]
# 🔹 加载权重:strict=False 允许部分参数不匹配
msg = model.load_state_dict(state_dict, strict=False)
print(f"Checkpoint loaded: {msg}")
model.to(device) # 模型迁移到GPU,将模型(model)及其所有参数(权重)移动到指定的计算设备(device)模型加载选择 videomamba_tiny(基于预训练模型选择),该函数在videomamba.py中有所定义
pytorch的 .pth的文件(检查点文件)通常以字典形式存储
常见的结构示例:
# 结构1: 最简形式 (只存模型参数) torch.save(model.state_dict(), 'model.pth') # 内容: {'layer1.weight': tensor(...), 'layer1.bias': tensor(...), ...} # 结构2: 完整检查点 (包含元信息) torch.save({ 'epoch': 10, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': 0.05, }, 'checkpoint.pth') # 内容: {'epoch': 10, 'model_state_dict': {...}, 'optimizer_state_dict': {...}, ...} # 结构3: 某些框架的命名习惯 torch.save({'model': model.state_dict()}, 'checkpoint.pth') # 内容: {'model': {...}}
1.先通过 torch.load加载.pth检查点文件
state_dict = checkpoint['model'] if 'model' in checkpoint else checkpoint
2. state_dict 模型状态字典,检查字典中是否有“model”键,如果存在,那就是结构3,如果不存在,就是结构1,直接使用整个checkpoint,整个checkpoint里面保存的就是整个模型参数字典
模型参数字典示例:
# 假设原始模型的 state_dict
state_dict_example = {
'patch_embed.proj.weight': torch.randn(96, 3, 2, 2),
'blocks.0.norm1.weight': torch.randn(96),
...,
'head.weight': torch.randn(1000, 768), # 分类头权重
'head.bias': torch.randn(1000), # 分类头偏置
}3.移除分类头权重
为什么要权重迁移(迁移学习)?
对于不同的数据集,分类的数量是不同的
比如本次实验,预训练权重使用K400数据集训练的,K400中有400/600类,但是UA-DETRAC数据集中只有4类,所以在模型参数字典中,参数的形状不匹配,预训练权重的head.height是(400,768),而我们用UA-DETRAC数据集训练的模型是(num_classes,768),其中num_classes = 4,所以要保留主干网络的权重,丢弃不匹配的分类头,分类头要重新训练
1. 加载预训练权重 → 只保留backbone参数
2. 新建分类头 → 随机初始化
3. 微调训练 → backbone小幅更新,head大幅学习4.检查加载状态
为了了解那些权重加载成功了,权重加载是否按预期进行
# 4. 加载权重
msg = model.load_state_dict(state_dict, strict=False)model是第一步加载的videomamba_tiny
strict = true:要求state_dict的键要与模型完全匹配
strict = false:允许部分加载

返回的msg格式:
# msg 的实际结构
class _IncompatibleKeys:
missing_keys: List[str] # 模型有但 state_dict 中没有的键
unexpected_keys: List[str] # state_dict 中有但模型中没有的键
_IncompatibleKeys(
missing_keys=['head.weight', 'head.bias'], # 模型有但 state_dict 无
unexpected_keys=['some_unused_key'] # state_dict 有但模型无
)
加载过程可视化:
预训练权重 state_dict: 您的模型结构:
┌─────────────────────┐ ┌─────────────────────┐
│ patch_embed.weight │ ←──匹配──→ │ patch_embed.weight │
│ blocks.0.norm1.weight│ ←──匹配──→ │ blocks.0.norm1.weight│
│ ... │ │ ... │
│ head.weight [400,768]│ ✗ │ head.weight [4,768] │ ← 不匹配,删除
│ head.bias [400] │ ✗ │ head.bias [4] │ ← 不匹配,删除
└─────────────────────┘ └─────────────────────┘
↓ ↓
删除 head.* 保留随机初始化实际输出示例:
# 打印加载信息
print(f"Checkpoint loaded: {msg}")
# 输出可能:
# Checkpoint loaded: <All keys matched successfully> # 理想情况
# 或
# Checkpoint loaded: _IncompatibleKeys(
# missing_keys=['head.weight', 'head.bias'], # 预期的,因为被删除了
# unexpected_keys=[]
# )4.6 优化器与损失函数
# --- 优化器 ---
optimizer = torch.optim.AdamW(
model.parameters(),
lr=lr,
weight_decay=0.05 # 建议添加L2正则,防止过拟合
)
criterion = nn.CrossEntropyLoss() # 多分类交叉熵损失
4.7 训练循环详解
print("Start Training...")
for epoch in range(epochs):
model.train() # 切换到训练模式(启用Dropout等)
epoch_loss = 0
for i, (frames, labels) in enumerate(loader):
# 1️⃣ 数据迁移到GPU
frames = frames.to(device, non_blocking=True) # non_blocking加速传输
labels = labels.to(device, non_blocking=True)
# 2️⃣ 前向传播
outputs = model(frames) # [B, num_classes]
loss = criterion(outputs, labels) # 标量损失
# 3️⃣ 反向传播
optimizer.zero_grad() # 清空上轮梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 4️⃣ 日志记录
epoch_loss += loss.item()
if i % 5 == 0: # 每5个batch打印一次
print(f"Epoch [{epoch}] Batch [{i}/{len(loader)}] Loss: {loss.item():.4f}")
# 5️⃣ 保存checkpoint
save_path = os.path.join(output_dir, f"mamba_detrac_epoch_{epoch}.pth")
torch.save(model.state_dict(), save_path)
# 6️⃣ 轮次统计
avg_loss = epoch_loss / len(loader)
print(f"Epoch {epoch} Average Loss: {avg_loss:.4f}")4.7.1 变量解析和loader数据加载器
epoch_loss:用来累加当前epoch内所有的批次的损失值,每个epoch(完整训练一次数据集)都要重新计算平均损失
for i, (frames, labels) in enumerate(loader):- i:当前批次的索引,从 0 开始
- frames:当前批次的数据(视频帧张量),[B,C,T,H,W]的形状
- labels:当前批次对应的标签或目标值
- loder:数据加载器的对象(Pytorch的DataLoader),用于批量生成训练数据
在循环训练中,loader每次返回一个批次
具体的数据结构:
# 假设 batch_size=4, clip_len=8, 图片尺寸224×224
print(type(frames)) # <class 'torch.Tensor'>
print(frames.shape) # torch.Size([4, 3, 8, 224, 224])
print(type(labels)) # <class 'torch.Tensor'>
print(labels.shape) # torch.Size([4])
print(labels) # tensor([2, 0, 3, 1], device='cuda:0')可视化表示:
frames 的形状 [4, 3, 8, 224, 224]:
┌─────────────────────────────────────────────────┐
│ Batch 0: 视频片段0 │
│ Shape: [3, 8, 224, 224] (RGB, 8帧, 高, 宽) │
├─────────────────────────────────────────────────┤
│ Batch 1: 视频片段1 │
│ Shape: [3, 8, 224, 224] │
├─────────────────────────────────────────────────┤
│ Batch 2: 视频片段2 │
│ Shape: [3, 8, 224, 224] │
├─────────────────────────────────────────────────┤
│ Batch 3: 视频片段3 │
│ Shape: [3, 8, 224, 224] │
└─────────────────────────────────────────────────┘
labels: [2, 0, 3, 1] ← 每个视频片段的类别标签完整的数据流示例:
数据集: [视频0, 视频1, ..., 视频999]
↓
DataLoader 打乱: [视频34, 视频12, 视频8, 视频25, 视频77, ...]
