YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
代码:https://github.com/isLinXu/YOLO-Master
Abstract
本文实现了基于MoE的Yolo:
1)通过稀疏混合专家模型(Efficient Sparse Mixture-of-Experts,ES-MoE)模块实现的,该模块会根据场景复杂度动态地为每个输入分配计算资源。
2)其核心是一个轻量级动态路由网络,该网络通过增强多样性的目标来引导训练过程中的专家专精,从而鼓励专家之间互补的专业知识。
3)此外,路由网络还能自适应地学习仅激活最相关的专家,从而在提高检测性能的同时,最大限度地减少推理过程中的计算开销。
1、introduce
YOLO 类架构的最新进展主要集中在两个方向:通过改进主干设计来增强特征表示[36],以及通过改进颈部架构来优化多尺度特征融合[25]。
例如,YOLOv5 引入了 C2f 模块以更好地进行多尺度特征学习,而 YOLOv11 则融入了选择性注意力机制以增强全局表示能力。
现代大型语言模型的研究表明,稀疏激活模式(sparse activation patterns)可以显著提高效率和适应性,其中不同的输入会选择性地激活模型参数的不同子集[7, 35]。这一发现促使我们探索类似的动态计算范式是否能够从根本上重塑实时目标检测中的准确率-效率格局。
[7] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022.
[35] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
我们的方法使检测器能够根据输入内容动态激活专家网络子集,从而打破了模型容量和计算成本之间传统的静态权衡。基于MoE的设计包含三个核心机制:
(1)动态路由,训练期间采用软Top-K激活以实现梯度流,推理期间采用硬Top-K稀疏性以提高效率;
(2)高效的专家组,采用具有不同感受野(3×3、5×5、7×7)的深度可分离卷积来捕获不同的多尺度模式;
(3)负载均衡监督,确保训练期间专家资源的均匀利用,同时在部署期间保持真正的稀疏性。
我们的贡献总结如下:
• 我们提出了首个基于多尺度专家(MoE)的实时目标检测条件计算框架,从根本上打破了静态精度-效率权衡的困境,通过动态专家激活机制,使模型容量能够根据输入复杂度进行调整。
• 我们设计了一个高效稀疏多尺度专家模块,该模块包含多尺度专家和动态路由网络。我们在训练过程中使用软Top-K专家来处理梯度流,在推理过程中使用硬Top-K专家来实现真正的稀疏性,从而实现了训练稳定性和部署效率。
• 我们引入了一种专为目标检测设计的负载均衡监督机制,该机制能够防止专家崩溃,同时保持均匀的资源利用率,这对于在不牺牲推理稀疏性的前提下实现稳定的多尺度专家训练至关重要。
• 在五个不同的基准数据集(MS COCO、PASCAL VOC、VisDrone、KITTI、SKU110K)上进行的大量实验表明,我们的方法具有最先进的性能。在不同的目标密度和视觉领域中持续的改进验证了自适应计算相对于静态架构的泛化能力。
2. Related Work
Mixture of Experts
专家混合模型(MoE)最初被提出是为了通过条件计算来提升模型容量,其中门控网络将输入路由到专门的专家子网络[14]。
[14] Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural Computation, 3(1):79–87, 1991.
这种稀疏激活策略在将语言模型扩展到数万亿参数的同时,保持了可控的计算成本,取得了显著的成功[7, 19]。
[7] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022.
[19] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. In International Conference on Learning Representations, 2021.
最近的研究将MoE扩展到了计算机视觉领域,主要集中在使用Vision Transformer进行图像分类[4, 29, 33]和多任务学习[2]。
[29] Joan Puigcerver, Carlos Riquelme, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts. arXiv preprint arXiv:2308.00951, 2023.
[33] Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, Andr’e Susano Pinto, Julian Menick, Yee Whye Xu, Jasper Snoek, Tao Yang, et al. Scaling vision with sparse mixture of experts. Advances in Neural Information Processing Systems, 34:8583–8595, 2021.
[2] Yi Chen, Hongchen Tan, Tianqi Wang, et al. Modality-agnostic mixed-expert training for visionlanguage models. In International Conference on Machine Learning (ICML), 2023.
