C语言的三大法宝:链表+结构体+函数指针
目录
1.结构体里塞函数指针:C语言的"类"
这就是 C 语言模拟面向对象最核心、最本质的底层逻辑,没有之一。
终极公式:
结构体(数据) + 函数指针(方法) = C 语言手写类逐行对应 C++ 类
| 组成部分 | C 语言写法 | C++ 类写法 |
|---|---|---|
| 属性 / 数据 | 结构体普通变量 | 类成员变量 |
| 行为 / 方法 | 结构体内部函数指针 | 类成员函数 |
| this 指针 | 方法第一个参数传结构体* |
编译器自动生成 |
| 封装 | static+ 头文件分离 |
private关键字 |
示例如下:
/* 定义一套"接口规范" */
typedef struct {
int (*open)(void *dev);
int (*read)(void *dev, uint8_t *buf, int len);
int (*write)(void *dev, const uint8_t *buf, int len);
void (*close)(void *dev);
} driver_ops_t;
/* 串口驱动的"实现" */
static int uart_open(void *dev) { /* 初始化串口硬件 */ return 0; }
static int uart_read(void *dev, uint8_t *buf, int len) { /* 从FIFO读 */ return len; }
static int uart_write(void *dev, const uint8_t *buf, int len) { /* 写TX寄存器 */ return len; }
static void uart_close(void *dev) { /* 关闭串口时钟 */ }
/* 把函数"注册"进结构体 */
driver_ops_t uart_ops = {
.open = uart_open,
.read = uart_read,
.write = uart_write,
.close = uart_close,
};上层代码调用时完全不关心底层是串口还是SPI:
void app_send_data(driver_ops_t *ops, void *dev, uint8_t *data, int len)
{
ops->open(dev);
ops->write(dev, data, len);
ops->close(dev);
}一句话总结:结构体是骨架,函数指针是关节。有了关节,骨架才能动。
2.侵入式链表:一套链表管遍所有结构体
教科书上的链表长这样:节点里放数据。听起来没毛病,但实际用起来你会发现——每种数据类型都得重写一遍链表操作。任务管理一套链表,定时器管理又一套链表,内存池还得再来一套。Linux内核的做法是反过来的:不是链表包含数据,而是数据包含链表。
只定义一个通用链表节点,不跟任何数据绑定:
// 万能链表节点,只关心前后,不关心数据
struct list_head {
struct list_head *prev;
