半监督和无监督学习
·
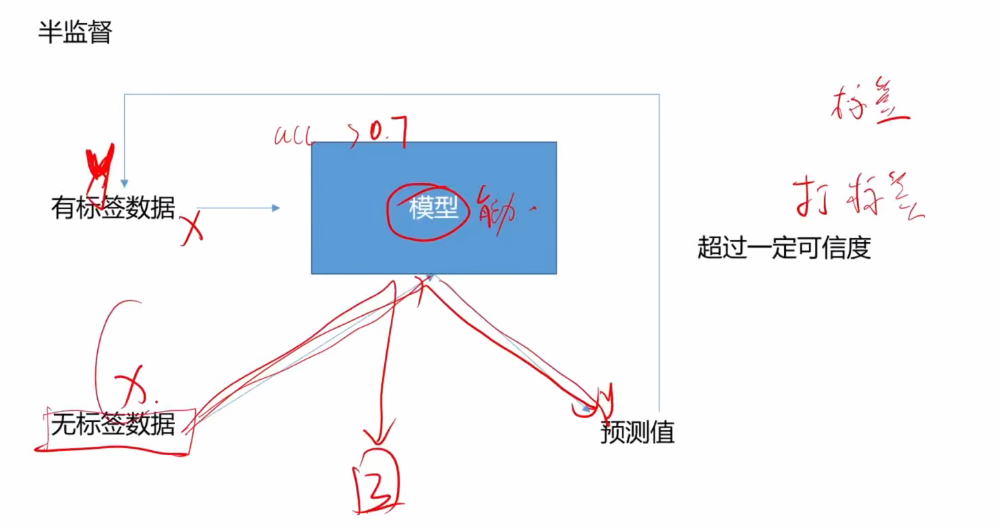
无标签数据使用:通过模型预测并打上标签,加入训练数据集。半监督学习利用少量有标签数据,结合大量无标签数据共同训练模型,解决实际场景中标注成本高、标签样本稀缺的问题。用预训练的模型(准确率较好的模型)对无标签数据进行预测,并通过设定置信度阈值(如向量y'的某一个值超过0.99),将预测结果作为标签加入训练集,转化为有标签数据。
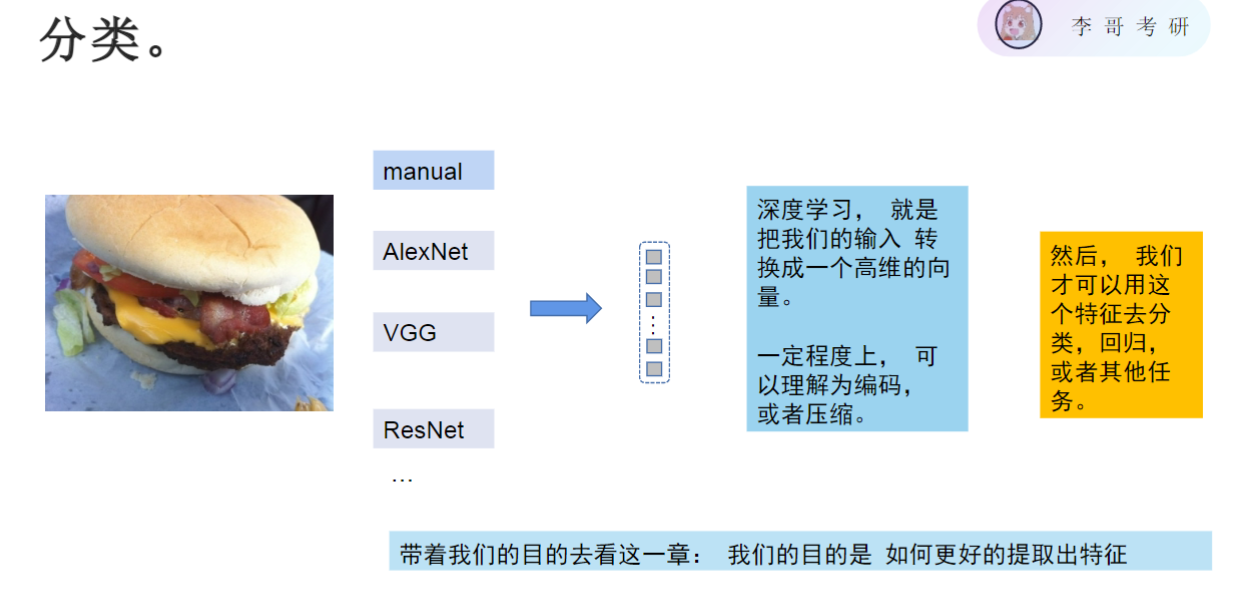
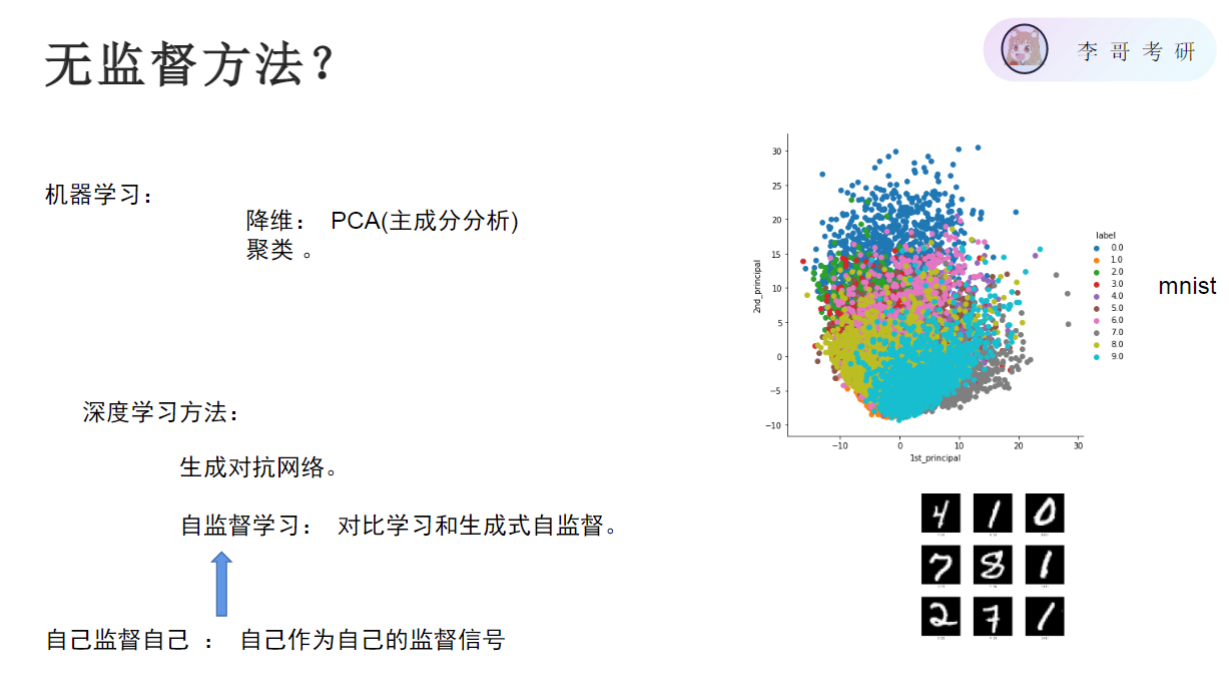
将手写数字图片输出为2维,发现相应的数字都聚集在群落中,输入一张图片输出为2维,最后落到某片群落中,该图片的数字大胆猜测跟周围数字为同一类

人类学习时,大概知道猫和狗不是一类的,猫和猫,狗和狗是一类的。

因为无标签,不知道猫和猫,狗和狗是一类的。故先让自己和自己(数据增广后)是同一类的,先让模型有一定的特征提取能力,让模型有了前进 的方向,这就是对比学习,一种无监督的方法。