然而,将MoE应用于目标检测等密集预测任务仍未得到充分探索。与路由操作基于全局图像表示的分类不同,目标检测需要处理具有不同目标密度和尺度分布的多尺度空间特征。
初步的研究尝试将MoE集成到基于ViT的检测器中[40],但它们通常会产生巨大的计算开销,不适用于实时场景。
[40] Lemeng Wang, Soyoung Yoon, Trung Jin, James Li, Xuwang Wang, and Rose Yu Chen. Residual mixture of experts. arXiv preprint arXiv:2204.09636, 2022.
Adaptive Feature Processing
注意力机制已被广泛应用于目标检测中,通过聚焦于信息丰富的区域来动态地重新校准特征[10, 12, 13, 41, 42]。尽管有效,但这些机制对所有输入都应用相同的计算,包括通道注意力(SE [13])、空间注意力(CBAM [42])和基于Transformer的自注意力[1, 37],它们都通过静态的、与输入无关的架构运行。最近一些高效的注意力机制变体[3, 26]降低了计算复杂度,但本质上仍然是密集型的,以统一的容量处理每个空间位置。
3. Methodology
3.1. Overview of YOLO-Master
YOLO 架构(例如 YOLOv12 [36])+ 高效稀疏混合专家 (ES-MoE) 模块,以实现稀疏的、实例条件的自适应计算。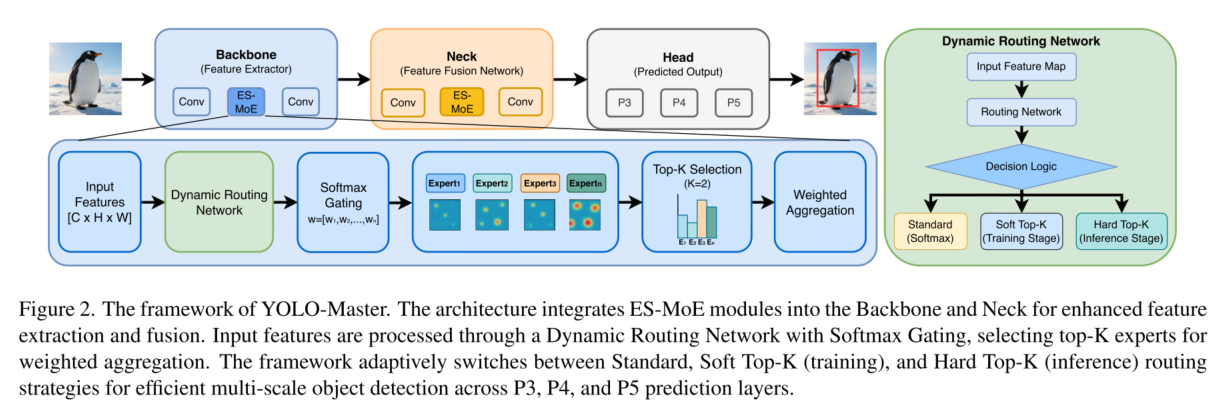
我们的 ES-MoE 模块插入到主干和颈部:在主干中,它动态地增强了不同物体尺度和场景复杂性下的特征提取;在颈部中,它实现了多尺度自适应融合和信息细化。
具体而言,ES-MoE包含三个关键组件:
i)动态路由网络,用于生成实例相关的路由信号;
ii)Softmax门控机制,用于选择最相关的专家;
iii)加权聚合单元,用于将激活的专家输出融合为更精细的表示。
在推理阶段使用硬Top-K激活以选择最相关的专家
具体而言,给定一个输入特征图 X ∈ RC×H×W,其中 C、H 和 W 分别表示通道数、高度和宽度,
1)该模块首先使用动态路由网络提取路由特征。
2)然后,这些特征被输入到 Softmax 门控机制中,以计算用于专家选择的权重分布。
令 E 表示专家总数,w = {w1, w2, …, wE} 表示分配给每个专家的门控权重。门控权重的计算公式如下: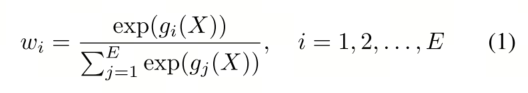
其中,g() 是gating function.