struct list_head *next;
};然后把它塞进你的业务结构体里:
// 定时器结构体
typedef struct Timer {
int timeout;
// 同样内嵌
struct list_head node;
} Timer;
/* 任务结构体,链表节点是它的"一个零件" */
typedef struct {
char name[16];
int priority;
list_node_t node; /* 嵌入链表节点 */
} task_t;链表增删改查,只操作 struct list_head,不管是 Task、Timer、Socket、MemBlock,全都通用。
这时候关键来了:怎么从链表节点反推出宿主结构体的地址?
答案就是大名鼎鼎的 container_of 宏:
#define container_of(ptr, type, member) \
((type *)((char *)(ptr) - offsetof(type, member)))内存布局示意图:
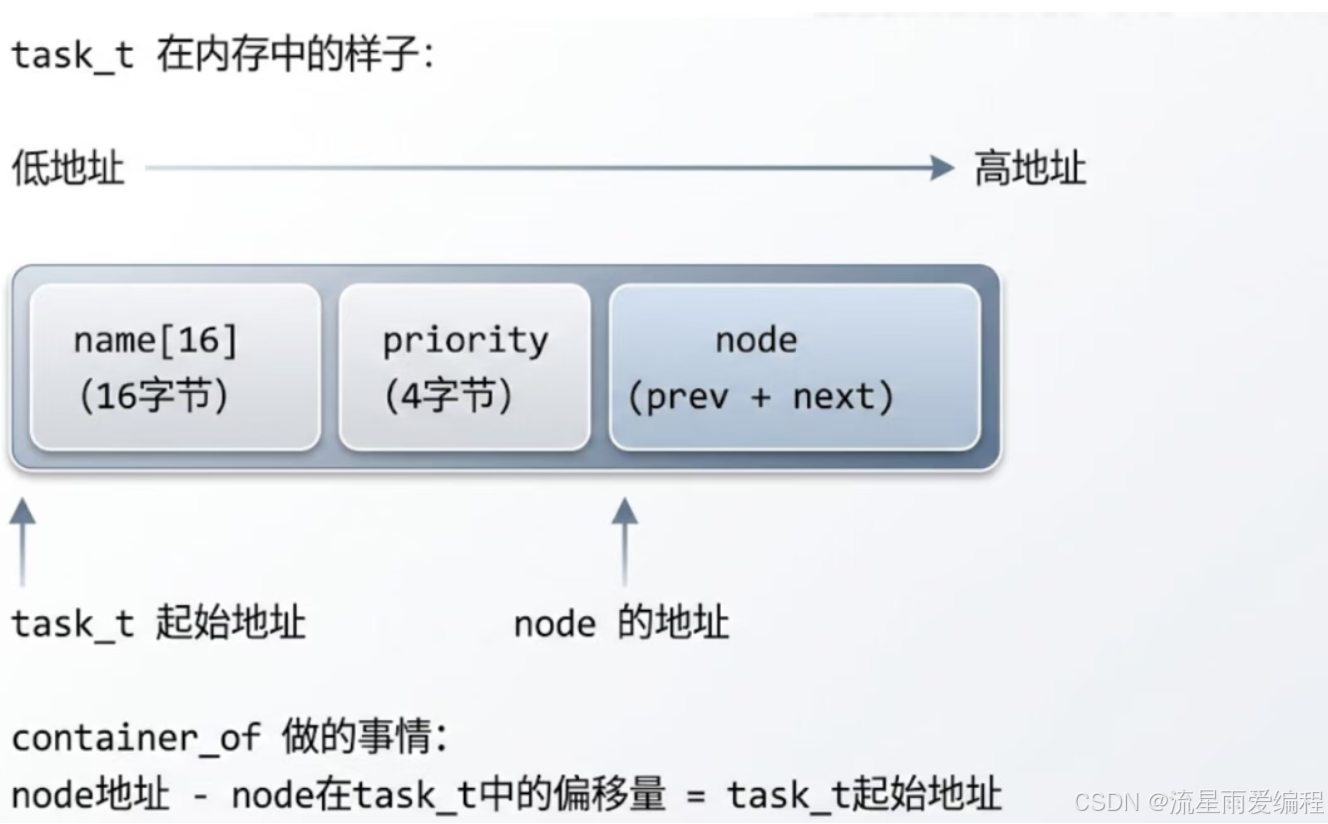
这样一来,所有的链表插入、删除、遍历操作只写一套,通过 container_of 就能操作任何结构体。
/* 通用的链表插入,跟数据类型完全无关 */
void list_add(list_node_t *head, list_node_t *new_node)
{
new_node->next = head->next;
new_node->prev = head;
head->next->prev = new_node;
head->next = new_node;
}
/* 遍历时拿回宿主结构体 */
task_t *task;
list_node_t *pos;
for (pos = head.next; pos != &head; pos = pos->next) {
task = container_of(pos, task_t, node);
printf("任务: %s, 优先级: %d\n", task->name, task->priority);
}为什么这招厉害? 因为同一个结构体甚至可以挂到多条链表上——加两个 list_node_t 成员就行。任务既在就绪队列里,又在定时等待队列里,互不干扰。
3.经典的解耦设计: 通知链机制
用侵入式链表管理一堆「函数指针(回调)」,事件触发时,遍历链表调用所有回调
- 链表:管注册 / 注销节点
- 函数指针:管事件处理逻辑(C 语言类的方法)
- 通知链:管事件分发
先看整体结构:
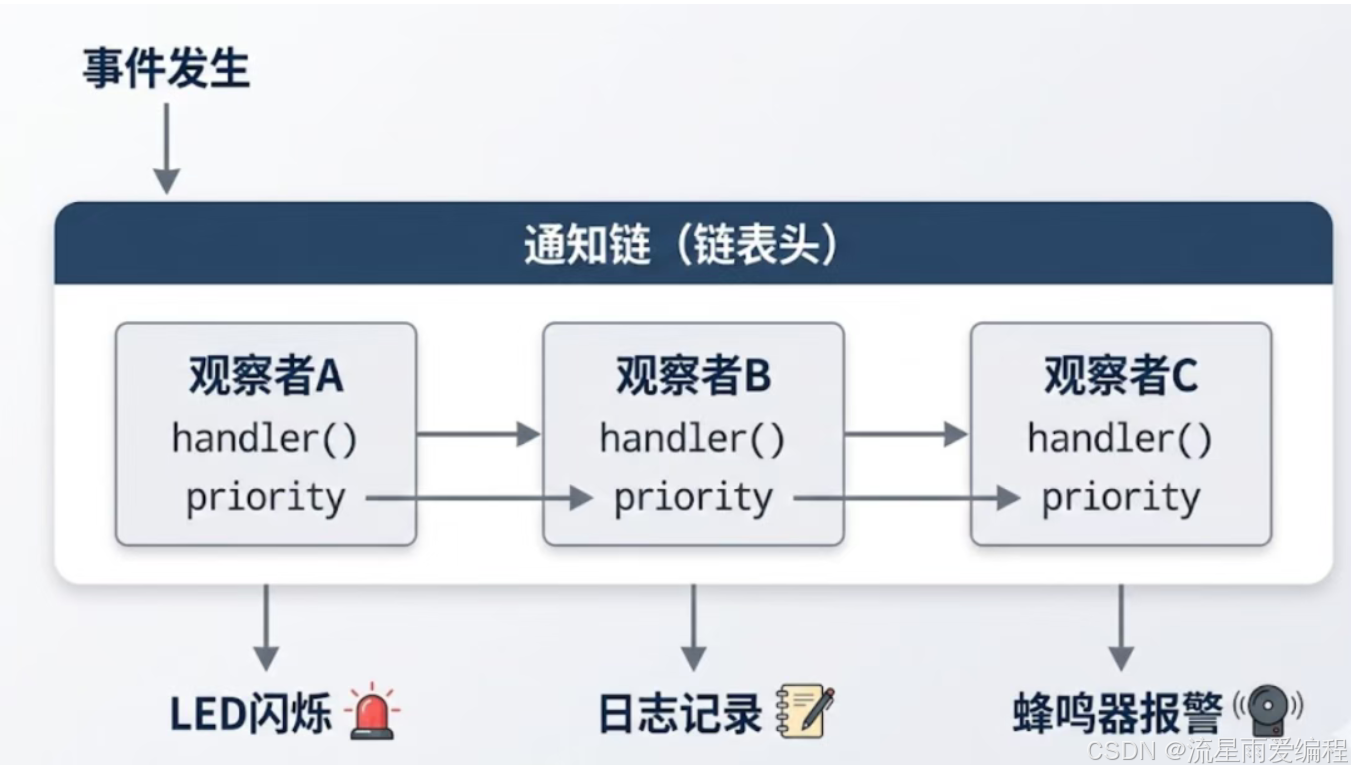
实现代码:
/* 通知链节点:结构体 + 函数指针 + 链表,三件套齐了 */
typedef struct notifier_node {
int (*handler)(int event, void *data); /* 函数指针:回调 */
int priority; /* 优先级 */
list_node_t node; /* 链表节点 */
} notifier_node_t;
