【第四周】论文精读:Hybrid Deep Searcher: Scalable Parallel and Sequential Search Reasoning
前言:当前的深度搜索代理(Deep Search Agents)陷入了一个“扩展性悖论”:单步串行搜索因信息覆盖不足而遇到瓶颈,而多步并行搜索则因缺乏结构化聚合能力导致推理混乱,两者均无法实现真正的测试时搜索扩展(Test-Time Search Scaling)。来自首尔大学与 LG AI Research 的研究团队提出了 HybridDeepSearcher,一种创新的混合搜索架构。它通过引入HDS-QA 数据集进行监督微调,教会模型在每一步中动态结合宽泛的并行查询与显式的证据聚合,从而在深入推理前构建完整的知识图谱。实验表明,该方法在 FanOutQA 和 BrowseComp 等高难度基准上分别提升 15.9 和 9.2 个 F1 点,且是唯一一个随着搜索次数(Turns)和调用量(Calls)增加而性能持续单调上升的模型。
简单来说这篇文章提出了一个多跳问答的数据集
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Hybrid Deep Searcher: Scalable Parallel and Sequential Search Reasoning |
| 核心方法名 | HybridDeepSearcher |
| 作者/机构 | Dayoon Ko, Jihyuk Kim et al. (Seoul National Univ, LG AI Research) |
| 发表年份/会议 | ICLR 2026 |
| 核心领域 | Agentic RAG, Test-Time Scaling, Hybrid Search, Supervised Fine-Tuning |
| 关键数据集 | HDS-QA (新构建), FanOutQA, BrowseComp, MuSiQue, FRAMES, MedBrowseComp |
| 基座模型 | Qwen3-8B (主要), Qwen2.5-7B, Qwen3-32B (用于数据生成) |
| 代码开源 | Project Page |
🔍 研究背景与痛点
1. “搜索扩展性失效” (The Failure of Search Scaling)
- 现象:现有的 Large Reasoning Models (LRMs) 结合 RAG 后,虽然能进行多步推理,但增加计算资源(搜索次数)并不能线性提升性能。
- 串行搜索 (Sequential Search):如 Search-R1,每步只发一个查询。
- 后果:信息覆盖窄,容易陷入局部最优。例如问“John Carpenter 导演最长的电影”,它可能先搜到一部,再搜下一部,效率极低且易漏掉关键影片。
