Chroma DB与FAISS等向量数据库中的层次可导航小世界 (HNSW)索引算法介绍
层次可导航小世界 (HNSW)
预计阅读时间:30分钟
什么是 HNSW?
想象一下,你正在一个大城市里寻找一家特定的餐厅。你不会逐个检查每一家餐厅,而是使用像 Google Maps 这样的智能导航系统。你从一个显示主要高速公路的缩略图开始,然后逐渐放大以查看小街道,最后到达你的确切目的地。这基本上就是层次可导航小世界(HNSW)算法的工作原理——但它不是用来寻找餐厅,而是用来在庞大的数据库中寻找相似的数据点。
HNSW 是一种复杂的基于图的搜索算法,旨在快速找到与您所寻找的项相似的物品。在处理计算机科学家所称的“高维数据”时,它特别强大——想象一下复杂的信息,比如句子的含义、图像的特征或音乐中的模式。该算法最初在 Yu. A. Malkov 和 D. A. Yashunin 于 2016 年发表的开创性研究论文中描述,标题为 Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
基础构件:理解组件
1. 小世界网络
想想你是如何与其他人联系的。你直接认识你的朋友,通过他们,你可以联系到他们的朋友,依此类推。令人惊讶的是,研究表明,世界上任何两个人之间平均只相隔六度。这创造了科学家所称的“小世界”——一个你可以相对快速地联系到任何人的网络。
小世界网络有两个关键特征:
- 高聚类系数:节点倾向于形成紧密的群体,邻居之间有很多连接
- 低平均路径长度:尽管存在聚类,你可以在几步之内从任何节点到达任何其他节点
HNSW 将这一原理应用于数据。数据点不是彼此认识,而是“连接”到相似的数据点,形成一个网络,让你可以快速地从任何一点导航到任何另一点。这个概念最早由邓肯·瓦茨和史蒂文·斯特罗戈茨在他们1998年的影响力论文中正式提出,并为许多现代搜索算法奠定了数学基础。
