公式推导|一文看懂DDIM加速扩散模型采样的神奇原理
前言
- DDIM原论文
- 本笔记参考自b站视频:一个视频看懂DDIM凭什么加速采样|扩散模型相关
作者自己学习了之后写下了自己跟着视频推导的过程和一些自己的解读,如有需要还是建议去看看这位up的原视频,讲的非常清晰到位。 - 如果觉得作者写的哪里有问题的,欢迎指出讨论
一、DDPM为什么要采样1000次(T=1000)
💡因为 DDPM 要采样 1000 次,而其他模型比如 GAN 都可以做到一步生成,所以相比而言 DDPM 采样非常慢。 我们可以让 DDPM 不要采样那么多次吗,直接把 T 改小能不能解决问题?
答案:不能直接改小。
我们来看DDPM中 x t x_t xt的采样公式,首先我们根据马尔可夫性质得到了 x t − 1 → x t x_{t-1} \to x_t xt−1→xt的公式:
x t = α t x t − 1 + 1 − α t ϵ (式 1 ) x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\epsilon(式1) xt=αtxt−1+1−αtϵ(式1)
经过推导,我们得到了 x 0 → x t x_0 \to x_t x0→xt的公式:
x t = α t ˉ x 0 + 1 − α t ˉ ϵ (式 2 ) x_t=\sqrt{\bar{\alpha_t}}x_0+\sqrt{1-\bar{\alpha_t}}\epsilon(式2) xt=αtˉx0+1−αtˉϵ(式2)
其中:
- α t ˉ = α 1 ∗ α 2 ∗ . . . ∗ α t \bar{\alpha_t}=\alpha_1*\alpha_2*...*\alpha_t αtˉ=α1∗α2∗...∗αt: α t ˉ \bar{\alpha_t} αtˉ是 α 1 \alpha_1 α1连乘到 α t \alpha_t αt的连乘积。
- ϵ ∼ N ( 0 , I ) \epsilon \sim N(0,I) ϵ∼N(0,I): ϵ \epsilon ϵ是服从标准高斯分布的随机噪声
- α t → 1 \alpha_t \to 1 αt→1 & α t < 1 \alpha_t<1 αt<1: α t \alpha_t αt是一个趋近于1但小于1的常数,比如0.99这样子
由于我们采样的时候是要从纯噪声 ϵ \epsilon ϵ开始,所以我们希望正向扩散的最后一步得到的 x T x_T xT可以趋近于是一个纯噪声。根据式2可知,如果要使得 x T → ϵ ∼ N ( 0 , I ) x_T \to \epsilon \sim N(0,I) xT→ϵ∼N(0,I),就必须让 α T ˉ → 0 \bar{\alpha_T} \to 0 αTˉ→0。
因为 α T ˉ = α 1 ∗ α 2 ∗ . . . ∗ α T \bar{\alpha_T}=\alpha_1*\alpha_2*...*\alpha_T αTˉ=α1∗α2∗...∗αT,而每一个 α t \alpha_t αt都是趋近于1的数,要让它们连乘后趋近于0,必须得乘的足够多,即 T T T要足够大。⇒DDPM必须采样很多次(比如1000次),不能随便减小T。
二、DDPM的采样可以跳步吗?
💡所谓跳步,就是原本采样是 x T → x T − 1 → . . . → x t → x t − 1 → . . . → x 0 x_T \to x_{T-1} \to ... \to x_t \to x_{t-1} \to ... \to x_0 xT→xT−1→...→xt→xt−1→...→x0。现在我想改成 x T → x T − s → . . . → x 0 x_T \to x_{T-s} \to ... \to x_0 xT→xT−s→...→x0,就是不一步一步的采样了,这样就可以让采样快很多,这在DDPM中是可以的吗?
