机器学习基础——线性回归数学原理
文章目录
线性回归
对于给定数据集 D = { ( x i , y i ) } i = 1 m D=\{(\mathbf x_i,y_i)\}_{i=1}^m D={(xi,yi)}i=1m,其中 x i = ( x i 1 , x i 2 , . . . , x i d ) , y i ∈ R \mathbf x_i=(x_{i1},x_{i2},...,x_{id}),y_i\in\mathbb R xi=(xi1,xi2,...,xid),yi∈R。线性回归的目的是找到一个函数
f ( x ) = w T x + b f(\mathbf x)=\mathbf w^T\mathbf x+b f(x)=wTx+b
使得线性模型的预测值 f ( x ) f(\mathbf x) f(x)与真实值 y y y尽可能接近。通常选用均方误差来判断其接近程度,即
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 = 1 m ∑ i = 1 m ( w T x i + b − y i ) 2 \begin{equation} \begin{aligned} E(f;D)&=\frac1m\sum_{i=1}^m(f(\mathbf x_i)-y_i)^2\\ &=\frac1m\sum_{i=1}^m(\mathbf w^T\mathbf x_i+b-y_i)^2 \end{aligned} \end{equation} E(f;D)=m1i=1∑m(f(xi)−yi)2=m1i=1∑m(wTxi+b−yi)2
当均方误差最小时,即可求得最优线性回归模型。此时
( w ∗ , b ∗ ) = arg min w , b E ( w , b ) = arg min w , b ∑ i = 1 m ( f ( x i ) − y i ) 2 = arg min w , b ∑ i = 1 m ( w T x i + b − y i ) 2 \begin{equation} \begin{aligned} (\mathbf w^*,b^*)&=\arg\min_{\mathbf w,b}E(\mathbf w,b)\\ &=\arg\min_{\mathbf w,b}\sum_{i=1}^m(f(\mathbf x_i)-y_i)^2\\ &=\arg\min_{\mathbf w,b}\sum_{i=1}^m(\mathbf w^T\mathbf x_i+b-y_i)^2 \end{aligned} \end{equation} (w∗,b∗)=argw,bminE(w,b)=argw,bmini=1∑m(f(xi)−yi)2=argw,bmini=1∑m(wTxi+b−yi)2
w ∗ , b ∗ \mathbf w^*,b^* w∗,b∗表示 w , b \mathbf w,b w,b的解。我们只需要求得均方误差 E E E在最小值时的 w , b \mathbf w,b w,b值,因此均方误差的常数项 1 m \frac1m m1可忽略。
一元线性回归
当数据集中 x i \mathbf x_i xi的维度为1时,即 x i = ( x i ) \mathbf x_i=(x_i) xi=(xi),此时 x x x为标量,则对于给定数据集 D = { ( x i , y i ) } i = 1 m D=\{(x_i,y_i)\}_{i=1}^m D={(xi,yi)}i=1m,线性回归给出的模型为
f ( x ) = w x + b \begin{equation} f(x)=wx+b \end{equation} f(x)=wx+b
此时 w w w也是标量。易证 E ( w , b ) = ∑ i = 1 m ( w x i + b − y i ) 2 E(w,b)=\sum_{i=1}^m(wx_i+b-y_i)^2 E(w,b)=∑i=1m(wxi+b−yi)2对 w , b w,b w,b均为开口向上且恒大于0的二次函数,因此我们可以使用二次函数对称轴公式或求导来确定该函数的最小值。这里选择求导的方法。将 E ( w , b ) E(w,b) E(w,b)分别对 w , b w,b w,b求导:
∂ E ( w , b ) ∂ w = 2 ∑ i = 1 m ( w x i + b − y i ) x i = 2 [ w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ] ∂ E ( w , b ) ∂ b = 2 ∑ i = 1 m ( w x i + b − y i ) = 2 [ m b − ∑ i = 1 m ( y i − w x i ) ] \begin{equation} \begin{aligned} \frac{\partial E(w,b)}{\partial w}&=2\sum_{i=1}^m(wx_i+b-y_i)x_i\\ &=2\left[w\sum_{i=1}^m x_i^2-\sum_{i=1}^m(y_i-b)x_i\right]\\ \frac{\partial E(w,b)}{\partial b}&=2\sum_{i=1}^m(wx_i+b-y_i)\\ &=2\left[mb-\sum_{i=1}^m(y_i-wx_i)\right] \end{aligned} \end{equation} ∂w∂E(w,b)∂b∂E(w,b)=2i=1∑m(wxi+b−yi)xi=2[wi=1∑mxi2−i=1∑m(yi−b)xi]=2i=1∑m(wxi+b−yi)=2[mb−i=1∑m(yi−wxi)]
令上式等于0,得到
b = 1 m ∑ i = 1 m ( y i − w x i ) = y ˉ − w x ˉ w = ∑ i = 1 m ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 m ( x i − x ˉ ) 2 = ∑ i = 1 m ( x i y i ) − m x ˉ y ˉ ∑ i = 1 m x i 2 − m x ˉ 2 \begin{equation} \begin{aligned} b&=\frac1m\sum_{i=1}^m(y_i-wx_i)=\bar y-w\bar x\\ w&=\frac{\sum_{i=1}^m(x_i-\bar x)(y_i-\bar y)}{\sum_{i=1}^m(x_i-\bar x)^2}=\frac{\sum_{i=1}^m(x_iy_i)-m\bar x\bar y}{\sum_{i=1}^m x_i^2-m\bar x^2} \end{aligned} \end{equation} bw=m1i=1∑m(yi−wxi)=yˉ−wxˉ=∑i=1m(xi−xˉ)2∑i=1m(xi−xˉ)(yi−yˉ)=∑i=1mxi2−mxˉ2∑i=1m(xiyi)−mxˉyˉ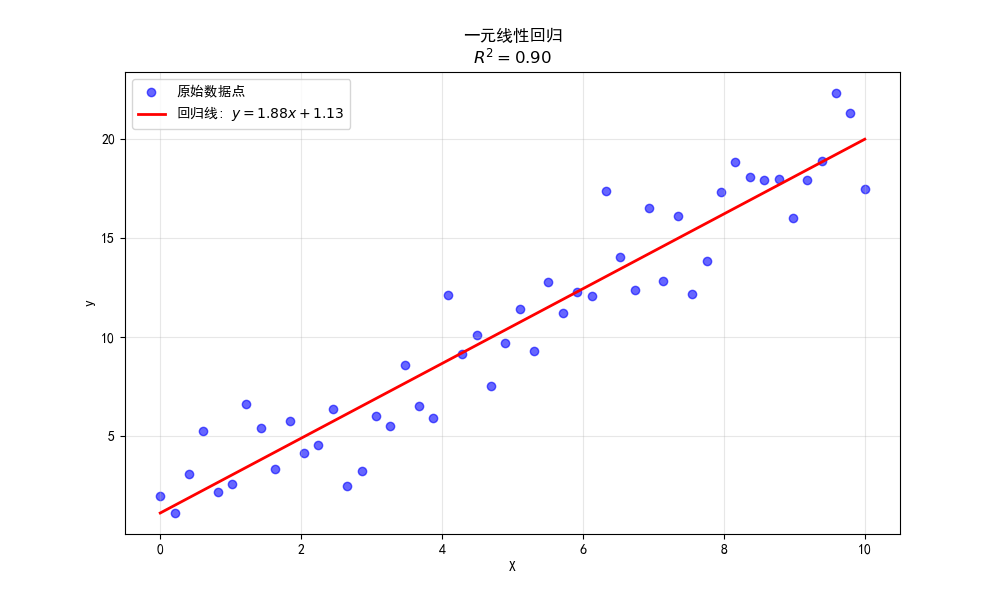
特别的,对于 x = x 0 x=x_0 x=x0( x 0 x_0 x0是常数)这类直线,斜率 w w w无法被表示,因此回归方程不存在。
多元线性回归
最小二乘法
对概述中的式子,我们令
X = [ x 11 x 12 ⋯ x 1 d 1 x 21 x 22 ⋯ x 2 d 1 ⋮ ⋮ ⋱ ⋮ ⋮ x m 1 x m 2 ⋯ x m d 1 ] = [ x 1 T 1 x 2 T 1 ⋮ ⋮ x m T 1 ] , y = [ y 1 y 2 ⋮ y m ] , w ^ = [ w b ] \begin{equation} \mathbf X=\begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1d} & 1\\ x_{21} & x_{22} & \cdots & x_{2d} & 1\\ \vdots & \vdots & \ddots & \vdots & \vdots\\ x_{m1} & x_{m2} & \cdots & x_{md} & 1 \end{bmatrix}=\begin{bmatrix} \mathbf x_1^T & 1\\ \mathbf x_2^T & 1\\ \vdots & \vdots\\ \mathbf x_m^T & 1 \end{bmatrix},\mathbf y=\begin{bmatrix} y_1\\ y_2\\ \vdots\\ y_m \end{bmatrix},\mathbf{\hat w}=\begin{bmatrix} \mathbf w\\ b \end{bmatrix} \end{equation} X=
