基于GA遗传优化的LSTM长短记忆网络模型的文本分类算法matlab仿真
目录
1.前言
GA-LSTM(长短时记忆网络)是LSTM网络的改进版,通过GA优化LSTM网络的参数,实现更有的训练效果。LSTM的核心是通过门控机制(输入门、遗忘门、输出门)控制信息的保留与丢弃,能捕捉文本的长距离依赖关系,适合处理文本序列的分类任务。
2.算法测试效果图预览
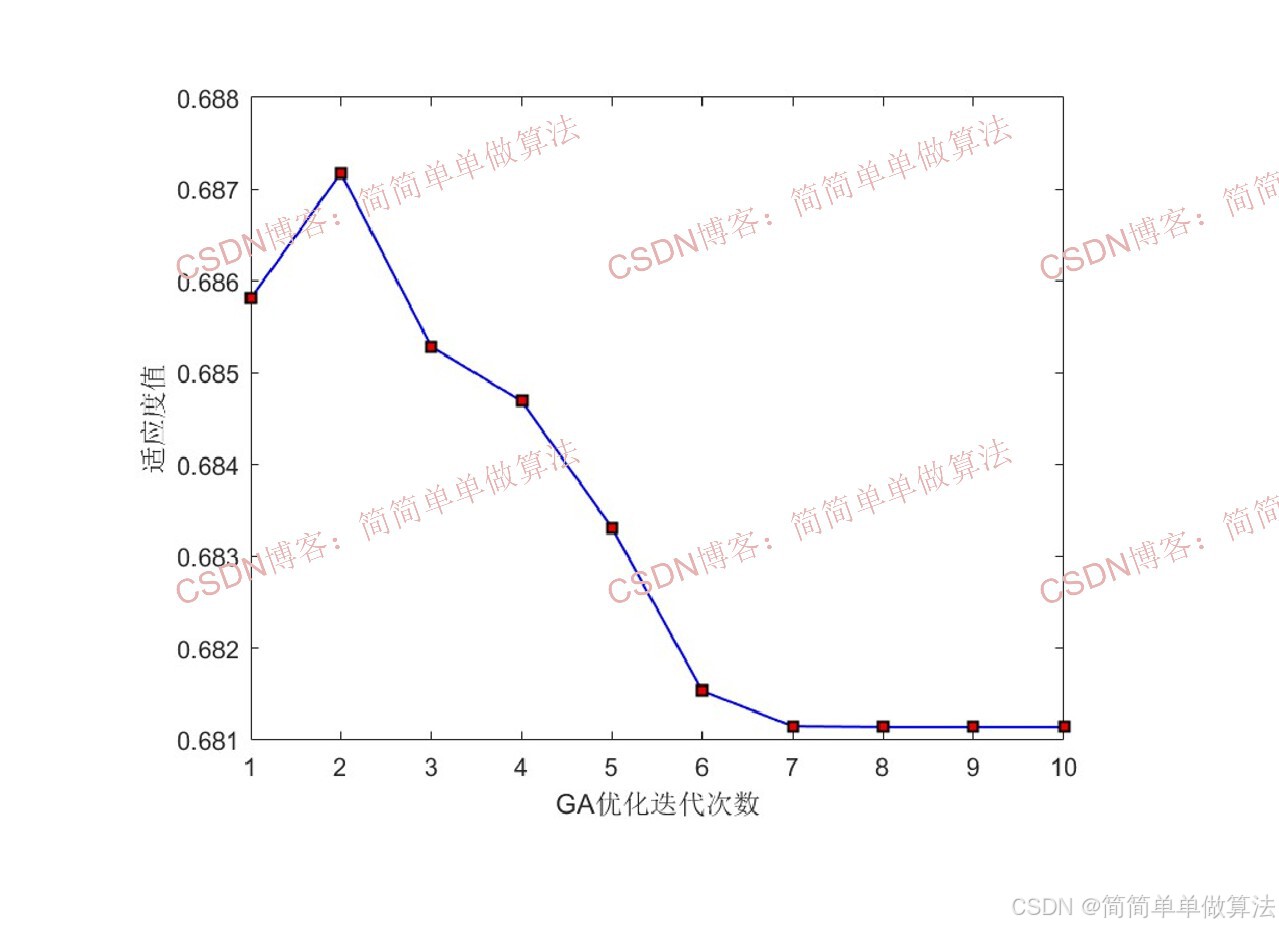
GA优化收敛曲线:
训练曲线:
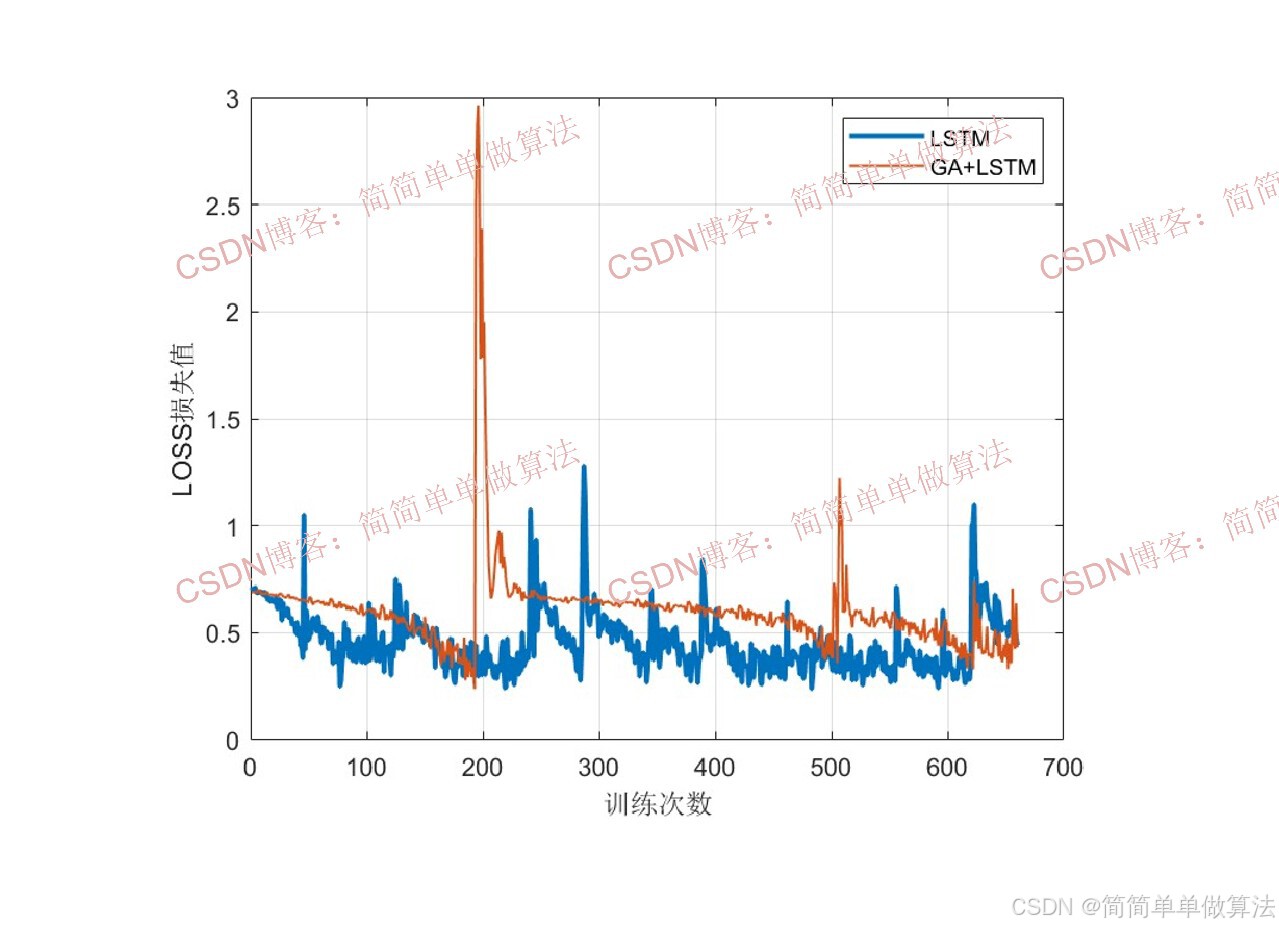
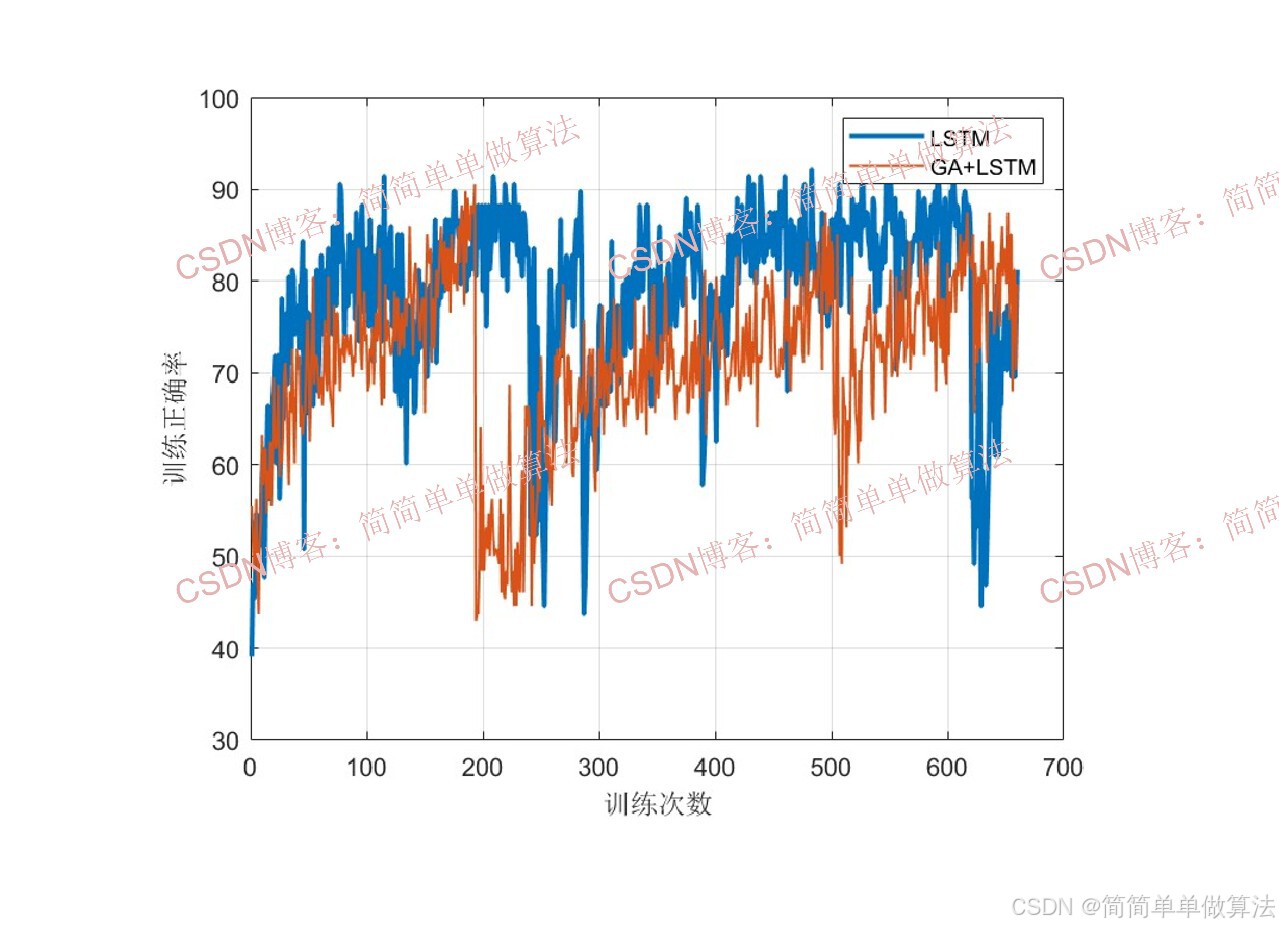
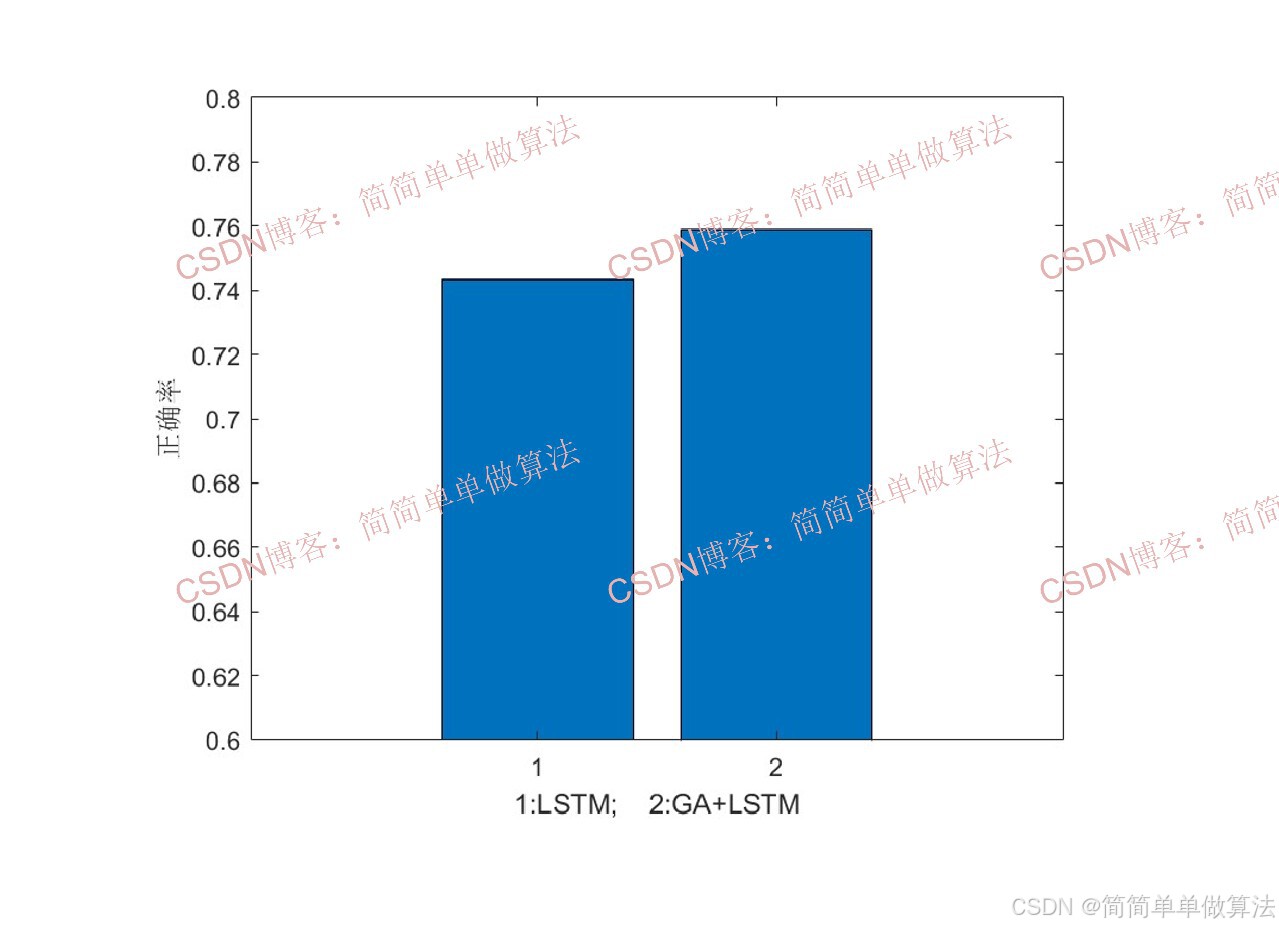
woa优化前后LSTM的文本分类性能对比:
3.算法运行软件版本
matlab2024b
4.部分核心程序
........................................................
X = g1;
