C++11 扩展 --- 并发支持库(补充1)

atomic
为什么需要引入原子操作的概念?这是因为在多线程环境下,多个线程可能同时对同一个变量进行读或写操作。同时读没有问题,但同时写、或者一读一写,就会产生线程安全问题。前面我们讲过,解决线程安全的一种方式是加互斥锁。
但加互斥锁属于较重的操作,会带来明显的性能开销:一个线程获取锁之后,其他所有想要访问该锁保护资源的线程,都必须在锁释放前阻塞等待。线程从运行态切换到阻塞态、再从阻塞态切换回运行态,会触发进程调度,需要执行保存上下文、恢复上下文等一系列底层操作,这些操作都有不小的性能成本。
如果临界区非常小,比如仅仅是对一个整型变量做 ++ 操作,那么频繁地加锁、解锁,成本远高于操作本身,非常不划算。
这时,我们就可以使用更轻量的方案 ——原子操作(atomic)。
atomic 是一个模板的实例化和全特化均定义的原子类型,它可以保证对一个原子对象的操作是线程安全的。--- 对原子对象的操作是不需要加锁的!!!
对 T 类型的要求:模板可用任何满足可复制构造(CopyConstructible)及可复制赋值(CopyAssignable)的可平凡复制(TriviallyCopyable)类型 T 实例化。简单点就是拷贝赋值的实现不是深拷贝的,并不是说拿一个 vector 的类放进去就可以实现后面对 vector 的操作都是原子的了!
T 类型用以下函数判断时,如果一个返回 false,则用于 atomic 不是原子操作:
-
std::is_trivially_copyable<T>::value -
std::is_copy_constructible<T>::value -
std::is_move_constructible<T>::value -
std::is_copy_assignable<T>::value -
std::is_move_assignable<T>::value -
std::is_same<T, typename std::remove_cv<T>::type>::value
这些全都是 C++ 的类型萃取(type traits)
#include <iostream>
#include <vector>
#include <string>
struct Date
{
int _year = 1;
int _month = 1;
int _day = 1;
};
template<class T>
void check()
{
std::cout << typeid(T).name() << std::endl;
std::cout << std::is_trivially_copyable<T>::value << std::endl;
std::cout << std::is_copy_constructible<T>::value << std::endl;
std::cout << std::is_move_constructible<T>::value << std::endl;
std::cout << std::is_copy_assignable<T>::value << std::endl;
std::cout << std::is_move_assignable<T>::value << std::endl;
std::cout << std::is_same<T, typename std::remove_cv<T>::type>::value << std::endl
<< std::endl;
}
int main()
{
check<int>();
check<double>();
check<int*>();
check<Date>();
check<Date*>();
check<std::string>();
check<std::string*>();
return 0;
}atomic 的功能
基本运算支持:对于整形和指针,atomic 支持基本加减运算和位运算。
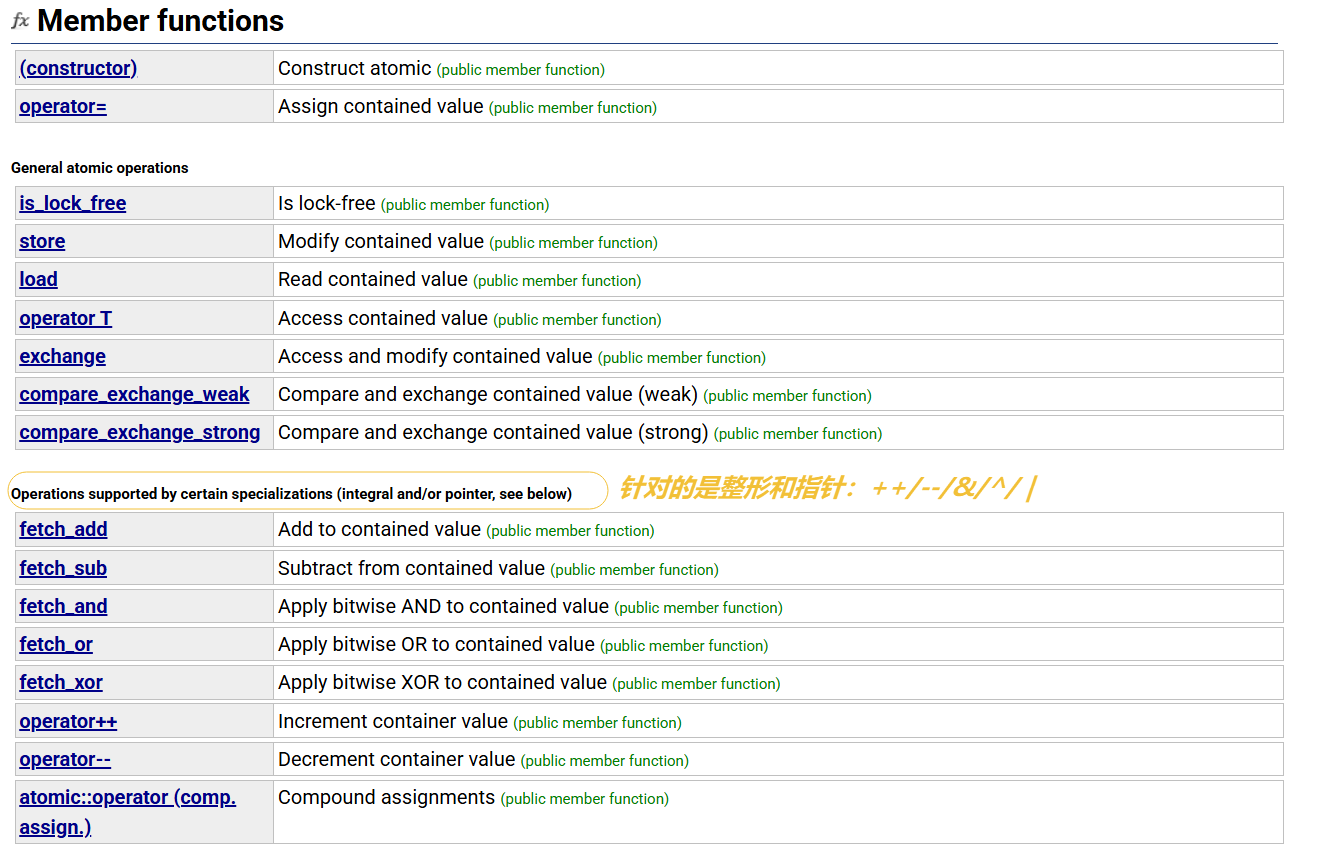
load 和 store:可以原子地读取和修改 std::atomic 封装的 T 对象。
原理:std::atomic 的核心原理依赖硬件层面的支持。现代处理器提供了专用原子指令来实现原子操作,例如 x86 架构中的 CMPXCHG(比较并交换) 指令。这些原子指令能够以不可分割的方式完成内存的读取、比较与写入操作,简称 CAS(Compare And Swap)。为了解决多处理器缓存间的数据一致性问题,硬件会采用缓存一致性协议:当原子操作修改变量时,该协议能保证其他处理器缓存中的同一份变量副本被及时更新或标记为无效。
