从零到一:手把手带你通关OceanBase seekdb部署与实战
从零到一:手把手带你通关OceanBase seekdb部署与实战
在开始本篇文章的正式内容之前,我们先来了解一下什么是 OceanBase seekdb?
OceanBase seekdb
OceanBase seekdb(简称 seekdb)是一款 AI 原生混合搜索数据库,在一个数据库中融合向量、文本、结构化与半结构化数据能力,并通过内置 AI Functions 支持多模混合搜索与智能推理。
seekdb 最高支持 16000 维的 Float 类型的稠密向量,支持稀疏向量,支持曼哈顿距离、欧式距离、内积、余弦距离等多种类型向量距离的计算,支持基于 HNSW/IVF 向量索引的创建,支持增量更新删除,同时增量更新删除操作不会影响召回率。
seekdb 向量搜索具备带有标量过滤的混合搜索能力。同时提供灵活的访问接口,不仅支持通过 MySQL 协议各种语言客户端使用 SQL 访问,也可以使用 Python SDK 访问。同时 seekdb 也完成了对 AI 应用开发框架 LlamaIndex、DB-GPT 及 AI 应用开发平台 Dify 的适配,更好的服务于 AI 应用开发。
下面我们来安装我们的 OceanBase seekdb吧!
部署模式介绍
seekdb 提供两种部署模式:嵌入式模式、服务器模式,我们可以根据业务场景需要选择合适的部署模式。
嵌入式模式:seekdb 作为一个“库”运行在你的应用程序内部,它可以轻松跑在各种“端“上,适合移动应用开发,桌面应用开发、物联网(IoT)与边缘设备上的应用开发。该模式下可以通过 Python 脚本或者 SDK 方式连接并进行 seekdb 的管理和使用。
服务器模式:采用单机部署,适合 CI/CD、测试,简单且运维成本低,服务器启动快。该模式下通过 MySQL 客户端连接,或者通过 SDK 连接,进行 seekdb 的管理和使用。
对于我们来说,服务器模式更适合当前的场景,那么我们就选择服务器模式。
服务器模式
服务器模式支持通过以下几种方式来部署,这里我们选择通过 yum install 部署 seekdb。
服务器模式:
通过 yum install 部署 seekdb。
详细的部署操作,参见 通过 yum install 部署 seekdb。
部署 seekdb 容器环境。
详细的部署操作,参见 部署 seekdb 容器环境。
部署 OceanBase Desktop。
OceanBase Desktop 是一个用于管理和操作 seekdb 的桌面应用程序。它提供了图形化界面,使用户能够方便地进行数据库管理、查询执行、数据导入导出等操作。
详细的部署操作,参见 部署 OceanBase Desktop。
部署资源
在部署之前,我们需要现有一台服务器,对于服务器系统的要求,我们可以参考下面内容
Anolis OS 8.X 版本(内核 Linux 3.10.0 版本及以上)
Alibaba Cloud Linux 2/3 版本(内核 Linux 3.10.0 版本及以上)
Red Hat Enterprise Linux Server 7.X 版本、8.X 版本(内核 Linux 3.10.0 版本及以上)
CentOS Linux 7.X 版本、8.X 版本(内核 Linux 3.10.0 版本及以上)
Debian 9.X 版本及以上版本(内核 Linux 3.10.0 版本及以上)
Ubuntu 20.X 版本及以上版本(内核 Linux 3.10.0 版本及以上)
SUSE / OpenSUSE 15.X 版本及以上版本(内核 Linux 3.10.0 版本及以上)
openEuler 22.03 和 24.03 版本(内核 Linux 5.10.0 版本及以上)
KylinOS V10 版本
统信 UOS 1020a/1021a/1021e/1001c 版本
中科方德 NFSChina 4.0 版本及以上
浪潮 Inspur kos 5.8 版本
需要注意的是,除了对服务器系统版本的要求外,还需要保证:当前环境中 CPU 最低要求 1 核,可用内存最低为 2G。
服务器准备
这里我们可以直接选择腾讯云轻量应用服务器就够用了,对于还没有服务器的小伙伴,可以直接打开 腾讯云轻量应用服务器控制台,选择【新建】,在打开的轻量应用服务器 创建页面 选择【基于操作系统镜像】-【CentOS】,完成服务器实例的创建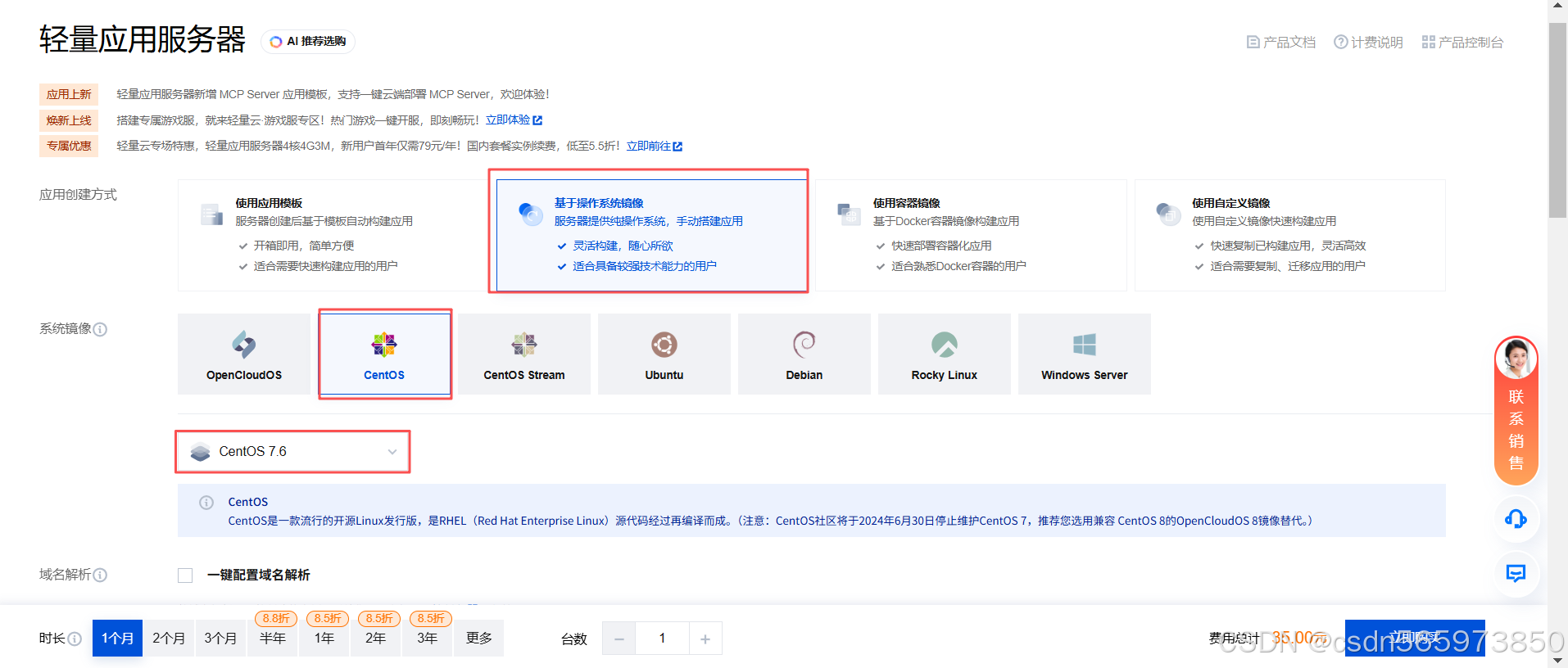
等待 服务器实例 创建完成后,可以在 轻量应用服务器 控制台的【服务器】页面看到我们当前账号下面的 服务器信息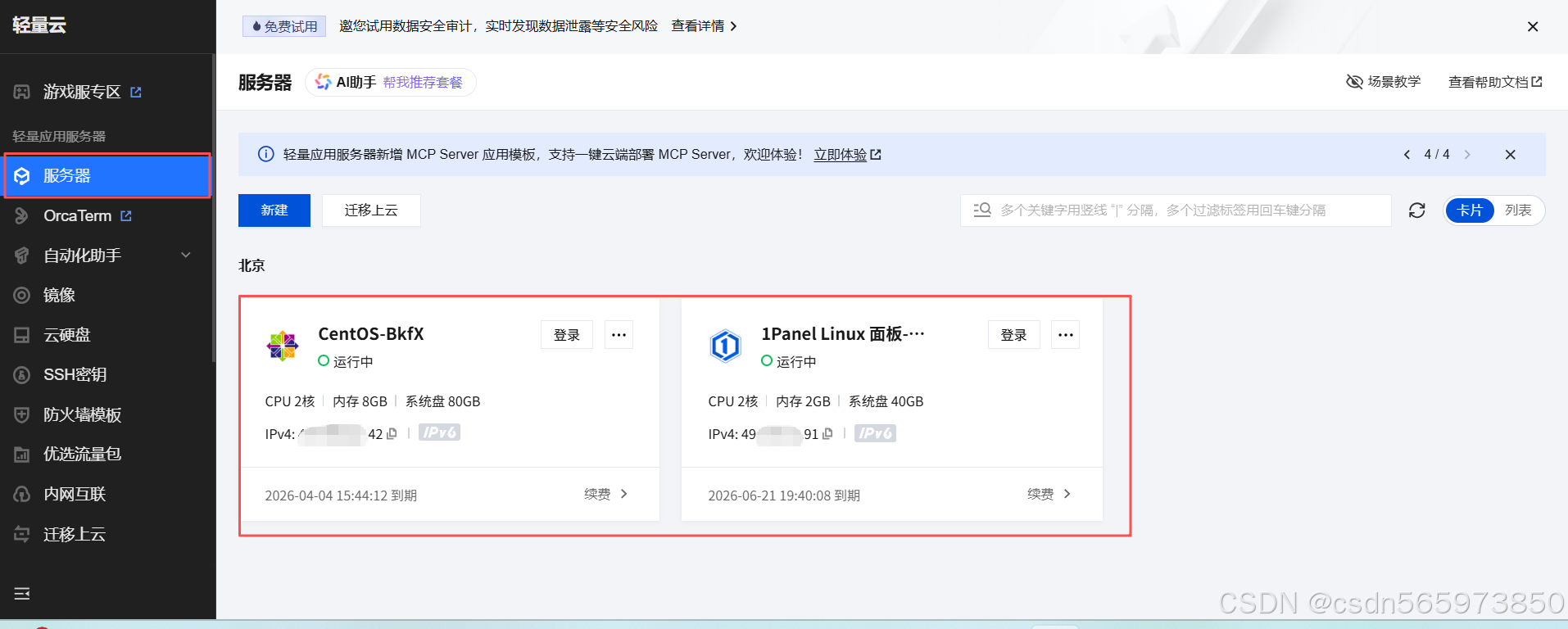
到这里,我们需要的服务器资源就准备妥当了。
通过 yum install 部署 seekdb
根据所在网络环境是否可以连接外网,通过 yum install 部署 seekdb 可以分为在线安装和离线安装两种安装方法。这里我们的服务器是云服务器,那必须可以连接外网,这里我们就使用在线安装的方法。
在线安装
在轻量应用服务器 控制台,点击服务器右上角的【登录】按钮,在新打开的页签中选择【登录】就可以成功登录服务器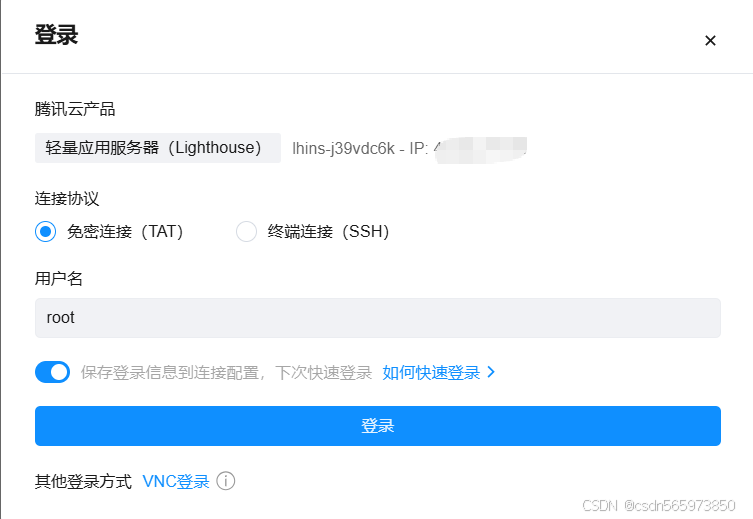
登录服务器之后,执行命令添加 seekdb 镜像源
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/oceanbase/OceanBase.repo
执行命令之后可以看到成功添加 OceanBase.repo 镜像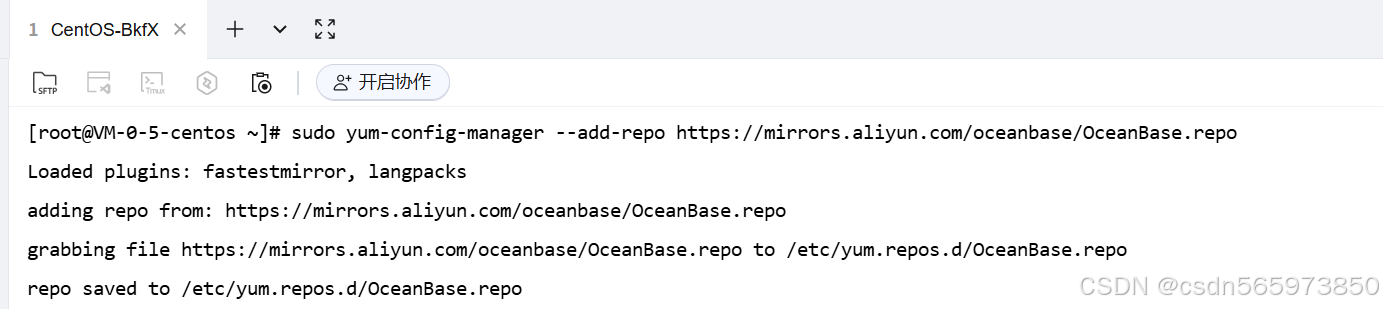
镜像添加完成之后,执行下面命令安装 seekdb
sudo yum install seekdb
在安装过程中遇到如下截图中的询问信息,输入 y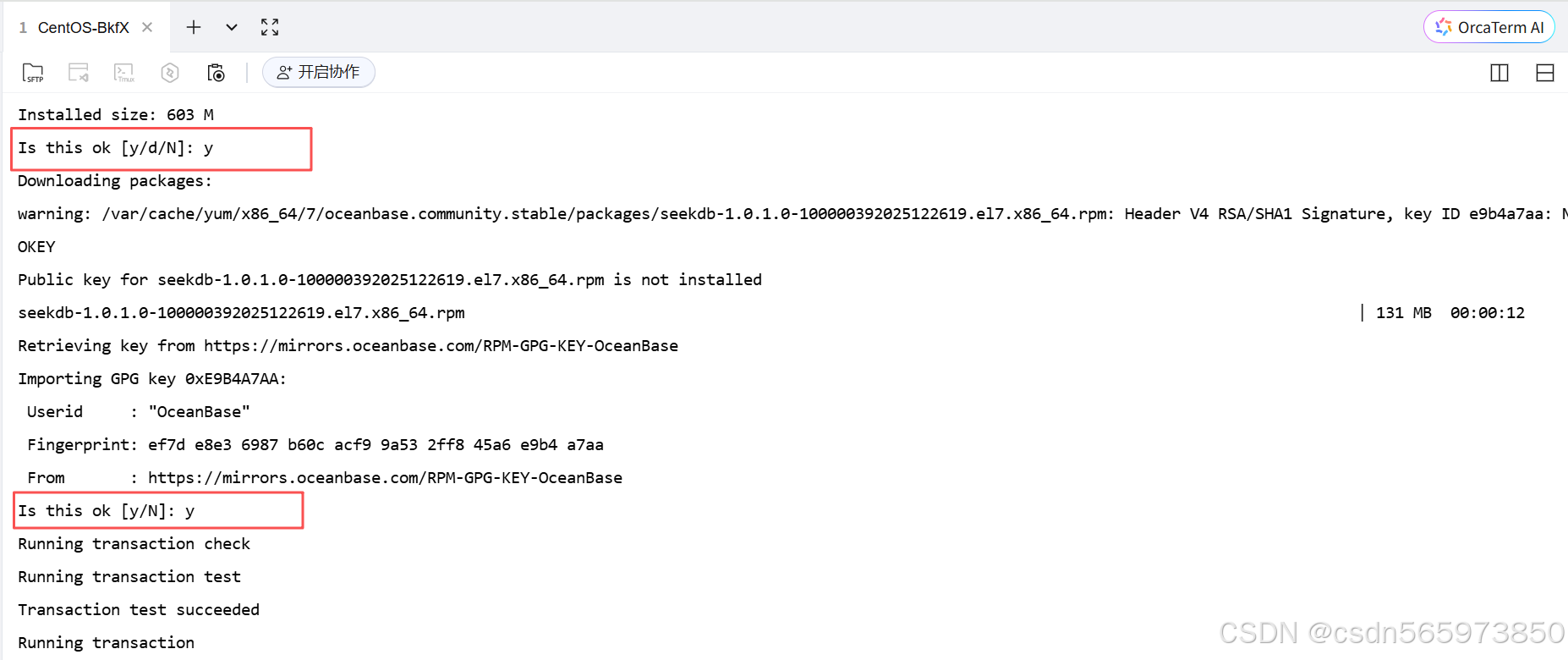
安装成功后,可以看到如下的结果信息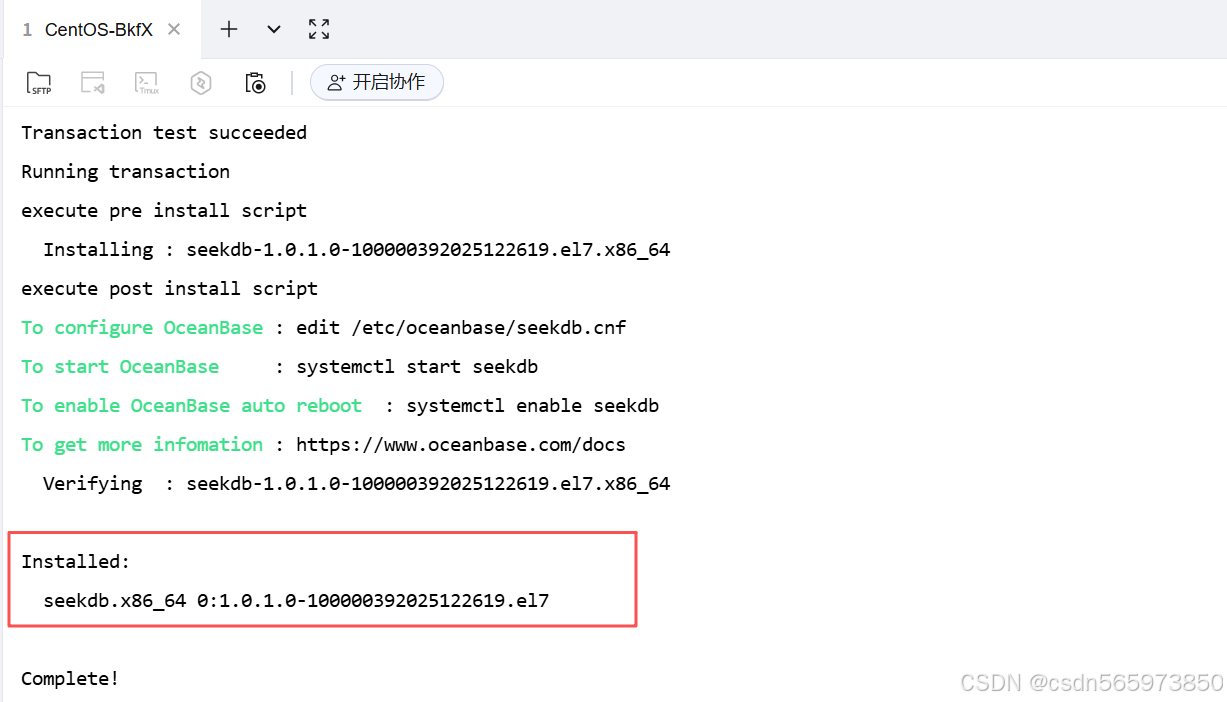
离线安装
离线安装的话,我们可以从 OceanBase 软件下载中心 下载所需版本的 seekdb 。下载完成后,将安装包复制到你的机器上。推荐你使用最新版本的安装包。
