京东大模型面试真题解析(非常详细),混合检索权重与RRF调参全解,收藏这一篇就够了!
前段时间有个学员找我复盘,他去面京东的AI算法岗,项目经历里写了一个金融保险公司的RAG问答系统,提到"用混合检索把召回率提升了17%"。
面试官一上来就很感兴趣,问他:“你这个混合检索是怎么做的?”
他答:“用了BM25加向量检索,然后用RRF做结果融合。”
面试官点点头,追问:“BM25和向量检索的权重比例你是怎么定的?”
他答:“用了RRF,不需要手动设置权重。”
面试官继续追:“RRF的k值你用的多少?”
他答:“用的默认值,60。”
面试官追得更紧了:“k=60这个数字是怎么来的?你为什么不用50,不用100?”
他卡住了。
面试官最后说了一句话:“你能说出用了什么,但说不出为什么这么用,这在生产环境里是不够的。”
这句话把问题说透了。混合检索不是把两种方法拼在一起那么简单,每一个参数背后都有它的道理。今天我们就把这件事从头讲清楚。
纯向量检索为什么不够用?
在讲混合检索之前,得先搞清楚一个问题:向量检索那么强,为什么还需要BM25?
我们项目的背景是这样的:金融保险公司,文档库里有5000份保险合同和理赔文档,用户通过对话系统查询保险条款、理赔规则、投保细节。这类场景有个非常典型的特点——用户的查询里经常包含大量专有名词和精确词。
比如用户问:“平安健康险2023版的等待期是多少天?”
这个查询里,"平安健康险2023版"是一个精确的产品标识,"等待期"是保险行业的专有术语。
向量检索怎么处理这个查询?它把整个问题编码成一个向量,然后在文档库里找语义最相近的段落。问题来了:向量模型学到的是语义相似性,“等待期"这个词在语义空间里和"观察期”、“免责期”、"生效时间"都很接近。结果向量检索可能返回的是另一个产品(比如中国人寿某款健康险)的等待期条款,因为语义上确实很像,但产品名称对不上。
这就是向量检索的核心弱点:对精确关键词、产品编号、专有名词,它的召回能力明显不足。
BM25在这个场景下有天然优势。BM25是基于词频统计的检索算法,"平安健康险2023版"这个字符串如果在某个文档里精确出现,BM25就会给这个文档很高的分数。对于长尾稀疏查询——也就是那些包含特定词汇、在语料里出现频次不高的查询——BM25的表现往往好于向量检索。
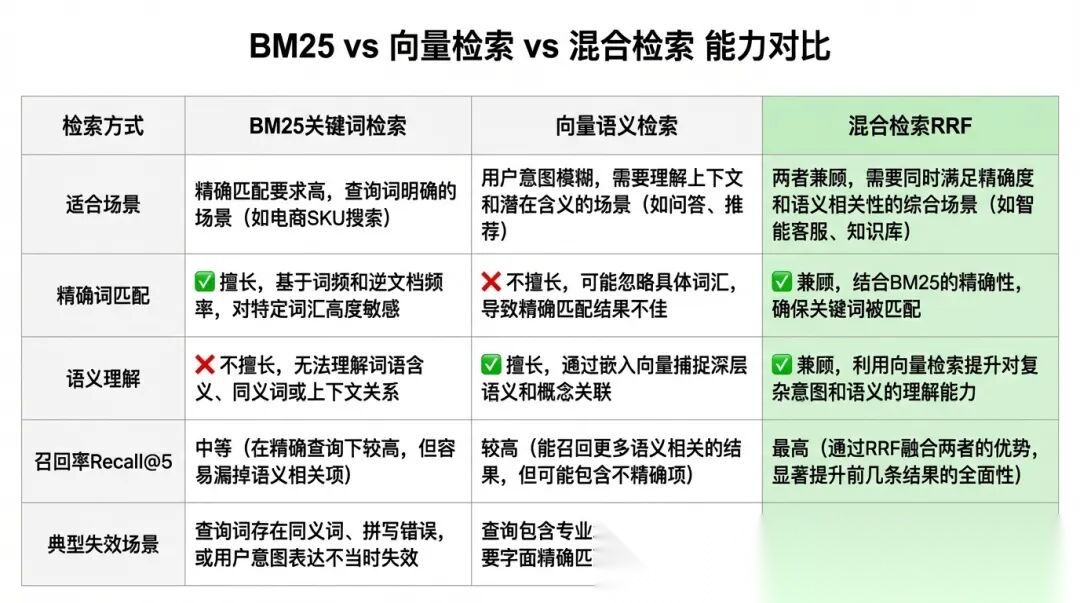
BM25 vs 向量检索 vs 混合检索 能力对比
用一个具体数字说明:在我们的测试集中,对于包含产品名称或专有术语的查询,纯向量检索的Recall@5只有0.48,而BM25单独使用能到0.71。但对于语义模糊、措辞多样的查询(比如"发生事故后要怎么报案",用户可能说"出险"也可能说"理赔申请"),BM25的召回率只有0.54,向量检索能到0.79。两者各有擅长,所以我们需要混合。
要真正用好BM25,光知道"它擅长精确词匹配"是不够的,还得搞清楚它内部是怎么打分的,参数背后是什么逻辑。
BM25原理:词频饱和与长度归一化
BM25的全称是Best Match 25,是Okapi BM25的简称,Robertson等人在1990年代提出。它的核心公式是:
公式里有几个关键部分,逐一拆开看。
IDF(逆文档频率):一个词在越少文档里出现,它的IDF越高,说明这个词越有区分度。"等待期"在保险合同里不算高频词,IDF相对较高;"保险"这个词几乎每个文档都有,IDF接近零,对检索贡献很小。
tf(词频):这个词在当前文档里出现了多少次。出现次数越多,分数越高,但BM25做了饱和处理。
k1(词频饱和参数,默认1.5):这是BM25最重要的参数之一。它控制词频对分数的边际贡献。如果k1很大,词频越高分数越高,线性增长;如果k1很小,词频超过一定次数后增益就趋于饱和。默认值1.5在大多数场景下表现稳定。在我们的保险文档场景里,由于文档都是条款性文本,词频分布比较均匀,k1不需要调整。