先说答案:不能
首先,我们要先明确什么是马尔可夫性质(Markov Poverty),这是DDPM推导的理论基础。所谓马尔可夫性质,指的就是:
当前状态只依赖于“现在”,而与“过去的过去”无关。
在DDPM中,马尔可夫性质的体现就是: x t x_t xt只依赖于 x t − 1 x_{t-1} xt−1,与前面的任意 x t − s x_{t-s} xt−s和 x 0 x_0 x0无关。
DDPM的采样目标是拟合反向条件分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0),DDPM中的做法是使用贝叶斯公式:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) (式 3 ) q(x_{t-1}|x_t,x_0)=\frac{q(x_t|x_{t-1},x_0)q(x_{t-1}|x_0)}{q(x_t|x_0)}(式3) q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)(式3)
其中:
- q ( x t − 1 ∣ x 0 ) q(x_{t-1}|x_0) q(xt−1∣x0)和 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)这两项可以由式2得到,而式2又是由马尔可夫性质推导得到。所以可以说贝叶斯公式中的 q ( x t − 1 ∣ x 0 ) q(x_{t-1}|x_0) q(xt−1∣x0)和 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)两项都是由马尔可夫性质得到的。
- 根据马尔可夫性质, x t x_t xt只与 x t − 1 x_{t-1} xt−1有关,所以有 q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) q(x_t|x_{t-1},x_0)=q(x_t|x_{t-1}) q(xt∣xt−1,x0)=q(xt∣xt−1),即可以直接去掉 x 0 x_0 x0。而 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)由式1可知。
综上所述,我们就可以回答DDPM为什么不能跳步的问题了:
因为DDPM反向采样中的每一步的分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)都是在假设马尔可夫性质成立的前提下定义的。如果跳过中间步骤,就违反了马尔可夫链结构。
三、DDIM如何去马尔可夫化——实现跳步
💡 DDIM的启发性思路:由于 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)服从马尔可夫性质,导致无法跳步。如果我们可以定义出一个新的 q q q,使其不依赖马尔可夫性质的成立,那是不是就可以跳步了呢?
由上面的思路出发,我们目标就是:定义一个 q ( x s ∣ x k , x 0 ) ∼ n o n − m a r k o v q(x_s|x_k,x_0) \sim non-markov q(xs∣xk,x0)∼non−markov ,其中 0 < s < k − 1 0<s<k-1 0<s<k−1。
我们同样可以将其展开成贝叶斯,得:
q ( x s ∣ x k , x 0 ) = q ( x k ∣ x s , x 0 ) q ( x s ∣ x 0 ) q ( x k ∣ x 0 ) (式 4 ) q(x_s|x_k,x_0)=\frac{q(x_k|x_s,x_0)q(x_s|x_0)}{q(x_k|x_0)}(式4) q(xs∣xk,x0)=q(xk∣x0)q(xk∣xs,x0)q(xs∣x0)(式4)
DDIM的改进有一个前提,就是只加速DDPM的采样,而不改变DDPM的训练。由于训练中采用了 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)的公式也就是式2,所以式4中的 q ( x s ∣ x 0 ) q(x_s|x_0) q(xs∣x0)和 q ( x k ∣ x 0 ) q(x_k|x_0) q(xk∣x0)两项我们依旧可以通过式2得到,而且必须可以通过式2得到,不然我们就不能继续使用DDPM的训练结果了。
所以在贝叶斯公式中,已经有以下两个已知项:
- q ( x s ∣ x 0 ) = α s ˉ x 0 + 1 − α s ˉ ϵ (式 5 ) q(x_s|x_0)=\sqrt{\bar{\alpha_s}}x_0+\sqrt{1-\bar{\alpha_s}}\epsilon(式5) q(xs∣x0)=αsˉx0+1−αsˉϵ(式5)
- q ( x k ∣ x 0 ) = α k ˉ x 0 + 1 − α k ˉ ϵ (式 6 ) q(x_k|x_0)=\sqrt{\bar{\alpha_k}}x_0+\sqrt{1-\bar{\alpha_k}}\epsilon(式6) q(xk∣x0)=αkˉx0+1−αkˉϵ(式6)
