基于Matlab的BiLSTM分类算法实践分享[特殊字符]
78.基于matlab的BiLSTM分类算法,输出迭代曲线,测试集和训练集分类结果和混淆矩阵,程序有详细注释,数据可更换自己的,程序已调通,可直接运行。
最近在做一些分类任务相关的项目,用到了基于Matlab的BiLSTM分类算法,今天来给大家分享一下整个过程😃。
一、算法概述
BiLSTM(Bidirectional Long Short-Term Memory)是一种强大的循环神经网络结构,它结合了前向LSTM和后向LSTM的输出,能够更好地处理序列数据中的上下文信息🧐。在分类任务中,它可以有效地捕捉序列的长期依赖关系,从而提高分类的准确性。
二、程序实现
下面是关键的Matlab代码部分:
% 清除工作区和命令窗口
clear all;
clc;
% 加载数据
data = load('your_data_file.mat'); % 这里记得把'your_data_file.mat'换成自己的数据文件名
X = data.X;
Y = data.Y;
% 划分训练集和测试集
[trainX, testX, trainY, testY] = splitData(X, Y, 0.8); % 80%作为训练集
% 数据预处理
trainX = preprocessData(trainX);
testX = preprocessData(testX);
% 创建BiLSTM网络
numFeatures = size(trainX, 2);
numHiddenUnits = 64;
layers = [ ...
sequenceInputLayer(numFeatures)
bilstmLayer(numHiddenUnits)
fullyConnectedLayer(size(unique(trainY), 1))
softmaxLayer
classificationLayer];
% 训练网络