↓
第一个批次: [视频34, 视频12, 视频8, 视频25] → (frames0, labels0)
↓
模型输入: frames0.shape = [4, 3, 8, 224, 224]
labels0 = [2, 0, 3, 1]
↓
第二个批次: [视频77, 视频91, 视频3, 视频61] → (frames1, labels1)4.7.2 向前传播 和 反向传播
outputs = model(frames) # [B, num_classes]
loss = criterion(outputs, labels) # 标量损失将输出和标签传入优化器中,得到loss损失
optimizer.zero_grad() # 清空上轮梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数epoch_loss += loss.item()
if i % 5 == 0:
print(f"Epoch [{epoch}] Batch [{i}/{len(loader)}] Loss: {loss.item():.4f}")loss:损失张量,带有梯度信息的PyTorch张量
loss.item():获取损失张量的Python标量数值
+=:累加到epoch_loss变量
# 示例:理解 loss 和 loss.item() 的区别
loss = criterion(outputs, labels)
print(type(loss)) # <class 'torch.Tensor'> (形状: torch.Size([]))
print(loss) # tensor(2.134, device='cuda:0', grad_fn=<NllLossBackward0>)
print(loss.item()) # 2.134 (Python float类型)
# 如果直接相加会怎样?
# epoch_loss += loss # ❌ 错误!会把张量也累积进去
# 最终 epoch_loss 会变成一堆张量的和,而不是数值4.7.3 保存权重文件和每个epoch平均损失统计
save_path = os.path.join(output_dir, f"mamba_detrac_epoch_{epoch}.pth")
torch.save(model.state_dict(), save_path)
avg_loss = epoch_loss / len(loader)
print(f"Epoch {epoch} Average Loss: {avg_loss:.4f}")4.7.4 数据流形状变化
输入: frames [B, 3, 8, 224, 224]
├─ B: batch_size=2
├─ 3: RGB通道
├─ 8: 时间帧数(clip_len)
└─ 224×224: 空间分辨率
VideoMamba内部:
1. 3D Patch Embed: [2,3,8,224,224] → [2, L, 192]
L = 8 × (224/16)² = 8 × 196 = 1568 tokens
2. B-Mamba Blocks × 24: [2, 1568, 192] → [2, 1568, 192]
3. [CLS] token提取: [2, 192]
4. Classification Head: [2, 192] → [2, num_classes]
输出: outputs [B, num_classes], labels [B]五、验证脚本
val_detrac.py
5.1 配置信息
def inference():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 1. 配置路径 ---
BASE = "/home/chenchenyang/pro26/VideoMamba-main"
test_csv = f"{BASE}/data/UA-DETRAC/annotations/train.csv" # ⚠️ 先用训练集测过拟合
img_prefix = f"{BASE}/data/UA-DETRAC/DETRAC-Images"
model_path = f"{BASE}/outputs/detrac_checkpoints/mamba_detrac_epoch_29.pth"test 临时用训练集测试,验证是否过拟合
5.2 加载数据
# --- 2. 加载数据 ---
# mode='val' 会使用中间抽帧,结果更稳定
dataset = DetracImageDataset(test_csv, prefix=img_prefix, mode='val')
loader = DataLoader(dataset, batch_size=1, shuffle=False)
# 获取反向映射表 (ID -> 原始标签)
inv_label_map = {v: k for k, v in dataset.label_map.items()}
num_classes = len(dataset.label_map)- mode = "val" : 居中抽帧,推理是用稳定的抽帧策略
- batch_size = 1:单样本,便于逐条查看预测结果
- shuffle = False :不打乱,保持样本顺序,便于调试
反向映射表:
# 假设 dataset.label_map = {0: 0, 1: 1, 2: 2, 3: 3}
# 则 inv_label_map = {0: 0, 1: 1, 2: 2, 3: 3}
# 如果原始标签是字符串:
# label_map = {'car': 0, 'bus': 1, 'van': 2}
# inv_label_map = {0: 'car', 1: 'bus', 2: 'van'}- 训练时,需要的映射: label_map = {'car': 0, 'bus': 1, 'van': 2}、
- 推理时,需要的反向映射: inv_label_map = {0: 'car', 1: 'bus', 2: 'van'},模型输出的是数字,映射为标签“car”
5.3 模型加载模块
# --- 3. 初始化模型并加载权重 ---
model = videomamba_tiny(num_classes=num_classes)
if os.path.exists(model_path):
print(f"Loading trained model from {model_path}")
model.load_state_dict(torch.load(model_path, map_location='cpu'))
else:
print("Model file not found!")
return
model.to(device)
model.eval() # 🔹 关键:切换到评估模式(关闭Dropout等)1. torch.load(model_path, map_location='cpu')
- 从磁盘读取.pth文件
- 将文件的权重数据加载到CPU内存
- 返回一个包含权重的字典(state_dict)
2.model.load_state_dict(...):
- 将这些权重复制到模型的参数中
- 模型的设备位置保持不变
模型model是一直在CPU上的,权重文件.pth从磁盘加载到字典,再复制到模型的参数中
model.load_state_dict(torch.load(model_path, map_location='cpu'))3.model.eval() :切换到评估模式

5.4 推理循环讲解
# --- 4. 开始推理 ---
correct = 0
total = 0
print(f"\n{'Sample Index':<15} | {'True Label':<12} | {'Pred Label':<12} | {'Status'}")
print("-" * 60)
with torch.no_grad():
for i, (frames, label) in enumerate(loader):
frames = frames.to(device)
label = label.to(device)
outputs = model(frames)
prob = F.softmax(outputs, dim=1)
pred = torch.argmax(prob, dim=1)
true_origin = inv_label_map[label.item()]
pred_origin = inv_label_map[pred.item()]
status = "✅" if label == pred else "❌"
if label == pred:
correct += 1
total += 1
print(f"{i:<15} | {true_origin:<12} | {pred_origin:<12} | {status}")
acc = 100 * correct / total
print("-" * 60)
print(f"Final Accuracy: {acc:.2f}% ({correct}/{total})")5.4.1变量解析和 loader 数据加载器
- correct:统计正确的样本数
- total:总样本数
for i, (frames, label) in enumerate(loader):先在loader里面加载的是 test 测试集(batch_size = 1)

将数据迁移到设备上(模型和数据必须在同一个设备上,否则报错!)
frames = frames.to(device)
label = label.to(device)5.4.2 模型向前传播
outputs = model(frames) # [1, num_classes]数据流形状变化:
输入 frames: [1, 3, 8, 224, 224]
├─ 1: batch_size
├─ 3: RGB 通道
├─ 8: 时间帧数 (clip_len)
└─ 224×224: 空间分辨率
↓ 3D Patch Embed (1×16×16)
Patch 序列: [1, 1568, 192]
├─ 1568 = 8 × (224/16)² = 8 × 196 tokens
└─ 192: embed_dim (Tiny 版本)
↓ B-Mamba Blocks × 24
隐藏状态: [1, 1568, 192]
↓ [CLS] Token 提取
CLS 表示: [1, 192]
↓ Classification Head
输出 outputs: [1, num_classes]
例如 [1, 4] → 4 个类别的 logits输出outputs示例:
outputs = tensor([[2.3, -0.5, 1.1, -1.2]]) # 原始 logits(未归一化)
# 对应类别:[car, bus, van, others]5.4.3 概率映射标签
1.softmax转概率:将logits转换为概率分布(和为1)
- 可以查看模型对每个类别的置信度
- 可以设置置信度阈值(如>0.8才相信预测)
prob = F.softmax(outputs, dim=1) # [1, num_classes], 和为 12. 取最大概率类别
pred = torch.argmax(prob, dim=1) # [1]argmax:返回最大值的索引
计算示例:
# 输入 logits
outputs = tensor([[2.3, -0.5, 1.1, -1.2]])
# Softmax 计算
exp_outputs = [e^2.3, e^-0.5, e^1.1, e^-1.2]
= [9.97, 0.61, 3.00, 0.30]
sum = 9.97 + 0.61 + 3.00 + 0.30 = 13.88
prob = [9.97/13.88, 0.61/13.88, 3.00/13.88, 0.30/13.88]
= [0.718, 0.044, 0.216, 0.022] # 和为 1.0
# 输出
prob = tensor([[0.718, 0.044, 0.216, 0.022]])3.标签反向映射
true_origin = inv_label_map[label.item()]
pred_origin = inv_label_map[pred.item()]- item():是Tensor的一个方法,用于提取Tensor中的数字
- items():是字典的方法,获取所有键值对
# 原始标签表 (类别名 → ID)
label_map = {'car': 0, 'bus': 1, 'van': 2}
# 使用 .items() 拿到每一对 (key, value)
label_map.items()