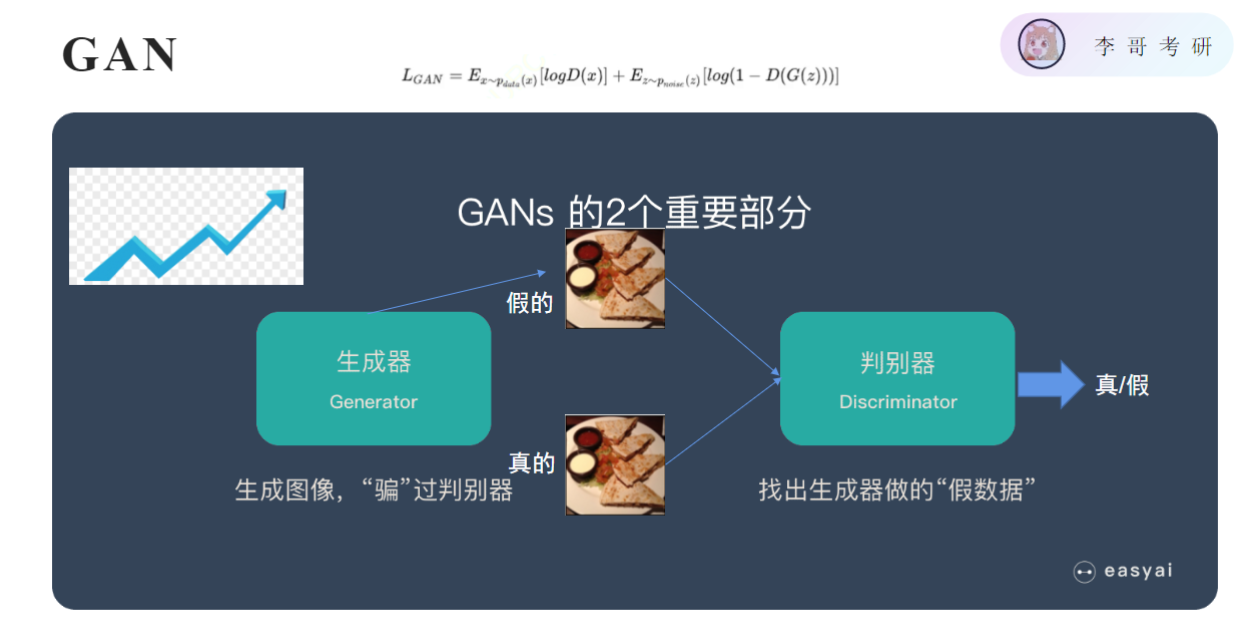
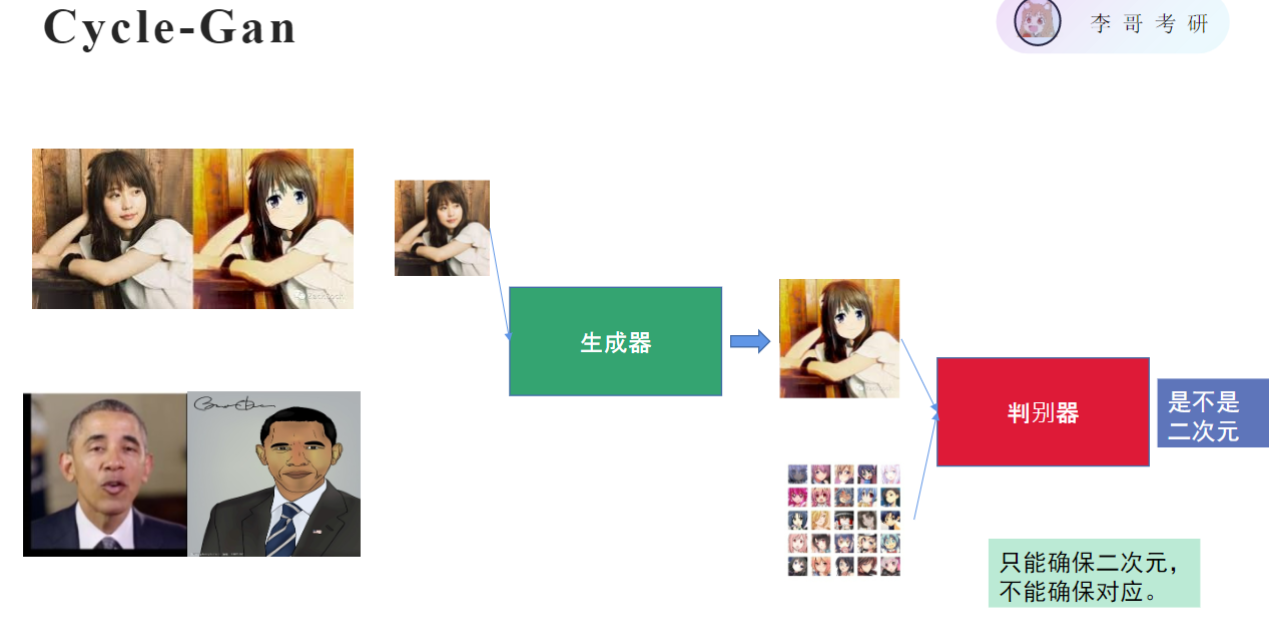
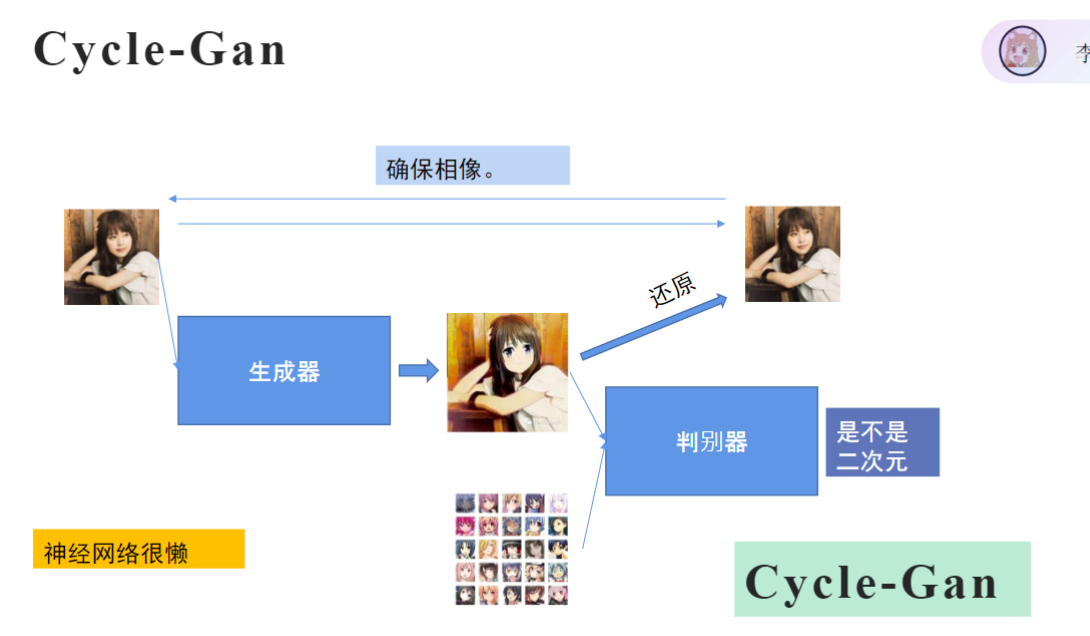
虽然没有标签但知道这个是假的,另一个是真的,这样判别器就可以进行简单的分类训练,判别器能力越来越强,带着生成器能力一起提升(因为目的是骗过判别器),准确率上升促使判别器成长,同时也推动生成器成长,因为在其看来准确率要越多越好,故称为对抗生成网络,可以训练出两个不错的模型用来提取图片的特征
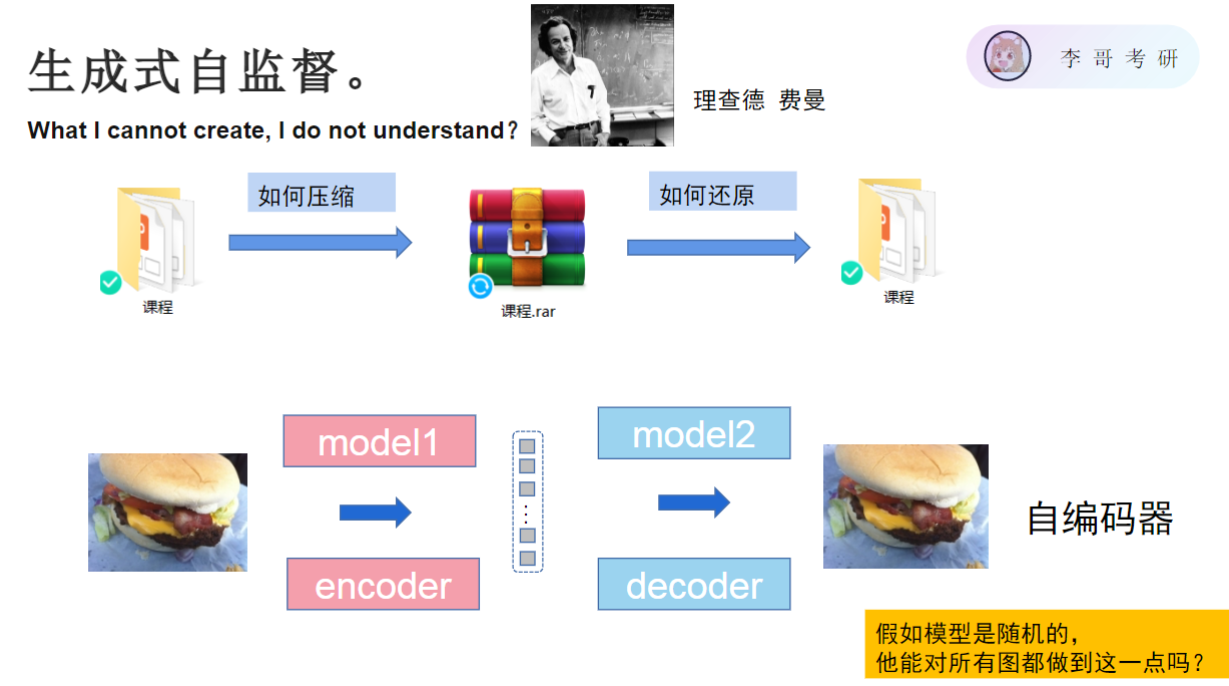
生成式自监督是,将图片提取为特征向量,再将特征还原成图片,通过这个过程训练出模型的特征提取能力,均是无标签图片,整个过程称为自编码器
-
- 生成式自监督学习模型构成
30:46
- 编码器(encoder):
- 功能:将输入数据压缩为低维特征表示
- 提取图像特征
- 解码器(decoder):