另外两项暂时未知,首先我们先不管 q ( x k ∣ x s , x 0 ) q(x_k|x_s,x_0) q(xk∣xs,x0),先来看 q ( x s ∣ x k , x 0 ) q(x_s|x_k,x_0) q(xs∣xk,x0)。我们尝试用待定系数法求出 q ( x s ∣ x k , x 0 ) q(x_s|x_k,x_0) q(xs∣xk,x0)的解析式。
在DDPM中,有:
q ( x t − 1 ∣ x t , x 0 ) ∼ N ( α t ( 1 − α t − 1 ˉ ) 1 − α t ˉ x t + α t − 1 ˉ β t 1 − α t ˉ x 0 , 1 − α t − 1 ˉ 1 − α t ˉ β t I ) (式 7 ) q(x_{t-1}|x_t,x_0) \sim N(\frac{\sqrt{\alpha_t}(1-\bar{\alpha_{t-1}})}{1-\bar{\alpha_t}}x_t+\frac{\sqrt{\bar{\alpha_{t-1}}}\beta_t}{1-\bar{\alpha_t}}x_0,~ \frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_tI)(式7) q(xt−1∣xt,x0)∼N(1−αtˉαt(1−αt−1ˉ)xt+1−αtˉαt−1ˉβtx0, 1−αtˉ1−αt−1ˉβtI)(式7)
⇒我们不妨设 q ( x s ∣ x k , x 0 ) ∼ N ( μ , σ 2 I ) q(x_s|x_k,x_0) \sim N(\mu, \sigma^2I) q(xs∣xk,x0)∼N(μ,σ2I)
由于式7中, q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)的均值是 x t x_t xt和 x 0 x_0 x0的线性组合(加权和)的形式,所以我们不妨也把 μ \mu μ设成这样的形式,即:
q ( x s ∣ x k , x 0 ) ∼ N ( n x 0 + m x k , σ 2 I ) ( n , m 为常数) q(x_s|x_k,x_0) \sim N(nx_0+mx_k, \sigma^2I)(n,m为常数) q(xs∣xk,x0)∼N(nx0+mxk,σ2I)(n,m为常数)
那么我们就可以用 x 0 x_0 x0和 x k x_k xk去表示 x s x_s xs,根据高斯分布的标准化与反标准化可以得到:
x s = ( n x 0 + m x k ) + σ ϵ ( ϵ ∼ N ( 0 , I ) )(式 8 ) x_s=(nx_0+mx_k)+\sigma\epsilon (\epsilon\sim N(0,I))(式8) xs=(nx0+mxk)+σϵ(ϵ∼N(0,I))(式8)
将式6代入上式,可以把 x k x_k xk用 x 0 x_0 x0的表达式代换掉:
x s = n x 0 + m ( α k ˉ x 0 + 1 − α k ˉ ϵ ′ ) + σ ϵ = ( n + m α k ˉ ) x 0 + ( m 1 − α k ˉ ϵ ′ + σ ϵ ) ( ϵ ′ , ϵ ∼ N ( 0 , I ) )(式 9 ) x_s=nx_0+m(\sqrt{\bar{\alpha_k}}x_0+\sqrt{1-\bar{\alpha_k}}\epsilon')+\sigma\epsilon =(n+m\sqrt{\bar{\alpha_k}})x_0+(m\sqrt{1-\bar{\alpha_k}}\epsilon'+\sigma\epsilon) (\epsilon',\epsilon \sim N(0,I))(式9) xs=nx0+m(αkˉx0+1−αkˉϵ′)+σϵ=(n+mαkˉ)x0+(m1−αkˉϵ′+σϵ)(ϵ′,ϵ∼N(0,I))(式9)
由于 ϵ ′ \epsilon' ϵ′和 ϵ \epsilon ϵ都服从标准高斯分布,所以由高斯分布的可加性可以得到 ( m 1 − α k ˉ ϵ ′ + σ ϵ ) ∼ N ( 0 , m 2 ( 1 − α k ˉ ) + σ 2 ) (m\sqrt{1-\bar{\alpha_k}}\epsilon'+\sigma\epsilon) \sim N(0,m^2(1-\bar{\alpha_k})+\sigma^2) (m1−αkˉϵ′+σϵ)∼N(0,m2(1−αkˉ)+σ2),用这个结论继续化简式9,得
x s = ( n + m α k ˉ ) x 0 + m ( 1 − α k ˉ ) + σ 2 ϵ (式 10 ) x_s=(n+m\sqrt{\bar{\alpha_k}})x_0+\sqrt{m(1-\sqrt{\bar{\alpha_k}})+\sigma^2}\epsilon(式10) xs=(n+mαkˉ)x0+m(1−αkˉ)+σ2ϵ(式10)
