C++11 扩展 --- 并发支持库(下)

lock_guard
在 C++ 开发中,我们常常会遇到一些需要成对操作的场景,例如 new 和 delete、malloc 和 free、lock 和 unlock 等。这些操作如果手动管理,很容易出现问题。比如,当程序在执行过程中抛出异常时,可能会导致某些操作未能正确执行,从而引发资源泄漏、死锁等一系列问题。手动管理这些操作的复杂性和潜在风险,使得我们迫切需要一种更加高效、安全的解决方案来简化资源管理。
RAII(Resource Acquisition Is Initialization,资源获取即初始化)正是为了解决这一问题而诞生的。它的核心思想是将资源的获取与对象的初始化绑定在一起,一旦获取到资源,就立即将其交给一个对象进行管理。这个对象的析构函数会自动负责资源的清理工作,例如释放内存或解锁。通过这种方式,资源的生命周期与对象的生命周期紧密绑定,无论程序是否发生异常,资源都能在对象析构时得到妥善处理,从而有效避免了资源泄漏和死锁等问题,大大提高了代码的健壮性和可维护性。
lock_guard 就是 C++11 提供的用于支持 RAII 方式管理互斥锁资源的类,能够有效防止因异常等原因导致的死锁问题。其大致原理类似于下面代码中的 LockGuard:
#include <iostream> // 包含标准输入输出流库
#include <chrono> // 包含时间相关功能
#include <thread> // 包含线程功能
#include <mutex> // 包含互斥锁功能
using namespace std;
// LockGuard 是一个模板类,用于管理互斥锁,遵循 RAII 原则
template<class Mutex>
class LockGuard
{
public:
// 构造函数:接受一个互斥锁的引用,并立即锁定该互斥锁
LockGuard(Mutex& mtx) : _mtx(mtx) {
_mtx.lock(); // 锁定互斥锁
}
// 析构函数:在对象生命周期结束时释放互斥锁
~LockGuard() {
_mtx.unlock(); // 解锁互斥锁
}
private:
Mutex& _mtx; // 互斥锁的引用,确保与传入的互斥锁绑定
};在 LockGuard 类中使用 Mutex& 是为了确保互斥锁对象的生命周期与 LockGuard 对象的生命周期紧密绑定。通过引用,LockGuard 直接绑定到传入的互斥锁对象上,而不是创建互斥锁的拷贝。这样可以避免因拷贝构造或赋值操作导致的潜在问题,因为标准库中的互斥锁(如 std::mutex)是不可拷贝的。【而且引用必须在构造函数初始化列表阶段就绑定,不能先创建对象再绑定】
使用引用可以简化代码逻辑并提高性能。引用避免了不必要的拷贝操作,直接操作原始互斥锁对象,从而减少了资源开销。此外,引用的使用也使得 LockGuard 的语义更加清晰:它只是一个互斥锁的“管理者”,而不是互斥锁的所有者。
最后,使用引用可以防止一些常见的错误,例如 LockGuard 持有无效的互斥锁对象。如果使用指针,可能会出现指针指向的互斥锁对象被提前销毁的情况,导致 LockGuard 在析构时尝试对一个已经销毁的对象调用 unlock,从而引发未定义行为。而引用则保证了 LockGuard 始终绑定到一个有效的互斥锁对象上。
也就是说:成员变量内部使用引用,引用的成员变量必须在初始化列表进行初始化,初始化列表可以认为是该类定义的地方,还用实参用引用的才是外面哪一个锁,才是同一个锁!
lock_guard 的功能简单纯粹,仅支持通过 RAII 方式管理锁对象。它可以在构造时通过传入 adopt_lock_t 的 adopt_lock 对象来管理已经加锁的锁对象。此外,lock_guard 类不支持拷贝构造。
int main()
{
int x = 0;
mutex mtx;
auto Print = [&x, &mtx](size_t n) {
{
lock_guard<mutex> lock(mtx);//出了作用域自动解锁
//LockGuard<mutex> lock(mtx);
//mtx.lock();
for (size_t i = 0; i < n; i++)
{
++x;
}
//mtx.unlock();
}
};
thread t1(Print, 1000000);
thread t2(Print, 2000000);
t1.join();
t2.join();
cout << x << endl;
return 0;
}
lock_guard 在上述代码保护的是for循环,但是如果后续还有代码呢?