# 输出类似:dict_items([('car', 0), ('bus', 1), ('van', 2)])
# 列表推导式里交换位置 (v: k for k, v in ...)
# 变成:{0: 'car', 1: 'bus', 2: 'van'}5.4.4 完整数据流变化
┌─────────────────────────────────────────────────────────────┐
│ 推理循环数据流 │
└─────────────────────────────────────────────────────────────┘
1️⃣ 数据加载
loader → (frames, label)
[1,3,8,224,224] [1]
2️⃣ 设备迁移
frames.to(device), label.to(device)
3️⃣ 前向传播
model(frames) → outputs
[1, num_classes]
例如 [1, 4] = [[2.3, -0.5, 1.1, -1.2]]
4️⃣ Softmax
F.softmax(outputs, dim=1) → prob
[1, 4] = [[0.718, 0.044, 0.216, 0.022]]
5️⃣ Argmax
torch.argmax(prob, dim=1) → pred
[1] = [0]
6️⃣ 标签映射
inv_label_map[pred.item()] → pred_origin
0 → 'car'
7️⃣ 统计
if label == pred: correct += 1
total += 1
8️⃣ 输出
print(f"{i} | {true_origin} | {pred_origin} | {status}")六、脚本源码
6.1 convert_detrac.py
import os
import xml.etree.ElementTree as ET
import pandas as pd
from sklearn.model_selection import train_test_split
# --- 路径配置 ---
BASE_PATH = os.path.dirname(os.path.abspath(__file__))
DATA_ROOT = os.path.join(BASE_PATH, "data/UA-DETRAC/DETRAC-Images")
XML_ROOT = os.path.join(BASE_PATH, "data/UA-DETRAC/DETRAC-Train-Annotations-XML")
OUTPUT_DIR = os.path.join(BASE_PATH, "data/UA-DETRAC/annotations")
os.makedirs(OUTPUT_DIR, exist_ok=True)
VEHICLE_MAP = {'car': 0, 'bus': 1, 'van': 2, 'others': 3}
def get_major_class(xml_path):
"""
解析XML文件,统计视频中出现最多的车辆类型
DETRAC XML结构:
<sequence>
<frame num="1">
<target_list>
<target id="1">
<box .../>
<attribute vehicle_type="car" .../>
</target>
</target_list>
</frame>
</sequence>
"""
try:
tree = ET.parse(xml_path)
root = tree.getroot()
counts = {'car': 0, 'bus': 0, 'van': 0, 'others': 0}
# 正确的遍历方式:遍历所有frame中的target_list/target/attribute
for frame in root.findall('.//frame'):
target_list = frame.find('target_list')
if target_list is not None:
for target in target_list.findall('target'):
attribute = target.find('attribute')
if attribute is not None:
v_type = attribute.get('vehicle_type')
if v_type in counts:
counts[v_type] += 1
else:
counts['others'] += 1
# 调试信息:打印统计结果
total = sum(counts.values())
if total > 0:
print(f" XML解析成功: {os.path.basename(xml_path)}")
print(f" 车辆统计: {counts}")
# 返回出现次数最多的类别对应的数字标签
major_class = max(counts, key=counts.get)
return VEHICLE_MAP[major_class]
except Exception as e:
print(f" ⚠️ XML解析失败 {xml_path}: {e}")
return 0 # 解析失败时默认返回'car'类别
def generate_csv():
data_list = []
print("=" * 60)
print("开始处理UA-DETRAC数据集...")
print("=" * 60)
# Step 1: 筛选有效视频文件夹(以MVI_开头)
video_folders = [f for f in os.listdir(DATA_ROOT)
if os.path.isdir(os.path.join(DATA_ROOT, f)) and f.startswith('MVI')]
print(f"\n📁 找到 {len(video_folders)} 个候选视频文件夹")
print(f"📂 数据目录: {DATA_ROOT}")
print(f"📄 标注目录: {XML_ROOT}")
print()
for idx, folder in enumerate(video_folders):
folder_path = os.path.join(DATA_ROOT, folder)
# Step 2: 匹配XML标注文件(兼容_v3后缀)
xml_file = f"{folder}_v3.xml" if os.path.exists(os.path.join(XML_ROOT, f"{folder}_v3.xml")) else f"{folder}.xml"
xml_path = os.path.join(XML_ROOT, xml_file)
if not os.path.exists(xml_path):
print(f"⚠️ [{idx + 1}/{len(video_folders)}] {folder}: 未找到XML文件,跳过")
continue
# Step 3: 统计有效图像帧数,过滤短视频
images = [img for img in os.listdir(folder_path) if img.lower().endswith(('.jpg', '.jpeg'))]
if len(images) < 8: # 帧数太少无法满足f8预训练模型输入
print(f"⚠️ [{idx + 1}/{len(video_folders)}] {folder}: 帧数不足({len(images)}<8),跳过")
continue
# Step 4: 获取主类别标签
print(f"[{idx + 1}/{len(video_folders)}] 处理: {folder} ({len(images)}帧)")
label = get_major_class(xml_path)
data_list.append([folder, len(images), label])
# 每处理10个视频显示一次进度摘要
if (idx + 1) % 10 == 0:
labels_count = {}
for _, _, l in data_list:
labels_count[l] = labels_count.get(l, 0) + 1
print(f" 进度: 已处理{len(data_list)}个视频,标签分布: {labels_count}\n")
print("\n" + "=" * 60)
print("处理完成!统计信息:")
print("=" * 60)
if not data_list:
print("\n❌ 错误:没有成功处理任何视频!")
print(f"请检查以下路径是否正确:")
print(f" - 数据目录: {DATA_ROOT}")
print(f" - 标注目录: {XML_ROOT}")
print(f"\n建议执行以下命令检查:")
print(f" ls {DATA_ROOT} | head -5")
print(f" ls {XML_ROOT} | head -5")
return
# 统计标签分布
label_stats = {}
for _, _, label in data_list:
label_stats[label] = label_stats.get(label, 0) + 1
print(f"\n✅ 成功处理 {len(data_list)} 个视频")
print(f"📊 标签分布:")
reverse_map = {v: k for k, v in VEHICLE_MAP.items()}
for label in sorted(label_stats.keys()):
print(f" {reverse_map[label]} (标签{label}): {label_stats[label]} 个")
# Step 5: 构建DataFrame并划分训练/验证集
df = pd.DataFrame(data_list, columns=['path', 'frames', 'label'])
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
# Step 6: 保存为无表头CSV
train_df.to_csv(os.path.join(OUTPUT_DIR, "train.csv"), index=False, header=False)
val_df.to_csv(os.path.join(OUTPUT_DIR, "val.csv"), index=False, header=False)
print(f"\n💾 文件已保存:")
print(f" 训练集: {os.path.join(OUTPUT_DIR, 'train.csv')} ({len(train_df)}条)")
print(f" 验证集: {os.path.join(OUTPUT_DIR, 'val.csv')} ({len(val_df)}条)")
print(f" 输出目录: {OUTPUT_DIR}")
# 显示前5行样例
print(f"\n📋 训练集前5行样例:")
print(train_df.head().to_string(index=False))
if __name__ == "__main__":
generate_csv()控制台打印:
(videomamba) chenchenyang@musk:~/pro26/VideoMamba-main$ python convert_detrac.py
============================================================
开始处理UA-DETRAC数据集...
