自然语言处理与bert
self attention又被称为自注意力机制,是现在运用最广的一种机制啊,通常被用于nlp里边,也就是,nature language process自然语言处理当中,
包括现在最为流行的大模型,各种各样的大模型基本上都是基于自注意力机制的。
首先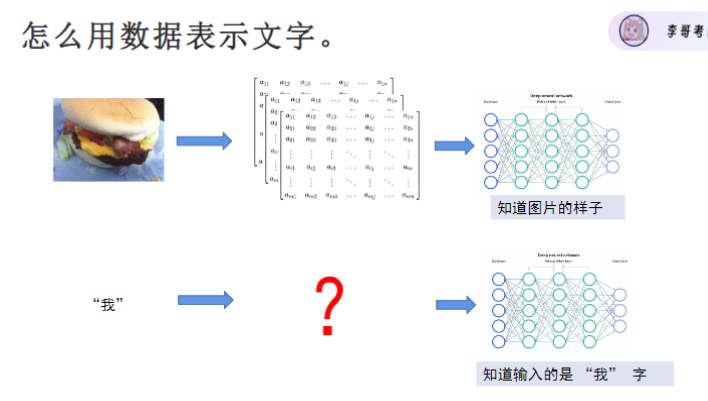
用向量来表示每一个字,共有21128个字,但有2个缺点,word embedding比较好,但还是只能输入向量,将one hot编码通过全连接层降维(如768维),通过一个全连接层就能让模型自动学习字词间的语义关系。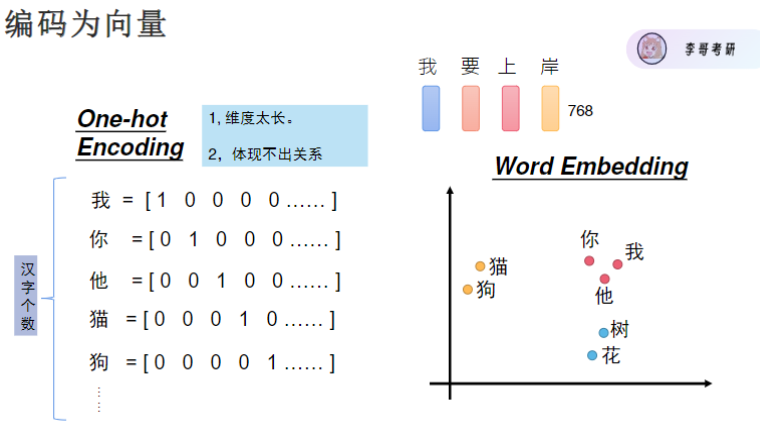
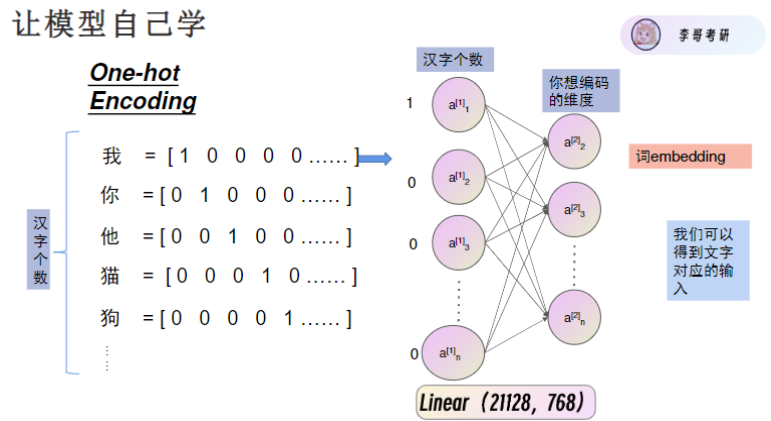
标点符号也对应一个向量

常见的输出有三类,前两个的类似分类任务,第三个是生成任务,这个下节再学
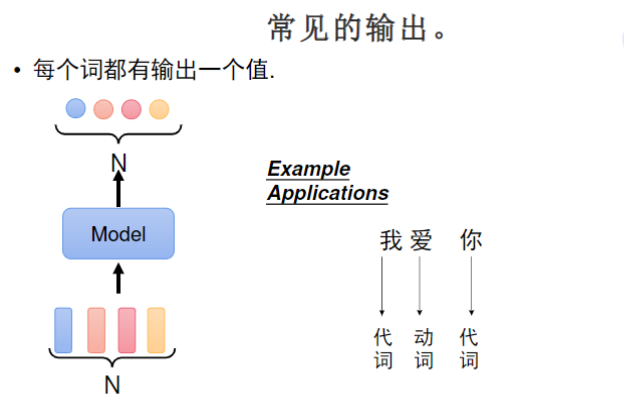
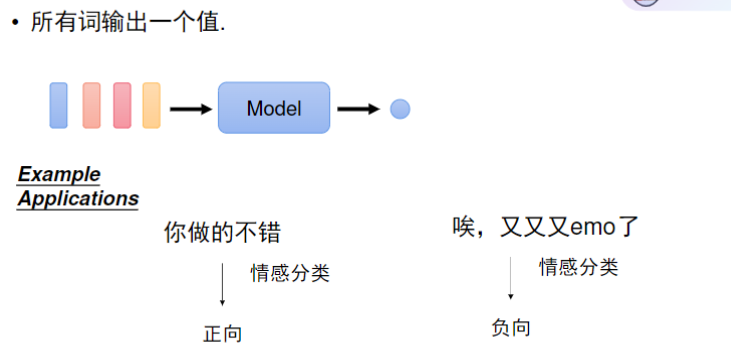
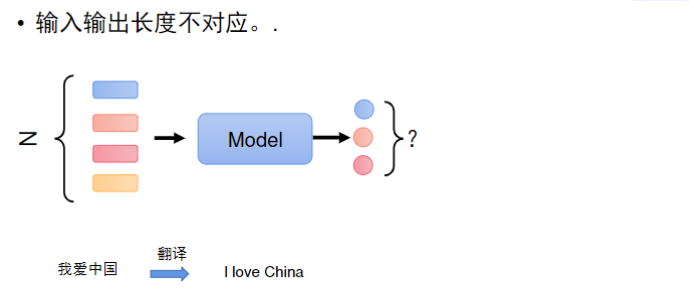