b(长度归一化,默认0.75):控制文档长度对分数的影响程度。b=1表示完全做长度归一化,b=0表示不做归一化。保险合同文档长短差异较大,有的免责条款只有几百字,有的理赔细则有几千字,b=0.75能有效避免长文档被过度惩罚。
avgdl:文档库中所有文档的平均长度,|D|是当前文档长度。
在Python里实现BM25,我们用的是rank_bm25库,代码如下:
from rank_bm25 import BM25Okapiimport jiebaclassBM25Retriever: def__init__(self, documents, k1=1.5, b=0.75): # 对文档做中文分词 tokenized_docs = [list(jieba.cut(doc)) for doc in documents] self.bm25 = BM25Okapi(tokenized_docs, k1=k1, b=b) self.documents = documents defretrieve(self, query, top_k=20): tokenized_query = list(jieba.cut(query)) scores = self.bm25.get_scores(tokenized_query) # 返回top_k个文档的索引和分数 top_indices = scores.argsort()[-top_k:][::-1] return [(idx, scores[idx]) for idx in top_indices]
如果线上系统已经有Elasticsearch,也可以直接用ES自带的BM25实现。ES从5.0版本开始默认使用BM25替代TF-IDF,配置如下:
{ "settings": { "similarity": { "custom_bm25": { "type": "BM25", "k1": 1.5, "b": 0.75 } } },"mappings": { "properties": { "content": { "type": "text", "similarity": "custom_bm25" } } }}
BM25这端搞清楚了,另一端的向量检索同样有不少工程决策需要做,尤其是中文场景下Embedding模型的选型,选错了对效果影响很大。
向量检索:Embedding模型选择与索引结构
向量检索这块,中文场景下Embedding模型的选择直接影响召回质量。我们在项目里对比测试了几个方案:
- text2vec-large-chinese:中文优化,在中文语义理解上表现不错,但向量维度1024,索引体积较大
- BGE-large-zh(BAAI/bge-large-zh-v1.5):当前中文开源Embedding效果最好的选项之一,MTEB中文榜单长期排名靠前,维度1024
- BGE-m3:支持多语言,在混合中英文的保险条款场景里有优势(部分条款会引用英文缩写如"IPO锁定期")
最终选了BGE-large-zh-v1.5,在我们的业务测试集上比text2vec高出约4个百分点。
Embedding生成代码:
from sentence_transformers import SentenceTransformerimport numpy as npclassVectorRetriever: def__init__(self, model_name="BAAI/bge-large-zh-v1.5"): self.model = SentenceTransformer(model_name) defencode(self, texts, batch_size=32): # BGE模型推荐在查询前加前缀 if isinstance(texts, str): texts = "为这个句子生成表示以用于检索相关文章:" + texts embeddings = self.model.encode( texts, batch_size=batch_size, normalize_embeddings=True# 归一化后可以用内积代替余弦距离 ) return embeddings defretrieve(self, query, index, top_k=20): query_embedding = self.encode(query) distances, indices = index.search( np.array([query_embedding], dtype=np.float32), top_k ) return list(zip(indices[0], distances[0]))
索引结构这里有一个常被忽视的选择问题:Faiss提供多种索引类型,常用的有两种:
IVF+PQ(倒排文件索引+乘积量化):离线批量构建和召回效率高,内存占用小,但需要训练阶段,适合离线构建大规模索引。我们5000份文档经过分块后大约有8万个向量,用IVF4096,PQ64配置,内存占用约400MB,批量召回QPS可以达到每秒数千次。
HNSW(层次可导航小世界图):构建时间更长、内存占用更大,但查询延迟极低(P99在5ms以内),适合线上实时检索。线上服务我们用HNSW,离线评估和批量重建用IVF+PQ。
import faissimport numpy as npdefbuild_hnsw_index(embeddings, dim=1024, M=32, ef_construction=200): """ M: 每个节点的最大连接数,越大精度越高但内存越大 ef_construction: 构建时的搜索范围,越大精度越高但构建越慢 """ index = faiss.IndexHNSWFlat(dim, M) index.hnsw.efConstruction = ef_construction index.hnsw.efSearch = 64 # 查询时的搜索范围 embeddings_array = np.array(embeddings, dtype=np.float32) index.add(embeddings_array) return index
两路检索各自准备好了,下一个问题就是:怎么把它们的结果合并在一起?这正是面试官追问的核心——RRF。
RRF融合算法:k=60从哪来的?
这是整篇文章最核心的部分,也是面试官追问的关键。
RRF的全称是Reciprocal Rank Fusion,由Cormack、Clarke和Buettcher在2009年的SIGIR论文《Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods》中提出。
算法本身非常简洁:
defrrf_fusion(bm25_results, vector_results, k=60): """ bm25_results: BM25检索结果列表,按分数降序排列,元素为doc_id vector_results: 向量检索结果列表,按相似度降序排列,元素为doc_id k: RRF平滑参数,默认60 返回: 按融合分数降序排列的(doc_id, score)列表 """ scores = {} for rank, doc_id in enumerate(bm25_results): scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank + 1) for rank, doc_id in enumerate(vector_results): scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank + 1) return sorted(scores.items(), key=lambda x: x[1], reverse=True)
