EvoDriveVLA:通过协同感知-规划提炼演进的自动驾驶VLA模型
26年3月来自北大和小鹏汽车的论文“EvoDriveVLA: Evolving Autonomous Driving Vision–Language–Action Model via Collaborative Perception-Planning Distillation”。
视觉-语言-动作模型在自动驾驶领域展现出巨大的潜力,但它们在解冻视觉编码器后会面临感知能力下降的问题,并且在长期规划中也难以克服累积不稳定性。为了应对这些挑战,提出EvoDriveVLA——一种协同感知-规划提炼框架,它融合自-锚定感知约束和预言机-引导的轨迹优化。具体而言,自-锚定视觉提炼利用自-锚定教师模型来提供视觉锚定约束,并通过轨迹引导的关键区域-觉察来规范学生模型的表征。同时,预言机-引导的轨迹提炼采用一种具有未来-觉察能力的预言机教师模型,结合由粗到精的轨迹优化和蒙特卡罗dropout采样来生成高质量的轨迹候选,从而选择最优轨迹来指导学生模型的预测。
作为提升自动驾驶系统性能的关键技术,知识蒸馏(Hinton et al., 2015)在近期的研究中获得了显著关注。现有的知识蒸馏方法可分为单-轨迹蒸馏和多-轨迹蒸馏。以DiMA(Hegde et al., 2025)为代表的单-轨迹方法,直接使用教师模型预测的轨迹来指导学习者。相比之下,多-轨迹方法,例如DistilDrive(Yu et al., 2025),通过构建规划词汇表来鼓励教师生成多样化的轨迹输出,旨在通过结构化的轨迹候选来丰富知识蒸馏过程中的规划知识,并缓解依赖单一轨迹所导致的表达能力有限和场景适应性差的问题。
如图所示:现有自动驾驶知识蒸馏范式的比较。(a) 单-轨迹蒸馏;(b) 多-轨迹蒸馏;©本文的协同感知-规划蒸馏。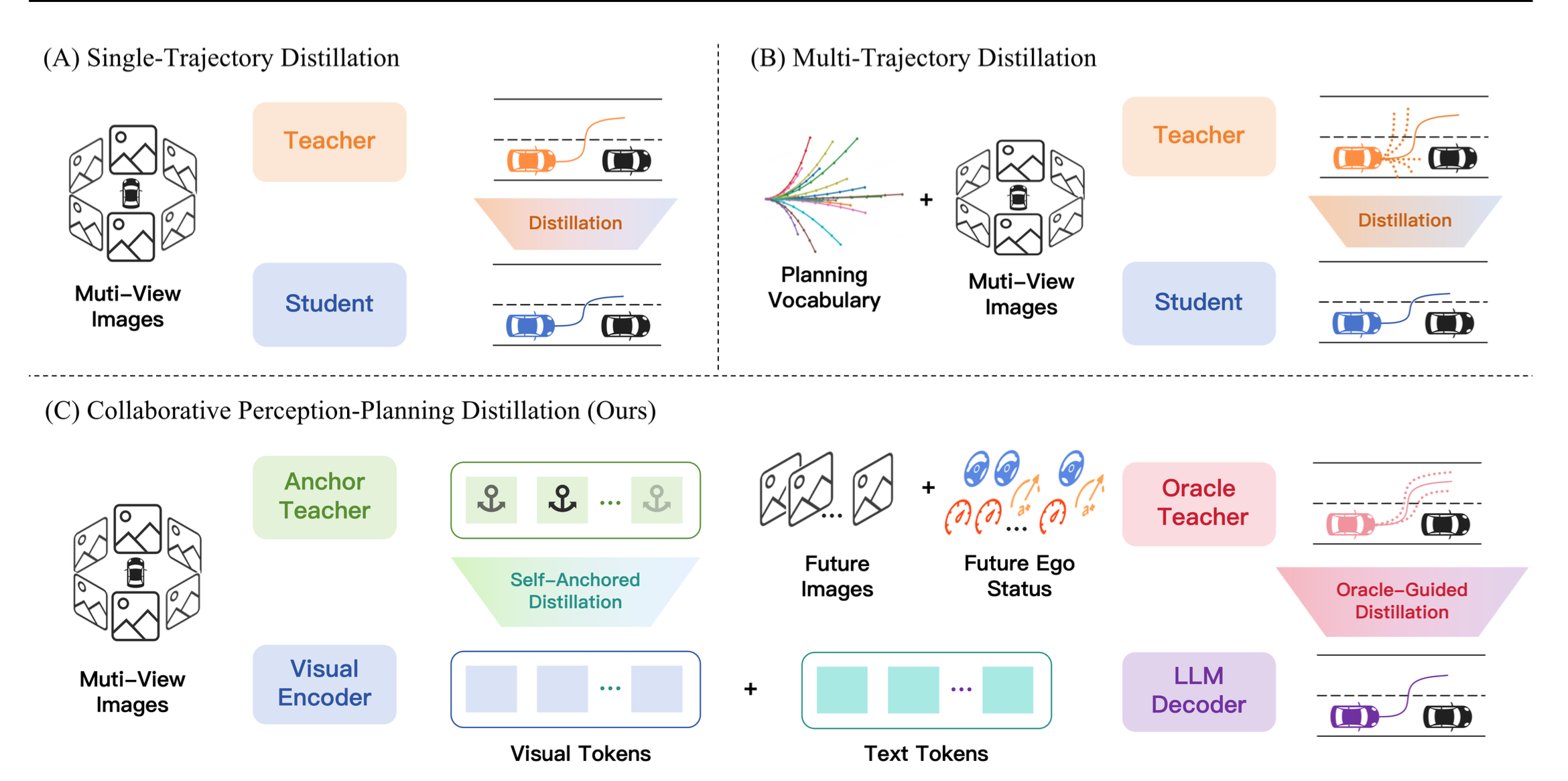
如图所示,本文提出的框架由“自-锚定视觉蒸馏”和“预言机-引导的轨迹蒸馏”组成,旨在协同增强视觉表征和轨迹预测。具体而言,在感知蒸馏层面,引入自-锚定教师模型来提供视觉锚定约束,防止视觉编码器在解冻后丢失其预训练的表征能力。同时,集成轨迹引导的注意机制,以对关键感知区域施加更强的锚定约束。在规划蒸馏层面,通过融合特权信息(包括未来场景图像和自我状态)构建一个面向未来的预言机教师模型,从而赋予该教师模型更高的轨迹预测精度。此外,还采用一种由粗到精的轨迹优化策略,并结合蒙特卡罗丢弃 (MC-Dropout) 采样,为每个场景生成一组多样化的高质量轨迹候选集。随后,选择最优轨迹作为蒸馏的软目标,从而在多模态推理和运动预测中实现更精细的知识迁移。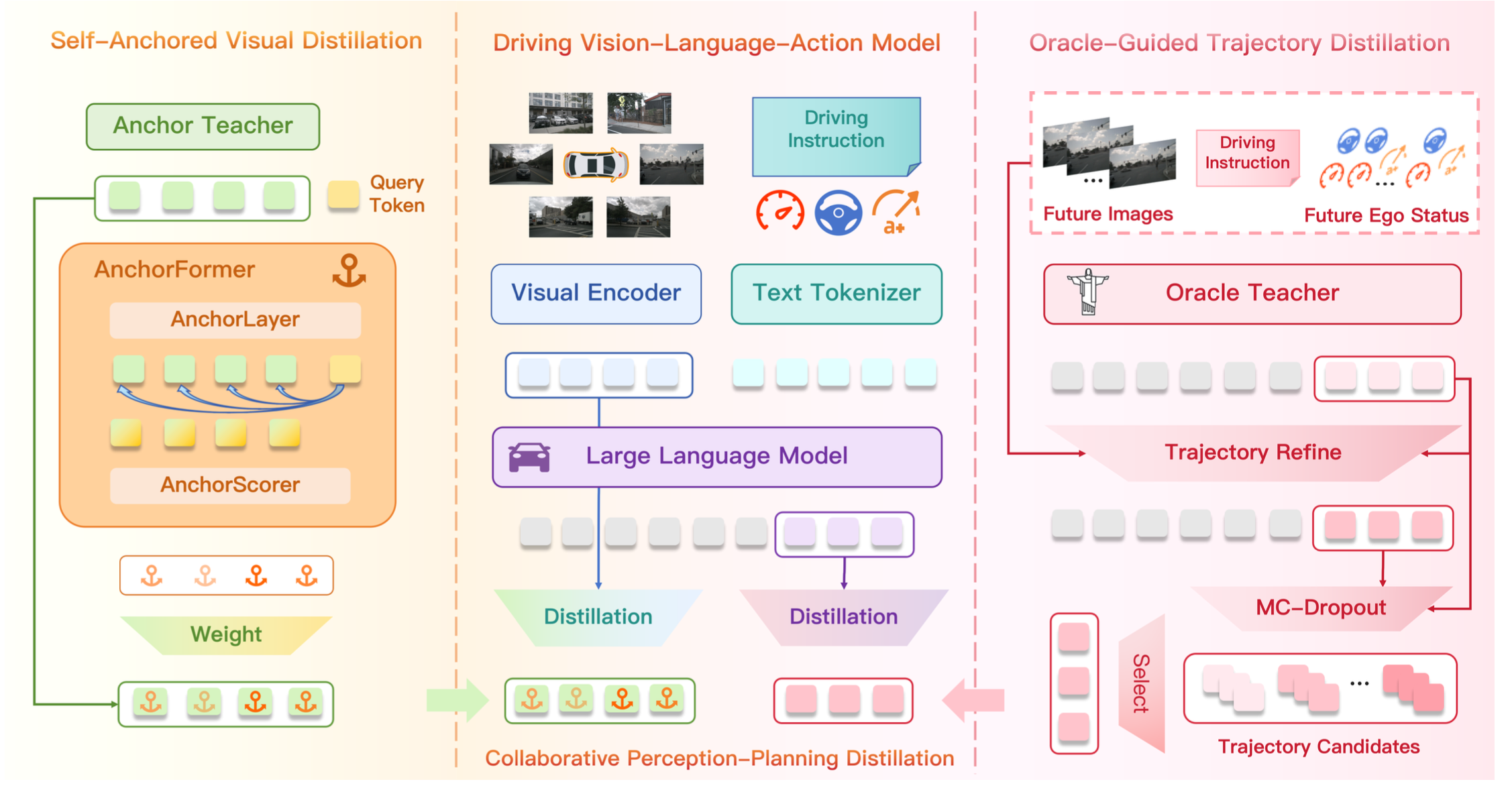
