【由浅入深探究langchain】第十四集-langgraph 状态管理器 checkpointer 详细解析
前言
AI 为什么需要“记忆”?
在构建复杂的 AI Agent 时,我们不仅需要它能干活(Node),更需要它能记住自己干了什么(State),甚至在出错时能回到过去重新开始(Checkpoint)。今天我们通过一段简洁的代码,拆解 LangGraph 的核心灵魂。
深入
作为深入理解的基石,我们可以把这几个点再点透一点:
1. 概念微调:Checkpointer vs Checkpoint
区分这两者,我们可以将它们理解为:一个是“管家”,一个是“档案”:
-
Checkpointer (存储器/管家):它是物理存在。比如我们接下来用的
InMemorySaver(存内存,断电即失)或者生产环境用的SqliteSaver/PostgresSaver(存数据库,永久保存)。 -
Checkpoint (快照/档案):它是逻辑存在。是某一时刻
State的完整镜像 + 路由信息(下一步去哪)。
2. 核心灵魂:thread_id(线程 ID)
Checkpoint 由 thread_id 管理,这点至关重要。
-
你可以把它理解为**“平行宇宙的坐标”**。
-
如果没有
thread_id,AI 就分不清谁是谁。有了它,同一个 AI 模型可以同时和 100 个人聊天,每个人都有属于自己的“档案袋”,互不干扰。
3. 作用详解
我们可以给到四个关键词并且加上最直白的解释:
-
记忆管理(Memory):
-
直白说:让 AI 记住刚才聊了什么。即使程序关闭再打开,只要
thread_id一样,它就能接上话。
-
-
时间旅行(Time Travel):
-
直白说:你可以通过
graph.get_state_history(config)查到 Step 1 的状态,甚至可以强行把状态改写,然后从那个时间点开始“分叉”运行。
-
-
人在回路(Human-in-the-loop):
-
直白说:比如 AI 要执行“删除数据库”的操作,你可以设置一个中断。AI 运行到这一步会产生一个 Checkpoint 然后挂起。直到你(人类)看了一眼,点击“批准”,它才从这个 Checkpoint 继续往下走。
-
-
容错(Fault Tolerance):
-
直白说:如果
node_b运行的时候服务器停电了,任务没完成。重启后,它不需要从node_a重新跑(省钱省时间),而是直接从 Step 1 的 Checkpoint 恢复。
-
补充一个进阶点:Checkpoint 到底存了什么?
Checkpoint 不仅存了 State(代码里的 foo 和 bar),它还存了 next(下一步该去哪个 Node)。
这也是为什么接下来代码里调用 get_state(config) 的结果里会有 next=() 或者 next=('node_b',) 的原因。
编码
先贴上全部代码,后面会做详细的解释
from langgraph.graph import StateGraph,START,END
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
from typing import Annotated
from typing_extensions import TypedDict
from operator import add
#状态
class State(TypedDict):
foo:str
bar:Annotated[list[str],add]
def node_a(state:State):
return {"foo":"a","bar":["a"]}
def node_b(state:State):
return {"foo":"b","bar":["b"]}
#构建状态图
workflow = StateGraph(State)
workflow.add_node(node_a)
workflow.add_node(node_b)
workflow.add_edge(START,"node_a")
workflow.add_edge("node_a","node_b")
workflow.add_edge("node_b",END)
#检查点管理器
checkpointer = InMemorySaver()
#编译
graph = workflow.compile(checkpointer=checkpointer)
#配置
config: RunnableConfig={
"configurable":{"thread_id":"1"}
}
#调用
results = graph.invoke({"foo":""},config)
print(results)
#状态查看
print(graph.get_state(config))
for checkpoint_tuple in checkpointer.list(config):
