知识图谱实战(实战实现NER)【第四章】
一、基于规则的方式实现NER(原理)
- 工业界常用的规则处理方法:
- 领域字典匹配(字典数据较多时,检索速度会慢很多)
- 定义正则表达式(一点不匹配就会导致无法匹配)
因为常见的规则处理方法有明显的局限性,我们可以考虑借助jieba的词性标注完成NER
比如jieba分词中ns表示地名(公司,地标,行政区域等),我们可以使用结巴先对句子进行分词把名词标注出来,再使用领域字典对机构类型进行标注,最后使用正则对词以领域字典标注的词为结尾,以jieba分词的名词作为开头完成NER。
二、基于规则的方式实现NER(实战)
- 为了更好地理解基于规则的NER方法,我们来看一个具体的例子。假设我们要从一段新闻报道中识别出机构名。首先,我们设计以下规则:
- 如果一个词语以“北京”、“中央”等地名词开头,那么它可能是一个机构名的开始。
- 如果一个词语后面紧跟着“公司”、“集团”、“局”、“部”等词,那么它可能是一个机构名的结束。
- 然后,我们构建一个包含“公司”、“集团”、“局”、“部”等词的词典。接下来,我们对新闻报道进行序列标注,将词典中的词标记为B或E,其余词语标记为O。最后,我们使用正则表达式“B+OE”从标注序列中抽取出机构名。
代码实现:
import jieba
import jieba.posseg as pseg
import re
org_tag = ['公司', '有限公司', '大学', '政府', '人民政府', '总局']
def extract_org(text):
# 使用jieba的词性标注进行分词
words_flags = pseg.lcut(text)
words, features = [], []
for word, flag in words_flags:
words.append(word)
if word in org_tag:
features.append('E')
else:
if flag in ['ns']: # 地名关键词,利用jieba的词性标注,'ns'代表地名
features.append('S')
else:
features.append('O')
labels = ''.join(features)
pattern = re.compile('S+O*E+')
match_label = re.finditer(pattern, labels)
match_list = []
for ne in match_label:
match_list.append(''.join(words[int(ne.start()):int(ne.end())]))
return match_list
text = "可在接到本决定书之日起六十日内向中国国家市场监督管理总局申请行政复议,杭州海康威视数字技术股份有限公司."
print(extract_org(text))
##result: ['中国国家市场监督管理总局', '杭州海康威视数字技术股份有限公司']
基于规则的方式有一个缺点,举例如下:

这样子可能只能返回(北京)有限责任公司
三、基于深度学习模型实现NER(原理)
3.1BiLSTM+CRF模型介绍
BiLSTM+CRF: 解决NER问题
实现方式: 从一段自然语言文本中找出相关实体,并标注出其位置以及类型。
命名实体识别问题实际上是序列标注问题: 例如输入序列是一串文字: “我是中国人”, 输出序列是一串标签: “OOBII”。 其中"BIO"是一种常用的命名实体识别标签体系: B表示这个字是词的开始, I表示词的中间到结尾, O表示其他类型词。 因此我们可以根据输出序列"OOBII"进行解码, 识别出实体中国人。 这个命名实体识别过程中符合“输入字符序列 -> 输出标签序列”的特征,所以就是序列标注问题。
序列标注问题涵盖了自然语言处理中的很多任务:包括语音识别, 中文分词, 机器翻译, 命名实体识别等, 而常见的序列标注模型包括HMM, CRF, RNN, LSTM, GRU等模型。
其中在命名实体识别技术上, 目前主流的技术: 通过BiLSTM+CRF模型进行序列标注。
3.2LSTM(长短时记忆网络)模型介绍
-
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象。
-