自锚式视觉蒸馏
视觉-语言模型 (VLM) 研究中一个长期存在的问题是,在监督式微调 (SFT) 阶段是否应该对视觉编码器进行完全微调。一些研究(Tong ,2024;Shi ,2024)认为,解冻视觉编码器有助于跨域适应,并改善在新领域或下游任务中的视觉感知。相反,其他研究(Karamcheti et al., 2024; Kachaev et al., 2025)表明,直接微调视觉编码器可能会降低大规模预训练期间学习的通用视觉表征,导致感知鲁棒性降低和对训练数据集过拟合,从而损害模型的泛化能力。因此,提出这样一个问题:如何在保持视觉编码器原有感知能力的同时,增强自动驾驶场景中与任务相关的视觉感知?
轨迹引导的锚定约束。为了解决视觉编码器在监督微调过程中面临的退化-适应困境,提出一种自-锚定视觉蒸馏方法。具体来说,在微调之前复制学生视觉编码器,从而创建一个自-锚定教师模型。在训练过程中,该自锚定教师模型生成的稳定视觉表征被用作蒸馏约束,确保学生视觉编码器在增强其在自动驾驶场景下的-感知能力的同时,保持其原有的视觉表征能力。与传统的样本级锚定蒸馏方法(Tang et al., 2024)不同,通过引入轨迹引导的token级锚定蒸馏进一步提高粒度。为此,设计 AnchorFormer,它为场景中的不同空间区域分配自适应的锚定权重,权重越高,表示这些区域的锚定约束越强。
AnchorFormer架构。AnchorFormer由AnchorLayer和AnchorScorer组成。AnchorLayer采用与单个LLM解码器层相同的架构,而AnchorScorer则实现为单个线性层。给定多视图图像I_t,自-锚教师和学生视觉编码器分别生成视觉tokens ztea_v和zstu_v。文本指令提示P_t、车辆自身状态S_t和真实未来路径点W∗_t被编码为token 表示z_p、z_s和z_w∗。
为了使自-锚教师能够根据指令、车辆自身状态和未来轨迹为视觉token分配自适应锚定权重,引入一组可学习的查询tokenq。这些token与观测 token z_o = [ztea_v, z_p, z_s] 和轨迹token z_w∗ 连接起来,然后输入到 AnchorLayer。