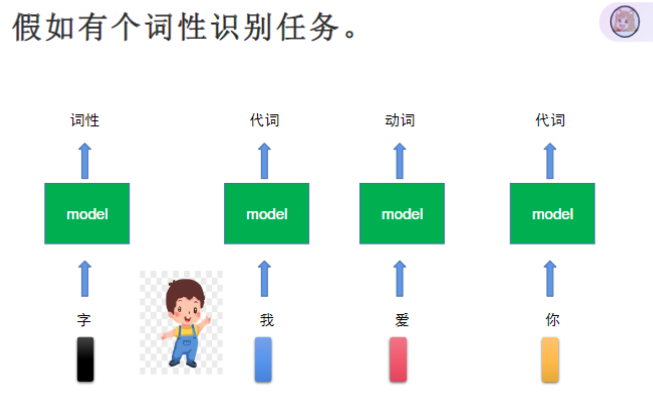
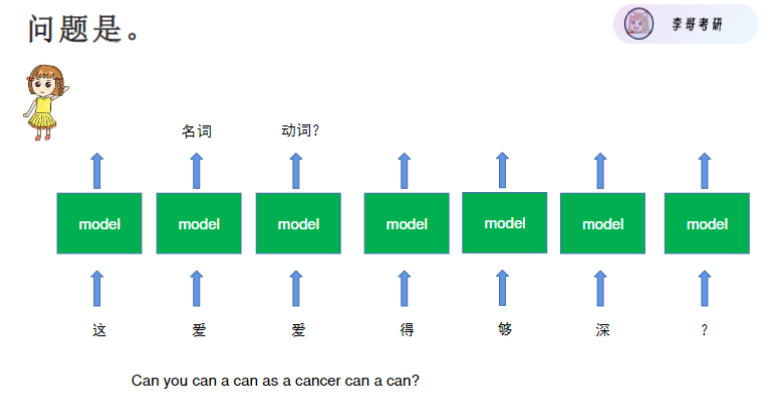
- 相同输入可能有不同输出(如"爱"字在不同上下文可能是名词或动词)
- 需要考虑前后文关系,不能孤立判断单个字
循环神经网络(RNN)通过传递记忆单元实现上下文关联,如判断"爱"字时知道前面是"这"字
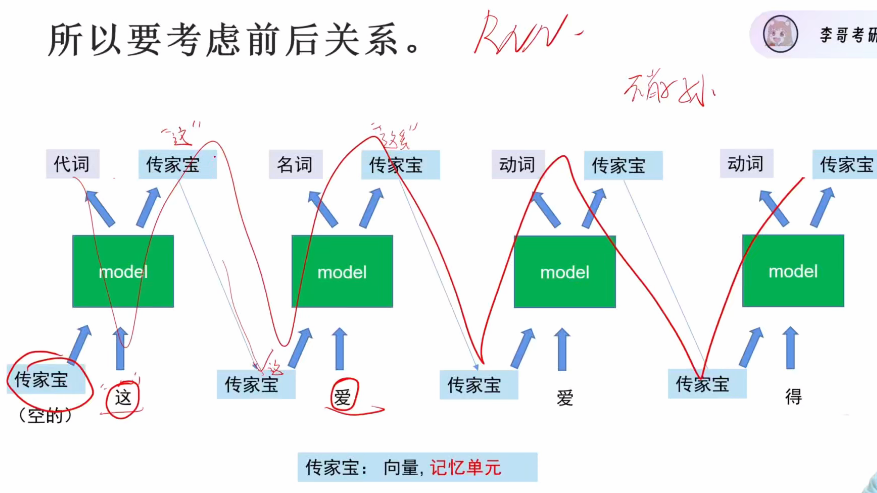
但当序列过长时,早期信息会被稀释或干扰(如"败家子孙"比喻),而且有并行限制: 必须串行处理,无法同时查看整个序列。而长短期记忆(LSTM)改进了一些。
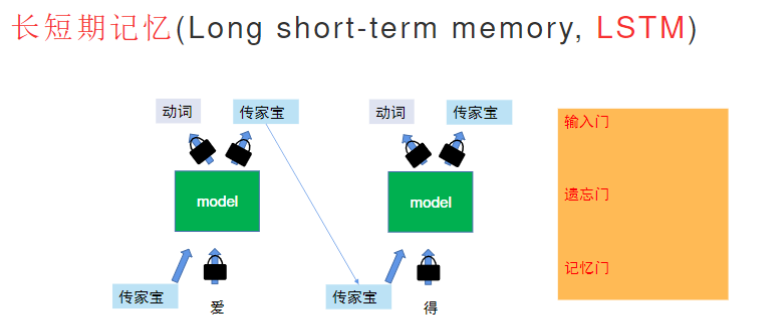
- 门控系统:
- 输入门:控制新信息进入记忆单元
- 遗忘门:决定保留或丢弃哪些历史信息
- 输出门:调节记忆单元对当前输出的影响
- 选择性记忆: 只保留关键信息(如只记住"我"和地点,忽略中间描述)
但这两个模型都只能一个字一个字的看,没法直接看完一整句话,即只能串行处理,没法并行输入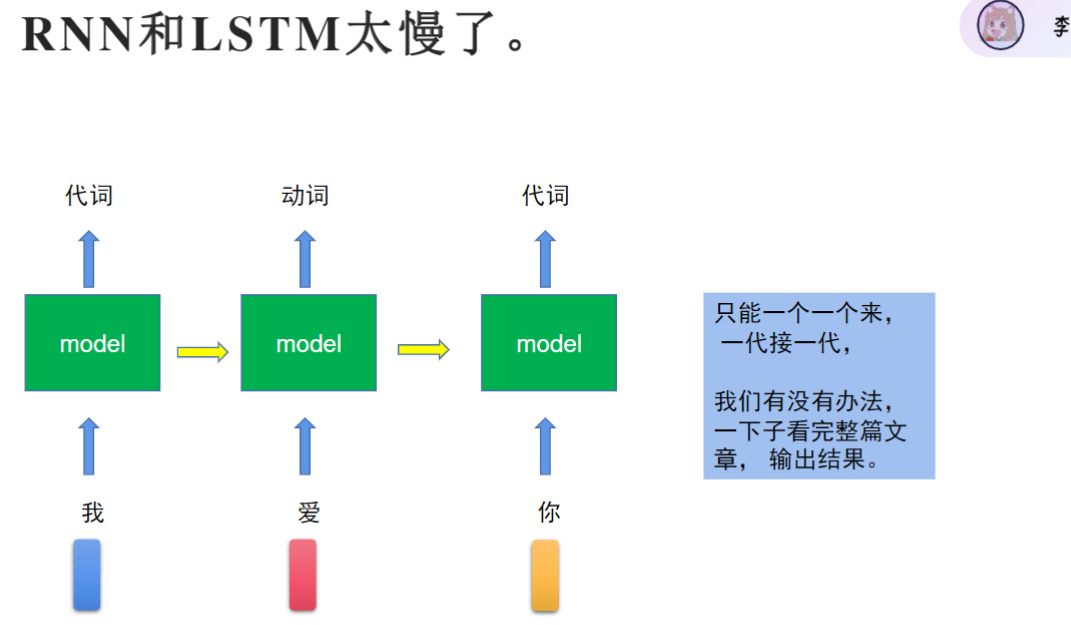