```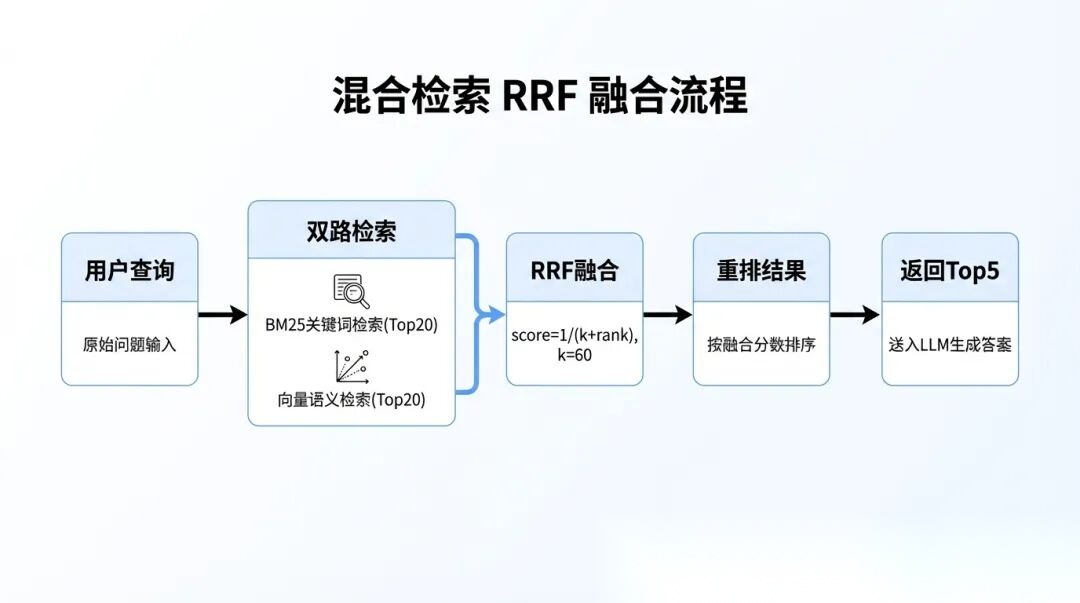
混合检索 RRF 融合流程
理解RRF的关键在于理解分数公式`1/(k+rank+1)`的含义。
rank从0开始,排名第1的文档得分是`1/(k+1)`,排名第2是`1/(k+2)`,以此类推。如果一个文档在BM25结果和向量结果里都出现了,它的最终分数就是两个`1/(k+rank)`的累加。
**k=60是怎么来的?**
Cormack等人在2009年的论文里做了大量实验,测试了不同k值在多个IR基准数据集上的表现。实验结论是:k=60在大多数场景下能取得最佳的融合效果,而且对k值的选取不是特别敏感——k在40到80之间,性能差异通常在1%以内。
从数学直觉上理解:k的作用是控制排名靠前的文档相对于后面文档的权重差距。
* k很小(比如k=1):排名第1的文档分数`1/2=0.5`,排名第2是`1/3≈0.33`,差距巨大,算法对最高排名文档极度敏感
* k很大(比如k=1000):排名第1是`1/1001≈0.001`,排名第20是`1/1020≈0.00098`,差距极小,几乎把所有文档都拉平了
* k=60:排名第1是`1/61≈0.0164`,排名第20是`1/80=0.0125`,保持了合理的排名差距,同时对噪声不过度敏感
用Python验证一下不同k值的分数分布:
```plaintext
defcompare_k_values(top_n=10): k_values = [1, 10, 60, 100, 1000] print(f"{'rank':<6}", end="") for k in k_values: print(f"{'k='+str(k):<12}", end="") print() for rank in range(top_n): print(f"{rank+1:<6}", end="") for k in k_values: score = 1 / (k + rank + 1) print(f"{score:<12.5f}", end="") print()compare_k_values()# 输出示例:# rank k=1 k=10 k=60 k=100 k=1000# 1 0.50000 0.09091 0.01639 0.00990 0.00100# 2 0.33333 0.08333 0.01613 0.00980 0.00100# 10 0.09091 0.04762 0.01429 0.00909 0.00099
为什么用RRF而不是加权求和?
这是另一个面试高频追问。加权求和的方式是:
final_score = α * bm25_normalized_score + (1-α) * vector_normalized_score
这个方式有一个致命问题:BM25的分数和向量相似度分数的量纲完全不同。BM25分数受文档库大小、词频分布影响,可能是0.1到50的任意范围;向量相似度经过归一化后在0到1之间。直接加权求和前必须对两路分数做归一化,而归一化方式的选择又会引入新的超参数,且在不同批次的检索结果里分数范围可能变化。
RRF完全绕开了这个问题——它只用排名,不用分数。无论BM25返回的分数是0.3还是30,排名第1就是排名第1,得分1/(k+1)。这使得RRF在跨批次、跨模型更新时表现非常稳定,不需要重新校准归一化参数。
标准RRF默认把两路结果等权融合,但实际业务中有时候需要让某一路的贡献更大一些。这就引出了下一个问题:如果非要手动调整权重,该怎么做?
权重调优:如果非要加权怎么做?