- 功能:从特征表示重建原始数据
- 从特征还原图像
- 整体架构: 称为自编码器(autoencoder),通过重建误差优化模型参数
- 编码器(encoder):
- 生成式自监督学习实例MAE模型
32:43
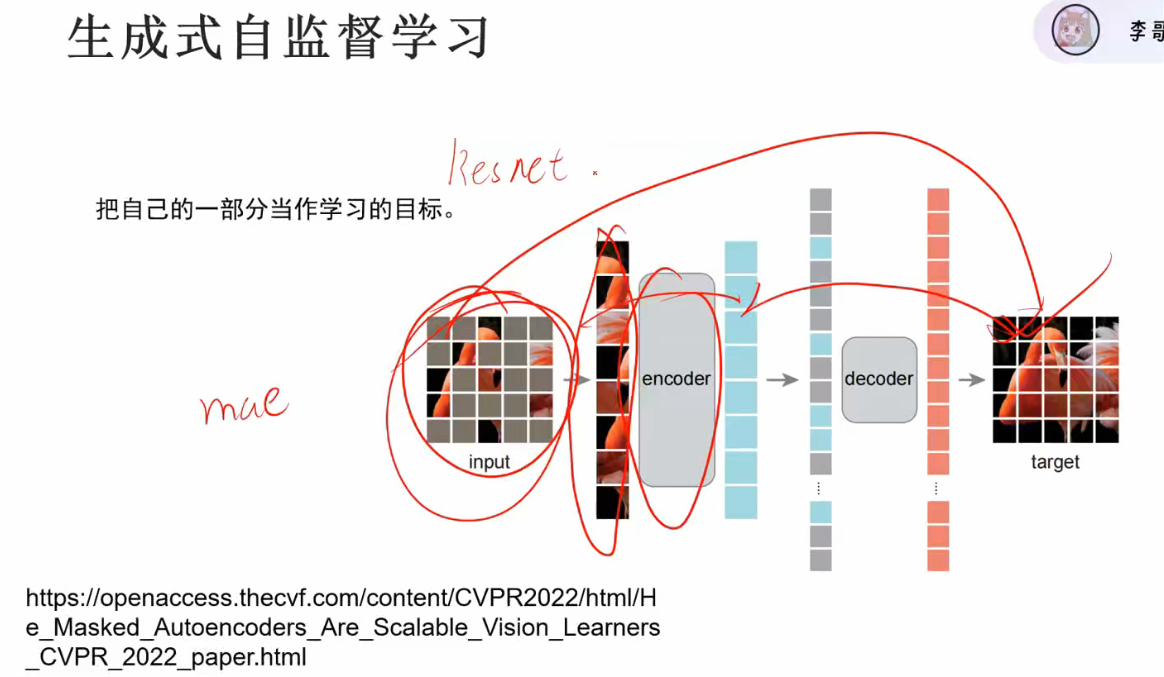
- 核心技术:
- 图像分块:使用ViT(Vision Transformer)将图像划分为16×16的patch
- 随机遮盖:随机mask掉75%-80%的图像块(变为灰色)
- 训练目标: 让模型根据可见的少量patch预测被遮盖区域
- 模型特点:
- 作者:何凯明(ResNet作者)
- 性能:仅用少量可见patch就能高质量重建原图
- 输出:能还原图像主体结构和语义内容
- 输入:仅保留20%图像块(196个patch中保留39个)
- 典型表现:
- 动物图像:能准确重建毛发纹理和姿态
- 场景图像:能保持场景布局和物体关系
- 技术意义: 证明模型通过自监督学习掌握了强大的特征表示能力
- 核心技术:
- 生成式自监督学习应用:灰度图还原
