AI时代研发破局:从上下文工程到Harness Engineering,重新定义工程师价值
AI Coding让代码生成快了10倍,我们却更累了。这不是错觉,而是全行业正在陷入的局部最优陷阱。
当大模型把编码效率拉满,占研发时长**70%**的非编码工作——验证、测试、部署、排障、Code Review,却随着代码量指数级爆发,人成了整个流程的新瓶颈。
字节跳动Web Infra AI Coding负责人周晓老师,在D2大会带来一场直击本质的分享, 他的核心观点直击痛点:AI时代的真正解法,不是让模型写更多代码,而是用Harness Engineering驾驭模型,让Agent接管研发全生命周期。
这场分享,他明确表示“不聊框架、不聊产品,只聊底层原理和工程师的角色转变”,带大家深挖AI时代研发破局的核心逻辑。
这不是工具升级,而是一场从「写代码」到「设计环境」的范式转移。
反常识真相:
AI越强大,研发越疲惫

他在现场展示了一张来自团队年终活动的关键词云,上面密密麻麻挤满了研发们的焦虑——“前端出路在哪?”“职业护城河是什么?”“为什么AI Coding普及后反而更累?” 这正是全行业的集体困惑:明明AI让代码生成速度提升了一个数量级,研发们的负担却反而加重了。
我们先看一组扎心的数据,当下AI研发时间分配:
- 编码(AI最强环节):30%
- 验证/CI/测试:40%
- 部署/发布/灰度:20%
- 排障/沟通/Code Review:10%
AI把30%的编码工作做到极致,却让剩下70%的非编码工作彻底失控。周晓老师现场吐槽:“很多同事跟我反馈,AI写完代码后,自己要花大量时间Review、测试、排障,工作量指数级上升,人反而成了整个流程的最大瓶颈。”
这就是AI时代研发的集体焦虑:
- 代码越生成,技术债越黑盒:AI批量生成代码,却留下大量难以追溯的技术债,后续排障难度陡增
- 模型有幻觉,交付越不可控:AI偶尔会“合理虚构”代码,导致交付质量不稳定,需要反复校验
- 手写能力退化,职业护城河消失:长期依赖AI补全代码,手写代码的能力逐渐弱化,开发者陷入自我怀疑
- 架构腐化加速,体验趋于平庸:AI只关注代码生成,不考虑整体架构合理性,长期下来架构逐渐腐化,产品体验难以提升
- 面试体系失效、八股文无用:AI能轻松应对传统面试题,过去的考核方式不再适用,开发者面临职业考核的重新洗牌
核心问题:我们只让AI做了「编码工」,没让它成为「全流程执行者」。
OpenAI前段时间发布的技术文章,已经给出了破局方向——Harness Engineering,这正是他本次分享的核心。他用一个形象的比喻解释:“Harness的本意是马具,我们要从‘使用模型的人’,转变为‘驾驭模型的人’,就像骑手用马具驾驭烈马,让AI的力量可控、可用。”
用OpenAI的官方类比更易理解:烈马(AI模型)速度极快、算力强大,但没有方向感,容易乱跑(生成不符合规范的代码);马具(Harness)是一套约束系统(包括Linters、自动化测试等),限制马的活动范围;骑手(人类工程师)不再亲自跑步(手写代码),而是提供方向、设定意图。
简单来说,Harness Engineering的核心的就是:为大模型套上「马具」,构建专属执行环境,让Agent完成从需求到验收的长闭环任务,打破70%非编码流程的枷锁。
底层原理:
先读懂大模型的「物理三限」
“很多人会发现,同样用AI Coding,有的人产出是别人的10倍,核心差距就在于对大模型底层原理的认知不同。” 所有高效Agent设计,都必须顺应模型的物理约束,而非对抗——这些约束不是产品Bug,而是架构本身的必然结果。