2. 可导航网络
在可导航网络中,你不仅仅拥有随机连接 - 你拥有智能连接,帮助你朝着正确的方向移动。就像有路标指引你到达目的地。在 HNSW 中,每个数据点与其他点相连,以帮助引导搜索朝向目标。
可导航小世界 (NSW) 算法是 HNSW 的基础,通过一种称为 greedy routing 的过程工作:
- 从图中的一个入口点开始
- 查看所有直接连接的邻居
- 移动到离目标最近的邻居
- 重复直到无法更接近
这种贪婪搜索的时间复杂度为 O(log^k n),显著快于对所有数据点进行的naive linear search。
3. 层次结构
在这里,HNSW展现了其真正的聪明之处。它并不是只有一个网络,而是创建了多个层次——就像一座有不同楼层的摩天大楼。层次概念受到skip lists的启发,这是一种维护多个层次链表的概率数据结构。
以下是各层的工作原理:
顶层(层):数据点非常少,但它们通过可以在数据空间中远距离跳跃的“长距离”链接相连。可以把这些看作是快速公路。在层L中,只有大约1/2^L的节点出现,概率呈指数下降。
中间层:有更多的数据点,连接为中距离。它们就像城市中的主要道路。每向下一个层级,节点数量增加,连接的范围逐渐缩短。
底层(最底层):包含所有数据点,连接为短距离。这些就像本地街道,您可以在这里找到确切的目的地。数据集中每个数据点都存在于层0。
每个节点的层级分配是通过使用指数衰减分布的概率方式确定的,类似于skip lists的工作原理。
HNSW工作原理 - 直观感受
在深入了解索引的构建之前,让我们来看看如何使用HNSW索引进行搜索:
第一步:从 HNSW 索引开始
下图展示了一个层次可导航的小世界图。
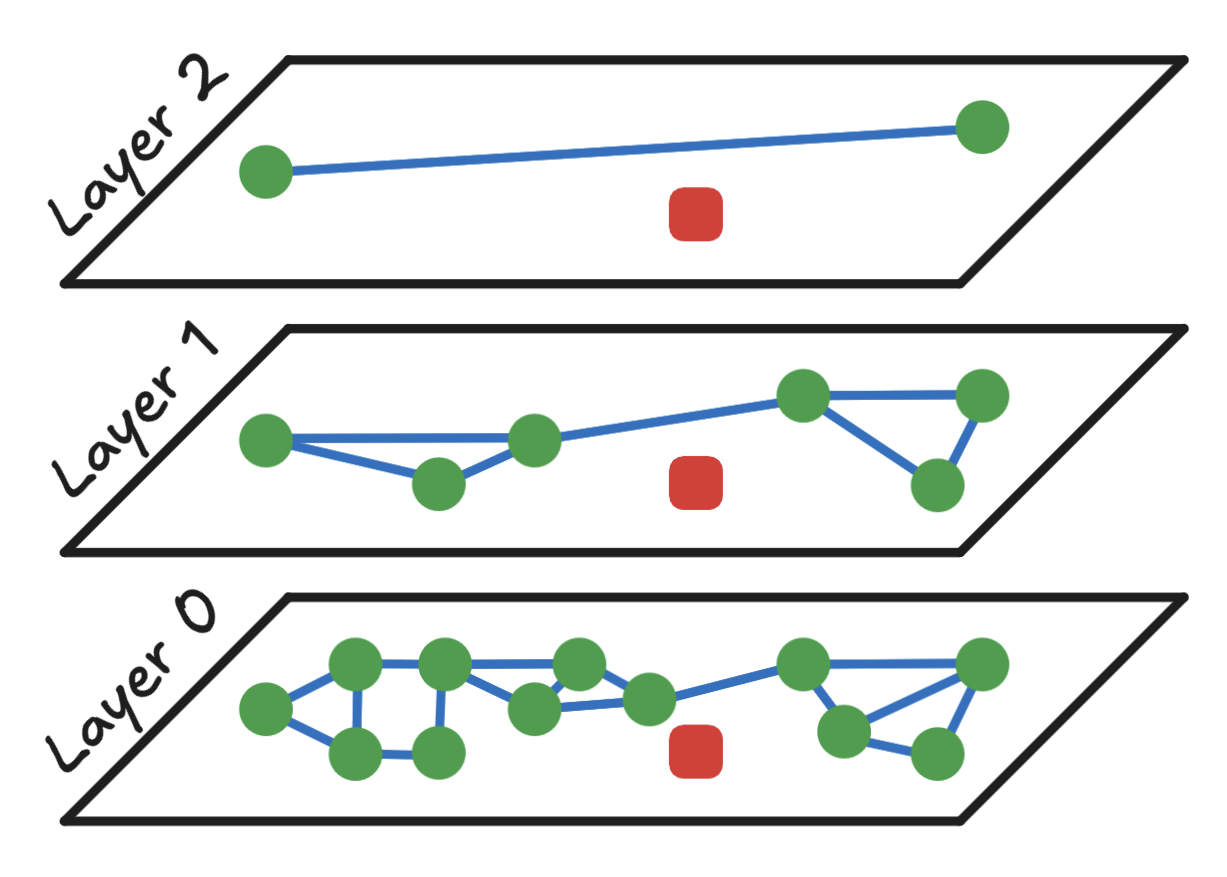