实际使用中,std::atomic 最常用于整型和指针类型;C++20 之后新增了对智能指针的支持,对浮点数的支持也得到了大幅完善。
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
atomic_int acnt;
int cnt;
void f()
{
for (int n = 0; n < 100000; ++n)
{
++acnt;
++cnt;
}
}
int main()
{
std::vector<thread> pool;
for (int n = 0; n < 4; ++n)
pool.emplace_back(f);
for (auto& e : pool)
e.join();
cout << "原子计数器为 " << acnt << '\n'
<< "非原子计数器为 " << cnt << '\n';
return 0;
} .section .text.startup,"ax",@progbits
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp # 保存基指针寄存器
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp # 设置基指针寄存器
.cfi_def_cfa 6, 16
andq $-16, %rsp # 对齐栈指针
subq $32, %rsp # 为局部变量分配栈空间
movl $4, -4(%rbp) # 初始化线程数量为4
xorl %eax, %eax # 清零寄存器eax
movl %eax, -8(%rbp) # 初始化线程索引为0
movl %eax, -12(%rbp) # 初始化线程池指针为nullptr
movl %eax, acnt(%rip) # 初始化原子计数器为0
movl $0, cnt(%rip) # 初始化非原子计数器为0
.L2:
movl -8(%rbp), %eax # 加载线程索引
cmpl $4, %eax # 比较线程索引是否小于4
jae .L3 # 如果不小于4,跳转到.L3
movq -12(%rbp), %rdx # 加载线程池指针
leaq 8(%rdx), %rax # 计算下一个线程对象的地址
movq %rax, -12(%rbp) # 更新线程池指针
movl $0, (%rdx) # 初始化线程对象
movq -12(%rbp), %rdx # 加载线程对象地址
movq %rdx, %rdi # 将线程对象地址传给f函数
call f # 调用f函数
movl -8(%rbp), %eax # 加载线程索引
addl $1, %eax # 增加线程索引
movl %eax, -8(%rbp) # 更新线程索引
jmp .L2 # 跳转回.L2继续循环
.L3:
movq -4(%rbp), %rax # 加载线程数量
testq %rax, %rax # 测试线程数量是否为0
je .L5 # 如果为0,跳转到.L5
.L4:
movq -4(%rbp), %rdx # 加载线程数量
decq %rdx # 减少线程数量
movq %rdx, -4(%rbp) # 更新线程数量
movq (%rdx), %rdx # 加载线程对象地址
movq %rdx, %rdi # 将线程对象地址传给join函数
call *%rdx # 调用join函数
jmp .L4 # 跳转回.L4继续循环
.L5:
movl acnt(%rip), %eax # 加载原子计数器的值
movl %eax, -16(%rbp) # 保存原子计数器的值
movl cnt(%rip), %eax # 加载非原子计数器的值
movl %eax, -20(%rbp) # 保存非原子计数器的值
movl -16(%rbp), %eax # 加载保存的原子计数器的值
movl %eax, -24(%rbp) # 保存原子计数器的值到输出缓冲区
movl -20(%rbp), %eax # 加载保存的非原子计数器的值
movl %eax, -28(%rbp) # 保存非原子计数器的值到输出缓冲区
movl $0, %eax # 清零寄存器eax