而自注意力机制可以并行输入。transformer模型分为特征提取和生成两个模块。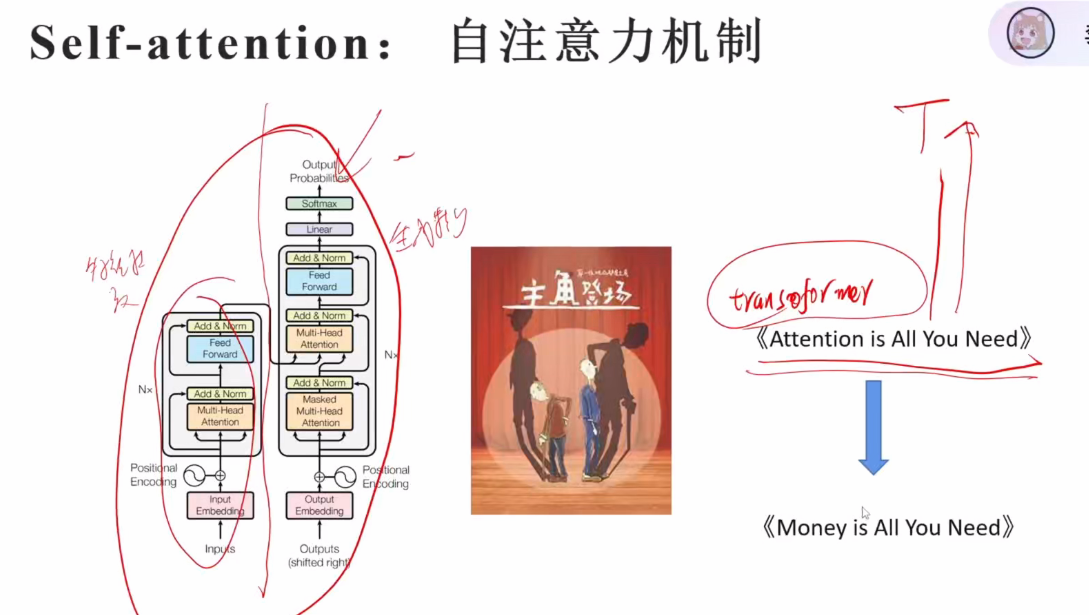
每一个输出都考虑了整个句子的特征
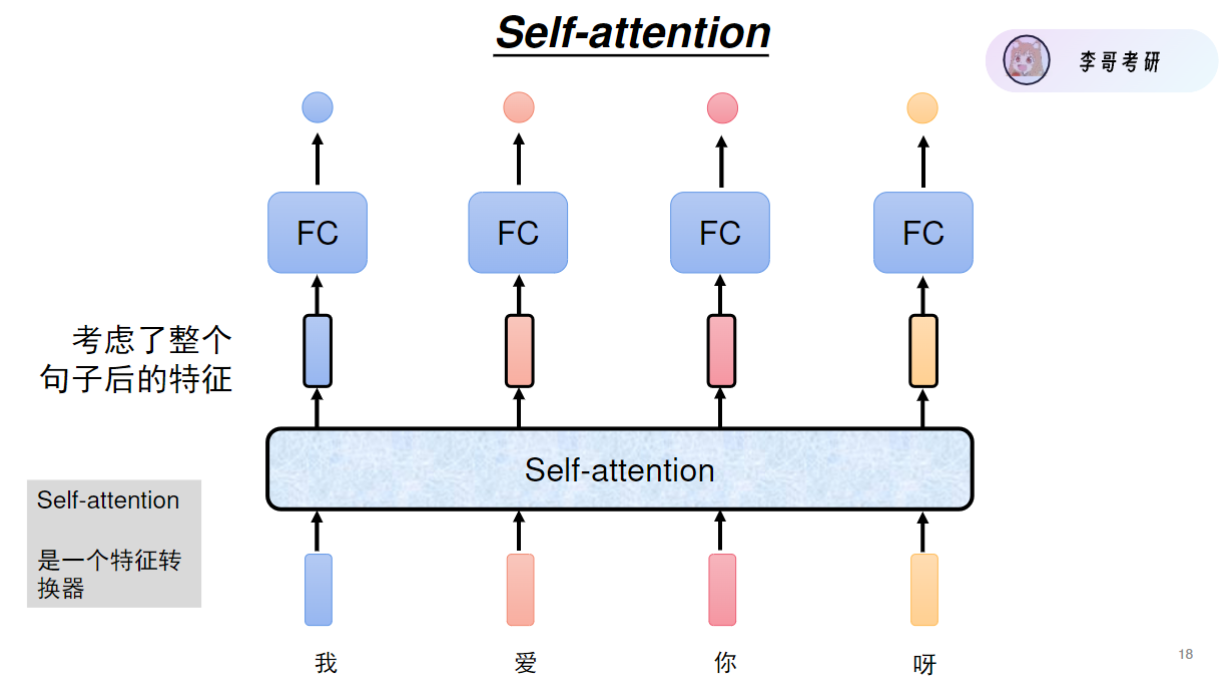
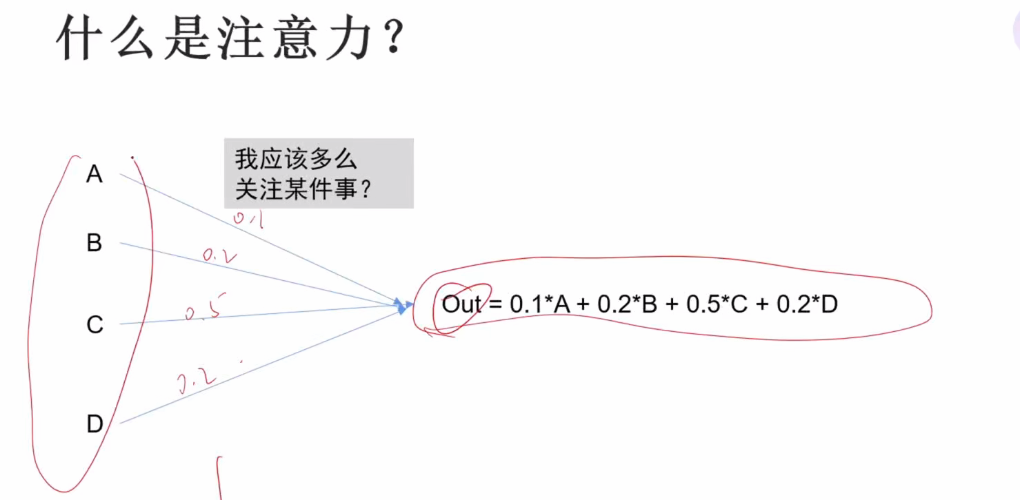
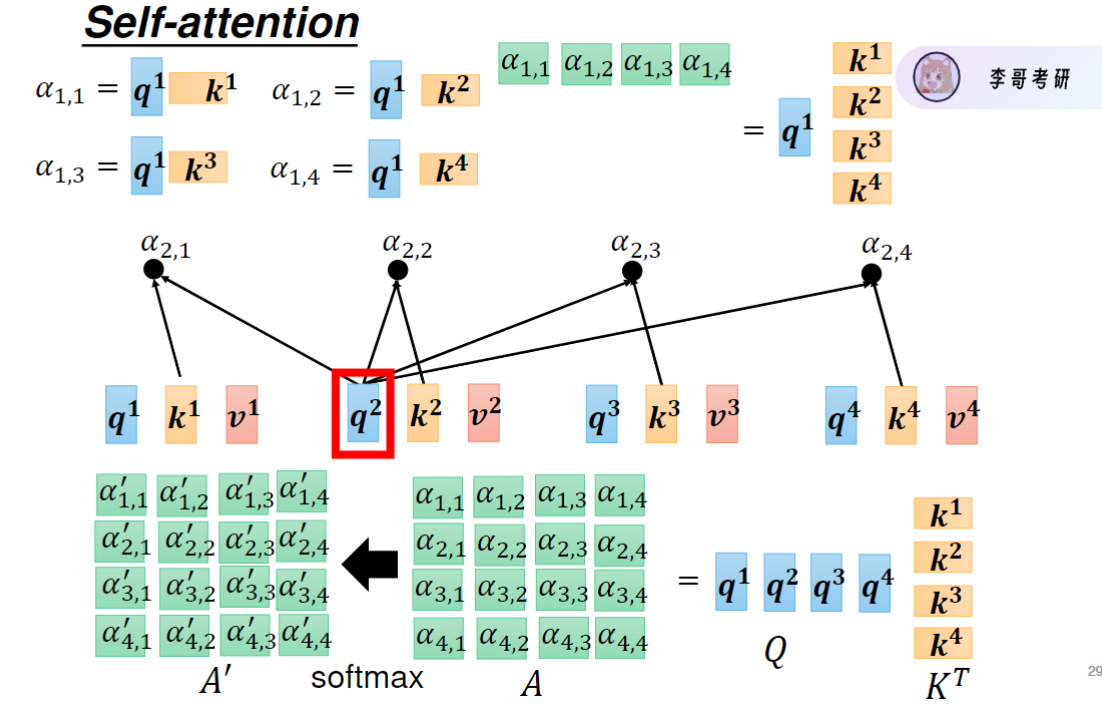
同理,要计算每个输入应该分配的注意力
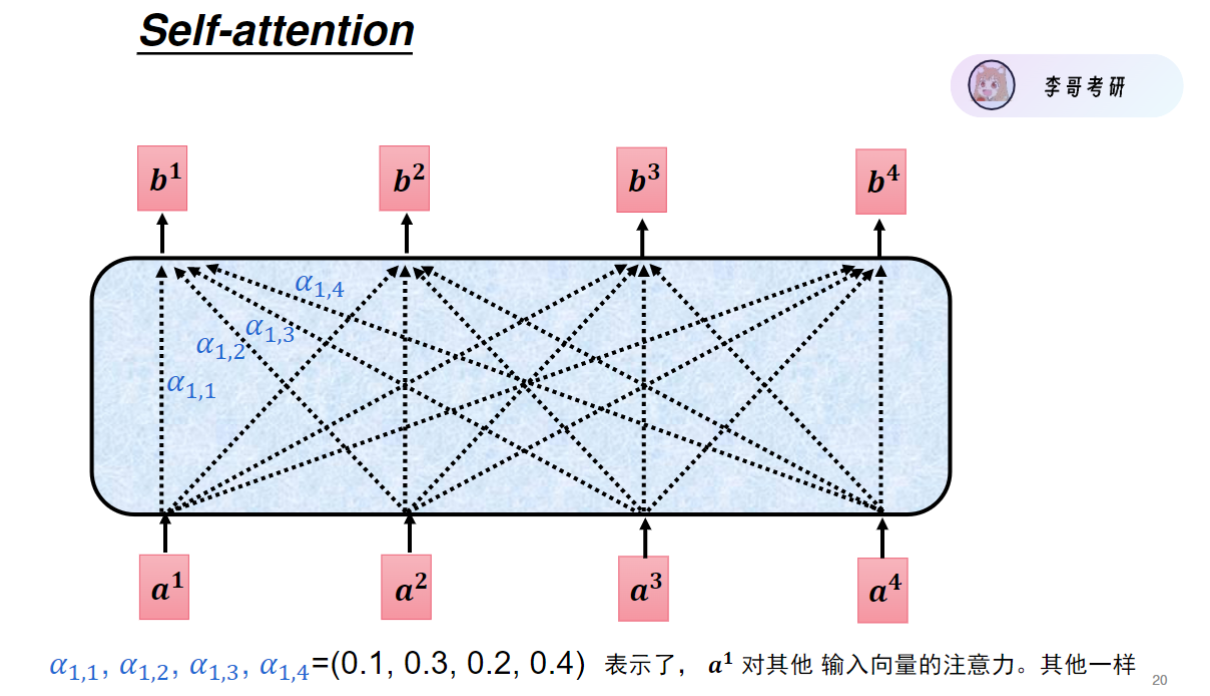
输入向量每乘一个矩阵实际就是经过一层全连接。注意力计算过程如下。


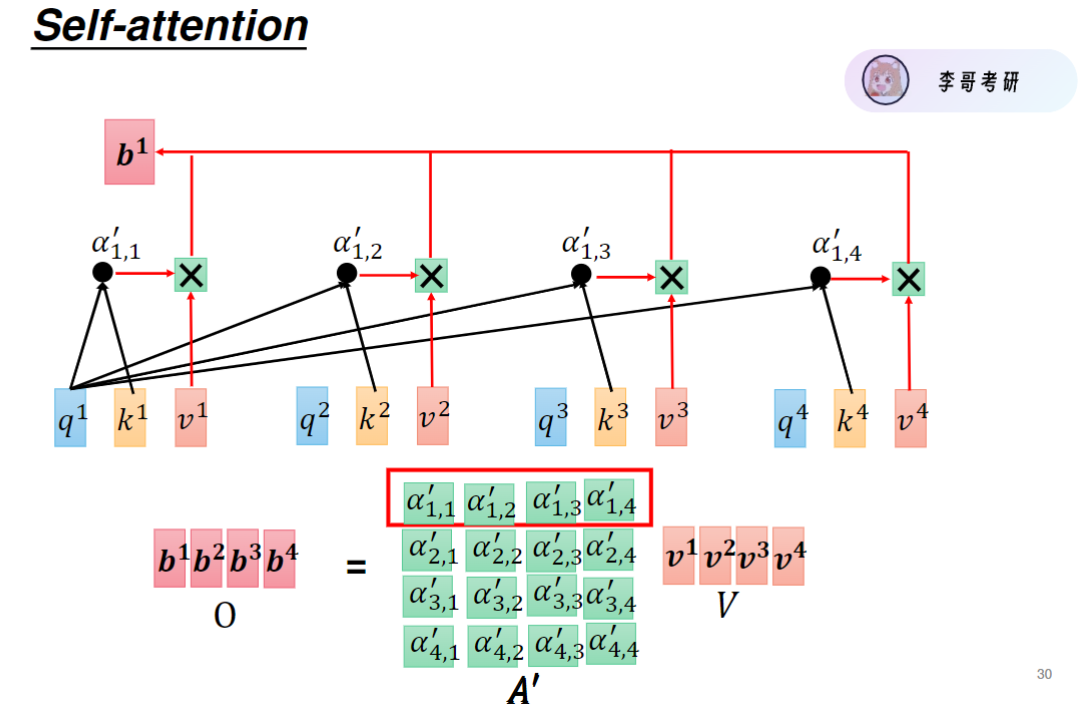
经过softmax函数得到注意力a'后,a还要再乘value矩阵得到v',再相加

这样所有注意力的计算都可以并行实现,同时运算,同时输出,比 串行快太多了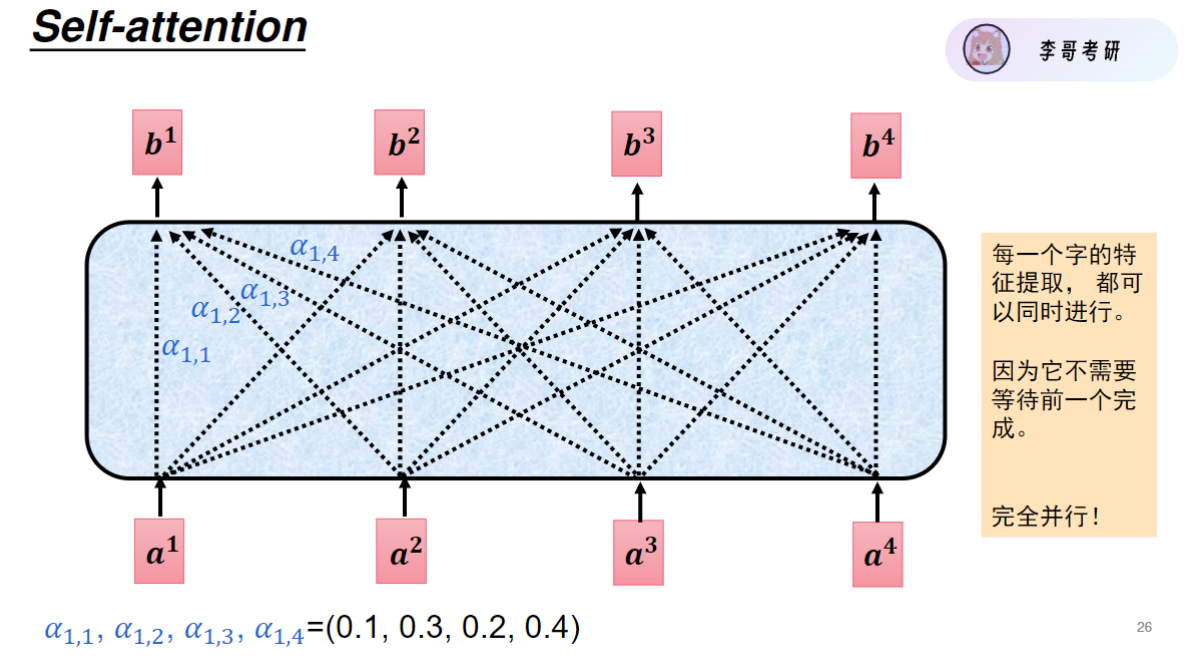
更具体的计算过程如下,将所有输入向量合并为矩阵与对应W矩阵相乘,得到Q K V矩阵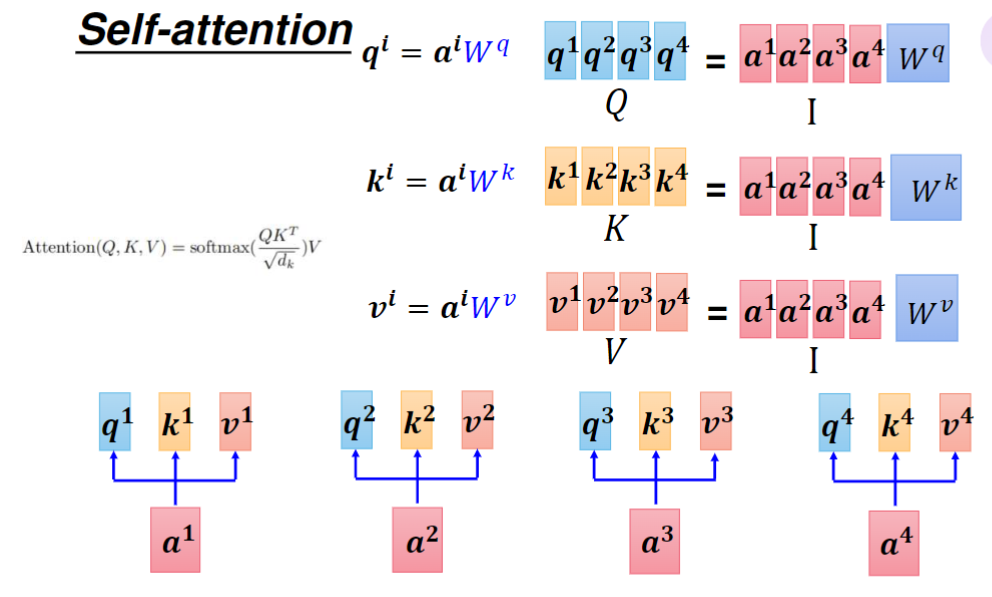