底层(Layer 0)包含所有数据点,以绿色圆圈表示,其中一些是相互连接的。HNSW 算法的目标是找到给定查询点的近似最近邻,查询点用红色矩形表示。在向量数据库的上下文中,绿色圆圈代表数据嵌入,而红色方块代表查询(query)嵌入。
在这个例子中,有 12 个数据点。暴力搜索需要计算查询与这 12 个点之间的距离(例如,余弦距离或 L2 距离)。而 HNSW 则通过更少的计算实现近似解。
一些数据点,包括查询点,被投影到更高的层次中,每个后续层包含的点数更少。以下图像显示了如何通过虚线连接跨层的相同数据点:
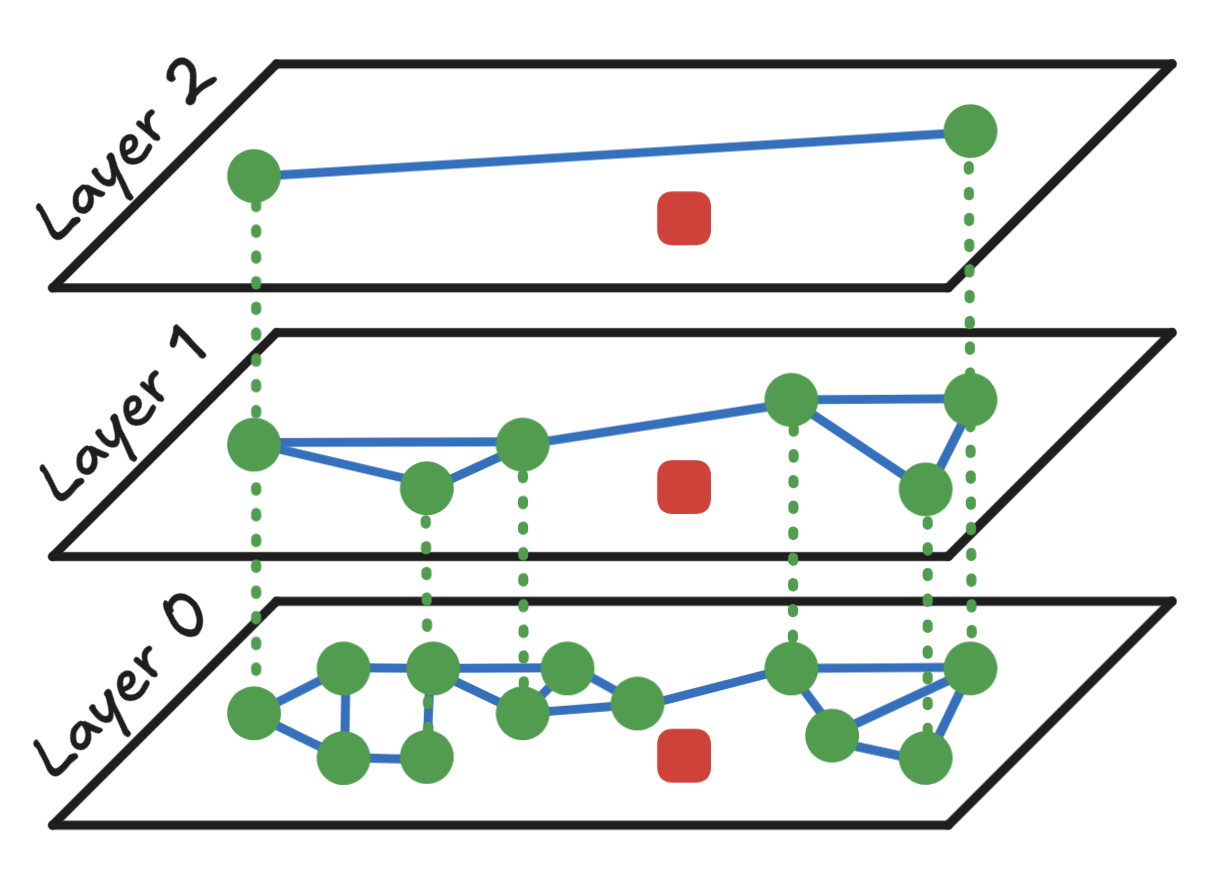
请注意,高层中的连接不一定与低层中的连接相同。
第2步:在顶层的随机点进入HNSW索引
在下面的图示中,搜索从顶层(Layer 2)中随机选择的一个点开始,标记为橙色点,标签为1,称为入口点。
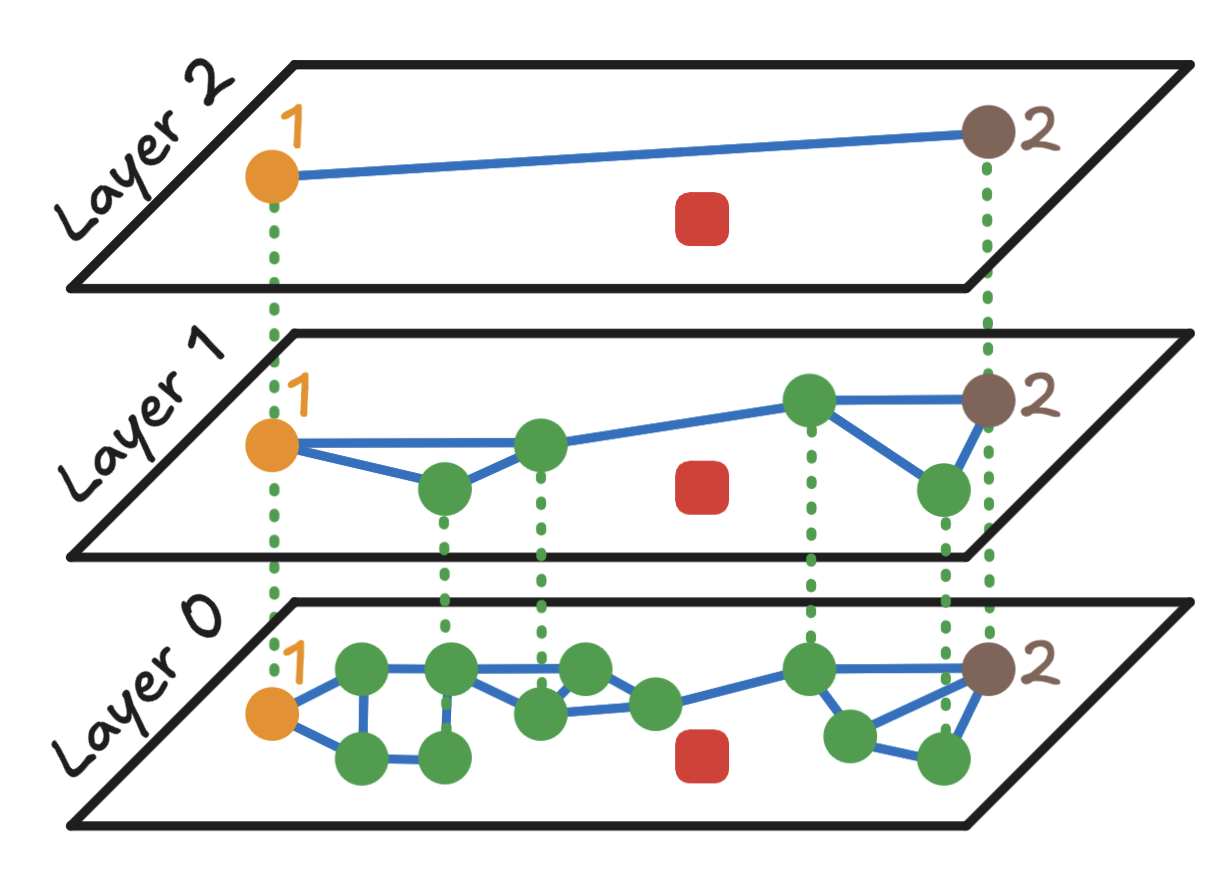
第3步:在当前层进行贪婪搜索
此步骤包括以下子步骤:
- 3.1:计算入口点与查询之间的距离。
- 3.2:计算查询与当前层入口点所有邻居之间的距离。
- 3.3:确定与查询距离最小的点。
- 3.4:如果最近的点是入口点,则继续进行第4步。
- 3.5:如果最近的点没有未探索的邻居,则继续进行第4步。
- 3.6:否则,将最近的点设为新的入口点,并从第3.1步重新开始。
在这个例子中:
- 从
Layer 2中的点1开始。 - 计算点
1及其唯一邻居点2与查询的距离。 - 点
2距离查询更近,因此它成为新的入口点。 - 由于点
2没有未探索的邻居,继续进行第4步。
第4步:向下移动一层并重复
现在移动到 Layer 1,使用点 2 作为入口点。
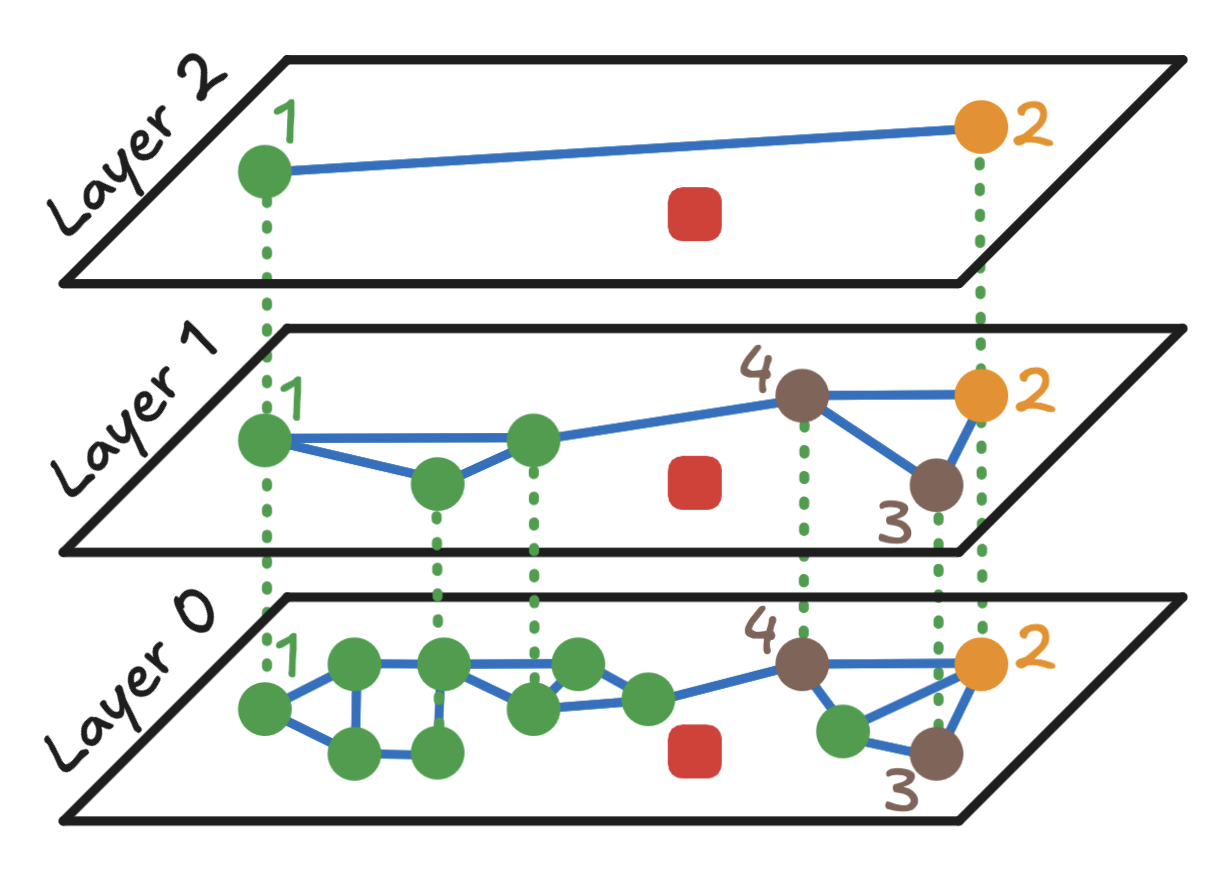
- 重用之前计算的点
2和查询之间的距离。 - 计算点
2在Layer 1的邻居(点3和4)与查询点的距离。 - 点