慢:自回归的天生宿命
大模型本质是下一个Token预测器,必须逐字逐token生成,这是Transformer架构的物理铁律,并非为了“更像人”而设计。周老师现场展示了一段无KV Cache的PyTorch朴素推理伪代码,直观解释了“慢”的根源:
| python # PyTorch 朴素推理 (无 KV Cache) for step in range(max_tokens): # 朴素实现:每步全量前向 out = model(input_ids) next = argmax(out.logits) # 拼接 -> 序列越来越长 input_ids = cat([input_ids, next]) |
这段代码的核心问题的是:每生成一个新Token,都要重算所有前文,上下文越长,Prefill阶段的计算成本越高,首Token延迟也就越大。这也是KV Cache诞生的核心动机——解决长上下文推理的效率问题。
笨:注意力的稀释效应
不是模型能力弱,而是上下文越多,关键信息越被淹没。举例:“把万行代码塞进模型上下文,就像把一堆杂物塞进一个小房间,模型根本抓不住核心逻辑,注意力被无限稀释,自然显得‘笨’。” 这也是为什么很多时候,AI能写好单行代码,却无法完成复杂的长周期任务。
幻觉:概率的必然猜测
“模型的幻觉不是故意欺骗,而是当上下文缺少事实锚点时,它为了维持语义连贯,只能做‘合理的猜测’。” 大模型本质是一个巨大的权重函数,它的输出是基于前文概率的预测,没有事实锚点,就只能“虚构”内容来保证逻辑通顺。
Harness Engineering的核心哲学:“不要对抗这些物理限制,要顺应它们,在约束里做最优解。理解这些约束,才能真正读懂Harness Engineering的底层逻辑。”

黄金定律:
KV Cache决定一切上下文设计
理解了大模型的物理限制,就不难明白KV Cache的重要性——它是优化长上下文推理的核心,也是周晓老师现场重点拆解的技术点。他先讲解了Transformer的Attention原理,给出了标准Attention公式:
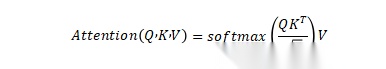
其中,Q代表问题,K代表标签,V代表细节。在此基础上,大模型推理分为两个阶段,周晓老师用通俗的语言现场拆解:
- Prefill(预填充):全量计算所有输入的KV(键值对),这个阶段成本极高,也是长上下文推理慢的核心原因
- Decode(解码):复用Prefill阶段计算好的KV,只计算新生成的Token,成本极低
由此,长任务黄金定律,这也是上下文工程的核心基础:
- 追加(Append)极度便宜:时间复杂度为
 ,可直接复用已有KV,只计算新Token,几乎不增加额外成本
,可直接复用已有KV,只计算新Token,几乎不增加额外成本 - 修改(Modify)极其昂贵:时间复杂度为
 ,修改点之后所有的KV Cache都会作废,需要重新全量计算
,修改点之后所有的KV Cache都会作废,需要重新全量计算
一切上下文工程,本质都是:尽量不破坏前缀。
一个关键细节:“以Claude Code的Sonnet模型为例,当Prompt Cache命中时,推理成本最高可直降90%,推理速度也会大幅提升。而Prompt Cache能命中的核心前提,就是System Prompt的稳定性——越稳定的前缀,越容易命中缓存,从而加速响应。” 这也是为什么优秀的AI Coding产品,都会尽量保持System Prompt的稳定,避免频繁修改。


Agent灵魂:
ReAct循环,用外部反馈对冲幻觉
2022年ChatGPT刚出现时,有一篇爆火的论文《ReAct》,它定义了当代Agent的核心运行逻辑——这也是解决模型幻觉、让Agent能解决真实世界问题的关键。
当代Agent的核心运行逻辑,来自经典论文ReAct:
思考 → 行动 → 观察 → 迭代
“就像人类解决问题的流程——基于当前状态思考下一步该做什么,执行行动后观察结果,再根据反馈调整下一步动作,反复迭代,直到解决问题。” 模型不再是单向生成代码,而是像人一样,通过外部反馈对冲自身的概率波动。
模型不再是单向生成,而是像人一样:
- 基于当前状态决策:比如判断代码是否有错误、下一步该调用哪个工具
- 调用工具执行:比如调用LSP检查代码错误、调用测试工具执行测试用例
- 拿到结果反馈:工具返回错误信息、测试结果等
- 修正下一步动作:根据反馈修改代码、调整工具调用逻辑
外部反馈,是消灭幻觉的唯一武器。“模型的幻觉源于缺少事实锚点,而ReAct循环的核心,就是通过外部工具反馈,给模型提供事实锚点,让它能够纠正自己的‘猜测’,从而逼近正确解。”
同时,ReAct循环也会带来一个问题——随着迭代次数增加,上下文会飞速增长,这就需要做好上下文管理,这也是上下文工程的核心意义所在。
AI友好工具链:
好工具的三大标准
“现在全行业都在做AI友好的改造,传统互联网产品的大量GUI界面和非结构化日志,对AI并不友好——上下文窗口有限,多模态模型也没有人类那么强的泛化能力,所以我们需要把人类能看到的信息,转化为模型能读懂的结构化文本。”
给模型用的工具,和给人用的工具,完全是两套逻辑。他提出了好工具的三大标准,这也是AI友好工具设计的核心评价依据:
好工具必须满足三点:
- 速度足够快:给模型即时反馈,降低等待延迟——模型的自回归特性本身就慢,如果工具反馈再延迟,会严重影响Agent的执行效率
- 结构化输出:用最少Token传递最高密度信息——上下文窗口有限,结构化输出能减少Token消耗,让模型在有限窗口内获取关键信息
- 错误比正确更重要:清晰报错让模型快速纠偏——基于ReAct循环逻辑,模型需要通过错误反思调整行动,清晰的错误反馈能帮助模型更快逼近正确解,周晓现场强调:“错误可能比正确更重要,这是很多工具设计时容易忽略的点。”
工具演进路线:MCP → Skill
现场拆解了工具的演进逻辑:“现在社区里每天都有新的工具思路,从早期的MCP到现在的Skill,核心目标从未改变——降低Token消耗、提升工具执行结果质量。”
- MCP:扩展模型工具能力——早期,模型的工具调用能力有限,MCP的出现,把各类工具集成到模型中,让模型能够调用更多工具,解决了“模型不会用工具”的基础问题
- Skill:渐进式加载领域知识,降低上下文占用,提升执行质量——周晓解释:“Skill本质是一个文件夹,里面除了脚本,更核心的是告诉模型‘怎么用这些工具’,相当于把领域知识直接交给模型。而且它是渐进式加载,需要时才载入领域知识,既降低了上下文占用,又能让模型更懂具体业务,所以效果提升明显。”
机器人的LSP


