知识图谱实战(知识查询语言、NER)【第三章】
一、Cypher
Cypher是一种声明式图形查询语言, 可用于图结构高效的查询更新和管理. 从语法规则上看, Cypher既受到SQL的启发, 又在模式匹配上借鉴了SPARQL的表达方法, 某些列表语义则是从Haskell和Python等语言中借用的. 综合来看Cypher是一种简介, 强大, 专为图数据库而生的新兴查询语言, 是AI新时代的杰出语言.
- Cypher是专门为图形数据而遍历设计和优化的, 被neo4j采用为官方查询语言
后续主要使用Cypher来进行neo4j数据库的操作
二、NER
NER(命名实体识别)有常用的两种方法:
- 基于规则的方式实现NER
- 基于机器学习方法实现NER
- 基于深度学习模型实现NER
常见的实体包括七种类别:人名、地名、机构名、时间、日期、货币、百分比。
2.1基于规则的方式实现NER
针对有特殊上下文的实体,或实体本身有很多特征的文本,使用规则的方法简单且有效。
比如抽取文本中物品价格,如果文本中所有商品价格都是“数字+元"的形式,则可以通过正则表达式"d*.?d+元"进行抽取。但如果待抽取文本中价格的表达方式多种多样,例如“一千八百万”,“伍佰贰拾圆”,“2000万元”,遇到这些情况就要修改规则来满足所有可能的情况。随着语料数量的增加,面对的情况也越来越复杂,规则之间也可能发生冲突,整个系统也可能变得不可维护。因此基于规则的方式比较适合半结构化或比较规范的文本中的进行抽取任务,结合业务需求能够达到一定的效果。
优点:简单,快速。
缺点:适用性差,维护成本高后期甚至不能维护。
2.2基于机器学习的方式实现NER
早期使用于命名实体识别任务之中的机器学习方法,主要是一些基于统计的方法。使用统计方法,包括三个步骤:
①选择特征。传统统计方法需要人工选择特征。这些特征包括词语上下文信息、词缀、词性上下文特征等等。
②选择模型并训练模型。
③预测实体。这一步是使用已经训练好的模型来预测实体。
一般使用统计模型是把实体抽取任务转化为序列标注问题,使用IO、BIO、BIOES等标注方法对实体进行标注。
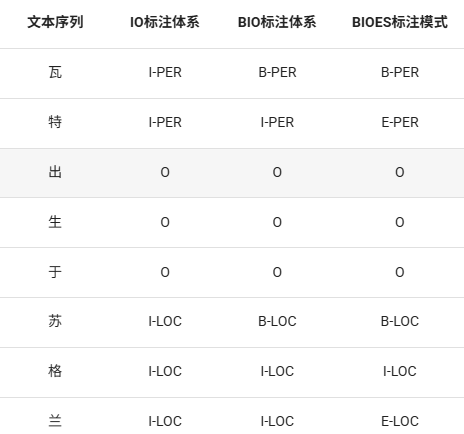
例举不同标注方法的样式
IO:实体开头是I,后面加标注类型(PER、LOC)非实体为O
BIO(使用最多):相较于IO,实体开头的token标注是B
BIOES:相较于IO,实体结尾token标注是E。sigle指的是单token实体会被标注为S(梨,花等)。
常见的序列标注模型有支持向量机(SVM)、隐马尔科夫模型(HMM)、条件随机场(CRF)(条件随机场效果最好)。