在安装包所在目录下,执行 rpm 命令安装 seekdb
sudo rpm -ivh seekdb-*.rpm
启动 seekdb
安装 seekdb 后,我们可以启动seekdb ,这里需要介绍一个配置文件,我们可修改配置文件,未修改的情况下将使用配置文件中的默认配置进行部署
sudo vim /etc/oceanbase/seekdb.cnf
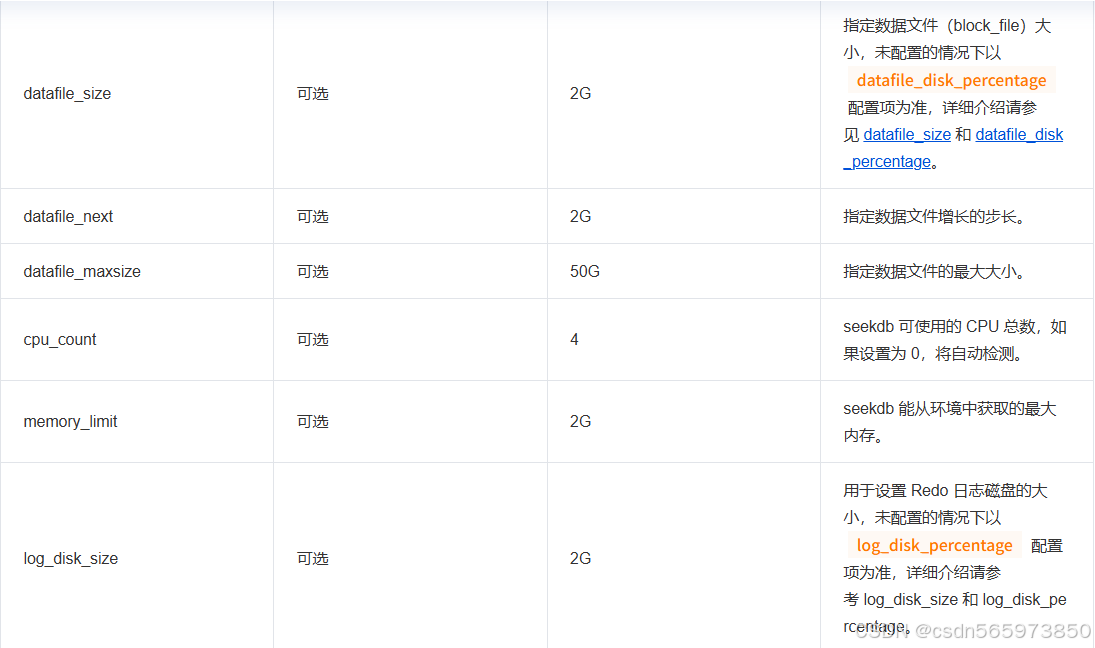
该配置文件包含以下内容
# These parameters are permanently valid
base-dir=/var/lib/oceanbase
data-dir=/var/lib/oceanbase/store
redo-dir=/var/lib/oceanbase/store/redo
# These parameters are valid only during initialization
port=2881
datafile_size=2G
datafile_next=2G
datafile_maxsize=50G
cpu_count=4
memory_limit=2G
log_disk_size=2G
默认配置项情况说明
执行命令
#启动 seekdb
sudo systemctl start seekdb
#查看 seekdb 的启动状态
sudo systemctl status seekdb
执行命令后看到如图说明 seekdb 启动成功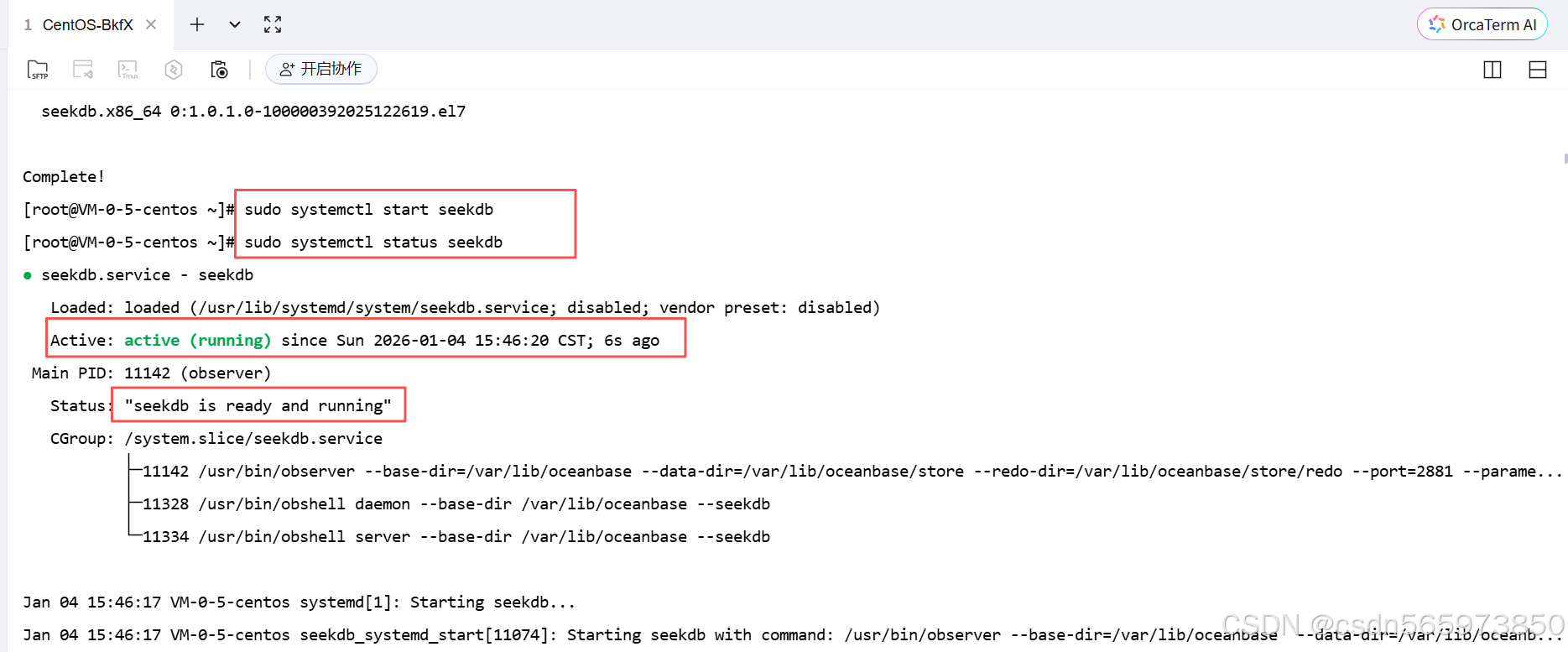
连接 seekdb
这里我们可以通过 MySQL 客户端连接 seekdb 的方式来连接,具体的命令如下
mysql -h<IP> -uroot -P<Port> -p<Passwd> -A oceanbase
# 连接命令
mysql -h127.0.0.1 -uroot -P2881 -p -A oceanbase
参数说明:
-h:提供 seekdb 连接 IP,使用 systemd 启动的 seekdb 默认 IP 为 127.0.0.1。
-u:提供 seekdb 的连接账户,格式:用户名。seekdb 实例用户名默认是 root。
-P:提供 seekdb 连接端口,为 /etc/oceanbase/seekdb.cnf 中 port 的值。
-p:提供 seekdb 连接密码,默认为空。
-A:表示在 MySQL 客户端连接数据库时不自动获取统计信息。
oceanbase:访问的数据库的名称,可以更改为业务数据库名。
执行通过 MySQL 客户端连接 seekdb 发生如下错误提示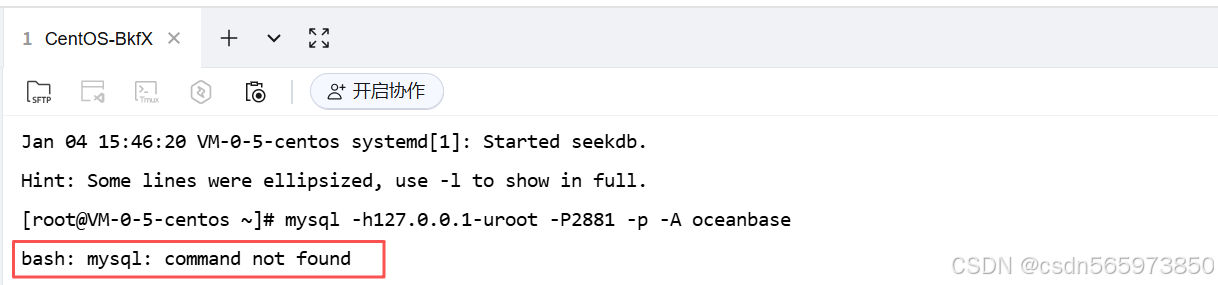
此时我们可以通过打开云服务器的 AI 助手,将我们遇到的命令问题粘贴后等待回复。AI 在分析完错误信息之后,会直接生成可执行命令,我们直接点击执行就可以自动安装 MySQL 客户端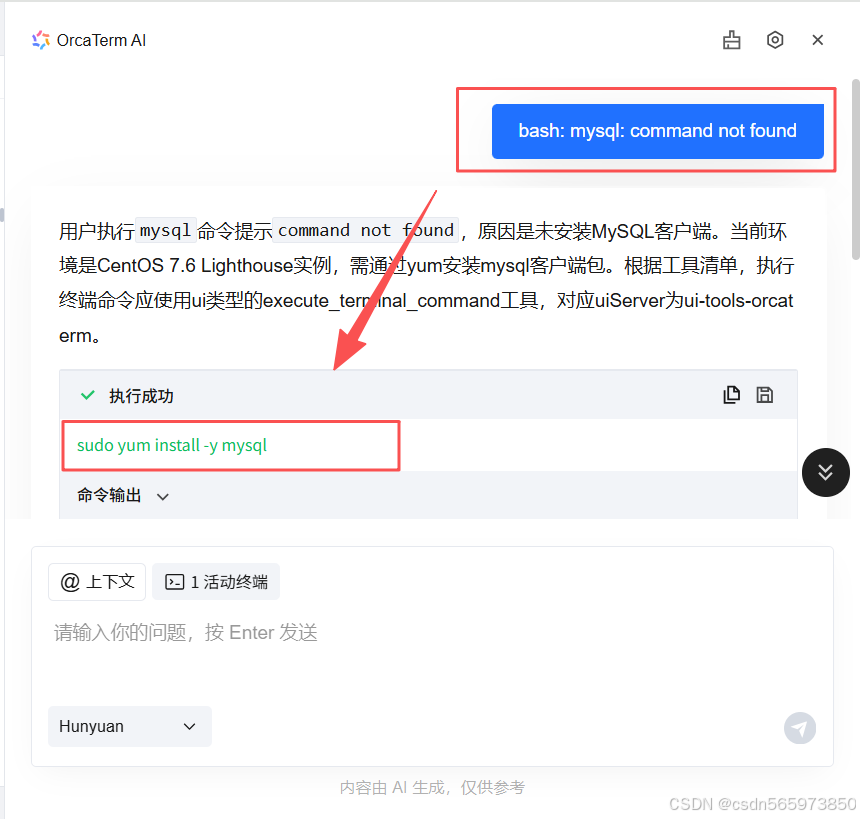
MySQL 客户端 安装成功后可以看到如下截图内容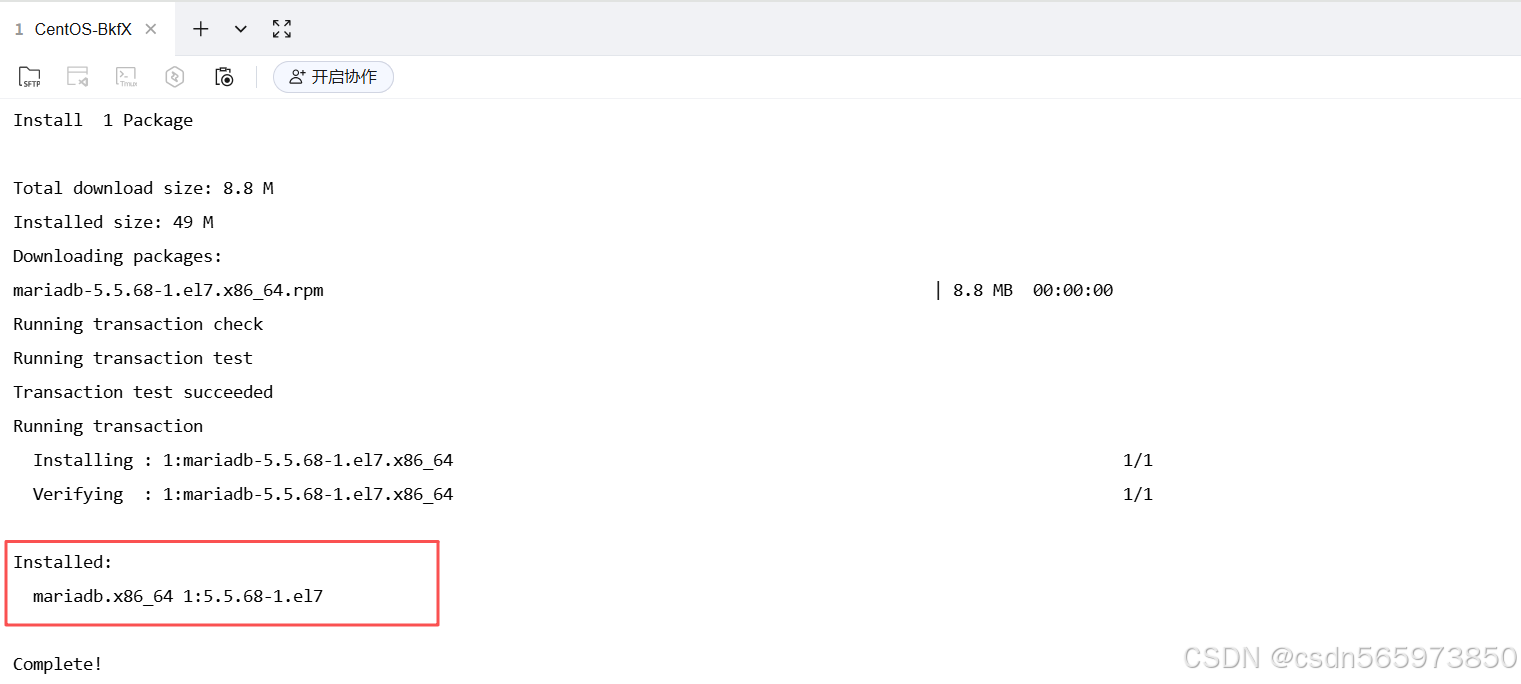
此时再次执行我们的 MySQL 客户端 连接命令,输入密码,这里的密码默认是 空,直接按 enter 键,连接成功后执行 show tables;可以看到当前已经存在的表信息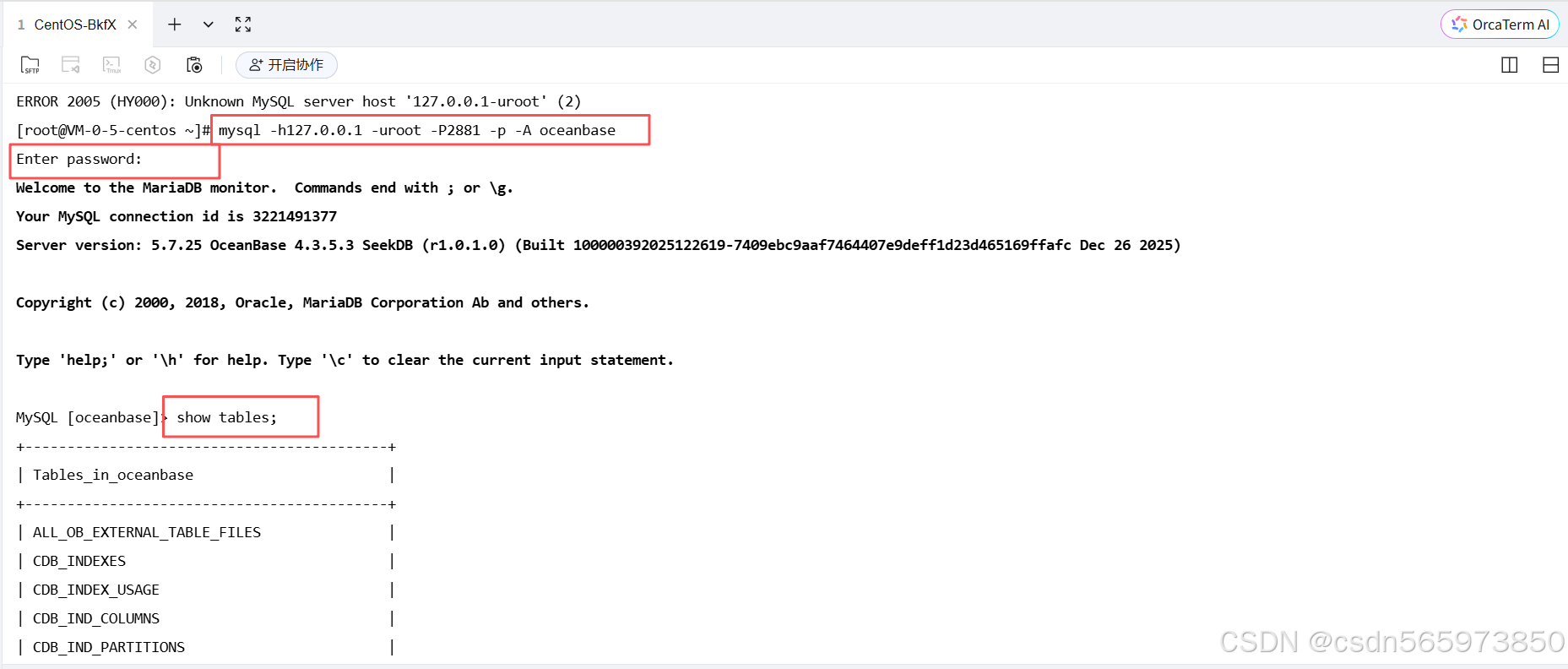
到这里,我们通过 yum install 部署 seekdb 的操作就圆满结束了,后续可以继续通过命令来查看 seekdb的运行状态。
seekdb 启停
我们可以通过 systemd 对 seekdb 进行启动(start)、停止(stop)以及查看状态(status)操作
可执行如下命令查看 seekdb 状态
sudo systemctl status seekdb
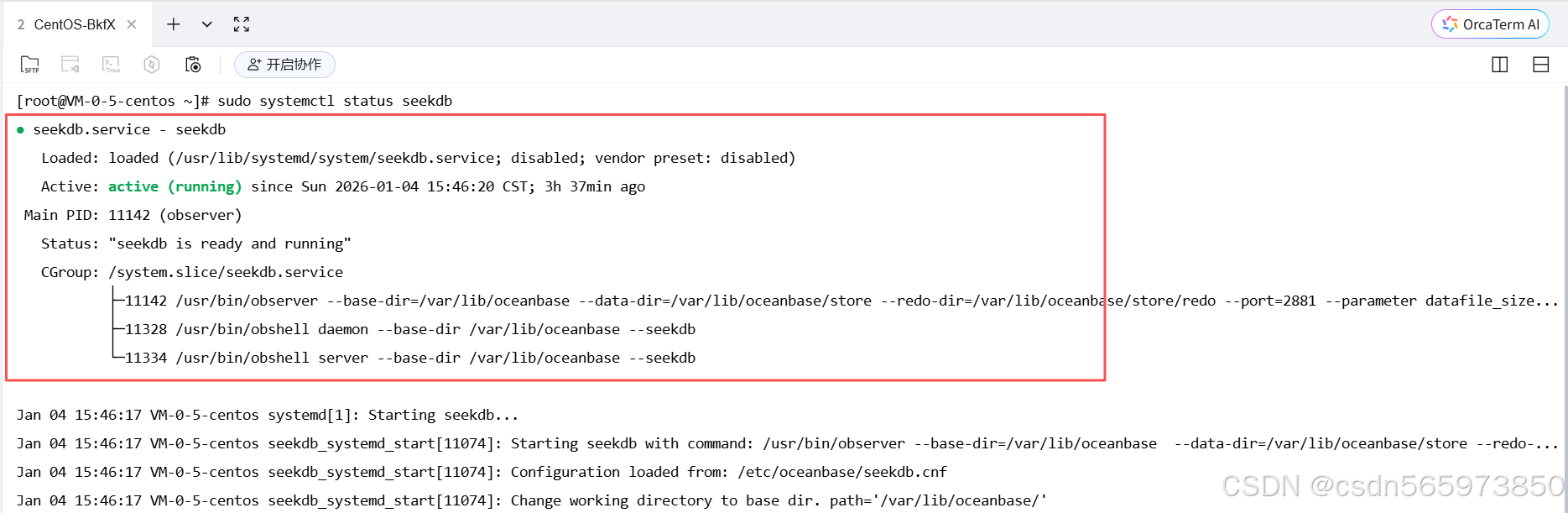
其中:
Active 展示为 active (running),且 Status 展示为 seekdb is ready and running,表示已成功启动 seekdb。
Active 展示为 inactive (dead),表示服务已经停止,即 seekdb 已停止。
Active 展示为 failed,表示服务发生了错误,需查看日志进行排查。
停止 seekdb
sudo systemctl stop seekdb
卸载 seekdb 可以执行以下命令,在线安装方式通过 yum list | grep seekdb 命令查看软件包名,离线安装方式通过 rpm -qa | grep seekdb 命令查看软件包名
# 在线安装方式,执行命令
sudo yum erase seekdb
# 离线安装方式 ,执行命令
sudo rpm -e seekdb
#删除 seekdb 数据
sudo bash /var/lib/oceanbase/oceanbase_clean.sh
混合搜索
在使用混合搜索之前,我们需要先连接 seekdb ,使用 MySQL 客户端连接 seekdb,具体连接命令如下
mysql -h127.0.0.1 -uroot -P2881 -p -A oceanbase
执行命令 show database; 可以查看当前已经存在的数据库
下面我们创建我们自己的数据库
# 创建数据库
create database my_test;
# 切换到自定义数据库
use my_test;
创建示例表并插入数据,这里我们创建一个包含标量列、向量列和全文索引列的文档表,用于演示全文搜索带标量过滤条件和混合搜索
CREATE TABLE doc_table(
c1 INT,
vector VECTOR(3),
query VARCHAR(255),
content VARCHAR(255),
VECTOR INDEX idx1(vector) WITH (distance=l2, type=hnsw, lib=vsag),
FULLTEXT INDEX idx2(query),
FULLTEXT INDEX idx3(content)
)
