吴恩达Agentic AI教程·模块2:反思设计模式 知识点总结
吴恩达Agentic AI教程·模块2:反思设计模式 知识点总结
一、反思设计模式(Reflection Design Pattern)核心定义与本质
-
本质:模仿人类“产出→复盘→优化”的思考过程,让大语言模型(LLM)先生成初稿,再通过反思指令优化输出,是Agentic AI的基础设计模式,实现简单且应用广泛。
-
核心逻辑:
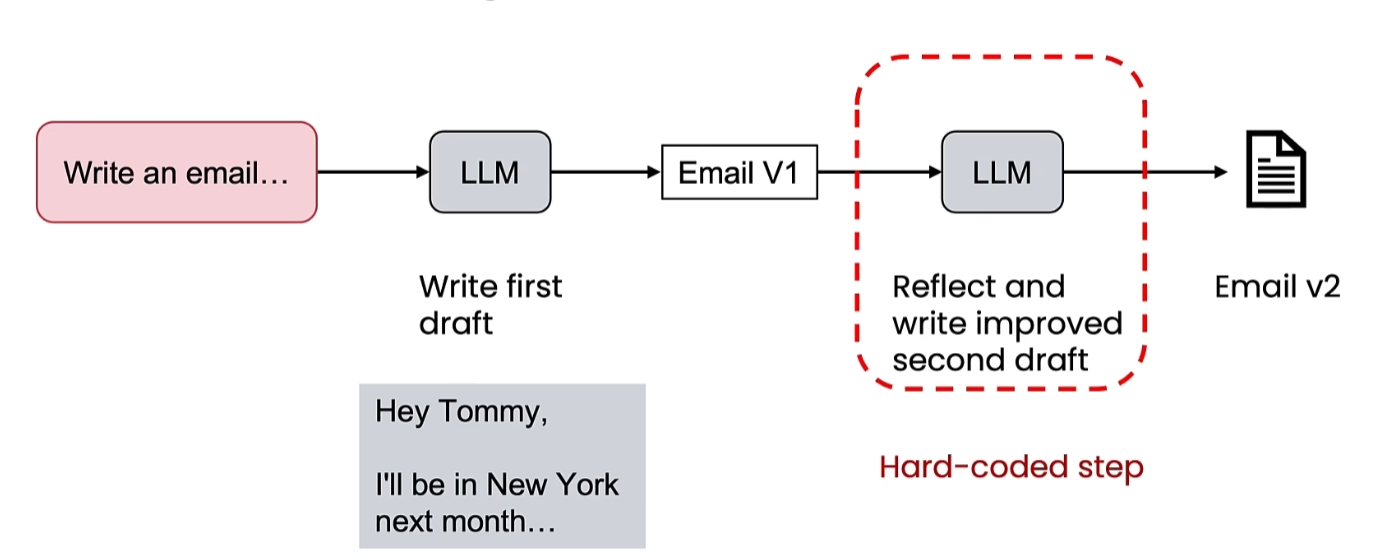
1. 使用初始提示词(Prompt)生成初稿(V1,如邮件、代码、图表等)
2. 将初稿+反思指令再次输入给LLM(可与初稿生成模型相同或不同)
3. LLM分析问题并生成优化版(V2),完成一次反思迭代。 -
通俗示例:人类快速撰写邮件初稿后,会通读修正措辞、补充细节、修正拼写错误(如遗漏签名)、澄清模糊表达等,LLM的反思模式与此一致。
二、反思模式的模型选择策略
-
初稿生成:使用通用生成模型即可,无需特殊配置,核心是快速产出基础内容。
-
反思优化:优先选用 “推理型(思考型)模型”,这类模型更擅长找错、逻辑优化(如代码Bug检查)。
-
灵活搭配:可根据任务特性,选用不同模型分别负责初稿生成与反思优化,充分发挥各类模型的优势。
三、反思模式的关键优化:外部反馈(External Feedback)
(一)核心观点
仅靠 LLM 自我反思效果有限,引入外部信息的反思,效果远强于纯模型自反思;外部反馈能为模型提供全新客观信息,让反思更精准、深度更高。
(二)外部反馈的主要来源
-
