第四章:Python3 之 字典
文章目录:
前言
在Python3编程语言体系中,字典(Dictionary)是唯一内置的映射类型数据结构,也是日常开发、AI模型搭建、后端接口开发、前端数据交互、运维脚本编写中使用率极高的核心数据类型。相比于列表、元组、集合这类序列型数据结构,字典最大的特点是通过"键值对(key-value)" 存储数据,实现了数据的无序(Python3.7+有序)、唯一映射存储,彻底解决了序列结构通过索引查找数据效率低下的问题。
不管是刚入门Python的初学者、想要夯实基础的中级开发者,还是深耕后端业务、前端数据处理、运维自动化、AI算法开发的技术人员,字典都是必须熟练掌握、深度理解的核心知识点。字典不仅能简化数据存储与调用逻辑,更能提升代码运行效率,在海量数据处理、配置文件读写、接口参数传递、机器学习数据集构建等场景中发挥着不可替代的作用。
本文将按照"字典基础认知→创建与基础使用→核心操作→内置方法→底层原理剖析→实战项目落地→高频面试题汇总"的完整逻辑,由浅入深、层层递进讲解Python3字典知识,搭配可直接运行的代码+详细注释,兼顾零基础入门与进阶深挖,助力全受众快速掌握字典,攻克开发与面试难题。
一、字典的基础认知
1.1 什么是字典
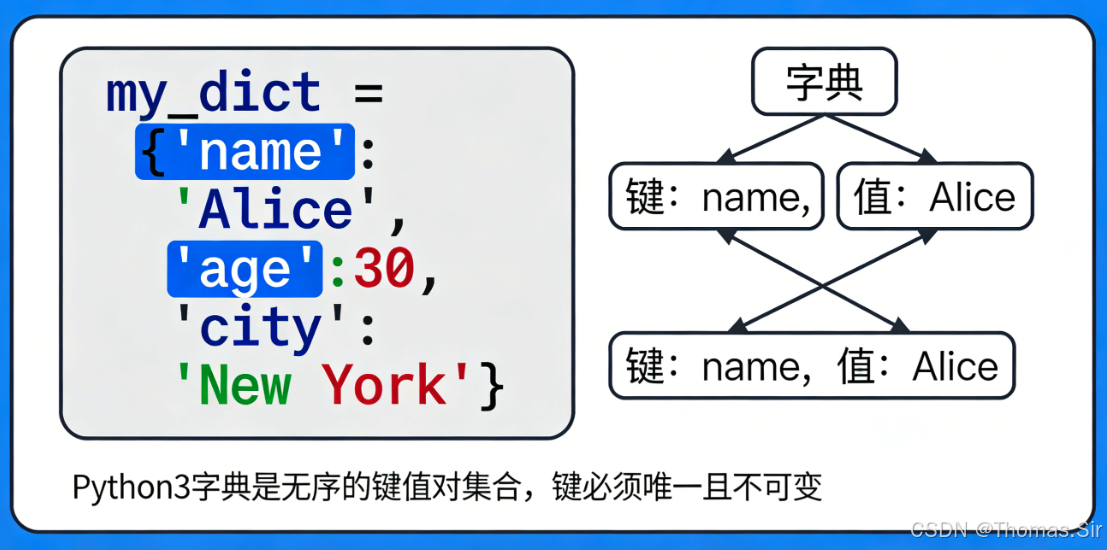
Python3字典是一种"可变、无序(Python3.7及以上版本保留插入顺序)" 的映射型数据结构,采用"键(key):值(value)" 的形式存储任意类型的数据,每个键唯一对应一个值,通过键可以快速定位、获取对应的值,查找效率接近O(1),远高于序列结构的O(n)查找效率。
可以把字典理解为生活中的字典工具书:键是汉字,值是汉字对应的释义,通过汉字(键)能快速查到对应的释义(值),无需逐页翻阅,极大提升数据检索速度。
1.2 字典核心特性
键必须唯一:同一个字典中,不允许出现重复的键,若重复赋值,后赋值的内容会覆盖之前的值;
键必须不可变:键只能使用字符串、数字、元组这类不可变数据类型,列表、集合、字典这类可变类型不能作为键,避免哈希冲突;
值可任意类型:值可以是Python支持的任意数据类型,包括列表、元组、字典、函数、类对象等,支持嵌套存储;
可变数据类型:字典创建后,可随时新增、删除、修改键值对,无需重新创建;
Python3.7+有序:Python3.6及以下版本字典无序,Python3.7及以上版本字典会保留键值对的插入顺序,遍历顺序与插入顺序一致;
高效查找:基于哈希表实现,键通过哈希函数转换为哈希值,直接定位数据存储位置,查找速度不受数据量影响。
1.3 字典适用场景
后端开发:接口请求参数封装、数据库查询结果返回、配置信息存储;
前端开发:JSON数据解析、页面渲染数据封装、表单数据处理;
运维开发:服务器配置管理、日志数据解析、自动化脚本参数传递;
AI开发:数据集标签映射、模型参数配置、特征数据存储;
通用开发:数据映射关系存储、快速数据检索、复杂数据结构嵌套。
二、创建与使用字典
字典的创建方式灵活多样,针对不同开发场景有不同的创建方法,零基础开发者可从基础语法入手,进阶开发者可掌握高效创建方式,所有代码均可直接复制运行,注释详解每一步逻辑。
2.1 基础创建方式(直接赋值法)
直接使用大括号{}包裹键值对,键值对之间用英文逗号分隔,键与值之间用英文冒号分隔,是最常用、最简洁的创建方式。
# 1. 创建空字典
empty_dict = {}
print("空字典:", empty_dict)
print("空字典类型:", type(empty_dict))
# 2. 创建带有初始数据的字典
# 键:字符串类型,值:数字、字符串、列表类型
user_info = {
"name": "张三",
"age": 25,
"gender": "男",
"hobby": ["读书", "跑步", "编程"]
}
print("基础用户字典:", user_info)
# 3. 键使用数字类型
num_dict = {1: "Java", 2: "Python", 3: "Go"}
print("数字键字典:", num_dict)
# 4. 键使用元组类型(不可变类型均可作为键)
tuple_key_dict = {(1, 2): "坐标A", (3, 4): "坐标B"}
print("元组键字典:", tuple_key_dict)
2.2 使用dict()函数创建字典
通过Python内置dict()函数创建字典,支持多种传参方式,适配不同数据格式转换,兼容性更强。
# 1. 空字典创建
empty_dict2 = dict()