x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd11⋮1
=
x1Tx2T⋮xmT11⋮1
,y=
y1y2⋮ym
,w^=[wb]
则
f ( x ) = w T x + b = X w ^ w ^ ∗ = arg min w ^ E ( w ^ ) = arg min w ^ ( y − X w ^ ) T ( y − X w ^ ) \begin{equation} \begin{aligned} f(\mathbf x)&=\mathbf w^T\mathbf x+b=\mathbf{X\hat w}\\ \mathbf{\hat w}^*&=\arg\min_{\mathbf{\hat w}}E(\mathbf{\hat w})\\ &=\arg\min_{\mathbf{\hat w}}(\mathbf y-\mathbf{X\hat w})^T(\mathbf y-\mathbf{X\hat w})\\ \end{aligned} \end{equation} f(x)w^∗=wTx+b=Xw^=argw^minE(w^)=argw^min(y−Xw^)T(y−Xw^)
将 E E E对 w ^ \mathbf{\hat w} w^求导得
∂ E ( w ^ ) ∂ w ^ = 2 X T ( X w ^ − y ) \begin{equation} \frac{\partial E(\mathbf{\hat w})}{\partial \mathbf{\hat w}}=2\mathbf X^T(\mathbf{X\hat w}-\mathbf y) \end{equation} ∂w^∂E(w^)=2XT(Xw^−y)
当 X T X X^TX XTX是满秩矩阵时,令上式等于0可得
w ^ = ( X T X ) − 1 X T y \begin{equation} \mathbf{\hat w}=\left(\mathbf X^T\mathbf X\right)^{-1}\mathbf X^T\mathbf y \end{equation} w^=(XTX)−1XTy
将其代入一元线性回归,仍有效。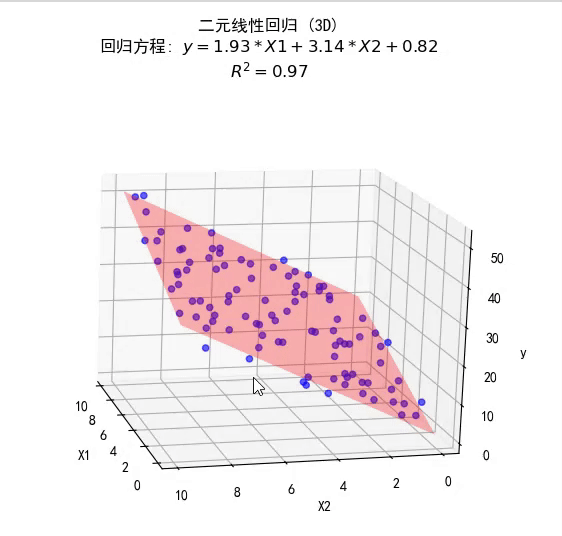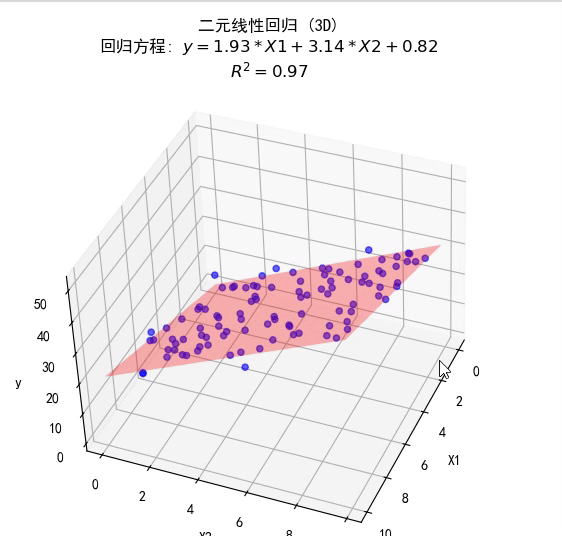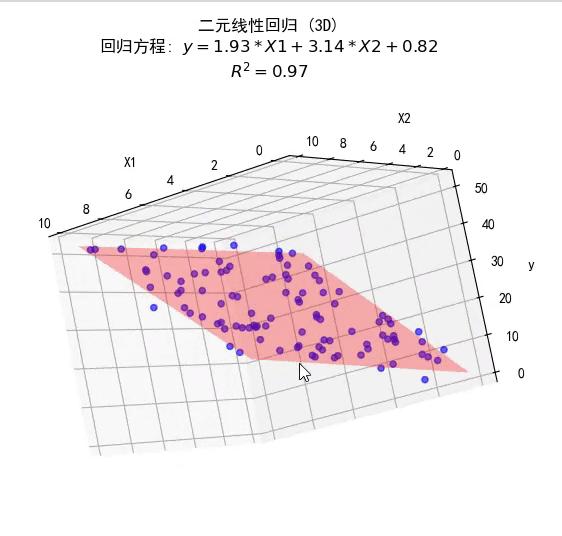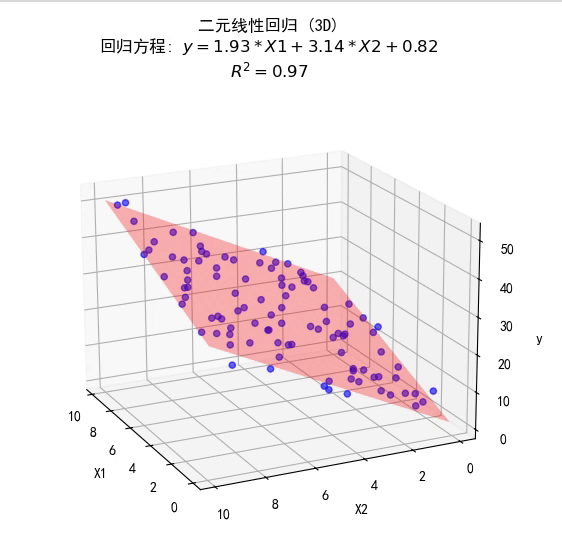
过拟合与正则化
在多元线性回归中,当特征维度 d d d较大而样本量 m m m相对不足时,最小二乘法容易出现过拟合(Overfitting)现象。过拟合是指模型在训练集上表现很好(均方误差很小),但在未知数据上泛化能力差。
造成过拟合的常见原因包括:
- 特征过多或特征之间高度相关:导致 X T X \mathbf X^T\mathbf X XTX接近奇异矩阵(不满秩),最小二乘解不稳定。
- 模型复杂度过高:参数过多使得模型倾向于拟合训练数据中的噪声。
为了缓解过拟合,常用手段是正则化(Regularization):在损失函数中增加一个关于模型参数的惩罚项,限制参数的大小,从而降低模型复杂度。一般化的正则化目标函数为:
w ^ ∗ = arg min w ^ [ ( y − X w ^ ) 2 + λ Ω ( w ^ ) ] \begin{equation} \hat{\mathbf w}^*=\arg\min_{\hat{\mathbf w}}\left[(\mathbf y-\mathbf{X\hat w})^2+\lambda\Omega(\hat{\mathbf w})\right] \end{equation} w^∗=argw^min[(y−Xw^)2+λΩ(w^)]
其中 λ ≥ 0 \lambda\geq 0 λ≥0为正则化系数(超参数), Ω ( w ^ ) \Omega(\hat{\mathbf w}) Ω(w^)为惩罚项。 λ \lambda λ越大,对参数的约束越强; λ = 0 \lambda=0 λ=0时退化为普通最小二乘法。
根据惩罚项 Ω ( w ^ ) \Omega(\hat{\mathbf w}) Ω(w^)的不同选取,可以得到不同的正则化方法。常见的有以下几种:
- L1正则化: Ω ( w ^ ) = ∥ w ^ ∥ 1 = ∑ j = 1 d ∣ w ^ j ∣ \Omega(\hat{\mathbf w})=\|\hat{\mathbf w}\|_1=\sum_{j=1}^{d}|\hat w_j| Ω(w^)=∥w^∥1=∑j=1d∣w^j∣,对应LASSO回归。
- L2正则化: Ω ( w ^ ) = ∥ w ^ ∥ 2 2 = w ^ T w ^ = ∑ j = 1 d w ^ j 2 \Omega(\hat{\mathbf w})=\|\hat{\mathbf w}\|_2^2=\hat{\mathbf w}^T\hat{\mathbf w}=\sum_{j=1}^{d}\hat w_j^2 Ω(w^)=∥w^∥22=w^Tw^=∑j=1dw^j2,对应岭回归。
- 弹性网络(Elastic Net):同时结合L1和L2正则化:
Ω ( w ^ ) = α ∥ w ^ ∥ 1 + 1 − α 2 ∥ w ^ ∥ 2 2 , α ∈ [ 0 , 1 ] \begin{equation} \Omega(\hat{\mathbf w})=\alpha\|\hat{\mathbf w}\|_1+\frac{1-\alpha}{2}\|\hat{\mathbf w}\|_2^2,\quad\alpha\in[0,1] \end{equation} Ω(w^)=α∥w^∥1+21−α∥w^∥22,α∈[0,1]
正则化的几何解释
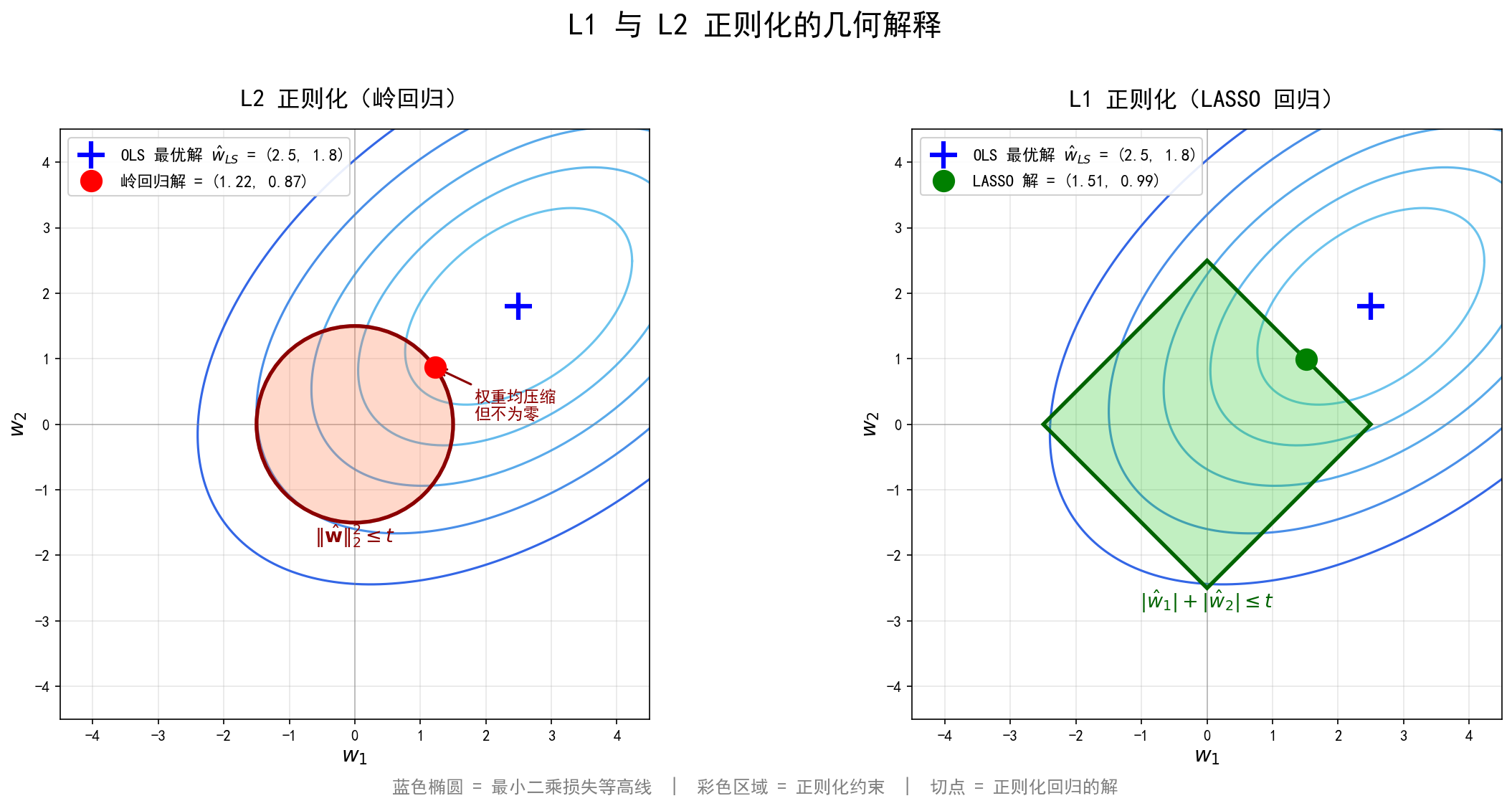
正则化的效果可以通过约束形式(而非拉格朗日形式)直观理解。以二维权重 ( w 1 , w 2 ) (w_1,w_2) (w1,w2)为例:
- 蓝色椭圆代表最小二乘损失的等高线,椭圆中心 w ^ L S \hat{\mathbf w}_{LS} w^LS为无正则化时的最优解。
- 彩色区域代表正则化约束(限制 w ^ \hat{\mathbf w} w^的范围),正则化回归的解就是等高线与约束区域的切点。
λ \lambda λ越大,约束区域越小,正则化回归的解离OLS最优解越远: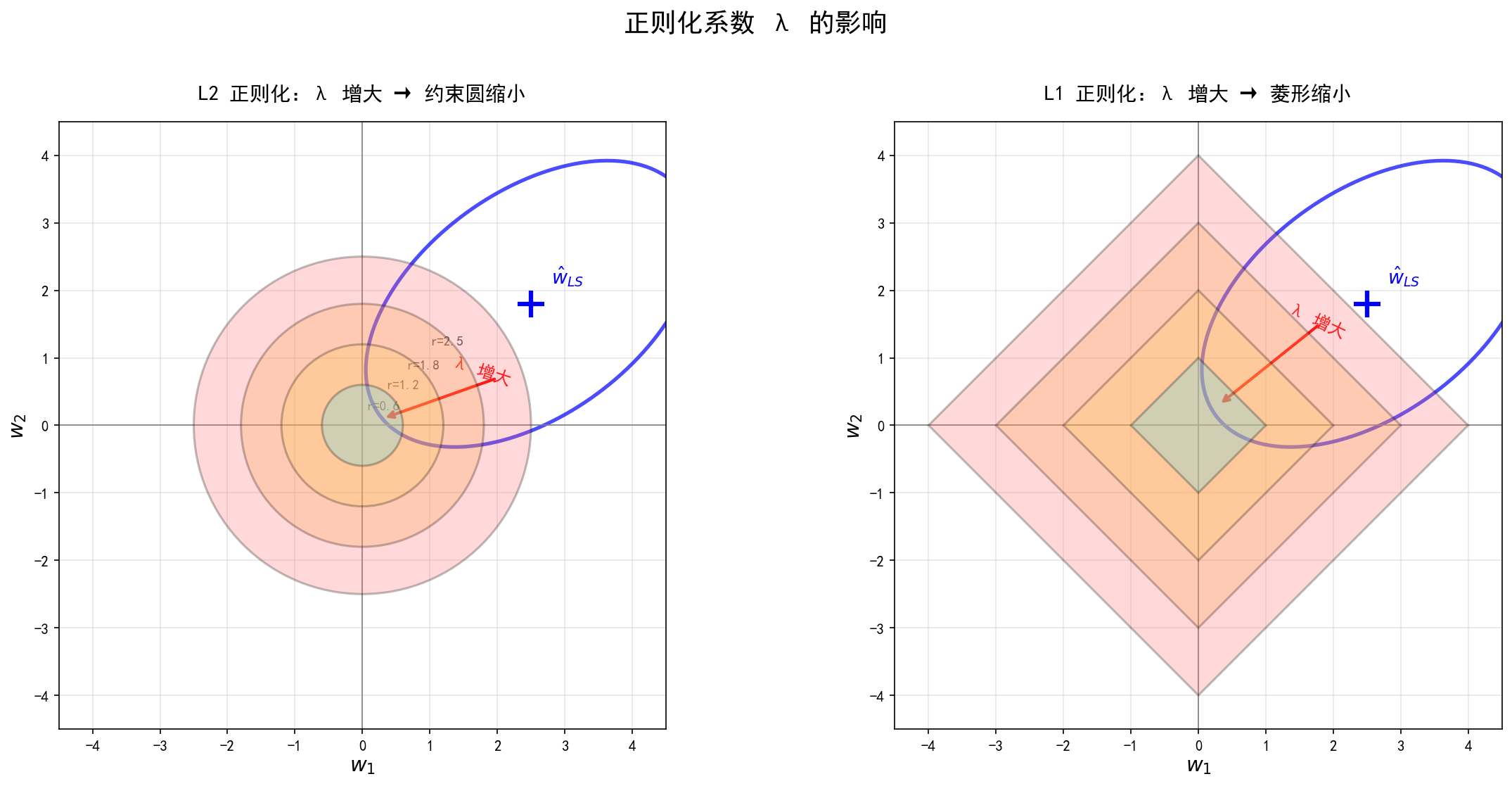
如上图所示:
- L2正则化(圆形约束):切点通常不在坐标轴上,即 w 1 ≠ 0 w_1\neq 0 w1=0且 w 2 ≠ 0 w_2\neq 0 w2=0,权重被压缩但不会为零。
- L1正则化(菱形约束):由于菱形存在"尖角"(顶点在坐标轴上),等高线更容易在顶点处与菱形相切,使得某个权重恰好为零(图中 w 1 = 0 w_1=0 w1=0),从而产生稀疏解。
LASSO回归
LASSO(Least Absolute Shrinkage and Selection Operator)回归在最小二乘损失的基础上增加L1正则化项,其目标函数为:
w ^ ∗ = arg min w ^ 1 2 ( y − X w ^ ) 2 + λ ∥ w ^ ∥ 1 \begin{equation} \hat{\mathbf w}^*=\arg\min_{\hat{\mathbf w}}\frac12(\mathbf y-\mathbf{X\hat w})^2+\lambda\|\hat{\mathbf w}\|_1 \end{equation} w^∗=argw^min21(y−Xw^)2+λ∥w^∥1