print()
print(checkpoint_tuple)
for checkpoint_tuple in checkpointer.list(config):
print()
print(checkpoint_tuple[2]["step"])
print(checkpoint_tuple[2]["source"])
print(checkpoint_tuple[1]["channel_values"])
代码详解
初始化
我们先撇开复杂的概念,逐步拆解这段代码。
把这段代码看作是在设计一个“自动化流水线”。
class State(TypedDict):
foo:str
bar:Annotated[list[str],add]第一步:定义“传单”(State)
这里的 State 就是流水线上一直在传递的那张信息单
foo: str:这是一个普通的字符串。规则是:后来者居上。如果节点 A 写了 "a",节点 B 写了 "b",那空格里最后就只剩下 "b"
bar: Annotated[list[str], add]:这是一个特殊的列表。add 是它的合并规则。规则是:只加不删。不管谁处理,都只能往列表末尾追加新内容。
第二步:定义“工人”(Nodes)
def node_a(state:State):
return {"foo":"a","bar":["a"]}
def node_b(state:State):
return {"foo":"b","bar":["b"]}这两个函数就是流水线上的两个工人:
-
node_a:它的任务很简单。不管传单之前写了什么,它都要在foo那里填上"a",在bar列表里塞进一个["a"]。 -
node_b:同理,它填"b"到foo,塞["b"]到bar。
第三步:铺设“传送带”(Graph & Edges)
workflow = StateGraph(State)
workflow.add_node(node_a)
workflow.add_node(node_b)
workflow.add_edge(START,"node_a")
workflow.add_edge("node_a","node_b")
workflow.add_edge("node_b",END)这部分就是在工厂车间里画地线、摆机器
-
StateGraph(State):告诉工厂,我们这张“传单”的格式已经定好了。 -
add_node:把工人(函数)放到指定的工位上。 -
add_edge:连接传送带。箭头指向上一个工位结束后,传单该送往哪。
到这里我们预期一下,这几行代码跑起来会发生什么?
想象一张空白传单:
-
START:传单进入流水线。
-
抵达 node_a:
foo变成"a",bar变成["a"]。 -
抵达 node_b:
foo被擦掉重写成了"b";bar发现已经有["a"]了,于是在后面加上["b"],变成了["a", "b"]。 -
END:任务结束,你拿到了最终那张写着
{'foo': 'b', 'bar': ['a', 'b']}的传单。
记录结果
接下去我们使用内存记录每一步的左右的状态快照
checkpointer = InMemorySaver()编译和配置
然后开始编辑,相当于我们定义的工作流程正式运行
graph = workflow.compile(checkpointer=checkpointer)compile() 会把所有节点和连线逻辑转化成一个可执行的 Runnable 对象。而且把checkpointer加入到了流程中。现在,相当于每当传单经过一个工位,checkpointer都会自动冲上去拍一张照。
配置:给即将开始的任务一个id,如上集所说,checkpointer是根据thread_id来管理流程的。
config: RunnableConfig = {
"configurable": {"thread_id": "1"}
}调用
下达指令并开跑,把一张只写了 foo 是空字符串的原始传单(输入数据),配合订单号(config),扔进流水线。
results = graph.invoke({"foo":""},config)
print(results)结果输出
![]()
我们看看为什么会这么打印
初始化(foo 是空的字符串 "",bar 是空列表)---------->到达 node_a节点( 把 foo 改成了 "a",往 bar 里塞了一个 ["a"])---------->到达 node_b节点(把 foo 改成 b,往bar中塞了一个 ["b"])---------->结束输出结果{'foo': 'b', 'bar': ['a', 'b']}
StateSnapshot详解
我们接下去打印它的详细
print(graph.get_state(config)) 可以看到返回结果是一个快照对象
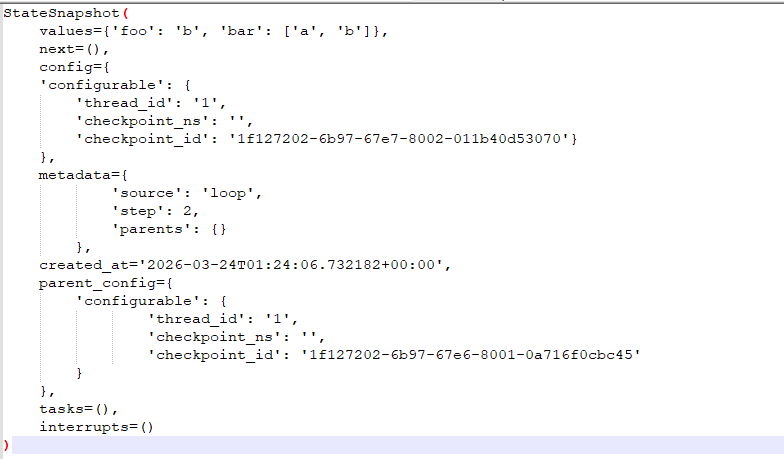