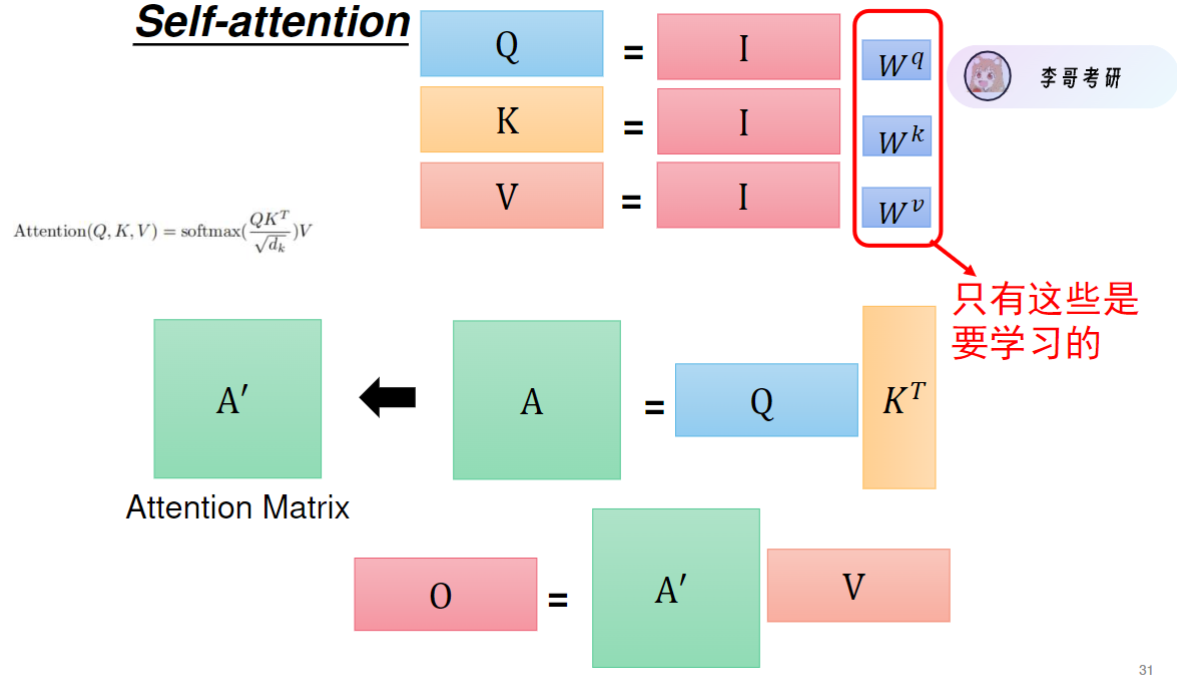
Q与K转置相乘,再对每行注意力权重单独做softmax进行归一化,得到注意力矩阵A‘
最终输出O=A′V,得到输出矩阵O,其中A′为4×4的注意力矩阵,V为4×768的特征矩阵
![]()
-
- 输入维度:在自注意力机制模型中,每个字的编码维度通常为768,即用一个768维的向量表示一个字。
- 序列长度:输入序列的长度通常为128或512个字符,以128为例进行计算。
- 输入矩阵:输入可以表示为128×768的矩阵,其中128是序列长度,768是每个字的编码维度。
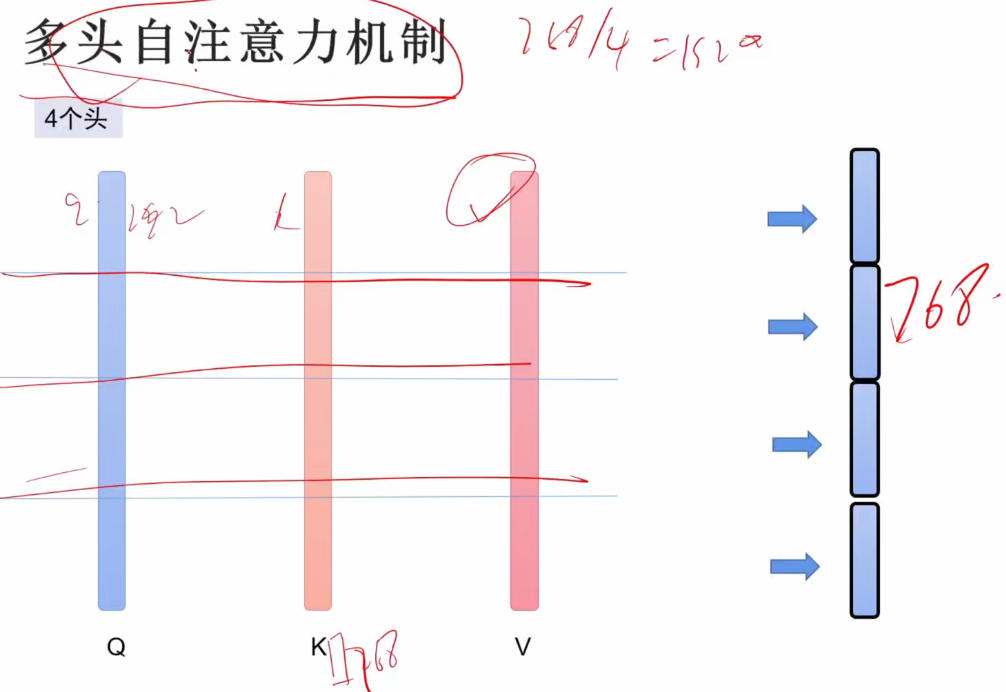
- 多头自注意力机制分割原理:将768维的Q、K、V分割为4个头,每个头的维度为192。
- 实际意义:虽然拼接后维度与原始输入相同,但多头机制可以捕捉不同子空间的注意力信息。
- 计算过程:
- 每个头独立计算注意力,得到4个192维的输出。
- 将4个头的输出拼接起来,恢复为768维,与原始输入维度一致。
此外输入的时候还要考虑字之间的位置信息
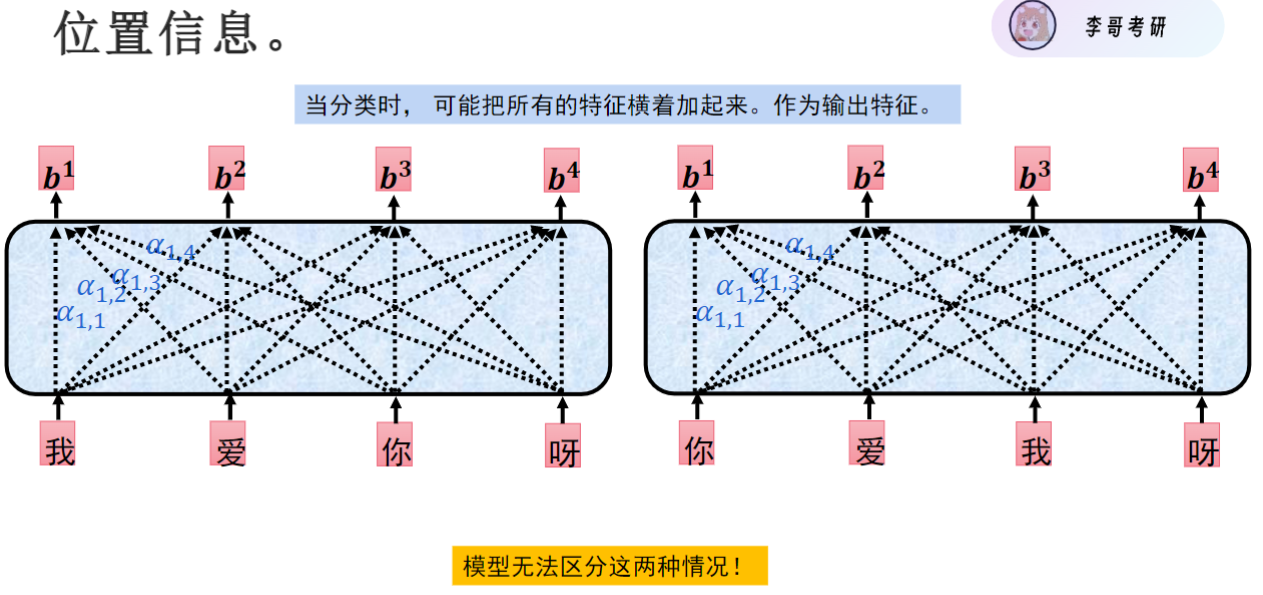
