DeepSeek豆包写的论文怎么降AI率?详细降AI率方法和工具推荐
DeepSeek豆包写的论文怎么降AI率?详细降AI率方法和工具推荐
不瞒你们说,我的毕业论文有大概60%的内容是用DeepSeek生成的。不是不想自己写,实在是时间不够——白天实习、晚上赶论文、还有两门课要考试。当时想着用DeepSeek先把框架和初稿搞出来,再自己改改润色一下就行了。
结果学校预检一出来,AI率72%。七十二啊兄弟们,几乎等于全篇都被判定为AI生成了。
这时候我才意识到,DeepSeek写的东西在知网眼里就是"AI味十足"。后来我花了几天时间研究怎么降AI率,从各种方法里筛选出了真正有用的,最终把AI率从72%降到了11%。
这篇文章就是把整个降AI率的过程和方法详细写出来,特别是针对用DeepSeek、豆包这类国产AI写的论文。
一、为什么DeepSeek/豆包写的论文AI率特别高
先说一个很多人不知道的事实:同样是用AI写论文,用DeepSeek写的内容被知网检测出来的AI率,通常比用ChatGPT写的还要高。
这不是因为DeepSeek写得差,而是因为2026年知网的AIGC检测系统专门增加了对国产大模型的特征识别。知网在自己的数据库里收录了DeepSeek、豆包、Kimi、文心一言等模型的写作特征——包括它们喜欢用的句式、偏好的连接词、段落组织方式等等。

DeepSeek论文的典型"AI特征"
我仔细对比了自己的论文和纯人工写的论文,发现DeepSeek生成的内容有几个特别明显的特征:
1. 过度使用"首先…其次…最后…"的递进结构
DeepSeek特别喜欢这种三段式展开,几乎每个论述段落都是这个模式。人类写论文虽然也会用,但不会每段都这样。
2. “值得注意的是”"需要指出的是"用得太频繁
在我3万字的论文里,"值得注意的是"出现了17次。正常人谁会在一篇文章里用17次这个表达?
3. 每段话的长度异常均匀
我数了一下,DeepSeek写的段落基本都在150-200字之间,像是一个模子里刻出来的。人写的段落有长有短,有时候一两句话就是一段。
4. 大量使用被动句和长定语
“被广泛应用于”“在很大程度上可以被认为是”“基于上述分析可以得出的结论是”——这种又臭又长的表达,AI用得特别溜。
