PINN:用物理约束求解偏微分方程的奇妙之旅
PINN物理约束求解偏微分方程,正向求解,反向求参,Python,优化,复现,模型构建,理论讲解,硬约束实现经典案例分析,理论讲解,代码实现全过程
在科学与工程计算领域,求解偏微分方程(PDEs)一直是个核心问题。传统的数值方法,如有限元法、有限差分法等,虽然强大,但对于复杂几何形状和高维问题,往往面临计算成本高、实现难度大等挑战。而近年来,基于深度学习的物理信息神经网络(Physics - Informed Neural Networks,PINNs)为解决这类问题提供了全新的思路。今天咱就来唠唠PINN,从理论到代码实现,一步一步带你复现这个神奇的方法。
PINN理论讲解
PINN的核心思想,就是将物理定律(以偏微分方程的形式呈现)融入到神经网络的训练过程中。传统的神经网络在训练时,只依赖于数据拟合,力求让网络输出与给定的数据标签尽可能接近。但PINN不同,它不仅利用观测数据,还把控制物理系统的偏微分方程作为额外的约束条件加入到损失函数中。
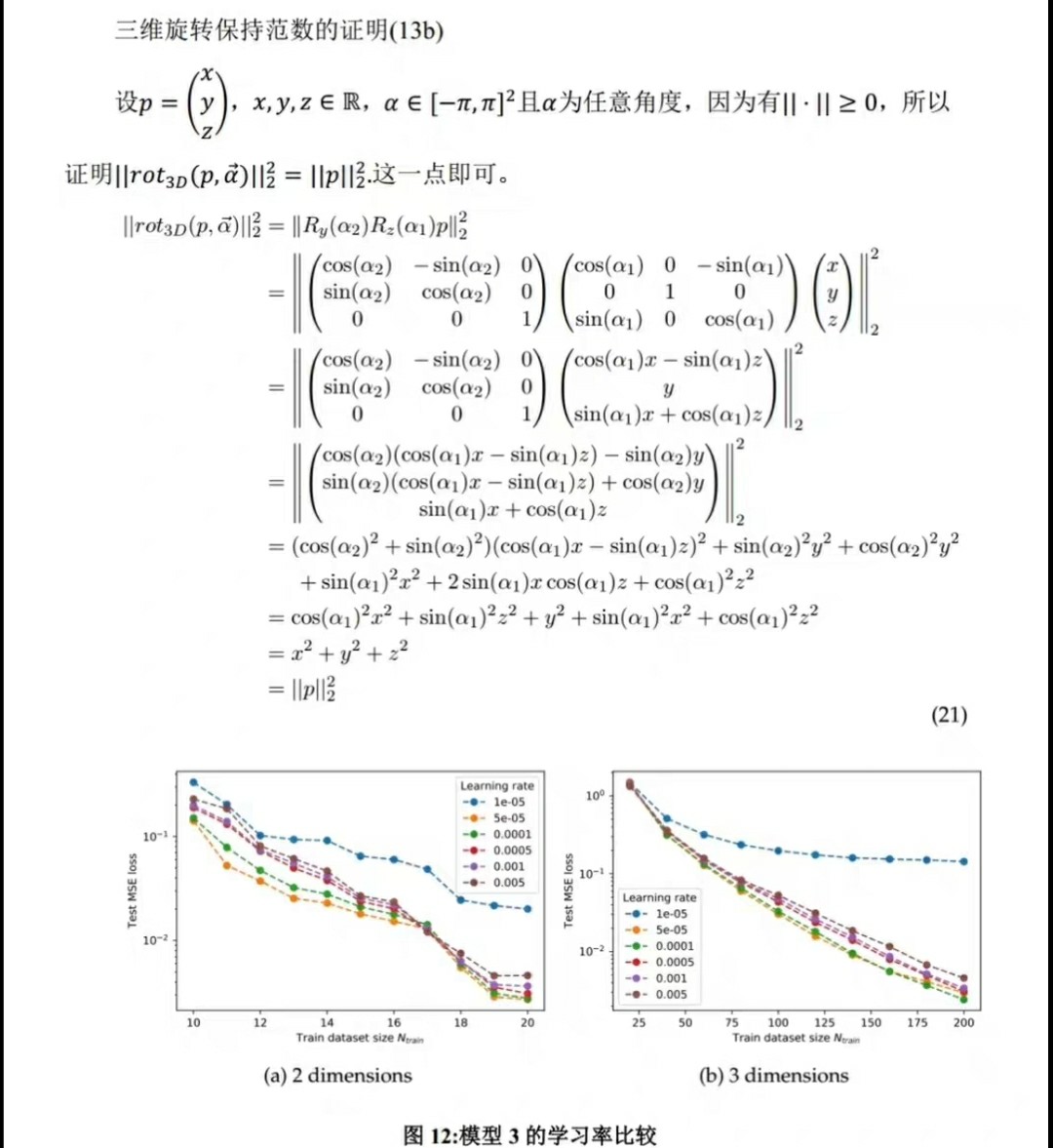
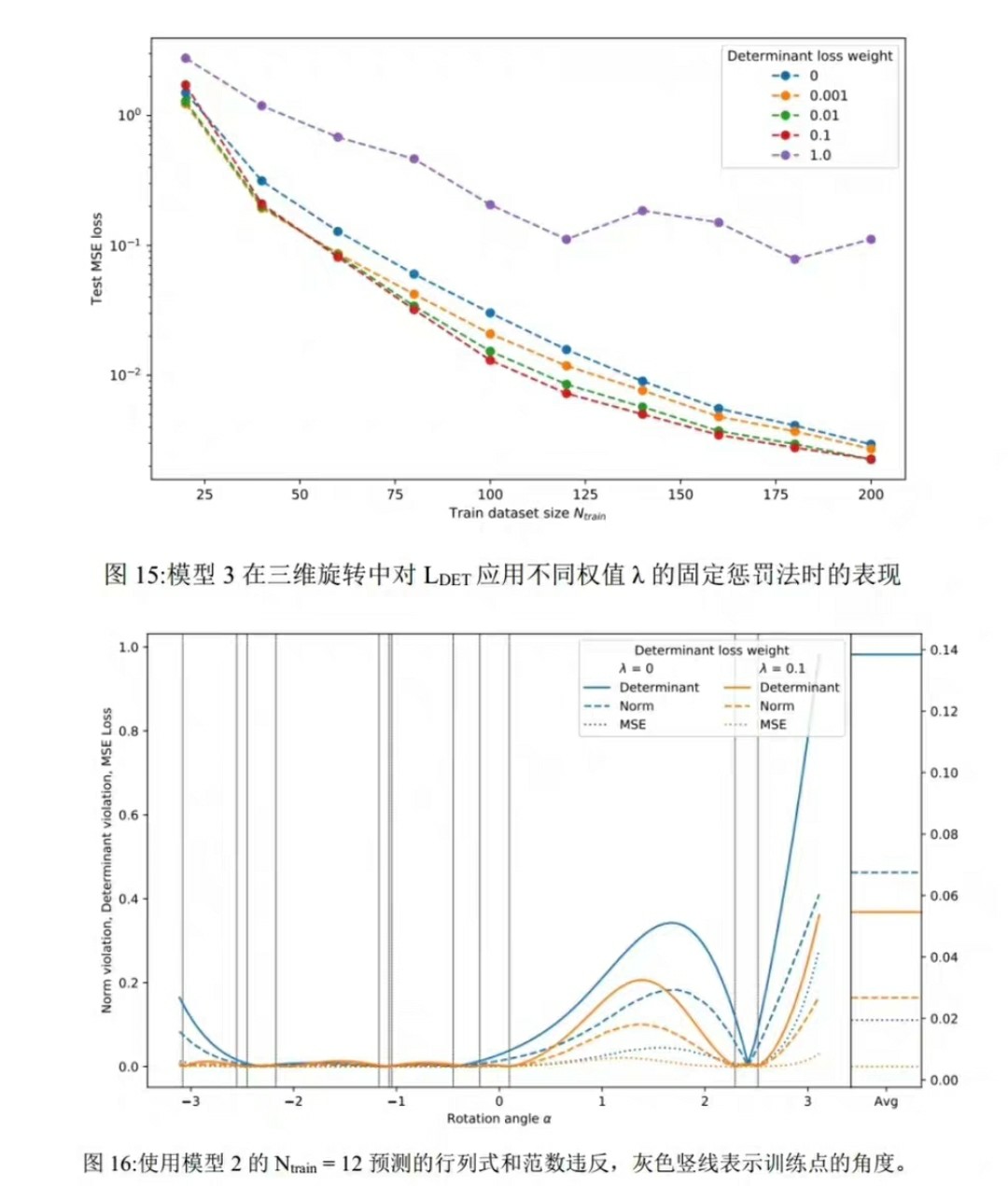
想象一下,我们有一个描述某个物理现象的偏微分方程,比如热传导方程:$\frac{\partial u}{\partial t} - \alpha (\frac{\partial^{2} u}{\partial x^{2}}+\frac{\partial^{2} u}{\partial y^{2}}) = 0$,这里$u$代表温度,$t$是时间,$x$和$y$是空间坐标,$\alpha$是热扩散系数。PINN会构建一个神经网络来近似函数$u(x, y, t)$,并且在训练过程中,通过调整神经网络的参数,使得这个近似函数不仅在观测数据点上与真实值接近,同时在整个求解域内都满足上述热传导方程。
从实现方式上看,PINN分为正向求解和反向求参两个关键步骤。正向求解就是利用构建好的神经网络,根据输入的自变量(如空间和时间坐标)预测因变量(如温度)。而反向求参则是通过计算损失函数(包含数据拟合损失和物理约束损失)对神经网络参数的梯度,利用优化算法(如随机梯度下降)来更新参数,使得损失函数最小化。
PINN模型构建
在Python中构建PINN模型,我们通常会借助深度学习框架,这里以PyTorch为例。
PINN物理约束求解偏微分方程,正向求解,反向求参,Python,优化,复现,模型构建,理论讲解,硬约束实现经典案例分析,理论讲解,代码实现全过程
首先,导入必要的库:
import torch
import torch.nn as nn