============================================================
📁 找到 100 个候选视频文件夹
📂 数据目录: /home/chenchenyang/pro26/VideoMamba-main/data/UA-DETRAC/DETRAC-Images
📄 标注目录: /home/chenchenyang/pro26/VideoMamba-main/data/UA-DETRAC/DETRAC-Train-Annotations-XML
[1/100] 处理: MVI_20011 (664帧)
XML解析成功: MVI_20011.xml
车辆统计: {'car': 7053, 'bus': 95, 'van': 296, 'others': 211}
[2/100] 处理: MVI_20012 (936帧)
XML解析成功: MVI_20012.xml
车辆统计: {'car': 6481, 'bus': 1337, 'van': 790, 'others': 0}
[3/100] 处理: MVI_20032 (437帧)
XML解析成功: MVI_20032.xml
车辆统计: {'car': 1657, 'bus': 0, 'van': 0, 'others': 0}
[4/100] 处理: MVI_20033 (784帧)
XML解析成功: MVI_20033.xml
车辆统计: {'car': 4188, 'bus': 327, 'van': 759, 'others': 0}
[5/100] 处理: MVI_20034 (800帧)
XML解析成功: MVI_20034.xml
车辆统计: {'car': 8073, 'bus': 1373, 'van': 488, 'others': 0}
[6/100] 处理: MVI_20035 (800帧)
XML解析成功: MVI_20035.xml
车辆统计: {'car': 10396, 'bus': 0, 'van': 1459, 'others': 0}
[7/100] 处理: MVI_20051 (906帧)
XML解析成功: MVI_20051.xml
车辆统计: {'car': 7738, 'bus': 906, 'van': 290, 'others': 0}
[8/100] 处理: MVI_20052 (694帧)
XML解析成功: MVI_20052.xml
车辆统计: {'car': 6982, 'bus': 694, 'van': 683, 'others': 0}
[9/100] 处理: MVI_20061 (800帧)
XML解析成功: MVI_20061.xml
车辆统计: {'car': 7348, 'bus': 873, 'van': 1035, 'others': 0}
[10/100] 处理: MVI_20062 (800帧)
XML解析成功: MVI_20062.xml
车辆统计: {'car': 3049, 'bus': 501, 'van': 725, 'others': 187}
进度: 已处理10个视频,标签分布: {0: 10}
[11/100] 处理: MVI_20063 (800帧)
XML解析成功: MVI_20063.xml
车辆统计: {'car': 4789, 'bus': 771, 'van': 712, 'others': 120}
[12/100] 处理: MVI_20064 (800帧)
XML解析成功: MVI_20064.xml
车辆统计: {'car': 13478, 'bus': 241, 'van': 465, 'others': 0}
[13/100] 处理: MVI_20065 (1200帧)
XML解析成功: MVI_20065.xml
车辆统计: {'car': 14205, 'bus': 1252, 'van': 1699, 'others': 0}
⚠️ [14/100] MVI_39031: 未找到XML文件,跳过
⚠️ [15/100] MVI_39051: 未找到XML文件,跳过
⚠️ [16/100] MVI_39211: 未找到XML文件,跳过
⚠️ [17/100] MVI_39271: 未找到XML文件,跳过
⚠️ [18/100] MVI_39311: 未找到XML文件,跳过
⚠️ [19/100] MVI_39371: 未找到XML文件,跳过
⚠️ [20/100] MVI_39401: 未找到XML文件,跳过
⚠️ [21/100] MVI_39501: 未找到XML文件,跳过
⚠️ [22/100] MVI_39511: 未找到XML文件,跳过
[23/100] 处理: MVI_39761 (1660帧)
XML解析成功: MVI_39761.xml
车辆统计: {'car': 3316, 'bus': 402, 'van': 0, 'others': 0}
[24/100] 处理: MVI_39771 (570帧)
XML解析成功: MVI_39771.xml
车辆统计: {'car': 2933, 'bus': 511, 'van': 161, 'others': 0}
[25/100] 处理: MVI_39781 (1865帧)
XML解析成功: MVI_39781.xml
车辆统计: {'car': 4707, 'bus': 2628, 'van': 91, 'others': 221}
[26/100] 处理: MVI_39801 (885帧)
XML解析成功: MVI_39801.xml
车辆统计: {'car': 4828, 'bus': 0, 'van': 0, 'others': 25}
[27/100] 处理: MVI_39811 (1070帧)
XML解析成功: MVI_39811.xml
车辆统计: {'car': 599, 'bus': 0, 'van': 0, 'others': 0}
[28/100] 处理: MVI_39821 (880帧)
XML解析成功: MVI_39821.xml
车辆统计: {'car': 3405, 'bus': 181, 'van': 609, 'others': 0}
[29/100] 处理: MVI_39851 (1420帧)
XML解析成功: MVI_39851.xml
车辆统计: {'car': 4007, 'bus': 777, 'van': 342, 'others': 0}
[30/100] 处理: MVI_39861 (745帧)
XML解析成功: MVI_39861.xml
车辆统计: {'car': 2298, 'bus': 96, 'van': 0, 'others': 0}
进度: 已处理21个视频,标签分布: {0: 21}
[31/100] 处理: MVI_39931 (1270帧)
XML解析成功: MVI_39931.xml
车辆统计: {'car': 3495, 'bus': 436, 'van': 0, 'others': 0}
[32/100] 处理: MVI_40131 (1645帧)
XML解析成功: MVI_40131.xml
车辆统计: {'car': 12117, 'bus': 2238, 'van': 969, 'others': 0}
[33/100] 处理: MVI_40141 (1600帧)
XML解析成功: MVI_40141.xml
车辆统计: {'car': 4916, 'bus': 0, 'van': 1306, 'others': 0}
[34/100] 处理: MVI_40152 (1750帧)
XML解析成功: MVI_40152.xml
车辆统计: {'car': 4599, 'bus': 256, 'van': 631, 'others': 126}
[35/100] 处理: MVI_40161 (1490帧)
XML解析成功: MVI_40161.xml
车辆统计: {'car': 4803, 'bus': 847, 'van': 975, 'others': 0}
[36/100] 处理: MVI_40162 (1765帧)
XML解析成功: MVI_40162.xml
车辆统计: {'car': 9380, 'bus': 1427, 'van': 454, 'others': 0}
[37/100] 处理: MVI_40171 (1150帧)
XML解析成功: MVI_40171.xml
车辆统计: {'car': 7084, 'bus': 1697, 'van': 147, 'others': 0}
[38/100] 处理: MVI_40181 (1700帧)
XML解析成功: MVI_40181.xml
车辆统计: {'car': 4261, 'bus': 2350, 'van': 417, 'others': 96}
[39/100] 处理: MVI_40191 (2495帧)
XML解析成功: MVI_40191.xml
车辆统计: {'car': 33647, 'bus': 0, 'van': 4633, 'others': 121}
[40/100] 处理: MVI_40192 (2195帧)
XML解析成功: MVI_40192.xml
车辆统计: {'car': 23573, 'bus': 346, 'van': 4097, 'others': 167}
进度: 已处理31个视频,标签分布: {0: 31}
[41/100] 处理: MVI_40201 (925帧)
XML解析成功: MVI_40201.xml
车辆统计: {'car': 10141, 'bus': 0, 'van': 784, 'others': 0}
[42/100] 处理: MVI_40204 (1225帧)
XML解析成功: MVI_40204.xml
车辆统计: {'car': 19387, 'bus': 267, 'van': 2774, 'others': 0}
[43/100] 处理: MVI_40211 (1950帧)
XML解析成功: MVI_40211.xml
车辆统计: {'car': 5792, 'bus': 92, 'van': 977, 'others': 31}
[44/100] 处理: MVI_40212 (1690帧)
XML解析成功: MVI_40212.xml
车辆统计: {'car': 6800, 'bus': 188, 'van': 870, 'others': 21}
[45/100] 处理: MVI_40213 (1790帧)
XML解析成功: MVI_40213.xml
车辆统计: {'car': 6301, 'bus': 133, 'van': 1124, 'others': 144}
[46/100] 处理: MVI_40241 (2320帧)
XML解析成功: MVI_40241.xml
车辆统计: {'car': 18502, 'bus': 71, 'van': 2596, 'others': 178}
[47/100] 处理: MVI_40243 (1265帧)
XML解析成功: MVI_40243.xml
车辆统计: {'car': 9047, 'bus': 171, 'van': 1259, 'others': 71}
[48/100] 处理: MVI_40244 (1345帧)
XML解析成功: MVI_40244.xml
车辆统计: {'car': 7885, 'bus': 122, 'van': 804, 'others': 0}
⚠️ [49/100] MVI_40701: 未找到XML文件,跳过
⚠️ [50/100] MVI_40711: 未找到XML文件,跳过
⚠️ [51/100] MVI_40712: 未找到XML文件,跳过
⚠️ [52/100] MVI_40714: 未找到XML文件,跳过
[53/100] 处理: MVI_40732 (2120帧)
XML解析成功: MVI_40732.xml
车辆统计: {'car': 10154, 'bus': 730, 'van': 276, 'others': 352}