通过将 AnchorScorer 应用于更新后的视觉token z̃t_v 和查询token q̃ 之间的 Hadamard 乘积来计算token级锚点得分。随后,通过温度缩放的 sigmoid 归一化获得锚点权重。
视觉蒸馏损失。采用均方误差 (MSE) 损失来约束学生的视觉token zstu_v 与自锚定教师的视觉token ztea_v,并由token级锚点权重 W_a 加权。由此得到的自锚定蒸馏损失定义为 L_a。
基于预言机(Oracle)的轨迹蒸馏
未来-觉察的预言机教师。在知识蒸馏中,教师模型在引导学生模型更快地收敛和提升性能方面起着决定性作用。因此,识别一个更强大的教师模型对于自动驾驶中的蒸馏至关重要。然而,现有方法要么直接采用更大规模的视觉-语言模型作为教师模型(Liu et al., 2025),要么在蒸馏过程中通过轨迹预测监督来联合训练教师模型(Hegde et al., 2025)。虽然后者似乎增强教师模型的轨迹预测能力,但实际上,当轨迹预测仅依赖于当前观测时,教师模型的能力与学生模型的能力本质上没有区别。因此,轨迹蒸馏的关键在于增强教师模型的轨迹预测能力。
受先前研究(Zeng et al., 2025; Li et al., 2025c)的启发,这些研究都融入未来图像预测,构建一个具备未来-觉察能力的预言教师模型。除了当前图像和自车状态外,还利用未来 T 秒的图像和自车状态对模型进行条件化。尽管使用优先的未来信息,但这种方法显著提升教师模型的预测性能,同时为学生模型保持公平的评估环境。此外,为了充分利用未来感知输入,将预言教师模型的粗略轨迹预测 Wc_t 作为附加输入,以获得更精确的轨迹 Wf_t,从而赋予模型由粗到精的渐进式轨迹细化能力。
在预言教师模型的训练过程中,采用基于采样的策略来联合优化两种轨迹建模方案。这使得模型能够同时学习粗粒度和细粒度的预测。
由粗到精的轨迹优化。将预言教师生成的粗粒度轨迹反馈给模型,以促进迭代轨迹优化。预言教师利用其对未来信息的全局感知,修正候选轨迹的时空一致性,从而生成更平滑且更符合物理规律的优化路径。这种递归的生成-优化过程有效地模拟预言指导下的轨迹演化过程。因此,为了给学生模型提供更准确的轨迹候选,将对应于粗粒度和细粒度轨迹的隐藏状态和logits分别纳入候选集S_h = {h_c, h_f} 和 S_l = {l_c, l_f}中。该策略使学生能够有效地继承优秀教师的细致纠错推理能力。
MC-Dropout轨迹采样。尽管由粗到精的轨迹细化策略能够产生相对准确的候选轨迹,但进一步旨在增强轨迹多样性,以便为学生模型提供更合理、更多样化的轨迹分布。为此,提出一种蒙特卡洛丢弃(MC-Dropout)采样策略。具体而言,对于每个隐状态h ∈ S_h,在保持模型参数不变的情况下应用N次随机dropout扰动,从而得到一组多样化的隐状态样本。