import numpy as np接着,定义神经网络结构。一个简单的多层感知机(MLP)就可以作为PINN的基础架构:
class PINN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(PINN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
out = torch.tanh(self.fc1(x))
out = torch.tanh(self.fc2(out))
out = self.fc3(out)
return out这段代码定义了一个三层的MLP。init方法中初始化了三个全连接层,输入维度为inputdim,隐藏层维度为hiddendim,输出维度为output_dim。在forward方法中,数据依次通过各层,中间层使用tanh激活函数,最后一层不使用激活函数,因为我们希望输出是连续值。
硬约束实现与经典案例分析
以求解二维稳态热传导方程为例,假设热传导系数$\alpha = 1$,边界条件为在区域边界上温度固定。
我们先定义一些辅助函数来计算物理约束项。这里用到自动求导功能,PyTorch在这方面非常方便:
def compute_pde_loss(model, x):
x.requires_grad_(True)
u = model(x)
u_x = torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u), create_graph=True)[0][:, 0]
u_y = torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u), create_graph=True)[0][:, 1]
u_xx = torch.autograd.grad(u_x, x, grad_outputs=torch.ones_like(u_x), create_graph=True)[0][:, 0]
u_yy = torch.autograd.grad(u_y, x, grad_outputs=torch.ones_like(u_y), create_graph=True)[0][:, 1]
pde_residual = - (u_xx + u_yy)
return torch.mean(pde_residual ** 2)在这个函数中,我们首先让输入x可求导。然后通过torch.autograd.grad多次求导得到$u$关于$x$和$y$的一阶导数ux、uy以及二阶导数uxx、uyy。最后根据热传导方程计算出PDE残差,并返回残差平方的均值作为物理约束损失。