这时我们发现式10和式5有着相同的形式,而且都代表着 x s x_s xs在 x 0 x_0 x0条件下的分布 q ( x s ∣ x 0 ) q(x_s|x_0) q(xs∣x0),所以我们可以将这两个式子的系数一一对应起来,即令:
- n + m α k ˉ = α s ˉ n+m\sqrt{\bar{\alpha_k}}=\sqrt{\bar{\alpha_s}} n+mαkˉ=αsˉ
- m ( 1 − α k ˉ ) + σ 2 = 1 − α s ˉ \sqrt{m(1-\sqrt{\bar{\alpha_k}})+\sigma^2}=\sqrt{1-\bar{\alpha_s}} m(1−αkˉ)+σ2=1−αsˉ
这里是两个方程,但是其实有 n , m , σ n,m,\sigma n,m,σ三个未知量,不过没关系,我们先把 n n n和 m m m表示出来:
m = 1 − α s ˉ − σ 2 1 − α k ˉ (式 11 ) m=\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}(式11) m=1−αkˉ1−αsˉ−σ2(式11)
n = α s ˉ − 1 − α s ˉ − σ 2 1 − α k ˉ α k ˉ (式 12 ) n=\sqrt{\bar{\alpha_s}}-\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}\sqrt{\bar{\alpha_k}}(式12) n=αsˉ−1−αkˉ1−αsˉ−σ2αkˉ(式12)
将式11和式12代入我们定义的均值 μ = n x 0 + m x k \mu=nx_0+mx_k μ=nx0+mxk,经过化简可得:
q ( x s ∣ x k , x 0 ) ∼ N ( α s ˉ x 0 + 1 − α s ˉ − σ 2 1 − α k ˉ ( x k − α k ˉ x 0 ) , σ 2 I ) (式 13 ) q(x_s|x_k,x_0) \sim N(\sqrt{\bar{\alpha_s}}x_0+\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}(x_k-\sqrt{\bar{\alpha_k}}x_0),\sigma^2I)(式13) q(xs∣xk,x0)∼N(αsˉx0+1−αkˉ1−αsˉ−σ2(xk−αkˉx0),σ2I)(式13)
式13是一个不遵循马尔可夫性质的采样条件分布,通过式13可以求得采样方程:
x s = α s ˉ x 0 + 1 − α s ˉ − σ 2 1 − α k ˉ ( x k − α k ˉ x 0 ) + σ ϵ (式 14 ) x_s=\sqrt{\bar{\alpha_s}}x_0+\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}(x_k-\sqrt{\bar{\alpha_k}}x_0)+\sigma\epsilon (式14) xs=αsˉx0+1−αkˉ1−αsˉ−σ2(xk−αkˉx0)+σϵ(式14)
有了式14,意味着我们可以通过 x 0 x_0 x0和 x k x_k xk直接求得 x s x_s xs,意味着我们摆脱了马尔可夫性质的限制,可以不需要连续采样了,即实现了跳步。
当然,在实际的采样过程中,我们是不知道 x 0 x_0 x0的,我们需要用模型预测的噪声 ϵ θ ( x t , t ) \epsilon_{\theta}(x_t,t) ϵθ(xt,t)的表达式来替换掉公式里的 x 0 x_0 x0。由式2我们可以反推出:
x 0 ˆ ( t ) = x t − 1 − α t ˉ ϵ θ ( x t , t ) α t ˉ \^{x_0}(t)=\frac{x_t-\sqrt{1-\bar{\alpha_t}}\epsilon_{\theta}(x_t,t)}{\sqrt{\bar{\alpha_t}}} x0ˆ(t)=αtˉxt−1−αtˉϵθ(xt,t)
将这个式子代入式14可以得到实际在DDIM采样的时候使用的公式:
x s = α s ˉ x 0 ˆ ( k ) + 1 − α s ˉ − σ 2 1 − α k ˉ ( x k − α k ˉ x 0 ˆ ( k ) ) + σ ϵ (式 15 ) x_s=\sqrt{\bar{\alpha_s}}\^{x_0}(k)+\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}(x_k-\sqrt{\bar{\alpha_k}}\^{x_0}(k))+\sigma\epsilon (式15) xs=αsˉx0ˆ(k)+1−αkˉ1−αsˉ−σ2(xk−αkˉx0ˆ(k))+σϵ(式15)
Question 1:为什么就不管 q ( x k ∣ x s , x 0 ) q(x_k|x_s,x_0) q(xk∣xs,x0)了?
