多模态大模型 + 自动化测试:从截图到结构化用例的系统设计思路
当多模态大模型开始具备“看图理解界面”的能力之后,很多人就在想:
如果模型已经能理解页面结构,它能否参与测试用例的生成?
过去,测试用例通常来自:
- PRD 文档
- 原型图
- 页面实现
- 流程图
- 接口文档
而现在,输入可能变成:
页面截图 + 业务上下文 + 测试目标
输出则是:
结构化 JSON 测试用例
问题不在于“能不能生成”。 真正值得讨论的是:
- 这套系统如何设计?
- 多模态输入如何进入工程链路?
- 代码如何分层?
- 它在哪些场景可用,在哪些场景不可用?
一、为什么视觉模型可以进入测试场景
UI 测试本质上依赖“页面理解”。
一个登录页,测试工程师会自然识别:
- 用户名输入框
- 密码输入框
- 登录按钮
- 第三方登录入口
多模态模型已经具备:
- OCR 文本识别
- 组件识别
- 页面结构推断
- 基础交互逻辑理解
因此从技术能力上,它确实可以参与 UI 测试设计。
但能力 ≠ 工程可用。
二、系统整体架构设计
合理架构不应该是:
图片 → 大模型 → 文本用例
而应该是分层结构:
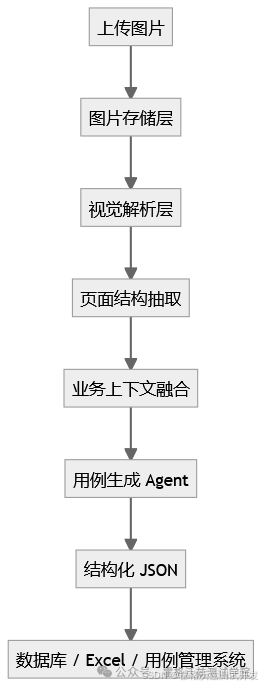
核心思想:
- 视觉理解与用例生成分离
- 输出必须结构化
- 与现有系统通过 API 集成
三、图片到测试用例的工程链路
生成用例至少需要三类输入:
- 页面截图
- 业务说明(例如:这是会员登录页)
- 测试目标(例如:覆盖登录路径)
如果只上传截图而无上下文,模型只能推断“表单结构”,无法推断业务规则。
多模态解析流程
模型首先会:
- 识别页面文本
- 识别按钮与输入区域
- 推断页面结构
- 分析潜在业务流程
例如登录页面,可能推断:
- 正常登录流程
- 空输入校验
- 错误密码提示
- 第三方登录跳转
然后进入用例生成阶段。
输出必须结构化
如果输出是自然语言描述,无法自动入库。
推荐强制 JSON:
{
"title": "",
"precondition": "",
"steps": [],
"expected_result": ""
}
这样可以:
- 存入数据库
- 导出为 Excel
- 对接禅道或其他管理系统
结构化输出,是工程可用的前提。
四、后端代码分层设计
典型前后端分离结构:
project/
├── backend/
│ ├── routes/
│ ├── services/
│ ├── models/
│ ├── utils/
│ └── ai_service.py
└── frontend/
核心接口设计
后端应提供:
- 生成测试用例接口
- 导出 Excel 接口
- 文件下载接口
时序逻辑如下:
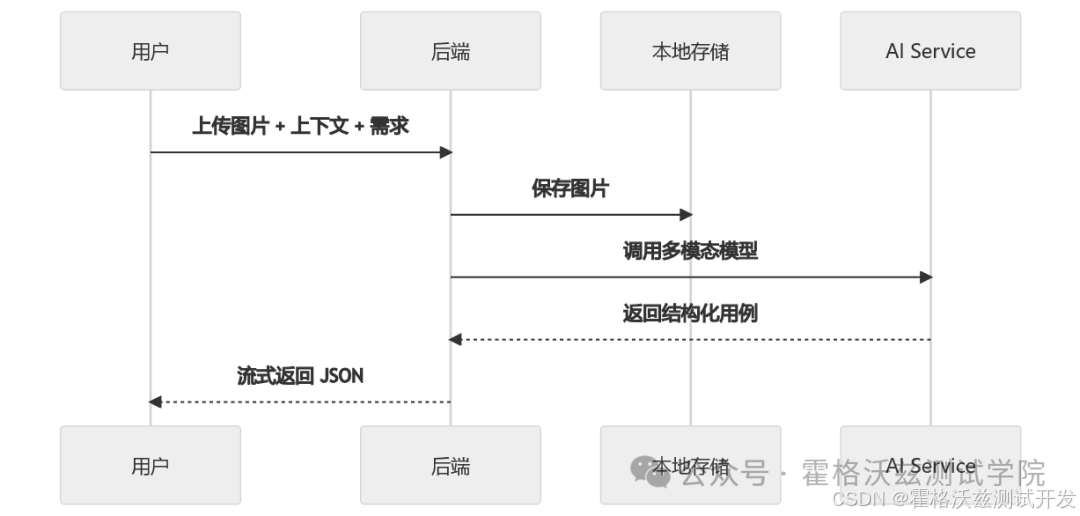
AI Service 的职责
AI service 不只是调用模型。
它应负责:
- Prompt 构造
- 输出格式约束
- 错误重试机制
- 日志记录
- 流式响应控制
否则系统难以调试。
Excel 导出模块
建议独立封装:

避免把导出逻辑写进模型调用层。
五、多模态模型的能力边界
必须清醒认识:
视觉模型适合:
- 标准 UI 表单
- 简单业务流
- 原型阶段页面
- 基础功能验证
不适合:
- 复杂权限体系
- 高并发场景
- 数据一致性校验
- 风险控制逻辑
它能生成 60% 的基础用例。 剩余 40% 仍需测试工程师设计。
六、为什么单模型方案不稳定
很多 Demo 直接:
截图 → 一个 Prompt → 输出全部用例
这在小规模测试中可行,但生产中会不稳定。
更合理的结构:
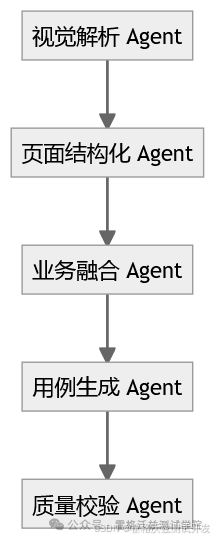
多智能体分工可以:
- 提高稳定性
- 提高可控性
- 降低 hallucination 风险
七、视觉驱动测试的真正价值
它的意义不在于“自动生成所有用例”。
而在于:
- 快速构建基础用例池
- 降低重复劳动
- 辅助需求评审
- 加速原型阶段测试
当 60% 的标准用例可自动生成时,
测试工程师的角色开始转向:
- 测试策略设计
- 边界条件建模
- 自动化框架搭建
- AI 输出质量控制
写在最后
视觉模型进入测试领域,不是概念展示,而是系统工程问题。
真正决定系统能否落地的因素包括:
- 是否分层设计
- 是否结构化输出
- 是否具备日志与可追溯机制
- 是否可与现有系统集成
模型能力只是起点。 架构设计才是关键。
当多模态能力进入测试链路后, “写用例”本身不再是核心竞争力, “设计 AI 流程”才是。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)