movq -24(%rbp), %rsi # 加载原子计数器的值到rsi
movq %rsi, (%rsp) # 将原子计数器的值放入栈中
movl $.LC0, %edi # 加载格式化字符串地址到edi
movq %rsp, %rsi # 将栈顶地址传给printf函数
movq %rsp, %rdx # 再次将栈顶地址传给printf函数
subq $32, %rsp # 为printf函数分配栈空间
call std::cout@plt # 调用cout函数输出原子计数器的值
addq $32, %rsp # 恢复栈空间
movl -28(%rbp), %eax # 加载非原子计数器的值
movl %eax, -32(%rbp) # 保存非原子计数器的值到输出缓冲区
movl $0, %eax # 清零寄存器eax
movq -32(%rbp), %rsi # 加载非原子计数器的值到rsi
movq %rsi, (%rsp) # 将非原子计数器的值放入栈中
movl $.LC1, %edi # 加载格式化字符串地址到edi
movq %rsp, %rsi # 将栈顶地址传给printf函数
movq %rsp, %rdx # 再次将栈顶地址传给printf函数
subq $32, %rsp # 为printf函数分配栈空间
call std::cout@plt # 调用cout函数输出非原子计数器的值
addq $32, %rsp # 恢复栈空间
movq %rbp, %rsp # 恢复栈指针
popq %rbp # 恢复基指针寄存器
ret # 返回调用者
.cfi_endproc
.LFE0:
.size main, .-mainCAS 接口
gcc 支持的 CAS 接口:
bool __sync_bool_compare_and_swap (type *ptr, type oldval, type newval);
type __sync_val_compare_and_swap (type *ptr, type oldval, type newval);Windows 支持的 CAS 接口:
InterlockedCompareExchange ( __inout LONG volatile *Target, __in LONG Exchange, __in LONG Comperand);C++11 支持的 CAS 接口:封装就是为了跨平台了!!!
template <class T>
bool atomic_compare_exchange_weak (atomic<T>* obj, T* expected, T val) noexcept;
template <class T>
bool atomic_compare_exchange_strong (atomic<T>* obj, T* expected, T val) noexcept;C++11 中 atomic 类的成员函数:
bool compare_exchange_weak (T& expected, T val, memory_order sync = memory_order_seq_cst) noexcept;
bool compare_exchange_strong (T& expected, T val, memory_order sync = memory_order_seq_cst) noexcept;代码样例:
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
atomic<int> acnt;
//atomic_int acnt;
int cnt;
void Add1(atomic<int>& cnt)
{
int old = cnt.load();
// 如果cnt的值跟old相等,则将cnt的值设置为old+1,并且返回true,这组操作是原子的。
// 那么如果在load和compare_exchange_weak操作之间cnt对象被其他线程改了
// 则old和cnt不相等,则将old的值改为cnt的值,并且返回false。
// while (!atomic_compare_exchange_weak(&cnt, &old, old + 1));
while (!cnt.compare_exchange_weak(old, old + 1));//使用成员函数也可以
}
void f()