其中 λ > 0 \lambda>0 λ>0为正则化系数, ∥ w ^ ∥ 1 = ∑ j = 0 d ∣ w ^ j ∣ \|\hat{\mathbf w}\|_1=\sum_{j=0}^{d}|\hat w_j| ∥w^∥1=∑j=0d∣w^j∣为权重向量的L1范数(包含偏置 b = w ^ d + 1 b=\hat w_{d+1} b=w^d+1或不包含均可,通常不对偏置做正则化)。
L1正则化的几何解释
L1正则化的等值线为菱形(如二维时为旋转 45 ° 45° 45°的正方形)。当等值线与最小二乘损失的等高线(椭圆)相切时,切点更容易落在坐标轴上,这意味着某些特征的权重恰好为0。因此LASSO回归具有特征选择(Feature Selection)的能力——它能自动将不重要的特征权重压缩为零,从而得到稀疏模型。
L1正则化的特点
- 稀疏性:倾向于产生稀疏解,自动进行特征选择。
- 无可解析解:由于L1范数的绝对值函数在零点不可导,LASSO没有像最小二乘法那样的闭式解,通常需要使用坐标下降法(Coordinate Descent)或近端梯度下降法(Proximal Gradient Descent)等迭代算法求解。
- 适用场景:当特征维度很高、怀疑大部分特征与目标无关时,LASSO回归尤为适用。
坐标下降法求解
坐标下降法的基本思想是:每次固定除一个变量外的所有变量,对这一个变量进行一维优化,交替进行直至收敛。对于LASSO回归中的第 j j j个权重 w ^ j \hat w_j w^j,更新公式为(省略偏置项的推导):
w ^ j ← S ( ∑ i = 1 m x i j ( y i − ∑ k ≠ j x i k w ^ k ) , λ ) ∑ i = 1 m x i j 2 \begin{equation} \hat w_j\leftarrow\frac{S\left(\sum_{i=1}^m x_{ij}(y_i-\sum_{k\neq j}x_{ik}\hat w_k),\lambda\right)}{\sum_{i=1}^m x_{ij}^2} \end{equation} w^j←∑i=1mxij2S(∑i=1mxij(yi−∑k=jxikw^k),λ)
其中 S ( z , λ ) S(z,\lambda) S(z,λ)为软阈值函数(Soft Thresholding):
S ( z , λ ) = sign ( z ) ⋅ max ( ∣ z ∣ − λ , 0 ) = { z − λ , z > λ 0 , ∣ z ∣ ≤ λ z + λ , z < − λ \begin{equation} S(z,\lambda)=\text{sign}(z)\cdot\max(|z|-\lambda,0)= \begin{cases} z-\lambda,&z>\lambda\\ 0,&|z|\leq\lambda\\ z+\lambda,&z<-\lambda \end{cases} \end{equation} S(z,λ)=sign(z)⋅max(∣z∣−λ,0)=⎩
⎨
⎧z−λ,0,z+λ,z>λ∣z∣≤λz<−λ
岭回归
岭回归(Ridge Regression)在最小二乘损失的基础上增加L2正则化项,其目标函数为:
w ^ ∗ = arg min w ^ ( y − X w ^ ) 2 + λ ∥ w ^ ∥ 2 2 \begin{equation} \hat{\mathbf w}^*=\arg\min_{\hat{\mathbf w}}(\mathbf y-\mathbf{X\hat w})^2+\lambda\|\hat{\mathbf w}\|_2^2 \end{equation} w^∗=argw^min(y−Xw^)2+λ∥w^∥22