ORGANIZATION HEAP;
插入示例数据
INSERT INTO doc_table VALUES
(1, '[1,2,3]', "hello world", "seekdb Elasticsearch database"),
(2, '[1,2,1]', "hello world, what is your name", "seekdb database"),
(3, '[1,1,1]', "hello world, how are you", "seekdb mysql database"),
(4, '[1,3,1]', "real world, where are you from", "postgres mysql database"),
(5, '[1,3,2]', "real world, how old are you", "redis mysql database"),
(6, '[2,1,1]', "hello world, where are you from", "starrocks seekdb database");
纯向量搜索
在当今信息爆炸的时代,用户常需要从海量数据中迅速搜索所需信息。例如在线文献数据库、电商平台产品目录、以及不断增长的多媒体内容库,都需要高效的搜索系统来快速定位到用户感兴趣的内容。随着数据量不断激增,传统的基于关键字的搜索方法已经无法满足用户对于搜索精度和速度的需求,向量搜索技术能够很好地解决这些问题。向量搜索通过将文本、图片、音频等不同类型的数据编码为数学上的向量,并在向量空间中进行搜索。这种方法允许系统捕捉数据的深层次语义信息,从而提供更为准确和高效的搜索结果。
向量搜索通过计算向量相似度来查找语义相关的内容,适用于语义搜索、推荐系统等场景。设置搜索参数,使用向量搜索查找与查询向量 [1,2,3] 最相似的记录
SET @parm = '{
"knn" : {
"field": "vector",
"k": 3,
"query_vector": [1,2,3]
}
}';
SELECT JSON_PRETTY(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm));
执行命令如图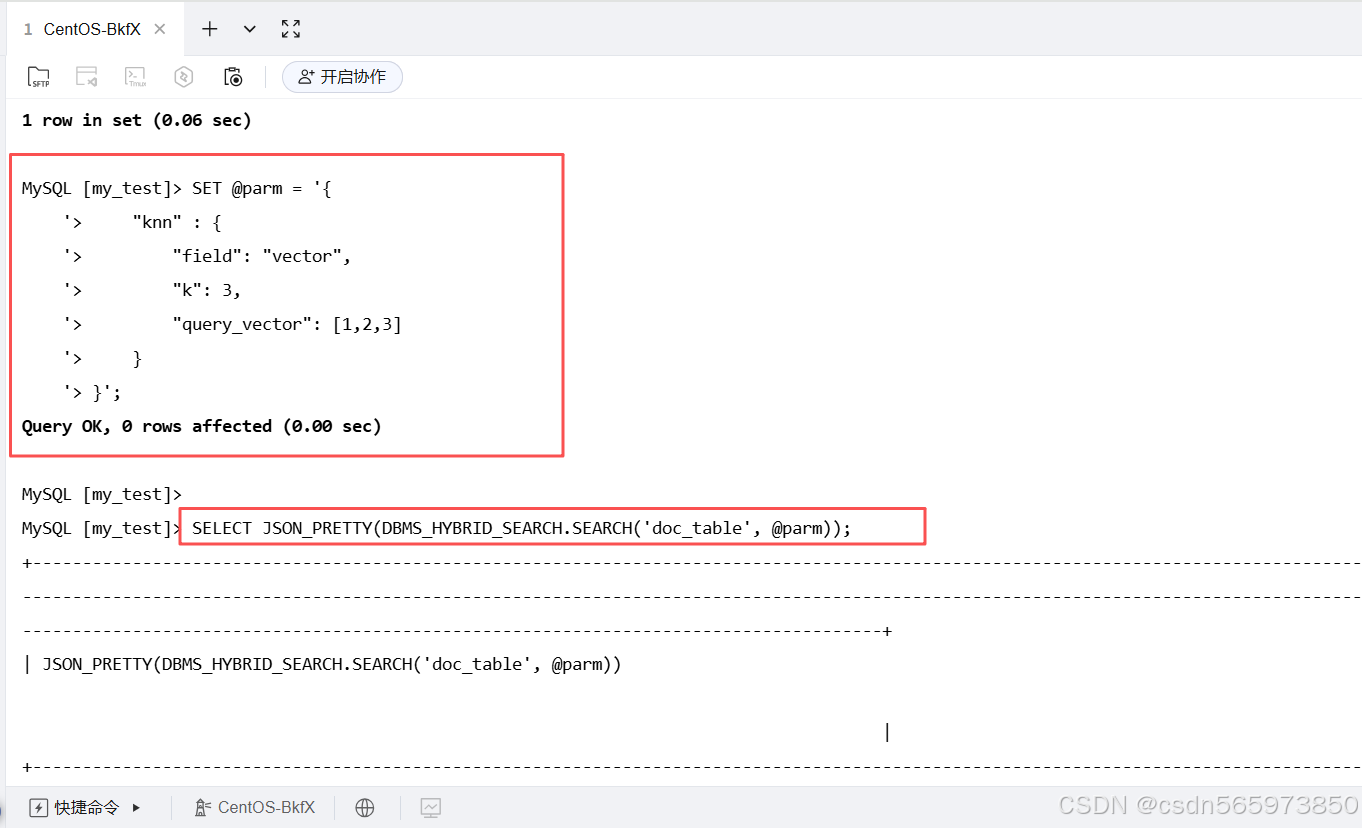
返回结果
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| JSON_PRETTY(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm)) |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| [
{
"c1": 1,
"query": "hello world",
"_score": 1.0,
"vector": "[1,2,3]",
"content": "seekdb Elasticsearch database"
},
{
"c1": 5,
"query": "real world, how old are you",
"_score": 0.41421356,
"vector": "[1,3,2]",
"content": "redis mysql database"
},
{
"c1": 2,
"query": "hello world, what is your name",
"_score": 0.33333333,
"vector": "[1,2,1]",
"content": "seekdb database"
}
] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
其中:返回结果按向量相似度排序,_score 表示相似度分数,分数越高表示越相似。
纯全文搜索
全文索引(Full-Text Index)是数据库中用于加速文本数据搜索的特殊索引类型,特别适用于处理包含大量文本字段(如文章内容、评论、博客等)的查询需求。它支持快速的关键词匹配查询,可以在文本中查找一个或多个词语,并返回相关结果。全文索引常常应用于搜索引擎和文本分析系统中,有效帮助企业快速定位关键信息,提升搜索效率。
全文搜索通过关键词匹配查找内容,适用于文档搜索、产品搜索等场景。设置搜索参数,使用全文搜索查找 query 和 content 字段中包含关键词的记录
SET @parm = '{
"query": {
"query_string": {
"fields": ["query", "content"],
"query": "hello oceanbase"
}
}
}';
SELECT JSON_PRETTY(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm));
查询执行结果如下
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| JSON_PRETTY(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm)) |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| [
{
"c1": 1,
"query": "hello world",
"_score": 0.37162162162162166,
"vector": "[1,2,3]",
"content": "seekdb Elasticsearch database"
},
{
"c1": 3,
"query": "hello world, how are you",
"_score": 0.3503184713375797,
"vector": "[1,1,1]",
"content": "seekdb mysql database"
},
{
"c1": 6,
"query": "hello world, where are you from",
"_score": 0.3503184713375797,
"vector": "[2,1,1]",
"content": "starrocks seekdb database"
},
{
"c1": 2,