- 编码方式: 将每个字的位置信息转换为768维向量,与字编码直接相加。例如"我"字编码为(0.3,0.1,0.2),位置编码为(1,0,0),相加结果为(1.3,0.1,0.2)。
- 实现效果: 这种直接相加的方式虽然看起来简单,但实际效果很好,能显著提升模型性能。
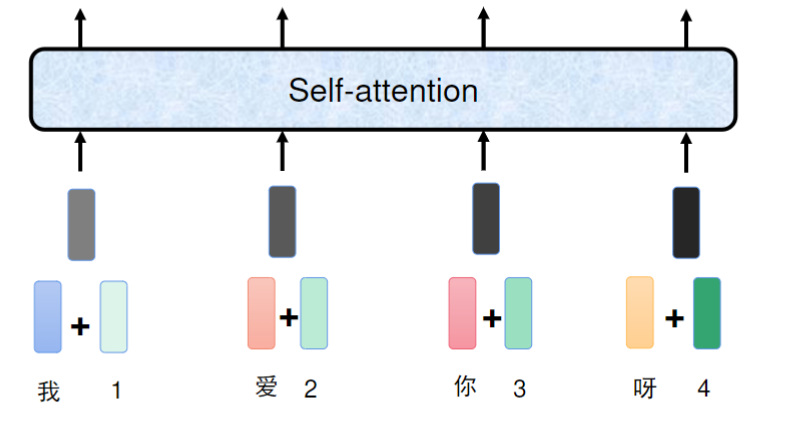
两个768维向量直接相加,形成最终的模型输入x。
-
-
- 词Embedding生成:
- 来源:词的one-hot形式
- 转换:通过Linear层(21128,768)转换为768维向量
- 位置Embedding生成:
- 来源:位置的one-hot形式(默认512长度)
- 转换:通过Linear层(512,768)转换为768维向量
- 词Embedding生成:
-
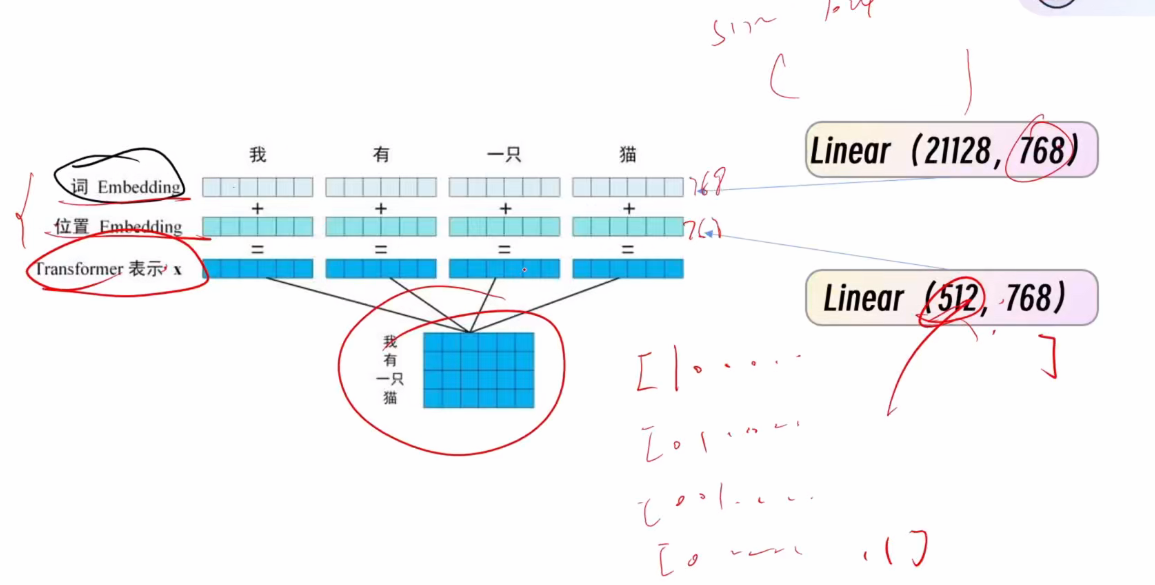
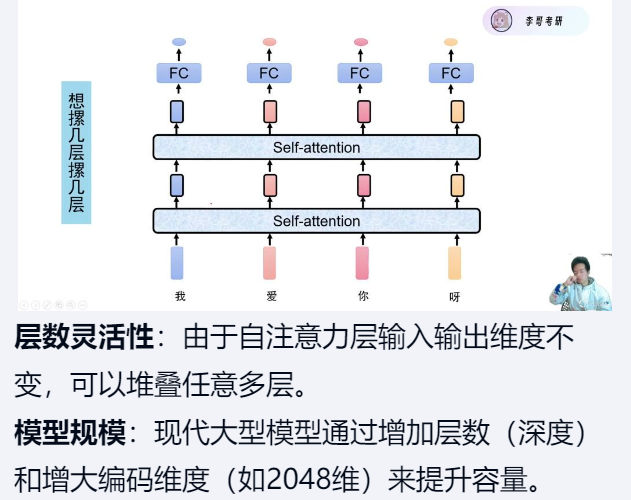
Token定义: 一个768维的向量称为一个token,包含词信息和位置信息。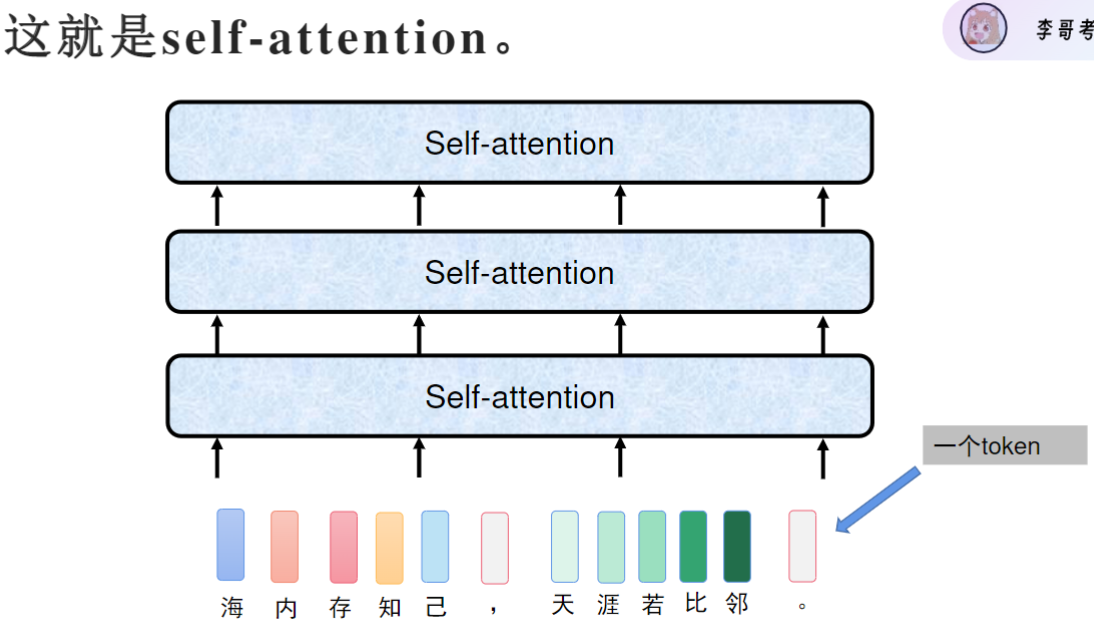