{
for (int n = 0; n < 100000; ++n)
{
//++acnt;
// Add1的用CAS模拟atomic的operator++的原子操作
Add1(acnt);
++cnt;
}
}
int main()
{
std::vector<thread> pool;
for (int n = 0; n < 4; ++n)
pool.emplace_back(f);
for (auto& e : pool)
e.join();
cout << "原子计数器为 " << acnt << '\n'
<< "非原子计数器为 " << cnt << '\n';
return 0;
}atomic<int> acnt;
int cnt;-
acnt是一个原子整数,用于线程安全的计数。 -
cnt是一个普通整数,用于非线程安全的计数。
void Add1(atomic<int>& cnt)
{
int old = cnt.load();
while (!cnt.compare_exchange_weak(old, old + 1));
}cnt.load() 获取当前原子变量的值。
compare_exchange_weak 是一个弱比较交换操作,它会将 cnt 的值与 old 比较:
-
如果相等,则将
cnt的值更新为old + 1,并返回true。 -
如果不相等,则将
old更新为当前的cnt值,并返回false。因为这个 cnt 在这个时刻已经被别的线程操作了 -
使用
while循环确保操作最终成功【因为多线程并发时,可能刚拿到old,别的线程就把值改了。这时候 CAS 会失败,必须重试,直到修改成功】
void f()
{
for (int n = 0; n < 100000; ++n)
{
Add1(acnt); // 原子操作
++cnt; // 非原子操作
}
}每个线程执行 100,000 次计数操作:
-
原子计数器
acnt使用Add1函数进行线程安全的递增。 -
非原子计数器
cnt使用普通递增操作。
int main()
{
vector<thread> pool;
for (int n = 0; n < 4; ++n)
pool.emplace_back(f);
for (auto& e : pool)
e.join();
cout << "原子计数器为 " << acnt << '\n'
<< "非原子计数器为 " << cnt << '\n';
return 0;
}-
创建 4 个线程,每个线程执行
f函数。 -
等待所有线程完成。
-
输出原子计数器和非原子计数器的值。
运行结果:
-
原子计数器 (
acnt):由于使用了原子操作,最终值应为400,000(4 个线程,每个线程递增 100,000 次)。 -
非原子计数器 (
cnt):由于没有线程同步,多个线程同时递增cnt,可能会导致数据竞争,最终值通常小于400,000。
CAS 操作的特性 --- 读取·比较·写入
操作逻辑:atomic 对象与 expected【我预期这个变量现在应该是什么值:期望值】 按位比较:
- 若相等,则使用
val更新atomic对象,并返回true; - 若不相等,则将
expected更新为atomic对象的当前值,并返回false。
compare_exchange_weak 和 compare_exchange_strong 的区别:
-
compare_exchange_weak在某些平台上,即使原子变量的值等于 expected,也可能“虚假地”失败(即返回 false)。这种失败是由于底层硬件或编译器优化导致的,但不会改变原子变量的值。 -
compare_exchange_strong保证在原子变量的值等于 expected 时不会虚假地失败。只要原子变量的值等于 expected,操作就会成功。 -
compare_exchange_weak在某些平台上可能比compare_exchange_strong更快,但可能会因为硬件层间的缓存一致性或编译器优化等问题而虚假失败。compare_exchange_strong要避免这些原因,需要付出一定的代价,比如使用硬件的缓存一致性协议(如 MESI 协议)。
在多核处理器系统中,CPU 核心通过高速缓存快速访问数据,寄存器用于存放当前正在处理的数据。缓存一致性问题是指:当一个核心修改了自身缓存中的数据时,其他核心里的同一份数据副本需要被及时更新或标记为无效,否则会出现数据不一致。