- 并行搜索 (Parallel Search):如 RAG-R1,每步发多个查询。
- 后果:缺乏结构化聚合。模型一次性扔出大量文档,却不知道怎么在下一步推理前把这些信息“消化”掉,导致上下文混乱,过早终止搜索。
- 串行搜索 (Sequential Search):如 Search-R1,每步只发一个查询。
- 本质:现有方法要么广度不够(串行),要么深度不足(并行但无聚合),无法像人类专家那样“先广泛搜集线索,再综合归纳,最后深入挖掘”。
2. 现有解决方案的局限
- 纯 RL 训练:如 Search-R1 使用 GRPO 强化学习,倾向于让模型生成长链条,但往往只是机械地增加步数,并未学会高效的搜索策略。
- 静态分解:如 GenDec,预先分解问题,无法根据中间检索结果动态调整策略(如发现线索不够时自动扩大搜索面)。
- 数据缺失:现有的训练数据(如 HotpotQA)大多只包含简单的 2 跳推理,缺乏教导模型如何进行“大规模并行搜集 + 深度串行推理”的复杂轨迹。
3. HybridDeepSearcher 的核心洞察
- 混合即扩展:真正的可扩展搜索必须是混合式的。在需要广度的步骤(如列举所有电影)执行并行查询,在需要深度的步骤(如比较时长)执行显式聚合后的串行推理。
- 监督即可学会:不需要昂贵的在线 RL,通过高质量的**混合搜索轨迹数据(HDS-QA)**进行监督微调(SFT),就能让模型内化这种复杂的搜索策略。
🛠️ 核心方法:HybridDeepSearcher 架构详解
HybridDeepSearcher 的核心在于数据驱动的策略内化。它不依赖复杂的提示工程或在线奖励优化,而是通过特制的数据集教会模型何时并行、何时串行。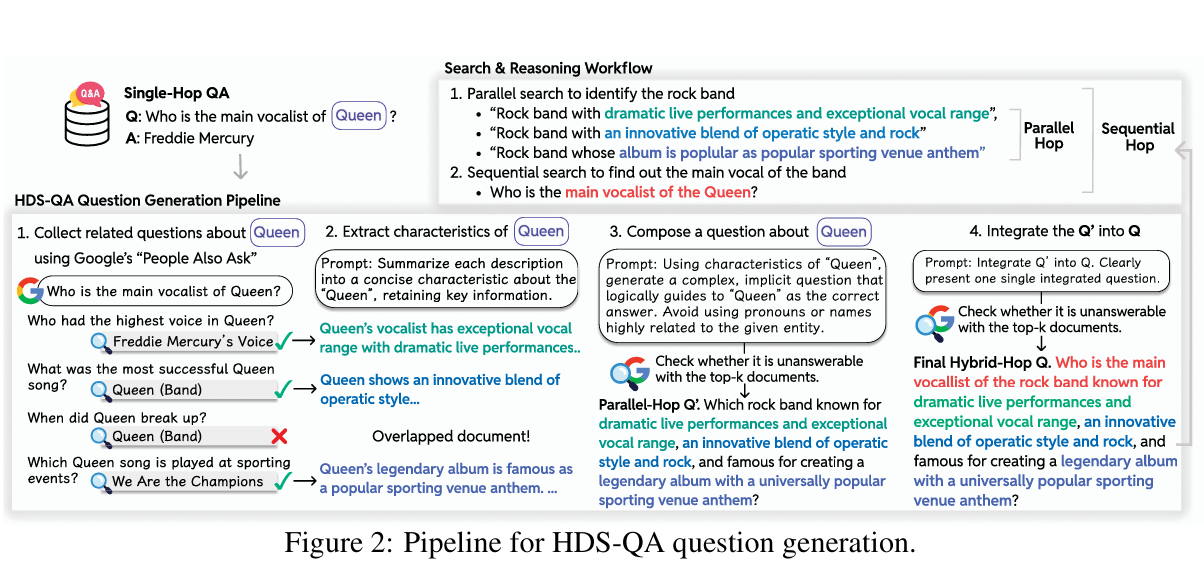
1. HDS-QA 数据集构建 —— “制造混合推理场景”
这是本文最大的贡献之一。作者设计了一套自动化流水线,专门生成需要先并行后串行的复杂问题。
-
四步生成法:
- 实体提取与相关问题收集:从单跳问题(如“Queen 乐队主唱是谁?”)提取实体,利用 Google “People Also Ask” 收集该实体的多个独立特征(如“成名曲”、“解散时间”、“风格”)。
- 特征摘要:将检索到的文档摘要为简洁的特征描述。
- 并行跳问题构造:利用这些特征构造一个隐式问题,不直接提及实体名,迫使模型必须同时搜索多个特征才能锁定实体(并行需求)。
- 例:“哪个摇滚乐队以歌剧风格融合闻名,且有一首常在体育赛事播放的国歌?”(答案隐含是 Queen)。
- 混合跳问题集成:将上述隐式问题作为条件,嵌入到原始的单跳问题中,形成最终的混合跳问题(串行需求)。
- 最终问题:“那个以歌剧风格融合闻名…的乐队,其主唱是谁?”