⚠️ [54/100] MVI_40742: 未找到XML文件,跳过
⚠️ [55/100] MVI_40743: 未找到XML文件,跳过
[56/100] 处理: MVI_40751 (1145帧)
XML解析成功: MVI_40751.xml
车辆统计: {'car': 5418, 'bus': 1836, 'van': 41, 'others': 91}
⚠️ [57/100] MVI_40761: 未找到XML文件,跳过
⚠️ [58/100] MVI_40762: 未找到XML文件,跳过
⚠️ [59/100] MVI_40763: 未找到XML文件,跳过
⚠️ [60/100] MVI_40771: 未找到XML文件,跳过
⚠️ [61/100] MVI_40772: 未找到XML文件,跳过
⚠️ [62/100] MVI_40773: 未找到XML文件,跳过
⚠️ [63/100] MVI_40774: 未找到XML文件,跳过
⚠️ [64/100] MVI_40775: 未找到XML文件,跳过
⚠️ [65/100] MVI_40792: 未找到XML文件,跳过
⚠️ [66/100] MVI_40793: 未找到XML文件,跳过
⚠️ [67/100] MVI_40851: 未找到XML文件,跳过
⚠️ [68/100] MVI_40852: 未找到XML文件,跳过
⚠️ [69/100] MVI_40853: 未找到XML文件,跳过
⚠️ [70/100] MVI_40854: 未找到XML文件,跳过
⚠️ [71/100] MVI_40855: 未找到XML文件,跳过
⚠️ [72/100] MVI_40863: 未找到XML文件,跳过
⚠️ [73/100] MVI_40864: 未找到XML文件,跳过
[74/100] 处理: MVI_40871 (1720帧)
XML解析成功: MVI_40871.xml
车辆统计: {'car': 29634, 'bus': 1720, 'van': 5271, 'others': 0}
⚠️ [75/100] MVI_40891: 未找到XML文件,跳过
⚠️ [76/100] MVI_40901: 未找到XML文件,跳过
⚠️ [77/100] MVI_40902: 未找到XML文件,跳过
⚠️ [78/100] MVI_40903: 未找到XML文件,跳过
⚠️ [79/100] MVI_40904: 未找到XML文件,跳过
⚠️ [80/100] MVI_40905: 未找到XML文件,跳过
[81/100] 处理: MVI_40962 (1875帧)
XML解析成功: MVI_40962.xml
车辆统计: {'car': 7009, 'bus': 96, 'van': 475, 'others': 0}
[82/100] 处理: MVI_40963 (1820帧)
XML解析成功: MVI_40963.xml
车辆统计: {'car': 9906, 'bus': 726, 'van': 1007, 'others': 0}
[83/100] 处理: MVI_40981 (1995帧)
XML解析成功: MVI_40981.xml
车辆统计: {'car': 9248, 'bus': 111, 'van': 990, 'others': 0}
[84/100] 处理: MVI_40991 (1820帧)
XML解析成功: MVI_40991.xml
车辆统计: {'car': 4482, 'bus': 0, 'van': 0, 'others': 0}
[85/100] 处理: MVI_40992 (2160帧)
XML解析成功: MVI_40992.xml
车辆统计: {'car': 4926, 'bus': 0, 'van': 136, 'others': 0}
[86/100] 处理: MVI_41063 (1505帧)
XML解析成功: MVI_41063.xml
车辆统计: {'car': 8447, 'bus': 76, 'van': 1338, 'others': 187}
[87/100] 处理: MVI_41073 (1825帧)
XML解析成功: MVI_41073.xml
车辆统计: {'car': 9143, 'bus': 0, 'van': 1041, 'others': 111}
[88/100] 处理: MVI_63521 (2055帧)
XML解析成功: MVI_63521.xml
车辆统计: {'car': 11806, 'bus': 2099, 'van': 962, 'others': 221}
[89/100] 处理: MVI_63525 (985帧)
XML解析成功: MVI_63525.xml
车辆统计: {'car': 2097, 'bus': 1161, 'van': 212, 'others': 0}
[90/100] 处理: MVI_63544 (1160帧)
XML解析成功: MVI_63544.xml
车辆统计: {'car': 1524, 'bus': 121, 'van': 318, 'others': 0}
进度: 已处理52个视频,标签分布: {0: 52}
[91/100] 处理: MVI_63552 (1150帧)
XML解析成功: MVI_63552.xml
车辆统计: {'car': 5482, 'bus': 0, 'van': 1540, 'others': 91}
[92/100] 处理: MVI_63553 (1405帧)
XML解析成功: MVI_63553.xml
车辆统计: {'car': 9208, 'bus': 167, 'van': 1338, 'others': 62}
[93/100] 处理: MVI_63554 (1445帧)
XML解析成功: MVI_63554.xml
车辆统计: {'car': 8359, 'bus': 0, 'van': 1457, 'others': 31}
[94/100] 处理: MVI_63561 (1285帧)
XML解析成功: MVI_63561.xml
车辆统计: {'car': 8578, 'bus': 0, 'van': 1007, 'others': 218}
[95/100] 处理: MVI_63562 (1185帧)
XML解析成功: MVI_63562.xml
车辆统计: {'car': 5650, 'bus': 66, 'van': 877, 'others': 87}
[96/100] 处理: MVI_63563 (1390帧)
XML解析成功: MVI_63563.xml
车辆统计: {'car': 8322, 'bus': 31, 'van': 1053, 'others': 158}
⚠️ [97/100] MVI_39361: 未找到XML文件,跳过
[98/100] 处理: MVI_40172 (2635帧)
XML解析成功: MVI_40172.xml
车辆统计: {'car': 16671, 'bus': 626, 'van': 644, 'others': 201}
[99/100] 处理: MVI_40752 (2025帧)
XML解析成功: MVI_40752.xml
车辆统计: {'car': 14529, 'bus': 479, 'van': 1647, 'others': 197}
⚠️ [100/100] MVI_40892: 未找到XML文件,跳过
============================================================
处理完成!统计信息:
============================================================
✅ 成功处理 60 个视频
📊 标签分布:
car (标签0): 60 个
💾 文件已保存:
训练集: /home/chenchenyang/pro26/VideoMamba-main/data/UA-DETRAC/annotations/train.csv (48条)
验证集: /home/chenchenyang/pro26/VideoMamba-main/data/UA-DETRAC/annotations/val.csv (12条)
输出目录: /home/chenchenyang/pro26/VideoMamba-main/data/UA-DETRAC/annotations
📋 训练集前5行样例:
path frames label
MVI_40201 925 0
MVI_20033 784 0
MVI_63552 1150 0
MVI_39811 1070 0
MVI_20061 800 0
6.2 train_detrac.py
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from datasets.detrac_loader import DetracImageDataset
from models.videomamba import videomamba_tiny
def train():
# --- 配置区 ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 如果还是报 ALLOC_FAILED,请尝试把 batch_size 设为 1
batch_size = 2
epochs = 30
lr = 1e-5
# 路径配置
BASE = "/home/chenchenyang/pro26/VideoMamba-main"
train_csv = f"{BASE}/data/UA-DETRAC/annotations/train.csv"
img_prefix = f"{BASE}/data/UA-DETRAC/DETRAC-Images"
ckpt_path = f"{BASE}/checkpoints/videomamba_t16_k400_f8_res224.pth"
output_dir = f"{BASE}/outputs/detrac_checkpoints"
os.makedirs(output_dir, exist_ok=True)
# --- 数据准备 ---
dataset = DetracImageDataset(train_csv, prefix=img_prefix, mode='train')
# 自动获取类别数量
num_classes = len(dataset.label_map)
print(f"Detected Number of Classes: {num_classes}")
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
# --- 模型加载 ---
model = videomamba_tiny(num_classes=num_classes)
if os.path.exists(ckpt_path):
print(f"Loading weights from {ckpt_path}")
checkpoint = torch.load(ckpt_path, map_location='cpu')
state_dict = checkpoint['model'] if 'model' in checkpoint else checkpoint
# 移除分类头权重
for k in ['head.weight', 'head.bias']:
if k in state_dict:
del state_dict[k]
msg = model.load_state_dict(state_dict, strict=False)
print(f"Checkpoint loaded: {msg}")
model.to(device)
# --- 优化器 ---
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
# --- 训练循环 ---
print("Start Training...")