4最近。然而,点4不是入口点,并且有未探索的邻居,因此它成为Layer 1的新入口点。
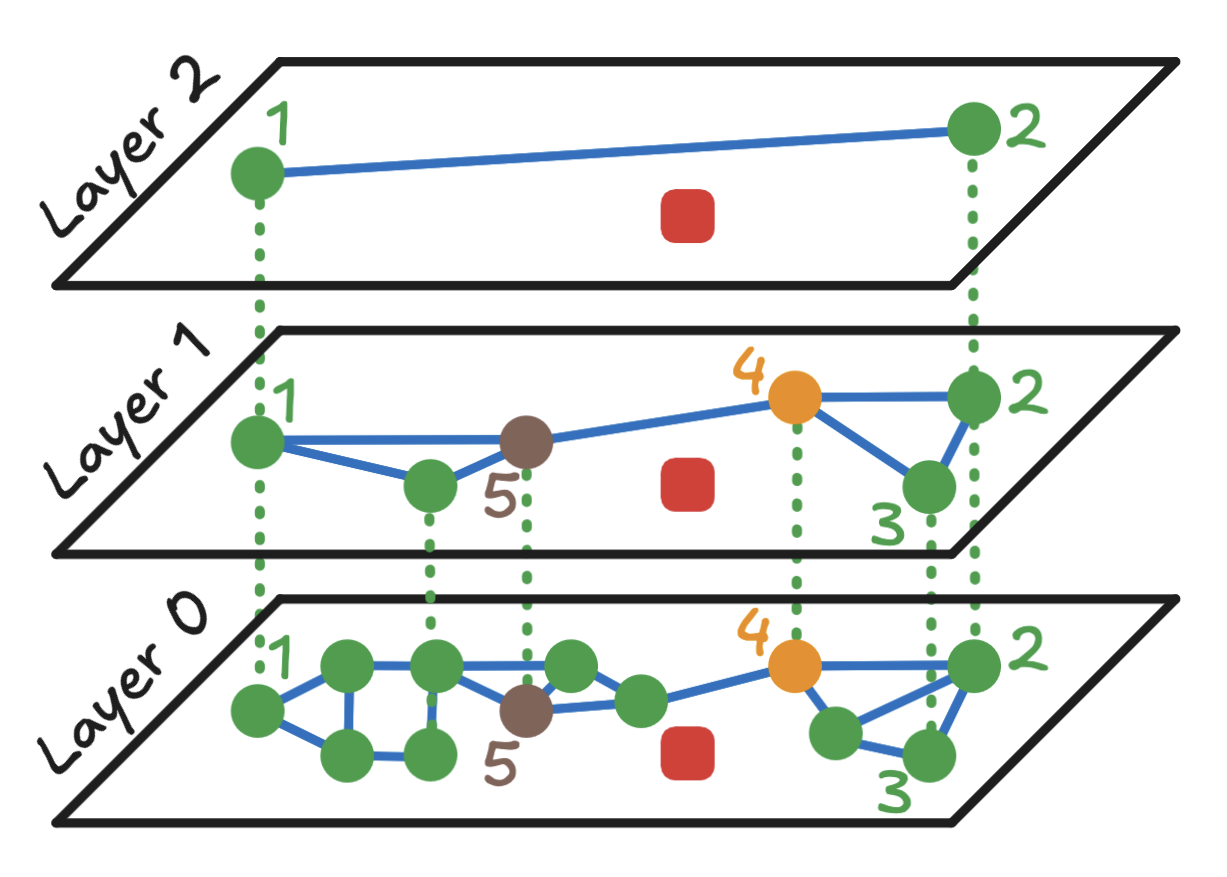
- 计算点
4和查询之间的距离(已经知道)。 - 计算新的邻居点
5与查询的距离(邻居2和3已经考虑过,可以安全忽略)。 - 点
4仍然是最近的,因此以点4作为入口继续进入Layer 0。
第5步:在底层进行最终搜索
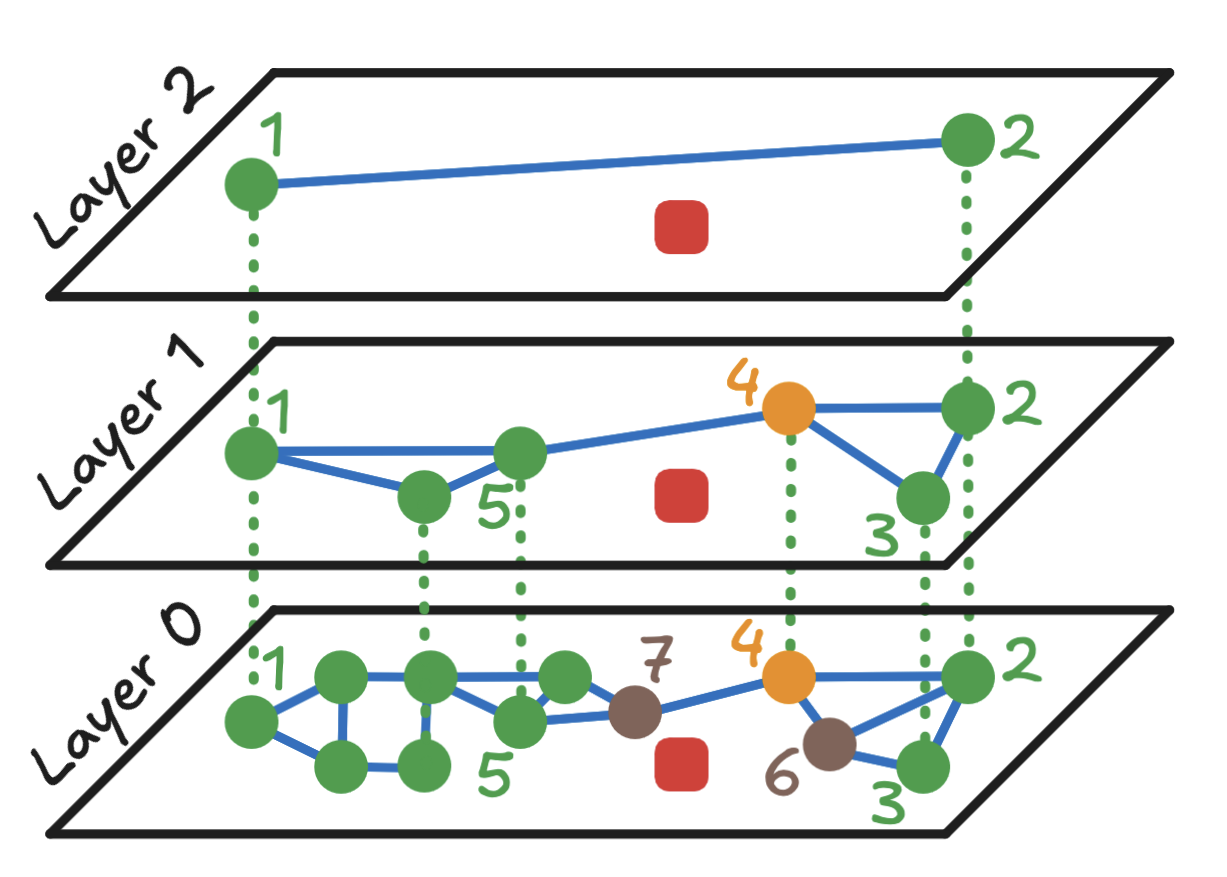
- 从点
4开始,计算与其在层0中的邻居(点2、6和7)的距离。实际上,点2被忽略,因为之前已经考虑过。 - 点
7是最近的,成为新的入口点。
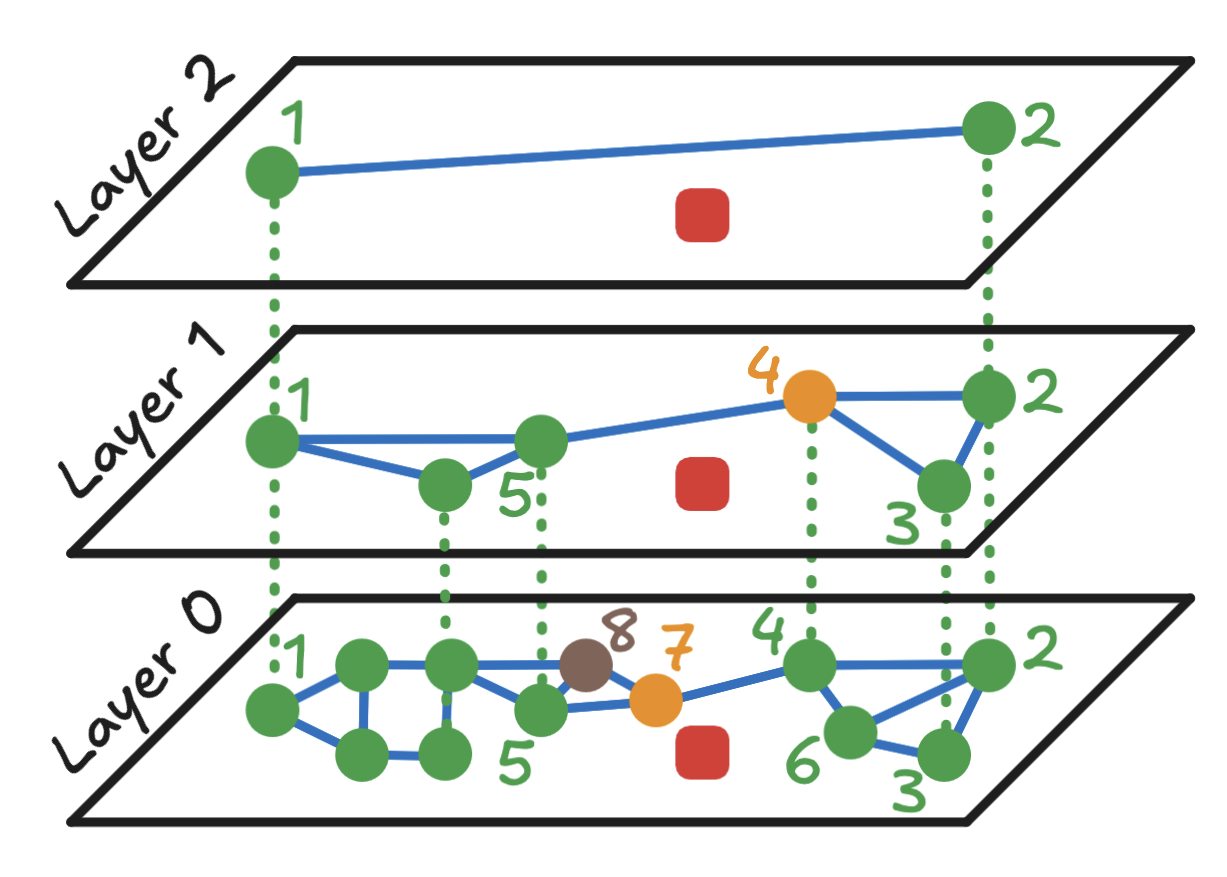
- 在点
7的邻居中,只有点8是未搜索的。 - 点
7仍然是最近的,因此搜索结束。
第6步:返回近似最近邻
该算法将点 7 作为近似最近邻返回。虽然 HNSW 由于其贪婪特性并不能保证找到确切的最近邻,但如果没有找到精确解,它通常会找到一个非常接近的匹配。在这个例子中,仅需要 8 次距离计算,而暴力搜索则需要 12 次。在具有优化图和更大数据集的实际场景中,效率提升更加显著。
现在我们已经探讨了 HNSW 如何执行搜索——通过贪婪路由从粗到细的层级导航——理解这个强大结构是如何构建的同样重要。下一部分将逐层介绍构建 HNSW 索引的过程,揭示数据点是如何组织的,以实现如此高效和可扩展的搜索性能。
HNSW索引的构建 — 步骤详解
想象一下你正在构建一个智能城市地图,每栋建筑(数据点)都以某种方式与其他建筑相连,帮助你找到到达任何目的地的最快路线。这就是HNSW的作用 — 但它处理的是数据。
第一步:从空图开始
- 一开始,没有任何结构——只有一个空白区域。
- 你插入的第一个数据点成为所有未来插入和搜索的起点(称为入口点)。