代码执行结果与报错日志:运行LLM生成的V1版本代码,将输出结果或语法错误信息反馈给LLM,助力代码优化。
-
工具检测结果:通过代码/工具进行正则匹配(如检测邮件中竞争对手名称)、字数统计(如控制文案字数,若超出字数限制要求重写)等,将检测结果作为反馈。
-
外部信息核查:通过网页搜索、权威数据源进行事实校验(如核查泰姬陵建造时间),补充精准信息用于反思优化。
-
多模态输入:将模型生成的图像、图表(如可视化图表)作为输入,让多模态模型通过视觉推理反思优化。
(三)外部反馈的工程价值
当纯提示词工程的性能进入瓶颈(趋于平稳,难以进一步提升)时,引入反思(尤其是带外部反馈的反思)可突破性能上限;反思会小幅增加系统耗时,但能换来显著的输出质量提升。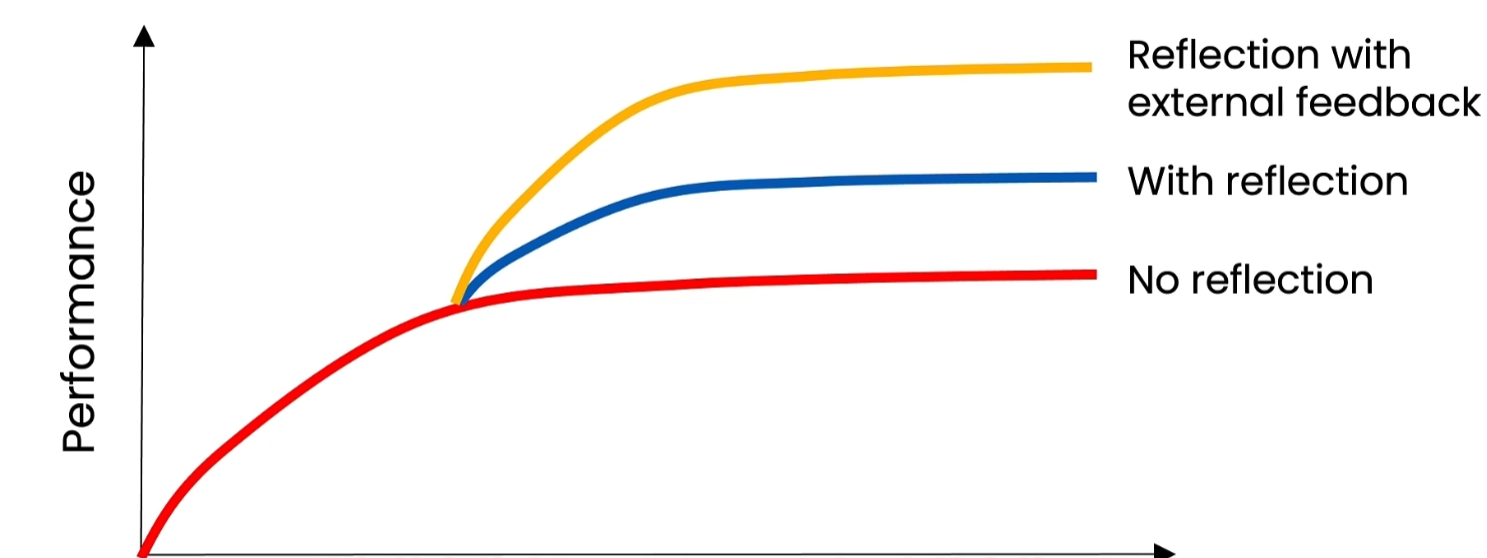
✅ 结论:反思 + 外部反馈 = 更强纠错与优化能力。
四、反思模式与零样本提示(直接生成,Zero-shot Prompting)的对比
(一)相关概念辨析
-
零样本提示(直接生成):仅向模型输入指令,不包含任何示例,让模型一次性直接生成输出(如直接让模型写论文、写代码)。
-
相关概念补充:单样本提示(提示中包含1个输入输出示例)、少样本提示(提示中包含多个输入输出示例),与零样本提示的核心区别是是否包含示例。
(二)效果对比
多项研究(如Radon等人的论文)表明,反思模式在多种任务中均能提升模型性能:同一模型在相同任务中,带反思的输出现显著优于零样本直接生成,具体提升幅度因应用场景而异。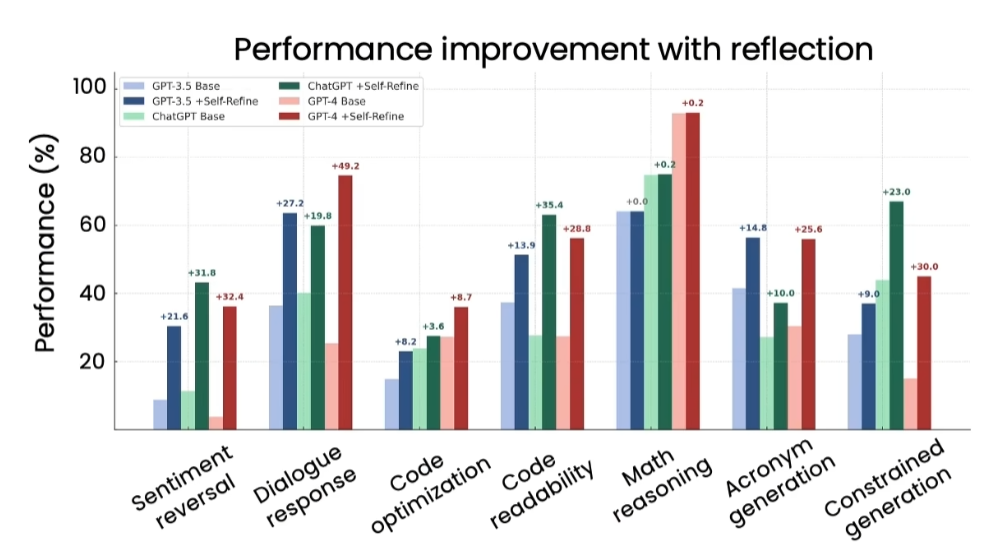
(三)代价
增加延迟(需两次调用 LLM)。
五、反思模式的适用场景与示例