for epoch in range(epochs):
model.train()
epoch_loss = 0
for i, (frames, labels) in enumerate(loader):
# 确保显存干净
frames = frames.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
# 前向传播
outputs = model(frames)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
if i % 5 == 0:
print(f"Epoch [{epoch}] Batch [{i}/{len(loader)}] Loss: {loss.item():.4f}")
# 保存模型
save_path = os.path.join(output_dir, f"mamba_detrac_epoch_{epoch}.pth")
torch.save(model.state_dict(), save_path)
print(f"Epoch {epoch} Average Loss: {epoch_loss / len(loader):.4f}")
if __name__ == "__main__":
# 清理显存缓存后再开始
torch.cuda.empty_cache()
train()控制台打印信息:
(videomamba) chenchenyang@musk:~/pro26/VideoMamba-main/videomamba/video_sm$ python train_detrac.py
Dataset Loaded: 48 samples.
Label Mapping: {437: 0, 570: 1, 694: 2, 745: 3, 784: 4, 800: 5, 880: 6, 885: 7, 906: 8, 925: 9, 936: 10, 1070: 11, 1145: 12, 1150: 13, 1160: 14, 1185: 15, 1225: 16, 1265: 17, 1270: 18, 1285: 19, 1345: 20, 1405: 21, 1420: 22, 1490: 23, 1505: 24, 1600: 25, 1645: 26, 1690: 27, 1700: 28, 1720: 29, 1750: 30, 1765: 31, 1790: 32, 1820: 33, 1865: 34, 1875: 35, 1995: 36, 2025: 37, 2055: 38, 2120: 39, 2195: 40, 2495: 41, 2635: 42} (Original -> Processed)
Detected Number of Classes: 43
Use checkpoint: False
Checkpoint number: 0
Loading weights from /home/chenchenyang/pro26/VideoMamba-main/checkpoints/videomamba_t16_k400_f8_res224.pth
Checkpoint loaded: _IncompatibleKeys(missing_keys=['head.weight', 'head.bias'], unexpected_keys=[])
Start Training...
Epoch [0] Batch [0/24] Loss: 3.6546
Epoch [0] Batch [5/24] Loss: 3.7955
Epoch [0] Batch [10/24] Loss: 4.0790
Epoch [0] Batch [15/24] Loss: 3.4785
Epoch [0] Batch [20/24] Loss: 3.7999
Epoch 0 Average Loss: 3.8162
Epoch [1] Batch [0/24] Loss: 3.3199
Epoch [1] Batch [5/24] Loss: 3.7698
Epoch [1] Batch [10/24] Loss: 3.9962
Epoch [1] Batch [15/24] Loss: 3.6377
Epoch [1] Batch [20/24] Loss: 3.6275
Epoch 1 Average Loss: 3.7062
Epoch [2] Batch [0/24] Loss: 3.3535
Epoch [2] Batch [5/24] Loss: 3.3764
Epoch [2] Batch [10/24] Loss: 3.5017
Epoch [2] Batch [15/24] Loss: 3.8081
Epoch [2] Batch [20/24] Loss: 3.0009
Epoch 2 Average Loss: 3.5204
Epoch [3] Batch [0/24] Loss: 3.7942
Epoch [3] Batch [5/24] Loss: 3.9798
Epoch [3] Batch [10/24] Loss: 3.7204
Epoch [3] Batch [15/24] Loss: 3.1437
Epoch [3] Batch [20/24] Loss: 3.2389
Epoch 3 Average Loss: 3.4369
Epoch [4] Batch [0/24] Loss: 4.0305
Epoch [4] Batch [5/24] Loss: 3.2542
Epoch [4] Batch [10/24] Loss: 2.9418
Epoch [4] Batch [15/24] Loss: 3.3940
Epoch [4] Batch [20/24] Loss: 3.8373
Epoch 4 Average Loss: 3.3070
Epoch [5] Batch [0/24] Loss: 3.4846
Epoch [5] Batch [5/24] Loss: 2.6126
Epoch [5] Batch [10/24] Loss: 3.4506
Epoch [5] Batch [15/24] Loss: 3.2055
Epoch [5] Batch [20/24] Loss: 2.9002
Epoch 5 Average Loss: 3.1427
Epoch [6] Batch [0/24] Loss: 2.3080
Epoch [6] Batch [5/24] Loss: 3.2808
Epoch [6] Batch [10/24] Loss: 2.9535
Epoch [6] Batch [15/24] Loss: 3.8067
Epoch [6] Batch [20/24] Loss: 3.3424
Epoch 6 Average Loss: 3.0210
Epoch [7] Batch [0/24] Loss: 2.7884
Epoch [7] Batch [5/24] Loss: 3.4619
Epoch [7] Batch [10/24] Loss: 3.0369
Epoch [7] Batch [15/24] Loss: 3.2042
Epoch [7] Batch [20/24] Loss: 3.1106
Epoch 7 Average Loss: 2.8892
Epoch [8] Batch [0/24] Loss: 2.5874
Epoch [8] Batch [5/24] Loss: 3.1701
Epoch [8] Batch [10/24] Loss: 2.8044
Epoch [8] Batch [15/24] Loss: 2.2516
Epoch [8] Batch [20/24] Loss: 1.8578
Epoch 8 Average Loss: 2.7995
Epoch [9] Batch [0/24] Loss: 3.2771
Epoch [9] Batch [5/24] Loss: 3.1957
Epoch [9] Batch [10/24] Loss: 2.7424
Epoch [9] Batch [15/24] Loss: 2.4377
Epoch [9] Batch [20/24] Loss: 1.7674
Epoch 9 Average Loss: 2.7260
Epoch [10] Batch [0/24] Loss: 2.8704
Epoch [10] Batch [5/24] Loss: 2.9154
Epoch [10] Batch [10/24] Loss: 2.6658
Epoch [10] Batch [15/24] Loss: 3.4208
Epoch [10] Batch [20/24] Loss: 2.3008
Epoch 10 Average Loss: 2.5322
Epoch [11] Batch [0/24] Loss: 2.8190
Epoch [11] Batch [5/24] Loss: 2.5571
Epoch [11] Batch [10/24] Loss: 1.9972
Epoch [11] Batch [15/24] Loss: 3.4188
Epoch [11] Batch [20/24] Loss: 2.6478
Epoch 11 Average Loss: 2.6028
Epoch [12] Batch [0/24] Loss: 1.8262
Epoch [12] Batch [5/24] Loss: 2.8447
Epoch [12] Batch [10/24] Loss: 3.2256
Epoch [12] Batch [15/24] Loss: 1.9309
Epoch [12] Batch [20/24] Loss: 2.4237
Epoch 12 Average Loss: 2.3503
Epoch [13] Batch [0/24] Loss: 2.7680
Epoch [13] Batch [5/24] Loss: 2.1569
Epoch [13] Batch [10/24] Loss: 1.7677
Epoch [13] Batch [15/24] Loss: 2.8003
Epoch [13] Batch [20/24] Loss: 1.0333
Epoch 13 Average Loss: 2.3477
Epoch [14] Batch [0/24] Loss: 2.1494