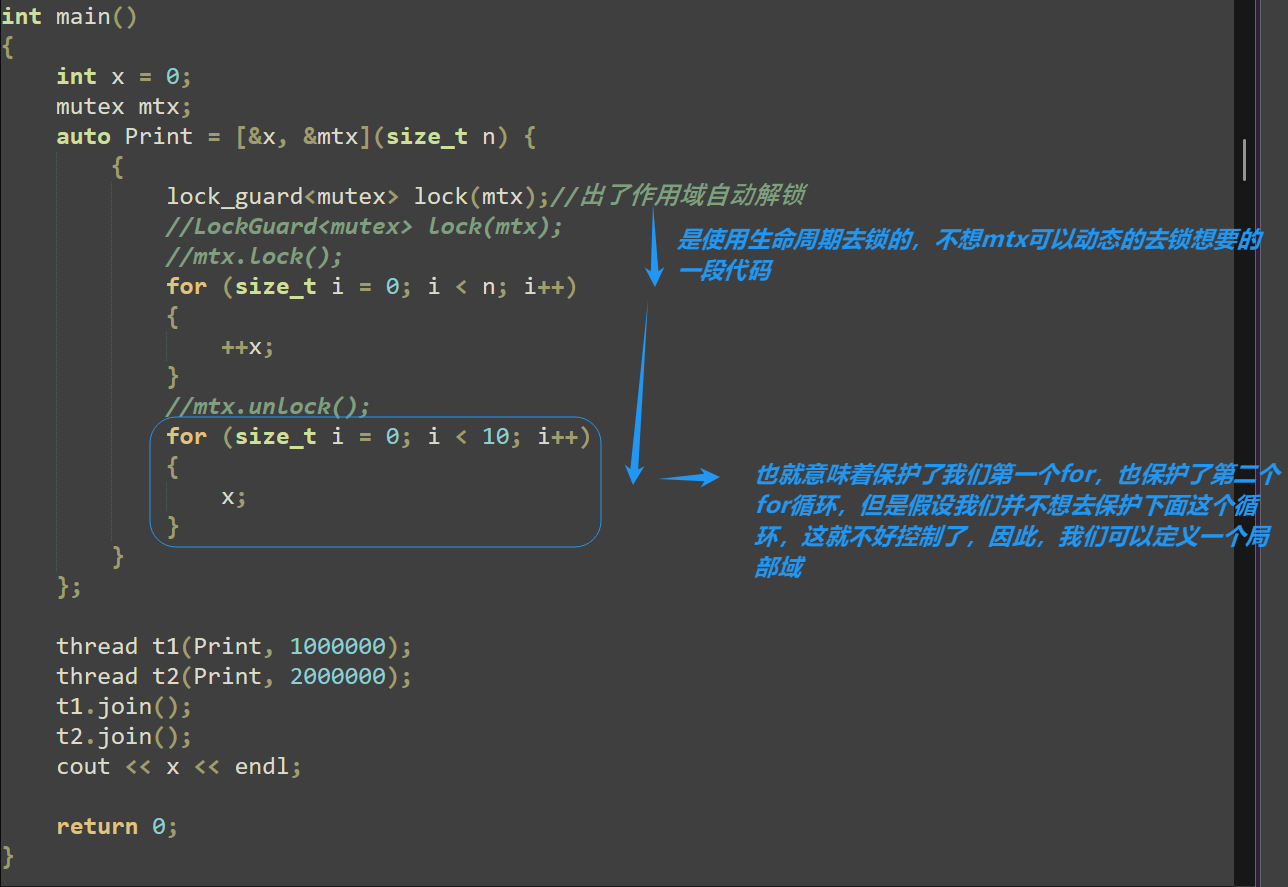
使用局部域:
int x = 0;
mutex mtx;
auto Print = [&x, &mtx](size_t n) {
{
{
lock_guard<mutex> lock(mtx);//出了作用域自动解锁
//LockGuard<mutex> lock(mtx);
//mtx.lock();
for (size_t i = 0; i < n; i++)
{
++x;
}
}
//mtx.unlock();
for (size_t i = 0; i < 10; i++)
{
x;
}
}
};锁定构造函数
explicit lock_guard(mutex_type& m);作用:构造一个 lock_guard 对象时,立即锁定传入的互斥锁 m。
mutex_type& m:一个互斥锁的引用,通常是 std::mutex 或其他派生自 std::mutex 的类。
内部:在构造函数中调用 m.lock(),锁定互斥锁。在析构函数中调用 m.unlock(),释放互斥锁。
std::mutex mtx;
std::lock_guard<std::mutex> lock(mtx); // 锁定互斥锁
// 在这里可以安全地访问共享资源采用锁构造函数
lock_guard(mutex_type& m, adopt_lock_t tag);
//adopt --- 领养作用:构造一个 lock_guard 对象时,假设传入的互斥锁 m 已经被锁定,lock_guard 不会再次锁定它。
mutex_type& m:一个互斥锁的引用。
adopt_lock_t tag:一个特殊的标记,表示互斥锁已经被锁定。
不会调用 m.lock(),因为假设互斥锁已经被锁定。
在析构函数中调用 m.unlock(),释放互斥锁。
std::mutex mtx;
mtx.lock(); // 显式锁定互斥锁
std::lock_guard<std::mutex> lock(mtx, std::adopt_lock); // 假设互斥锁已经被锁定
// 在这里可以安全地访问共享资源也就是说,锁在之前已经被锁住了,lock_guard 不会再次加锁,只是帮我们保存锁的引用,等到出作用域时,自动析构并解锁。
拷贝构造函数
lock_guard(const lock_guard&) = delete;作用:禁止拷贝构造。互斥锁是不可拷贝的,因此 lock_guard 也不支持拷贝构造。如果允许拷贝,可能会导致多个 lock_guard 对象同时管理同一个互斥锁,从而引发未定义行为。如果尝试使用拷贝构造函数,编译器会报错。
unique_lock
unique_lock 也是 C++11 提供的用于支持 RAII 方式管理互斥锁资源的类,相比 lock_guard,它的功能支持更丰富复杂。这是 unique_lock 的官方文档。
unique_lock 首先在构造的时候传不同的 tag,用以支持在构造的时候不同的方式处理锁对象。
| 值 | 描述 | 中文注释 |
|---|---|---|
| (no tag) | Lock on construction by calling member lock. | 构造时通过调用成员函数 lock 来锁定。 |
| try_to_lock | Attempt to lock on construction by calling member try_lock | 构造时尝试通过调用成员函数 try_lock 来锁定 |
