建设高质量数据集背后,真正被抬高的是数据治理门槛
今年两会期间,众多代表委员深刻揭示了当前我国在推进人工智能与实体经济深度融合过程中,高质量数据集所面临的机遇与挑战。2026 年政府工作报告也明确提出:深化数据资源开发利用,健全数据要素基础制度,建设高质量数据集,完善人工智能治理。这意味着,数据工作正在从“资源积累”进入“能力建设”阶段,高质量数据集已经被放到 AI 产业链的关键位置。
早在2025 年 8 月,国家数据局正式发布《高质量数据集建设指引》,“高质量数据集”往更深一层看,这件事真正抬高的,是企业的数据基础能力门槛。热度落在数据集,压力会传导到数据治理、数据工程和数据底座。
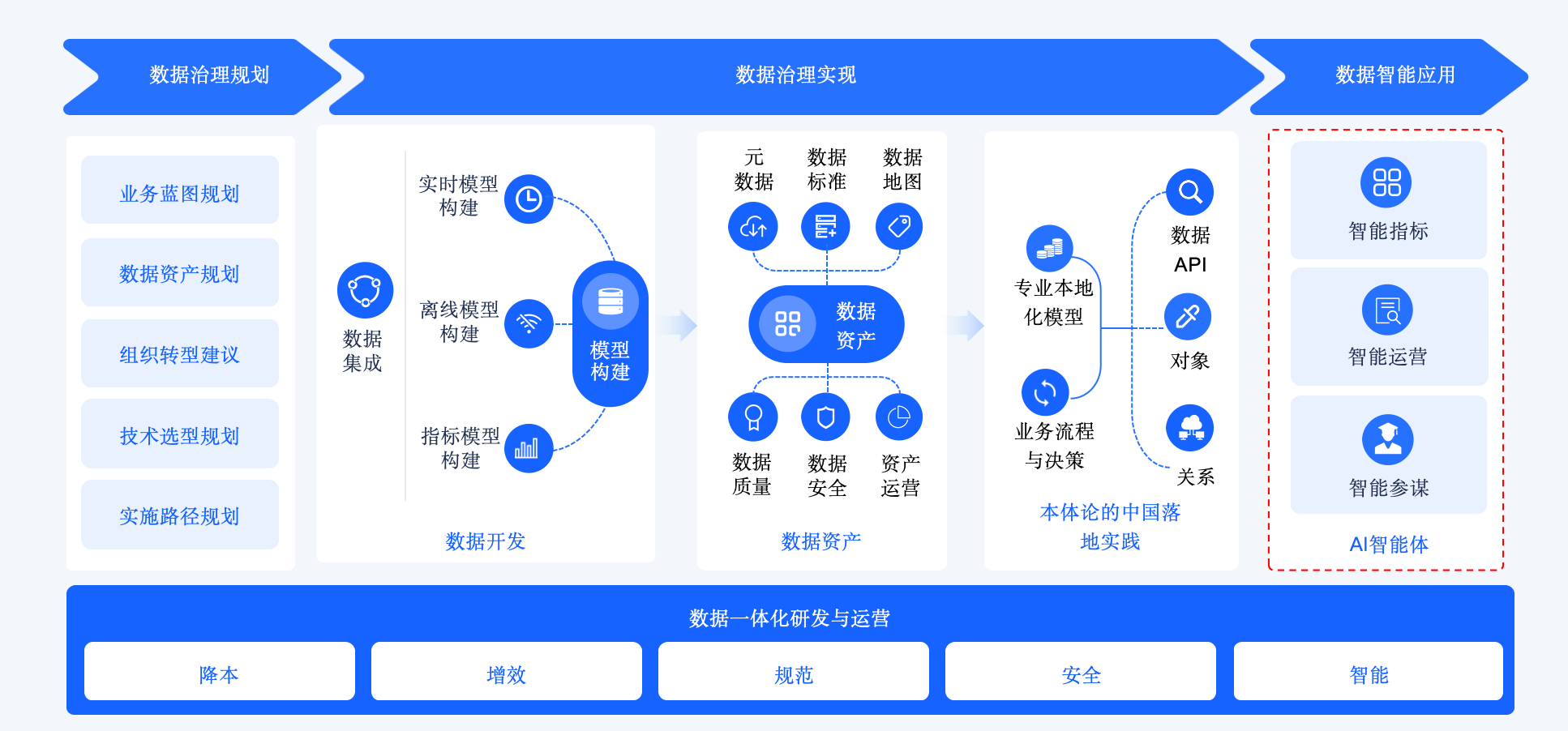
袋鼠云数据治理工程全链路
高质量数据集,关键在“可用性”
高质量数据集更接近一套面向明确任务、具备稳定语义、能够持续供给的数据资产。它要服务模型训练,也要服务业务应用;要能进入实验环境,也要能进入生产系统。国家数据局发布的《高质量数据集建设指引》提到,高质量数据集建设要覆盖数据需求、数据规划、数据采集、数据预处理、数据标注、模型验证等全流程环节。经过全流程处理后,可直接用于AI模型开发与训练的数据,其核心区别于传统数据的优势,集中体现为“规模大、安全牢、观点正、效果好、应用广”五大核心特征。

高质量数据集建设模式
企业真正需要关注的,有三点。