"query": "hello world, what is your name",
"_score": 0.3313253012048193,
"vector": "[1,2,1]",
"content": "seekdb database"
}
] |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
其中:返回结果按关键词匹配度排序,_score 表示匹配度分数,分数越高表示匹配度越好。
混合搜索
混合搜索同时结合关键词匹配和语义理解,提供更精准、全面的搜索结果,能够同时利用全文索引和向量索引的优势。设置搜索参数,同时进行全文搜索和向量搜索
SET @parm = '{
"query": {
"query_string": {
"fields": ["query", "content"],
"query": "hello oceanbase"
}
},
"knn" : {
"field": "vector",
"k": 5,
"query_vector": [1,2,3]
}
}';
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm));
返回查询结果如下
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm)) |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| [
{
"c1": 1,
"query": "hello world",
"_score": 1.3716216216216217,
"vector": "[1,2,3]",
"content": "seekdb Elasticsearch database"
},
{
"c1": 2,
"query": "hello world, what is your name",
"_score": 0.6646586312048193,
"vector": "[1,2,1]",
"content": "seekdb database"
},
{
"c1": 3,
"query": "hello world, how are you",
"_score": 0.6593354613375797,
"vector": "[1,1,1]",
"content": "seekdb mysql database"
},
{
"c1": 5,
"query": "real world, how old are you",
"_score": 0.41421356,
"vector": "[1,3,2]",
"content": "redis mysql database"
},
{
"c1": 6,
"query": "hello world, where are you from",
"_score": 0.3503184713375797,
"vector": "[2,1,1]",
"content": "starrocks seekdb database"
},
{
"c1": 4,
"query": "real world, where are you from",
"_score": 0.30901699,
"vector": "[1,3,1]",
"content": "postgres mysql database"
}
] |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
其中:混合搜索的结果会综合考虑关键词匹配分数 (_keyword_score) 和语义相似度分数 (_semantic_score)。最终的 _score 是这两者之和,用于对搜索结果进行全面排序。
AI 函数服务
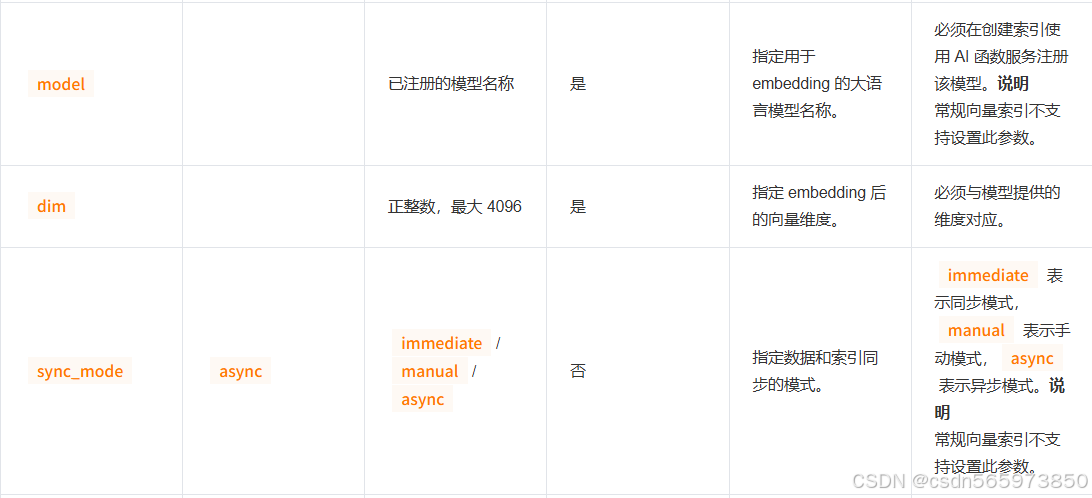
AI 函数通过 SQL 表达式,将 AI 模型能力直接集成到数据库内的数据处理中。它极大地简化了利用 AI 大模型进行数据提取、分析、总结和保存等操作,是当前数据库和数据仓库领域的重要新特性。seekdb 通过 DBMS_AI_SERVICE 包提供全面的 AI 模型和端点管理,并内置了多个 AI 函数表达式,同时支持通过视图监控 AI 模型调用情况。您无需编写额外代码,即可在 SQL 中直接调用 AI 模型,几分钟内即可体验 AI_COMPLETE、AI_EMBED、AI_RERANK、AI_PROMPT 几个核心函数:
AI_EMBED:通过调用嵌入模型(Embedding Model)将文本数据转换为向量数据。
AI_COMPLETE:通过调用指定文本生成大模型处理提示词和数据信息,并解析处理结果。
AI_PROMPT:将提示词模板和动态数据组织成 JSON 格式,可以在 AI_COMPLETE 函数中替换 prompt 参数直接使用。
AI_RERANK:通过调用重排序模型(Rerank Model)根据提示词对文本进行相似度排序。
该特性可以应用于文本生成、文本转换、文本重排序等场景。
DBMS_AI_SERVICE
在使用AI 函数服务之前,需要先注册模型和端点,那么说到这里,就需要先介绍一下 DBMS_AI_SERVICE 包提供的 AI 模型和端点管理能力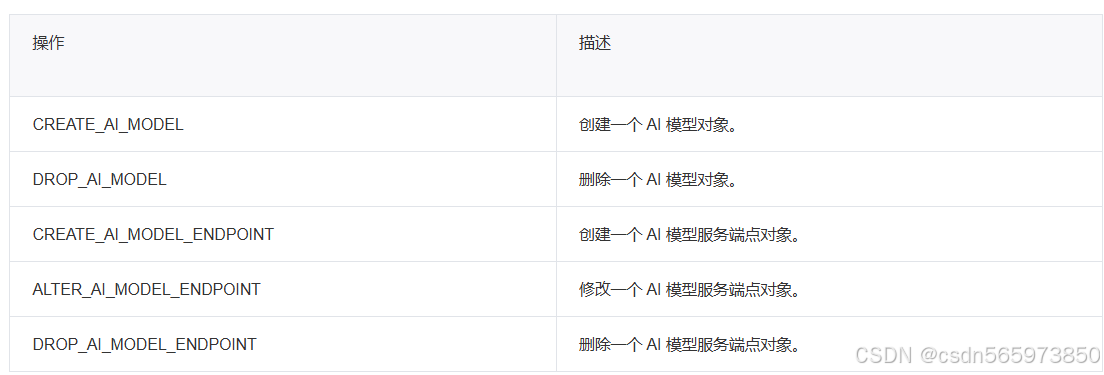
其中,下面我们主要用到的 CREATE_AI_MODEL_ENDPOINT 的参数有一些需要注意,这里直接标记出来

url 参数取值范围: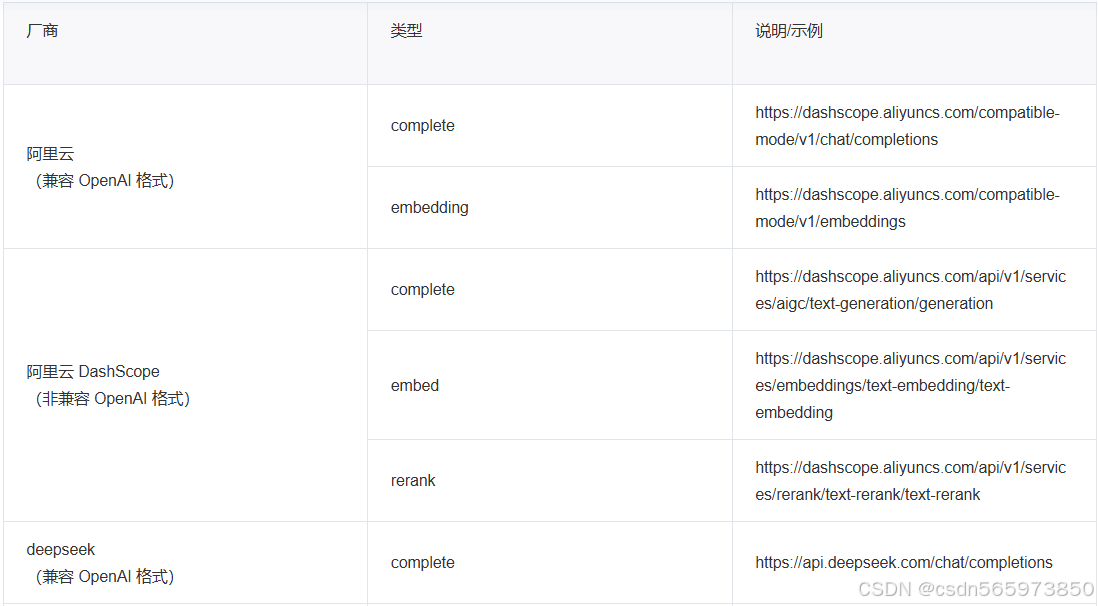
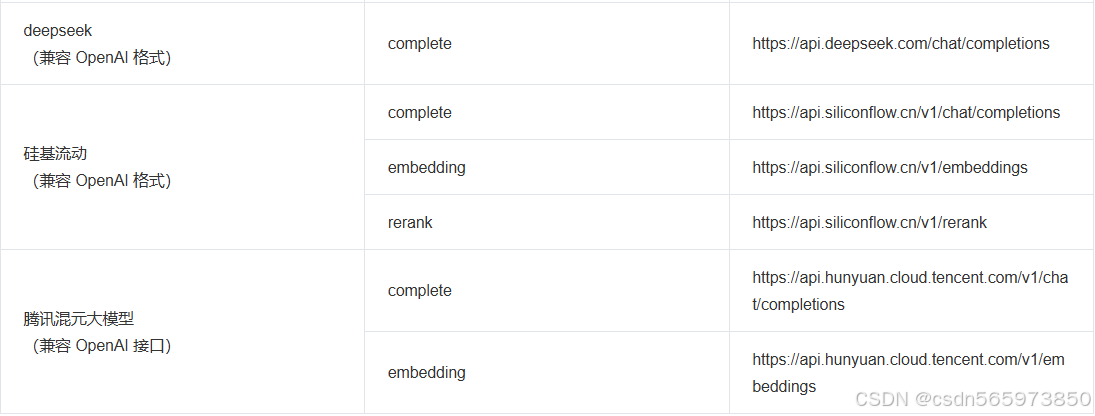
关于 DBMS_AI_SERVICE 具体操作的入参介绍可以参考: https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004479802 下面我们开始我们后面基于AI 函数服务的操作。
前提条件
在使用 AI 函数服务之前,我们需要先准备一下基础参数。这里在 DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT 注册模型的时候会用到 url 和 access_key ,这里的url 我们就用上面 DBMS_AI_SERVICE 操作入参介绍文档中提供的url 即可,下面我们获取 access_key 。