/* 通知链头 */
typedef struct {
list_node_t head;
} notifier_chain_t;
/* 初始化通知链 */
void notifier_chain_init(notifier_chain_t *chain)
{
chain->head.next = &chain->head;
chain->head.prev = &chain->head;
}
/* 注册观察者(按优先级插入) */
void notifier_register(notifier_chain_t *chain, notifier_node_t *n)
{
list_node_t *pos;
notifier_node_t *entry;
/* 找到第一个优先级比自己低的,插在它前面 */
for (pos = chain->head.next; pos != &chain->head; pos = pos->next) {
entry = container_of(pos, notifier_node_t, node);
if (entry->priority < n->priority)
break;
}
/* 插到pos前面 */
n->node.next = pos;
n->node.prev = pos->prev;
pos->prev->next = &n->node;
pos->prev = &n->node;
}
/* 发送通知:遍历链表,依次调用每个handler */
void notifier_call(notifier_chain_t *chain, int event, void *data)
{
list_node_t *pos;
notifier_node_t *entry;
for (pos = chain->head.next; pos != &chain->head; pos = pos->next) {
entry = container_of(pos, notifier_node_t, node);
if (entry->handler(event, data) != 0)
break; /* handler返回非0表示"到此为止,别往下传了" */
}
}使用起来非常清爽:
/* 各模块各管各的,互相不知道对方存在 */
static int led_handler(int event, void *data)
{
if (event == EVT_ERROR) led_blink(RED);
return 0; /* 继续传递 */
}
static int log_handler(int event, void *data)
{
printf("[LOG] event=%d\n", event);
return 0;
}
/* 注册 */
notifier_node_t led_notifier = { .handler = led_handler, .priority = 10 };
notifier_node_t log_notifier = { .handler = log_handler, .priority = 5 };
