深度学习篇---ROC与AUC指标
ROC曲线(Receiver Operating Characteristic Curve,受试者工作特征曲线)是一种用于评估二分类模型性能的重要工具。它通过综合考虑模型的灵敏度和特异性,帮助我们判断模型在不同阈值下的分类能力,尤其适用于样本不平衡的场景。
一、ROC曲线的核心概念
1. 基本指标
对于一个二分类问题,模型预测结果与真实标签构成混淆矩阵:
| 真实 \ 预测 | 正类(Positive) | 负类(Negative) |
|---|---|---|
| 正类 | TP(真阳性) | FN(假阴性) |
| 负类 | FP(假阳性) | TN(真阴性) |
基于此定义:
-
TPR(True Positive Rate,真正率) = TP / (TP + FN)
又称灵敏度或召回率,表示实际正类中被正确预测的比例。 -
FPR(False Positive Rate,假正率) = FP / (FP + TN)
表示实际负类中被错误预测为正类的比例。
2. ROC曲线绘制原理
ROC曲线的横轴是 FPR,纵轴是 TPR。
模型通常输出一个概率值(如逻辑回归的0~1概率),通过设定不同分类阈值(从0到1),每个阈值对应一对(FPR, TPR)。将这些点依次连接,就得到ROC曲线。
-
阈值极高(如1.0):所有样本判为负类 → (FPR=0, TPR=0)
-
阈值极低(如0.0):所有样本判为正类 → (FPR=1, TPR=1)
-
理想情况:曲线从左下角快速上升至左上角,然后平缓向右延伸。
二、AUC(曲线下面积)
AUC(Area Under Curve) 是ROC曲线下的面积,取值范围[0.5, 1]:
-
AUC = 0.5:模型无分类能力(相当于随机猜测)
-
0.5 < AUC < 0.7:分类能力较差
-
0.7 ≤ AUC < 0.85:分类能力中等
-
0.85 ≤ AUC ≤ 0.95:分类能力良好
-
AUC > 0.95:分类能力优秀(需警惕过拟合)
AUC的直观意义:随机抽取一个正样本和一个负样本,模型将正样本排在负样本前面的概率。因此AUC对样本分布不敏感,是评估不平衡数据集的理想指标。
三、ROC曲线的优势与局限
优势
-
不受类别分布影响:TPR和FPR均为比例值,即使正负样本比例悬殊,ROC曲线仍能稳定反映模型性能。
-
全面性:涵盖所有可能阈值,反映模型在不同分类偏好下的表现。
-
便于比较:通过AUC可以直观比较不同模型的优劣。
局限
-
对阈值不敏感:当实际应用需要特定阈值(如医疗诊断要求极高灵敏度)时,ROC曲线不能直接给出最优阈值,需结合其他指标(如约登指数)确定。
-
忽略概率校准:ROC只关注排序能力,不关心预测概率是否准确。若需要概率校准,应结合校准曲线评估。
四、实际应用场景
-
医学诊断:评估疾病筛查模型的灵敏度和特异度平衡。
-
信用评分:判断违约风险模型在不同决策阈值下的表现。
-
推荐系统:衡量正负样本(点击/未点击)的排序能力。
-
不平衡分类:欺诈检测、故障预测等领域。
五、ROC曲线总结框图
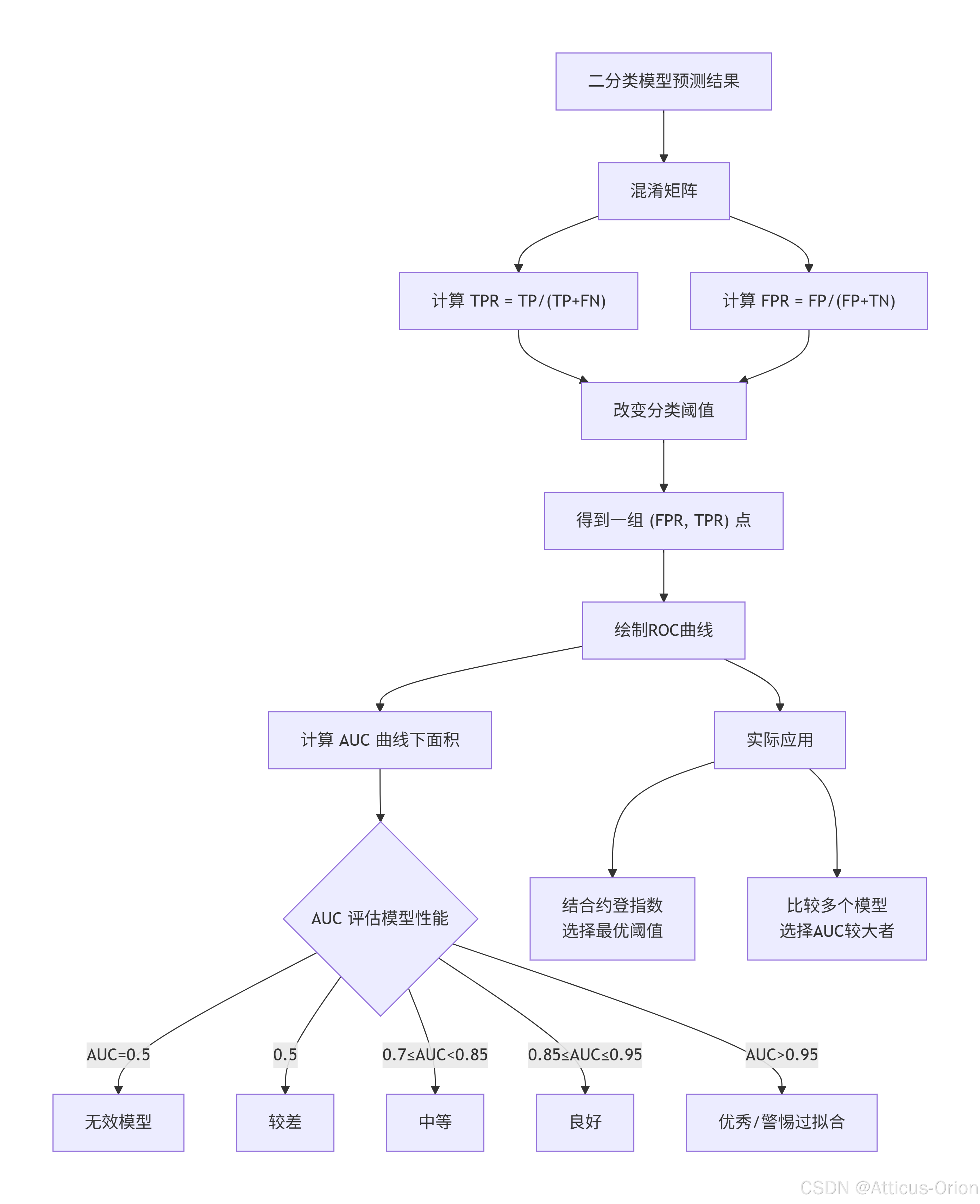
六、小结
ROC曲线与AUC是分类模型评估中不可或缺的工具。它通过展示模型在所有可能阈值下的真阳性率与假阳性率之间的权衡,为模型选择与阈值优化提供了直观依据。尤其在数据不平衡时,ROC比准确率等指标更具可靠性。但在实际部署时,还需结合业务场景(如成本、风险偏好)进一步确定最优阈值,并辅以其他评估指标(如精准率-召回率曲线)以获得更全面的模型理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)