步骤 2:为每个数据点分配高度(层级)
- 每个数据点可以被视为城市中的一座建筑。
- 一些建筑很高(它们出现在更高的层级),而一些则较矮(它们只出现在底层)。
- 高度是随机选择的,但较高的建筑较为稀少。这个分配遵循指数递减的概率分布:
- 大多数点只出现在底层(层级 0)。
- 少数出现在更高的楼层(层级 1、2、3,等等)。
- 这种分层结构帮助算法从广泛的概览“缩放”到细节。
第3步:将点插入图中
对于每个新点:
a. 从顶层开始
- 从当前入口点所在的最高层开始。
- 使用一种称为贪婪搜索的方法:查看当前点的邻居,移动到离新点最近的那个。
- 重复此过程,直到在该层无法更靠近为止。
b. 向下移动一层
- 一旦到达当前层的最佳位置,向下移动到下一层。
- 从前一层找到的最佳点重复贪婪搜索。
c. 连接邻居
- 在每一层(从上到下),新点连接到其M个最近的邻居。
- 这些连接是双向的——两个点彼此了解。
- 这创建了一个小世界网络,使数据点之间的快速遍历成为可能。
第 4 步:对所有点重复该过程
- 每个新点都经过相同的过程:分配高度,从顶部搜索,并在每个层级连接到邻居。
- 随着时间的推移,这构建了一个多层图,搜索速度很快。
控制构建和搜索过程的关键参数
1. M — 每个节点的最大连接数
- 控制每个点连接多少个邻居。
- 更高的 M = 更好的准确性,更多的内存使用。
- 更低的 M = 更快的构建,较少的内存,较低的准确性。
2. efConstruction — 构建期间的搜索广度
- 控制在插入时考虑多少候选者以寻找邻居。
- 更高的 efConstruction = 更好的图质量,构建速度较慢。
- 更低的 efConstruction = 构建速度较快,但后续搜索质量可能较低。
3. efSearch — 查询时的搜索广度
- 在您搜索图形时使用(而不是构建它)。