notifier_register(&error_chain, &led_notifier);
notifier_register(&error_chain, &log_notifier);
/* 某处发生错误,一行代码通知所有人 */
notifier_call(&error_chain, EVT_ERROR, NULL);看到没?添加新的处理模块不需要改任何已有代码,只要自己注册一下就完事了。这就是三件套带来的解耦能力。
4.函数指针数组 + 结构体:表驱动状态机
写嵌入式跑不掉状态机。很多人的状态机长这样:
switch (state) {
case STATE_IDLE: do_idle(); break;
case STATE_START: do_start(); break;
case STATE_RUN: do_run(); break;
case STATE_STOP: do_stop(); break;
// ... 20个state以后你就不想维护了
}状态少的时候没问题,一旦状态多了、转换条件复杂了,这个 switch 就是一场灾难。
更好的做法是用结构体数组来描述状态转换表:
typedef enum { S_IDLE, S_START, S_RUN, S_STOP, S_MAX } state_e;
typedef enum { E_BEGIN, E_DONE, E_ERROR, E_MAX } event_e;
/* 状态转换表的每一行 */
typedef struct {
state_e current;
event_e event;
state_e next;
void (*action)(void *ctx); /* 转换时执行的动作 */
} transition_t;
/* 把状态机逻辑变成一张"表" */
transition_t trans_table[] = {
/* 当前状态 事件 下一状态 动作 */
{ S_IDLE, E_BEGIN, S_START, action_init },
{ S_START, E_DONE, S_RUN, action_run },
{ S_RUN, E_DONE, S_STOP, action_stop },
{ S_RUN, E_ERROR, S_IDLE, action_reset },
{ S_STOP, E_DONE, S_IDLE, action_clean },
};状态机引擎就这么几行:
void fsm_handle_event(state_e *state, event_e event, void *ctx)
{
int n = sizeof(trans_table) / sizeof(trans_table[0]);
for (int i = 0; i < n; i++) {
if (trans_table[i].current == *state &&
trans_table[i].event == event) {
trans_table[i].action(ctx); /* 执行动作 */
*state = trans_table[i].next; /* 切换状态 */