34:45
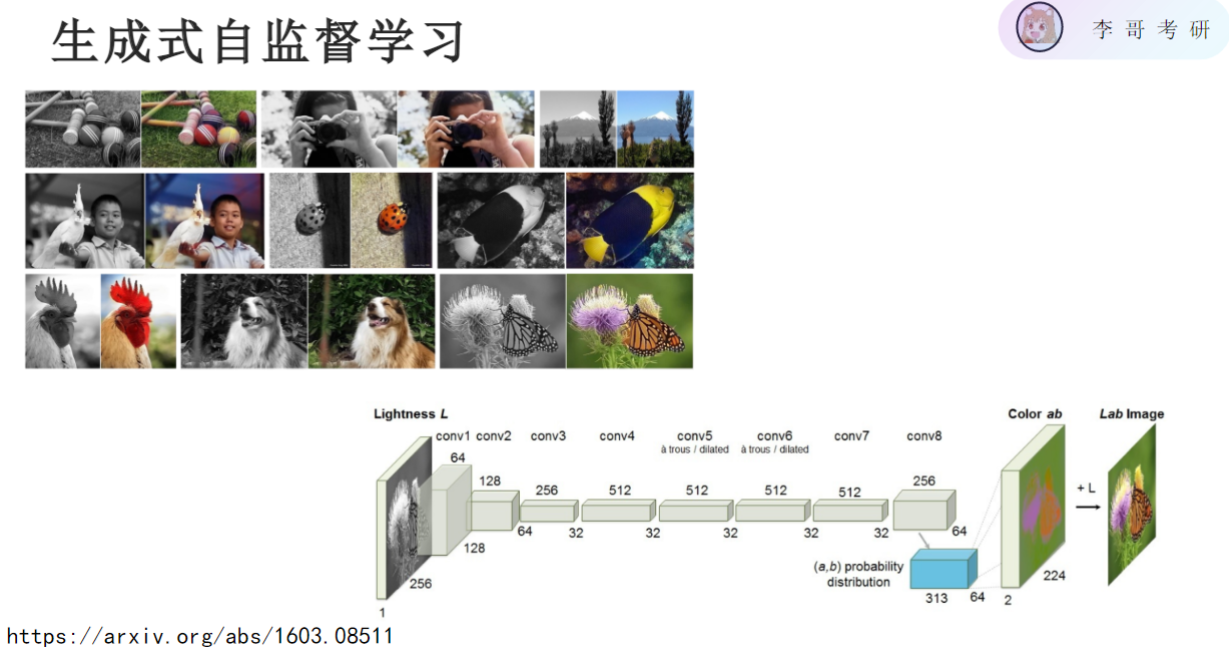
- 任务形式:
- 输入:单通道灰度图(技术处理得到)
- 输出:预测原始彩色图像
- 训练优势:
- 无需人工标注:仅需原始彩色图像自身作为监督信号
- 特征学习:模型必须理解物体语义才能正确着色
- 扩展应用:
- 图像修复:预测被损坏的图像区域
- 超分辨率:从低分辨率图像重建高清细节
- 任务形式:
- 生成式自监督学习模型构成
- 文字里的自监督
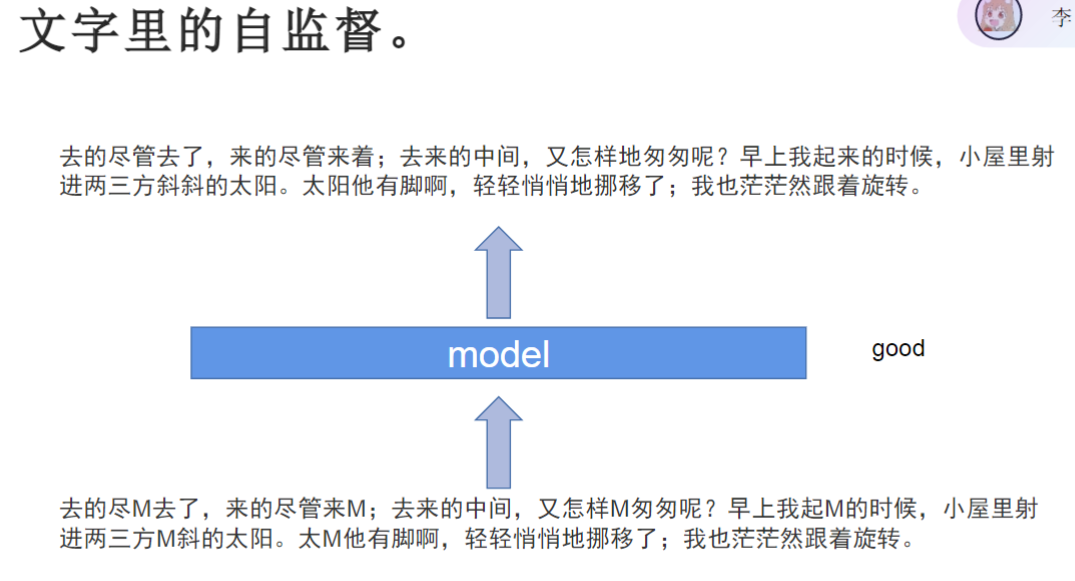
- 核心方法:通过随机遮盖(mask)文本中的部分字词(如15%比例),让模型预测被遮盖的原始内容。例如将"去的尽管去了"处理为"去的尽M去了"。
- 训练优势:
- 无需人工标注数据,任何书籍/文章都可作为训练素材
- 模型若能准确预测被mask字词(如"管"、"匆"等),则证明具备良好的文字特征提取能力
- 本质特征:属于自监督学习范式,通过数据自身构造监督信号(原始文本作为预测目标)