在上面的贝叶斯表达式式4中,我们已知 q ( x s ∣ x 0 ) q(x_s|x_0) q(xs∣x0)和 q ( x k ∣ x 0 ) q(x_k|x_0) q(xk∣x0)是高斯分布,然后我们又假设了 q ( x s ∣ x k , x 0 ) q(x_s|x_k,x_0) q(xs∣xk,x0)也是高斯分布,那么根据高斯分布的性质⇒ q ( x k ∣ x s , x 0 ) q(x_k|x_s,x_0) q(xk∣xs,x0)也是一个高斯分布。
不过论文中作者并没有给出 q ( x k ∣ x s , x 0 ) q(x_k|x_s,x_0) q(xk∣xs,x0)的计算方式,因为完全没有用到,所以我们就不管它了。
Question 2:Diffusion的正向过程变了吗?
q ( x k ∣ x s , x 0 ) q(x_k|x_s,x_0) q(xk∣xs,x0)代表着模型在正向过程的条件分布。当我们使用DDIM的采样方法的时候,实际上模型正向扩散中的每一步的加噪过程其实是变了的,就是说 x t − 1 → x t x_{t-1} \to x_t xt−1→xt这中间的变化其实是跟DDPM不一样了的。但是我们为什么还是可以使用DDPM训练好的模型呢?
因为DDPM模型在训练的时候其实没有用到 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)这个每一步的变化,而是一步到位的学习了 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)。所以即使 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)变了,只要 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0)没有变,我们的模型就依然可以用DDIM的方法进行采样加速。
四、标准差的选取
标准差的两种取值
在我们推导出的DDIM采样公式中,现在只剩下了 σ \sigma σ这一个未知数,接下来我们就讨论一下 σ \sigma σ应该取什么值。
x s = α s ˉ x 0 ˆ ( k ) + 1 − α s ˉ − σ 2 1 − α k ˉ ( x k − α k ˉ x 0 ˆ ( k ) ) + σ ϵ (式 15 ) x_s=\sqrt{\bar{\alpha_s}}\^{x_0}(k)+\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}(x_k-\sqrt{\bar{\alpha_k}}\^{x_0}(k))+\sigma\epsilon (式15) xs=αsˉx0ˆ(k)+1−αkˉ1−αsˉ−σ2(xk−αkˉx0ˆ(k))+σϵ(式15)
有两种 σ \sigma σ的取值方式,如下:
- 令 σ = 0 \sigma=0 σ=0
在式14中,只有 ϵ \epsilon ϵ是一个随机采样的变量,他也代表了整个采样的随机性。如果 σ = 0 \sigma=0 σ=0,意味着最后一项 σ ϵ \sigma\epsilon σϵ就没了,那么整个采样公式就失去了随机性,变成了一个确定的过程。
这也就是论文中所说的:一旦给定初始噪声 x T x_T xT,生成的样本 x 0 x_0 x0 是唯一确定的。
论文中提到,令 σ = 0 \sigma=0 σ=0有以下优缺点:
- 失去了 ϵ \epsilon ϵ带来的每一步生成的随机性后,模型生成的图片会损失一部分多样性
- 但是 σ = 0 \sigma=0 σ=0的时候反而模型的效果是最好的,经过论文作者的验证
- 沿用DDPM中的标准差取值,即令
σ = 1 − α t − 1 ˉ 1 − α t ˉ β t \sigma=\sqrt{\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t} σ=1−αtˉ1−αt−1ˉβt
