大模型分布式训练技术 DP,DDP,DeepSpeed ZeRO
一、DP
今天我们来讨论一下模型的分布式训练的原理。模型分布式训练有多种方式,有数据并行、模型并行、张量并行等。其中数据并行适用范围最广,应用最多。今天我们就主要讨论数据并行的模型分布式训练的原理。分布式训练主要解决两个问题,一个是可以利用多个GPU加快模型训练,还有一个问题就是模型太大,单张GPU显存不足以支持模型训练,所以需要分布式训练减少每个GPU的显存占用。
我们来复习一下单机单卡情况下的训练流程。首先从硬盘读取数据CPU处理数据,将数据组成一个batch传入GPU进行网络前向传播,算出loss。然后进行后向传播计算梯度,用梯度更新网络参数,完成一次训练。

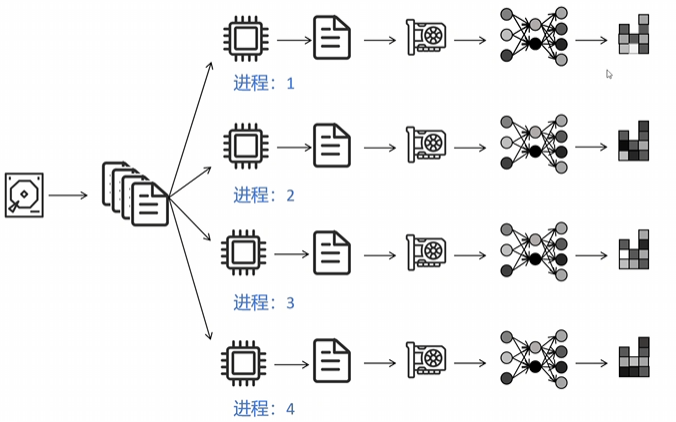
接下来我们来学习一下python里最早的数据并行多卡训练的框架data parallel,简称DP。它的运行模式是从硬盘读取数据,然后通过一个CPU进程将数据分成多份给每个GPU1份。每个GPU独立进行网络的前向传播,后向传播计算出各自的梯度,然后所有其他的GPU都将自己计算的梯度传递到GPU0上进行平均,GPU0用全局平均的梯度更新自己的网络参数,然后将更新后的参数广播到其他GPU上。在进行分布式训练时,最关键的任务是如何减少多卡之间的通信量,以提高训练效率。在分布式训练任务里,可能一半的训练时间都是被多卡之间的通信占用。
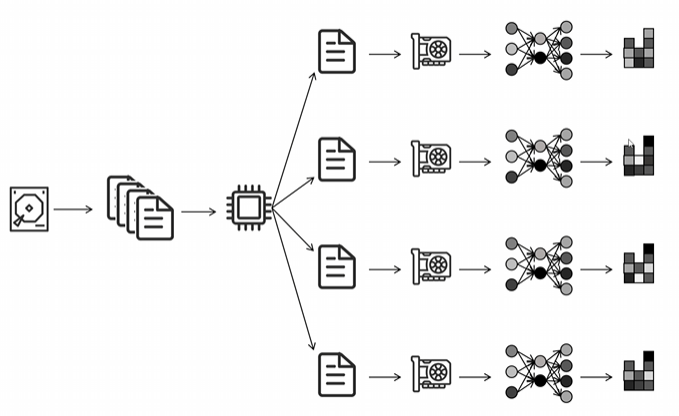
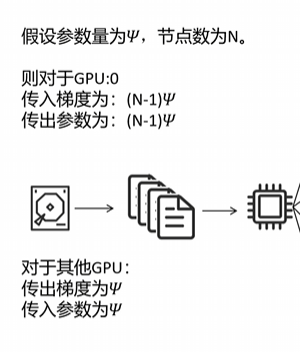
我们来分析一下 DP 模式下每个进程的通信量。我们假设神经网络的参数量为 φ,GPU 个数为 N。对 GPU0 来说,其他 N-1 个 GPU 都需要传入它们的梯度,所以传入梯度的通信量为 (N-1) × φ。同样,GPU0 需要将自己更新好的参数传递给所有其他 N-1 个 GPU,所以传出的通信量也是 (N-1) × φ。可以看到这两个通信量都是和 GPU 个数相关的,也就是说总的 GPU 越多,GPU0 的通信量就越大。我们再来看其他 GPU,它们都需要传出自己的梯度,通信量为 φ;另外传入 GPU0 更新后的参数,传输量也为 φ。所以对于其他 GPU 来说,不论总的 GPU 个数为多少,它们的通信量都不变。