| defer_lock | Do not lock on construction (and assume it is not already locked by thread) | 构造时不锁定(假设线程未锁定) |
| adopt_lock | Adopt current lock (assume it is already locked by thread). | 采用当前锁(假设线程已经锁定)。 |
// unique_lock constructor example
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::lock, std::unique_lock
// std::adopt_lock, std::defer_lock
std::mutex foo,bar;
void task_a () {
std::lock (foo,bar); // simultaneous lock (prevents deadlock)
std::unique_lock<std::mutex> lck1 (foo,std::adopt_lock);
std::unique_lock<std::mutex> lck2 (bar,std::adopt_lock);
std::cout << "task a\n";
// (unlocked automatically on destruction of lck1 and lck2)
}
void task_b () {
// foo.lock(); bar.lock(); // replaced by:
std::unique_lock<std::mutex> lck1, lck2;
lck1 = std::unique_lock<std::mutex>(bar,std::defer_lock);
lck2 = std::unique_lock<std::mutex>(foo,std::defer_lock);
std::lock (lck1,lck2); // simultaneous lock (prevents deadlock)
std::cout << "task b\n";
// (unlocked automatically on destruction of lck1 and lck2)
}
int main ()
{
std::thread th1 (task_a);
std::thread th2 (task_b);
th1.join();
th2.join();
return 0;
}这里补充一点:
std::lock 是 C++ 标准库中用于同时锁定多个互斥锁的函数模板,它的主要作用是防止死锁。
在多线程程序中,如果多个线程需要同时锁定多个互斥锁,可能会因为锁的获取顺序不一致而导致死锁。std::lock 可以同时锁定多个互斥锁,确保它们被以一种安全的方式获取,从而避免死锁。
具体来说:它就是一个能一次性锁住多个锁,并且绝对不会发生死锁的 C++ 工具。
假如:
- 线程 1 先锁 A → 再锁 B
- 线程 2 先锁 B → 再锁 A
两个人互相等对方的锁,谁都不松手 → 卡死 = 死锁。
我们把所有锁一次性丢给它:
std::lock(mtx1, mtx2, mtx3);
它会自动用安全的顺序把所有锁全部锁住,不管线程顺序怎么乱,都不会死锁!