LSTM的设计旨在解决梯度消失和爆炸问题,并提高网络对长时间依赖关系的捕捉能力。
==传统RNN结构为什么会出现梯度消失或爆炸问题?==
因为RNN在反向传播时, 梯度要经过多个时间步的链式相乘,而每个时间步使用的相同的权重矩阵,所以就会造成梯度消失或爆炸。
-
-
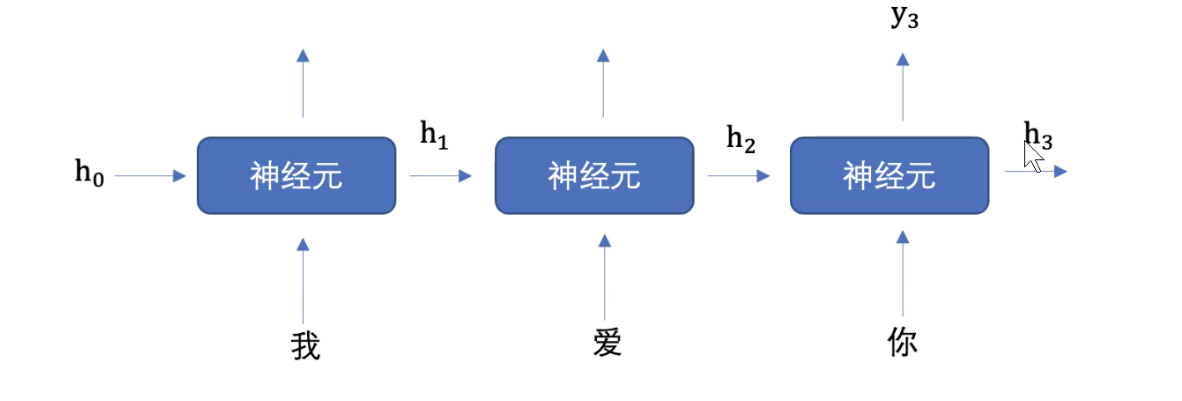
RNN结构如图所示
-
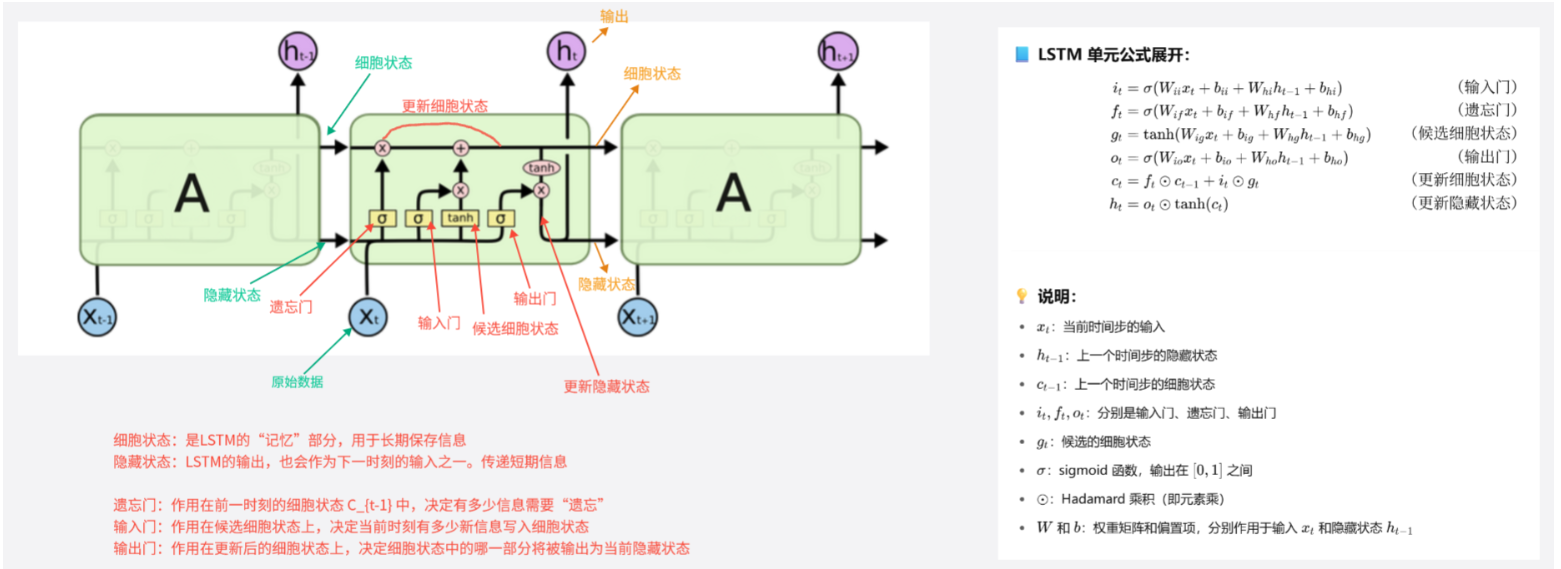
LSTM的核心改进点在于引入了记忆单元(Cell State)和一系列门控机制:
-
记忆单元(Cell State):LSTM通过引入一个长时间的记忆单元来存储重要的信息,并通过门控机制来控制信息的存储、遗忘和输出。这一设计使得LSTM能够在序列中“记住”关键信息,而非依赖单一的隐藏状态。
-
门控机制:LSTM的结构包含三个关键的门:输入门、遗忘门和输出门,这些门用于控制信息的流动和更新。
-
遗忘门:决定是否“遗忘”记忆单元中已存储的历史信息,从而允许模型有选择性地“清除”无关信息。
-
输入门:决定将当前输入的信息写入记忆单元的程度。
-
输出门:决定记忆单元中的信息在当前时间步的输出。
-
-
-
==这些门控机制使得LSTM可以“选择性地”记忆和遗忘信息,从而有效缓解了梯度消失和梯度爆炸的问题,能够更好地捕捉序列中的长时间依赖关系。==因此,LSTM相较于普通RNN在处理长序列任务(如文本生成、语音识别、时间序列预测等)中表现更为出色。
LSTM有三个输入:细胞状态、隐藏状态、原始数据
三个输出:细胞状态、隐藏状态、输出
遗忘门作用在输入的细胞状态上,决定有那些记忆会被遗忘(使用隐藏状态和输入数据决定哪些信息会被遗忘).
输入门作用在候选细胞状态上,决定那些信息可以输入到细胞状态中
输出门作用在更新细胞状态上,决定输出的细胞状态
LSTM环节梯度消失的底层原理:每个时间步都会根据自身的输入改变本身的权重矩阵,这样可以在反向传播的时候不用乘同一个权重矩阵,那么就可以缓解梯度消失的问题
-
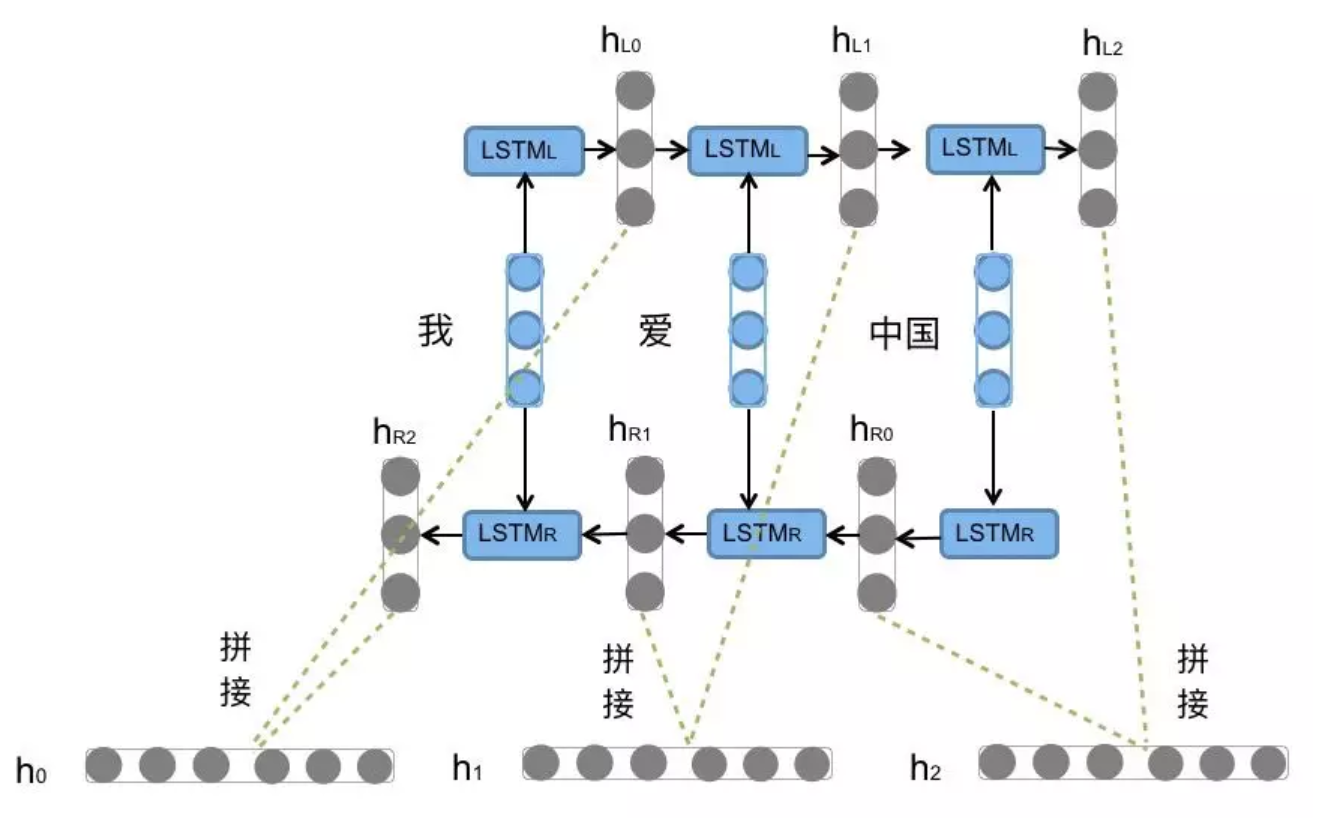