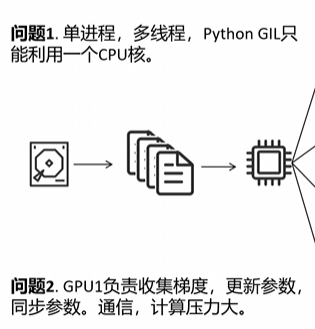
DP 这种训练模式有两个问题:首先它是单进程多线程模型,受限于 Python 的 GIL,只能利用一个 CPU;其次也是最重要的,GPU0 负责收集梯度、更新参数、同步参数,通信和计算的压力都很大,它的通信量是和总的 GPU 个数线性相关的。接下来我们就来讲一个 PyTorch 里替代 DP 的分布式训练框架——DDP(Distributed Data Parallel)。
二、DDP
首先我们介绍一种集群通讯方式,叫做 ring all-reduce,它把多个节点连成一个环进行通讯。比如这里有三张 GPU,分别是 GPU0、GPU1 和 GPU2,它们各自持有三个参数 A、B、C 的梯度值。我们的目标是让每张 GPU 上都拥有这三个参数梯度的总和,比如对参数 A 来说,我们希望通讯结束后,GPU0、GPU1 和 GPU2 上都存储着 A0 + A1 + A2。
首先,我们把 GPU0 上的 A0 传给 GPU1,与 GPU1 上的 A1 求和;把 GPU1 上的 B1 传给 GPU2,与 GPU2 上的 B2 求和;把 GPU2 上的 C2 传给 GPU0,与 GPU0 上的 C0 求和。这样就形成了一个环,每张 GPU 都在同时发送和接收数据,这是第一次通讯后的结果。
接着我们继续进行累加。将 GPU0 上的 C0 + C2 传递给 GPU1,与 GPU1 上的 C1 求和;将 GPU1 上的 A0 + A1 传递给 GPU2,与 GPU2 上的 A2 求和;将 GPU2 上的 B1 + B2 传递给 GPU0,与 GPU0 上的 B0 求和。这是第二次通讯后的结果。此时我们发现,GPU0 上已经得到了参数 B 的梯度累加和,即 B0 + B1 + B2;同样,GPU1 上有了参数 C 的梯度总和,GPU2 上有了参数 A 的梯度总和。这样我们就完成了 ring all-reduce 的第一个阶段。