第一,任务是否清晰。
高质量数据集一定对应具体问题。比如医疗辅助诊断、工业缺陷识别、设备故障预警、交通事件感知、金融风控判断。任务边界清楚,数据边界才会清楚。
第二,语义是否稳定。
数据口径、标签规则、样本定义、上下文关系要足够一致。否则,数据量再大,模型学到的也可能只是无效信息。
第三,供给是否持续。
一次性整理出来的数据很难支撑长期应用。真正有价值的数据集,需要能够更新、校验、复用、迭代。
说到底,高质量数据集考验的是企业能否把数据变成“持续生产的智能原料”。
从通识到专识,高质量数据集持续沉淀行业 know-how
这件事最容易被低估的地方,在于它承载的内容远不止数据本身。尤其当数据集从通识层走向行业通识层,再走向行业专识层时,其中沉淀的行业知识、业务规则与任务经验会不断加深。行业 know-how,正是在这个过程中逐步进入数据集。

高质量数据集分类
高质量数据集本质上是在把行业 know-how 转成机器可以理解、模型可以学习、系统可以调用的表达形式。通识数据集更多承载基础认知和通用语义;进入行业通识数据集阶段后,数据开始沉淀某一行业内相对共性的对象体系、术语体系、流程逻辑和规则框架;继续向行业专识数据集深入,数据中进一步叠加具体企业、具体业务、具体任务场景中的操作经验、处置机制和反馈结果。数据集建设走到这里,已经进入知识沉淀和业务沉淀阶段。
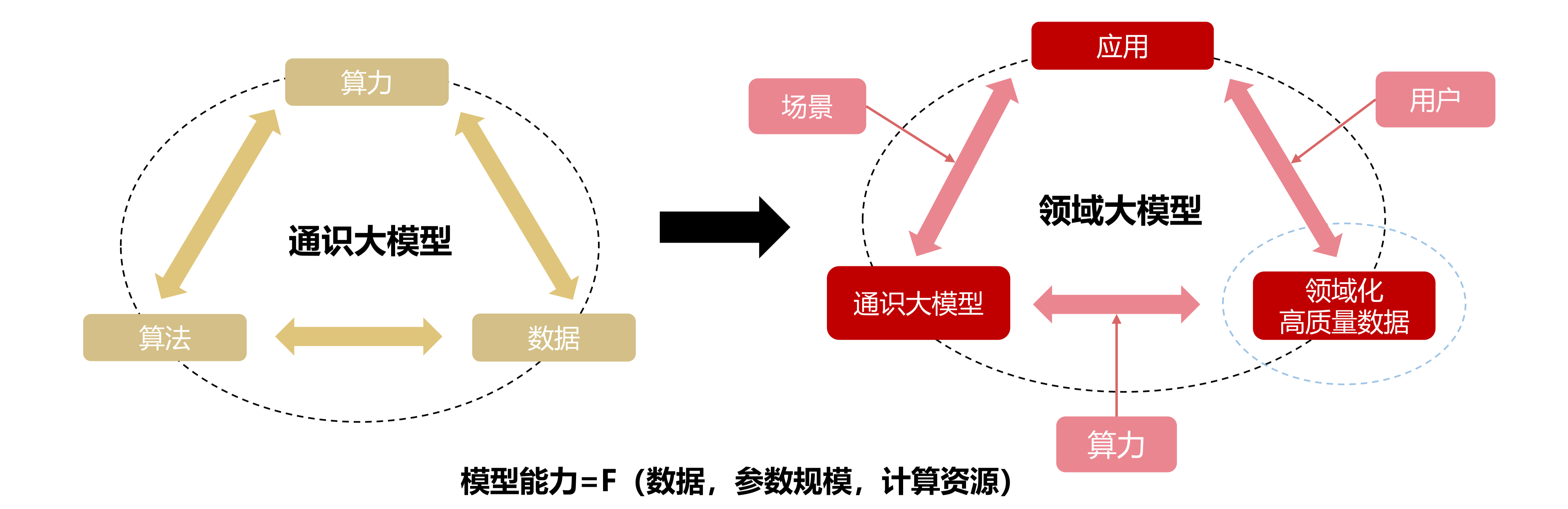