- 推理路径:Step 1 (并行搜特征 -> 锁定 Queen) -> Step 2 (串行搜主唱 -> Freddie Mercury)。
-
轨迹生成:使用 Qwen3-32B 生成包含并行查询块的正确推理轨迹。只有最终答案正确的轨迹会被保留,确保训练数据的准确性。共收集 2,111 条高质量轨迹。
💡 核心逻辑:传统数据教模型“一步步走”,HDS-QA 教模型“一步看全貌(并行),再走下一步(串行)”。
2. 混合搜索代理 (The Hybrid Agent)
基于 Qwen3-8B 微调而成的 HybridDeepSearcher,其推理过程具有独特的结构:
- 思维链 (Reasoning):在
<think>标签中分析当前缺口。 - 混合查询 (Querying):
- 模型被训练为在单个步骤中输出多个由分号分隔的查询。
- 格式:
<|begin search queries|> Query A; Query B; Query C <|end search queries|> - 系统会并行执行这些查询。
- 显式聚合 (Aggregation):
- 检索结果经过外部大模型(Summarizer)去噪和摘要。
- 所有结果的摘要被拼接并包裹在
<|begin search results|>标签中,作为一个整体输入给模型。 - 模型必须在下一个
<think>步骤中综合阅读这些结果,提炼出关键信息,再进行下一步决策。
类比解释:侦探办案
- 传统串行 (Search-R1):侦探每次只问一个证人。问完 A 再想问谁,效率低,容易漏掉关键团伙成员。
- 传统并行 (RAG-R1):侦探一次性把所有人叫来,七嘴八舌说话,侦探听晕了,没法理清线索,草草结案。
- HybridDeepSearcher:侦探先列出所有需要核实的线索(如:案发时间、地点、嫌疑人特征),同时派助手去调查(并行)。助手回来后,侦探先开会总结(显式聚合),整理出一份清晰的情报简报,然后再决定下一步抓谁(串行)。
🏆 实验结果与分析
作者在 5 个高难度基准上进行了全面评估,重点考察准确性和扩展性。
1. 性能全面碾压 SOTA
| 数据集 | 任务特点 | HybridDeepSearcher (F1) | 最强基线 (F1) | 提升幅度 |
|---|---|---|---|---|
| FanOutQA | 需检索大量分散实体 | 44.1 | RAG-R1 (28.2) | ↑ 56.0% |
| BrowseComp† | 极难的网络浏览推理 | 15.1 | RAG-R1 (5.9) | ↑ 155.9% |
| FRAMES | 复杂多跳事实核查 | 39.1 | RAG-R1 (35.8) | ↑ 9.2% |
| MuSiQue | 标准多跳 QA | 31.2 | Search-R1 (26.6) | ↑ 17.3% |
| MedBrowseComp | 医疗专业搜索 | 19.8 | DeepResearcher (14.7) | ↑ 34.7% |
- 注意:在 FanOutQA 这种需要“扇出”大量检索的任务中,优势最为巨大,证明了并行能力的有效性。
2. 真正的“测试时搜索扩展” (Test-Time Search Scaling)
这是本文最核心的发现。作者通过限制最大搜索轮数(Turns)和调用次数(Calls)来观察性能变化。
- 基线表现:
- 串行模型:随着 Turns 增加,性能很快** plateau (停滞)**,因为单步信息量太少,搜再多也没用。
- 并行模型:随着 Calls 增加,性能也停滞,因为无法有效聚合过多信息。
- HybridDeepSearcher 表现:
- 单调上升:无论是增加 Turns (1→8) 还是 Calls (2→16),性能都持续线性增长。
- 数据:在 BrowseComp 上,当 Turns 从 1 增加到 8 时,F1 从 4.0 飙升至 15.1 (3.8 倍提升);当 Calls 从 2 增加到 16 时,F1 从 3.4 飙升至 15.1 (4.4 倍提升)。
