构建测试专属 AI Agent。让 AI 成为你的 24 小时质量专家(含完整代码与部署指南
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
想象一下:
🗣️ 对着 IDE 说:“生成支付模块的冒烟测试用例” → 自动生成符合规范的 Pytest 代码
📊 上传 Allure 报告 → AI 自动总结:“失败集中在优惠券叠加场景,建议补充边界值”
🔍 遇到偶发失败 → 问:“这个 Selenium 超时可能是什么原因?” → 结合历史日志给出根因
这就是 测试专属 AI Agent 的能力——将你的项目知识、测试经验、缺陷模式注入 AI,打造永不疲倦的质量副驾驶。
本文提供 端到端实现方案,从数据准备到 PyCharm 集成,助你落地专属 AI 助手。
🎯 一、为什么需要“测试专属”AI Agent?
表格
通用 AI(如 Copilot) 测试专属 AI Agent
❌ 不了解你的项目结构 ✅ 熟悉 tests/api/ vs tests/ui/ 目录规范
❌ 无法访问私有缺陷库 ✅ 学习过 Jira 中 1000+ 历史缺陷
❌ 生成泛化测试用例 ✅ 知道“支付必须校验幂等性”等业务规则
❌ 无法分析 Allure 报告 ✅ 能解析你的测试报告并提供建议
💡 核心价值:将团队隐性知识显性化,让新人秒变专家
🧱 二、系统架构设计
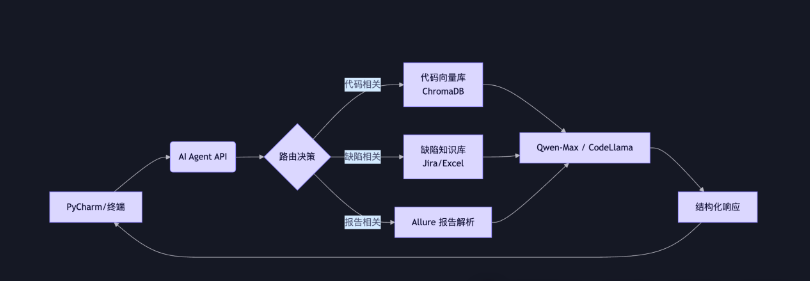
核心组件:
知识库:项目代码 + 缺陷数据 + 测试文档
向量化引擎:将文本转为语义向量
大模型:Qwen(高精度)或本地 CodeLlama(私有)
Agent 路由:根据问题类型选择知识源
PyCharm 集成:无缝嵌入开发环境
🛠️ 三、实战:四步构建你的测试 AI Agent
步骤 1:准备知识库(注入团队智慧)
1.1 项目代码索引
# index_code.py
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
def index_project_code(project_path: str, persist_dir: str):
# 加载所有 Python 文件
loader = DirectoryLoader(project_path, glob="**/*.py")
docs = loader.load()
# 按函数/类分块(保留上下文)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=600,
chunk_overlap=100,
separators=["\n\ndef ", "\n\nclass "]
)
splits = text_splitter.split_documents(docs)
# 向量化并存储
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"),
persist_directory=persist_dir
)
vectorstore.persist()
print(f"Indexed {len(splits)} code chunks to {persist_dir}")
# 执行索引
index_project_code("./my_project", "./vectorstores/code")1.2 缺陷知识库构建
# index_defects.py
import pandas as pd
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
def index_defects(jira_csv: str, persist_dir: str):
df = pd.read_csv(jira_csv)
# 构造缺陷描述文本
defect_texts = []
for _, row in df.iterrows():
text = f"""
缺陷ID: {row['issue_key']}
标题: {row['summary']}
描述: {row['description']}
根因: {row['root_cause']}
解决方案: {row['resolution']}
模块: {row['component']}
"""
defect_texts.append(text)
# 向量化
vectorstore = Chroma.from_texts(
texts=defect_texts,
embedding=OllamaEmbeddings(model="nomic-embed-text"),
persist_directory=persist_dir
)
vectorstore.persist()
# 从 Jira 导出 CSV 后执行
index_defects("jira_defects.csv", "./vectorstores/defects")📌 数据源建议:
代码:Git 仓库
缺陷:Jira / Azure DevOps 导出
文档:Confluence / Markdown 测试规范
步骤 2:搭建 AI Agent 核心引擎
2.1 定义工具(Tools)
# tools.py
from langchain_core.tools import tool
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
@tool
def search_code(query: str) -> str:
"""搜索项目代码库,返回相关代码片段"""
vectorstore = Chroma(
persist_directory="./vectorstores/code",
embedding_function=OllamaEmbeddings(model="nomic-embed-text")
)
results = vectorstore.similarity_search(query, k=3)
return "\n\n".join([doc.page_content for doc in results])
@tool
def search_defects(query: str) -> str:
"""搜索历史缺陷库,返回相似缺陷案例"""
vectorstore = Chroma(
persist_directory="./vectorstores/defects",
embedding_function=OllamaEmbeddings(model="nomic-embed-text")
)
results = vectorstore.similarity_search(query, k=2)
return "\n\n".join([doc.page_content for doc in results])2.2 创建 Agent 执行器
# agent.py
from langchain import hub
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_ollama import OllamaLLM
from tools import search_code, search_defects
def create_test_agent():
# 初始化大模型(可替换为阿里云百炼 API)
llm = OllamaLLM(model="qwen:7b", temperature=0.2)
# 获取预设 Prompt(支持中文)
prompt = hub.pull("hwchase17/openai-functions-agent")