print("dict()创建空字典:", empty_dict2)
# 2. 关键字参数形式创建
# 注意:此种方式键只能是字符串,且无需加引号
student = dict(name="李四", age=22, score=95.5)
print("关键字参数创建字典:", student)
# 3. 列表嵌套元组创建字典
# 列表内每个元组包含两个元素:第一个为键,第二个为值
data_list = [("id", 1001), ("course", "Python开发"), ("teacher", "王老师")]
course_dict = dict(data_list)
print("列表嵌套元组创建字典:", course_dict)
# 4. 元组嵌套列表创建字典
data_tuple = (["name", "MySQL"], ["version", 8.0], ["type", "数据库"])
db_dict = dict(data_tuple)
print("元组嵌套列表创建字典:", db_dict)2.3 快速创建重复值字典
使用dict.fromkeys()方法快速创建包含相同值的字典,适用于批量初始化字典数据。
# 语法:dict.fromkeys(键序列, 默认值)
# 键序列:列表、元组等可迭代对象;默认值:不指定则为None
# 1. 不指定默认值,默认值为None
key_list = ["name", "age", "address"]
default_dict1 = dict.fromkeys(key_list)
print("默认值为None的字典:", default_dict1)
# 2. 指定默认值
default_dict2 = dict.fromkeys(key_list, "未填写")
print("指定默认值的字典:", default_dict2)
2.4 字典的基础调用
字典创建完成后,通过"字典名[键]" 的方式即可快速调用对应的值,无需遍历查找。
# 定义基础字典
person = {"name": "赵五", "age": 30, "job": "运维工程师"}
# 调用字典值
print("姓名:", person["name"])
print("年龄:", person["age"])
print("职业:", person["job"])
# 注意:调用不存在的键会报错,后续会讲解容错调用方式
# print(person["phone"]) # 报错:KeyError: 'phone'
三、字典的基本操作
字典的核心操作包含增、删、改、查四大类,是日常开发中最常用的功能,所有操作均配有详细代码与注释,上手即用。
3.1 查找操作(获取字典值)
3.1.1 普通查找(字典名[键])
直接通过键获取值,写法简单,但键不存在时会抛出KeyError异常,适用于确定键存在的场景。
# 定义商品字典
goods = {"id": 100, "name": "笔记本电脑", "price": 5999, "stock": 20}
# 普通查找
print("商品ID:", goods["id"])
print("商品名称:", goods["name"])
3.1.2 安全查找(get()方法)
使用get()方法查找,键不存在时不会报错,返回None或自定义默认值,开发中更推荐使用。
# 语法:字典名.get(键, 键不存在时的默认值)
goods = {"id": 100, "name": "笔记本电脑", "price": 5999, "stock": 20}
# 键存在,正常返回值
print("商品价格:", goods.get("price"))
# 键不存在,返回None
print("商品颜色:", goods.get("color"))
# 键不存在,返回自定义默认值
print("商品颜色:", goods.get("color", "白色"))
3.2 新增操作(添加键值对)
直接给字典中不存在的键赋值,即可完成键值对新增,支持批量新增与单个新增。
# 初始化空字典
student_info = {}
# 1. 单个新增键值对
student_info["name"] = "陈六"
student_info["age"] = 21
print("单个新增后字典:", student_info)
# 2. 批量新增键值对
student_info.update({"score": 92, "class": "计科1班", "major": "计算机科学与技术"})
print("批量新增后字典:", student_info)