% 构建并训练LSTM分类网络
Osize = 2^(floor(X(1))+1);
RR = X(2);
Nclass = numel(categories(Ytrain));
% 定义网络层结构
layers = []
% 设置训练选项
options = trainingOptions('sgdm','MaxEpochs',15,'InitialLearnRate',RR,'Plots','none', 'Verbose',1);
% 训练网络:输入序列XTrain、标签Ytrain、层结构layers、训练选项options
rng('default')
[net,INFO1] = trainNetwork(XTrain,Ytrain,layers,options);
% 测试集
Xstest = erasePunctuation(Xstest);
Xstest = lower(Xstest);
% 将测试集文本分词为文档对象
Doc_test2 = tokenizedDocument(Xstest);
%将测试集文档转换为序列
Doc_Trunctest2 = docfun(@(words) words(1:min(Len_seqs,end)),Doc_test2);
XTest = func_doc2seq(Wnet,Doc_Trunctest2);
for i=1:numel(XTest)
XTest{i} = func_leftPad(XTest{i},Len_seqs);
end
% 模型推理
YPred = classify(net,XTest);
% 计算准确率
accuracy = sum(YPred == Ytest)/numel(YPred);
save R1.mat accuracy INFO1 gb1
2495.算法理论概述
基于LSTM网络的文本分类方法,通过门控机制解决了传统RNN的长文本处理 难题,能有效捕捉序列依赖关系。算法流程包括:文本预处理 、词嵌入转换、LSTM特征提取、特征聚合和分类输出。具体实现中,采用左侧填充统一序列长度,构建包含嵌入层、LSTM层和全连接层的网络结构,使用sgdm优化器进行训练。测试阶段对文本进行分词、截断和填充处理后输入训练好的模型。理论部分详细阐述了词嵌入、LSTM门控计算、特征聚合和分类层设计,其中特征聚合可采用最后时刻状态或池化方法。文本分类流程为:预处理→词嵌入→LSTM提取序列特征→特征聚合→分类层输出概率。
5.1 词嵌入
将离散索引转换为连续低维向量,捕捉语义特征:

5.2 LSTM层计算
LSTM的细胞状态Ct和隐藏状态ht由3个门控和候选状态共同决定:

5.3 特征聚合
取LSTM最后一个时刻的隐藏状态hT (T为文本序列长度)作为整段文本的特征向量,也可采用平均池化/最大池化:
![]()
5.4 分类层计算
将聚合后的特征向量输入全连接层,结合激活函数输出分类概率:

5.5 GA优化
通过GA搜索LSTM的最优超参数组合Θ=[lr,Nh],lr学习率、Nh隐藏层神经元 数。将LSTM的训练误差定义为GA的适应度函数,将优化得到的lr和Nh,作为LSTM最终的训练参数。
6.算法完整程序工程
OOOOO
OOO
O
关注GZH后输入回复:0032

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)