(一)文本生成(如邮件撰写)
- 初稿可能语气不当、信息模糊、缺少关键细节。
- 反思提示可要求:检查语气、事实准确性、日期/承诺一致性、完整性,优化措辞、补充细节、修正拼写/格式错误。
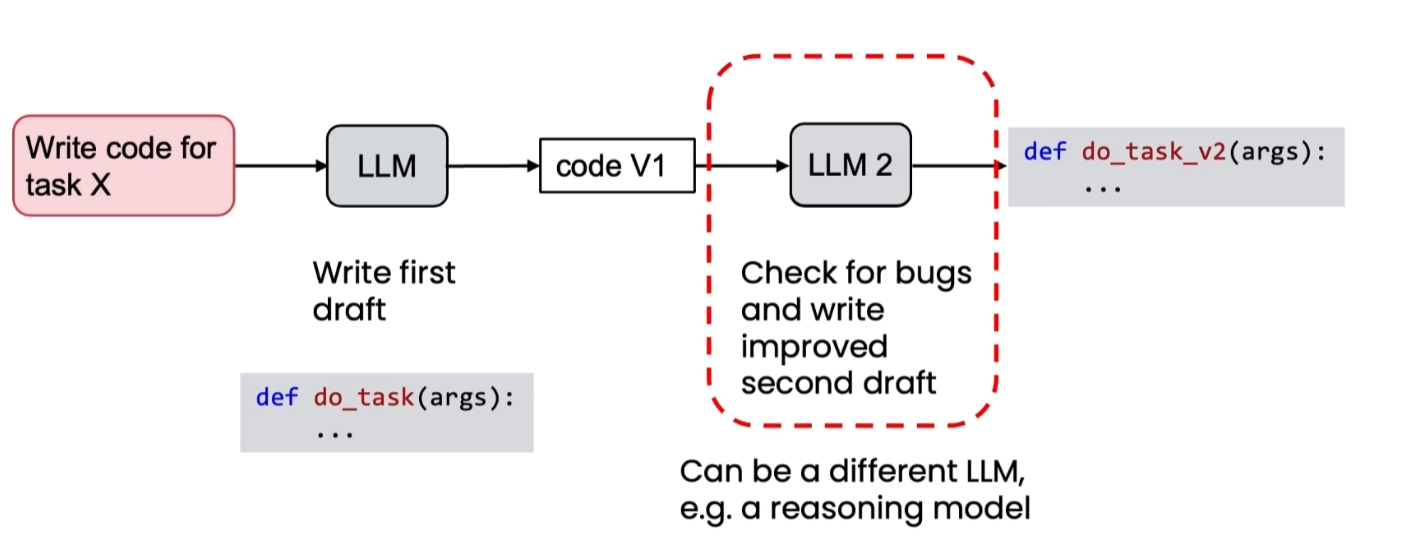
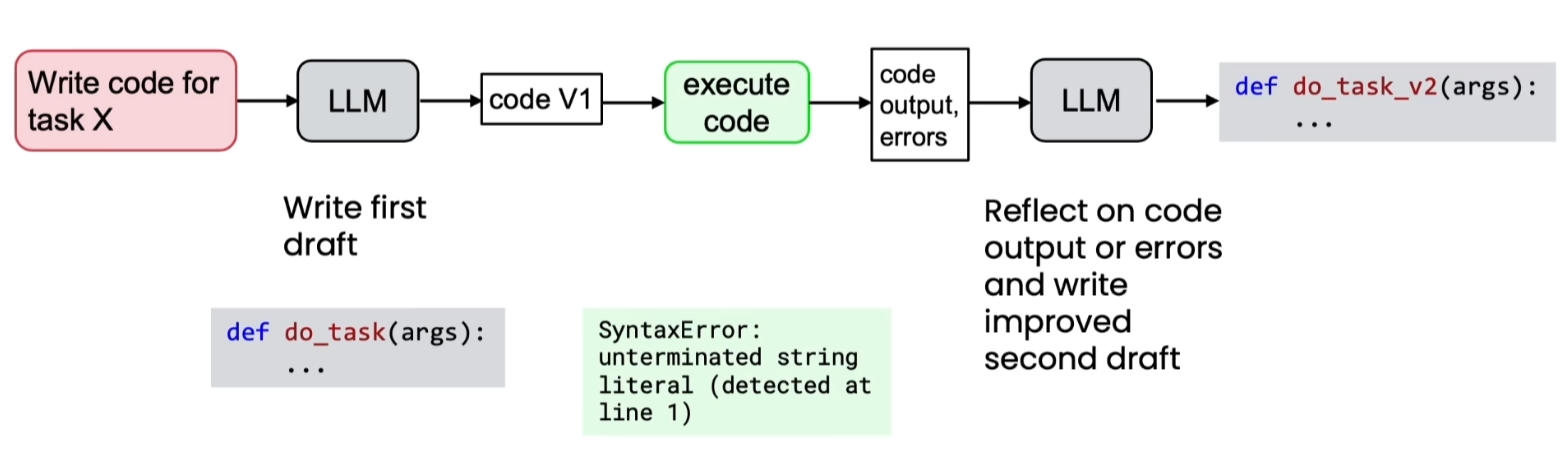
(二)代码生成
- 初稿可能存在语法错误、逻辑漏洞。
- 反思步骤可要求:检查 bug、检查语法错误、修复Bug、优化代码逻辑、优化结构、提高可读性,结合代码执行反馈进一步提升质量。
- 推荐策略:用通用模型生成初稿,用“推理型模型”(reasoning model)进行反思(因其更擅长找错)。
(三)结构化输出
- 复杂嵌套结构易出错。
- 反思可用于验证格式正确性、字段完整性。例如校验HTML代码、复杂嵌套JSON等数据格式,修正格式错误。
(四)步骤指令生成
- 初稿可能遗漏关键步骤。
- 反思可检查:指令逻辑连贯性、步骤完整性,补全遗漏步骤(如“如何泡一杯完美的茶”的步骤优化)。
(五)创意生成(如域名 brainstorm)
- 初稿可能包含:难发音的词;负面/冒犯性含义(尤其在多语言中)。
- 反思提示可要求筛选:易读性、文化敏感性、发音友好性。
(六)数据可视化
- 初稿图表可能类型不当(如堆叠柱状图 vs 分组柱状图)、美观度差。
- 多模态反思:将生成的图像 + 代码一起输入支持图像理解的 LLM,要求其:视觉评估图表清晰度;建议更合适的可视化方式;重写绘图代码。
- 示例:咖啡销量对比图从堆叠柱状图优化为分组柱状图,优化了图表类型,提升了图表可读性与美观度,结合生成的图表进行多模态反思。