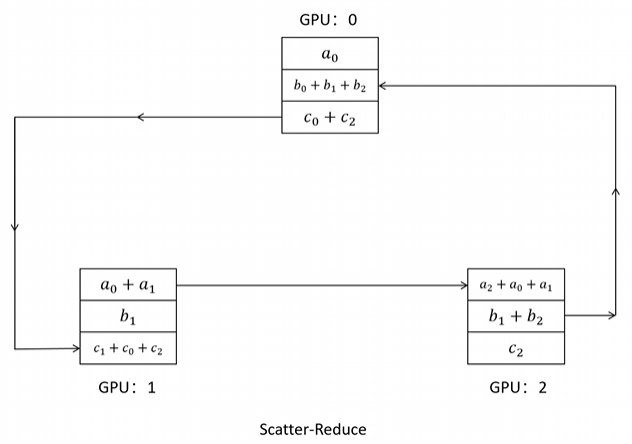
第一个阶段叫做 scatter reduce。Scatter 的意思是通过分发让每个节点持有不同的数据,Reduce 的意思是收集所有节点的值并进行计算,这里进行的是累加操作。所以第一个阶段称为 scatter reduce。
下一个通信阶段的任务是将各个参数梯度的累加和同步到其他 GPU,这一阶段叫做 all-gather。我们来看一下在多个 GPU 环状连接下是如何进行的。首先,GPU0 把参数 B 的梯度总和发送给 GPU1,GPU1 把参数 C 的梯度总和发送给 GPU2,GPU2 把参数 A 的梯度总和发送给 GPU0。接下来,GPU0 把参数 A 的梯度总和发送给 GPU1,GPU1 把参数 B 的梯度总和发送给 GPU2,GPU2 把参数 C 的梯度总和发送给 GPU0,最终完成整个 ring all-reduce 的通讯过程。此时每张 GPU 上都拥有了所有参数的梯度总和。
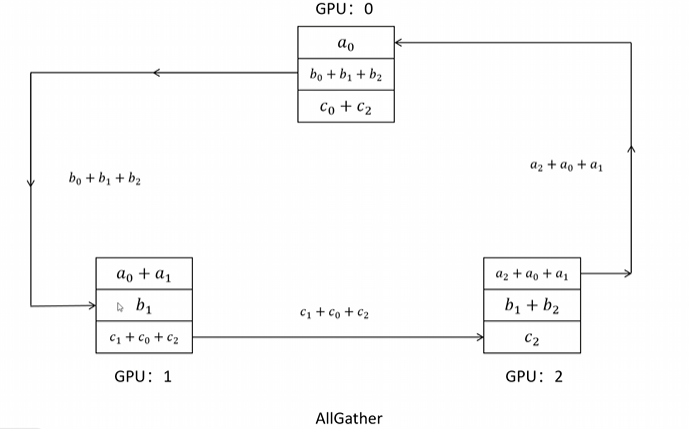
可以看到,通过环形连接的 ring all-reduce,每张 GPU 的负载都是一样的,并且可以同时进行发送和接收,能够最大限度地利用每张显卡的上行和下行带宽。
我们再来回顾一下 DP 架构下的模式:它是单进程多线程的模式,只有 GPU0 需要优化器进行参数更新。而在 DDP 模式下是多进程的,每个进程为自己的 GPU 准备数据,并与其他 GPU 通信。每个进程用各自的数据进行神经网络的前向和后向传播,计算自己的梯度。因为数据不同,所以每个 batch 计算出来的梯度也不同。然后通过 ring all-reduce 来同步多个 GPU 计算出来的梯度,同步后各个 GPU 的梯度就相同了。它们用各自的优化器来更新各自的神经网络状态,并且优化器状态始终保持同步。之后再进行下一个 batch 的训练,每个 GPU 计算各自的梯度,同步梯度,更新网络。