RRF默认的行为是两路等权融合,但有时候业务上确实需要调整两路的权重。比如我们发现,在理赔查询类问题中BM25更可靠,而在产品咨询类问题中向量检索更稳定。
加权RRF的公式是:
score = α * 1/(k + rank_bm25 + 1) + (1-α) * 1/(k + rank_vector + 1)
实现代码:
defweighted_rrf_fusion(bm25_results, vector_results, k=60, alpha=0.5): """ alpha: BM25的权重,1-alpha是向量检索的权重 alpha=0.5 等价于标准RRF alpha>0.5 更偏重BM25,适合精确词查询多的场景 alpha<0.5 更偏重向量检索,适合语义查询多的场景 """ scores = {} for rank, doc_id in enumerate(bm25_results): scores[doc_id] = scores.get(doc_id, 0) + alpha * (1 / (k + rank + 1)) for rank, doc_id in enumerate(vector_results): scores[doc_id] = scores.get(doc_id, 0) + (1 - alpha) * (1 / (k + rank + 1)) return sorted(scores.items(), key=lambda x: x[1], reverse=True)
alpha值通过在验证集上做网格搜索确定。我们的做法是准备了一个500条人工标注的查询集,覆盖精确词查询、语义查询、混合查询三类,然后:
import numpy as npfrom tqdm import tqdmdefevaluate_recall_at_k(fusion_results, ground_truth, k=5): """计算Recall@k""" hits = 0 for query_id, relevant_docs in ground_truth.items(): top_k_docs = [doc_id for doc_id, _ in fusion_results[query_id][:k]] if any(doc in top_k_docs for doc in relevant_docs): hits += 1 return hits / len(ground_truth)# 网格搜索最优alphabest_alpha = 0.5best_recall = 0.0alpha_range = np.arange(0.1, 1.0, 0.1)for alpha in tqdm(alpha_range): fusion_results = {} for query_id, query in validation_queries.items(): bm25_res = bm25_retriever.retrieve(query, top_k=20) vector_res = vector_retriever.retrieve(query, faiss_index, top_k=20) bm25_doc_ids = [idx for idx, _ in bm25_res] vector_doc_ids = [idx for idx, _ in vector_res] fusion_results[query_id] = weighted_rrf_fusion( bm25_doc_ids, vector_doc_ids, k=60, alpha=alpha ) recall = evaluate_recall_at_k(fusion_results, ground_truth, k=5) if recall > best_recall: best_recall = recall best_alpha = alphaprint(f"最优alpha: {best_alpha:.1f}, 对应Recall@5: {best_recall:.4f}")# 我们项目的结果: 最优alpha: 0.4, 对应Recall@5: 0.8921# alpha=0.4意味着向量检索权重略高,符合我们文档以语义查询为主的特点
对于k值本身,如果业务场景特殊(比如文档库非常小,只有几百个文档),也可以做类似的网格搜索验证k=60是否仍然最优。我们在5000份文档上验证过,k=60确实是局部最优,k=40和k=80的Recall@5差距在0.3%以内。
参数调好了,最终到底能带来多大提升?下面用实际数据说话。
实战效果:混合检索带来了什么?

混合检索 vs 纯向量检索 效果对比
上线混合检索之前,我们在测试集上做了完整的A/B对比:
整体Recall@5从0.72提升到0.89,绝对提升17个百分点。
拆分来看:
- 语义查询类(如"发生意外如何申请理赔"):从0.79提升到0.85,提升约6个百分点。这类查询向量检索本来就做得不错,BM25的补充效果有限,但RRF融合后依然有小幅提升,因为BM25能额外召回一些包含关键动词的相关文档。
- 精确词查询类(如"重疾险豁免条款第三条"):从0.51提升到0.78,提升约27个百分点。BM25在这类查询上贡献最大,"豁免条款第三条"这样的精确词组,BM25几乎能100%命中,而向量检索则可能把"豁免条款第二条"也排进来。
- 专有名词查询类(如"平安健康险2023版等待期"):从0.48提升到0.73,提升约25个百分点。这是提升最显著的一类,BM25对产品型号、年份、专业术语的精确匹配能力是关键。
值得一提的是,混合检索对检索延迟的影响较小。BM25的检索速度极快(毫秒级),向量检索HNSW索引P99延迟约5ms,RRF融合本身是纯Python列表操作,不到1ms。整体端到端检索延迟从约7ms增加到约9ms,对用户感知无影响。
上面分开介绍了各个模块,实际项目里当然是把它们组合成一个完整的类来用,下面直接给出可以拿来参考的实现。
完整的混合检索实现
把上面所有部分组合成一个完整的检索类,供参考:
classHybridRetriever: def__init__( self, documents, embedding_model="BAAI/bge-large-zh-v1.5", bm25_k1=1.5, bm25_b=0.75, rrf_k=60, alpha=0.5 ): self.documents = documents self.rrf_k = rrf_k self.alpha = alpha # 初始化BM25 self.bm25_retriever = BM25Retriever( documents, k1=bm25_k1, b=bm25_b ) # 初始化向量检索 self.vector_retriever = VectorRetriever(embedding_model) # 构建Faiss HNSW索引 print("正在构建向量索引...") embeddings = self.vector_retriever.encode(documents) self.faiss_index = build_hnsw_index( embeddings, dim=embeddings.shape[1] ) print(f"索引构建完成,共{len(documents)}个文档") defretrieve(self, query, top_k=5, bm25_candidate=20, vector_candidate=20): # BM25检索 bm25_results = self.bm25_retriever.retrieve(query, top_k=bm25_candidate) bm25_doc_ids = [idx for idx, _ in bm25_results] # 向量检索 vector_results = self.vector_retriever.retrieve( query, self.faiss_index, top_k=vector_candidate ) vector_doc_ids = [idx for idx, _ in vector_results] # RRF融合 fused = weighted_rrf_fusion( bm25_doc_ids, vector_doc_ids, k=self.rrf_k, alpha=self.alpha ) # 返回top_k结果 top_results = fused[:top_k] return [ { "doc_id": doc_id, "content": self.documents[doc_id], "rrf_score": score } for doc_id, score in top_results ]
代码层面的东西梳理清楚了,最后来说一个更实际的问题:面试的时候遇到这类追问,该怎么组织语言回答才最有效?