Epoch [14] Batch [5/24] Loss: 1.3228
Epoch [14] Batch [10/24] Loss: 2.5616
Epoch [14] Batch [15/24] Loss: 1.6309
Epoch [14] Batch [20/24] Loss: 3.3164
Epoch 14 Average Loss: 2.2747
Epoch [15] Batch [0/24] Loss: 2.3707
Epoch [15] Batch [5/24] Loss: 2.6382
Epoch [15] Batch [10/24] Loss: 1.8941
Epoch [15] Batch [15/24] Loss: 2.5973
Epoch [15] Batch [20/24] Loss: 2.5639
Epoch 15 Average Loss: 2.0765
Epoch [16] Batch [0/24] Loss: 1.7345
Epoch [16] Batch [5/24] Loss: 2.1229
Epoch [16] Batch [10/24] Loss: 2.0360
Epoch [16] Batch [15/24] Loss: 0.9865
Epoch [16] Batch [20/24] Loss: 2.6630
Epoch 16 Average Loss: 2.0696
Epoch [17] Batch [0/24] Loss: 2.3109
Epoch [17] Batch [5/24] Loss: 1.2731
Epoch [17] Batch [10/24] Loss: 0.9292
Epoch [17] Batch [15/24] Loss: 2.5292
Epoch [17] Batch [20/24] Loss: 1.6114
Epoch 17 Average Loss: 1.9946
Epoch [18] Batch [0/24] Loss: 2.1993
Epoch [18] Batch [5/24] Loss: 2.2475
Epoch [18] Batch [10/24] Loss: 2.0214
Epoch [18] Batch [15/24] Loss: 1.9476
Epoch [18] Batch [20/24] Loss: 1.9298
Epoch 18 Average Loss: 1.8699
Epoch [19] Batch [0/24] Loss: 2.0948
Epoch [19] Batch [5/24] Loss: 2.0984
Epoch [19] Batch [10/24] Loss: 2.4701
Epoch [19] Batch [15/24] Loss: 2.6715
Epoch [19] Batch [20/24] Loss: 2.2770
Epoch 19 Average Loss: 1.8093
Epoch [20] Batch [0/24] Loss: 1.9324
Epoch [20] Batch [5/24] Loss: 2.2716
Epoch [20] Batch [10/24] Loss: 1.9846
Epoch [20] Batch [15/24] Loss: 1.7885
Epoch [20] Batch [20/24] Loss: 2.3410
Epoch 20 Average Loss: 1.7327
Epoch [21] Batch [0/24] Loss: 2.1571
Epoch [21] Batch [5/24] Loss: 1.7383
Epoch [21] Batch [10/24] Loss: 2.2885
Epoch [21] Batch [15/24] Loss: 1.5238
Epoch [21] Batch [20/24] Loss: 2.1028
Epoch 21 Average Loss: 1.7622
Epoch [22] Batch [0/24] Loss: 1.5601
Epoch [22] Batch [5/24] Loss: 1.4831
Epoch [22] Batch [10/24] Loss: 2.4486
Epoch [22] Batch [15/24] Loss: 1.4114
Epoch [22] Batch [20/24] Loss: 1.1914
Epoch 22 Average Loss: 1.6845
Epoch [23] Batch [0/24] Loss: 1.7578
Epoch [23] Batch [5/24] Loss: 1.6144
Epoch [23] Batch [10/24] Loss: 1.9124
Epoch [23] Batch [15/24] Loss: 1.9735
Epoch [23] Batch [20/24] Loss: 1.9652
Epoch 23 Average Loss: 1.5833
Epoch [24] Batch [0/24] Loss: 1.3146
Epoch [24] Batch [5/24] Loss: 1.3311
Epoch [24] Batch [10/24] Loss: 1.9232
Epoch [24] Batch [15/24] Loss: 1.8452
Epoch [24] Batch [20/24] Loss: 1.6920
Epoch 24 Average Loss: 1.6171
Epoch [25] Batch [0/24] Loss: 1.2637
Epoch [25] Batch [5/24] Loss: 1.8589
Epoch [25] Batch [10/24] Loss: 1.8562
Epoch [25] Batch [15/24] Loss: 1.7846
Epoch [25] Batch [20/24] Loss: 1.0790
Epoch 25 Average Loss: 1.5976
Epoch [26] Batch [0/24] Loss: 2.0882
Epoch [26] Batch [5/24] Loss: 1.6817
Epoch [26] Batch [10/24] Loss: 1.4747
Epoch [26] Batch [15/24] Loss: 1.2525
Epoch [26] Batch [20/24] Loss: 0.7680
Epoch 26 Average Loss: 1.5485
Epoch [27] Batch [0/24] Loss: 1.6124
Epoch [27] Batch [5/24] Loss: 0.6368
Epoch [27] Batch [10/24] Loss: 1.2857
Epoch [27] Batch [15/24] Loss: 2.3080
Epoch [27] Batch [20/24] Loss: 1.5885
Epoch 27 Average Loss: 1.4144
Epoch [28] Batch [0/24] Loss: 1.5449
Epoch [28] Batch [5/24] Loss: 1.9299
Epoch [28] Batch [10/24] Loss: 1.0669
Epoch [28] Batch [15/24] Loss: 0.9294
Epoch [28] Batch [20/24] Loss: 1.6587
Epoch 28 Average Loss: 1.4043
Epoch [29] Batch [0/24] Loss: 1.5119
Epoch [29] Batch [5/24] Loss: 0.9596
Epoch [29] Batch [10/24] Loss: 0.7105
Epoch [29] Batch [15/24] Loss: 1.7968
Epoch [29] Batch [20/24] Loss: 1.9556
Epoch 29 Average Loss: 1.3969
6.3 val_detrac.py
import os
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from datasets.detrac_loader import DetracImageDataset
from models.videomamba import videomamba_tiny
def inference():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 1. 配置路径 (确保与训练时一致) ---
BASE = "/home/chenchenyang/pro26/VideoMamba-main"
test_csv = f"{BASE}/data/UA-DETRAC/annotations/train.csv" # 先用训练集测,看有没有过拟合
img_prefix = f"{BASE}/data/UA-DETRAC/DETRAC-Images"
# 加载你刚刚跑出来的第 29 轮权重
model_path = f"{BASE}/outputs/detrac_checkpoints/mamba_detrac_epoch_29.pth"
# --- 2. 加载数据 ---
# mode='val' 会使用中间抽帧,结果更稳定
dataset = DetracImageDataset(test_csv, prefix=img_prefix, mode='val')
loader = DataLoader(dataset, batch_size=1, shuffle=False)
# 获取反向映射表 (ID -> 原始标签)
inv_label_map = {v: k for k, v in dataset.label_map.items()}
num_classes = len(dataset.label_map)
# --- 3. 初始化模型并加载权重 ---
model = videomamba_tiny(num_classes=num_classes)
if os.path.exists(model_path):
print(f"Loading trained model from {model_path}")
model.load_state_dict(torch.load(model_path, map_location='cpu'))
else:
print("Model file not found!")
