AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration
发表:MLSys 2024
链接https://proceedings.mlsys.org/paper_files/paper/2024/file/42a452cbafa9dd64e9ba4aa95cc1ef21-Paper-Conference.pdf
代码:https://github.com/mit-han-lab/llm-awq
ABSTRACT
大语言模型(LLMs)已经从根本上改变了众多应用的能力,从自然语言处理到机器人和自动驾驶中更复杂的特定领域任务。此外,近年来端侧(on-device)大语言模型的重要性显著增加。在边缘设备上运行大语言模型不仅有望降低延迟并提升用户体验,而且由于数据处理可以在本地进行,这也符合日益增长的用户隐私需求。然而,现代大语言模型庞大的模型尺寸以及边缘设备在内存大小和带宽方面的主要限制,给部署带来了巨大的挑战。在本文中,我们提出了激活感知的权重量化(AWQ),这是一种硬件友好型的大语言模型低比特纯权重(weight-only)量化方法。我们的方法基于这样一个观察:权重并不是同等重要的,仅保护 1% 的显著权重(salient weights)就能极大地减少量化误差。因此,我们提出通过观察激活值(而不是观察权重本身)来搜索最佳的逐通道(per-channel)缩放比例,从而保护这些显著权重。AWQ 不依赖任何反向传播或重建过程,因此它可以很好地保留大语言模型在不同领域和模态上的泛化能力,而不会对校准集产生过拟合。AWQ 在各种语言建模和特定领域基准测试(编程和数学)上的表现均优于现有工作。得益于更好的泛化能力,它在指令微调语言模型以及(首次在)多模态语言模型上都取得了极其优异的量化性能。与 AWQ 算法一起,我们还实现了 TinyChat,这是一个专为端侧 LLM/VLM(大语言模型/视觉语言模型)量身定制的高效且灵活的推理框架,在桌面级和移动级 GPU 上,相比于 Huggingface 的 FP16 实现,它提供了超过 3 倍的速度提升。它还使得在移动端 GPU 上部署 70B 的 Llama-2 模型成为可能。
1 INTRODUCTION
将大型语言模型(LLM)直接部署在边缘设备上至关重要。端侧使用消除了将数据发送到云服务器造成的延迟,并使 LLM 能够离线运行,这对于虚拟助手、聊天机器人和自动驾驶汽车等实时应用非常有利。与维护和扩展集中式云基础设施相关的运营成本也能得到降低。端侧 LLM 通过将敏感信息保留在本地,还能增强数据安全性,降低数据泄露的风险。基于 Transformer 架构的 LLM (Vaswani et al., 2017) 因其在各种基准测试中令人印象深刻的性能而备受瞩目 (Brown et al., 2020; Zhang et al., 2022; Touvron et al., 2023a; Scao et al., 2022)。然而,庞大的模型尺寸导致了高昂的部署服务成本。例如,GPT-3 拥有 175B 的参数,在 FP16 精度下需要 350GB 的内存,而最新的 H100 GPU 也只有 96GB 内存,更不用说边缘设备了。

针对 LLM 的低比特权重量化可以显著减少端侧 LLM 推理的内存占用,但这是一项艰巨的任务。量化感知训练 (QAT) 由于训练成本高而不具备效率,而训练后量化 (PTQ) 在低比特设置下会遭遇大幅度的精度下降。最相近的工作是 GPTQ (Frantar et al., 2022),它利用二阶信息来进行误差补偿。然而,它在重建过程中可能会对校准集产生过拟合,从而扭曲了在分布外领域(out-of-distribution domains)学习到的特征(图 8),这非常成问题,因为 LLM 是通用主义模型。
在本文中,我们提出了激活感知权重量化(AWQ),这是一种针对 LLM 的硬件友好型低比特纯权重(weight-only)量化方法。我们的方法基于这样一个观察:对于 LLM 的性能而言,权重并不是同等重要的。只有一小部分(0.1%-1%)的显著权重(salient weights);跳过对这些显著权重的量化将显著减少量化损失(表 1)。为了找到这些显著权重通道,我们的见解是,尽管我们做的是纯权重量化,但我们应该参考激活值的分布而不是权重本身的分布:对应于较大激活幅度的权重通道更为显著,因为它们处理的是更重要的特征。为了避免在硬件上效率低下的混合精度实现,我们分析了权重量化带来的误差,并推导出对显著通道进行放大(scaling up)可以降低它们的相对量化误差(公式 2)。遵循这一直觉,我们设计了一种逐通道(per-channel)缩放方法,以自动搜索在全权重量化下能使量化误差最小化的最佳缩放比例。AWQ 不依赖于任何反向传播或重建,因此它可以很好地保留 LLM 在各种领域和模态上的泛化能力,而不会对校准集过拟合。