options = trainingOptions('adam', ...
'MaxEpochs', 50, ...
'MiniBatchSize', 64, ...
'InitialLearnRate', 0.001, ...
'Shuffle', 'every-epoch', ...
'Verbose', false, ...
'Plots', 'training-progress');
net = trainNetwork(trainX, trainY, layers, options);
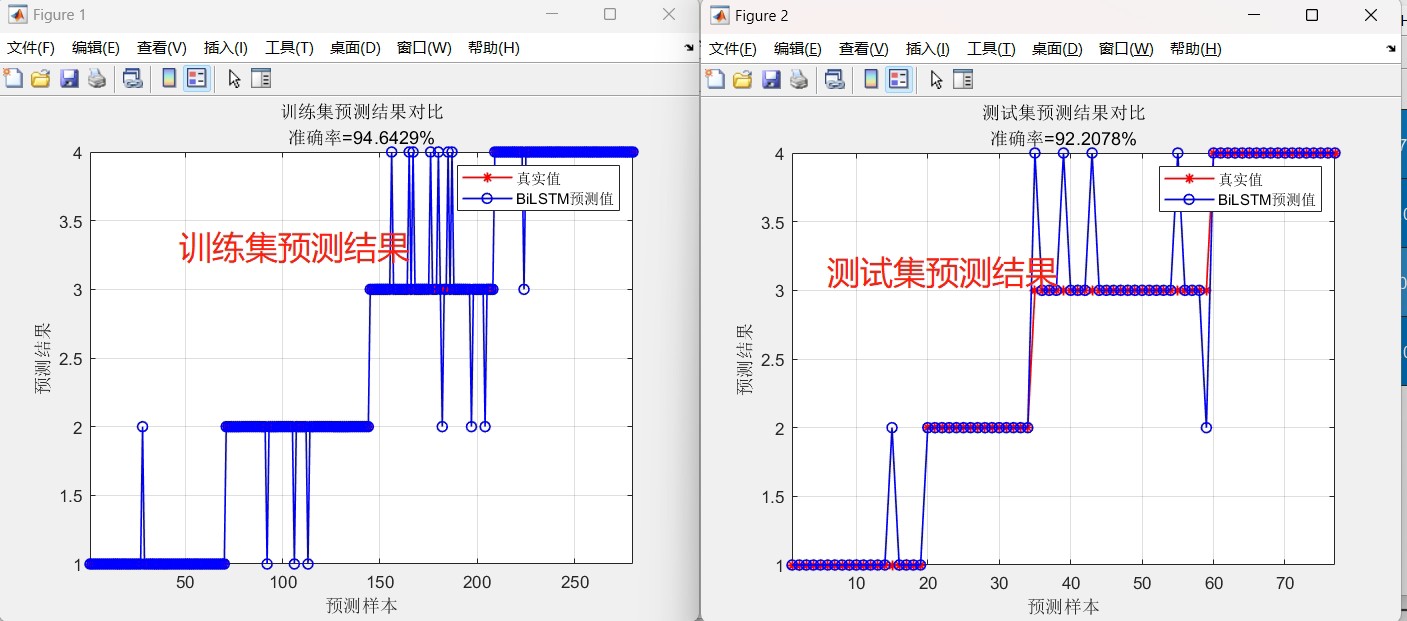
% 预测
predictedLabels = classify(net, testX);
% 计算分类结果
trainAccuracy = sum(trainY == classify(net, trainX)) / numel(trainY);
testAccuracy = sum(testY == predictedLabels) / numel(testY);
% 生成混淆矩阵
confusionMatrix = confusionmat(testY, predictedLabels);
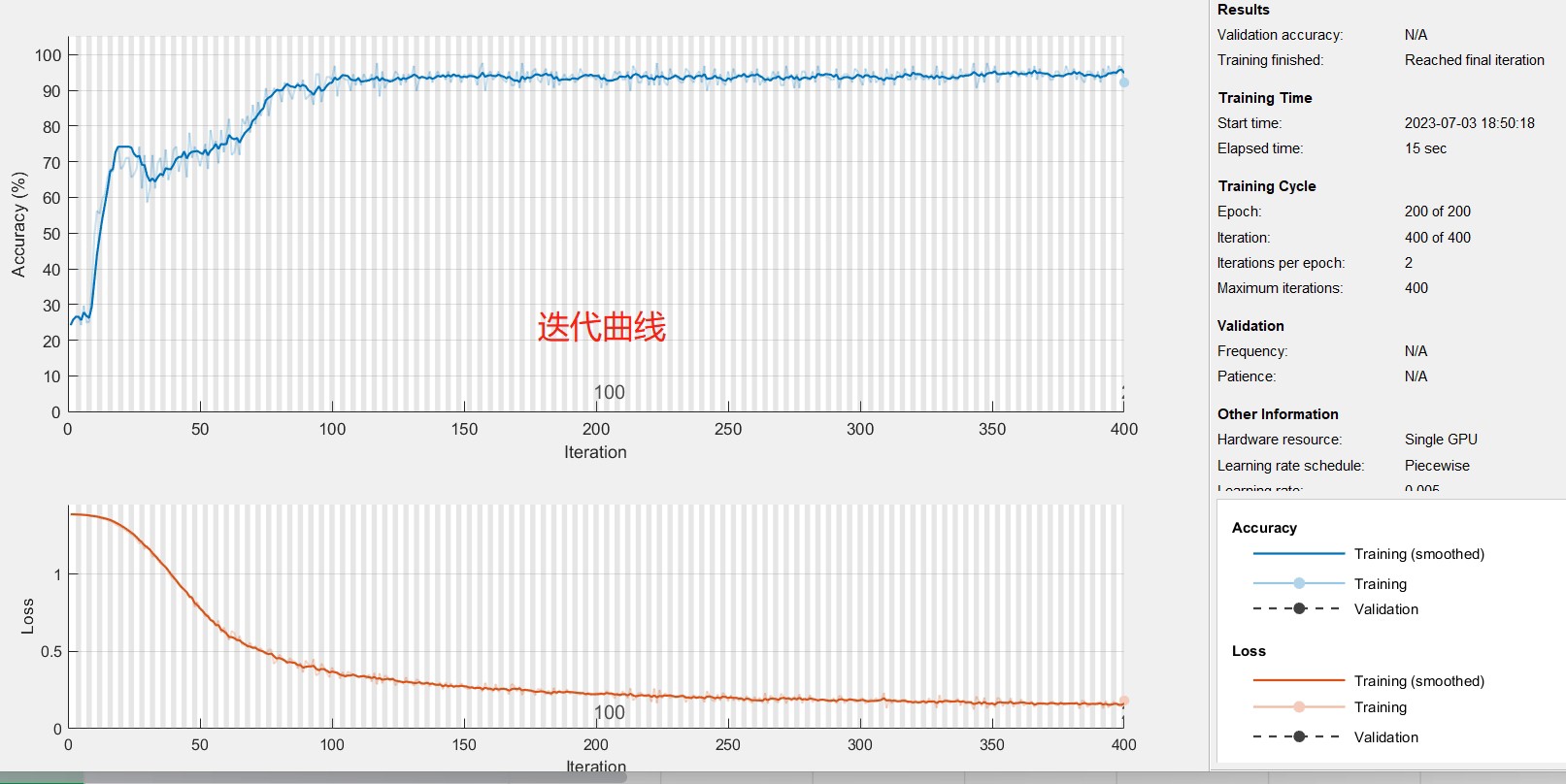
% 绘制迭代曲线
figure;
plot(net.Layers(end).OutputWeights.MovingAverageLoss);
title('Training Loss');
xlabel('Epoch');
ylabel('Loss');
% 输出结果
disp(['训练集准确率: ', num2str(trainAccuracy)]);
disp(['测试集准确率: ', num2str(testAccuracy)]);
disp('混淆矩阵:');
disp(confusionMatrix);代码分析
- 数据加载与划分:
`matlab
data = load('yourdatafile.mat'); % 这里记得把'yourdatafile.mat'换成自己的数据文件名
X = data.X;
Y = data.Y;
[trainX, testX, trainY, testY] = splitData(X, Y, 0.8); % 80%作为训练集
`
这部分代码首先加载你自己的数据文件,然后使用splitData函数(这里假设已经定义好了这个函数)将数据划分为训练集和测试集。
- 数据预处理:
matlab
trainX = preprocessData(trainX);
testX = preprocessData(testX);preprocessData函数用于对数据进行预处理,比如归一化等操作,以提高模型的训练效果。
- 网络创建:
matlab
numFeatures = size(trainX, 2);
numHiddenUnits = 64;
layers = [ ...
sequenceInputLayer(numFeatures)
bilstmLayer(numHiddenUnits)
fullyConnectedLayer(size(unique(trainY), 1))
softmaxLayer
classificationLayer];
这里定义了BiLSTM网络的结构。首先获取输入数据的特征数量,然后设置隐藏层单元数为64。接着依次定义了输入层、BiLSTM层、全连接层、softmax层和分类层。
- 网络训练:
`matlab
options = trainingOptions('adam', ...
'MaxEpochs', 50, ...
'MiniBatchSize', 64, ...
'InitialLearnRate', 0.001, ...
'Shuffle', 'every-epoch', ...
'Verbose', false, ...