std::lock 是一个函数模板,定义在 <mutex> 头文件中,其语法如下:
template <class... Mutexes>
void lock(Mutexes&... m);-
参数:
Mutexes&... m是一个参数包,表示可以传递多个互斥锁对象。 -
返回值:
std::lock不返回任何值,它直接锁定所有传入的互斥锁。
std::lock 的主要逻辑是:
-
尝试锁定所有互斥锁:
std::lock会尝试以一种安全的顺序锁定所有传入的互斥锁。 -
避免死锁:它通过一种特殊的算法(通常是尝试锁的顺序排序)来确保不会因为锁的获取顺序不一致而导致死锁。
-
原子操作:
std::lock的锁定过程是原子的,即在锁定所有互斥锁之前,不会释放任何已经锁定的互斥锁。
std::lock 通常用于以下场景:
-
多锁同步:当一个线程需要同时锁定多个互斥锁时,使用
std::lock可以避免死锁。 -
线程安全的资源管理:在需要同时访问多个受保护的资源时,
std::lock确保这些资源的访问是线程安全的。
我们也就大致能理解上面这段代码了:如果将两个锁对象直接传给 unique_lock,且不携带标签参数,unique_lock 会立即尝试加锁 —— 无占用则上锁,有占用则阻塞,这样往往达不到我们想要的效果。我们真正的需求是:先手动获取锁,再把锁交给 unique_lock 管理。
也可以像 task_b 中的用法:先创建两个 unique_lock,并以推迟(defer) 方式绑定锁对象,含义是:先不进行加锁,仅把锁交给 unique_lock 托管,保证析构时自动释放;之后再统一对这两把锁执行 std::lock 批量加锁即可。
unique_lock 还可以在构造的时候传时间段和时间点,用来管理 timed_mutex 系统,构造时调用 try_lock_for 和 try_lock_until。
unique_lock 不支持拷贝和赋值,支持移动构造和移动赋值。
unique_lock 还显示提供了 lock/try_lock/unlock 等系列的接口,这就更好控制了,和mutex类似的!
unique_lock 还可以通过 operator bool 去检查是否锁了锁对象。和 owns_lock 函数调用是一样的效果!