return
model.to(device)
model.eval()
# --- 4. 开始推理 ---
correct = 0
total = 0
print(f"\n{'Sample Index':<15} | {'True Label':<12} | {'Pred Label':<12} | {'Status'}")
print("-" * 60)
with torch.no_grad():
for i, (frames, label) in enumerate(loader):
frames = frames.to(device)
label = label.to(device)
outputs = model(frames)
prob = F.softmax(outputs, dim=1)
pred = torch.argmax(prob, dim=1)
true_origin = inv_label_map[label.item()]
pred_origin = inv_label_map[pred.item()]
status = "✅" if label == pred else "❌"
if label == pred:
correct += 1
total += 1
print(f"{i:<15} | {true_origin:<12} | {pred_origin:<12} | {status}")
acc = 100 * correct / total
print("-" * 60)
print(f"Final Accuracy: {acc:.2f}% ({correct}/{total})")
if __name__ == "__main__":
inference()控制台打印:
(videomamba) chenchenyang@musk:~/pro26/VideoMamba-main/videomamba/video_sm$ python val_detrac.py
Dataset Loaded: 48 samples.
Label Mapping: {437: 0, 570: 1, 694: 2, 745: 3, 784: 4, 800: 5, 880: 6, 885: 7, 906: 8, 925: 9, 936: 10, 1070: 11, 1145: 12, 1150: 13, 1160: 14, 1185: 15, 1225: 16, 1265: 17, 1270: 18, 1285: 19, 1345: 20, 1405: 21, 1420: 22, 1490: 23, 1505: 24, 1600: 25, 1645: 26, 1690: 27, 1700: 28, 1720: 29, 1750: 30, 1765: 31, 1790: 32, 1820: 33, 1865: 34, 1875: 35, 1995: 36, 2025: 37, 2055: 38, 2120: 39, 2195: 40, 2495: 41, 2635: 42} (Original -> Processed)
Use checkpoint: False
Checkpoint number: 0
Loading trained model from /home/chenchenyang/pro26/VideoMamba-main/outputs/detrac_checkpoints/mamba_detrac_epoch_29.pth
Sample Index | True Label | Pred Label | Status
------------------------------------------------------------
0 | 925 | 1225 | ❌
1 | 784 | 784 | ✅
2 | 1150 | 1405 | ❌
3 | 1070 | 1070 | ✅
4 | 800 | 800 | ✅
5 | 906 | 694 | ❌
6 | 1145 | 1145 | ✅
7 | 800 | 800 | ✅
8 | 1820 | 1820 | ✅
9 | 1420 | 1420 | ✅
10 | 1690 | 1690 | ✅
11 | 2635 | 2635 | ✅
12 | 1490 | 1765 | ❌
13 | 1185 | 1185 | ✅
14 | 1865 | 1865 | ✅
15 | 1150 | 1150 | ✅
16 | 800 | 800 | ✅
17 | 2195 | 2195 | ✅
18 | 1765 | 1765 | ✅
19 | 885 | 885 | ✅
20 | 1750 | 1750 | ✅
21 | 1285 | 1285 | ✅
22 | 800 | 800 | ✅
23 | 1225 | 1225 | ✅
24 | 1405 | 1405 | ✅
25 | 1720 | 1720 | ✅
26 | 1265 | 1345 | ❌
27 | 2495 | 2495 | ✅
28 | 1995 | 1995 | ✅
29 | 936 | 936 | ✅
30 | 1270 | 1270 | ✅
31 | 437 | 437 | ✅
32 | 1505 | 1505 | ✅
33 | 2120 | 2120 | ✅
34 | 1790 | 1690 | ❌
35 | 1600 | 1600 | ✅
36 | 2055 | 2055 | ✅
37 | 800 | 800 | ✅
38 | 1645 | 800 | ❌
39 | 880 | 880 | ✅
40 | 2025 | 2025 | ✅
41 | 745 | 745 | ✅
42 | 694 | 694 | ✅
43 | 1875 | 1820 | ❌
44 | 570 | 570 | ✅
45 | 1700 | 1700 | ✅
46 | 1160 | 1160 | ✅
47 | 1345 | 1345 | ✅
------------------------------------------------------------
Final Accuracy: 83.33% (40/48)
6.4 detrac_loader.py
import os
import torch
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import pandas as pd
class DetracImageDataset(Dataset):
def __init__(self, anno_path, prefix='', split=' ', mode='train',
clip_len=8, frame_sample_rate=4, filename_tmpl='img{:05}.jpg'):
self.anno_path = anno_path
self.prefix = prefix
self.split = split
self.mode = mode
self.clip_len = clip_len
self.frame_sample_rate = frame_sample_rate
self.filename_tmpl = filename_tmpl
# 读取 CSV
# 注意:这里根据你之前的报错,默认 delimiter 是空格或逗号,pd.read_csv 比较智能
cleaned = pd.read_csv(self.anno_path, header=None, sep=None, engine='python')
self.dataset_samples = list(cleaned.values[:, 0])
raw_labels = list(cleaned.values[:, 1])
# --- 自动标签映射:确保标签在 [0, num_classes-1] ---
unique_labels = sorted(list(set(raw_labels)))
self.label_map = {val: i for i, val in enumerate(unique_labels)}
self.label_array = [self.label_map[l] for l in raw_labels]
print(f"Dataset Loaded: {len(self.dataset_samples)} samples.")
print(f"Label Mapping: {self.label_map} (Original -> Processed)")
def __len__(self):
return len(self.dataset_samples)
def __getitem__(self, index):
folder_name = str(self.dataset_samples[index])
label = int(self.label_array[index])
folder_path = os.path.join(self.prefix, folder_name)
# 1. 获取图片列表
try:
all_imgs = sorted([img for img in os.listdir(folder_path) if img.endswith('.jpg')])
except FileNotFoundError:
print(f"Error: Folder not found {folder_path}")
return torch.zeros(3, self.clip_len, 224, 224), 0
total_frames = len(all_imgs)
# 2. 抽帧逻辑
converted_len = self.clip_len * self.frame_sample_rate
if total_frames <= converted_len:
indices = np.linspace(0, total_frames - 1, num=self.clip_len).astype(np.int64)
else:
if self.mode == 'train':
start_idx = np.random.randint(0, total_frames - converted_len)
else:
start_idx = (total_frames - converted_len) // 2
indices = np.arange(start_idx, start_idx + converted_len, self.frame_sample_rate)[:self.clip_len]
# 3. 读取并 Resize
frames = []
for i in indices:
img_name = self.filename_tmpl.format(i + 1)
img_path = os.path.join(folder_path, img_name)
if not os.path.exists(img_path):
img_path = os.path.join(folder_path, all_imgs[i])
with Image.open(img_path) as img:
img = img.convert('RGB').resize((224, 224))
img_tensor = torch.from_numpy(np.array(img)).permute(2, 0, 1).float() / 255.0
frames.append(img_tensor)
# 4. 拼成 (C, T, H, W) 并归一化
frames = torch.stack(frames).permute(1, 0, 2, 3)
mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1, 1)
frames = (frames - mean) / std
return frames, label
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)