基于计算的wi,选择top-K的expert,K是比较少的,保证了稀疏性。
expert输出后进入 Weighted aggregation 聚合模型。
3.2. Dynamic Routing Network
1)每个专家架构都采用深度可分离卷积(DWconv)作为其基本构建模块,而不是标准卷积[11]。DWconv 通过将空间滤波(深度卷积)与通道信息融合(逐点卷积)解耦,显著减少了参数数量和浮点运算次数:
2) 多样化的感受野。 每个专家的 DWconv 都采用了不同的卷积核大小 ki。
3) 专家输出与聚合。每个专家 Experti 生成一个输出 Yi ∈ RCout×H×W,该输出保持与输入特征 X 相同的空间维度 H×W,并具有预定义的输出通道数 Cout。所有专家输出 Y1, . . . , YE 随后使用由动态路由机制计算的路由权重 Ω = [ω1, . . . , ωE] 进行聚合: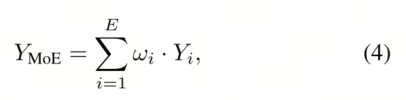
3.3. Gating Network Design
门控网络 G 在 ES-MoE 模块中起着至关重要的作用,负责生成激活 E 专家的原始 logits Λ ∈ RE×1×1。其设计遵循轻量级原则,以确保路由决策过程本身不会成为计算瓶颈 [33]。
1) 信息聚合。路由权重应源自全局上下文信息,因此,我们采用全局平均池化 (GAP) 将输入特征图压缩成紧凑的全局描述符
2)逻辑值计算。信息聚合 输入到一个参数高效的门控网络 G 中。该网络由两个 1 × 1 卷积层组成,并采用非线性激活函数。我们引入通道缩减比 γ = 8 来定义中间通道维度 Cred = max(C/γ, 8),从而限制门控网络的计算开销。
3)专家逻辑值。最后,生成专家逻辑值 Λ = Λ1, Λ2, . . . , ΛE 的计算复杂度,仅取决于通道维度 C 和专家数量 E,而与输入特征图的空间维度 H × W 无关。这种设计确保即使在架构的骨干网和颈环组件中处理高分辨率特征图时也能高效运行。
3.4. Phased Routing Strategy
路由范式设计追求 ES-MoE 框架的基本目标,即在训练期间确保全面的专家学习,同时在推理期间强制执行严格的稀疏激活以实现计算加速。这一双重目标是通过分阶段动态路由机制实现的[7, 45]。
1) 专家权重 Ω 的计算。门控网络 G 输出原始 logits Λ ∈ RE×1×1。首先,通过 Softmax 函数对 Λ 进行归一化,以获得初始权重: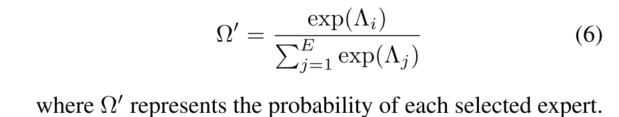
2) TopK
(详细分析下)
在 MoE 模型中,每一层有 N个专家(Experts),但每次计算只希望激活其中的 K个(K≪N),这样可以减少计算量。但如果直接用硬性的 0/1 掩码(Mask)来选专家,梯度就无法回传了(因为 0 的位置梯度直接被截断)。
所以,这里提出了一个 “软” 版本的 Top-K:它仍然选出 K个专家,同时剩余的专家也能被更新。它让模型在前向计算时表现得像只用了 Top-K,但在反向传播时却让所有专家都能“蹭”到梯度(虽然梯度都是0)。
- 硬 Top-K(传统方式):像直接淘汰。没选上的选手(专家)直接送回家,他们没有任何机会改进,也不知道自己为什么输。
- 软 Top-K(本策略):像保留训练资格。
- 舞台表现(前向):只让 Top-K 的选手上台表演(计算),其他人坐冷板凳(权重为 0)。
- 赛后复盘(反向):所有选手(包括冷板凳)都要看录像复盘,接受教练(梯度)的指导。冷板凳选手虽然这次没上台,但知道了自己差在哪里,下次可能就冲进 Top-K 了。
符号含义速查表
- Ω′\Omega'Ω′:原始的专家权重向量(未做稀疏处理的)。
- KKK:我们想保留的“活跃专家”数量。
- IK\mathcal{I}_KIK:Top-K 的索引集合,即 Ω′\Omega'Ω′ 中值最大的 KKK 个元素的下标。
- MKM_KMK:二进制硬掩码(Binary Hard Mask),只有 IK\mathcal{I}_KIK 中的位置是 1,其余是 0。
- Ωtrain\Omega_{train}Ωtrain:最终用于训练的“软 Top-K”权重。