这里面values: 核心数据,代表了当前时刻状态机里存储的所有数据。
next: 待办事项(路由信息)
-
这里是一个元组。如果它是空的
(),说明流程已经彻底结束(跑到了END)。 -
如果你设置了断点(比如在
node_a后执行暂停),这里会显示('node_b',),意思是:“数据已经停在路口了,下一站是node_b”。
config: 当前坐标
这是当前这个状态的唯一标识:
-
thread_id: 订单号(你在同一个 ID 下做的所有事都会被串起来)。 -
checkpoint_id: 当前这一步的唯一指纹。如果你想让程序精准跳回到这一秒钟的状态,就需要用到这个 ID。 -
checkpoint_ns: 命名空间,通常在复杂的“子图(Subgraph)”嵌套时使用,现在可以暂时忽略。
metadata: 操作日志
-
source: 来源。loop表示这是由状态图自动循环运行产生的。如果是你手动修改了状态,这里可能会显示update。 -
step: 步数计数器。从-1(输入)开始,到2(完成 node_b),清晰地记录了这是第几次操作。
parent_config: 溯源信息(父级指针)
这是 Checkpointer 实现“时间旅行”的核心
-
它保存了上一个步骤的
checkpoint_id。 -
意义:就像链条一样,当前的步骤指向了上一步。LangGraph 就是通过这个字段,把分散在数据库里的快照串成了一个完整的“历史长河”。
tasks 与 interrupts: 运行状态
-
tasks: 如果当前有节点正在并发执行,这里会显示正在运行的任务。因为你的代码是串行的且已经运行完,所以它是空的。 -
interrupts: 记录当前的“中断”。如果你设置了人工审批流程(Human-in-the-loop),当程序停下来等你点击“批准”时,这里会显示中断的原因。
StateSnapshot 不只是数据的集合,它是一个带有‘时空属性’的信封。它记录了:我是谁(config)、我从哪来(parent_config)、我要去哪(next),以及我肚子里装了什么(values)。
这里可以试一下,获取上一步的状态(node_a 刚结束时的状态)
parent_id = graph.get_state(config).parent_config['configurable']['checkpoint_id']
old_config = {"configurable": {"thread_id": "1", "checkpoint_id": parent_id}}
print(graph.get_state(old_config).values)打印出的是 {'foo': 'a', 'bar': ['a']}。这就是利用 parent_config 实现的回溯
CheckpointTuple详解
将checkpointer从后往前,一步一步的翻出来看看。在 LangGraph 中,每一步操作(Step)都会生成一个独立的 CheckpointTuple。运行这个 for 循环,你会看到整个程序的进化史。
它是一个包含三个核心组件的“档案袋”:
-
config:这一页账目的“页码”(包含唯一的checkpoint_id)。 -
checkpoint:这一页记下的“原始原始数据”(包含版本号、时间戳、所有通道的内部值)。 -
metadata:这一页的“备注”(比如是哪一秒存的、是哪个节点跑完存的)。
我们看一下CheckpointTuple 的详细结构
CheckpointTuple(
config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f127352-80fd-6ca4-8002-d762516fa820'
}
},
checkpoint={
'v': 4,
'ts': '2026-03-24T03:54:28.407414+00:00',
'id': '1f127352-80fd-6ca4-8002-d762516fa820',
'channel_versions': {
'__start__': '00000000000000000000000000000002.0.5958868265123454',
'foo': '00000000000000000000000000000004.0.4198389292977224',
'branch:to:node_a': '00000000000000000000000000000003.0.4096430761596095',
'bar': '00000000000000000000000000000004.0.4198389292977224',
'branch:to:node_b': '00000000000000000000000000000004.0.4198389292977224'
},