DDP 内部实现有一些细节我们可以深入了解一下。假设我们有三张显卡,首先是 GPU0 加载模型,它把模型同步到 GPU1 和 GPU2。然后按照神经网络参数定义的反序,把参数进行排列,也就是输出层排在最前面,输入层排在最后面。然后对每个参数注册一个监听器,这些监听器按顺序放到一个个桶里。
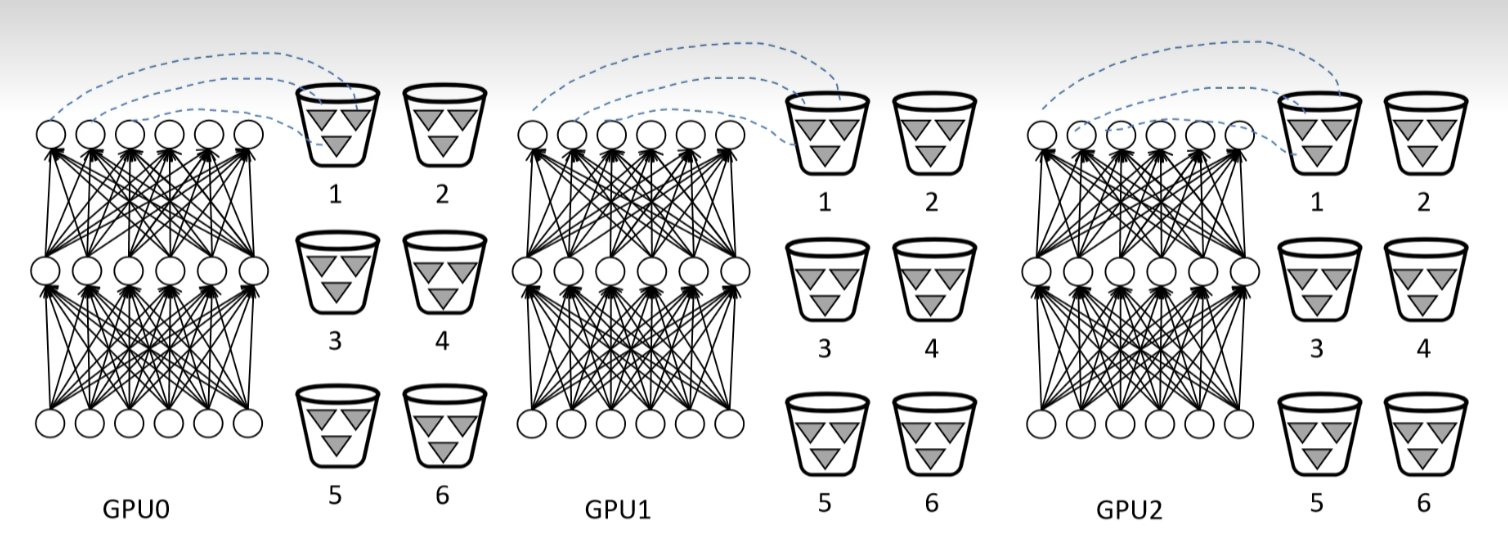
为什么要对参数进行反序排列呢?因为反向传播计算梯度时,后边的参数(靠近输出层)的梯度先计算出来,前面参数(靠近输入层)的梯度后计算出来。所以输出层的参数放在前面,输入层的参数放在后面,这样在多卡传输时,最好是 GPU 在进行计算的同时进行传输,让计算和传输的时间重叠,从而减少整体的训练时间。
先计算出来的梯度可以先进行同步,同时GPU还在计算其他梯度,但是每算出来一个梯度就进行同步,系统开销太大,得不偿失。所以就收集满一个桶再进行同步。注册的监听器是为了让DDP框架知道哪个参数的梯度。计算好了当多个GPU开始进行训练后向传播时,梯度逐步算出。当多个GPU的同一个桶里面的梯度都计算完成后,这个桶就进行ring all reduce的同步梯度,同时GPU还在计算其他的梯度。最终当所有的桶都梯度同步了,每个GPU分别调用它们各自的优化器来更新网络。这时他们的优化器状态,神经网络参数都是同步的,然后就可以进行下一次训练了。
我们对 DDP 的通信量进行分析。同样参数量为 φ,GPU 个数为 N。之前我们讲 ring all-reduce 时是三个 GPU 同步三个梯度值。实际上,我们需要把所有要同步的参数 φ 除以总的 GPU 数量 N,作为 ring all-reduce 需要同步的一个块,所以每个块的大小为 φ 除以 N。

在 scatter reduce 阶段,每个通讯块需要传递 N-1 次才能得到梯度之和。所以在 scatter reduce 阶段,每个 GPU 发送和接收到的通信量都是 (N-1) × (φ / N),当 N 足够大时约等于 φ。同样,在 all-gather 阶段,聚合好的梯度块需要经过 N-1 步才能同步给所有的 GPU。在这期间,每个 GPU 发送和接收的通信量也都是 (N-1) × (φ / N),约等于 φ。