硬件层面通过缓存一致性协议(如 MESI 协议)解决这一问题,保证所有核心的缓存与内存数据始终保持一致,从而维持系统的正确性与性能。
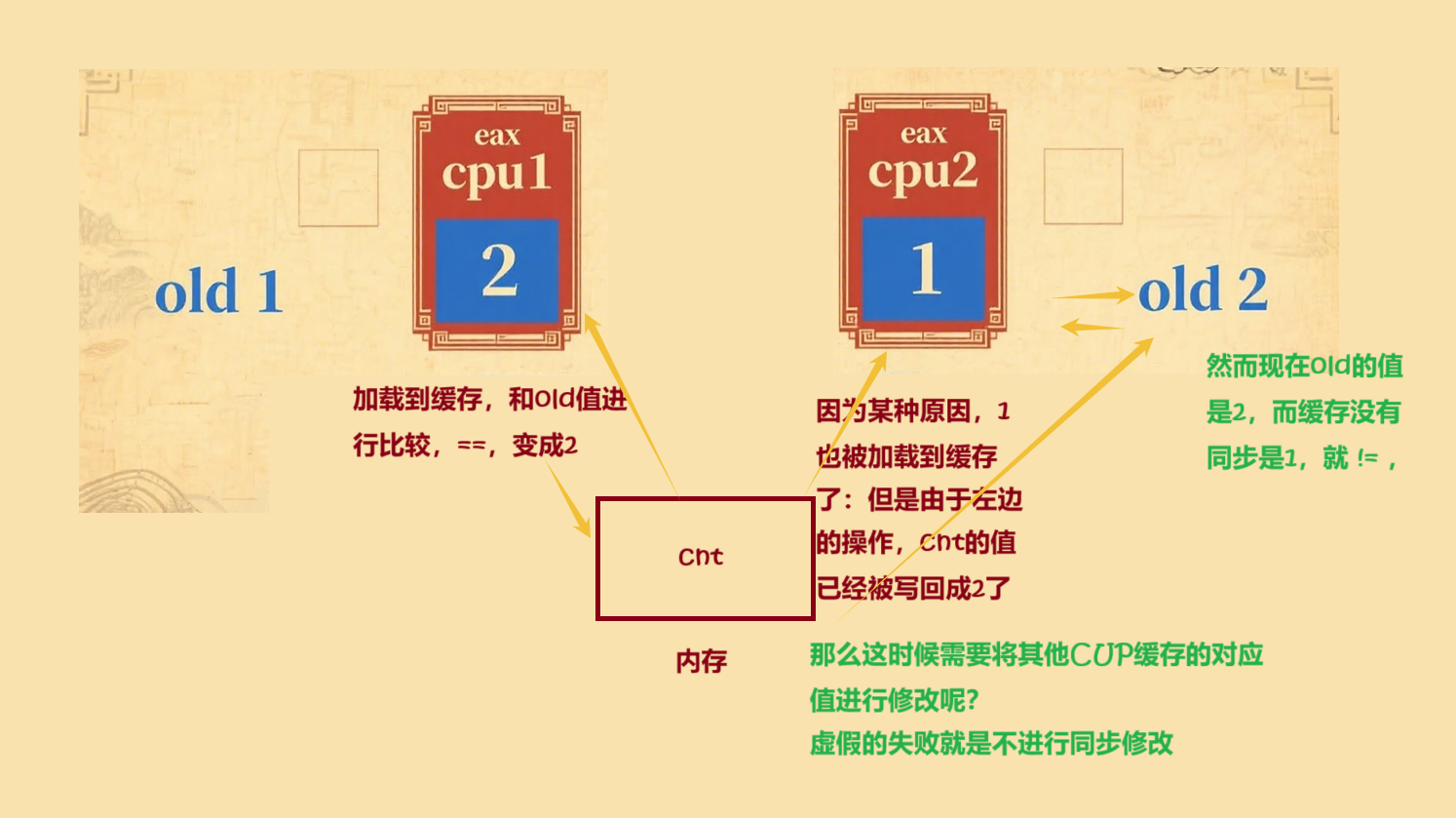
在这个过程中,CPU1 和 CPU2 都试图修改共享内存中的变量 Cnt。CPU1 首先将 Cnt 的值加载到自身缓存,与预期值 old(1) 比较,相等后将其修改为 2。几乎同时,CPU2 也将 Cnt 的值加载到自身缓存,此时 Cnt 已被 CPU1 修改为 2,但 CPU2 的缓存尚未同步,依旧是旧值 old(1)。当 CPU2 执行比较操作时,发现自身缓存值(1)与预期值 old(1) 相等,于是也将其修改为 2,但该操作基于旧数据,因此是无效的。这就是所谓的 “虚假失败”,需要通过缓存一致性协议来解决,确保所有 CPU 核心的缓存与寄存器中的数据保持同步。
我们看一个示例:原子的去对一个链表添加节点:
【头插:新节点 → 老 head,然后新节点变 head】
#include <atomic> // 包含 std::atomic 的头文件
#include <thread> // 包含 std::thread 的头文件
#include <vector> // 包含 std::vector 的头文件
#include <iostream> // 包含 std::cout 的头文件
#include <chrono> // 包含 std::this_thread::sleep_for 的头文件
// 定义一个简单的全局链表结构
struct Node {
int value; // 节点的值
Node* next; // 指向下一个节点的指针
};
std::atomic<Node*> list_head(nullptr); // 使用原子操作的链表头指针,初始值为 nullptr
// 向链表中追加一个元素的函数
void append(int val) {
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作,让线程暂停 1 秒
Node* oldHead = list_head.load(); // 加载当前链表头指针的值
Node* newNode = new Node{ val, oldHead }; // 创建一个新节点,其值为 val,指向当前的链表头
// 使用原子操作安全地更新链表头指针
// 相当于:list_head = newNode,但以线程安全的方式实现
// 失败重试期间的赋值,只是准备工作,真正 “修改共享链表头” 的那一下,是原子的!
while (!list_head.compare_exchange_weak(oldHead, newNode)) {
newNode->next = oldHead; // 如果更新失败,重新设置新节点的 next 指针
oldHead = list_head.load(); // 重新加载当前链表头指针的值
}
}
int main()
{
// 创建 10 个线程来填充链表
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i)
threads.push_back(std::thread(append, i)); // 启动线程,每个线程调用 append 函数,传入不同的值
// 等待所有线程完成
for (auto& th : threads)
th.join();
// 打印链表的内容
for (Node* it = list_head; it != nullptr; it = it->next)
std::cout << ' ' << it->value;
std::cout << '\n';
// 清理链表,释放内存
Node* it;
while (it = list_head) {
list_head = it->next; // 将链表头指针移动到下一个节点
delete it; // 删除当前节点
}
return 0;
}两个线程同时执行头部插入节点操作,并且同时将 next 指针指向新节点,就有可能导致其中一个线程的操作被另一个线程覆盖,最终造成节点丢失。这个问题我们的代码解决了:
它的逻辑是:
- 我先看一眼现在的头是谁
- 我尝试把新节点设为头
- 如果中途别人改了头 → 我失败!
- 失败了我就重新获取最新头,再试一次!