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
-
Bi-LSTM相比LSTM能同时捕捉前后文信息,提升序列建模效果,但计算成本更高、训练时间更长。
-
-
传统RNN结构为什么会出现梯度消失和爆炸问题?
因为在RNN的反向传播时,梯度要经过多个时间步的链式相乘,而每个时间步使用的是相同的权重矩阵,就会造成梯度消失或爆炸!当权重矩阵的特征值小于1时,梯度会指数级衰减(梯度消失);而当特征值大于1时,则会指数级增长(梯度爆炸)
LSTM相比RNN有什么优势?
LSTM的门控机制使得LSTM可以"选择性地"记忆和遗忘信息,从而有效缓解了梯度消失和梯度爆炸的问题,能够更好地捕捉序列中的长时间依赖关系。因此,LSTM相较于普通RNN在处理长序列任务(如文本生成、语音识别、时间序列预测等)中表现更为出色。
BiLSTM相比LSTM有什么特点?
Bi-LSTM相比LSTM能同时捕捉前后文信息,提升序列建模效果,但计算成本更高、训练时间更长。
3.3CRF模型
CRF本质上是一个概率模型,它用来描述一堆变量之间的关系,尤其是当这些变量有依赖性的时候(比如序列数据)。
3.3.1相关原理
- 条件概率:
事件A条件下事件B发生的概率:P(B|A)
- 联合概率:
既在事件A中又在事件B中的概率计算:P(A|B)=P(A)P(B|A)
- 马尔可夫性:当前的状态只依赖当前的状态,和更早的状态无关
比如你今天中午吃不吃饭,可能只取决于你现在的饥饿程度(当前状态),而跟你昨天吃了什么(更早状态)没啥关系。这就是马尔可夫性。
3.3.2CRF的核心思想
条件随机场是一类给定输入序列 𝑋 的条件下,输出标签序列 𝑌 的概率分布 𝑃(𝑌∣𝑋)的概率模型。其特点是全局考虑标签之间的依赖关系,从而提升整体预测的准确性,适用于序列标注等结构化预测任务。
简单来讲就是说:CRF首先会判断序列每个词的词性,判断好以后不会直接取概率最高的词性,而是先使用马尔可夫性判断x+1,x-1词的词性搭不搭,然后确定词性.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)