可以看到,DDP 架构下每个进程总的发送和接收通信量都是 2φ,和整个集群有多少 GPU 无关。
三、DeepSpeed ZeRO - 1
上面的 DDP 架构中,每个 GPU 里都要存储完整的神经网络和优化器状态。在训练大模型时,由于 GPU 显存的限制,可能显存不够。接下来我们就来介绍 DeepSpeed 的 ZeRO 架构,ZeRO 的意思是零冗余优化器。
假设我们有 3 个 GPU,有一份训练数据,数据并行将数据分块,每个 GPU 分到一块。如果按照 DDP 的架构进行混合精度训练,每个 GPU 里需要存储 FP16 的网络参数、FP16 的梯度,优化器里需要存放 FP32 的梯度、为 Adam 优化器存储的 FP32 的一阶动量和二阶动量,以及 FP32 的参数(也就是 master weight)。
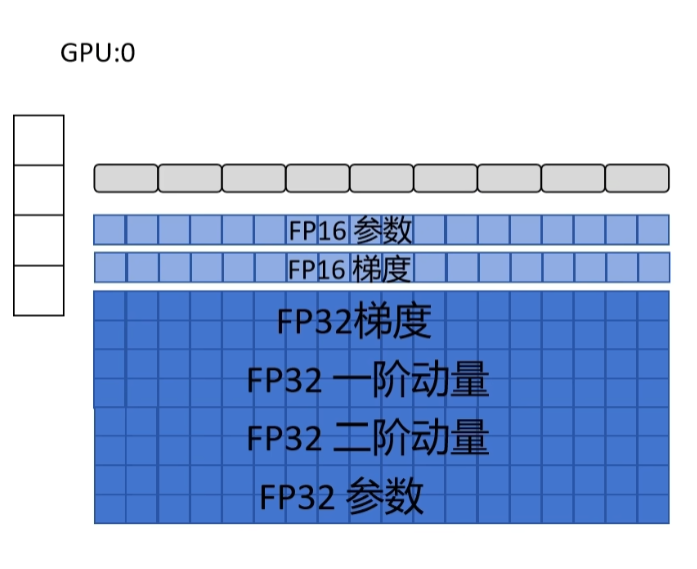
可以看到,对于每个 GPU 来说,占用显存最大的就是优化器状态,而且在每个 GPU 里都存储了一份完全相同的优化器状态,产生了冗余。那么,能不能让每个 GPU 只存储一部分的优化器状态,整个系统只有一份完整的优化器状态,从而消除冗余呢?这就是 ZeRO-1 的出发点。
比如这里神经网络有九层,我们让 GPU0 存储前三层神经网络对应的优化器状态,负责前三层网络参数的更新;GPU1 存储中间三层的优化器状态,负责更新中间三层的网络参数;GPU2 存储最后三层的优化器状态,负责更新最后三层的网络参数。
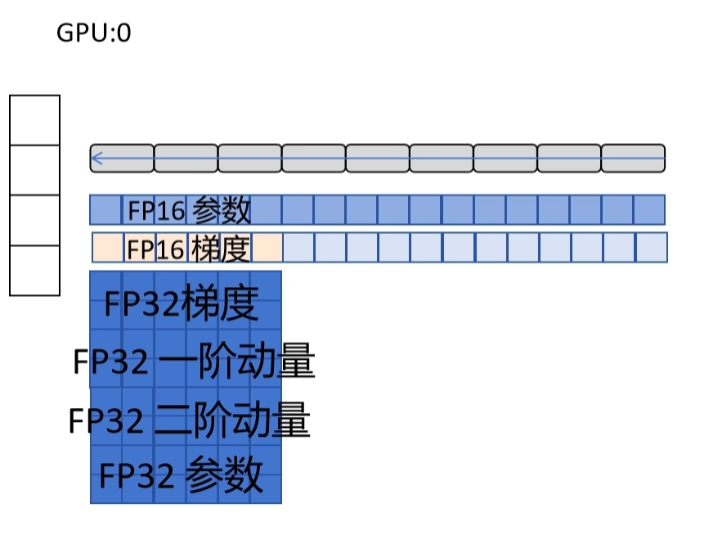