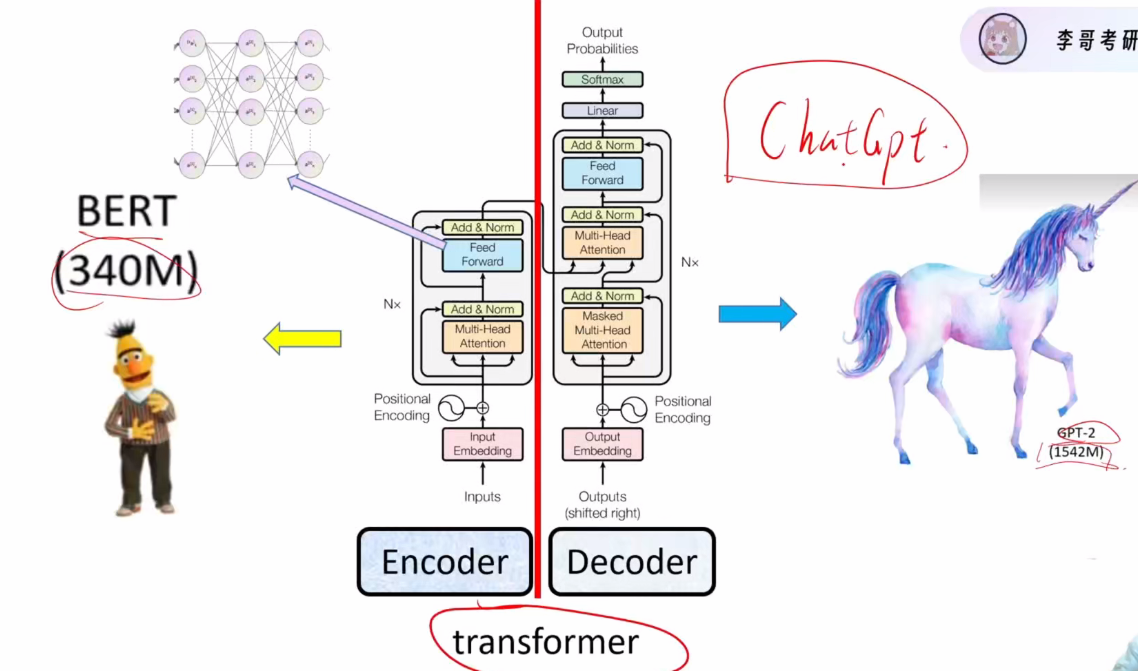
Transformer的编码器与解码器(Encoder):负责特征提取。(Decoder):基于编码特征生成文字,采用掩码自注意力机制。由Transformer延伸出来两个模型
BERT模型:基于Encoder部分,340M参数,成为文本分类任务标杆
GPT系列:基于Decoder部分,GPT-2达1542M参数,开创大模型时代
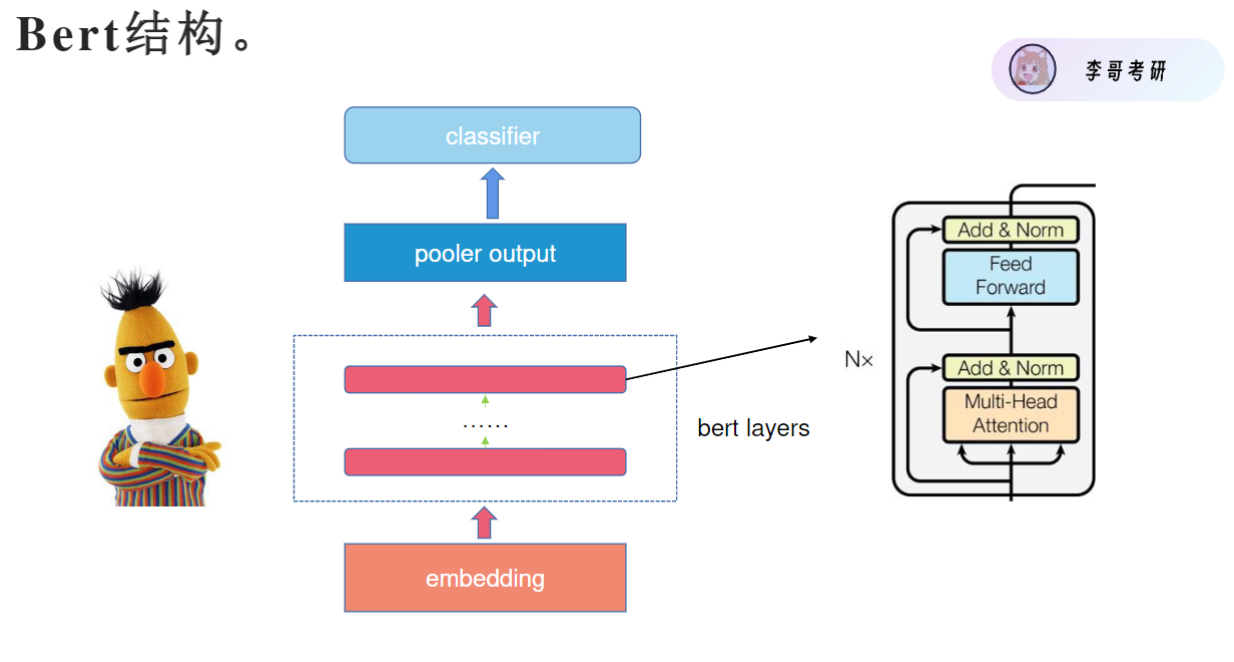
BERT模型借鉴了Transformer的Encoder部分,Encoder分为,词和位置Embedding相加输入,多头注意力机制,残差结构out=f(x)+x,层归一化处理,MLP多层感知机(前向传播层)由两个全连接层组成,先扩展后压缩(768→3072→768),这样经过多层堆叠后,最终输出768维的深度语义特征表示。
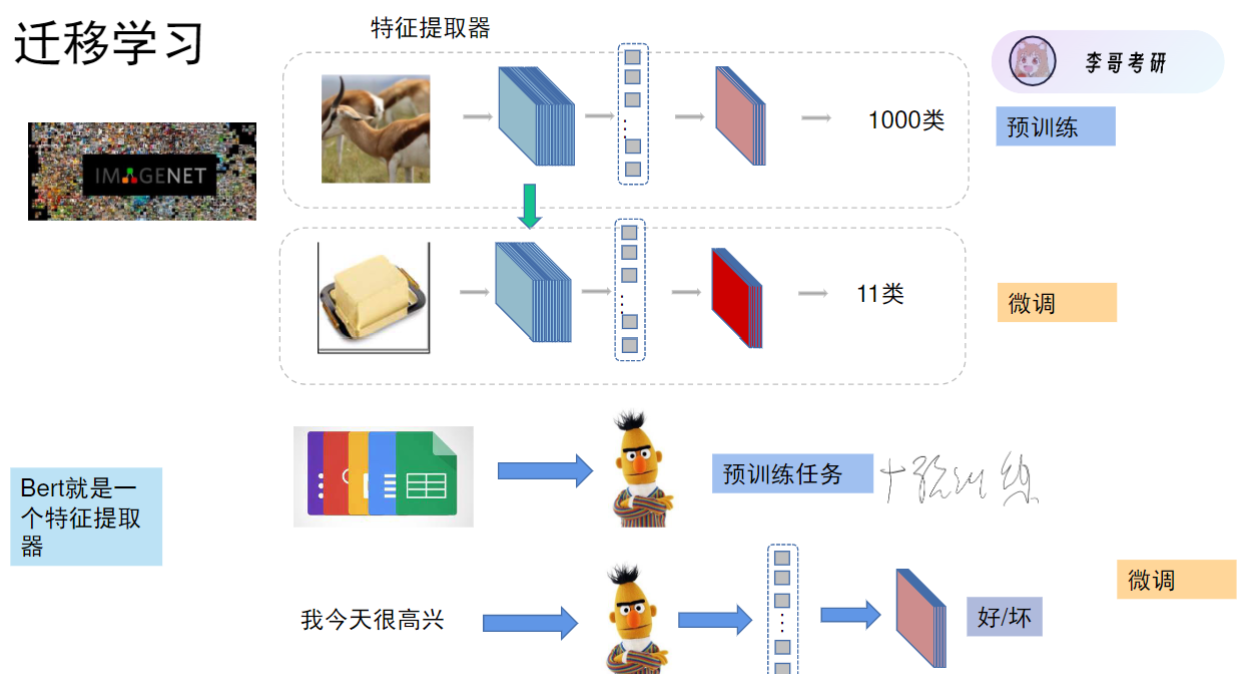
BERT模型通过自监督预训练获得文本特征提取能力
BERT模型预训练有两个主要任务,掩码语言模型(Masked Language Model)任务和Next Sentence Prediction (NSP)判断两个句子是否原文连续