为了实现 AWQ,我们设计了 TinyChat,这是一个高效的推理框架,旨在将 4-bit LLM 带来的理论内存节省转化为实测的速度提升。我们的框架通过即时(on-the-fly)反量化显著加快了线性层的速度。我们还利用高效的 4-bit 权重打包(packing)和算子融合(kernel fusion)来最小化推理开销(例如,中间 DRAM 访问和内核启动开销),这样尽管计算机是按字节对齐(byte-aligned)的,我们也能更好地实现将权重缩小到 4-bit 所带来的加速。
实验表明,AWQ 在针对不同模型系列(例如 LLaMA、OPT)和模型尺寸的各种任务上均优于现有的工作。得益于更好的泛化能力,它在指令微调的语言模型(例如 Vicuna),以及首次在多模态语言模型(OpenFlamingo)上也取得了卓越的量化性能。TinyChat 进一步将近 4 倍的内存占用降低转化为实测的加速比。在台式机、笔记本电脑和移动设备 GPU 上,针对各种类型的 LLM,与 Huggingface 的 FP16 实现相比,我们一致观察到了平均 3.2-3.3 倍的速度提升。此外,它还使得在具有 64GB 内存的单张 NVIDIA Jetson Orin 上能够毫不费力地部署 Llama-2-70B 模型。它还使得在仅有 8GB 内存的 RTX 4070 笔记本 GPU 上,能够以 30 token/秒的交互速度普及部署 130 亿(13B)参数的 LLM。AWQ 已被包括 FastChat、vLLM、HuggingFace TGI、LMDeploy 等在内的多种开源 LLM 部署和服务解决方案广泛采用。
2 R ELATED WORK
模型量化方法 量化降低了深度学习模型的比特精度 (Han et al., 2016; Jacob et al., 2018; Nagel et al., 2019; Wang et al., 2019; Nagel et al., 2020; Lin et al., 2020),这有助于减小模型尺寸并加速推理。量化技术通常分为两类:量化感知训练(QAT,依赖于反向传播来更新量化后的权重)(Bengio et al., 2013; Gholami et al., 2021; Nagel et al., 2021; Choi et al., 2018) 和训练后量化(PTQ,通常是免训练的)(Jacob et al., 2018; Nagel et al., 2019; 2020)。QAT 方法无法轻易地扩展到像大语言模型(LLMs)这样的大型模型上。因此,人们通常使用 PTQ 方法来对 LLMs 进行量化。
大语言模型 (LLMs) 的量化 人们主要研究 LLM 量化的两种设置:(1) W8A8 量化,即激活值和权重都被量化为 INT8 (Dettmers et al., 2022; Xiao et al., 2022; Yao et al., 2022; Wei et al., 2022a; 2023);(2) 低比特纯权重 (weight-only) 量化(例如 W4A16),即仅将权重本身量化为低比特整数 (Frantar et al., 2022; Dettmers & Zettlemoyer, 2022; Sheng et al., 2023; Park et al., 2022)。在这项工作中,我们重点关注第二种设置,因为它不仅降低了硬件门槛(需要更小的内存容量),而且还加速了 token 的生成(缓解了内存带宽瓶颈型的工作负载)。除了基础的就近舍入(round-to-nearest, RTN)基线外,GPTQ (Frantar et al., 2022) 是与我们工作最相近的方法。然而,GPTQ 的重建过程会导致对校准集的过拟合问题,可能无法保留 LLMs 在其他模态和领域中的通用能力。它还需要一种“重排序 (reordering)”技巧才能在某些模型上生效(例如 LLaMA-7B (Touvron et al., 2023a) 和 OPT-66B (Zhang et al., 2022))。除了针对通用硬件设计的量化方法外,SpAtten (Wang et al., 2020) 设计了一种渐进式的方法,逐步增加 softmax 计算中使用的比特数。