'versions_seen': {
'__input__': {},
'__start__': {
'__start__': '00000000000000000000000000000001.0.8405408819711978'
},
'node_a': {
'branch:to:node_a': '00000000000000000000000000000002.0.5958868265123454'
},
'node_b': {
'branch:to:node_b': '00000000000000000000000000000003.0.4096430761596095'
}
},
'updated_channels': ['bar', 'foo'],
'channel_values': {
'foo': 'b',
'bar': ['a', 'b']
}
},
metadata={
'source': 'loop',
'step': 2,
'parents': {}
},
parent_config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f127352-80f1-668a-8001-6ff0371fbcc6'
}
},
pending_writes=[]
)我们从数据里面最核心的四个维度来讲
1. config 与 parent_config:“时空链路”
这是实现“断点续传”和“回溯”的钥匙。
-
checkpoint_id: 当前这一秒钟状态的唯一“身份证号”。 -
parent_config: 记录了上一秒钟(上一个节点)的“身份证号”。 -
直白解释:就像链条一样,每一环都勾住了上一环。通过它们,LangGraph 才能把分散的记录串成一个完整的“故事线”。
2. channel_values:“当前账本实况”
-
核心定义:这是用户最关心的业务数据。
-
直白解释:这是此时此刻“传单”上写着的最终内容。它展示了经过所有节点处理后,
foo变成了什么,bar累加到了什么程度。
3. channel_versions 与 versions_seen:“版本控制器”
这是 CheckpointTuple 里看起来最乱但技术含量最高的部分。
-
直白解释:LangGraph 为了防止数据冲突,给每个状态字段(如
foo,bar)都发了一个版本号(那串长长的00000...)。 -
关键作用:它记录了哪个节点(Node)看过哪个版本的数据。
-
为什么重要? 如果你的图里有并行执行(比如两个节点同时运行),LangGraph 就是靠这些版本号来判断谁先谁后,以及是否需要根据 Reducer(如
add)进行合并,确保数据不会乱套。
-
4. pending_writes:“任务待办单”
-
核心定义:记录那些**“已经计算出结果但还没正式写入账本”**的数据。
-
直白解释:在你的结果里它是空的,说明这一步已经稳稳地写进了存档。
-
容错价值:如果在写入过程中程序突然崩溃,
pending_writes里的内容就像是“未保存的草稿”,系统重启后会先去翻这里,确保数据一丁点都不会丢失。
在 Step 1 的快照里,可以看到: pending_writes=[(..., 'foo', 'b'), (..., 'bar', ['b'])]。意味着在 Step 1 存档时,node_a 已经写完了(foo 是 "a")。但是,node_b 的指令已经发出了,它“正准备”写入 'b'。Checkpointer 连这种“正在路上”的状态都记录了下来,这就是为什么如果程序在 node_b 运行时断电,重启后它能完美接上的原因。
总结来说
CheckpointTuple 不仅仅是数据的简单堆砌,它是一套严密的、带有版本追踪和链式溯源能力的持久化方案。channel_values 存储了结果,而 channel_versions 和 parent_config 则保证了结果的来源可追溯、更新可控。
简化信息展示
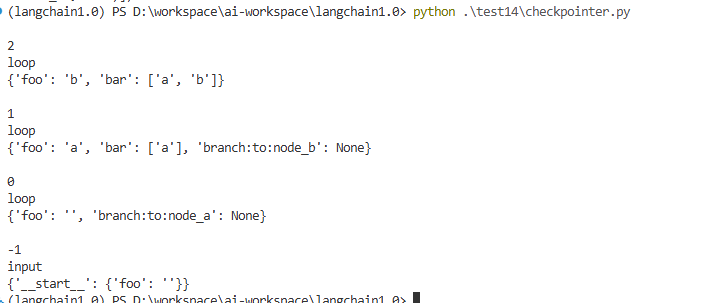
for checkpoint_tuple in checkpointer.list(config):
print()
print(checkpoint_tuple[2]["step"])
print(checkpoint_tuple[2]["source"])
print(checkpoint_tuple[1]["channel_values"])拿出最关键的 “步数、来源、数据内容” 展示出来。形成一个透明的易读的运行过程,
总结
通过一份代码,完整地拆解了 LangGraph 的“大脑”是如何工作的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 45
45 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)