- 双重任务设计:
- MLM关注词汇级语义理解(微观)
- NSP关注句子级逻辑关系(宏观)
- 效果验证:
- 通过遮盖词预测准确率评估MLM效果
- 通过相邻句判断准确率评估NSP效果
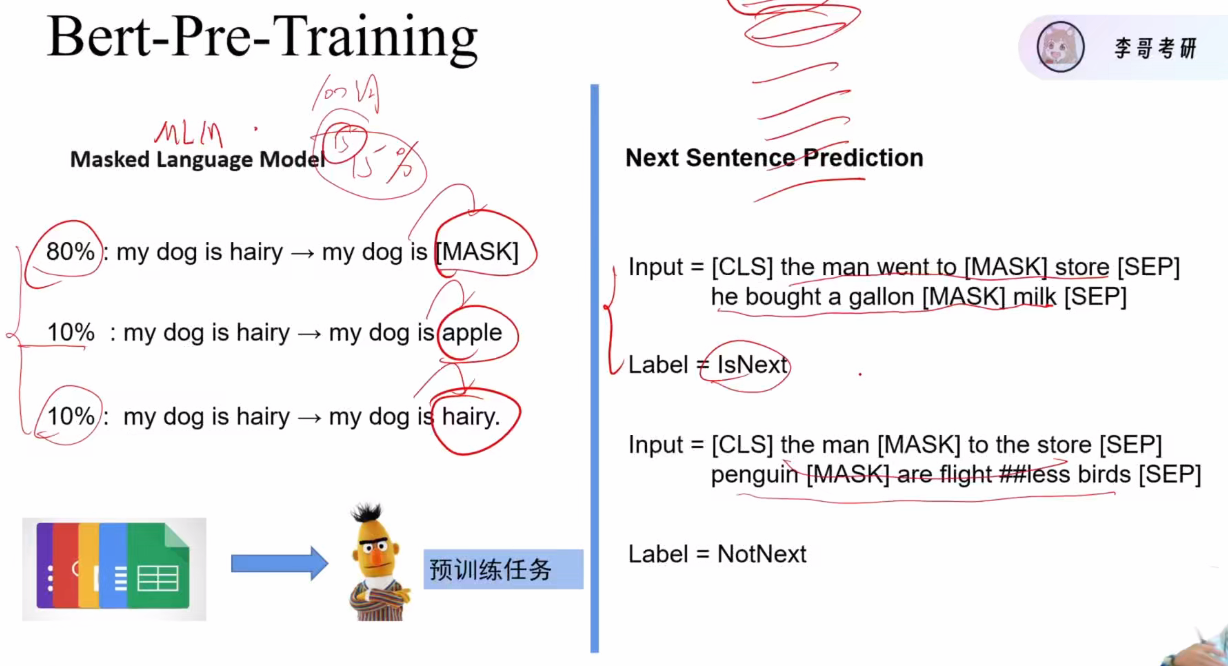
Bert layers有多个之前讲的Encoder层
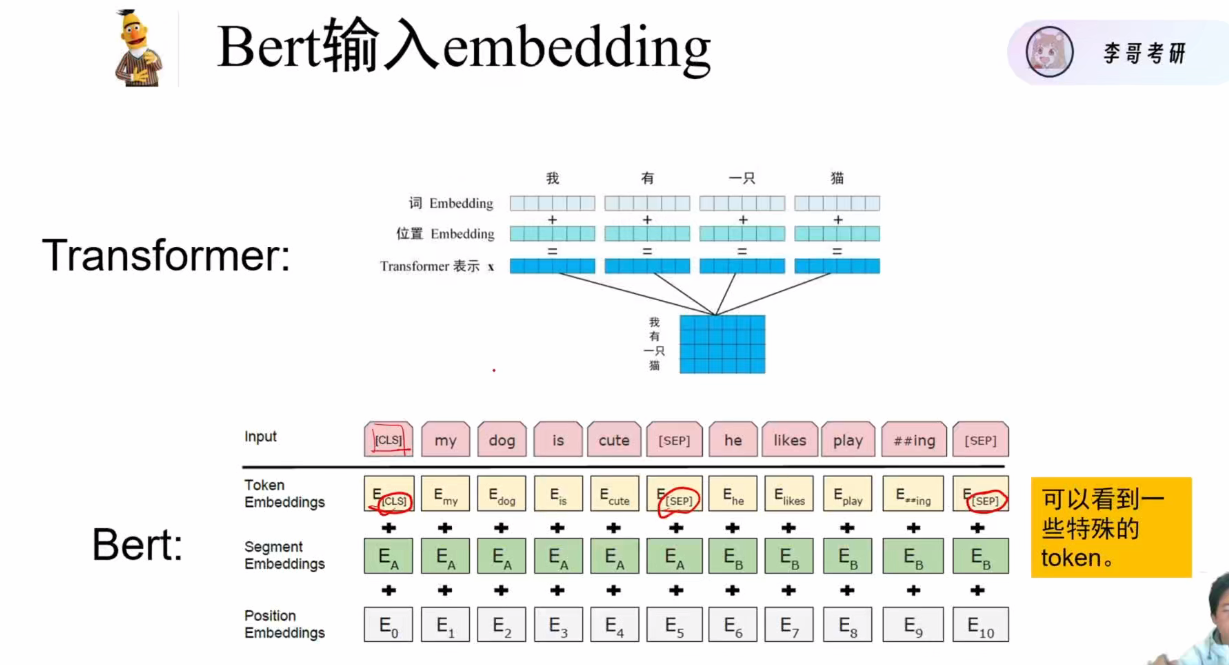
- 三种embedding相加:
- Token Embedding:与Transformer相同,将单词映射为768维向量(英语词表约3万词)
- Position Embedding:标记单词位置(0,1,2,...),与Transformer相同
- Segment Embedding:BERT特有,用于区分句子(A/B两种编码),表明该词属于不同的句子,用于NSP任务
- [CLS]:
- 分类任务专用标记(classification缩写)
- 通过自注意力机制聚合全局信息
- 类似链表的头节点作用
- [SEP]:
- 句子分隔标记(相当于句号/逗号)
- 用于划分句子边界