然后,将采样得到的隐状态输入到模型的lm_head,以获得相应的logits。最后,所有采样的隐状态及其对应的logits分别被纳入候选集S_h和S_l。
由于MC-Dropout仅应用于隐状态,而logits是通过轻量级的lm_head计算的,因此该策略在显著丰富候选集的同时,开销极小。
轨迹蒸馏损失。计算候选集S_l中每条轨迹的预测logits与真实轨迹之间的交叉熵损失,并选择损失最小的最优轨迹。然后,用与该最优轨迹相关的隐藏状态和logits作为软目标来蒸馏学生模型,鼓励学生模型在潜表示空间和预测分布上与理想教师模型保持一致。
本质上,这种双层对齐不仅使学生模型能够复现理想教师模型的输出,还能内化复杂轨迹细化所需的底层语义推理。
总体训练损失
学生模型的总体训练损失 L_all 是一个加权组合,由轨迹预测损失 L、自锚视觉蒸馏损失 L_a 以及预言引导轨迹蒸馏损失项 L_h 和 L_l 组成。
实验设置
实现细节。学生模型和预言教师模型均采用相同的 Qwen2.5-VL 3B (Bai et al., 2025) 架构,相应的视觉编码器用作自-锚定教师模型。此外,锚定层使用其最终 LLM 层的权重进行初始化。在蒸馏训练过程中,预言教师模型和自锚定教师模型的权重保持不变,仅对学生模型和 AnchorFormer 的参数进行主动优化。
数据集和评估。对于开环评估,用 nuScenes 基准数据集 (Caesar et al., 2020),该数据集包含 1000 个驾驶场景,每个场景持续约 20 秒。数据集根据标准数据划分分为训练集和验证集。评估协议严格遵循ST-P3(Hu,2022)和UniAD(Hu,2023)制定的设置。性能评估采用1秒、2秒和3秒间隔的L2位移误差,以及整个预测周期内的平均碰撞率。
对于闭环评估,采用NAVSIM基准测试(Dauner,2024)。数据集分为navtrain(1192个训练场景)和navtest(136个评估场景)。采用PDM评分(PDMS)作为主要评估指标,它通过几个子指标提供全面的评估:无碰撞(NC)、可行驶区域合规性(DAC)、碰撞时间(TTC)、舒适度(Comf.)和自我进度(EP)。此外,还评估并报告4秒预测周期内的规划性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)