由于DDPM的方差中用的是 t t t和 t − 1 t-1 t−1,代表着两个相邻的时间步。所以如果使用这个方差那意味着我们的 s s s和 k k k也要满足 s = k − 1 s=k-1 s=k−1的关系了。所以式15就变成了:
x t − 1 = α t − 1 ˉ x 0 ˆ ( t ) + 1 − α t − 1 ˉ − σ 2 1 − α t ˉ ( x t − α t ˉ x 0 ˆ ( t ) ) + σ ϵ (式 16 ) x_{t-1}=\sqrt{\bar{\alpha_{t-1}}}\^{x_0}(t)+\frac{\sqrt{1-\bar{\alpha_{t-1}}-\sigma^2}}{\sqrt{1-\bar{\alpha_t}}}(x_t-\sqrt{\bar{\alpha_t}}\^{x_0}(t))+\sigma\epsilon (式16) xt−1=αt−1ˉx0ˆ(t)+1−αtˉ1−αt−1ˉ−σ2(xt−αtˉx0ˆ(t))+σϵ(式16)
论文中提到:
如果令 σ = 1 − α t − 1 ˉ 1 − α t ˉ β t \sigma=\sqrt{\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t} σ=1−αtˉ1−αt−1ˉβt,那么DDIM的采样又会变回一个依赖于马尔可夫性质的DDPM了。
但是即使我们现在公式中的两个时间步已经是相邻的了,但是他的写法也跟DDPM不一样呀,为什么会又变回DDPM了呢?我们该如何证明论文中所说的这个结论?
论文中所说的这个结论在数学上表达就是,当 σ = 1 − α t − 1 ˉ 1 − α t ˉ β t \sigma=\sqrt{\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t} σ=1−αtˉ1−αt−1ˉβt,时,DDIM的 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)和DDPM的 p ( x t − 1 ∣ x t , x 0 ) p(x_{t-1}|x_t,x_0) p(xt−1∣xt,x0)变成了同一个分布,有着一样的均值和方差。DDPM和DDIM的采样条件分布如下:
D D P M : p ( x t − 1 ∣ x t , x 0 ) ∼ N ( 1 α t ( x t − 1 − α t 1 − α t ˉ ϵ θ ) , 1 − α t − 1 ˉ 1 − α t ˉ β t I ) DDPM:p(x_{t-1}|x_t,x_0) \sim N(\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}}\epsilon_{\theta}), \frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_tI) DDPM:p(xt−1∣xt,x0)∼N(αt1(xt−1−αtˉ1−αtϵθ),1−αtˉ1−αt−1ˉβtI)
D D I M : q ( x t − 1 ∣ x t , x 0 ) ∼ N ( α t − 1 ˉ x 0 ˆ ( t ) + 1 − α t − 1 ˉ − 1 − α t − 1 ˉ 1 − α t ˉ β t 1 − α t ˉ ( x t − α t ˉ x 0 ˆ ( t ) ) , 1 − α t − 1 ˉ 1 − α t ˉ β t I ) DDIM:q(x_{t-1}|x_t,x_0) \sim N(\sqrt{\bar{\alpha_{t-1}}}\^{x_0}(t)+\frac{\sqrt{1-\bar{\alpha_{t-1}}-\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t}}{\sqrt{1-\bar{\alpha_t}}}(x_t-\sqrt{\bar{\alpha_t}}\^{x_0}(t)), \frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_tI) DDIM:q(xt−1∣xt,x0)∼N(αt−1ˉx0ˆ(t)+1−αtˉ1−αt−1ˉ−1−αtˉ1−αt−1ˉβt(xt−αtˉx0ˆ(t)),1−αtˉ1−αt−1ˉβtI)