- 直到成功为止
memory_order 【第三个参数】:是否需要控制内存序—— 需要就手动传入参数,不需要则使用默认值。
此外还有是否带 volatile 修饰的区别:
volatile 是 C++ 关键字,作用是防止编译器优化变量访问,通常用于硬件寄存器、中断处理等场景,但它不保证线程安全,也不提供原子性。而 std::atomic 是 C++11 专门用于多线程的原子类型,能保证线程安全、无数据竞争,还可以通过内存序控制操作的同步行为。
简单总结:volatile 用于禁止编译器优化,std::atomic 用于多线程安全与原子操作。
CPU 缓存与无锁编程
-
CPU 缓存相关知识:可以参考陈皓的博客 与程序员相关的 CPU 缓存知识 | 酷壳 - CoolShell
-
无锁编程知识:可以参考陈皓的博客 无锁队列的实现 | 酷壳 - CoolShell
std::atomic 的内存顺序选项
注意:
store是:直接赋值
compare_exchange_weak是:有条件的赋值
store()就是:安全的、原子的 “赋值”相当于:
atomic<int> a; a = 10; // 本质就是 store(10)它的逻辑:
不管现在值是多少,直接改成我要的值!一步到位,没有判断,没有比较。
compare_exchange_weak是:只有等于我预期的值,才修改!不等于,就不改,返回失败!它的逻辑:
if (a == 预期值) { a = 新值; return true; } else { return false; }这是 “有条件修改”必须满足条件才会改!
上面代码里用 CAS,不用 store 是因为我们是多线程并发头插链表!如果我们直接用 store:
list_head.store(newNode); // 错误!会覆盖!后果:两个线程同时 store → 直接覆盖 → 节点丢失!
所以我们必须用 CAS:
while(!list_head.compare_exchange_weak(oldHead, newNode));因为:
- 只有头还是
oldHead才修改- 被别人改了就失败,重试
- 绝对不会覆盖
对于内存顺序选项:
memory_order_relaxed:最宽松的内存顺序,仅保证原子操作的原子性,不提供任何同步或顺序约束。适用于不需要同步的场景,例如计数器或统计信息。
std::atomic<int> x(0);
x.store(42, std::memory_order_relaxed); // 仅保证原子性memory_order_consume:限制较弱的内存顺序,仅保证依赖于当前加载操作的数据的可见性。通常用于数据依赖的场景,实际使用较少。
std::atomic<int*> ptr(nullptr);
int* p = ptr.load(std::memory_order_consume);
if (p) {
int value = *p; // 保证 p 指向的数据是可见的
}memory_order_acquire:保证当前操作之前的所有读写操作(在当前线程中)不会被重排序到当前操作之后。通常用于加载操作,适用于实现锁或同步机制中的“获取”操作。
std::atomic<bool> flag(false);
int data = 0;
// 线程 1
data = 42;
flag.store(true, std::memory_order_release);
// 线程 2
while (!flag.load(std::memory_order_acquire)) {}
std::cout << data; // 保证看到 data = 42memory_order_release:保证当前操作之后的所有读写操作(在当前线程中)不会被重排序到当前操作之前。通常用于存储操作,适用于实现锁或同步机制中的“释放”操作。
std::atomic<bool> flag(false);
int data = 0;
// 线程 1
data = 42;
flag.store(true, std::memory_order_release); // 保证 data = 42 在 flag = true 之前可见
// 线程 2
while (!flag.load(std::memory_order_acquire)) {}
std::cout << data; // 保证看到 data = 42memory_order_acq_rel:结合了 memory_order_acquire 和 memory_order_release 的语义,适用于读 - 修改 - 写操作(如 fetch_add 或 compare_exchange_strong),用于需要同时实现“获取”和“释放”语义的操作。
std::atomic<int> x(0);
x.fetch_add(1, std::memory_order_acq_rel); // 保证前后的操作不会被重排序memory_order_seq_cst:最严格的内存顺序,保证所有线程看到的操作顺序是一致的(全局顺序一致性)。默认的内存顺序,适用于需要强一致性的场景,但性能开销较大。
std::atomic<int> x(0);
x.store(42, std::memory_order_seq_cst); // 全局顺序一致性
int value = x.load(std::memory_order_seq_cst);内存顺序的关系:
-
宽松到严格:
memory_order_relaxed < memory_order_consume < memory_order_acquire < memory_order_release < memory_order_acq_rel < memory_order_seq_cst。 -
宽松的内存顺序(如
memory_order_relaxed)性能最好,但同步语义最弱;严格的内存顺序(如memory_order_seq_cst)性能最差,但同步语义最强。
| 内存顺序 | 适用操作 | 语义描述 |
|---|---|---|
| memory_order_relaxed | 任意操作 | 仅保证原子性,无同步或顺序约束。 |
| memory_order_consume | 加载操作 | 保证依赖链的可见性,实际使用较少。 |
| memory_order_acquire | 加载操作 | 保证当前操作之前的读写不会被重排序到之后。 |
| memory_order_release | 存储操作 | 保证当前操作之后的读写不会被重排序到之前。 |
| memory_order_acq_rel | 读-修改-写操作 | 同时具有 acquire 和 release 语义。 |
| memory_order_seq_cst | 任意操作 | 全局顺序一致性,保证所有线程看到的操作顺序一致。 |
atomic_flag
对于线程安全,我们可以通过互斥锁或者原子操作/无锁来解决,还有一种方式就是自旋锁,当然还有其他的锁,读写锁等等。
自旋锁主要对比互斥锁,都可以保证线程安全,都是加锁解锁,但是和互斥锁的区别就是:
互斥锁会在已经有线程获取到锁了,其他想要获取锁的线程进入阻塞状态,对于很小的临界区,就会有消耗,有代价!