- 无监督后做什么
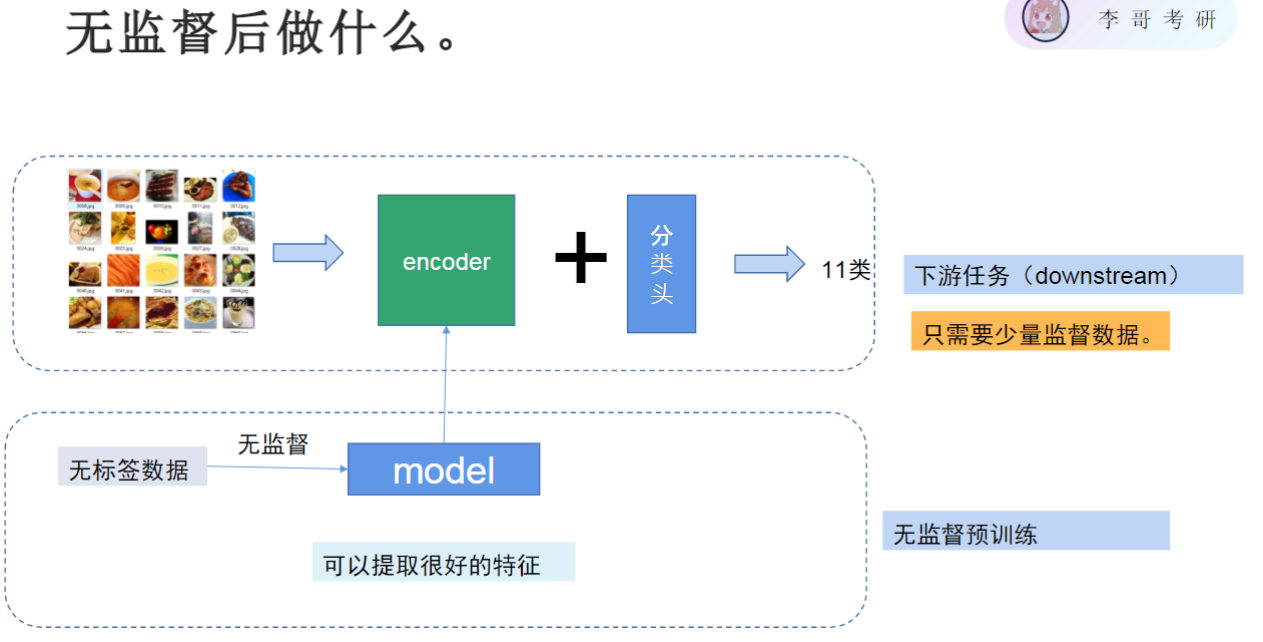
- 特征提取与应用
- 核心流程:
- 通过无监督预训练获得encoder(如自编码器结构)
- 用encoder提取的特征作为下游任务输入
- 典型应用:
- 图片分类:在encoder后直接添加分类头(分类层)
- 文本理解:使用预训练语言模型的embedding
- 核心流程:
- 预训练与微调机制
- 概念区分:
- 预训练(Pretraining):上游无监督训练(如ChatGPT中的"P")
- 微调(Fine-tuning):下游监督任务适配
- 效果对比:
- 纯半监督学习准确率约62%
- 结合对比学习的无监督预训练可达82%准确率
- 关键优势:
- 减少对标注数据的依赖
- 特征表示具有更强泛化能力
- 概念区分:
- 特征提取与应用
- 自编码器的特征
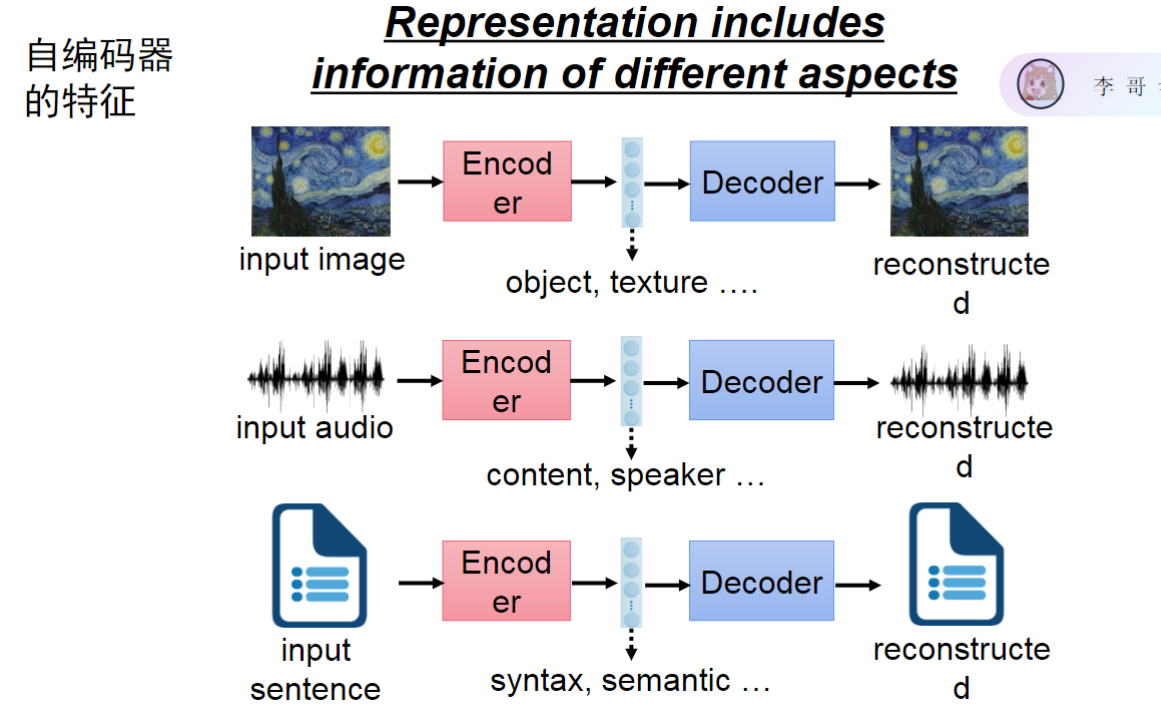
- 图像编码特征
- 多维度信息包含: 自编码器中间层特征包含输入图像的多方面信息,如物体类别(山、房屋等)、纹理特征(绘画风格、笔触特点等)