- 控制在查询期间探索多少候选节点。
- 较高的 efSearch = 更好的准确性(更有可能找到真正的最近邻),但搜索速度较慢。
- 较低的 efSearch = 更快的搜索,但可能会错过最佳匹配。
- 这是在查询时调整速度与准确性的主要参数。
4. ml — 层级倍增器
- 影响一个点在更高层级出现的可能性。
- 控制层级的形状 — 更多或更少的高楼。
为什么这有效
- 顶层帮助你在数据空间中进行大幅跳跃——就像高速公路一样。
- 底层提供细致的细节——就像地方街道一样。
- 这种组合使得 HNSW 即使在巨大的数据集中也能快速且准确。
第一步:从顶部开始
当你想找到与查询相似的内容时,HNSW 从顶层开始。这里只有少数几个点,但它们的位置经过精心安排,并通过长距离链接相连。算法从一个预定的 入口点 开始,通常是索引构建过程中最近插入的节点。
第2步:朝着目标前进
算法执行贪婪路由:它查看当前点并询问:“我连接的邻居中,哪个离我想要的目标最近?”然后跳到那个邻居。这个过程重复进行,每次跳跃都更接近目标。
第 3 步:下移一层
一旦它在当前层无法再靠近(达到局部最小值),就会下移到下一层。该层具有更多的点和更精确的连接,从而允许更精细的导航。
第4步:重复直到到达底部
算法继续这个过程 - 尽可能使用贪婪搜索进行导航,然后向下移动一层 — 直到到达所有数据点存在的底层。
第5步:寻找最佳匹配
在底层(层0),它执行最终的贪婪搜索,以找到与您的查询最相似的项目。如果指定,算法可以返回多个近似最近邻。
时间复杂度:层次结构使得对数搜索复杂度为 O(log n),相比之下,暴力搜索的复杂度为线性 O(n)。
权衡:理解局限性
近似结果
HNSW 提供快速而准确的结果,尽管它有时可能会错过确切的最近邻。典型的召回率在 90% 到 99% 之间,这意味着它有 90-99% 的几率找到真实的最近邻。对于大多数应用来说,这种权衡是值得的。