缺点:序列的特征构建至关重要,人工设计的特征极大影响了实体抽取的效果
2.3基于深度学习的方式实现NER
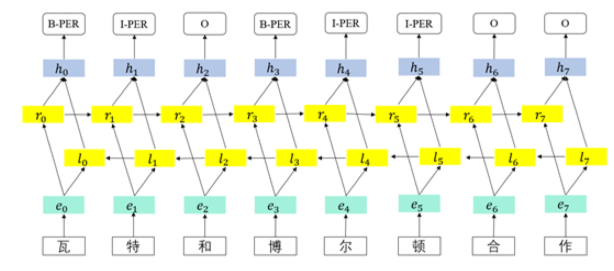
常见的实现NER的深度学习模型:CNN(卷积神经网络),RNN(循环神经网络),LSTM(长短期记忆神经网络)等。BILSTM-CRF是目前最常见的命名实体识别模型。
下面是BILSTM-CRF实现序列标注的原理:序列输入进来以后,经过BILSTM-CRF实现序列的标注。
优点:基于深度学习的方法,不需要人工来设计特征,同时能够取得较高的准确率和召回率。
缺点:但是这些模型十分依赖人工标注数据,标注语料的缺乏为模型的训练带来了极大的困难。
三、使用doccono实现NER
选择标注项目