- 在NSP任务中分隔两个句子
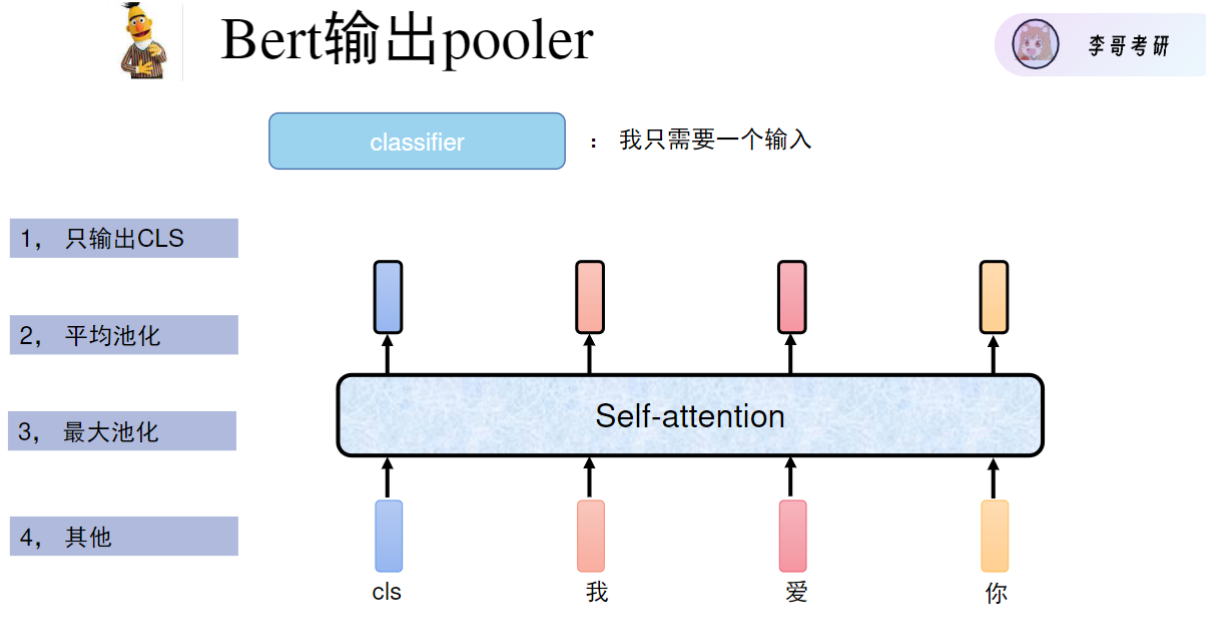
- 三种池化输出方法:
- CLS专用:仅提取[CLS]位置的768维向量(最常用)
- 平均池化:对所有token的768维向量取平均
- 最大池化:对每个维度取最大值(实际很少用)

自注意力机制的基本概念
1.自注意力机制是一种广泛应用的机制,尤其在自然语言处理(NLP)中。 2.该机制允许模型在处理序列数据时考虑整个序列,而不仅仅是局部信息。 3.自注意力机制通过计算序列中每个元素之间的注意力权重,实现对序列信息的全局关注。
文字序列的表示方法
1.文字序列是NLP任务中的常见输入,如句子、段落等。 2.将文字转换为计算机可理解的数值表示是关键步骤。 3.常见的表示方法包括one-hot编码和词嵌入(word embedding)。
词嵌入方法
1.词嵌入:根据词的含义将词转换为向量表示,使含义相近的词向量距离更近。 2.通过神经网络学习词嵌入关系,可以将词编码为具有含义的向量。 3.全连接网络可用于将高维词嵌入转换为固定维度的向量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)