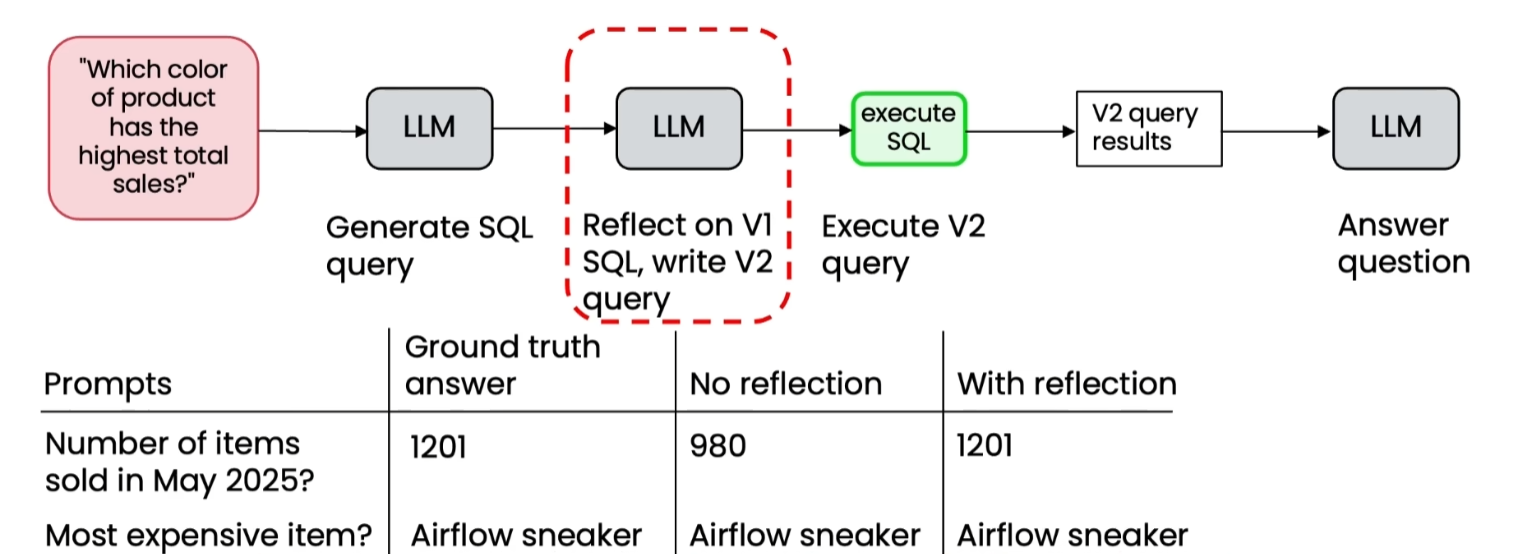
(七)数据库查询(SQL)
- 优化SQL语句,提升查询准确率,结合数据库查询结果验证优化效果。
(八)文案/论文撰写
- 事实校验、控制字数、优化表述,结合外部信息核查提升内容准确性。
六、反思提示词(Reflection Prompts)编写技巧
-
明确角色:如“你是一位资深数据分析师,请提供建设性反馈”。
-
明确指令:清晰告知模型需要“审阅、反思初稿”,避免模糊表述。
-
设定标准:指定具体的评估维度,引导模型聚焦关键优化点。
邮件:语气、事实核对、完整性;
域名:发音难度、负面含义;
图表:清晰度、标题/坐标轴标签、图表类型可读性与合理性。 -
提供上下文:包括初稿、原始需求、对话历史、外部反馈(如错误日志、图像)
-
参考借鉴:通过阅读开源软件中的优质提示词,学习优秀反思提示词的编写逻辑,提升自身提示词质量。
七、反思模式的评估方法(Evals)
评估核心:验证反思模式对具体应用的性能提升幅度,为提示词优化、模型选择提供依据,同时权衡反思带来的耗时增加与性能提升。
(一)客观评估(有标准答案的任务)
-
适用场景:SQL查询、数据计算、事实类问答等有明确“正确答案”的任务。
-
评估方法:
1.准备带标准答案的测试集(如10-15个数据库查询问题及正确答案,测试集 = 问题 + 真实答案)
2.分别运行“无反思”和“有反思”的工作流
3.统计两者的正确率,对比性能差异。 -
原文示例:无反思时SQL查询正确率87%,加入反思后提升至95%,验证了反思的有效性。
-
