ASR 实时语音识别中低音量与断句过碎问题的优化实践
在做实时语音识别(ASR)系统的时候,有两个问题基本绕不开:
- 音量太低 → 识别不稳定、丢字
- 断句过碎 → 结果被切得稀碎,体验很差
这两个问题在电话语音、会议转写、物联网设备语音场景里特别常见。前期如果不处理好,后面做语义理解(NLP)会非常痛苦。
现在我们就来聊聊熙瑾会悟是怎么通过:
- 自适应过滤(Adaptive Filtering)
- 多级分句策略(Multi-stage Segmentation)
来解决这些问题的。
一、问题复现:为什么会“识别不稳 + 句子很碎”
先说结论:不是 ASR 模型不行,而是输入信号“太脏”
1. 低音量的影响
低音量通常会带来几个问题:
- 有效语音被当作噪声过滤掉
- 特征提取(MFCC / FBank)失真
- VAD(语音活动检测)误判为“静音”
简单理解就是:模型“听不清你在说啥”。
2. 断句过碎的根本原因
大多数实时 ASR 系统都会用到:
- VAD(Voice Activity Detection)
- 流式识别(Streaming ASR)
如果 VAD 太敏感:
- 停顿 200ms → 就认为一句结束
- 轻微气音 → 被识别成一句
结果就是:
你好
今天
天气
怎么样
而不是:
你好,今天天气怎么样
二、整体解决思路
我们把问题拆成两层:
输入层(音频处理)
👉 解决:低音量、噪声问题
👉 手段:自适应过滤
输出层(文本处理)
👉 解决:断句过碎
👉 手段:多级分句策略
三、自适应过滤:让模型“听清楚”
这一块主要是音频前处理。
1. 音频处理流程
典型流程如下:
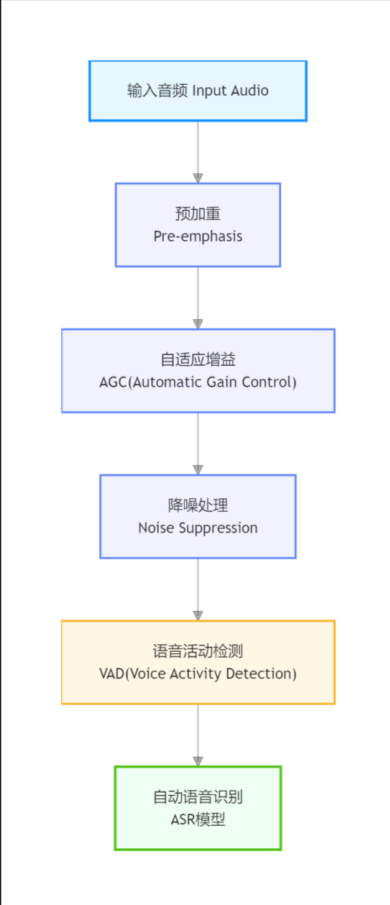
2. 自适应增益(AGC)
核心目标:让小声变清楚,但不过曝
常见实现方式:
- RMS 音量检测
- 动态调整增益(Gain)
简单实现思路:

3. 降噪(Noise Suppression)
常用技术:
- 谱减法(Spectral Subtraction)
- Wiener Filter
- 深度学习降噪(RNNoise / DNN)
实际工程中推荐:
👉 WebRTC AudioProcessing 模块
它里面已经集成了:
- NS(降噪)
- AGC(自动增益)
- AEC(回声消除)
稳定性很高。
4. 自适应 VAD 阈值
传统 VAD 是固定阈值:
能量 > threshold → 语音
但现实中:
- 有人声音小
- 环境噪声大
👉 所以需要动态阈值
改进方式:
- 根据最近 1~2 秒背景噪声计算基线
- 阈值 = 噪声均值 + 偏移量
四、多级分句策略:让结果“像人说的话”
音频处理完,接下来就是文本层优化。
1. 为什么不能只靠 VAD?
VAD 只能做:
👉 “有没有人在说话”
但做不了:
👉 “这句话说完了吗?”
2. 多级分句架构
整体策略:
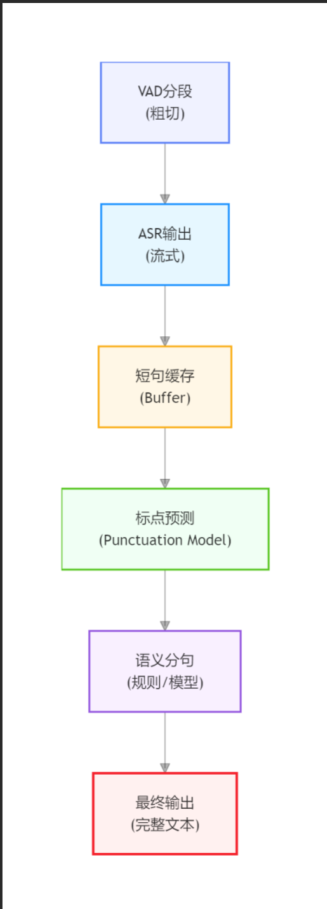
3. 一级分句:基于时间窗口
- 设定最小句长(如 1.5 秒)
- 小于这个时间 → 不立即切句
防止:
“你好”
“今天”
“天气”
4. 二级分句:标点恢复模型
常见模型:
- BiLSTM + CRF
- BERT + punctuation
作用:
👉 给 ASR 输出加上:
你好 今天天气怎么样
↓
你好,今天天气怎么样?
5. 三级分句:语义规则
这里是“工程味”最浓的地方:
常见规则:
- 句尾词: “吗 / 呢 / 吧”
- 停顿时间: 800ms → 可能断句
- 语气词: “嗯”、“啊”
6. 缓冲机制(核心优化点)
很多人忽略了这一点。
👉 不要一有结果就输出
而是:
- 维护一个 句子缓存区
- 等“更确定”再输出
示例:
输入流:
你好 / 今天 / 天气 / 怎么样
缓存后:
你好今天天气怎么样
五、模型与技术选型建议
结合实际项目,推荐如下:
ASR 模型
- 流式: Conformer-Transducer
- DeepSpeech(老但稳)
VAD
- WebRTC VAD
- Silero VAD(深度学习)
标点恢复
- BERT-based Punctuation Model
- FastPunct(轻量)
降噪 & AGC
- WebRTC AudioProcessing ⭐(强烈推荐)
六、实际效果对比
优化前:
你好
今天
天气
怎么样
优化后:
你好,今天天气怎么样?
七、踩坑总结(很重要)
1. AGC 不要调太猛
否则:
👉 声音会“炸裂”,反而影响识别
2. VAD 阈值不能写死
不同设备差异非常大:
- 手机麦克风
- 车载设备
- 工控设备
3. 分句不要过度依赖规则
规则太多会变成:
👉 “不可维护的地狱”
建议:
- 规则 + 模型结合
上述在 ASR 实时语音识别中针对低音量与断句过碎问题的优化实践,熙瑾会悟在真实会议场景中表现出更强的稳定性与可用性。通过自适应音频处理与多级分句策略的落地,系统能够在复杂环境下依然保持语音识别的连贯性与准确性,为上层应用提供高质量的数据基础。
考虑到政企及敏感场景需求,熙瑾会悟重点支持私有化部署,所有数据本地闭环处理,具备高安全性与强保密能力,在保障数据不出域的前提下,兼顾智能化与实用性,适用于政府、金融、能源等对数据安全要求较高的行业场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)