参数调整
从 HNSW 获取最佳性能需要调整各种设置:
关键参数:
- M(最大连接数):更高的 M = 更好的召回率,但需要更多内存
- efConstruction:影响构建质量的构建时参数
- efSearch:影响速度/准确性权衡的查询时参数
- ml(层级倍增器):控制层概率分布
调整指南:
- 从默认值开始(M=16,efConstruction=200)
- 增加 M 以提高召回率(最高可达 M=64)
- 根据速度/准确性要求调整 efSearch
- 使用基准测试工具找到最佳设置
动态更新
HNSW 最适合 主要是静态的数据集。频繁的插入和删除可能会:
- 降低性能:图随着时间的推移变得不那么优化
- 需要重建:为了获得最佳性能,需定期重建
- 增加复杂性:动态更新需要仔细的同步
距离度量的局限性
HNSW 支持多种距离度量,但在以下情况下表现最佳:
- 欧几里得距离 (L2)
- 余弦相似度
- 其他度量:可能需要修改或表现不佳
HNSW背后的科学
原始研究
HNSW 是由研究人员 Yu. A. Malkov 和 D. A. Yashunin 于 2016 年开发的。他们的论文《使用层次可导航小世界图进行高效且稳健的近似最近邻搜索》发表在 arXiv (arXiv:1603.09320) 上,并随后在 IEEE 计算机学会模式分析与机器智能汇刊上发表。它已成为相似性搜索领域中最具影响力的作品之一,在学术文献中被引用超过 2,000 次。
关键创新
这一突破是将两个现有概念结合在一起:
-
跳表:由威廉·皮尤于1989年发明的概率数据结构,通过维护多个链接级别来实现快速搜索
-
可导航的小世界网络:通过智能连接快速到达任意点的网络,基于克莱因伯格对可导航网络的研究
数学基础
虽然数学可能很复杂,但核心见解却很优雅:
搜索复杂度:层次结构使得**对数搜索复杂度 O(log n)**,相比之下,暴力搜索的复杂度为线性 O(n)。
连接策略:在每一层,节点连接到其 M 个最近邻居,M 是一个可调参数,影响准确性和内存使用。
贪婪搜索保证:该算法保证在每一层达到局部最小值,层次结构增加了该局部最小值接近全局最优解的概率。
理论属性
- 尺度分离:上层提供“高速公路”连接,以便进行远距离跳跃
- 多对数复杂性:搜索时间的规模为 O(log^k n),其中 k 通常较小
- 高概率保证:数学证明显示找到接近最佳结果的高概率
实用考虑事项
何时使用 HNSW
HNSW 适用于以下情况:
- 在大型数据集中快速进行相似性搜索。
- 在合理速度下获得良好的准确性。
- 处理高维数据(具有许多特征的数据)。
- 随着数据增长,提供可扩展的解决方案。
何时不使用 HNSW
考虑替代方案当:
- 你需要保证准确的结果。
- 你的数据集非常小(传统方法可能更简单)。
- 内存使用是一个关键限制。
- 你需要频繁添加或删除数据(HNSW 针对大多数静态数据集进行了优化)。
结论
层次可导航小世界(HNSW)在我们如何在大型数据集中搜索相似信息方面代表了一项重大突破。通过巧妙地将数据组织成多个层次并在相似项之间创建智能连接,HNSW 实现了快速、准确的搜索,推动了我们每天使用的许多数字服务。
尽管其基础数学可能很复杂,但核心概念——使用层次结构高效导航数据——是直观且强大的。随着我们的数字世界不断生成更多数据,像 HNSW 这样的算法在使数据变得有用和可访问方面变得越来越重要。
无论你是对搜索工作原理感到好奇的学生,还是考虑在项目中使用 HNSW 的专业人士,亦或是仅仅想理解现代数字服务背后技术的人,HNSW 都是一个引人入胜的例子,展示了聪明的算法如何在惊人的规模上解决现实世界的问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)