这里我们会用阿里云百炼的大模型,那么就需要阿里云账号登录。登录阿里云账号,打开阿里云百炼平台 选择【密钥管理】-【创建API-KEY】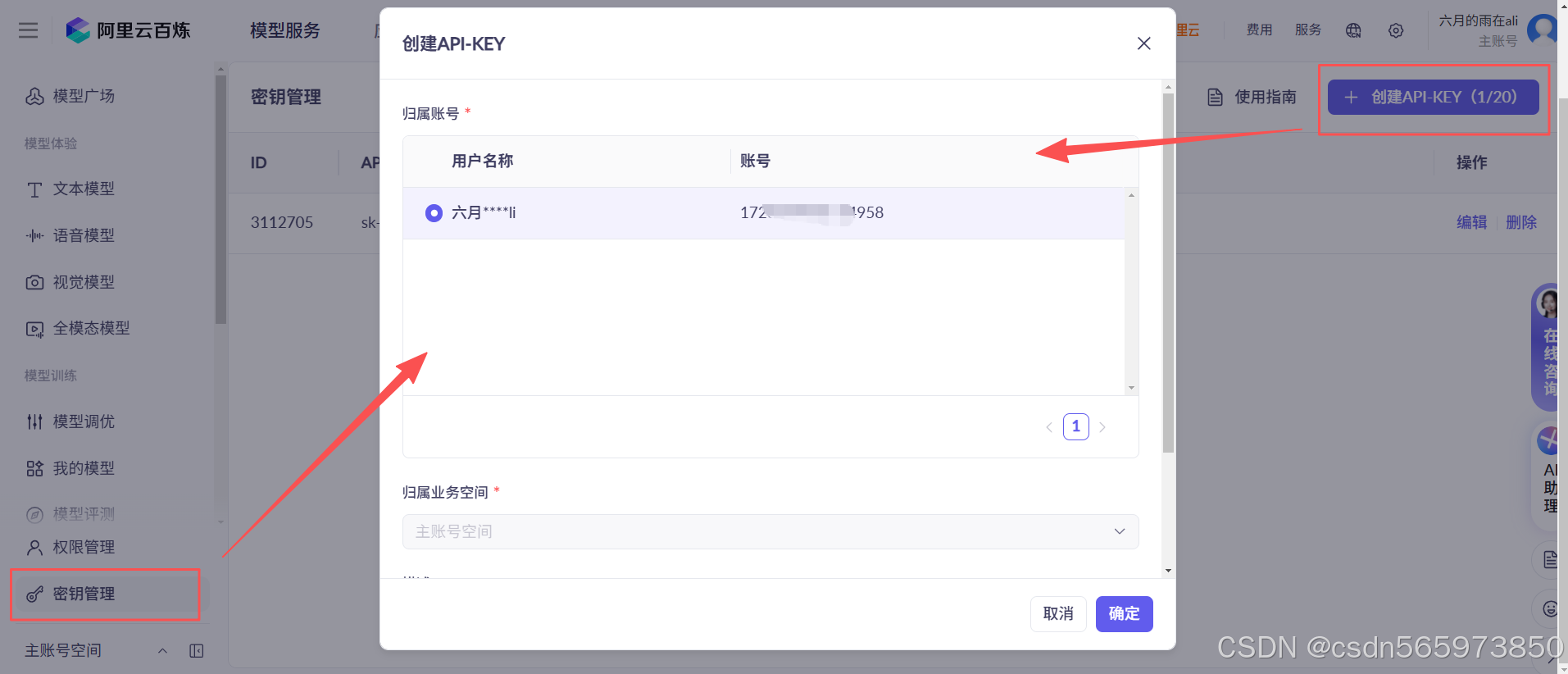
点击【确定】后完成阿里云百炼大模型 API-KEY 的创建,回到 密钥管理 列表页面,选择【复制】保存 API-KEY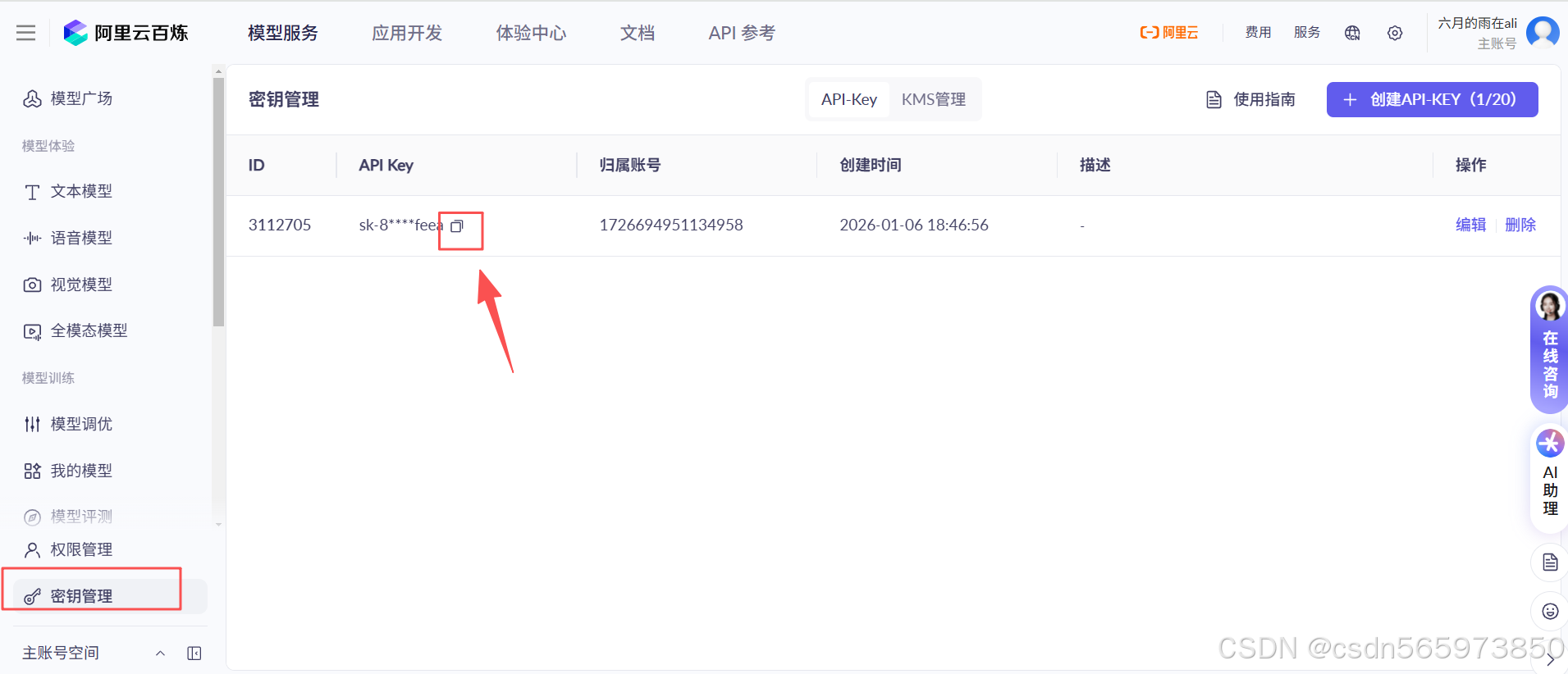
AI_EMBED 生成向量
AI_EMBED 可以将文本转换为向量,用于向量搜索。这是向量搜索的基础步骤,将文本数据转换为高维向量表示,以便进行相似度计算。
AI_EMBED 函数通过 model_key 指定一个已注册的嵌入模型(Embedding Model),将用户提供的文本数据转换为向量数据。当模型支持多个维度时,允许通过 dim 参数指定输出相关维度的向量。
语法格式如下:
AI_EMBED(model_key, input, [dim])
参数说明: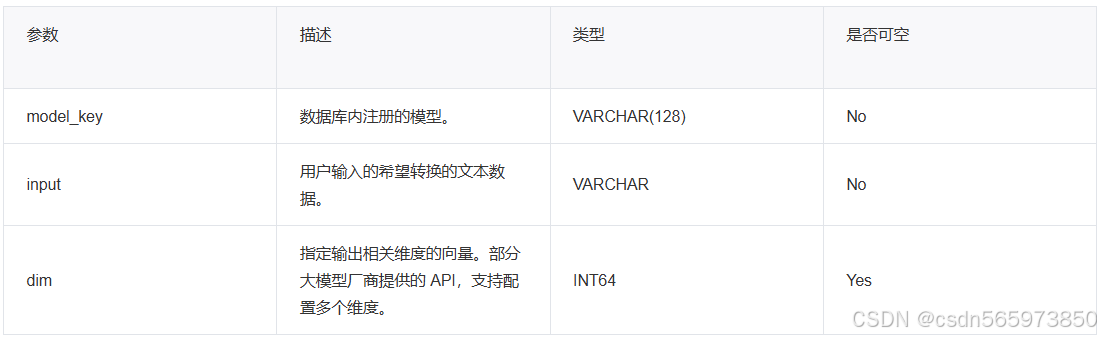
在开始 生成向量之前,我们需要先 注册嵌入模型和端点 。这里我们就可以注册模型和端点了
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_embed');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_embed_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_embed', '{
"type": "dense_embedding",
"model_name": "text-embedding-v2"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_embed_endpoint', '{
"ai_model_name": "ob_embed",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"access_key": "sk-86cd4617f24e42d1b24e73093a85feea",
"provider": "aliyun-openAI"
}');
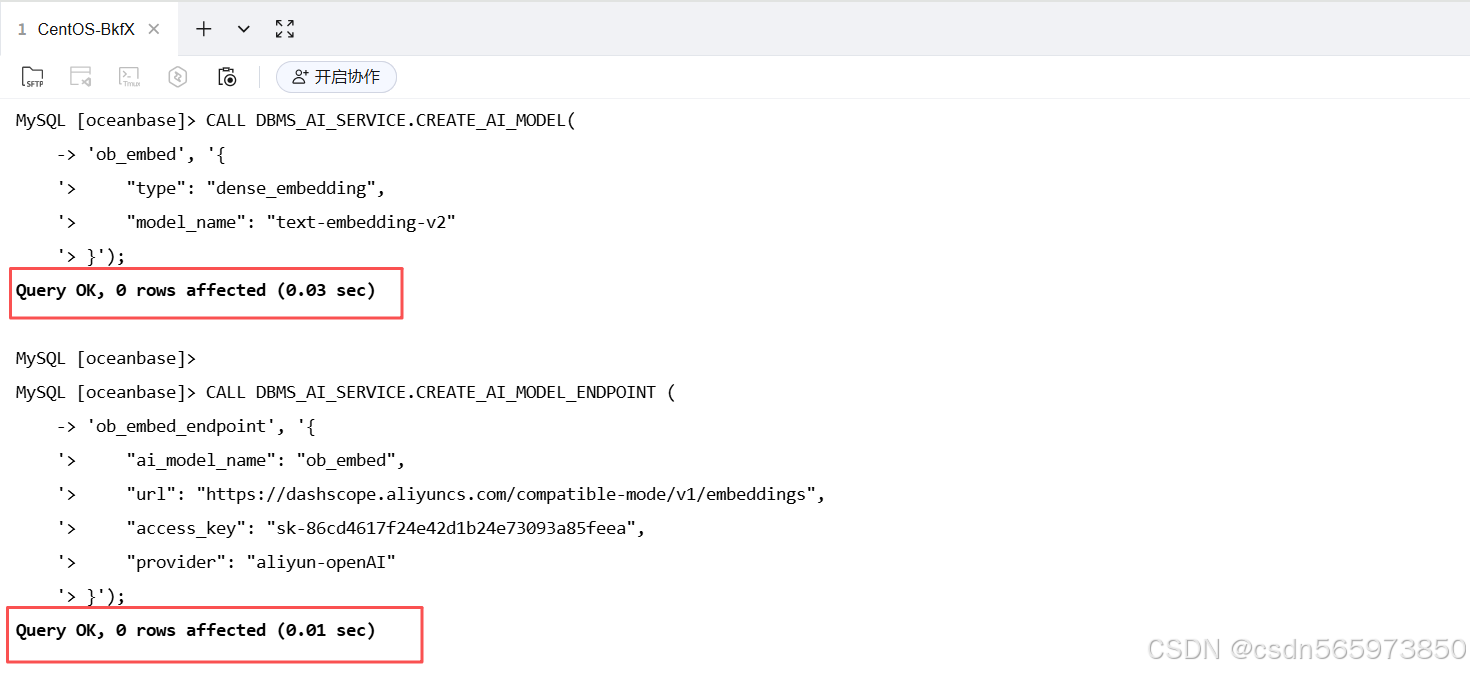
执行后可以看到结果
一切准备就绪之后,下面我们就可以嵌入单行数据了,比如
SELECT AI_EMBED("ob_embed", "Hello world") AS embedding;
执行结果如图所示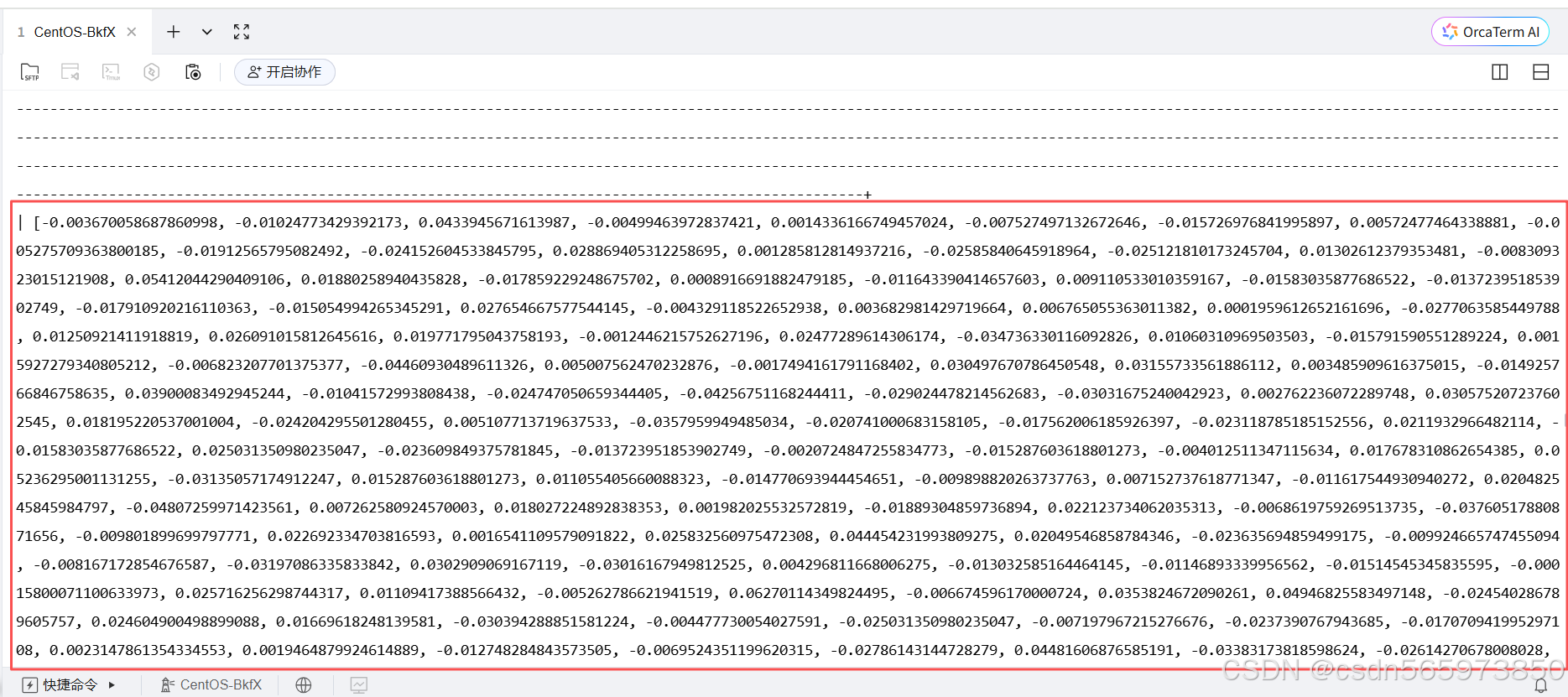
到这里,我们使用 AI_EMBED 将文本转换为向量就转换成功了。
AI_COMPLETE 和 AI_PROMPT 生成文本
AI_COMPLETE 可以在 SQL 中直接调用大语言模型,实现文本生成、翻译、分析等功能。AI_PROMPT 函数可以将提示词模板和动态数据组织成 JSON 格式,可以在 AI_COMPLETE 函数中替换 prompt 参数直接使用。
AI_COMPLETE 函数通过 model_key 指定一个已注册的文本生成大模型(LLM),对用户提供的提示词(prompt)和数据进行处理,并返回大模型生成的文本信息。用户可以在 prompt 参数中自定义组织提示词和数据库内的数据格式。
AI_PROMPT 函数用于构建和格式化提示词,支持动态插入数据。
AI_PROMPT 函数语法如下:
AI_PROMPT('template', expr0 [ , expr1, ... ]);

在开始 生成文本之前,我们同样需要先 注册文本生成模型和端点 ,下面我们开始注册模型和端点
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_complete');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_complete_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_complete', '{
"type": "completion",
"model_name": "qwen3-vl-plus"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_complete_endpoint', '{
"ai_model_name": "ob_complete",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions",
"access_key": "sk-86cd4617f24e42d1b24e73093a85feea",
"provider": "aliyun-openAI"
}');
文本生成模型注册成功后如图
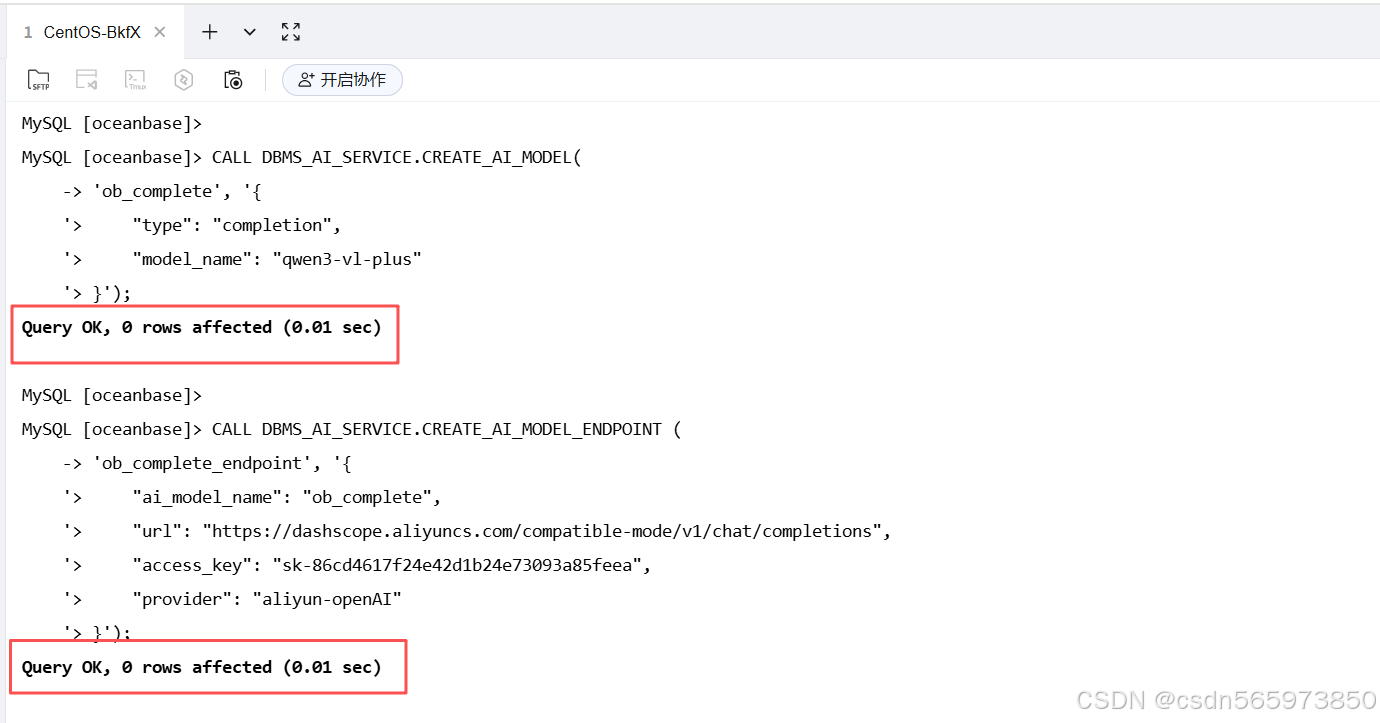
下面我们简单测试一下,进行文本内容的情感分析,输入
SELECT AI_COMPLETE("ob_complete", AI_PROMPT('你的任务是对提供的文本进行情感分析,判断其情感倾向为正面还是负面。
以下是需要分析的文本:
<text>
{0}
</text>
判断标准如下:
如果文本表达的是正面情感,输出1;如果文本表达的是负面情感,输出 -1。不要输出其他东西。', '天气真好啊')) AS sentiment;
执行情感分析后返回内容如下
AI_RERANK 优化搜索结果
AI_RERANK 可以对搜索结果进行智能重排序,根据查询词的相关性对文档列表重新排序。
AI_RERANK 函数通过 model_key 指定一个已注册的重排序模型(Rerank Model),将用户提供的查询词和文档列表按厂商规则组织消息发送给指定模型,解析并返回模型返回的排序结果,适用于 RAG 的 rerank 场景。
语法格式如下:
AI_RERANK(model_key, query, documents[, document_key])
参数说明: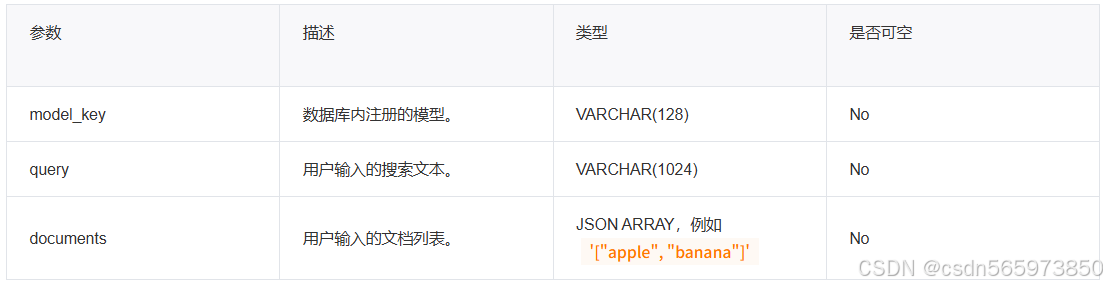
在开始对搜索结果进行智能化重排序之前,同样需要先 注册重排序模型和端点 ,执行下面的语句注册模型和端点。这里考虑到 模型供应商 aliyun-openAI 不支持 rerank ,这里我们切换为 阿里云 DashScope
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_rerank');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_rerank_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_rerank', '{
"type": "rerank",
"model_name": "qwen3-rerank"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_rerank_endpoint', '{
"ai_model_name": "ob_rerank",
"url": "https://dashscope.aliyuncs.com/api/v1/services/rerank/text-rerank/text-rerank",
"access_key": "sk-86cd4617f24e42d1b24e73093a85feea",
"provider": "aliyun-dashscope"
}');
注册完成模型和端点之后可以看到如图
执行下面语句尝试重排序
SELECT AI_RERANK("ob_rerank", "Apple", '["apple", "banana", "fruit", "vegetable"]');
返回结果如图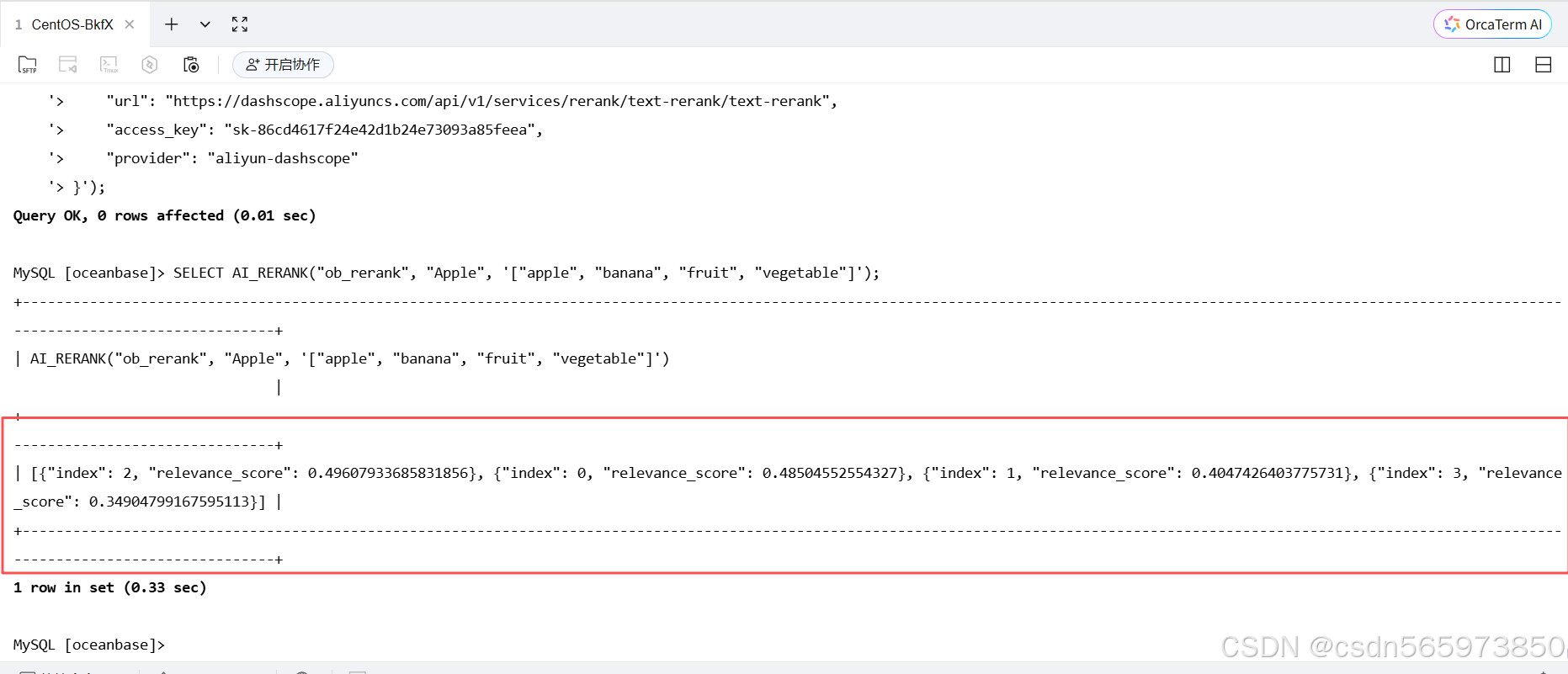
构建智能问答系统
构建智能问答系统就是基于上面三个AI 函数来实现,本示例需要同时使用嵌入模型、文本生成模型和重排序模型,如果已经按照上面注册模型和端点的方式对三个 AI 函数完成了模型注册,下面的语句就无需执行。如果没有注册模型的话,则需要执行下面的语句
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_embed');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_embed_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_embed', '{
"type": "dense_embedding",
"model_name": "text-embedding-v2"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_embed_endpoint', '{
"ai_model_name": "ob_embed",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"access_key": "sk-86cd4617f24e42d1b24e73093a85feea",
"provider": "aliyun-openAI"
}');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_complete');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_complete_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_complete', '{
"type": "completion",
"model_name": "qwen3-vl-plus"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_complete_endpoint', '{
"ai_model_name": "ob_complete",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions",
"access_key": "sk-86cd4617f24e42d1b24e73093a85feea",
"provider": "aliyun-openAI"
}');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_rerank');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_rerank_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_rerank', '{
"type": "rerank",
"model_name": "qwen3-rerank"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_rerank_endpoint', '{
"ai_model_name": "ob_rerank",
"url": "https://dashscope.aliyuncs.com/api/v1/services/rerank/text-rerank/text-rerank",
"access_key": "sk-86cd4617f24e42d1b24e73093a85feea",
"provider": "aliyun-dashscope"
}');
下面我们开始构建智能问答系统。首先我们需要准备数据,生成向量数据方便后面查询
CREATE TABLE knowledge_base (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
embedding TEXT
);
INSERT INTO knowledge_base (title, content) VALUES