优势:易于管理,可通过代码自动化统计结果,评估结果客观、可复现。
(二)主观评估(无唯一标准答案的任务)
-
适用场景:图表生成、文案风格、创意筛选等无明确“正确答案”,需主观判断优劣的任务。
-
避坑点:避免让LLM直接二选一对比(易受位置偏差影响,多数模型会优先选择第一个选项,与实际质量无关)。

-
最优方法:评分细则(Rubric)+ 二进制打分
-
设定清晰的量化标准(如图表是否有清晰标题、坐标轴标签是否完整、图表类型是否合适等)。
-
对每条标准进行0/1二进制打分(符合为1,不符合为0),求和得到总分,结果更稳定、更贴合人类判断,比 1–5 分制更稳定、可复现。
-
-
评估流程:收集多个用户查询(如10-15个可视化需求),分别生成“无反思”和“有反思”的输出,用上述评分方法打分,对比两者的平均分,判断反思的提升效果。
(三)评估的实际价值
通过评估可快速测试不同反思提示词、模型搭配的效果,筛选最优方案;后续优化提示词或模型时,可通过重新评估验证优化效果,实现持续迭代。
✅ 建议:无论客观/主观任务,都应建立 evals 以系统化比较不同提示策略。
八、多模态反思拓展(原文实操示例)
-
核心前提:多模态模型可接收图像输入(如模型生成的图表、图片),具备视觉推理能力。
-
实操流程(咖啡销售可视化示例):
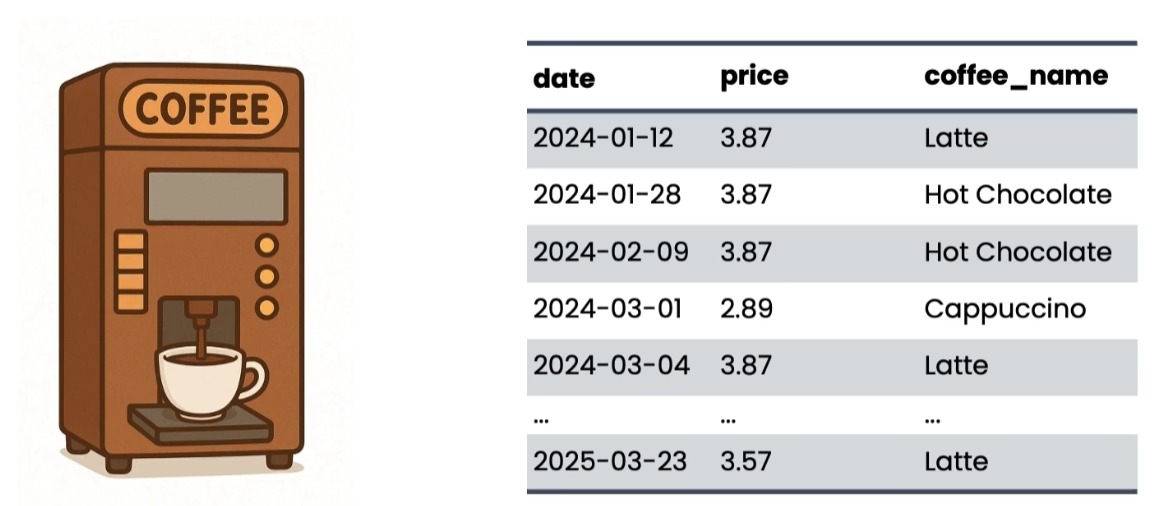
-
需求:生成2024年与2025年Q1咖啡销售对比图表。
-
初稿(V1):模型生成堆叠柱状图代码,执行后得到的图表可读性差、不美观。
-
反思优化:将V1代码、生成的图表输入多模态模型,要求其批评图表、优化可视化效果、更新代码。