- ϵ\epsilonϵ:一个极小的正数,防止分母为 0。
2. 第一步:生成硬掩码 MKM_KMK
公式 (7):
MK,i={1if i∈IK0otherwise M_{K,i} = \begin{cases} 1 & \text{if } i \in \mathcal{I}_K \\ 0 & \text{otherwise} \end{cases} MK,i={10if i∈IKotherwise
- 通俗理解:我们先找出 Ω′\Omega'Ω′ 中最大的 KKK 个值,记下它们的位置(索引),然后在 MKM_KMK 里把这些位置标为 1,其他标为 0。
- 作用:标记哪些专家是“被选中的”。
3. 第二步:生成软权重 Ωtrain\Omega_{train}Ωtrain
公式 (8):
Ωtrain=Ω′⊙MK∑j=1E(Ω′)j⊙(MK)j+ϵ \Omega_{train} = \frac{\Omega' \odot M_K}{\sum_{j=1}^{E} (\Omega')_j \odot (M_K)_j + \epsilon} Ωtrain=∑j=1E(Ω′)j⊙(MK)j+ϵΩ′⊙MK
- ⊙\odot⊙:这是逐元素相乘(Hadamard Product)。意思是把 Ω′\Omega'Ω′ 和 MKM_KMK 对应位置相乘。
- 结果:只有被 MKM_KMK 标记为 1 的位置保留了 Ω′\Omega'Ω′ 的原始值,其他位置变成 0。
- 分子:Ω′⊙MK\Omega' \odot M_KΩ′⊙MK —— 这就是“只保留 Top-K 的原始权重,其余清零”。
- 分母:∑j=1E(Ω′)j⊙(MK)j+ϵ\sum_{j=1}^{E} (\Omega')_j \odot (M_K)_j + \epsilon∑j=1E(Ω′)j⊙(MK)j+ϵ —— 这是把分子里那些非零值加起来(即 Top-K 权重之和),加上一个极小值 ϵ\epsilonϵ 防止除零。
- 整体作用:把分子里的 Top-K 权重做一个 归一化,让它们的和为 1。这样,Ωtrain\Omega_{train}Ωtrain 就变成了一种“概率分布”或“软权重”。
3)Hard Top-K Strategy (Inference Mode).
在推理过程中,我们追求真正的计算稀疏化。我们直接从 Λ 中选择前 K 个最大的 logits ΛK,对它们应用 Softmax 归一化 ΩK = Softmax(ΛK),并将剩余 E − K 个专家的权重严格设置为零 [35]。
3.5. Loss Function Design
包含:标准的 YOLOv8 检测损失 LYOLO 和专为 MoE 架构设计的负载均衡损失
检测损失 LYOLO:检测损失 LYOLO
它由三个核心组件构成:分类损失 Lcls,用于衡量预测类别与真实类别之间的差异;定位损失 Lloc,通常使用 CIoU 或 DIoU 损失来实现,以评估预测边界框与真实边界框之间的重叠度和位置偏差 [44];以及 Distribution Focal损失 ,用于优化边界框的分布表示 [22]。
缓解 MoE 训练中普遍存在的专家崩溃问题
负载均衡损失 (LLB) 的引入是为了缓解 MoE 训练中普遍存在的专家崩溃问题,即路由网络倾向于将大部分输入标记分配给一小部分“更强”或初始化更好的专家 [7]。LLB 通过惩罚每个专家的平均利用频率 µi 与理想均匀分布 1/E 之间的偏差,来鼓励所有专家的均衡利用。
首先,我们将专家 i 在当前批次和所有空间位置上的平均利用频率 µi 定义为:
通过最小化 LLB,我们确保模型在训练过程中充分利用所有 E 专家,从而增强其整体泛化能力和鲁棒性。(妙!)
5. 结论
本文提出了一种新型实时目标检测框架YOLO-Master,该框架在YOLO架构中引入了高效稀疏混合专家(ES-MoE)算法。我们的方法通过轻量级动态路由网络解决了模型容量和计算效率之间的根本权衡问题。我们在训练过程中采用软top-K路由来维持梯度流,并在推理过程中切换到硬top-K路由以实现真正的计算稀疏性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)