Ai的命根子,企业如何构建自己的知识库体系,到底需要整理哪些维度?
最近很多人问我:“六哥,企业如何构建自己的知识库体系,需要整理哪些维度的数据?”
这么跟你说吧,企业构建知识库的核心本质,就是把“培养一个小白变成3-5年老员工”的全过程数字化。
你招个高智商的清华实习生(通用AI大模型),他不了解你们卖什么、客户是谁、踩过什么坑,他干不了活。你必须把公司的产品资料、销售话术、历史避坑指南整理出来“投喂”给他。
构建知识库不是简单地把几十个Word文档扔给AI,而是要建立一个四层架构(认知、技能、风格、执行),并把散乱的资料“清洗”成标准的问答对。
这里有一张我们团队总结的企业AI知识库构建指南图,你先有个整体概念 👇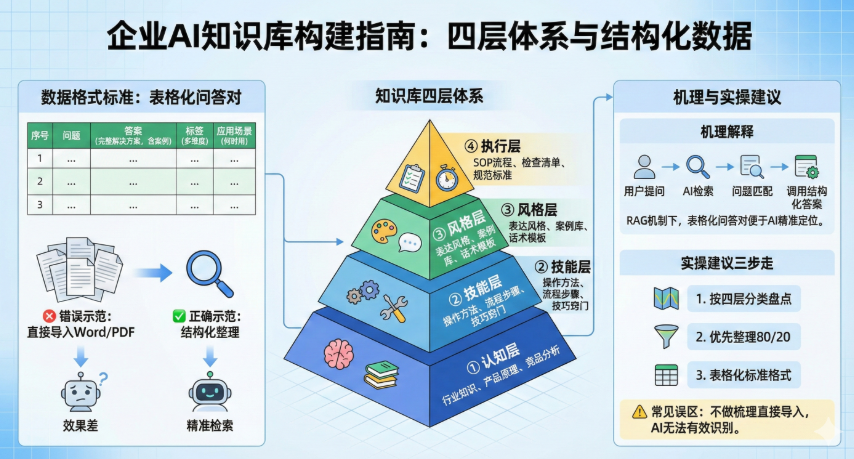
看明白这张图,你就理解了训练智能体的核心逻辑:不是让AI去网上瞎搜,而是让AI在你的“私有资产”里找答案。
🔍 底层逻辑
为什么买了几十万的AI系统,用了半年效果还是很差?
因为通用大模型(比如ChatGPT、DeepSeek)的聪明是“通用的聪明”。它懂全人类的知识,但唯独不懂你公司的业务。
解决这个问题的技术路径叫 RAG(检索增强生成)。说白了,就是给AI配了个“外挂资料库”。当员工或客户提问时,系统先从你的知识库里检索相关资料,再把资料喂给AI,让AI基于你的资料来回答。没有这个“行业种子”作为前提,一切都是零。
📖 深度解析:知识库需要整理的15个核心维度
为了让知识库真正落地,我们必须按照**“认知层 → 技能层 → 风格层 → 执行层”**的递进逻辑,系统性地盘点企业的数据资产。这15个维度,涵盖了一个老员工脑子里的所有“隐性知识”:
第一层:认知层(让AI懂行业、知边界)
这是知识库的地基,解决AI“懂不懂行”的问题。
- 底层与行业书籍:行业经典教材、白皮书、咨询公司研报(决定AI的专业深度)。
- 行业动态与资讯:近10年有价值的行业公众号文章、36氪/虎嗅深度报道、行业峰会演讲(让AI把握风向标)。
- 法规与合规要求:行业标准、国标、税务/广告法合规要点(划定AI不可触碰的红线)。
第二层:技能层(让AI会干活、懂业务)
这部分直接决定了AI能不能替代人工干具体的活。
4. 公司业务与产品资料:产品PRD文档、说明书、核心卖点、价格体系、活动策划方案。
5. 实战经验与踩坑总结:各部门负责人的复盘报告、项目失败教训(这是最值钱的!告诉AI“不要怎么做”)。
6. 历史项目档案:成功项目的完整复盘(背景、过程、结果、可复用点)、历史招投标文件。
7. 供应链与竞品数据:供应商库、竞品动态追踪记录、优劣势对比分析。
第三层:风格层(让AI像你们、懂客户)
让AI褪去“机器味”,拥有你们品牌的灵魂。
8. 爆款文案与视频脚本:近5年有价值的对标账号文案、公司历史高转化文案(让AI学习爆款网感)。
9. 客户真实沟通记录:微信群精华、售前咨询记录、售后投诉记录(提炼出最真实的用户语料)。
10. 客户声音(VOC):电商评价追评、NPS反馈、小红书/知乎上的UGC讨论(让AI深刻洞察客户痛点)。
11. 多模态视觉资产:产品实物图、设计稿、数据报表截图(交由AI解析转化为结构化描述)。
第四层:执行层(让AI守规矩、能传承)
把大目标拆解成可标准化的动作。
12. 业务流程与SOP:各岗位的标准作业流程、审批权限说明。
13. 客服/销售话术库:常见问题FAQ、异议处理话术、销冠逼单话术。