豆包论文的情况
豆包的特征和DeepSeek类似,但豆包还有一个额外的问题:它生成的内容有时候会出现一些微妙的逻辑断层。前一段说的是A,后一段突然跳到了C,中间的B被省略了。这种断层虽然不影响AI率检测,但会影响论文质量,需要额外修补。
二、降AI率之前,先做这些准备工作
在开始用工具降AI率之前,有几件事值得先做好:
准备1:标记哪些部分是AI生成的
把你论文里AI生成的段落做个标记。这样你就知道哪些部分需要重点处理,哪些部分是自己写的可以先放一放。
准备2:备份原文
这个不用多说,处理前一定要保存一份完整的原文。我见过有人处理完之后发现不满意想恢复,结果找不到原文了。
准备3:确认学校的AI率要求
不同学校的要求不一样。有的学校要求低于15%,有的要求低于20%,还有的学校是30%。搞清楚具体要求,省得过度处理浪费钱。
准备4:把参考文献、致谢等部分单独拿出来
这些部分不需要降AI率处理,而且参考文献如果被工具改了格式会很麻烦。处理正文的时候把这些部分剔除。
三、DeepSeek论文降AI率方法一:先自己动手改一轮
纯工具处理之前,建议先自己动手做一轮初步修改,能省不少钱。
找到那些"AI味最重"的表达,直接替换
这是效率最高的手动操作。打开Word的查找替换功能:
| AI味表达 | 替换为 |
|---|---|
| 值得注意的是 | 这里有个关键点 / 我发现 / 有意思的是 |
| 需要指出的是 | 其实 / 这里要说一下 |
| 在一定程度上 | 某种意义上说 / 多少有点 |
| 与此同时 | 另一方面 / 再说 |
| 不可忽视 | 挺重要的 |
| 综上所述 | 回过头来看 / 整体看下来 |
| 具有重要意义 | 挺关键的 / 对…影响不小 |
光这一步,我的AI率就从72%降到了63%左右。虽然幅度不大,但这是零成本的操作。
打破段落的均匀性
把一些150-200字的标准段落拆开,或者把几个短段落合并。让段落长度呈现出自然的差异。
加入你自己的真实体验和观点
在关键论述段落里加入一两句你自己的思考。比如"在实际操作中我发现这个方法有个局限"“数据跑出来的时候我还挺意外的”。
四、DeepSeek论文降AI率方法二:用降AI率工具深度处理