-
优化结果:模型将堆叠柱状图改为普通柱状图,图表更清晰、美观,更易对比数据。

-
-
注意事项:可选用不同模型分别负责初始代码生成与多模态反思,适配任务需求。
九、课程核心总结
-
反思设计模式是Agentic AI的基础,核心是“初稿+反思优化”,可显著提升模型输出质量。
-
外部反馈是反思模式的关键优化点,能突破纯提示词工程的性能瓶颈,各类工具、外部信息均可作为反馈来源。
-
模型选择、提示词编写、评估方法是落地反思模式的核心要素,需结合具体场景灵活调整。
-
反思模式可适配文本、代码、多模态等多种场景,是提升Agentic AI应用性能的重要手段。
十、课程衔接预告
下一模块将介绍 “工具使用(Tool Use)”:
- 系统化调用函数/API;
- 让 Agent 主动获取外部信息;
- 进一步增强 Agentic AI 的能力。
附视频链接
1、官方视频链接 Agentic AI
https://learn.deeplearning.ai/courses/agentic-ai/lesson/shknq1/reflection-to-improve-outputs-of-a-task
2、B站视频链接 Agentic AI
https://www.bilibili.com/video/BV1DfrdByE2H?spm_id_from=333.788.videopod.episodes&vd_source=4a79cbf7097a81f45c953a0bd7874893&p=9

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)