('seekdb 简介', 'seekdb 是一个强大的数据库系统,支持向量搜索和 AI 函数。'),
('向量搜索', '向量搜索可以用于语义搜索,找到相似的内容。'),
('AI 函数', 'AI 函数可以在 SQL 中直接调用 AI 模型。');
UPDATE knowledge_base
SET embedding = AI_EMBED("ob_embed", content);
执行完成之后,我们继续进行向量搜索重排序操作
SET @query = "什么是向量搜索?";
SET @query_vector = AI_EMBED("ob_embed", @query);
SET @candidate_docs = '["seekdb 是一个强大的数据库系统,支持向量搜索和 AI 函数。", "向量搜索可以用于语义搜索,找到相似的内容。"]';
SELECT AI_RERANK("ob_rerank", @query, @candidate_docs) AS ranked_results;
返回结果如下,index 为文档索引,relevance_score 为相关性分数
下面我们就可以来看我们智能问答的效果了,基于第一步的问题搜索和第二步的重排序结果,生成答案
SELECT AI_COMPLETE("ob_complete",
AI_PROMPT('基于以下文档内容,回答用户的问题。
用户问题:{0}
相关文档:{1}
请基于以上文档内容,简洁准确地回答用户的问题。', @query, CAST(JSON_EXTRACT(@candidate_docs, '$[1]') AS CHAR))) AS answer;
这样我们就在 seekdb 数据库内快速完成完整的 AI 应用流程:向量化、搜索、重排序、生成答案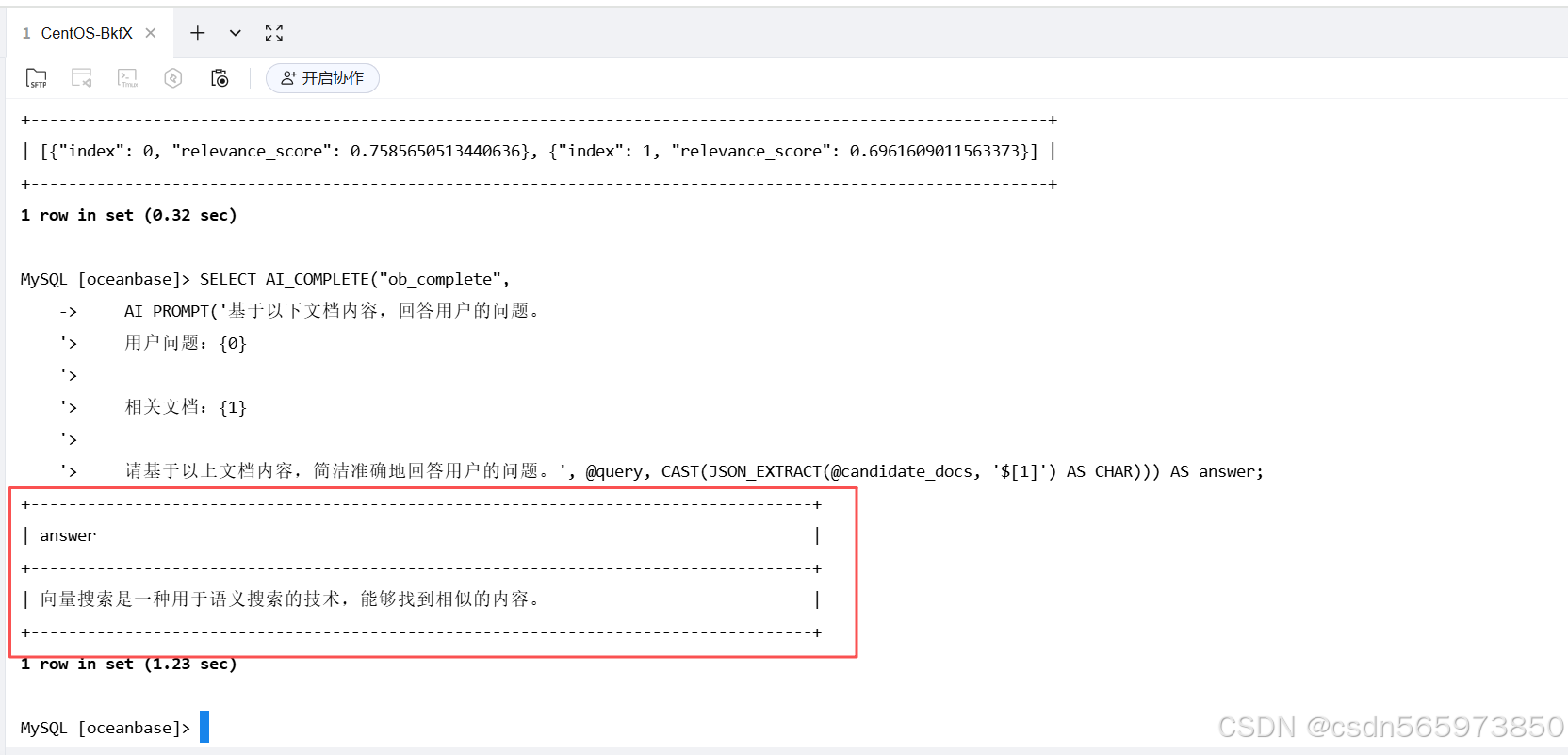
到这里,我们对于AI 函数服务 AI_EMBED、AI_COMPLETE、AI_RERANK 的核心功能以及语法格式,参数说明等都有了一个比较深刻的认知。同时对于注册模型和端点 的服务 DBMS_AI_SERVICE 也有了一个熟悉的操作经验。
语义索引
作为研发,大家在日常工作中都会用到索引,那么对于 seekdb 同样可以创建索引。
语义索引(Hybrid Vector Index)利用 seekdb 内置的嵌入(Embedding)能力,极大地简化了向量索引的使用流程。它实现了向量概念对用户的透明化:你可以直接写入需要存储的原始数据(如文本),seekdb 会在内部自动将其转换为向量并建立索引。在搜索时,你同样只需提供原始搜索内容,seekdb 也会自动进行嵌入并搜索向量索引,从而显著提升了使用的便捷性。
考虑到嵌入模型的性能开销,语义索引提供了同步和异步两种嵌入方式供用户选择:
同步模式:数据写入后立即进行嵌入和索引,确保数据实时可见。
异步模式:由后台任务分批进行数据的嵌入和索引,这能显著提升写入性能。你可以根据对数据实时可见性的要求,灵活设置后台任务的触发周期。
此外,本特性还提供了对语义索引进行暴力搜索的能力,用以辅助判断搜索结果的正确性。暴力搜索指的是采用全表扫描的方式进行搜索,得到距离最近的前 n 行的精确结果。
当前版本仅支持 HNSW/HNSW_BQ 索引。
支持的功能点如下: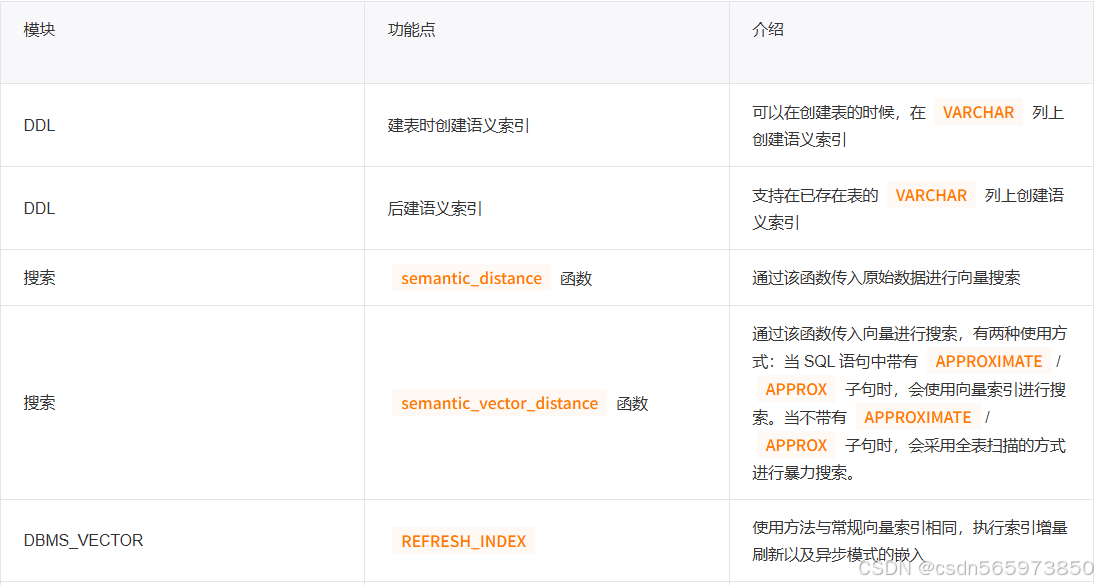

前提条件
在使用语义索引之前,必须先注册嵌入模型和端点。上面我们已经掌握了使用阿里云百炼来注册模型和端点,下面我们来换一家服务商,比如:硅基流动。在使用硅基流动api 之前,没有账号的话需要先注册账号,注册完成后,可以获取access_key 。
在硅基流动控制台页面: https://cloud.siliconflow.cn/me/account/ak 选择【API密钥】-【新建API密钥】输入密钥描述后点击【新建密钥】完成密钥创建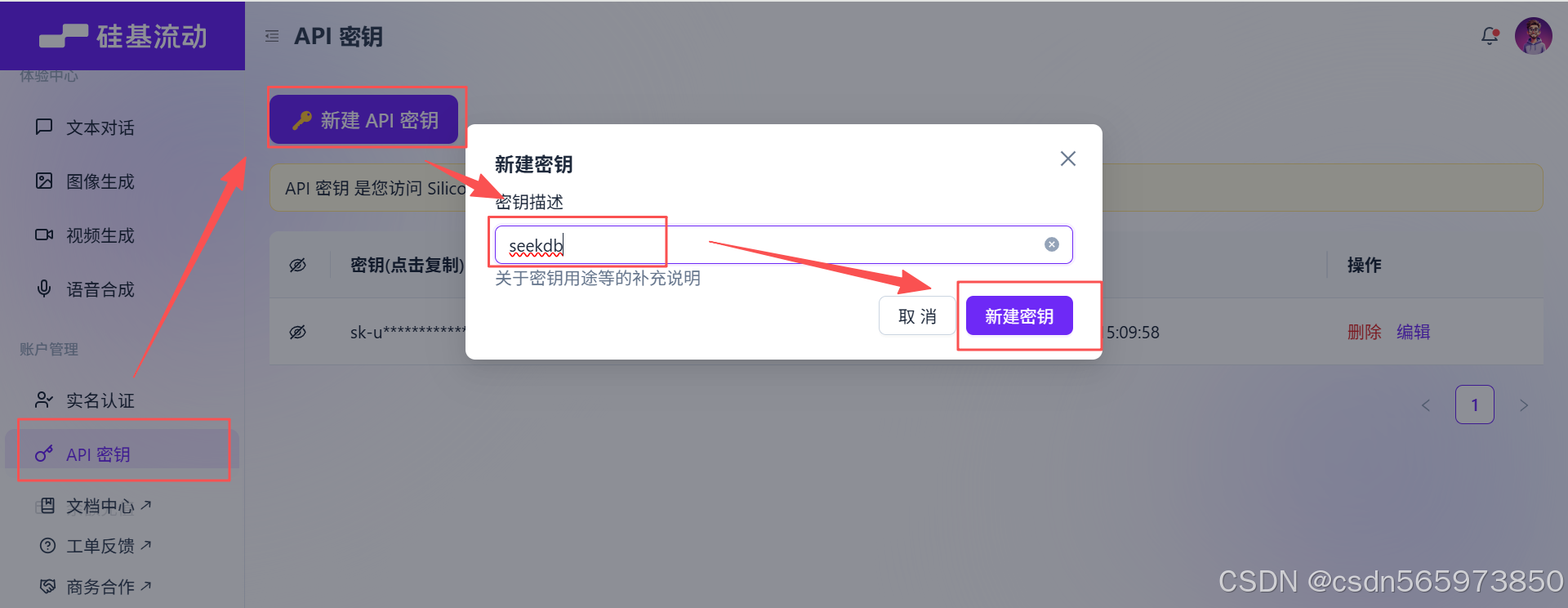
在 【API密钥】列表页面,选择【复制】按钮复制 API密钥备用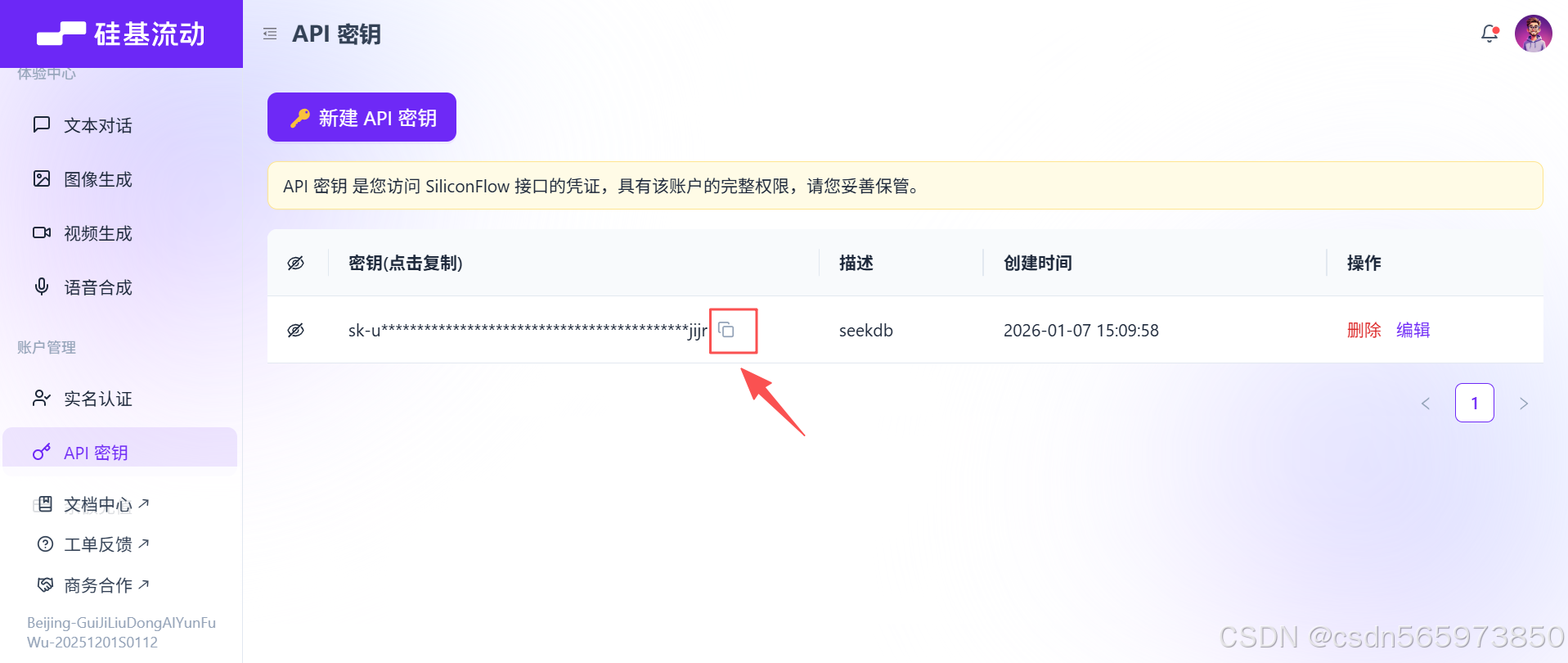
密钥准备完毕,关于硅基流动的计费大家可能也比较关系,在硅基流动官网可以看到还是有一部分模型可以免费用的,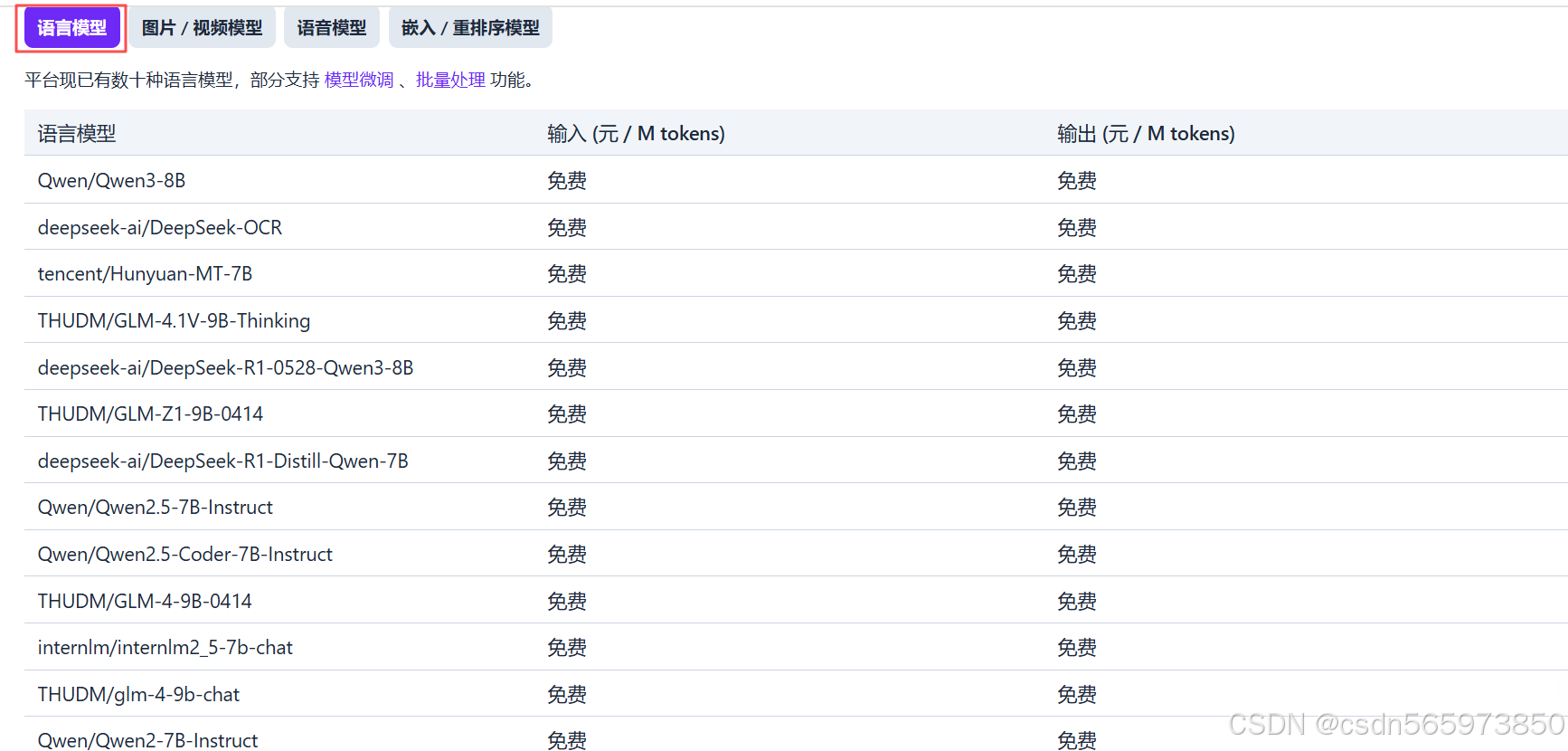
下面我们就可以注册模型和端口了
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_embed');
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_embed_endpoint');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'ob_embed', '{
"type": "dense_embedding",
"model_name": "BAAI/bge-m3"
}');
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
'ob_embed_endpoint', '{
"ai_model_name": "ob_embed",
"url": "https://api.siliconflow.cn/v1/embeddings",
"access_key": "sk-ugcqbuimzlbnovfoyhmncfbzsjirvkmvonzimctcgbzmjijr",
"provider": "siliconflow"
}');
建表时创建
支持使用 CREATE TABLE 语句创建语义索引,通过索引参数,同步或者异步发起后台任务。同步模式会在插入数据时自动将 VARCHAR 数据转换成向量数据,异步模式则会定期或者手动完成数据转换。
语法格式如下
CREATE TABLE table_name (
column_name1 data_type1,
column_name2 VARCHAR, -- 文本列
...,
VECTOR INDEX index_name (column_name2) WITH (param1=value1, param2=value2, ...)