3.3 修改操作(修改键值对)
字典是可变类型,直接给已存在的键重新赋值,即可完成值的修改,操作逻辑与新增一致,区别在于键是否存在。
employee = {"emp_id": 001, "name": "孙七", "salary": 8000, "dept": "开发部"}
# 修改单个键对应的值
employee["salary"] = 9000
print("修改薪资后:", employee)
# 批量修改键值对
employee.update({"dept": "AI研发部", "age": 28})
print("批量修改后:", employee)
3.4 删除操作(删除键值对/字典)
3.4.1 del语句删除
可删除指定键值对,也可直接删除整个字典对象,删除后字典无法再使用。
car = {"brand": "比亚迪", "price": 200000, "color": "灰色", "year": 2024}
# 删除指定键值对
del car["year"]
print("删除年份后:", car)
# 删除整个字典
del car
# print(car) # 报错:NameError: name 'car' is not defined
3.4.2 pop()方法删除
删除指定键值对,并且返回被删除的值,支持设置默认值避免键不存在报错。
phone = {"brand": "华为", "memory": "128G", "price": 4999}
# 删除指定键,返回对应值
del_value = phone.pop("price")
print("被删除的值:", del_value)
print("删除后字典:", phone)
# 删除不存在的键,设置默认值,避免报错
del_value2 = phone.pop("size", "键不存在")
print("删除结果:", del_value2)
3.4.3 popitem()方法删除
Python3.7+版本,默认删除字典最后插入的键值对,返回被删除的键值对元组。
book = {"name": "Python从入门到精通", "author": "佚名", "price": 69, "page": 400}
# 删除最后一个键值对
del_item = book.popitem()
print("被删除的键值对:", del_item)
print("删除后字典:", book)
3.4.4 clear()方法清空字典
清空字典内所有键值对,保留字典对象,字典变为空字典。
test_dict = {"a": 1, "b": 2, "c": 3}
# 清空字典
test_dict.clear()
print("清空后字典:", test_dict) # 输出:{}
3.5 字典遍历操作
字典支持遍历键、遍历值、遍历键值对三种方式,适配不同数据处理场景。
user = {"id": 1003, "name": "周八", "age": 26, "job": "前端开发"}
# 1. 遍历字典所有键
print("===遍历所有键===")
for key in user.keys():
print("键:", key)
# 2. 遍历字典所有值
print("===遍历所有值===")
for value in user.values():
print("值:", value)
# 3. 遍历字典所有键值对(最常用)
print("===遍历所有键值对===")
for key, value in user.items():
print(f"键:{key},值:{value}")
3.6 字典长度判断
使用len()函数获取字典键值对的数量,即字典长度。
data_dict = {"a": 10, "b": 20, "c": 30, "d": 40}
# 获取字典长度
print("字典键值对数量:", len(data_dict)) # 输出:4
3.7 键存在性判断
使用in关键字判断指定键是否存在于字典中,返回布尔值。
city = {"北京": "首都", "上海": "直辖市", "广州": "一线城市"}
# 判断键是否存在
print("北京是否在字典中:", "北京" in city) # True
print("深圳是否在字典中:", "深圳" in city) # False四、字典常用内置方法详解
Python3为字典内置了大量实用方法,涵盖数据获取、修改、合并、拷贝、推导式等场景,全面掌握可大幅提升开发效率,以下为高频内置方法的详细讲解+可运行代码。
4.1 基础操作方法
|
方法名 |
功能描述 |