其中 λ > 0 \lambda>0 λ>0为正则化系数, ∥ w ^ ∥ 2 2 = w ^ T w ^ = ∑ j = 0 d w ^ j 2 \|\hat{\mathbf w}\|_2^2=\hat{\mathbf w}^T\hat{\mathbf w}=\sum_{j=0}^{d}\hat w_j^2 ∥w^∥22=w^Tw^=∑j=0dw^j2为权重向量的L2范数的平方。
闭式解
与LASSO不同,岭回归的目标函数是二次的、可微的,因此存在闭式解。将目标函数对 w ^ \hat{\mathbf w} w^求导并令其等于0:
∂ ∂ w ^ [ ( y − X w ^ ) 2 + λ w ^ T w ^ ] = − 2 X T ( y − X w ^ ) + 2 λ w ^ = 0 \begin{equation} \frac{\partial}{\partial\hat{\mathbf w}}\left[(\mathbf y-\mathbf{X\hat w})^2+\lambda\hat{\mathbf w}^T\hat{\mathbf w}\right]=-2\mathbf X^T(\mathbf y-\mathbf{X\hat w})+2\lambda\hat{\mathbf w}=\mathbf 0 \end{equation} ∂w^∂[(y−Xw^)2+λw^Tw^]=−2XT(y−Xw^)+2λw^=0
整理得:
( X T X + λ I ) w ^ = X T y \begin{equation} (\mathbf X^T\mathbf X+\lambda\mathbf I)\hat{\mathbf w}=\mathbf X^T\mathbf y \end{equation} (XTX+λI)w^=XTy
因此岭回归的闭式解为:
w ^ ∗ = ( X T X + λ I ) − 1 X T y \begin{equation} \hat{\mathbf w}^*=\left(\mathbf X^T\mathbf X+\lambda\mathbf I\right)^{-1}\mathbf X^T\mathbf y \end{equation} w^∗=(XTX+λI)−1XTy
其中 I \mathbf I I为 ( d + 1 ) × ( d + 1 ) (d+1)\times(d+1) (d+1)×(d+1)的单位矩阵。在普通最小二乘法中,闭式解为 w ^ ∗ = ( X T X ) − 1 X T y \hat{\mathbf w}^*=(\mathbf X^T\mathbf X)^{-1}\mathbf X^T\mathbf y w^∗=(XTX)−1XTy,要求 X T X \mathbf X^T\mathbf X XTX可逆。然而,当特征之间存在共线性(某些列线性相关),或特征维度 d d d大于样本数 m m m时, X T X \mathbf X^T\mathbf X XTX将不满秩,即存在为零的特征值,导致矩阵不可逆(奇异)。岭回归通过在 X T X \mathbf X^T\mathbf X XTX的对角线上添加 λ I \lambda\mathbf I λI,对所有特征值进行了"抬升":设 X T X \mathbf X^T\mathbf X XTX的特征值为 μ 1 , μ 2 , … , μ d + 1 \mu_1,\mu_2,\dots,\mu_{d+1} μ1,μ2,…,μd+1(均 ≥ 0 \geq 0 ≥0),则 X T X + λ I \mathbf X^T\mathbf X+\lambda\mathbf I XTX+λI的特征值为 μ 1 + λ , μ 2 + λ , … , μ d + 1 + λ \mu_1+\lambda,\mu_2+\lambda,\dots,\mu_{d+1}+\lambda μ1+λ,μ2+λ,…,μd+1+λ。由于 λ > 0 \lambda>0 λ>0:
μ j + λ > 0 , ∀ j = 1 , 2 , … , d + 1 \mu_j+\lambda>0,\quad \forall\, j=1,2,\dots,d+1 μj+λ>0,∀j=1,2,…,d+1