);
参数说明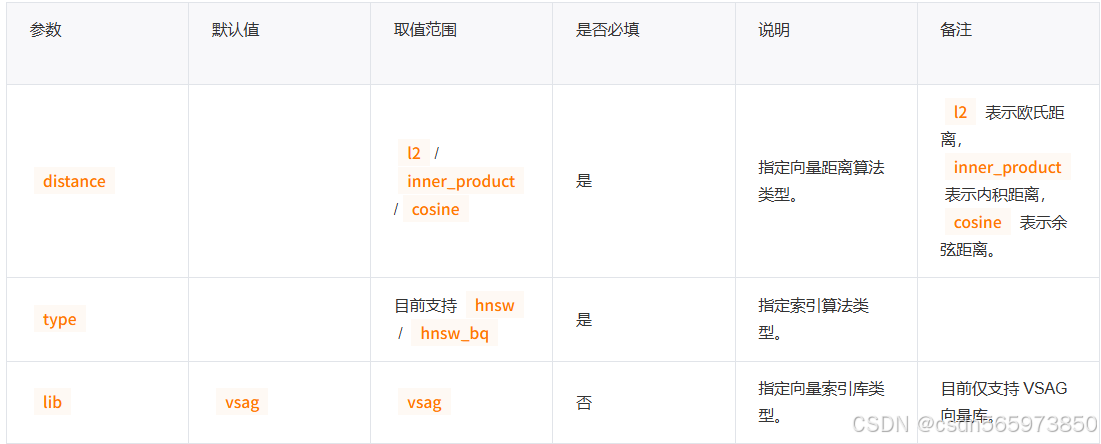

比如这里我们创建测试表 items 时创建 vector_idx 索引并插入一条数据
CREATE TABLE items (
id BIGINT PRIMARY KEY,
doc VARCHAR(100),
VECTOR INDEX vector_idx(doc)
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=async, sync_interval=10s)
);
INSERT INTO items(id, doc) VALUES(1, 'Rose');
执行结果如图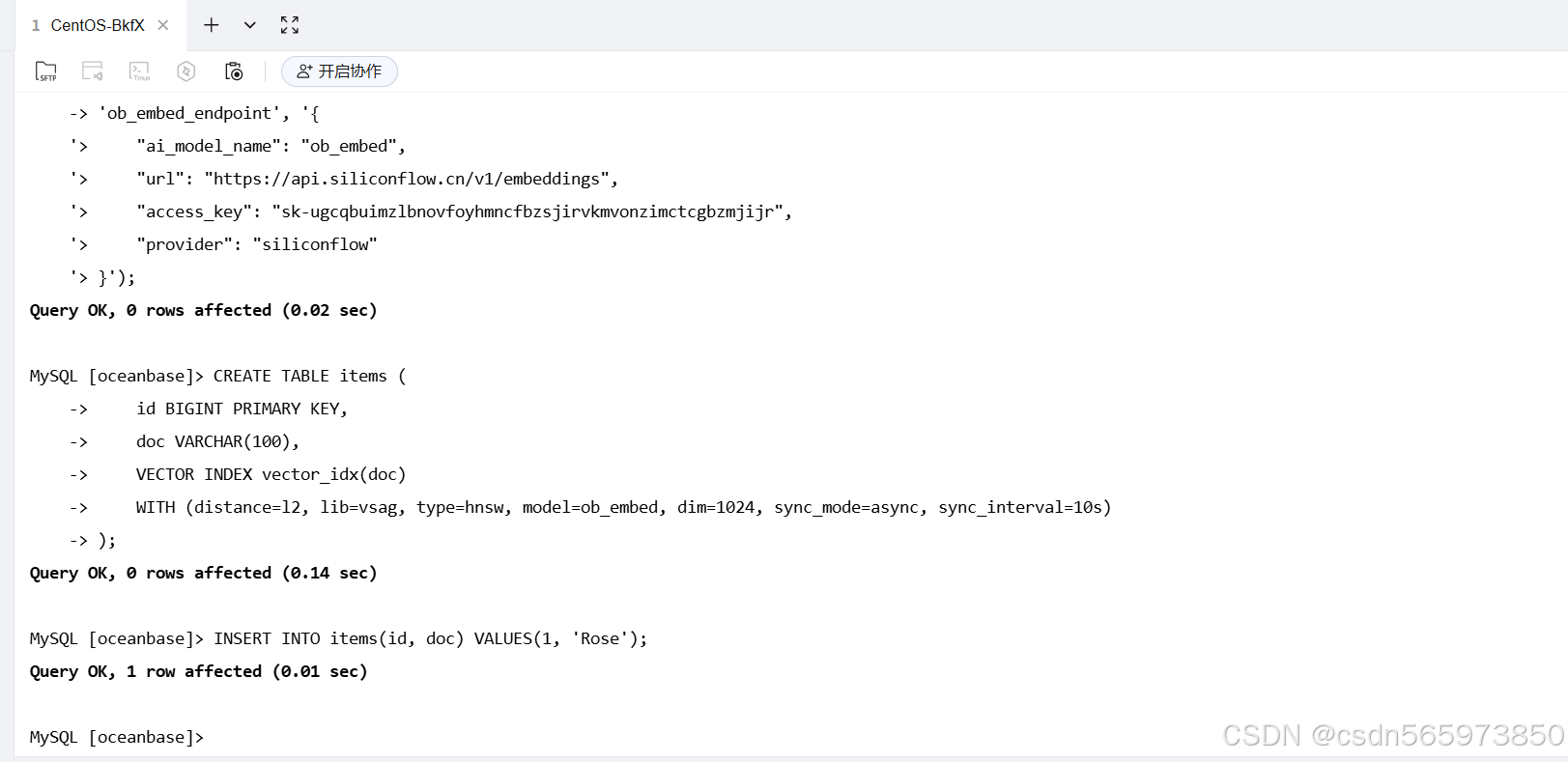
建表后创建
创建测试表 items 后,使用 CREATE VECTOR INDEX 语句创建 vector_idx 索引
CREATE TABLE items (
id BIGINT PRIMARY KEY,
doc VARCHAR(100)
);
CREATE VECTOR INDEX vector_idx
ON items (doc)
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=async, sync_interval=10s);
INSERT INTO items(id, doc) VALUES(1, 'Rose');
当然我们也可以更新数据或者删除数据,具体示例语句如下
UPDATE items SET doc = 'Lily' WHERE id = 1;
DELETE FROM items WHERE id = 1;
搜索数据
搜索数据支持两种搜索方式:使用原始文本搜索、使用向量搜索
使用原始文本搜索
使用 semantic_distance 表达式,传入原始文本进行向量搜索,语法格式:
SELECT ... FROM table_name
ORDER BY semantic_distance(column_name, 'query_text') [APPROXIMATE|APPROX]
LIMIT n;
其中:
column_name:语义索引创建时指定的文本列。
query_text:搜索的原始文本。
n:返回的结果行数。
搜索语句示例,完整建表及索引语句,插入数据语句,搜索语句如下
CREATE TABLE items (
id INT PRIMARY KEY,
doc varchar(100),
VECTOR INDEX vector_idx(doc)
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=immediate)
);
INSERT INTO items(id, doc) VALUES(1, 'Rose');
INSERT INTO items(id, doc) VALUES(2, 'Sunflower');
INSERT INTO items(id, doc) VALUES(3, 'Rose');
INSERT INTO items(id, doc) VALUES(4, 'Sunflower');
INSERT INTO items(id, doc) VALUES(5, 'Rose');
SELECT id, doc FROM items
ORDER BY semantic_distance(doc, 'Sunflower')
APPROXIMATE LIMIT 3;
理论上是应该可以搜到如下结果的,但是我实际搜索没有搜索到内容
使用向量搜索
使用 semantic_vector_distance 表达式,传入向量进行搜索,当搜索语句中带有 APPROXIMATE/APPROX 子句时,会使用向量索引进行搜索,语法格式如下
SELECT ... FROM table_name
ORDER BY semantic_vector_distance(column_name, 'query_vector') [APPROXIMATE|APPROX]
LIMIT n;
其中:
column_name:语义索引创建时指定的文本列。
query_vector:查询向量。
n:返回的结果行数。
使用向量搜索示例语句如下
--建表语句和插入数据的语句就按照上面 使用原始文本搜索的语句就可以了
SET @query_vector = AI_EMBED('ob_embed', 'Sunflower');
-- 使用向量进行索引搜索
SELECT id, doc FROM items
ORDER BY semantic_vector_distance(doc, @query_vector)
APPROXIMATE LIMIT 3;
-- 使用向量进行暴力搜索(精确结果)
SELECT id, doc FROM items
ORDER BY semantic_vector_distance(doc, @query_vector)
LIMIT 3;
执行索引搜索后的结果如图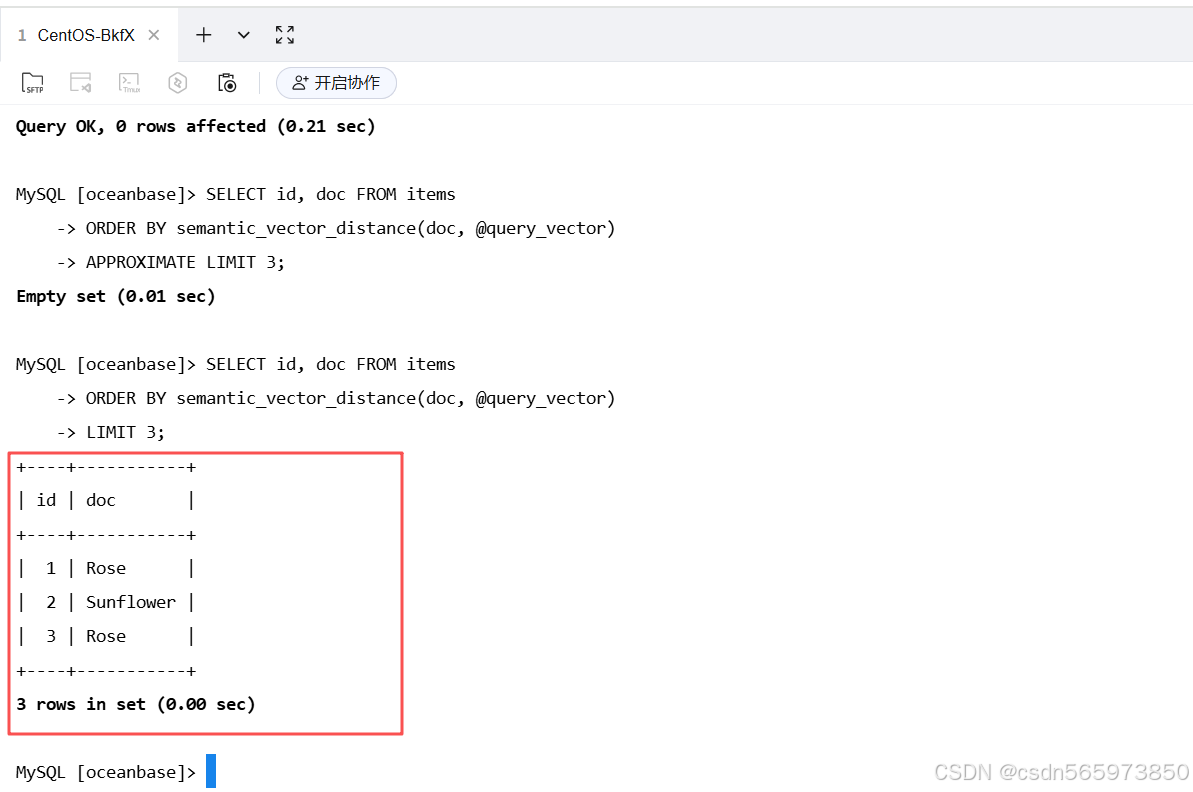
到这里,我们关于seekdb 如何创建索引以及使用索引实现文本搜索的操作就全部完成,整个操作上难度适中,对于经常接触 sql 的开发者来说还是很容易理解的。
实践体验
部署感受
经过从零开始部署OceanBase seekdb,并系统体验其混合搜索、AI函数服务、语义索引等核心功能,我对这款AI原生数据库有了深刻的认识。总体感受是:理念超前,潜力巨大,但作为早期产品仍需在工程化和开发者体验上持续打磨。
seekdb最吸引人的地方在于其“All-in-One”的设计哲学。它将向量、全文、结构化查询与AI能力深度融合,真正实现了在一个数据库内完成从数据存储、语义理解到智能生成的完整闭环。这极大地简化了AI应用的技术架构,减少了数据搬运和系统集成的复杂度。特别是AI函数与SQL的无缝集成,让开发者能够用熟悉的数据库操作方式调用大模型能力,学习曲线相对平缓。
然而,在实际操作中,我也切身体会细节上的不足。安装部署过程虽然最终成功,但是在实际操作中,文档中某些步骤与实际结果的微小偏差,文档内容也有点分散,有时候想要完全理解命令的含义,则需要查阅不少文档。不过,其核心功能的稳定性和性能表现给我留下了良好印象,混合搜索的响应速度和多模查询的灵活性都达到了可用甚至好用的水平。
部署流程建议
在部署上,当前是通过yum分步安装,对于新手仍有一定门槛。建议提供一键安装脚本(如install-seekdb.sh),自动检测系统环境、安装依赖(如MySQL客户端)、配置初始参数并启动服务。脚本可提供交互式选项(如设置端口、内存大小),并输出清晰的安装成功验证命令。
对于DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT这类参数复杂的操作,目前是通过查阅文档找到具体的厂商url 以及 provider ,这些参数是否可以开发一个在线的“端点配置生成器”。用户通过表单选择厂商、模型类型、填入密钥,自动生成对应的SQL调用语句,极大降低学习成本和出错概率。
开发体验与建议
结合上面体验来说,目前的seekdb,对数据库开发者友好,SQL接口直观,比较方便开发者快速上手。但是当AI函数返回意外结果或错误时,缺乏有效的排查工具。性能调优指南(如向量索引参数选择、AI函数批处理)不足。
具体的建议比如:为AI函数调用提供更详细的执行日志,可在特殊模式下记录发送给模型端点的实际请求体和返回的原始响应。或者提供一个DBMS_AI_SERVICE.TEST_ENDPOINT(‘endpoint_name’, ‘test_prompt’)存储过程,用于快速测试模型端点连通性和基本功能。丰富Python/Java/Go等SDK的文档和示例代码,特别是涵盖复杂混合搜索、事务性操作与AI函数结合的场景。在GitHub建立活跃的examples仓库,提供从入门到进阶的完整应用案例,如搜索引擎、推荐系统、知识问答、内容去重等。
总的来说
OceanBase seekdb是一款极具创新性和战略眼光的产品,它准确抓住了AI时代数据基础设施的核心痛点。当前的体验如同手握一块潜力巨大的“璞玉”——核心能力坚实,但需要更多精细的雕琢(易用性、稳定性、生态)。后续希望OceanBase团队能持续聚焦于开发者体验、生产就绪度和生态繁荣,seekdb有极大可能成为未来AI应用开发中不可或缺的基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)