手动改完之后,剩下的就得靠降AI率工具了。下面是三款我实际用过的工具。
嘎嘎降AI:适合第一轮全面降AI率处理
嘎嘎降AI(aigcleaner.com)支持9个检测平台,对DeepSeek生成的内容处理效果很好。
为什么推荐它做第一轮:
DeepSeek写的论文AI率通常很高(50%以上),需要先做一轮大幅度的降AI率处理。嘎嘎降AI的优势就是降幅大,能一次性把AI率砍掉30-50个百分点。而且它有1000字免费试用,你可以先把AI率最高的一段话丢进去看看效果。
我的实际操作:
- 先用1000字免费额度测试了文献综述部分(这部分AI率最高)
- 效果不错,文本通顺度保持得很好
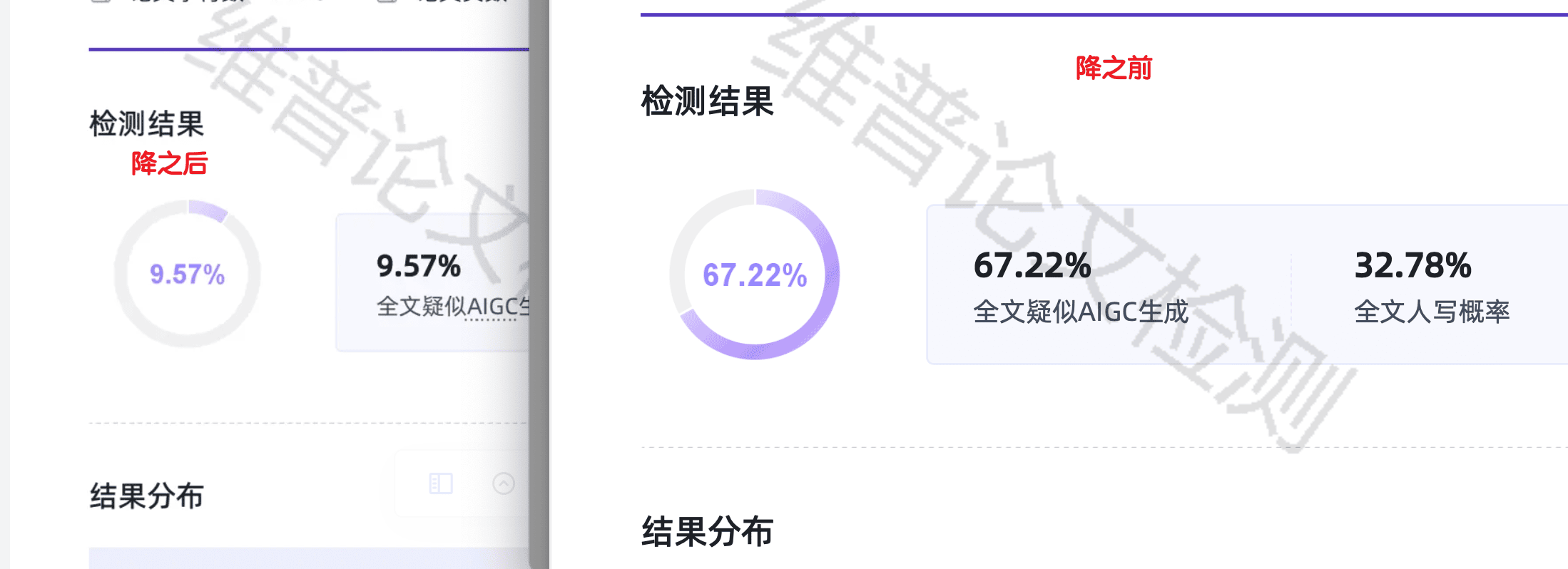
- 充值后处理了全文,选择知网检测模式
- 处理后知网AI率从63%降到了24%
比话降AI:专攻知网的降AI率利器
嘎嘎降AI第一轮处理后AI率还有24%,知网要求15%以下,还差一截。这时候用比话降AI(bihua.com)来做精细化降AI率处理。
比话是专门针对知网AIGC检测算法做优化的,对于DeepSeek生成内容的知网检测特征有很深的理解。
操作很简单:
- 把嘎嘎降AI处理后的文本粘贴到比话
- 选择知网模式提交
- 等大约半小时收到结果
效果:知网AI率从24%降到了11%。
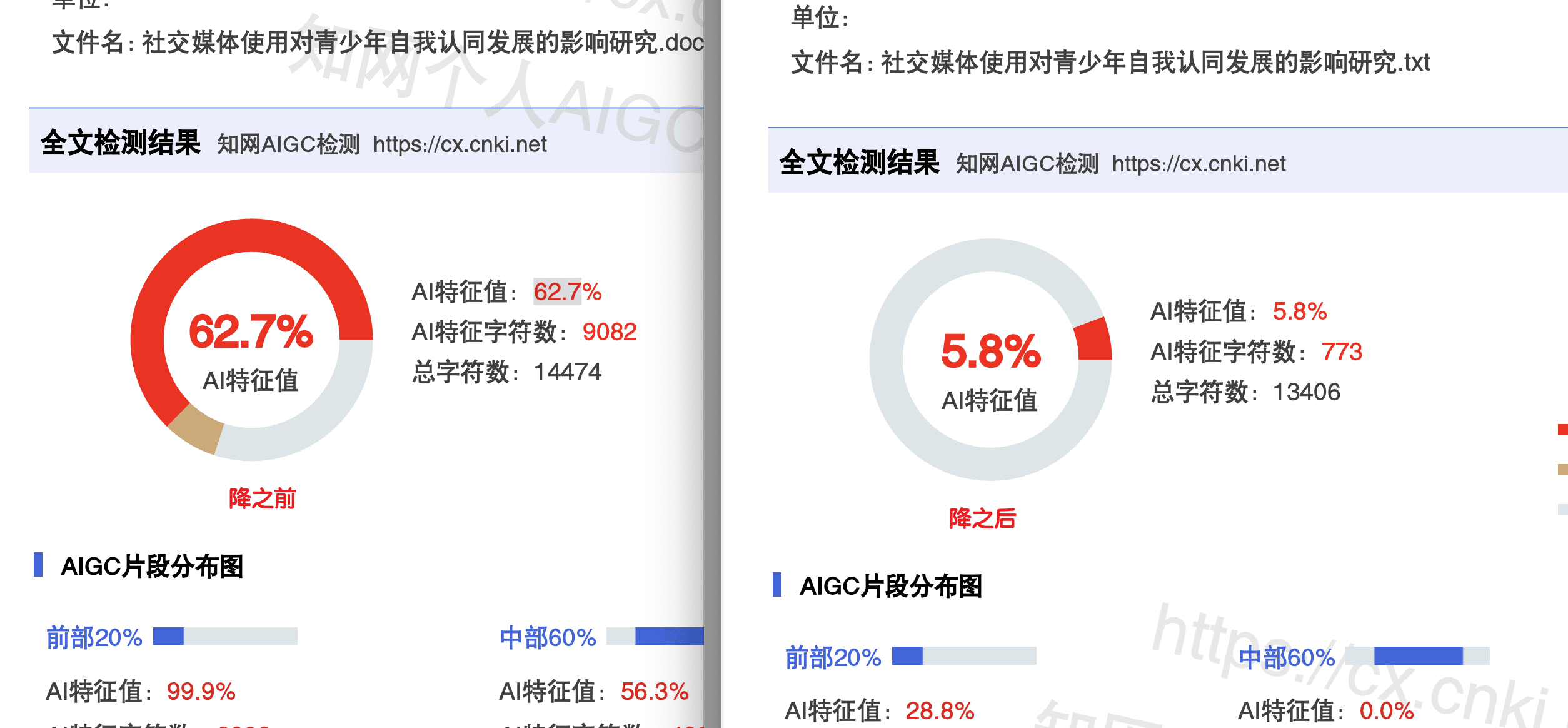
比话的定价是8元/千字,3万字论文大概240元。有人可能觉得贵,但它有个别家没有的承诺:处理后AI率>15%全额退款+赔检测费。等于说你花的钱是有保障的,不满意可以退。
另外比话支持10万字/篇、7天内无限修改,对于论文要反复修改的情况很友好。
率零:预算紧张的同学用这个
率零(lv0.cn)的免费额度比较多,适合两种情况:一是预算有限的同学,二是AI率不算太高只需要处理几个段落的情况。

我用率零处理了几段维普检测AI率较高的段落,效果还行,虽然没有嘎嘎降AI和比话那么精准,但考虑到是免费的,已经很不错了。
五、DeepSeek/豆包论文降AI率的完整操作顺序
根据我的实战经验,推荐这个操作顺序:
第1步(30分钟):用Word查找替换功能,把论文里的高频AI味表达批量替换掉。预期降幅5-10个百分点。
第2步(1小时):手动调整几个AI率最高的段落——打乱句式、加入个人表达、调整段落长度。预期再降5-10个百分点。
第3步(20分钟):用嘎嘎降AI做第一轮全面处理。预期降AI率30-40个百分点。
第4步(30分钟):如果需要过知网,用比话降AI做针对性优化。预期再降10-15个百分点。
第5步(20分钟):如果还有个别段落AI率偏高,用率零免费额度处理。
第6步(2小时):自己通读全文,修正专业术语、检查逻辑、补充个人观点。
第7步:复检确认AI率达标。
按照这个流程走下来,DeepSeek/豆包写的论文基本都能降到15%以下。
六、特别注意:DeepSeek论文降AI率后的质量检查
DeepSeek和豆包生成的内容有一个问题:降AI率处理后,有些学术表达可能会被改得不太专业。我列几个常见的情况:
- “回归分析"被改成了"回头分析”
- “显著性水平"被改成了"明显程度”
- “相关系数"被改成了"关联数值”
- “控制变量"被改成了"管理要素”
处理完之后一定要仔细检查这些专业术语,一个个改回来。这个步骤虽然繁琐但不能省,否则答辩的时候被导师发现了会很尴尬。
另外,DeepSeek生成的论文里经常会有一些"看起来很专业但其实是瞎编的"内容——比如引用了一篇实际上不存在的文献,或者编造了一个看似合理的数据。降AI率工具不会帮你核实这些内容的真实性,需要你自己把关。
七、最后说几句
用AI写论文这事,现在基本是公开的秘密了。但"用了AI"和"论文质量差"之间不能画等号。关键是你怎么用、用完之后怎么打磨。
降AI率的本质不是弄虚作假,而是让你的论文在表达方式上更像"人类写作"。毕竟检测算法也不是完美的,很多自己写的内容也会被误判。
工具推荐方面:嘎嘎降AI做第一轮全面处理,比话降AI做知网精细化降AI率优化,率零补充处理个别段落。 这三款搭配使用,基本能搞定绝大部分情况。
希望这篇降AI率攻略对你有帮助,加油!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献539条内容
已为社区贡献539条内容

所有评论(0)