|---|---|
|
keys() |
返回字典所有键的视图对象 |
|
values() |
返回字典所有值的视图对象 |
|
items() |
返回字典所有键值对的视图对象 |
|
get() |
安全获取指定键的值,键不存在返回默认值 |
|
update() |
批量新增/修改字典键值对 |
4.2 删除相关方法
|
方法名 |
功能描述 |
|---|---|
|
pop(key, default) |
删除指定键,返回对应值,键不存在返回默认值 |
|
popitem() |
删除最后插入的键值对,返回键值对元组 |
|
clear() |
清空字典所有键值对 |
4.3 拷贝方法(浅拷贝/深拷贝)
4.3.1 浅拷贝copy()
拷贝字典第一层数据,第二层嵌套数据为引用,修改嵌套数据会影响原字典。
# 浅拷贝
original_dict = {"name": "测试", "info": {"age": 20, "score": 88}}
copy_dict = original_dict.copy()
# 修改第一层数据,原字典不受影响
copy_dict["name"] = "浅拷贝测试"
print("原字典第一层:", original_dict["name"])
print("拷贝字典第一层:", copy_dict["name"])
# 修改嵌套数据,原字典受影响
copy_dict["info"]["age"] = 22
print("原字典嵌套数据:", original_dict["info"])
print("拷贝字典嵌套数据:", copy_dict["info"])
4.3.2 深拷贝
需要导入copy模块,完全拷贝所有层级数据,修改拷贝后数据完全不影响原字典。
import copy
original_dict = {"name": "测试", "info": {"age": 20, "score": 88}}
# 深拷贝
deep_copy_dict = copy.deepcopy(original_dict)
# 修改嵌套数据,原字典不受影响
deep_copy_dict["info"]["score"] = 95
print("原字典嵌套数据:", original_dict["info"])
print("深拷贝字典嵌套数据:", deep_copy_dict["info"])
4.4 字典推导式
通过一行代码快速创建字典,简化代码逻辑,支持过滤、计算等操作。
# 1. 基础字典推导式:列表转字典
key_list = ["a", "b", "c", "d"]
value_list = [1, 2, 3, 4]
new_dict = {key: value for key, value in zip(key_list, value_list)}
print("基础推导式字典:", new_dict)
# 2. 带过滤条件的字典推导式
# 筛选值大于2的键值对
filter_dict = {k: v for k, v in new_dict.items() if v > 2}
print("过滤后字典:", filter_dict)
# 3. 值计算推导式
num_dict = {x: x"2 for x in range(1, 6)}
print("平方数字典:", num_dict)
4.5 setdefault()方法
获取指定键的值,若键不存在,则新增该键并设置默认值,兼具查找与新增功能。
test = {"name": "demo", "age": 18}
# 键存在,直接返回值
res1 = test.setdefault("name", "默认名称")
print("返回值:", res1)
print("字典:", test)
# 键不存在,新增键并设置默认值
res2 = test.setdefault("gender", "男")
print("返回值:", res2)
print("字典:", test)
五、字典原理深度剖析
想要熟练运用字典、解决复杂开发问题、应对大厂面试,必须掌握字典的底层实现原理,本节从哈希表、存储结构、执行效率三个维度深度剖析,兼顾专业性与易懂性。
5.1 字典底层数据结构:哈希表
Python3字典的底层是通过"哈希表(Hash Table)" 实现的,哈希表也叫散列表,是一种通过哈希函数将键映射到固定位置的数据结构,以此实现O(1)时间复杂度的快速查找。
5.1.1 哈希函数
哈希函数是字典的核心,作用是将任意长度的键(不可变类型)转换为固定长度的哈希值(整数),Python通过内置hash()函数获取键的哈希值。