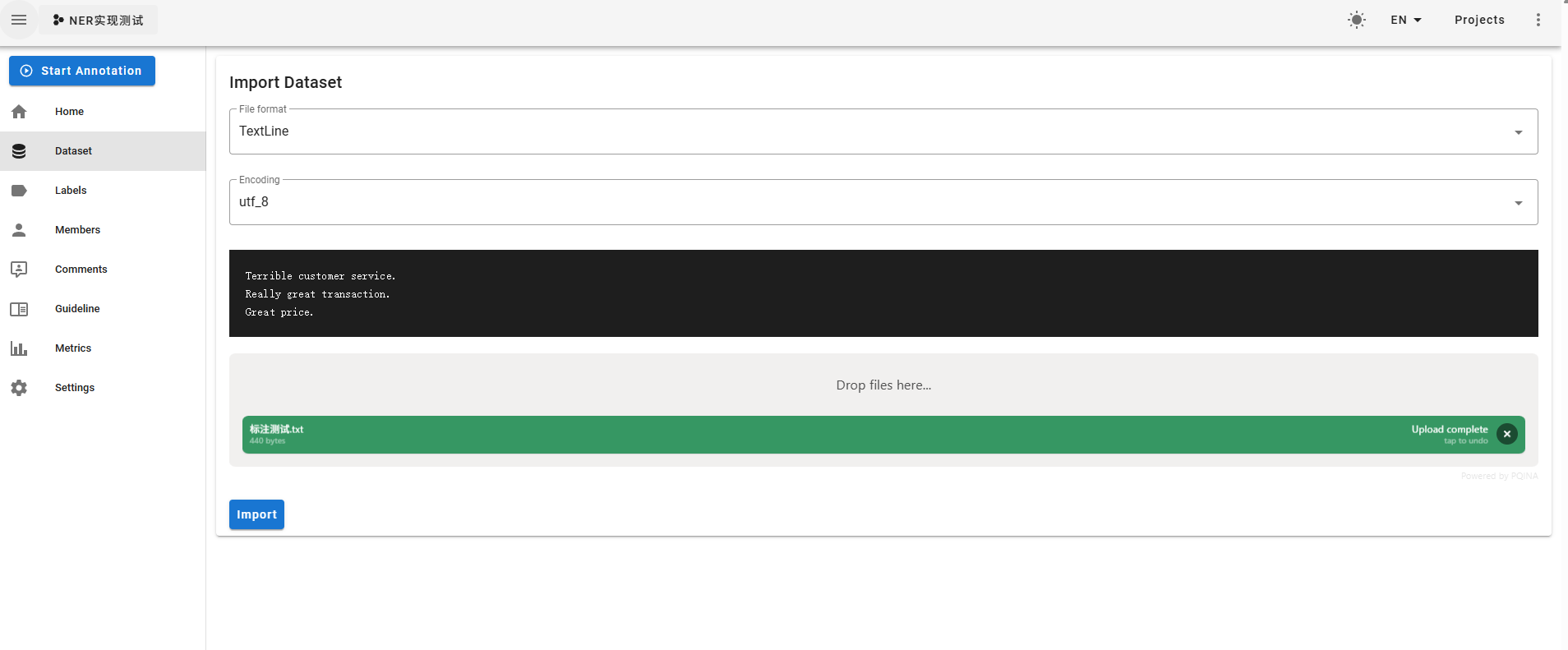
导入数据集
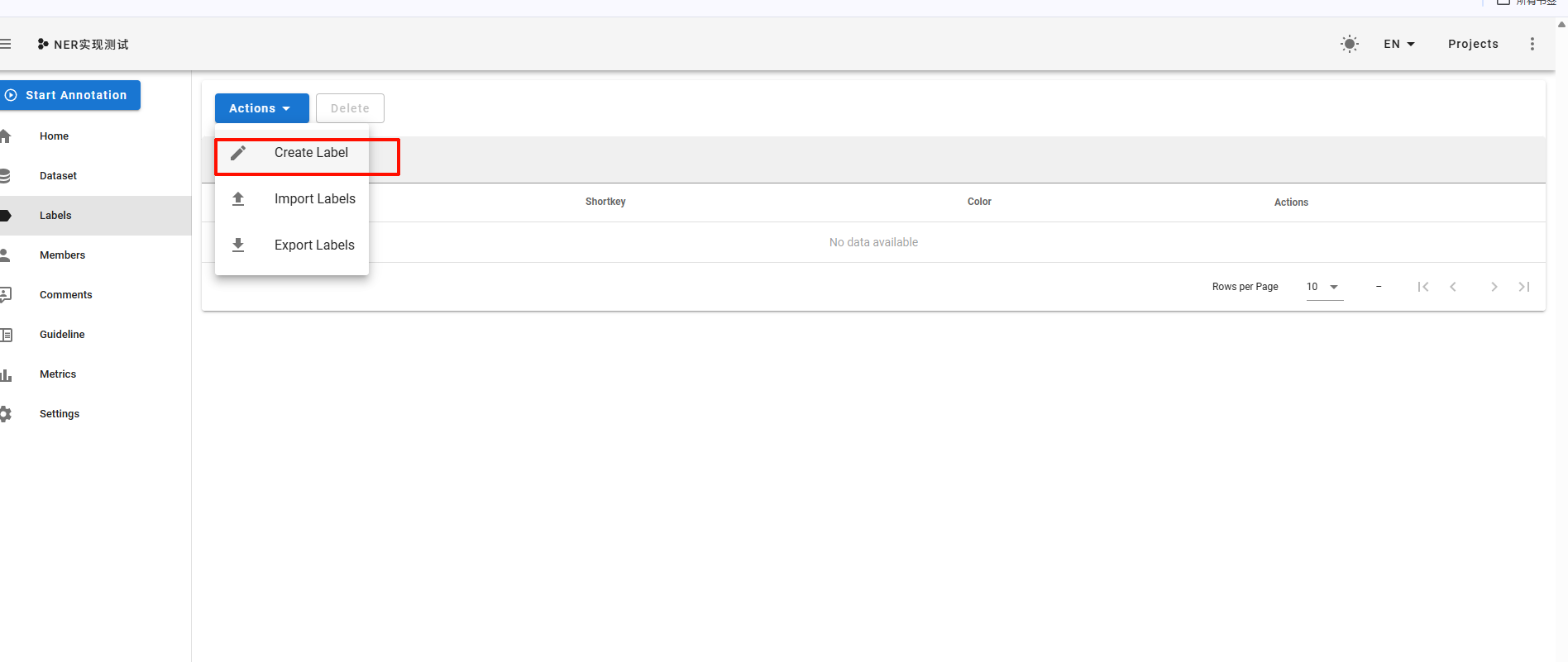
创建标签
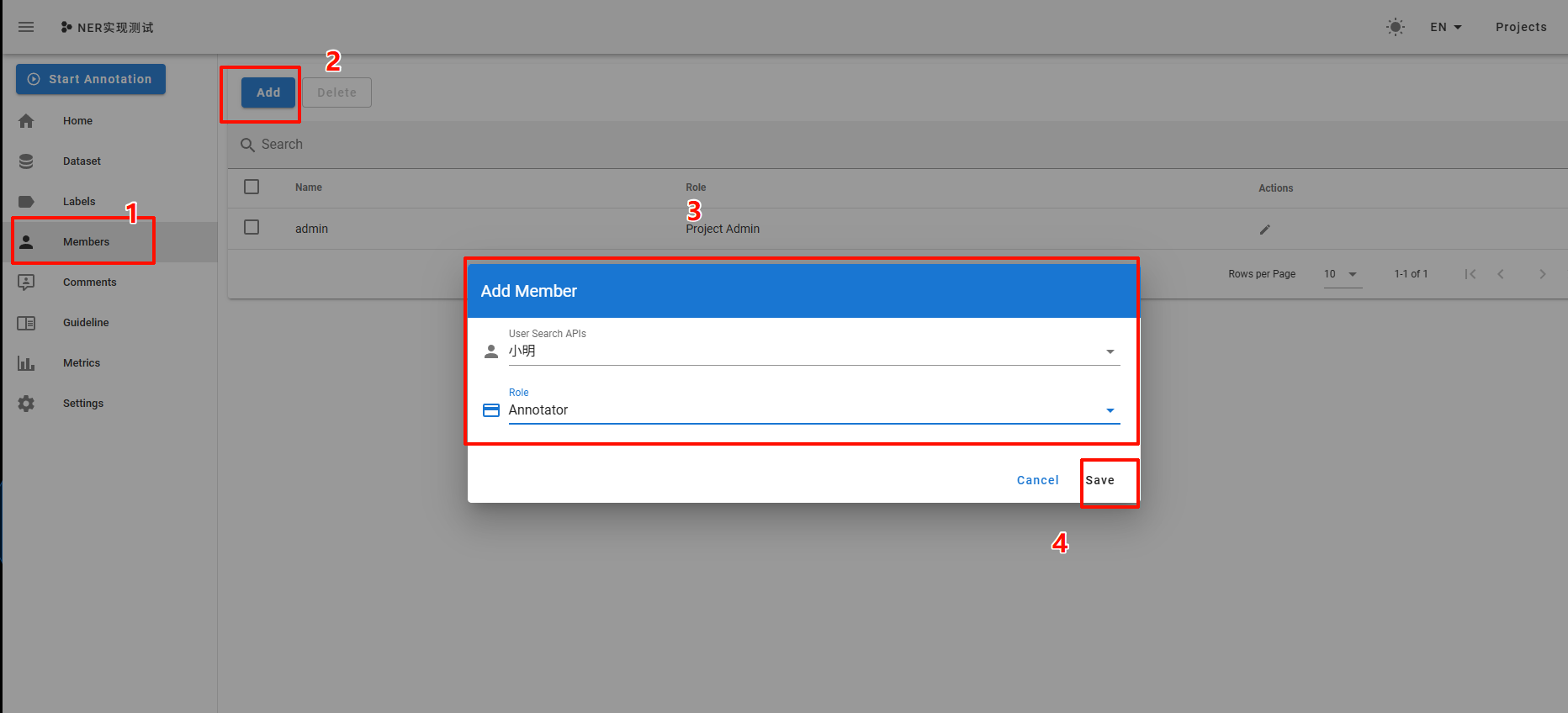
添加标注成员
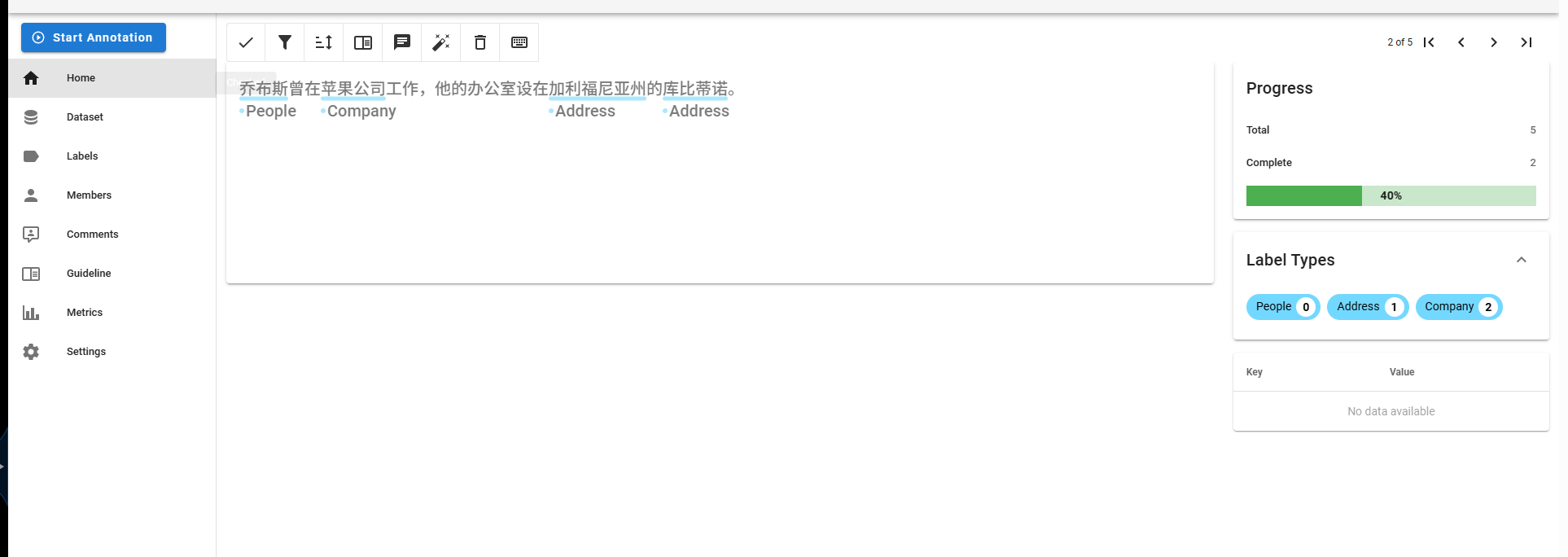
标注数据
导出标注好的数据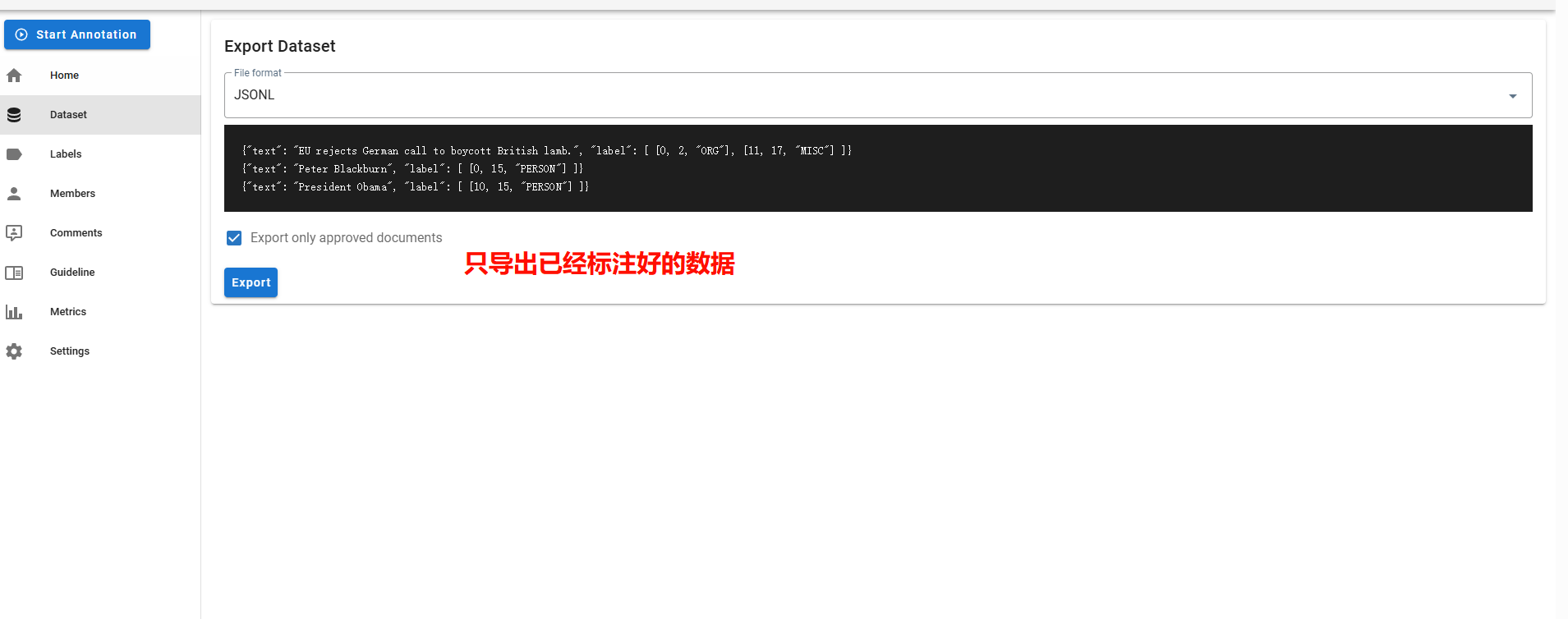
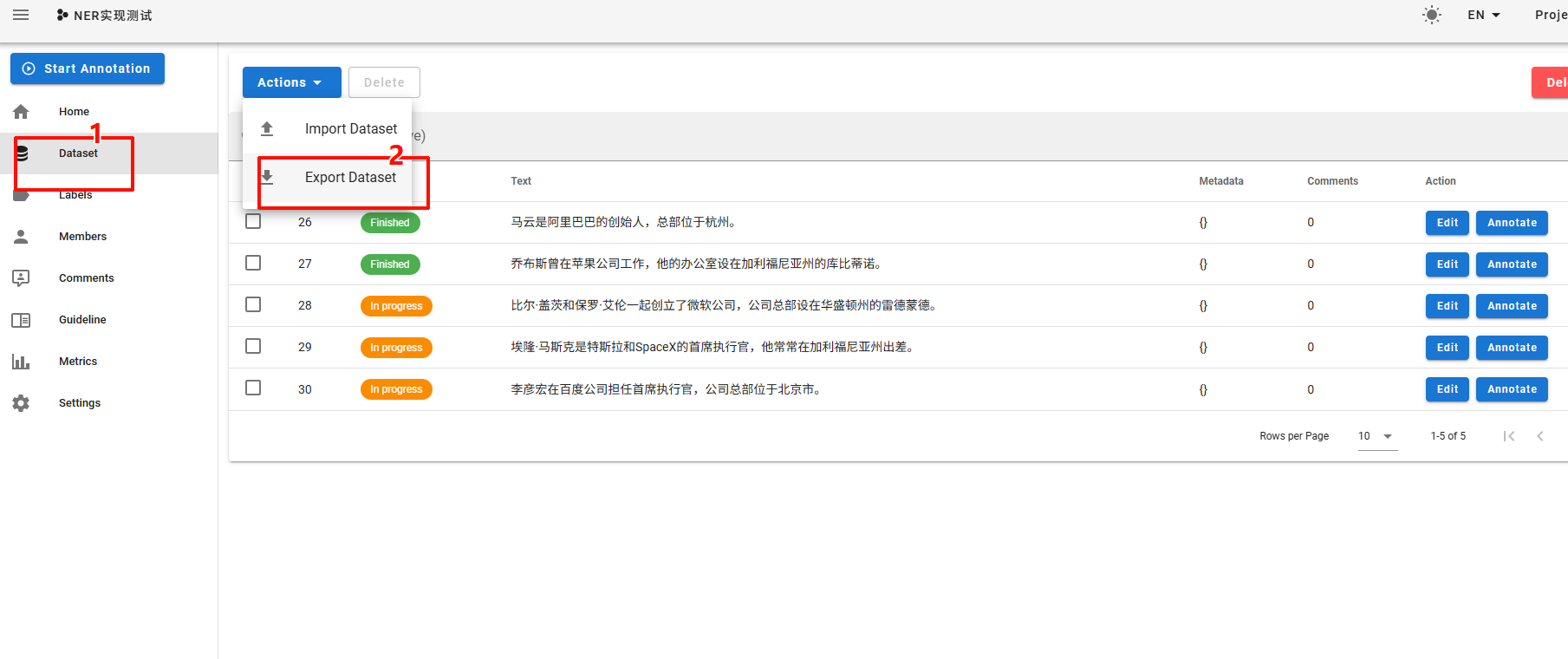 导出成功
导出成功
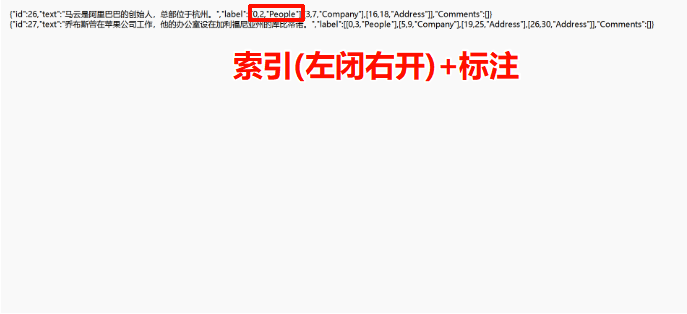
四、NER评测标准
- NER的评测标准通常包括:准确率 ( Precision ) 、召回率 ( Recall ) 和 F1 值三个方面
- 准确率:模型识别出来的实体中,被所有预测为正的样本中实际为正样本的概率
- 召回率:模型识别出来的实体中,实际为正的样本中被预测为正样本的概率
- 而 F1 值则是准确率和召回率的调和平均值,可以对系统的性能进行综合性的评价
- 对应的计算为:

4.1NER的常见问题
- 现阶段的实体抽取模型很少考虑标签重叠问题。所谓标签重叠,指的是每个词或字具有两种以上的标签。而现阶段的模型,每个词或字只能属于某一类标签。对于多标签的实体抽取,仍然是实体抽取未来的主要研究方向之一。
- 目前的实体抽取方法大都局限于抽取人名、地名、机构名等传统实体类别,而实际应用中,所需要抽取的类别会更多,并且缺乏标注数据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)