前向传播没有问题,因为每个 GPU 都存储着 FP16 的网络参数。在后向传播时,每个 GPU 都从后向前计算出每一层参数的梯度。GPU0 和 GPU1 并不负责更新后面三层的参数,它们需要把自己计算的梯度发送给负责更新后面三层参数的 GPU2。在它们发送梯度的同时,GPU 仍然在继续计算其他层的梯度。GPU2 聚合三个 GPU 计算的最后三层的梯度,并算出梯度的平均值。同理,GPU0 和 GPU2 把它们计算出来的中间三层的梯度值发送给 GPU1,GPU1 汇总计算出梯度的均值。最后,GPU1 和 GPU2 把它们计算出来的前三层的梯度发送给 GPU0,GPU0 负责汇总计算出梯度均值。
反向传播完毕后,每个 GPU 都拿到自己优化器对应部分参数的梯度均值,然后将梯度转化为 FP32 进行缩放,然后更新优化器里的一阶和二阶动量,最后优化器更新 FP32 的参数。接下来,每个 GPU 更新各自优化器对应的那部分 FP16 的网络参数,然后再把各自更新后的 FP16 的网络参数广播给其他 GPU,这样就完成了一次训练。
接下来我们对 DeepSpeed ZeRO-1 的通信量进行分析。对于每个 GPU,在梯度收集阶段,它负责更新的那部分参数量为 φ 除以 GPU 个数 N。每个 GPU 需要把计算出的、由其他 GPU 负责更新的那部分梯度发送出去,所以发送的通信量为 (N-1) × (φ / N)。同样,对于自己负责更新的那部分参数梯度,需要接收其他 N-1 个 GPU 计算的梯度,所以接收的通信量也为 (N-1) × (φ / N)。当 N 比较大时,约等于 φ。

在每个 GPU 更新完自己负责的那部分参数后,需要把更新后的参数广播给其他 N-1 个 GPU,同时也要接收其他 N-1 个 GPU 发来的更新参数。发送和接收的量都为 (N-1) × (φ / N)。总的发送和接收通信量和标准的 DDP 一样,都是 2φ。
令人惊奇的是,ZeRO-1 大大减少了 GPU 的显存占用,却没有增加 GPU 之间的通信量。为什么呢?因为每个 GPU 都只把自己计算出来的梯度发送给负责更新的唯一的那一个 GPU,而不是进行广播,这一部分减少了通信量;但是因为 ZeRO-1 对参数更新进行了划分,更新后对参数广播又增加了通信量。两者相抵,DeepSpeed ZeRO-1 总体的通信量和标准的 DDP 是一样的。