领域大模型的训练质量很大程度依赖于领域化的行业专识高质量数据集
国家数据局发布的首批 104 个典型案例,覆盖科学研究、工业制造、智慧能源、交通运输、金融服务、医疗卫生、教育教学、文旅、应急管理等重点领域,以及低空经济、具身智能、智能驾驶等创新方向。这个覆盖面本身已经说明,高质量数据集不是一个单纯的数据整理工程,它已经进入行业知识工程层面。
在很多行业里,这种沉淀通常会经历两个层次:先形成面向行业共识的行业通识数据集,再继续下沉为贴近企业真实任务的行业专识数据集。
以工业制造为例,缺陷检测数据集中首先沉淀的是工艺判断标准、缺陷类型划分、噪声识别边界等行业共识内容,这些构成了行业通识数据集的重要基础。当数据继续下沉到具体产线、具体设备、具体材料和具体工艺条件时,哪些异常会影响良率、哪些波动属于可接受范围、哪些处置动作更有效,这些更贴近现场任务的经验会进一步沉淀为行业专识数据集。
智慧能源场景中的设备运维、管道监测、市场预测类数据集,也呈现出相似路径。设备分类、工况划分、典型异常征兆、环境变量关系等内容,构成了行业通识层的知识基础;而具体到某家企业的设备类型、运行环境、巡检机制和处置流程,数据集中承载的就已经是更具业务针对性的行业专识知识。