return;
}
}
/* 没有匹配的转换,可以加默认处理 */
}用图来理解更清楚:
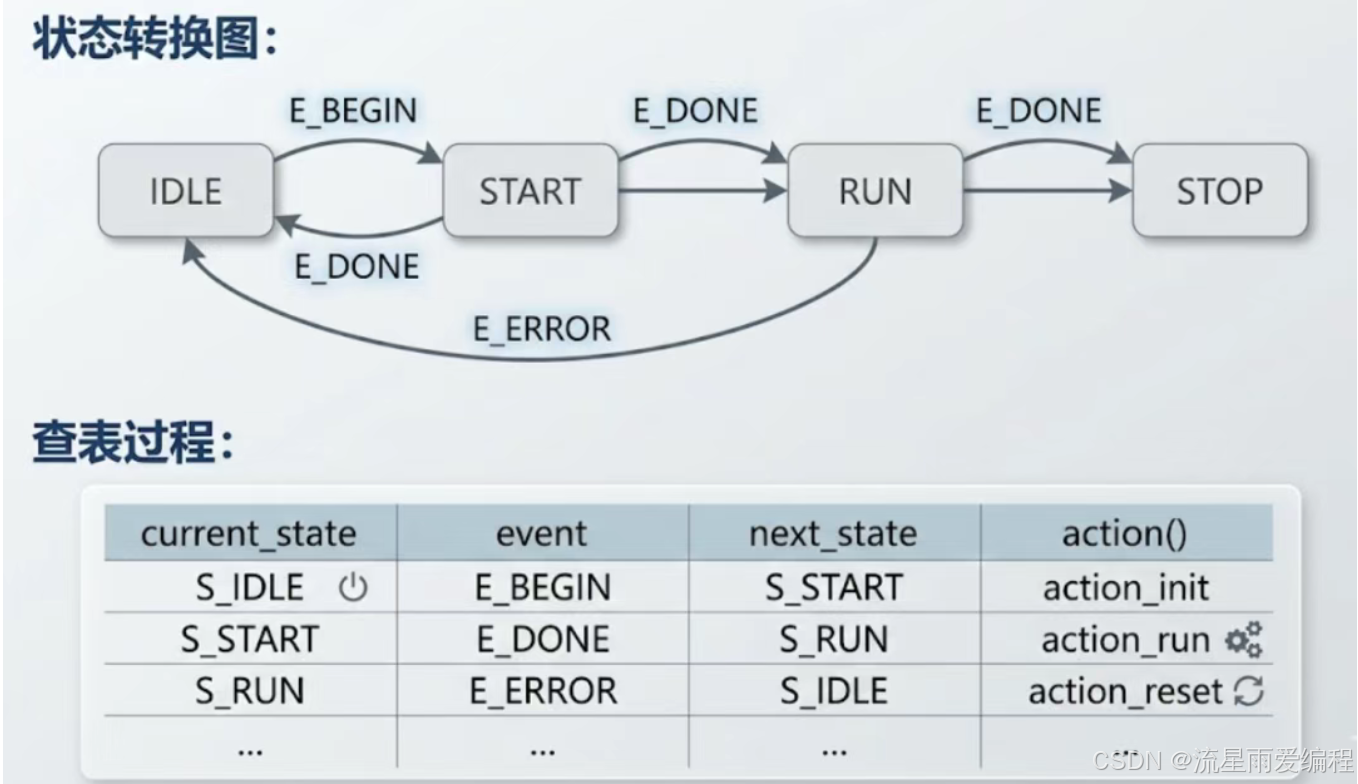
这种写法的好处是:加状态只需要在表里加一行,状态机引擎代码一个字不用动。而且整张表一眼就能看出所有状态转换关系,比散落在 switch-case 里清晰十倍。
5.模块自注册
前面说的通知链有个小问题——每个模块还得手动调用 notifier_register()。能不能让模块"自己注册自己"?
还真能。这招在Linux内核和RT-Thread里都在用,核心思路是:利用链接器把结构体收集到一个特殊的段里,启动时统一遍历执行。
/* 定义一个初始化描述结构体 */
typedef struct {
const char *name;
int (*init)(void); /* 初始化函数 */
} init_entry_t;
/* 黑魔法宏:把结构体放到自定义段 */
#define MODULE_INIT(fn, module_name) \
__attribute__((used, section(".init_table"))) \
static const init_entry_t _init_##fn = { \
.name = module_name, \
.init = fn, \
}各模块各写各的,互不相干:
/* uart.c */
static int uart_init(void) { /* 串口初始化 */ return 0; }
MODULE_INIT(uart_init, "UART");
/* spi.c */
static int spi_init(void) { /* SPI初始化 */ return 0; }
MODULE_INIT(spi_init, "SPI");
/* sensor.c */
static int sensor_init(void) { /* 传感器初始化 */ return 0; }
MODULE_INIT(sensor_init, "Sensor");启动时一把梭:
/* 链接器脚本里声明的段起止符号 */
extern const init_entry_t __start_init_table;
extern const init_entry_t __stop_init_table;
void system_init(void)
{
const init_entry_t *entry;
for (entry = &__start_init_table;
entry < &__stop_init_table;
entry++) {
printf("初始化模块: %s\n", entry->name);
entry->init();
}
}效果是这样的:

这招的杀伤力在于:新增一个模块,只需要在自己的 .c 文件里加一行 MODULE_INIT,完全不需要改 main.c 或任何其他文件。编译器和链接器帮你搞定一切。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)