面试怎么答混合检索?
这是面试中最容易被追问到底的技术点,回答要有层次,大约30-40秒说清楚。分4步走:
第一步,说背景和问题(5秒):先交代为什么要用混合检索。“我们的RAG系统在处理包含产品编号、专业术语的精确词查询时,纯向量检索的召回率只有0.48,存在明显的召回短板。”
第二步,说方案选择(10秒):说清楚为什么选BM25+向量+RRF这个组合,而不是其他方案。“BM25对精确词匹配有天然优势,向量检索擅长语义匹配,两者互补。RRF做融合是因为它不需要对两路分数做归一化,鲁棒性好,这是Cormack 2009年论文的结论,k=60是论文实验中在多个数据集上表现最稳定的值。”
第三步,说实现细节(10秒):说出你真正做了什么。“每路各取Top20候选,RRF融合后返回Top5。如果需要调整两路权重,用加权RRF,alpha通过在500条标注验证集上网格搜索确定,我们的最优值是0.4,略微偏向向量检索。”
第四步,说效果和数据(10秒):用数字收尾,显示你有量化评估意识。“上线后整体Recall@5从0.72提升到0.89,含专有名词的查询提升约25个百分点,检索延迟仅增加约2ms,整体在可接受范围内。”
这4步说完,面试官大概率不会再追问,因为你已经把背景、原理、实现、效果都覆盖了,而且每个点都有具体数字支撑,不是泛泛而谈。
光有理论框架还不够,真实部署中踩过的坑往往比原理更能打动面试官,也更能说明你真正上过生产。
一些踩坑经验
最后补充几个在实际部署中遇到的问题,这类细节在面试里往往能让你加分。
中文分词的质量直接影响BM25效果。Jieba默认词典不包含保险行业专有词汇,“免赔额"可能被切成"免/赔额”,“等待期"可能被切成"等待/期”。我们的解决方案是给Jieba添加自定义词典,把5000份文档里出现的保险专业术语全部收录进来,这一步让BM25的精确词召回率额外提升了约8个百分点。
import jieba# 加载自定义词典(保险行业专有词汇)jieba.load_userdict("/path/to/insurance_terms.txt")# insurance_terms.txt格式:每行一个词,可附词频和词性# 等待期 100 n# 免赔额 100 n# 豁免条款 100 n# 重疾险 100 n
候选集大小的选择有讲究。我们每路取Top20,这个数字不是随意选的。Top5太少,两路的交集可能非常少,RRF融合的价值没有充分体现;Top100太多,会引入大量噪声。我们实验的结论是,对于5000份文档、每份平均切分成16个块的情况,每路Top20是效果与效率的最佳平衡点。
BGE模型的查询前缀不能忘。BGE系列模型在训练时对查询和文档使用了不同的前缀格式,查询需要加"为这个句子生成表示以用于检索相关文章:"的前缀,文档编码不需要加。如果忘了加前缀,召回率会下降约3-5个百分点。
这些细节都是在生产环境里真实踩过的坑,面试时提到一两个,会让面试官感受到你有实战经验,不只是在背理论。
把上面所有内容串起来,做个收尾。
总结
混合检索解决的核心问题是:向量检索的语义理解能力和BM25的精确词匹配能力各有短板,单独使用都无法覆盖所有查询类型。RRF融合算法用一个极简的公式1/(k+rank)把两路结果整合起来,k=60来自2009年论文的实验验证,代表的是在分数敏感度和排名稳定性之间的最优平衡。在实际部署中,分词质量、候选集大小、模型前缀这些工程细节和算法本身同样重要。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)