由于方差已经一样,所以我们只需要证明他们的均值一样,就可以说明他们是同一个分布,即证明: q m e a n = p m e a n q_{mean}=p_{mean} qmean=pmean
q m e a n = α t − 1 ˉ x 0 ˆ ( t ) + 1 − α t − 1 ˉ − 1 − α t − 1 ˉ 1 − α t ˉ β t 1 − α t ˉ ( x t − α t ˉ x 0 ˆ ( t ) ) q_{mean}=\sqrt{\bar{\alpha_{t-1}}}\^{x_0}(t)+\frac{\sqrt{1-\bar{\alpha_{t-1}}-\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t}}{\sqrt{1-\bar{\alpha_t}}}(x_t-\sqrt{\bar{\alpha_t}}\^{x_0}(t)) qmean=αt−1ˉx0ˆ(t)+1−αtˉ1−αt−1ˉ−1−αtˉ1−αt−1ˉβt(xt−αtˉx0ˆ(t))
p m e a n = 1 α t ( x t − 1 − α t 1 − α t ˉ ϵ θ ) p_{mean}=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}}\epsilon_{\theta}) pmean=αt1(xt−1−αtˉ1−αtϵθ)
(经过一系列严谨的数学推导,我们确实可以证明出 q m e a n = p m e a n q_{mean}=p_{mean} qmean=pmean,证明过程暂时省略。)
验证两种取值的效果
在论文中,作者通过实验对比了两种标准差取值的实验效果。其中为了方便对比,作者引入了一个变量 η \eta η来控制 σ \sigma σ的取值,作者令 σ = η ∗ 1 − α t − 1 ˉ 1 − α t ˉ β t \sigma=\eta * \sqrt{\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t} σ=η∗1−αtˉ1−αt−1ˉβt,则:
- 当 η = 0 \eta=0 η=0时, σ = 0 \sigma=0 σ=0
- 当 η = 1 \eta=1 η=1时, σ = 1 − α t − 1 ˉ 1 − α t ˉ β t \sigma=\sqrt{\frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t} σ=1−αtˉ1−αt−1ˉβt,即DDPM的标准差
刚好对应了上面的两种 σ \sigma σ的取值。作者的对比实验结果如下图:
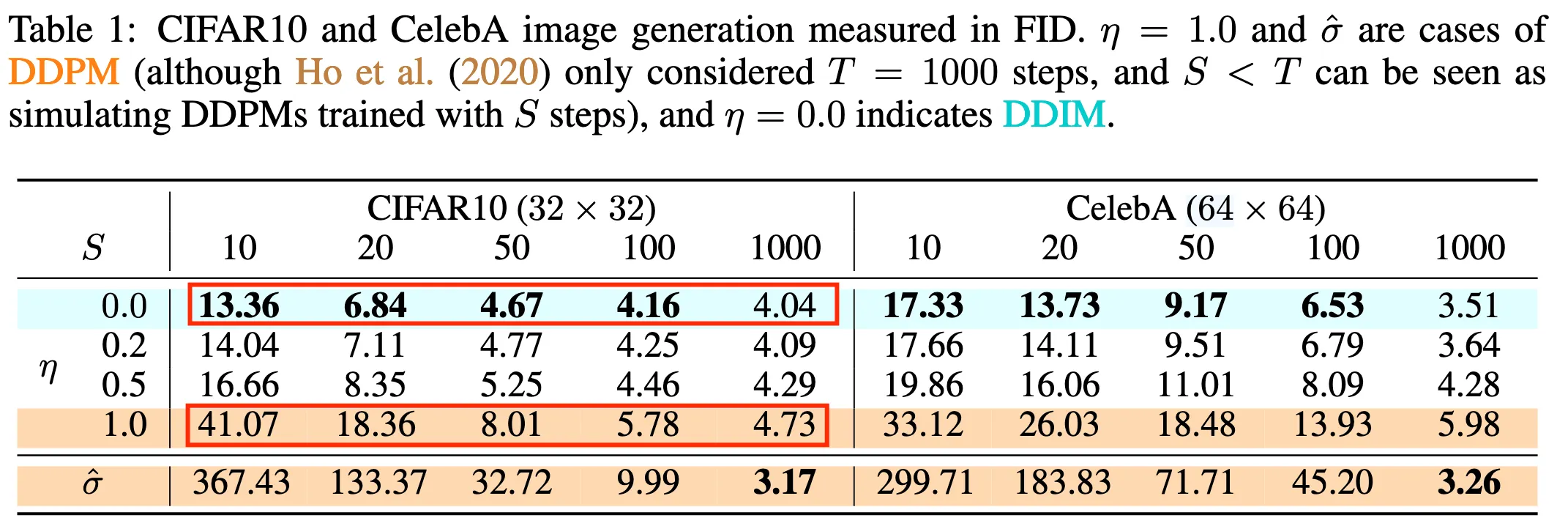
其中:
- 当 η = 1 \eta=1 η=1, S = 1000 S=1000 S=1000的时候,就是完整的DDPM
- 当 η = 1 \eta=1 η=1, S < 1000 S<1000 S<1000的时候,模型是跳步的DDPM
- 当 η = 0 \eta=0 η=0的时候,模型是DDIM
通过不同 η \eta η取值的结果对比可以看出, η \eta η越小,结果是越好的,而且当 η = 0 \eta=0 η=0的时候结果是最好的。另外,如果看 η = 1 \eta=1 η=1的那一行会发现,当 η = 1 \eta=1 η=1且 S < 1000 S<1000 S<1000也就是使用DDPM标准差且跳步的情况下,模型的效果是会变差很多的。
- 相反DDIM的跳步跳的多了之后,虽然效果会变差,但没有变差那么多——采样50步和1000步的效果并没有太大差距。
- 还有一点是,DDIM采样50步的效果居然比采样1000步的完整DDPM效果更好!