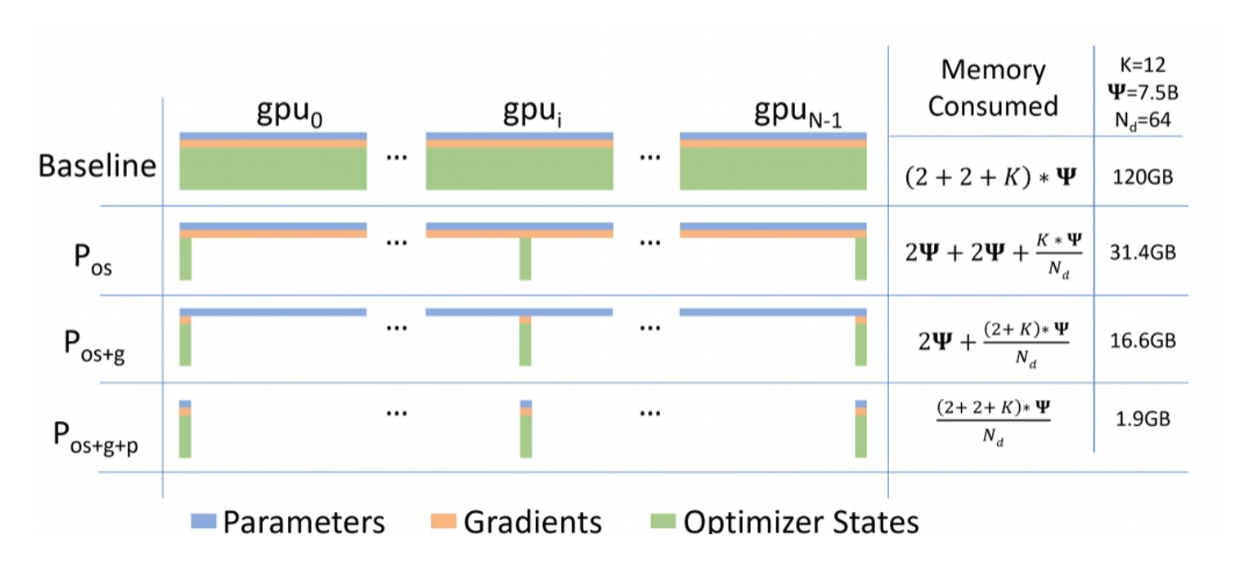
这里我们可以看一下 DeepSpeed ZeRO-1 对显存的节省。上面这一行是标准 DDP 训练下每个显卡的显存占用。其中的“2+2”指的是混合精度训练下 FP16 的参数和 FP16 的梯度各占两个字节,后面的 K 是指优化器占用的字节数,比如 Adam 优化器每个参数占用 12 字节。假设训练的模型参数量为 7.5B,那么每个显卡的显存占用约为 120GB。在原文论文里,ZeRO-1 也被称为 OS(Optimizer States),即优化器状态划分。在 DeepSpeed ZeRO-1 下,使用 64 张 GPU 进行训练,优化器状态被平均分配到 64 张卡上,因此每个显卡的显存占用大幅降低到了约 31.4GB。
四、DeepSpeed ZeRO - 2 & DeepSpeed ZeRO - 3
DeepSpeed ZeRO 没有止步于此,继续进行优化,于是有了 ZeRO-2。在 ZeRO-2 里,把 FP16 的梯度也按 GPU 进行了划分。动机很简单:既然每个 GPU 只负责更新一部分参数,那么它只要保存这一部分参数的梯度值就可以了,其他的梯度没有必要保存。
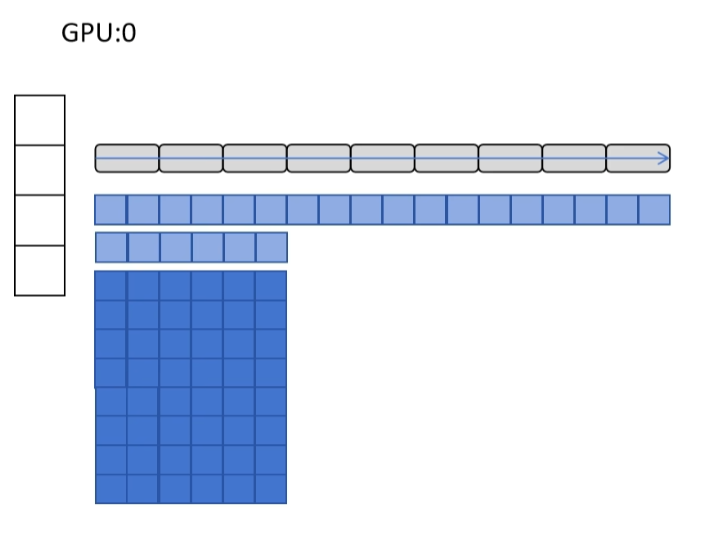
我们来看一下具体过程。后向传播时,GPU0 和 GPU1 计算出最后一层的梯度,这些梯度以桶的形式发送给负责更新这部分参数的 GPU2,然后只有 GPU2 保存最后汇总的平均梯度,GPU0 和 GPU1 则立即释放掉这部分梯度占用的显存。以此类推,计算每一层的梯度,并把梯度发送给负责更新这部分参数的 GPU,其他 GPU 立即释放这部分的显存占用。反向操作完成后,每个 GPU 都有了自己负责更新参数的汇总后的平均梯度,然后更新优化器状态,优化器更新参数,接着每个 GPU 再把自己更新后的参数广播给其他 GPU。这就是 ZeRO-2。
它和 ZeRO-1 类似,只是每个 GPU 不再保存自己用不到的梯度,通讯量也没有改变,显存占用继续减小。