对低比特量化 LLMs 的系统支持 低比特量化的 LLMs 已成为降低推理成本的一种流行设置。目前已有一些系统级别的支持来实现实际的速度提升。GPTQ (Frantar et al., 2022) 为 OPT 模型提供了 INT3 算子(kernels),而 GPTQ-for-LLaMA 则在 Triton (Tillet et al., 2019) 的帮助下扩展了对 INT4 重排序量化的算子支持。FlexGen (Sheng et al., 2023)、llama.cpp 以及 exllama 采用了分组(group-wise)的 INT4 量化以减少 I/O 成本并实现内存卸载(offloading)。FasterTransformer 实现了 FP16×INT4 的 GEMM,用于逐张量(per-tensor)的纯权重量化,但不支持分组量化。LUT-GEMM (Park et al., 2022) 借助查找表(lookup tables)在 GPU CUDA 核心上执行按位计算。与我们同期的工作 MLC-LLM (MLC-Team, 2023) 得益于强大的 TVM (Chen et al., 2018; Feng et al., 2023) 后端,在多个边缘 CPU 和 GPU 平台上取得了强劲的结果。
3 AWQ:激活感知权重量化 (ACTIVATION-AWARE WEIGHT QUANTIZATION)
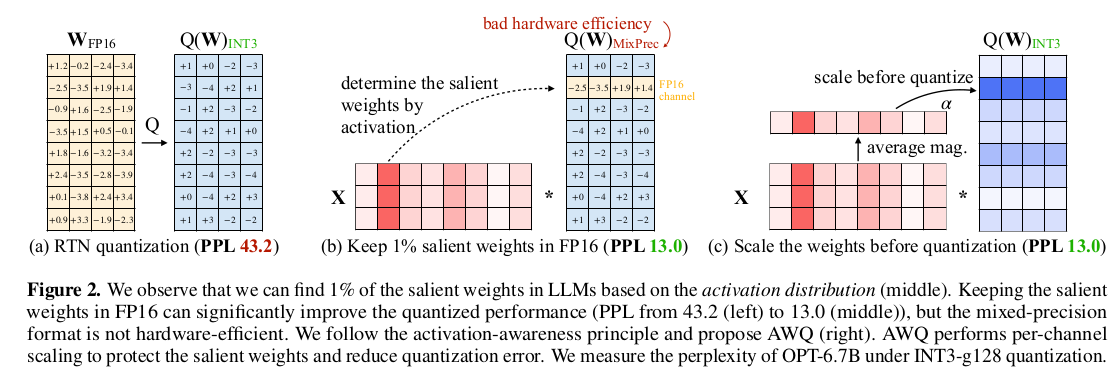
量化将浮点数映射为低比特整数。这是减小大语言模型(LLMs)尺寸和降低推理成本的一种有效方法 (Dettmers et al., 2022; Frantar et al., 2022; Yao et al., 2022; Xiao et al., 2022)。在本节中,我们首先提出一种纯权重量化(weight-only quantization)方法,通过保护更多“重要”的权重,在无需训练或回归的情况下提高准确率。然后,我们开发了一种数据驱动的方法来搜索最优缩放比例(scaling),从而减少量化误差(图 2)。
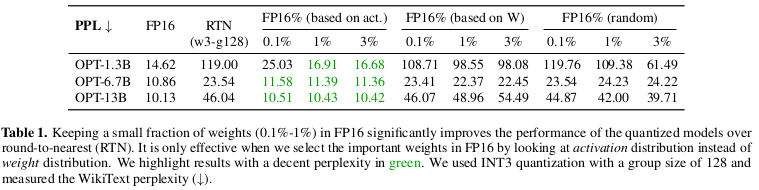
3.1 通过保留 1% 的显著权重来改进 LLM 量化
我们观察到 LLMs 的权重并不是同等重要的:有一小部分显著权重(salient weights)对 LLMs 的性能比其他权重重要得多。跳过对这些显著权重的量化有助于弥补由量化损失导致的性能下降,而无需任何训练或回归过程(图 2(b))。为了验证这个想法,我们在表 1 中对跳过部分权重通道时的量化 LLMs 的性能进行了基准测试。我们测量了 INT3 量化模型在保留一定比例的权重通道为 FP16 精度的条件下的性能。一种确定权重重要性的广泛使用的方法是观察其幅度或 L2 范数 (Han et al., 2015; Frankle & Carbin, 2018)。但我们发现,跳过具有大范数的权重通道(即基于权重的 FP16%)并没有显著提高量化性能,其带来的边际改善与随机选择相似。有趣的是,基于激活幅度(activation magnitude)来选择权重,尽管只保留了 0.1%-1% 的通道为 FP16,却能显著提升性能。我们假设,具有较大值的输入特征通常更重要。将相应的权重保留为 FP16 可以保留这些特征,这有助于获得更好的模型性能。
局限性: 尽管将 0.1% 的权重保留在 FP16 可以在模型大小(以总比特数衡量)没有明显增加的情况下提高量化性能,但这种混合精度的数据类型会使系统实现变得困难。我们需要提出一种方法来保护重要权重,而不是实际将它们保留为 FP16 格式。
3.2 通过激活感知缩放保护重要权重
我们提出了一种替代方法,通过**每通道缩放(per-channel scaling)**来减少重要权重的量化误差,这种方法不会受到硬件低效问题的影响。





AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)