因此即使某些 μ j = 0 \mu_j=0 μj=0(矩阵奇异),加扰动后所有特征值都严格大于零, X T X + λ I \mathbf X^T\mathbf X+\lambda\mathbf I XTX+λI变为正定矩阵,逆矩阵始终存在。此外,当 X T X \mathbf X^T\mathbf X XTX接近奇异(某些 μ j ≈ 0 \mu_j\approx 0 μj≈0)时, ( μ j ) − 1 (\mu_j)^{-1} (μj)−1极大,解的数值极不稳定;添加 λ \lambda λ后, ( μ j + λ ) − 1 (\mu_j+\lambda)^{-1} (μj+λ)−1被限制在 1 λ \frac{1}{\lambda} λ1以内,显著提升了数值稳定性。这也是岭回归被称为"收缩方法"的原因——较大的特征值对应的权重受影响较小,而较小的特征值对应的权重被显著收缩。
L2正则化的几何解释
L2正则化的等值线为圆形(球面),当与最小二乘损失的等高线相切时,切点不会落在坐标轴上,因此权重不会恰好为零。L2正则化的作用是将所有权重均匀地向零收缩,但不会产生稀疏解。
L2正则化的特点
- 权重收缩:所有权重被均匀压缩,但不会变为零,因此不具备特征选择能力。
- 数值稳定性:通过 λ I \lambda\mathbf I λI保证 X T X + λ I \mathbf X^T\mathbf X+\lambda\mathbf I XTX+λI可逆,解决了共线性问题(多重共线性下 X T X \mathbf X^T\mathbf X XTX的某些特征值接近0,导致解不稳定)。
- 有闭式解:计算高效,无需迭代。
- 适用场景:当特征之间存在较强的多重共线性,或希望保留所有特征而只控制模型复杂度时,岭回归是更好的选择。
弹性网络
弹性网络(Elastic Net)是LASSO回归和岭回归的结合,它同时在目标函数中加入L1和L2正则化项,其目标函数为:
w ^ ∗ = arg min w ^ 1 2 m ( y − X w ^ ) 2 + λ [ α ∥ w ^ ∥ 1 + 1 − α 2 ∥ w ^ ∥ 2 2 ] \begin{equation} \hat{\mathbf w}^*=\arg\min_{\hat{\mathbf w}}\frac{1}{2m}(\mathbf y-\mathbf{X\hat w})^2+\lambda\left[\alpha\|\hat{\mathbf w}\|_1+\frac{1-\alpha}{2}\|\hat{\mathbf w}\|_2^2\right] \end{equation} w^∗=argw^min2m1(y−Xw^)2+λ[α∥w^∥1+21−α∥w^∥22]
其中:
- λ ≥ 0 \lambda\geq 0 λ≥0为整体正则化强度,控制正则化项的总体大小。
- α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1]为L1与L2的混合比例:
- α = 1 \alpha=1 α=1时,退化为LASSO回归。
- α = 0 \alpha=0 α=0时,退化为岭回归。
- 0 < α < 1 0<\alpha<1 0<α<1时,同时包含L1和L2正则化的效果。
与LASSO和岭回归的关系
弹性网络旨在克服LASSO回归的两个局限性:
- LASSO的样本选择局限:当特征数 d d d大于样本数 m m m时( d > m d>m d>m),LASSO最多只能选择 m m m个特征。弹性网络不受此限制,能够选择超过 m m m个特征。
- LASSO的共线性处理:当存在一组高度相关的特征时,LASSO倾向于从中随机选择一个而忽略其余。弹性网络则会倾向于同时保留整组相关特征(类似于岭回归的分组效应),同时仍保持一定的稀疏性。
求解方法
弹性网络同样没有闭式解,常用的求解方法为坐标下降法。对于第 j j j个权重 w ^ j \hat w_j w^j,更新公式为:
w ^ j ← S ( ∑ i = 1 m x i j ( y i − ∑ k ≠ j x i k w ^ k ) , λ α ) ∑ i = 1 m x i j 2 + λ ( 1 − α ) \begin{equation} \hat w_j\leftarrow\frac{S\left(\sum_{i=1}^m x_{ij}(y_i-\sum_{k\neq j}x_{ik}\hat w_k),\lambda\alpha\right)}{\sum_{i=1}^m x_{ij}^2+\lambda(1-\alpha)} \end{equation} w^j←∑i=1mxij2+λ(1−α)S(∑i=1mxij(yi−∑k=jxikw^k),λα)
其中 S ( z , ⋅ ) S(z,\cdot) S(z,⋅)仍为软阈值函数,与LASSO的区别在于分母增加了 λ ( 1 − α ) \lambda(1-\alpha) λ(1−α)项(来自L2正则化的贡献),使得权重更新更加稳定。
弹性网络的特点
- 兼具稀疏性与稳定性:L1正则化提供特征选择能力(稀疏性),L2正则化提供权重的稳定性(处理共线性)。
- 分组效应:对于高度相关的特征组,弹性网络倾向于同时保留或同时剔除,而非像LASSO那样随机选取一个。
- 超参数调优:需要同时调整 λ \lambda λ和 α \alpha α两个超参数,通常通过交叉验证(如网格搜索)来选择最优组合。
- 适用场景:当特征维度高、特征之间存在分组相关性(多共线性),且同时希望进行特征选择时,弹性网络是理想的选择。
三种正则化方法的比较
LASSO回归 岭回归 弹性网络 正则化项 λ ∥ w ^ ∥ 1 λ ∥ w ^ ∥ 2 2 λ [ α ∥ w ^ ∥ 1 + 1 − α 2 ∥ w ^ ∥ 2 2 ] 特征选择 可以 不可以 可以 闭式解 无 有 无 求解方法 坐标下降法 矩阵求逆 坐标下降法 共线性处理 随机选一个 均匀收缩 分组保留 超参数 λ λ λ , α 适用场景 高维稀疏 特征共线性 高维+共线性 \begin{array}{lccc} \hline & \text{LASSO回归} & \text{岭回归} & \text{弹性网络} \\ \hline \text{正则化项} & \lambda\|\hat{\mathbf w}\|_1 & \lambda\|\hat{\mathbf w}\|_2^2 & \lambda[\alpha\|\hat{\mathbf w}\|_1+\frac{1-\alpha}{2}\|\hat{\mathbf w}\|_2^2] \\ \text{特征选择} & \text{可以} & \text{不可以} & \text{可以} \\ \text{闭式解} & \text{无} & \text{有} & \text{无} \\ \text{求解方法} & \text{坐标下降法} & \text{矩阵求逆} & \text{坐标下降法} \\ \text{共线性处理} & \text{随机选一个} & \text{均匀收缩} & \text{分组保留} \\ \text{超参数} & \lambda & \lambda & \lambda,\alpha \\ \text{适用场景} & \text{高维稀疏} & \text{特征共线性} & \text{高维+共线性} \\ \hline \end{array} 正则化项特征选择闭式解求解方法共线性处理超参数适用场景LASSO回归λ∥w^∥1可以无坐标下降法随机选一个λ高维稀疏岭回归λ∥w^∥22不可以有矩阵求逆均匀收缩λ特征共线性弹性网络λ[α∥w^∥1+21−α∥w^∥22]可以无坐标下降法分组保留λ,α高维+共线性
下面以20维特征、4个真实非零特征的模拟数据为例,对比三种方法的权重分布(红色虚线标记真实非零特征位置):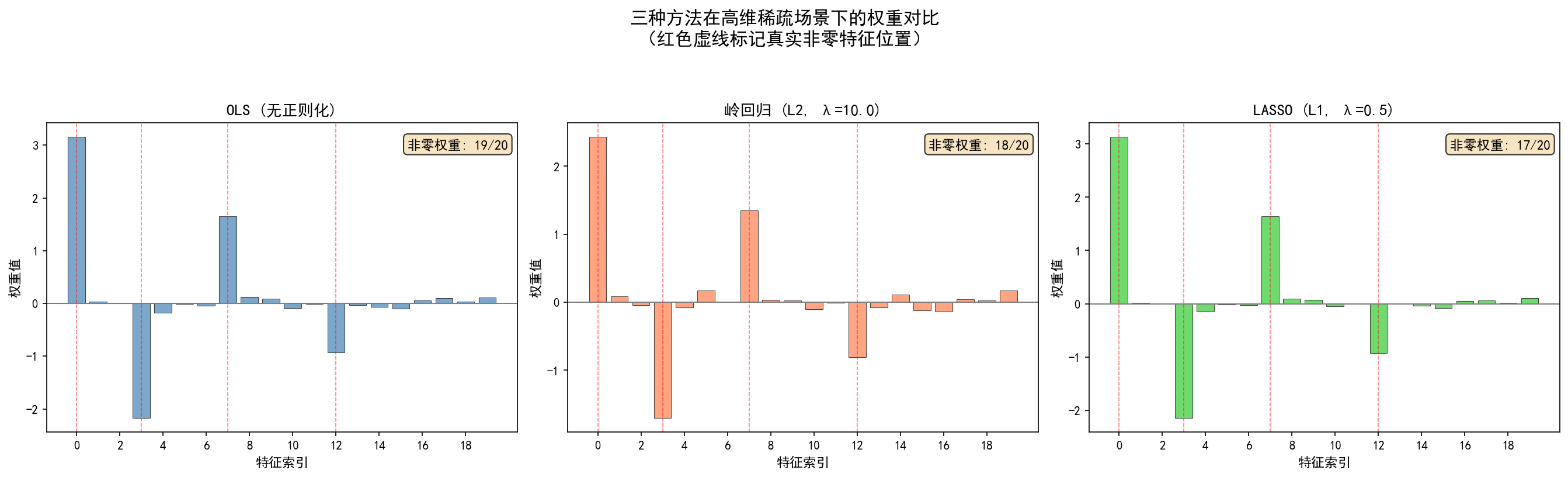
从图中可以直观看出:
- OLS:所有特征都分配了非零权重,存在过拟合风险。
- 岭回归:所有权重被压缩,但均不为零,不具备特征选择能力。
- LASSO:大部分权重被压缩为零,仅保留少数非零权重,实现了特征选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)