医疗领域更明显。病种术语、检验指标、诊疗路径和质控标准,支撑的是行业通识数据集;而当数据进一步关联到具体医院的诊疗流程、专科经验、病例结构和随访反馈时,数据集就会进入行业专识层。模型后续能否进入更复杂的辅助判断和临床支持场景,与这一层数据沉淀深度关系密切。
所以,高质量数据集的价值,体现在将行业知识、业务规则和任务经验持续沉淀为可训练、可复用、可扩展的数据资产。随着数据集从通识层走向行业通识层、再走向行业专识层,这种知识沉淀的深度也会持续加深。
高质量数据集越往深处做,越会回到数据治理
很高质量数据集通常不是一次性形成的,而是随着治理能力的持续深化逐步沉淀出来。
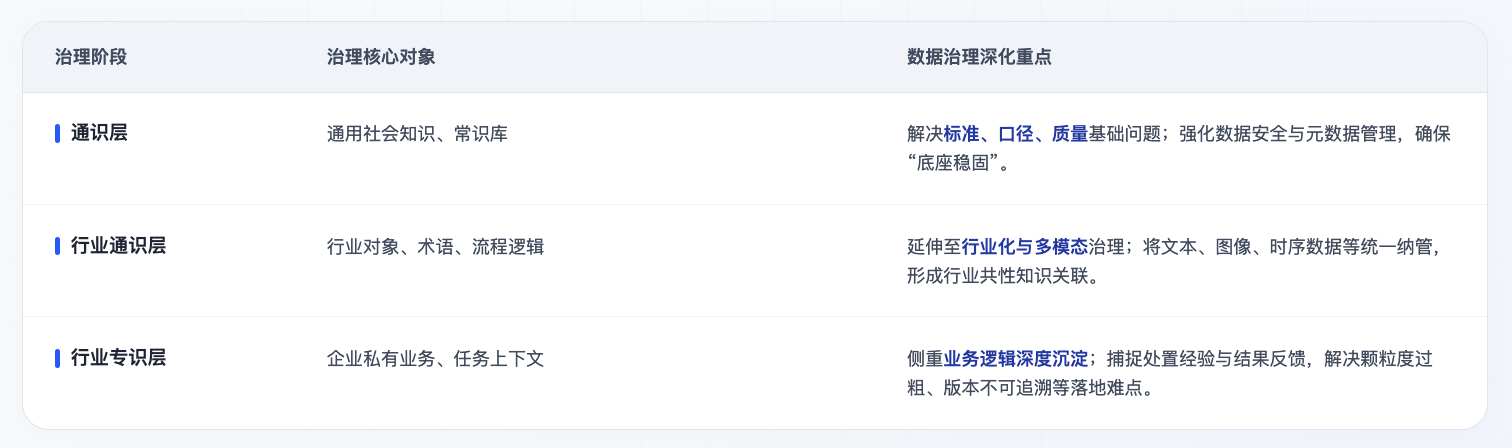
通识数据集更多依赖基础数据治理,重点解决数据标准、质量、元数据、安全权限等问题,为通用大模型接入和基础智能能力应用提供支撑。
当数据集建设走向行业通识层,治理重点也会同步变化。企业需要围绕行业对象、术语体系、流程逻辑和知识关系来组织数据,并将文本、图像、音视频、日志、时序等多种类型的数据纳入统一治理范围。此时,数据治理已经从基础治理延伸到行业治理和多模态治理,支撑行业大模型和行业知识库建设。
继续向下走,进入行业专识数据集阶段,治理要求还会进一步抬升。数据集会更紧贴具体企业、具体业务和具体任务场景,除了行业共性知识,还要沉淀流程细节、任务上下文、规则机制、处置经验和反馈结果。这一层更依赖业务数据治理能力,也直接影响垂类业务模型能否进入真实场景。