接下来,定义数据和训练过程:
# 生成训练数据
x_domain = np.linspace(0, 1, 100)
y_domain = np.linspace(0, 1, 100)
X, Y = np.meshgrid(x_domain, y_domain)
x_train = np.vstack((X.flatten(), Y.flatten())).T
x_train = torch.FloatTensor(x_train)
# 初始化模型、损失函数和优化器
model = PINN(input_dim=2, hidden_dim=50, output_dim=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
optimizer.zero_grad()
u_pred = model(x_train)
data_loss = criterion(u_pred, torch.zeros_like(u_pred))
pde_loss = compute_pde_loss(model, x_train)
total_loss = data_loss + pde_loss
total_loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f'Epoch {epoch + 1}/{num_epochs}, Total Loss: {total_loss.item()}')这里我们在$[0, 1]\times[0, 1]$的区域内生成均匀分布的训练数据点。初始化PINN模型、均方误差损失函数criterion和Adam优化器optimizer。在训练循环中,每次迭代计算数据拟合损失dataloss(这里因为没有真实数据标签,我们简单设为与零的均方误差)和物理约束损失pdeloss,相加得到总损失total_loss,通过反向传播计算梯度并更新模型参数。
代码实现全过程总结
通过上述步骤,我们完成了PINN从理论到代码的全过程实现。从构建神经网络模型,到利用自动求导计算物理约束损失,再到数据准备和模型训练,每个环节都紧密相连。PINN为求解偏微分方程提供了一种灵活且强大的方法,尤其在处理复杂问题时展现出独特的优势。当然,实际应用中还需要根据具体问题调整网络结构、损失函数权重等超参数,以获得更好的结果。希望这篇博文能帮助你开启PINN的探索之旅,在偏微分方程求解的世界中发现更多有趣的应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)