'Plots', 'training-progress');
net = trainNetwork(trainX, trainY, layers, options);
`
使用trainingOptions函数设置训练参数,如优化算法为adam,最大迭代次数为50,小批量大小为64等。然后使用trainNetwork函数训练网络。
- 预测与结果计算:
`matlab
predictedLabels = classify(net, testX);
trainAccuracy = sum(trainY == classify(net, trainX)) / numel(trainY);
78.基于matlab的BiLSTM分类算法,输出迭代曲线,测试集和训练集分类结果和混淆矩阵,程序有详细注释,数据可更换自己的,程序已调通,可直接运行。
testAccuracy = sum(testY == predictedLabels) / numel(testY);
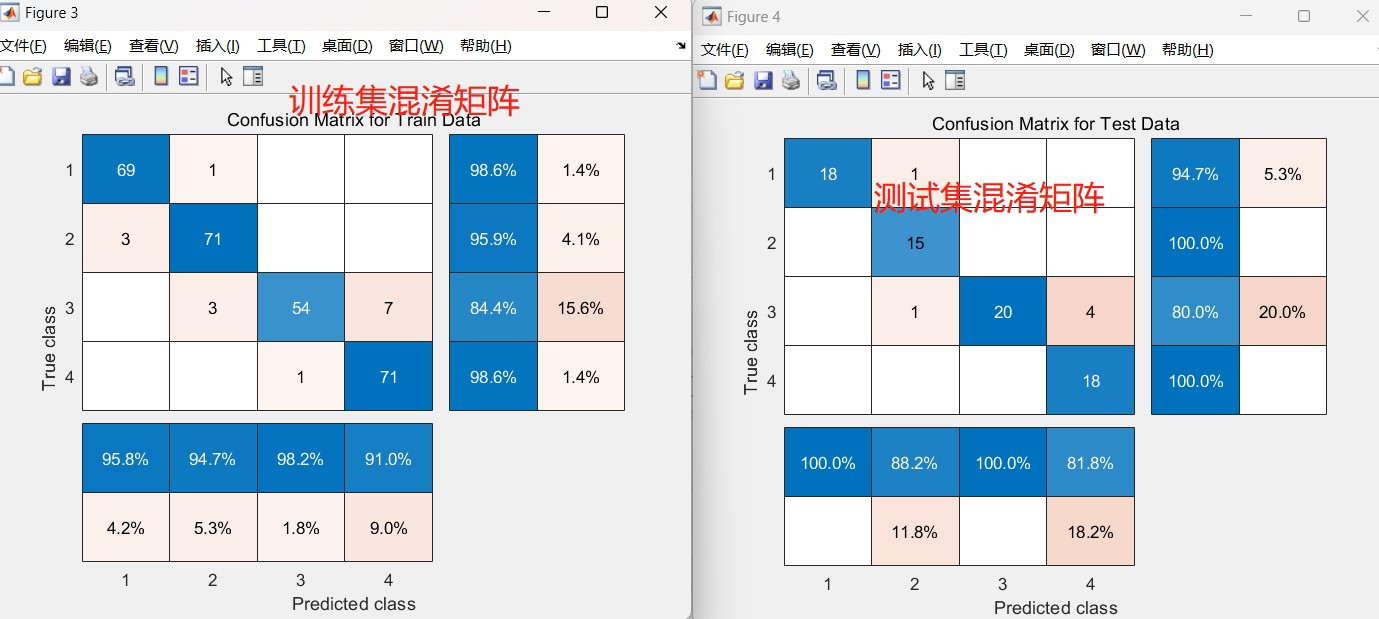
confusionMatrix = confusionmat(testY, predictedLabels);
`
使用训练好的网络对测试集进行预测,然后计算训练集和测试集的准确率,并生成混淆矩阵。
- 绘制迭代曲线:
matlab
figure;
plot(net.Layers(end).OutputWeights.MovingAverageLoss);
title('Training Loss');
xlabel('Epoch');
ylabel('Loss');
绘制网络训练过程中的损失迭代曲线,直观地展示训练的进展情况。
三、总结
整个基于Matlab的BiLSTM分类算法实现过程还是比较清晰的😁。通过上述代码,我们可以方便地加载自己的数据,训练模型,并得到训练集和测试集的分类结果以及混淆矩阵,还能直观地看到训练过程中的损失变化。大家如果有类似的序列分类任务,不妨试试这个方法呀🧐!
希望这篇分享对大家有所帮助😎,如果有任何问题或者想法,欢迎在评论区留言交流🤗。
以上代码中的函数splitData和preprocessData需要根据具体的数据情况进行定义和实现哦😉。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)