很多企业推进 AI 时,模型能力进步很快,场景落地速度却始终提不起来,问题往往集中在数据层。口径不统一、标签不可靠、来源不清晰、上下文不完整、版本不可追溯、权限边界模糊,这些问题在高质量数据集建设阶段会被进一步放大。数据集越往下做,治理对象越复杂,治理颗粒度越细,对数据组织能力的要求也越高。
多模态数据智能中台,开始成为AI时代新数据底座
高质量数据集建设继续往深处推进,企业的数据底座也会被迫升级。
多模态数据智能中台的价值,正在这个阶段变得越来越清晰。它解决的不是“数据要不要接”,而是“不同类型的数据如何被统一承载、统一开发治理、统一供给”。
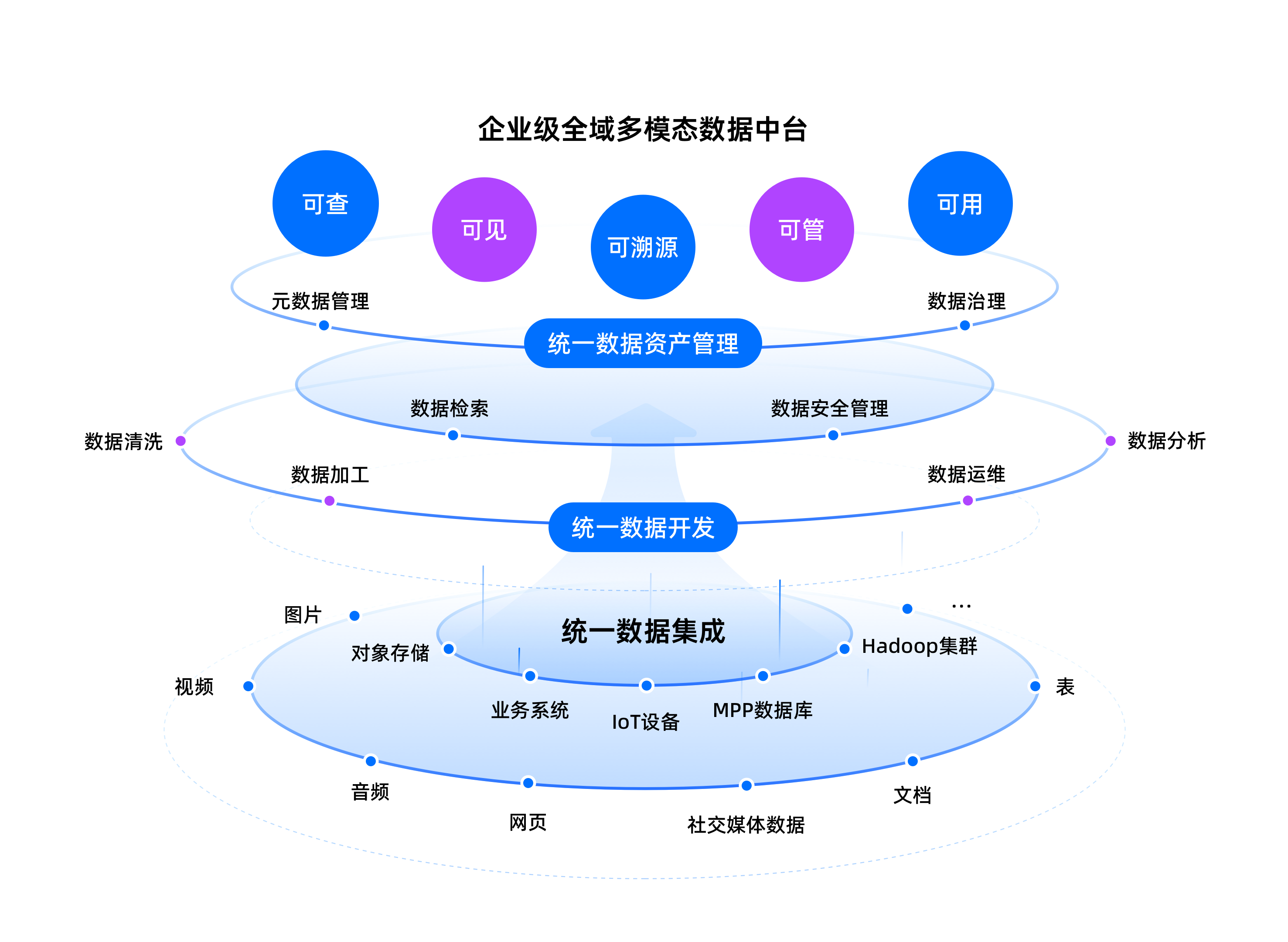
第一层,是统一承载。
结构化、非结构化、时序、时空等数据,需要进入同一套底座,才能形成真正可复用的数据资产。
第二层,是统一开发治理。
高质量数据集依赖清晰的业务对象、标签体系、语义关系、版本规则和权限边界,这些能力必须沉到平台层。
第三层,是统一供给。
数据集不能只服务某一次训练任务,它还要支撑知识问答、预测预警、智能分析、Agent 执行等不同场景,形成持续供给能力。

从这个角度看,高质量数据集建设已经不只是一个专项任务,它更像一场能力测试。企业要回答的问题很直接:能不能把行业 know-how、业务流程和多模态数据沉成稳定的数据供给体系。
把高质量数据集做深,关键是走通咨询、治理与应用供给