14. 会议与电话录音:战略会议记录、销售电话录音稿(用AI转译并提取金句)。
15. 新人培训体系:入职培训PPT、考核题库(已经被萃取过一次的高密度知识)。
这是整理数据的维度清单,你可以直接对照着盘点 👇

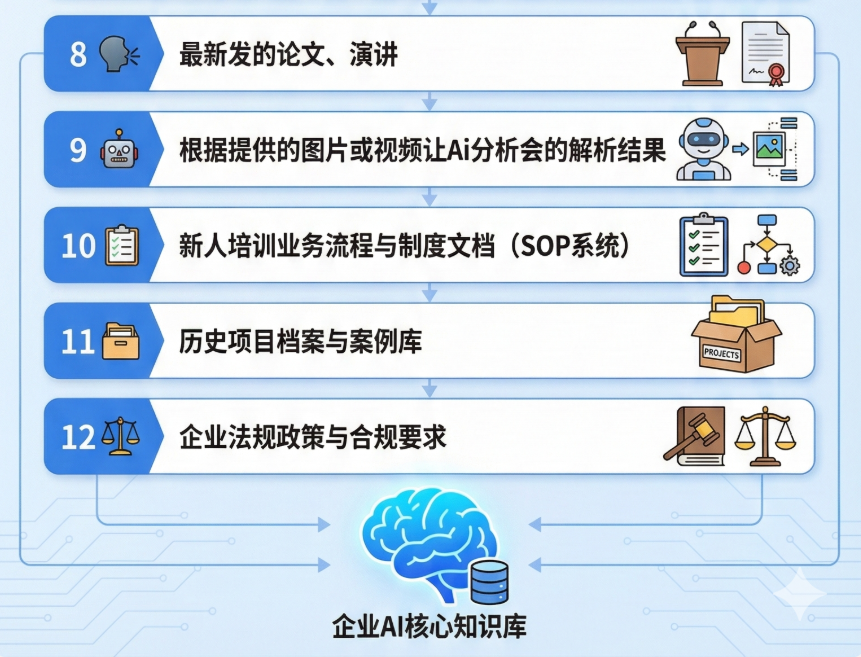
你在实操中,就应该先让业务骨干把平时用的零散文件收集起来,然后用AI工具把它们洗成“序号-问题-答案-标签-应用场景”的表格。
🧩 实战案例(详细版)
背景/痛点:
某母婴电商公司的客服和内容团队效率低下。每天面对大量的重复咨询,新来的编导写不出有“网感”的种草文案。老板想引入AI,但直接用ChatGPT写出来的东西全是假大空的废话。
原本做法:
把产品手册(PDF)直接扔给AI,命令它:“写一篇卖奶粉的文案”。结果AI生成的文案毫无转化力。
解决思路:
放弃直接提问,决定按“四层架构”重构专属知识库,把公司销冠和优秀编导的经验“萃取”出来。
详细操作步骤:
- 第一步:数据盘点(做减法)。不把所有垃圾文件都扔进去。挑出了3个核心维度:产品核心卖点表(技能层)、过去卖得最好的100篇小红书文案(风格层)、客服每天被问得最多的50个问题及销冠回复(执行层)。
- 第二步:数据清洗(原子化)。用AI工具把这些文档全部拆解成“问答对”。
- 比如把一段话术拆成:【问题】客户嫌贵怎么办? 【答案】宝妈,咱这虽然贵五十,但配方里加了乳铁蛋白... 【标签】异议处理/价格
- 第三步:导入与测试。把清洗好的Excel表格导入知识库平台(如Dify或Coze),并设定提示词:“你是一个有5年经验的母婴金牌顾问,必须且只能根据知识库里的案例风格来回复”。
具体结果:
重构知识库后,AI客服的问题解决率从45%直接飙升到78%。AI写出的文案直接达到了公司中级编导的水平。
你可以这样复用:
不要一开始就搞大而全。先挑出你们公司最能赚钱、最高频的一个场景(比如销冠的销售话术),把它洗成50个问答对,喂给AI跑通闭环,再逐渐扩展到其他14个维度。
⚠️ 常见误区与避坑指南
我们在做了1200+个中小企业落地项目后,发现90%的企业都会踩这几个坑:
误区一:把公司所有的Word/PDF原封不动打包扔给AI
- ❌ 很多人以为:资料越多越好,AI自己会看懂。
- ✅ 实际上:原始文档往往格式混乱、信息冗余(有很多废话)。AI在海量垃圾信息中检索,命中率极低。
- 💡 正确做法:必须经过“清洗”——提炼要点,结构化整理成表格或问答对(QA)。垃圾进,一定是垃圾出。
误区二:按“部门”顺序来建知识库
- ❌ 很多人以为:先整理行政部制度,再整理财务流程,最后搞业务。
- ✅ 实际上:这些“后端支撑”类知识对提升公司收入见效极慢,会导致老板觉得AI没用。
- 💡 正确做法:遵循**“70-30原则”**。前3个月,把70%的精力投入到“变现+流量”相关的知识(如:产品卖点、营销话术、客户案例)。先让AI帮你赚钱,再让它帮你管后勤。
误区三:建完知识库就不管了
- ❌ 很多人以为:知识库是个“项目”,建完了就万事大吉。
- ✅ 实际上:行业在变,客户问题在变。去年的话术用到今年可能就不管用了。
- 💡 正确做法:每月必须召开一次“知识库评审会”,把最新的踩坑教训、新出的爆款案例补充进去。知识库是“活的”,需要持续喂养。
💡 思考框架
以后遇到任何“AI落地没效果”的问题,你可以用这个**“ABC诊断模型”**来分析:
- 第一问:A (AI大模型) 选对了吗?(是不是用了太弱的开源模型,理解不了复杂逻辑?)