- 典型示例分析: 以梵高画作为例,特征层同时编码了画面内容(精神病院场景)和艺术风格(后印象派特有的色彩与笔触)
- 重建原理: 通过编码器-解码器结构,输入图像被压缩为特征表示后能完整重建原始图像,证明特征包含全部必要信息
- 音频编码特征
- 语音内容分离: 音频编码时特征层同时包含语义内容(说话文字)和声学特征(说话人音色、频率特性)
- 加密应用: 可将特征向量作为加密载体,接收方通过专用解码器还原原始信息,实现比传统密码更安全的通信方式
- 浪漫应用场景: 适用于情感表达场景,如将表白信息编码为特征向量传递,接收方解码后还原原始情话
- 文本编码特征
- 语言结构分离: 文本编码特征包含表层语法结构(句式、词序)和深层语义信息(话语含义、情感倾向)
- 信息压缩原理: 通过编码过程将高维文本数据降维为紧凑特征表示,仍能通过解码器准确重建原始语句
- 跨模态对比: 与图像/音频编码类似,不同模态数据在特征层都能实现输入信息的分布式表示
- 图像编码特征
- 特征分离
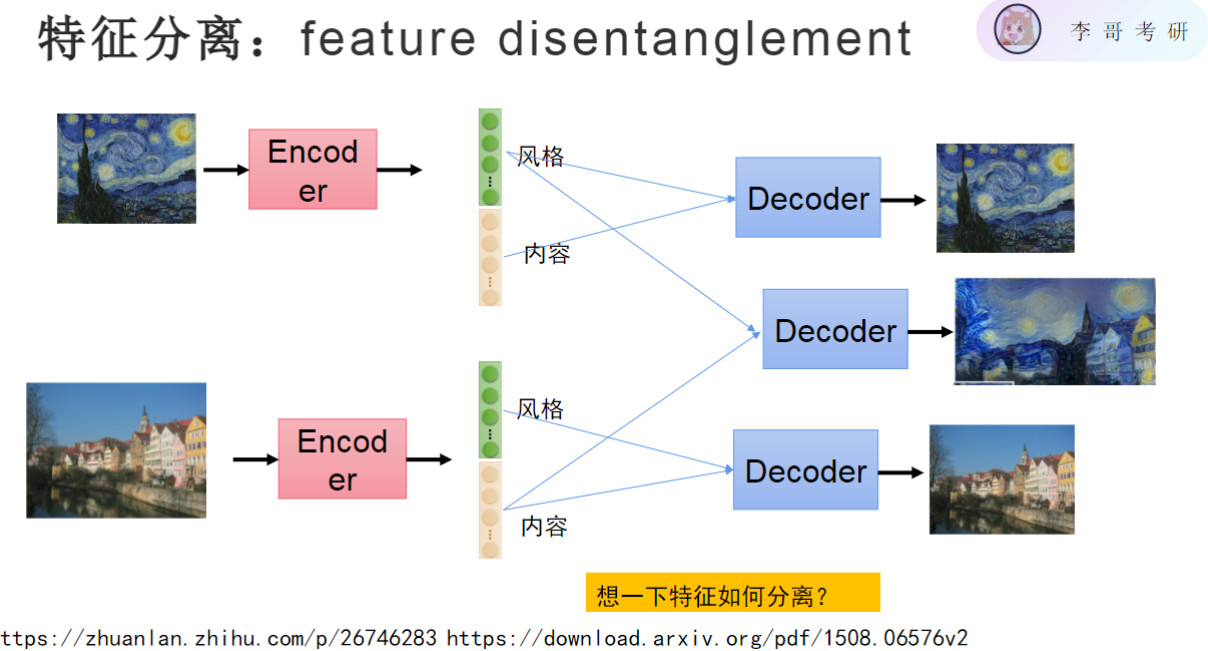
- 实现基础:深度学习模型能够自动学习特征的层次化表示
- 典型应用:图像领域可将特征分解为风格(纹理、色彩)和内容(物体结构)两部分
- 核心思想:通过编码器将输入数据分解为不同语义的特征分量,如风格特征和内容特征
-

- 特征分离的设想
43:15
-

- 特征交换原理:将样本A的风格特征与样本B的内容特征组合,可生成具有A风格+B内容的新样本
- 具体示例:若上图的风格特征与下图的内容特征结合,生成的图像会呈现上图风格+下图内容
- 关键问题:如何确保特征空间中的风格和内容维度是真正解耦的
-
- 特征分离的实际操作
- 分层特征假设:
- 前5层卷积输出代表内容特征(物体结构)
- 后6层卷积输出代表风格特征(纹理样式)
- 实现方法:
- 将源图像前5层特征与目标图像后6层特征拼接
- 通过解码器重构混合特征的输出图像
- 特殊现象:这种分层划分缺乏严格理论依据,但实验证明有效
- 分层特征假设:
- 例题1:李宏毅老师的语音例子