高质量数据集进入企业真实建设阶段后,竞争焦点已经落到体系化能力上。袋鼠云对这件事的理解,是把高质量数据集建设放进一条完整路径里来推进:
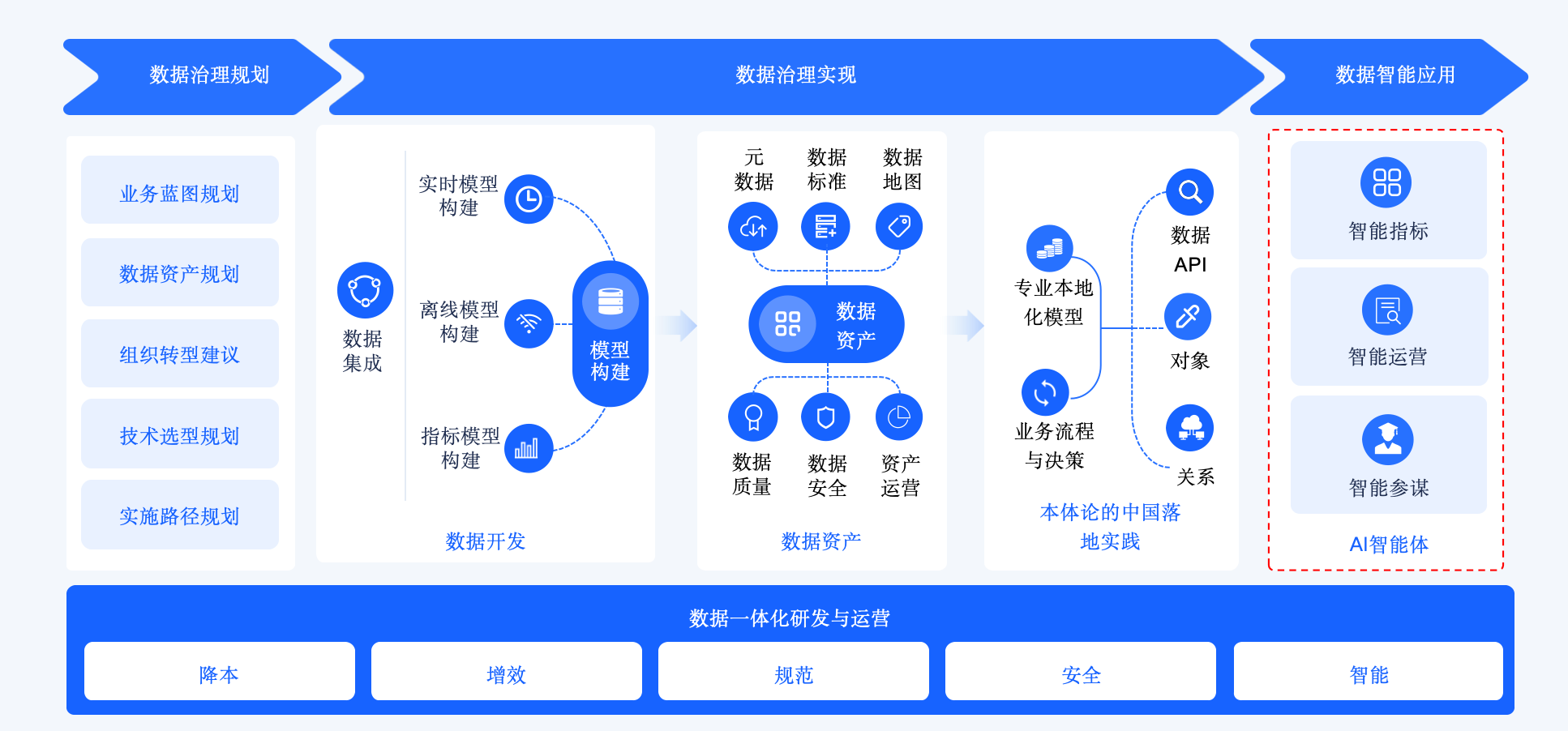
袋鼠云数据治理工程全链路
前端先做咨询与规划,从业务蓝图、数据资产边界、组织机制、技术路线和实施节奏入手,先把企业为什么建、围绕什么建、优先建什么说清楚。
中段进入治理建设,通过数据集成、离线与实时模型构建、指标模型沉淀、元数据与标准体系建设、质量安全管理和资产运营,把分散数据逐步沉淀为可管理、可复用、可服务的数据资产。
后端再把这些治理成果进一步组织成可供调用的对象、关系、API 和业务语义能力,持续面向智能指标、智能运营等场景供给。
数据治理最终要走向业务价值释放,走向智能应用落地,走向企业在 AI 时代可持续的数据供给能力。
就像过去,很多企业更关注数据规模;接下来,竞争会更集中到治理能力。过去,很多企业把重点放在模型接入;接下来,数据能否承载行业知识,会成为更核心的分水岭。过去,很多项目追求的是把一个场景快速做出来;接下来,真正拉开差距的,会是高质量数据能否持续、稳定、规模化供给。
高质量数据集持续升温,表面上看是数据资源建设提速,实际抬高的,是企业的数据治理能力、数据工程能力,以及多模态数据底座能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)