# 获取不同类型键的哈希值
print("字符串哈希值:", hash("Python"))
print("数字哈希值:", hash(123456))
print("元组哈希值:", hash((1, 2, 3)))
# 可变类型无法获取哈希值,不能作为字典键
# print(hash([1,2,3])) # 报错:TypeError
5.1.2 哈希冲突
哈希冲突指不同的键经过哈希函数计算后,得到了相同的哈希值。Python采用"开放寻址法(线性探测)" 解决哈希冲突:当出现冲突时,按照一定规则寻找下一个空闲位置存储数据,保证数据正常存储。
5.2 字典的存储结构
Python3.7+版本对字典结构进行了优化,采用"紧凑数组+索引表"的存储方式,既保留了哈希表的高效查找,又实现了插入有序。
字典存储的核心三部分:
哈希值:键通过hash()函数计算得到的整数;
键指针:指向键的内存地址;
值指针:指向值的内存地址。
每一组哈希值、键指针、值指针构成一个哈希表条目,字典本质就是由多个条目组成的数组。
5.3 字典的执行效率
1. 查找效率:最优时间复杂度O(1),最坏O(n)(极端哈希冲突),实际开发中接近O(1),数据量越大,对比列表的效率优势越明显;
2. 新增/修改效率:直接通过哈希值定位位置,无需移动其他数据,效率O(1);
3. 空间复杂度:哈希表需要预留空闲位置解决冲突,属于空间换时间,内存占用略高于列表,但换来极高的查找效率。
5.4 字典有序性原理
Python3.6及以下版本:字典采用纯哈希表存储,数据分散存储,无序;
Python3.7及以上版本:底层新增索引表记录插入顺序,紧凑数组存储实际数据,遍历按照索引表顺序执行,因此保留插入有序,且效率无明显下降。
5.5 字典键不可变的原因
字典键依赖哈希值定位数据位置,如果键是可变类型(列表、集合),修改后哈希值会发生变化,导致无法定位原有数据,引发内存泄漏、数据丢失等问题,因此Python强制要求字典键必须是不可变类型。
六、字典项目实战
理论结合实战才能真正掌握字典,本节针对后端、前端、运维、AI四大受众,打造4个真实可运行的字典实战项目,代码完整可直接部署使用。
6.1 后端实战:用户信息管理系统
基于字典实现简易用户信息管理,支持新增、查询、修改、删除、展示所有用户功能,适配后端接口开发逻辑。
# 后端用户信息管理系统(字典实现)
# 存储所有用户信息,键为用户ID,值为用户详情字典
user_system = {}
def add_user(user_id, name, age, gender, dept):
"""新增用户"""
if user_id in user_system:
print(f"用户ID{user_id}已存在,新增失败!")
return False
user_info = {
"name": name,
"age": age,
"gender": gender,
"dept": dept
}
user_system[user_id] = user_info
print(f"用户{name}新增成功!")
return True
def query_user(user_id):
"""查询用户信息"""
user_info = user_system.get(user_id, None)
if not user_info:
print(f"用户ID{user_id}不存在!")
return None
print(f"用户ID{user_id}信息:{user_info}")
return user_info
def update_user(user_id, key, value):
"""修改用户信息"""
if user_id not in user_system:
print(f"用户ID{user_id}不存在,修改失败!")
return False
user_system[user_id][key] = value
print(f"用户ID{user_id}信息修改成功!")
return True
def delete_user(user_id):
"""删除用户"""
if user_id not in user_system:
print(f"用户ID{user_id}不存在,删除失败!")
return False
user_system.pop(user_id)
print(f"用户ID{user_id}删除成功!")
return True
def show_all_user():
"""展示所有用户"""
if not user_system:
print("暂无用户信息!")