- 第二问:B (Base知识库) 喂足了吗?(AI是不是在“裸奔”?有没有把你们的行业秘籍喂给它?)
- 第三问:C (Context提示词) 规矩立好了吗?(有没有告诉AI以什么身份、用什么语气、按什么格式输出?)
掌握了这个框架,你就不只是在解决一个软件问题,而是掌握了重构企业数字资产的上帝视角。
🎯 六哥观点
说实话,大家赚钱都不容易。很多老板被市面上的“AI神话”忽悠,以为买个工具就能裁员一半。
假如我是个傻叉,用AI大概率也是个傻叉——AI只是放大器。
真正能在AI时代建立护城河的,根本不是你用了哪个大模型,而是你常年积累的、别人抄不走的行业数据和踩坑经验(知识库)。这才是你最核心的资产。赶紧把你脑子里的、老员工脑子里的东西,一点点抠出来变成数据吧。
✅ 现在你可以做的
- 今天就做:在纸上列出你们公司目前最高频、最直接影响收入的3个业务场景(比如:短视频选题、客服售后问答)。
- 这周完成:找业务骨干,把这3个场景里相关的资料找出来,别管乱不乱,先归拢到一个文件夹里。
- 持续优化:利用AI工具(如我们提供的智能体),把这些凌乱的资料“榨干”,转化为标准的、带标签的问答对,导入你们的专属系统。
🗺️ 逻辑总览图
最后,我把构建企业知识库的核心维度和结构,给你梳理成了一张脑图,方便你保存和内部开会时拉齐认知:
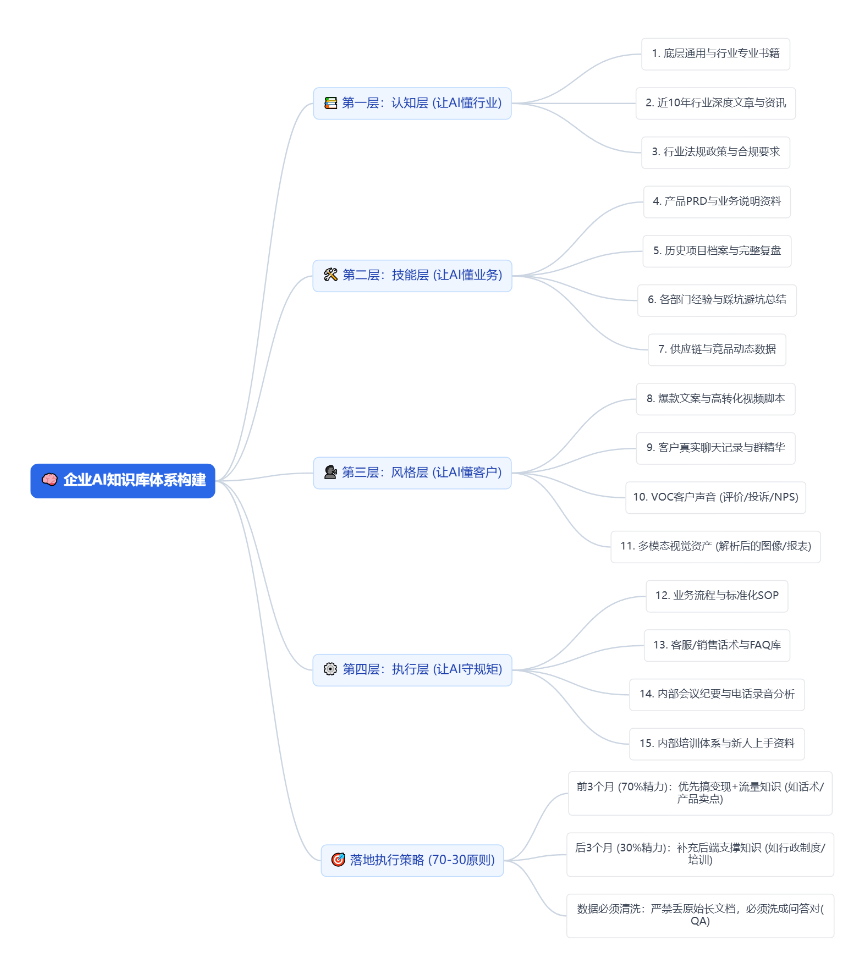

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)