这就意味着,DDIM真的可以很有效的提升图像生成的速度,而且生成的效果不降反增。
五、总结
DDPM的拟合目标 q ( x t − 1 ∣ x t , x 0 ) ∼ M a r k o v q(x_{t-1}|x_t,x_0) \sim Markov q(xt−1∣xt,x0)∼Markov,所以必须step by step采样。→所以我们试图找出一个 q ( x s ∣ x k , x 0 ) ∼ n o n − M a r k o v q(x_s|x_k,x_0) \sim non-Markov q(xs∣xk,x0)∼non−Markov,来实现跳步。
然后我们利用贝叶斯展开 q ( x s ∣ x k , x 0 ) q(x_s|x_k,x_0) q(xs∣xk,x0),得到:
q ( x s ∣ x k , x 0 ) = q ( x k ∣ x s , x 0 ) q ( x s ∣ x 0 ) q ( x k ∣ x 0 ) (式 4 ) q(x_s|x_k,x_0)=\frac{q(x_k|x_s,x_0)q(x_s|x_0)}{q(x_k|x_0)}(式4) q(xs∣xk,x0)=q(xk∣x0)q(xk∣xs,x0)q(xs∣x0)(式4)
其中 q ( x s ∣ x 0 ) q(x_s|x_0) q(xs∣x0)和 q ( x k ∣ x 0 ) q(x_k|x_0) q(xk∣x0)要继续沿用DDPM中的公式,因为他们参与了模型训练。
然后我们假设:
q ( x s ∣ x k , x 0 ) ∼ N ( n x 0 + m x k , σ 2 I ) ( n , m 为常数) q(x_s|x_k,x_0) \sim N(nx_0+mx_k, \sigma^2I)(n,m为常数) q(xs∣xk,x0)∼N(nx0+mxk,σ2I)(n,m为常数)
通过待定系数法,经过一通复杂的计算,我们求得了 n n n和 m m m两个参数的表达式,于是得到了采样公式:
x s = α s ˉ x 0 ˆ ( k ) + 1 − α s ˉ − σ 2 1 − α k ˉ ( x k − α k ˉ x 0 ˆ ( k ) ) + σ ϵ (式 15 ) x_s=\sqrt{\bar{\alpha_s}}\^{x_0}(k)+\frac{\sqrt{1-\bar{\alpha_s}-\sigma^2}}{\sqrt{1-\bar{\alpha_k}}}(x_k-\sqrt{\bar{\alpha_k}}\^{x_0}(k))+\sigma\epsilon (式15) xs=αsˉx0ˆ(k)+1−αkˉ1−αsˉ−σ2(xk−αkˉx0ˆ(k))+σϵ(式15)
接下来我们又分析了 σ \sigma σ的取值,其中当 σ = 0 \sigma=0 σ=0时,扩散过程变成了一个确定性的过程:给定一个 x T ∼ N ( 0 , I ) x_T \sim N(0,I) xT∼N(0,I),就可以唯一确定一个生成图像 x 0 x_0 x0。
在这种情况下,DDIM的速度大幅上升了,质量也上升了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)