return
print("===所有用户信息===")
for user_id, info in user_system.items():
print(f"用户ID:{user_id},详情:{info}")
# 测试功能
if __name__ == '__main__':
# 新增用户
add_user(1001, "张三", 25, "男", "后端开发部")
add_user(1002, "李四", 23, "女", "前端开发部")
# 查询用户
query_user(1001)
# 修改用户
update_user(1001, "age", 26)
# 展示所有用户
show_all_user()
# 删除用户
delete_user(1002)
show_all_user()
6.2 前端实战:JSON数据解析与渲染
前端开发中JSON数据与Python字典无缝转换,实现接口数据解析、页面渲染数据封装,适配前后端数据交互场景。
import json
# 前端实战:JSON与字典数据交互
# 模拟后端返回的JSON字符串
json_data = '''
{
"code": 200,
"msg": "请求成功",
"data": {
"title": "Python字典实战",
"content": "前端数据渲染",
"list": [
{"id": 1, "name": "字典基础"},
{"id": 2, "name": "字典实战"}
]
}
}
'''
# 1. JSON字符串转Python字典(前端数据解析)
py_dict = json.loads(json_data)
print("JSON转字典结果:", type(py_dict))
print("接口状态码:", py_dict["code"])
# 2. 提取前端渲染所需数据
if py_dict["code"] == 200:
page_data = py_dict["data"]
print("页面标题:", page_data["title"])
print("页面内容:", page_data["content"])
print("列表数据:", page_data["list"])
# 3. Python字典转JSON字符串(前端数据传递)
page_dict = {
"page_name": "首页",
"page_num": 1,
"page_size": 10
}
json_str = json.dumps(page_dict, ensure_ascii=False, indent=4)
print("字典转JSON字符串:\n", json_str)
6.3 运维实战:服务器配置管理脚本
基于字典存储服务器配置信息,实现配置读取、修改、批量导出功能,适配运维自动化脚本开发。
# 运维服务器配置管理脚本
# 存储多台服务器配置
server_config = {
"server_01": {
"ip": "192.168.1.10",
"port": 22,
"user": "root",
"cpu": "4核",
"memory": "8G",
"status": "运行中"
},
"server_02": {
"ip": "192.168.1.11",
"port": 22,
"user": "root",
"cpu": "8核",
"memory": "16G",
"status": "运行中"
}
}
def read_server_config(server_name):
"""读取服务器配置"""
config = server_config.get(server_name)
if not config:
print(f"服务器{server_name}不存在")
return
print(f"===服务器{server_name}配置===")
for k, v in config.items():
print(f"{k}: {v}")
def update_server_config(server_name, key, value):
"""修改服务器配置"""
if server_name not in server_config:
print(f"服务器{server_name}不存在")
return
server_config[server_name][key] = value
print(f"服务器{server_name} {key}配置修改为{value}成功")
def export_all_config():
"""批量导出所有服务器配置"""
print("===所有服务器配置汇总===")
for name, config in server_config.items():
print(f"服务器名称:{name},配置:{config}")
# 测试脚本
if __name__ == '__main__':
# 读取配置
read_server_config("server_01")
# 修改配置
update_server_config("server_01", "status", "维护中")
# 导出所有配置
export_all_config()
6.4 AI实战:数据集标签映射工具
基于字典实现AI数据集标签与数字映射,适配机器学习、深度学习数据集预处理场景。
# AI数据集标签映射工具
# 标签映射字典:文本标签转数字标签(AI模型训练常用)
label_map = {
"cat": 0,
"dog": 1,
"bird": 2,
"fish": 3,
"flower": 4
}
def label_to_num(label_list):
"""文本标签转数字标签"""
num_list = []
for label in label_list:
num = label_map.get(label, -1) # 未知标签标记为-1
num_list.append(num)
return num_list
def num_to_label(num_list):
"""数字标签转文本标签"""
# 反转字典键值对
reverse_map = {v: k for k, v in label_map.items()}
text_list = []
for num in num_list:
text = reverse_map.get(num, "未知标签")
text_list.append(text)
return text_list
# 测试AI数据集预处理
if __name__ == '__main__':
# 模拟数据集文本标签
data_label = ["cat", "dog", "bird", "tiger", "flower"]
print("原始文本标签:", data_label)
# 转数字标签
num_label = label_to_num(data_label)
print("转换后数字标签:", num_label)
# 转回文本标签
text_label = num_to_label(num_label)
print("转回文本标签:", text_label)
七、字典高频面试题汇总
字典是Python面试必考知识点,涵盖基础用法、原理、场景题、算法题,本节汇总大厂高频面试题,附带详细答案,助力面试通关。
7.1 基础面试题
1. 字典、列表、元组、集合的区别?