【unique_lock 就是加强版、豪华版、万能版的 lock_guard】
lock 和 try_lock
-
lock是一个函数模板,可以支持对多个锁对象同时锁定。如果其中一个锁对象没有锁住,lock函数会把已经锁定的对象解锁,然后进入阻塞,直到锁定所有的对象。(具体上面已经说过了) -
try_lock也是一个函数模板,尝试对多个锁对象进行同时锁定。如果全部锁对象都锁定了,返回-1;如果某个锁对象尝试锁定失败,则把已经锁定成功的锁对象解锁,并返回这个对象的下标(第一个参数对象,下标从 0 开始算)。
template <class Mutex1, class Mutex2, class... Mutexes>
void lock (Mutex1& a, Mutex2& b, Mutexes&... cde);
template <class Mutex1, class Mutex2, class... Mutexes>
int try_lock (Mutex1& a, Mutex2& b, Mutexes&... cde);// std::lock example
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::lock
std::mutex foo, bar;
void task_a() {
std::this_thread::sleep_for(std::chrono::seconds(1));
foo.lock();
bar.lock(); // replaced by:
//std::lock(foo, bar);
std::cout << "task a\n";
foo.unlock();
bar.unlock();
}
void task_b() {
std::this_thread::sleep_for(std::chrono::seconds(1));
bar.lock();
foo.lock(); // replaced by:
//std::lock(bar, foo);
std::cout << "task b\n";
bar.unlock();
foo.unlock();
}
int main()
{
std::thread th1(task_a);
std::thread th2(task_b);
th1.join();
th2.join();
return 0;
}一个线程执行 task_a,另一个线程执行 task_b。task_a 先锁定 foo,再锁定 bar;task_b 则顺序相反。这种情况下,某些场景下会出现严重问题:
如果两个线程同时进入任务,task_a 先锁住了 foo,与此同时 task_b 锁住了 bar,就会直接导致死锁,双方会一直相互阻塞,无法继续执行。
但是我们使用 lock 来进行同时锁:
std::lock 可以同时锁定多个互斥锁,确保它们被以一种安全的顺序获取,从而避免死锁。
-
在
task_a和task_b中,我们使用std::lock(foo, bar)和std::lock(bar, foo)来同时锁定两个互斥锁。 -
std::lock会尝试以一种安全的顺序锁定所有互斥锁,如果某个锁已经被其他线程持有,它会阻塞当前线程,直到所有锁都被成功锁定。
std::call_once
功能:在多线程执行时,确保某个函数(Fn)只被第一个线程执行一次,其他线程不会再次执行该函数。
函数模板声明
template <class Fn, class... Args>
void call_once (once_flag& flag, Fn&& fn, Args&&... args);参数:
-
flag:一个std::once_flag对象,用于标记函数是否已经被执行过。 -
fn:要执行的函数或可调用对象。 -
args:传递给fn的参数,支持可变参数。
行为:
-
如果
flag表示函数尚未执行,则call_once会调用fn,并将args转发给它。 -
如果
flag表示函数已经执行过,则call_once不会再次调用fn。 -
call_once确保即使多个线程同时调用它,fn也只会被调用一次。
call_once example
#include <iostream> // std::cout
#include <thread> // std::thread, std::this_thread::sleep_for
#include <chrono> // std::chrono::milliseconds
#include <mutex> // std::call_once, std::once_flag
int winner;
void set_winner(int x) { winner = x; }
std::once_flag winner_flag;
void wait_1000ms(int id) {
// count to 1000, waiting 1ms between increments:
for (int i = 0; i < 100; ++i)
std::this_thread::sleep_for(std::chrono::milliseconds(1));
// claim to be the winner (only the first such call is executed):
std::call_once(winner_flag, set_winner, id);
}这段代码展示了如何使用 std::call_once 和 std::once_flag 来确保在多线程环境中某个操作只被第一个线程执行一次。具体来说:
-
线程任务:每个线程都会执行
wait_1000ms函数,该函数模拟了一个耗时操作(通过循环调用std::this_thread::sleep_for模拟等待 1000 毫秒)。 -
竞争条件:所有线程在完成等待后,都会尝试调用
set_winner函数来设置全局变量winner的值为当前线程的 ID。 -
std::call_once的作用:通过std::call_once和std::once_flag,确保只有第一个完成等待的线程能够成功调用set_winner,其他线程的调用会被忽略。这样可以避免多个线程同时修改全局变量winner,从而避免竞争条件。 -
结果:最终,
winner的值会被设置为第一个完成等待的线程的 ID,而其他线程的尝试不会改变这个值。
简而言之,这段代码通过 std::call_once 确保在多个线程中只有第一个完成任务的线程能够设置全局变量 winner,从而避免了多线程环境下的竞争条件。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)