接着看 ZeRO-2 对显存的节省分析,在原论文里它叫做 OS 加 G,G 就代表梯度,也就是优化器状态加上梯度进行零冗余优化。可以看到在 ZeRO-2 里,梯度占用的这两个字节也被移动到了分子上,这样梯度占用的显存也可以被所有的显卡平均分担,每个显卡的显存占用降低到了 16.6GB。看到这儿你也能想到接下来 DeepSpeed 的 ZeRO-3 要干什么了。
那就是对参数也按 GPU 进行划分,让参数在整个系统里也是零冗余。这是对参数也进行划分后的样子。那么前向传播时遇到自己没有的参数怎么办呢?那就靠其他 GPU 来广播。比如 GPU1 和 GPU2 没有第一层的参数,那就从 GPU0 来广播。GPU1 和 GPU2 计算完第一层后,立即丢弃这部分参数,不占用显存。
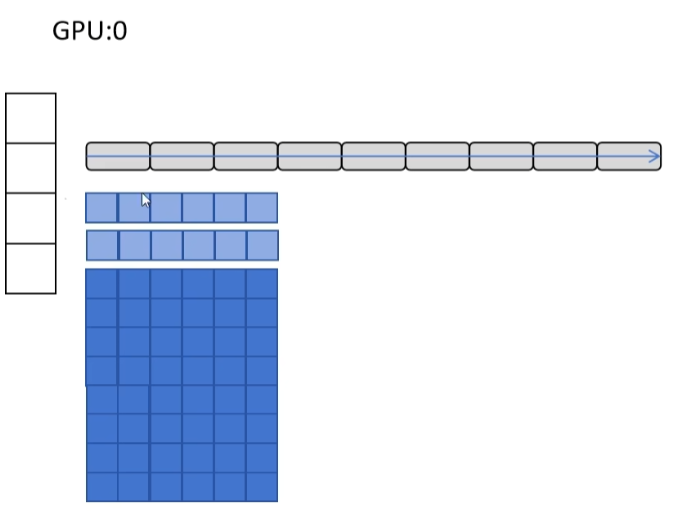
其他类似,完成前向传播。后向传播计算梯度时依然需要参数,那怎么办?那就再广播一次。同样,所有 GPU 在使用完不是自己负责的参数后,就立即丢弃来节省显存。对梯度和参数更新部分和 ZeRO-2 一样,我们就不重复了。
最后我们来分析一下 DeepSpeed ZeRO-3 的通信量,你可能觉得这下通信量一定很大。那我们来计算一下:首先梯度收集部分不变,通信量还是 2φ。由于原来 ZeRO-1 和 ZeRO-2 在前向传播前也是需要进行参数广播的,ZeRO-3 在此基础上只是增加了后向传播时的参数广播,所以增加了一个 φ 的通信传输,总的发送和接收的通信量为 3φ,也就是标准 DDP 的 1.5 倍。

我们最后看一下 ZeRO-3 的显存节省,它把最后参数占用的两个字节也移动到了分子上。这样理论上只要你的显卡数量 N 趋于无穷大,那么每张卡上的显存占用就是 0。在这个例子里,它的显存占用降到了 1.9GB。可以看一下,从标准 DDP 的 120GB 降低到 1.9GB,还是非常厉害的。一般实际中我们多采用 ZeRO-2,因为它没有增加通信量,但大大减少了显存占用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)