# 绑定工具
tools = [search_code, search_defects]
agent = create_tool_calling_agent(llm, tools, prompt)
return AgentExecutor(agent=agent, tools=tools, verbose=True)
# 全局 Agent 实例
test_agent = create_test_agent()步骤 3:扩展高级能力(测试专项)
3.1 Allure 报告分析
# allure_analyzer.py
import xml.etree.ElementTree as ET
def parse_allure_report(report_path: str) -> str:
"""解析 Allure 测试报告,提取失败用例模式"""
tree = ET.parse(f"{report_path}/widgets/summary.json")
summary = tree.getroot()
failed_tests = []
for suite in summary.findall(".//testSuite"):
if suite.find("statistic/failed").text != "0":
suite_name = suite.get("name")
failed_count = suite.find("statistic/failed").text
failed_tests.append(f"{suite_name}: 失败 {failed_count} 个用例")
return "近期失败热点:\n" + "\n".join(failed_tests[:5])
# 在 Agent 中注册为工具
@tool
def analyze_allure() -> str:
return parse_allure_report("./allure-report")3.2 测试用例生成器
# test_generator.py
TEST_PROMPT_TEMPLATE = """
你是一名资深测试工程师,请为以下函数生成 pytest 用例:
要求:
1. 覆盖正常流、异常流、边界值
2. 使用 @pytest.mark.parametrize
3. 包含中文注释
4. 遵循团队规范:用例名以 test_ 开头
函数代码:
@tool
def generate_test_cases(code_snippet: str) -> str:
"""根据代码片段生成测试用例"""
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen:7b")
prompt = TEST_PROMPT_TEMPLATE.format(code=code_snippet)
return llm.invoke(prompt)步骤 4:部署与集成(让 Agent 随时可用)
4.1 启动 HTTP 服务
# server.py
from flask import Flask, request, jsonify
from agent import test_agent
app = Flask(__name__)
@app.route('/ask', methods=['POST'])
def ask_agent():
query = request.json['query']
# 路由逻辑:根据问题类型选择工具
if "生成测试" in query or "写用例" in query:
# 调用专用生成器
code = request.json.get('code', '')
result = generate_test_cases(code)
elif "allure" in query or "报告" in query:
result = analyze_allure()
else:
# 通用问答
response = test_agent.invoke({"input": query})
result = response["output"]
return jsonify({"answer": result})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)4.2 集成到 PyCharm
安装 REST Client 插件
创建 test_agent.http 文件:
### 生成测试用例
POST http://localhost:8080/ask
Content-Type: application/json
{
"query": "生成用户登录测试用例",
"code": "def login(username, password): ..."
}
### 分析缺陷
POST http://localhost:8080/ask
Content-Type: application/json
{
"query": "支付超时有哪些历史案例?"
}在编辑器中按 Alt+Enter → Send Request,结果直接显示
💡 进阶:用 PyCharm Plugin SDK 开发侧边栏插件,实现语音输入!
📊 四、效果验证:真实场景演示
场景 1:生成符合规范的测试用例
用户输入:
“为 calculate_discount 函数生成测试用例,需覆盖 VIP/普通用户”
Agent 输出:
import pytest
@pytest.mark.parametrize("user_level, expected_discount", [
("VIP", 0.8), # VIP 享受 8 折
("regular", 1.0), # 普通用户无折扣
("", 1.0), # 空用户级别视为普通
])
def test_calculate_discount(user_level, expected_discount):
"""测试不同用户级别的折扣计算"""
price = 100.0
result = calculate_discount(price, user_level)
assert result == price * expected_discount场景 2:分析缺陷根因
用户输入:
“最近支付模块有哪些偶发失败?”
Agent 输出:
根据历史缺陷库,近 3 个月支付模块偶发失败主要集中在:
DEF-1234:第三方支付网关超时(发生于网络波动时)
解决方案:增加 3 秒超时重试机制
DEF-1567:并发下单导致库存超卖
解决方案:数据库行锁 + 库存预占
建议:在自动化中增加网络延迟混沌实验
⚠️ 五、避坑指南与优化建议
常见问题:
|
问题 |
解决方案 |
|---|---|
|
响应慢 |
1. 用 GPU 加速 Ollama |
|
答案不准确 |
1. 优化分块策略(按函数而非固定长度) |
|
内存溢出 |
1. 限制向量库大小 |
提升效果的关键:
高质量知识注入:清洗缺陷数据,补充根因字段
精准 Prompt 设计:明确角色(“你是一名金融测试专家”)
反馈闭环:记录用户对答案的评分,持续优化
💎 结语:你的团队知识,值得被 AI 记住
测试专属 AI Agent 不是炫技,而是将团队多年积累的隐性知识转化为可复用的资产。
通过本文方案,你将获得:
✅ 24 小时在线的质量顾问
✅ 新人快速上手的智能导师
✅ 缺陷预防的预测能力
现在就开始行动:
今天:用 Ollama 跑通 Qwen 7B
本周:索引你的项目代码库
本月:在团队内试用 AI Agent,收集反馈
未来的质量保障,属于那些善用 AI 放大专业价值的人。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)