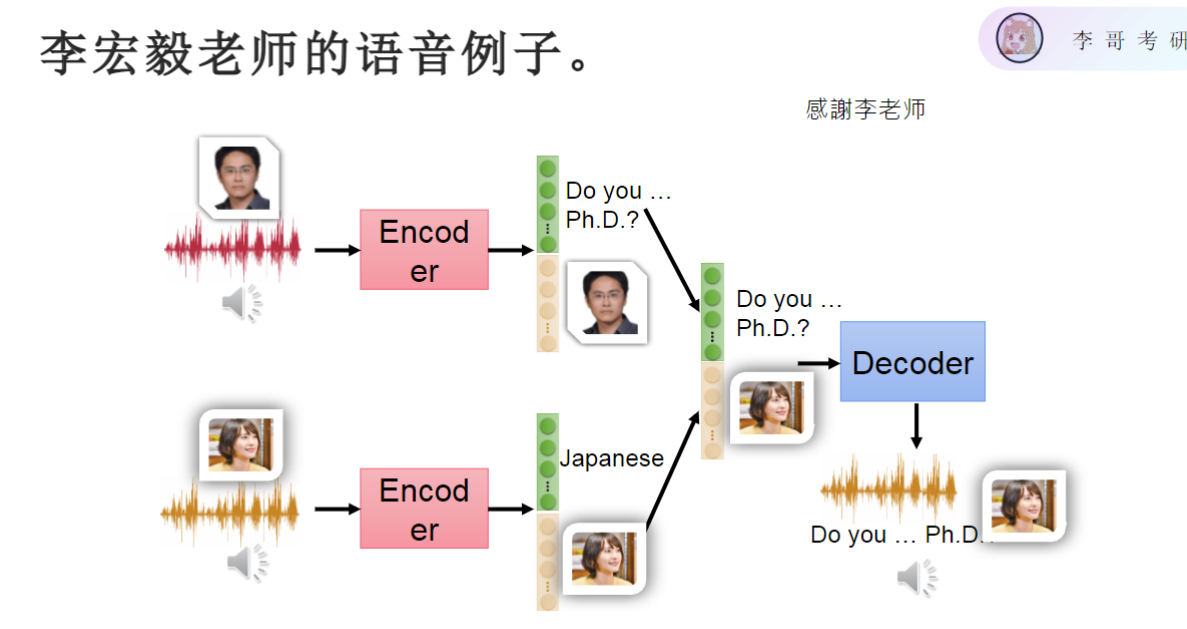
- 语音特征分解:
- 内容特征:"Do you want to study a PhD"(语义信息)
- 风格特征:说话人的音色(声学特征)
- 特征重组:
- 将日语语音的内容特征替换为英语语句
- 保持原始日语语音的音色特征
- 结果:生成新垣结衣说英语的语音效果
- 反向案例:
- 用李宏毅老师的音色特征+日语内容特征
- 可实现老师"说"日语的效果
- 语音特征分解:
- 深度学习与特征的关系

- 核心观点:深度学习本质是特征的变换与流动过程特征处理特点:
- 网络各层对特征进行不同层次的抽象和转换
- 特征在网络的流动过程中不断被重组和优化
- 方法论:
- 只要特征处理方式具有合理逻辑即可尝试
- 实际效果需要通过实验调参来验证
- 重要结论:AI不是在模仿人类,而是在学习和操作特征表示
- 核心观点:深度学习本质是特征的变换与流动过程特征处理特点:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)