自旋锁就是第一个线程来了往下走,第二个线程来了不进入到阻塞状态,而是在自旋,就是不断的去检查一个值,进行空转行为,不断访问锁本身的标志,不切换上下文!【自旋锁与互斥锁的区别】
但是如果临界区比较到的话,自旋锁就比较不适合了!因为会过分占用 CPU !
-
特性:
atomic_flag是一种原子布尔类型,与所有 atomic 的特化不同,它保证是免锁的。与atomic<bool>不同,atomic_flag不提供加载或存储操作,主要提供test_and_set操作将 flag 原子地设置为 true 并返回之前的值,clear原子地将 flag 设置为 false。 -
示例:使用
atomic_flag实现自旋锁。#include <atomic> #include <iostream> #include <thread> #include <vector> using namespace std; atomic<int> acnt; int cnt; void Add1(atomic<int>& cnt) { int old = cnt.load(); while (!atomic_compare_exchange_weak(&cnt, &old, old + 1)); } void f() { for (int n = 0; n < 100000; ++n) { ++acnt; ++cnt; } } int main() { vector<thread> pool; for (int n = 0; n < 4; ++n) pool.emplace_back(f); for (auto& e : pool) e.join(); cout << "原子计数器为 " << acnt << '\n' << "非原子计数器为 " << cnt << '\n'; return 0; }
检查类型特性
-
代码示例:
template<class T> void check() { cout << typeid(T).name() << endl; cout << std::is_trivially_copyable<T>::value << endl; cout << std::is_copy_constructible<T>::value << endl; cout << std::is_move_constructible<T>::value << endl; cout << std::is_copy_assignable<T>::value << endl; cout << std::is_move_assignable<T>::value << endl; cout << std::is_same<T, typename std::remove_cv<T>::type>::value << endl << endl; }
atomic::compare_exchange_weak 示例
-
代码示例:
#include <iostream> // std::cout #include <atomic> // std::atomic #include <thread> // std::thread #include <vector> // std::vector struct Node { int value; Node* next; }; std::atomic<Node*> list_head(nullptr); void append(int val, int n) { for (int i = 0; i < n; i++) { Node* oldHead = list_head; Node* newNode = new Node{ val+i,oldHead }; while (!list_head.compare_exchange_weak(oldHead, newNode)) newNode->next = oldHead; } } int main() { vector<thread> threads; threads.emplace_back(append, 0, 10); threads.emplace_back(append, 20, 10); threads.emplace_back(append, 30, 10); threads.emplace_back(append, 40, 10); for (auto& th : threads) th.join(); for (Node* it = list_head; it != nullptr; it = it->next) cout << ' ' << it->value; cout << '\n'; Node* it; while (it = list_head) { list_head = it->next; delete it; } return 0; }
锁与无锁栈的性能对比
-
代码示例:
#include <iostream> // 包含 std::cout #include <atomic> // 包含 std::atomic #include <thread> // 包含 std::thread #include <mutex> // 包含 std::mutex #include <vector> // 包含 std::vector #include <ctime> // 包含 clock 函数 // 定义一个通用的链表节点模板 template<typename T> struct node { T data; // 节点存储的数据 node* next; // 指向下一个节点的指针 node(const T& data) : data(data), next(nullptr) {} // 构造函数 }; // 无锁栈的命名空间 namespace lock_free { // 无锁栈模板类 template<typename T> class stack { public: std::atomic<node<T>*> head = nullptr; // 使用原子操作的头指针 public: // 向栈中压入数据 void push(const T& data) { node<T>* new_node = new node<T>(data); // 创建一个新节点 // 将 head 的当前值放到 new_node->next 中 new_node->next = head.load(std::memory_order_relaxed); // 现在令 new_node 为新的 head ,但如果 head 不再是 // 存储于 new_node->next 的值(某些其他线程必须在刚才插入结点) // 那么将新的 head 放到 new_node->next 中并再尝试 while (!head.compare_exchange_weak(new_node->next, new_node, std::memory_order_release, // 成功时的内存顺序 std::memory_order_relaxed)) // 