- 结论:只有混合策略才能真正利用更多的计算资源来解决更难的问题。
3. 证据覆盖率 (Evidence Coverage)
- 在 FanOutQA 上,HybridDeepSearcher 的金标证据覆盖率高达 61.0%,而最强的并行基线 RAG-R1 仅为 53.2%,串行基线 Search-o1 仅为 38.3%。
- 这证明模型确实学会了“把网撒得更大”,从而捕获了更多必要的碎片信息。
4. 消融实验与 RL 的对比
- 混合行为是关键:如果只用 HDS-QA 数据但强制模型单步单查(去除并行),性能大幅下降,甚至不如基线。证明并行+聚合的混合行为本身才是增益来源。
- SFT vs RL:作者在 HybridDeepSearcher 基础上又加了 GRPO (RL) 训练。
- 结果:RL 能略微提升准确率,但会导致搜索步数显著增加,效率 (AUC) 反而下降。
- 启示:对于搜索策略的学习,高质量的监督微调 (SFT) 比盲目试错的 RL 更高效、更直接。
💡 主要创新点总结
- 提出“混合搜索”范式:首次明确指出了单纯串行或并行搜索在扩展性上的缺陷,并提出了“并行搜集 + 显式聚合 + 串行推理”的闭环架构。
- 构建 HDS-QA 数据集:填补了训练数据中“大规模并行推理轨迹”的空白,通过自动化流水线生成了 2000+ 条高质量混合跳问答数据。
- 验证了 SFT 的有效性:证明了通过精心设计的监督数据,小模型(8B)也能学会复杂的搜索调度策略,且效果优于昂贵的在线 RL 方法。
- 实现了真正的测试时扩展:模型性能随资源投入(搜索次数)单调递增,解决了当前 Agentic RAG“算力堆砌无效”的痛点。
⚠️ 局限性与挑战
- 数据依赖性:模型的表现高度依赖于 HDS-QA 数据的质量和分布。如果真实场景中的问题模式与训练数据差异过大(如不需要并行只需极深串行),效果可能打折。
- 摘要器开销:为了处理并行检索的大量噪音,系统依赖一个强大的外部摘要模型(实验中用了 32B 模型),这增加了系统的延迟和成本(尽管论文提到用 8B 摘要器效果下降不多)。
- 长上下文压力:虽然做了聚合,但在极端并行下,聚合后的上下文长度仍可能对基座模型的注意力机制构成挑战。
🚀 对开发者的实战建议
如果你正在构建需要高准确度、复杂推理的 RAG 应用(如深度研报、法律案情分析):
-
实施“并行 - 聚合”循环:
- 不要让用户的问题直接触发单条搜索。让 Agent 先思考:“要回答这个问题,我需要哪几个方面的信息?”
- 动作:一次性并发执行 3-5 个不同维度的搜索查询。
- 关键:在拿到结果后,必须有一个独立的步骤(或 Prompt 指令)让模型对这些结果进行“综合摘要”或“冲突消解”,然后再决定是否进行下一轮搜索。
-
构建自己的“混合轨迹”数据:
- 如果资源允许,模仿 HDS-QA 的思路,收集一些需要多路并行的复杂问题,并人工或通过大模型编写“标准推理过程”(包含并行查询和综合步骤)。
- 用这些数据对你的 RAG Agent 进行微调,比单纯调 Prompt 效果好得多。
-
动态资源分配:
- 对于简单问题,限制并行度;对于检测到实体多、条件复杂的问题(如“比较 A、B、C 三个产品的参数”),自动放宽并行查询的数量限制。
-
优先选择 SFT 而非 RL:
- 在搜索策略优化上,先尝试构建高质量的 Few-shot 示例或进行 SFT。除非你有极强的算力和奖励模型设计能力,否则不要轻易上 PPO/GRPO,性价比可能不高。
一句话总结:HybridDeepSearcher 证明了**“先广撒网(并行),再精提炼(聚合),后深挖掘(串行)”**是人类解决复杂问题的核心智慧,也是让 AI 搜索代理真正具备扩展性的唯一路径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)