答案:
-
列表:有序、可变、可重复、通过索引查找;
-
元组:有序、不可变、可重复、通过索引查找;
-
集合:无序、可变、元素唯一、无索引、自动去重;
-
字典:无序/有序(版本差异)、可变、键唯一值可重复、通过键查找。
2. 为什么字典键不能是列表?
答案:字典底层基于哈希表实现,键需要通过哈希函数计算哈希值定位数据;列表是可变类型,无法计算哈希值,且修改后哈希值会变动,导致无法定位原有数据,因此列表不能作为字典键。
3. 如何安全获取字典值,避免KeyError?
答案:使用字典get()方法获取值,键不存在时返回None或自定义默认值,不会抛出异常;也可提前使用in关键字判断键是否存在。
4. Python3.7+字典有序吗?原理是什么?
答案:Python3.7及以上版本字典是有序的,保留插入顺序;底层通过索引表记录插入顺序,紧凑数组存储数据,遍历按照索引表顺序执行,兼顾高效与有序性。
5. 浅拷贝和深拷贝的区别?
答案:浅拷贝只拷贝第一层数据,嵌套数据为引用,修改嵌套数据会影响原数据;深拷贝完全拷贝所有层级数据,修改拷贝后数据不会影响原数据,需要使用copy.deepcopy()实现。
7.2 进阶面试题
1. 如何合并两个字典?
答案:
方法1:使用update()方法,将一个字典合并到另一个字典;
方法2:使用"解包语法,dict1 = {"dictA, "dictB};
方法3:Python3.9+支持|运算符,dict1 = dictA | dictB。
2. 字典查找和列表查找效率差异?为什么?
答案:字典查找效率接近O(1),列表查找效率O(n);字典通过哈希值直接定位数据位置,列表需要遍历所有元素查找,数据量越大效率差异越明显。
3. 如何反转字典的键值对?
答案:使用字典推导式,reverse_dict = {v: k for k, v in original_dict.items()},注意值必须唯一,否则会覆盖。
4. 什么是哈希冲突?Python如何解决?
答案:不同键计算出相同哈希值即为哈希冲突;Python采用开放寻址法(线性探测)解决,出现冲突时寻找下一个空闲位置存储数据。
5. 如何判断字典是否为空?
答案:使用if not 字典名: 判断,空字典布尔值为False;也可通过len(字典) == 0判断。
7.3 手写代码面试题
1. 统计字符串中每个字符出现的次数
def count_char(s):
count_dict = {}
for char in s:
count_dict[char] = count_dict.get(char, 0) + 1
return count_dict
# 测试
print(count_char("pythonpython"))
2. 找出字典中值最大的键
def get_max_key(data_dict):
max_value = max(data_dict.values())
for k, v in data_dict.items():
if v == max_value:
return k
# 测试
test_dict = {"a": 10, "b": 30, "c": 20}
print(get_max_key(test_dict))
结语
Python3字典作为核心映射型数据结构,贯穿前端、后端、运维、AI全开发场景,本文从基础认知、创建使用、核心操作、内置方法、底层原理、实战项目、面试复盘七大维度,全方位拆解字典知识,搭配可直接运行的代码与详细注释,兼顾零基础入门与进阶深挖。
想要熟练掌握字典,不仅要牢记基础用法,更要理解底层哈希表原理,结合实战场景反复练习,同时吃透高频面试题,才能在开发与面试中灵活运用。日常开发中,优先使用字典处理映射关系数据,既能提升代码效率,又能简化开发逻辑。
后续可继续深入学习字典与JSON、数据库、多线程结合的高级用法,适配更复杂的开发需求,持续提升Python开发能力。
🙌 感谢你读到这里!
🔍 技术之路没有捷径,但每一次阅读、思考和实践,都在悄悄拉近您与目标的距离。
💡 如果本文对你有帮助,不妨 👍 点赞、📌 收藏、📤 分享 给更多需要的朋友!
💬 欢迎在评论区留下你的想法、疑问或建议,我会一一回复,我们一起交流、共同成长 🌿
🔔 关注我,不错过下一篇干货!我们下期再见!✨

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)