失败时的内存顺序 ; // 循环体为空 // 成功失败使用的模型相对应是有要求的: failure 强于 success 是未定义的! } }; } // 有锁栈的命名空间 namespace lock { // 有锁栈模板类 template<typename T> class stack { public: node<T>* head = nullptr; // 普通的头指针 // 向栈中压入数据 void push(const T& data) { node<T>* new_node = new node<T>(data); // 创建一个新节点 new_node->next = head; // 新节点指向当前的头节点 head = new_node; // 更新头节点为新节点 } }; } int main() { // 创建无锁栈和有锁栈实例 lock_free::stack<int> st1; lock::stack<int> st2; std::mutex mtx; // 用于有锁栈的互斥锁 int n = 1000000; // 每个线程要插入的数据量 // 无锁栈的线程任务 auto lock_free_stack = [&st1, n] { for (size_t i = 0; i < n; i++) // 插入 n 个数据 { st1.push(i); // 使用无锁方式压入数据 } }; // 有锁栈的线程任务 auto lock_stack = [&st2, &mtx, n] { for (size_t i = 0; i < n; i++) // 插入 n 个数据 { std::lock_guard<std::mutex> lock(mtx); // 加锁 st2.push(i); // 使用有锁方式压入数据 } }; // 4个线程分别使用无锁方式和有锁方式插入n个数据到栈中对比性能 size_t begin1 = clock(); // 记录无锁栈操作的开始时间 std::vector<std::thread> threads1; for (size_t i = 0; i < 4; i++) // 创建 4 个线程 { threads1.emplace_back(lock_free_stack); // 启动线程,使用无锁栈 } for (auto& th : threads1) th.join(); // 等待所有线程完成 size_t end1 = clock(); // 记录无锁栈操作的结束时间 std::cout << end1 - begin1 << std::endl; // 输出无锁栈操作的耗时 size_t begin2 = clock(); // 记录有锁栈操作的开始时间 std::vector<std::thread> threads2; for (size_t i = 0; i < 4; i++) // 创建 4 个线程 { threads2.emplace_back(lock_stack); // 启动线程,使用有锁栈 } for (auto& th : threads2) th.join(); // 等待所有线程完成 size_t end2 = clock(); // 记录有锁栈操作的结束时间 std::cout << end2 - begin2 << std::endl; // 输出有锁栈操作的耗时 return 0; }
自旋锁示例
-
代码示例:
#include <atomic> // 包含 std::atomic 和 std::atomic_flag #include <thread> // 包含 std::thread #include <iostream> // 包含 std::cout #include <vector> // 包含 std::vector // 自旋锁(SpinLock)是一种忙等待的锁机制,适用于锁持有时间非常短的场景。 // 在多线程编程中,当一个线程尝试获取已被其他线程持有的锁时,自旋锁会让该 // 线程在循环中不断检查锁是否可用,而不是进入睡眠状态。这种方式可以减少上 // 下文切换的开销,但在锁竞争激烈或锁持有时间较长的情况下,会导致CPU资源的浪费。 // 以下是使用C++11实现的一个简单自旋锁示例: class SpinLock { private: // ATOMIC_FLAG_INIT默认初始化为false std::atomic_flag flag = ATOMIC_FLAG_INIT; // 原子标志,用于表示锁的状态 public: // 尝试获取锁 void lock() { // test_and_set将内部值设置为true,并且返回之前的值 // 第一个进来的线程将值原子地设置为true,返回false // 后面进来的线程将原子的值设置为true,返回true,所以卡在这里空转, // 直到第一个进去的线程unlock,clear,将值设置为false while (flag.test_and_set(std::memory_order_acquire)); // 使用 acquire 顺序保证获取锁时的内存可见性 } // 释放锁 void unlock() { // clear将值原子地设置为false flag.clear(std::memory_order_release); // 使用 release 顺序保证释放锁时的内存可见性 } }; // 测试自旋锁的工作线程函数 void worker(SpinLock& lock, int& sharedValue) { lock.lock(); // 尝试获取锁 // 模拟一些工作 for (int i = 0; i < 1000000; ++i) { ++sharedValue; // 对共享变量进行操作 } lock.unlock(); // 释放锁 } int main() { SpinLock lock; // 创建一个自旋锁实例 int sharedValue = 0; // 定义一个共享变量 std::vector<std::thread> threads; // 用于存储线程的容器 // 创建多个线程 for (int i = 0; i < 4; ++i) { threads.emplace_back(worker, std::ref(lock), std::ref(sharedValue)); // 启动线程,传入自旋锁和共享变量 } // 等待所有线程完成 for (auto& thread : threads) { thread.join(); // 等待每个线程结束 } std::cout << "Final shared value: " << sharedValue << std::endl; // 输出最终的共享变量值 return 0; }
测试的时候请在 realease 下进行测试!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 34
34 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)