周晓老师现场用LSP举例,直观展示好工具的威力:“未接入LSP时,AI Coding和开发者之间存在严重的信息不对称——开发者能看到代码里的红色报错、语法高亮,知道哪里出了问题,但AI看不到,只能盲目修改代码,效率极低。”
接入LSP后,模型可以直接获取结构化错误位置(比如“第12行语法错误,缺少分号”),精准感知错误位置,动态修正代码,大幅提升开发效率。“LSP完美符合好工具的三大标准:速度快、结构化输出、能提供清晰的错误反馈,这就是AI友好工具的核心价值。”
此外,他还提到了多Agent/SubAgent的设计思路:“当单个Agent的上下文窗口不够用时,把任务拆分给子Agent,让子Agent独立执行,不占用主Agent的注意力槽,这是突破模型上下文上限的有效思路,和人类社会的分工逻辑完全一致。”


突破上下文上限:
多Agent分治架构
“Transformer自回归模型的注意力机制,本身就存在‘遗忘’问题——上下文越长,模型对早期信息的关注度越低,遗忘越明显。单个Agent有上下文窗口硬限,当任务过于复杂、上下文过长时,模型就会变得‘笨’,甚至出现幻觉。”
单个Agent有上下文窗口硬限,怎么办?
答案:SubAgent / MultiAgent
就像人类社会的分工:“老板管不过来所有事情,会把任务分配给下属一样,当单个Agent无法承载足够信息时,我们就把大任务拆成小任务,分配给不同的子Agent,让子Agent独立执行,主Agent只负责统筹协调。”
- 把大任务拆成小任务:比如把“开发一个网页”拆成“编写前端页面”“编写后端接口”“测试验收”三个小任务
- 子Agent独立执行,不占用主Agent注意力:每个子Agent专注于自己的任务,上下文不会相互干扰,也不会占用主Agent的上下文窗口
- 像人类分工一样,各司其职,协同完成:子Agent完成各自任务后,将结果反馈给主Agent,主Agent汇总后完成最终交付
这是当前突破模型物理上限的最优解。“多Agent的核心价值,就是通过分治,解决单个Agent上下文溢出的问题,让模型能够处理更复杂、更长周期的任务,这也是Harness Engineering的重要实践方向。”
AI Native设计:
释放人类最稀缺的资源——注意力
“人类的注意力是有限的,每天真正能用于工作的时间很少,但Agent可以7×24小时不间断工作,一个开发者可以同时使用几十个Agent。现在很多人用AI还是很累,核心原因就是——只让AI写代码,没有让AI完成全流程交付,人类依然要承担大量的非编码工作,注意力被严重消耗。”
未来的研发模式,一定是1个人 + N个Agent,核心是释放人类的注意力,让人类专注于更有价值的事情——设计环境、明确意图,而不是重复的编码、测试、Review工作。


核心转变:从「逐行Review」到「结果验收」
周晓老师分享了自己团队的实践经验:“我们团队正在做一款类似Claude Code的AI产品,核心就是实现‘AI全流程交付’——从需求输入到最终验收,全部由AI完成,开发者只做结果Review。” 具体流程如下:
- AI完成编码:开发者输入需求,AI自动生成代码,无需人类干预
- AI自动测试、验收、自验:AI调用测试工具,完成单元测试、集成测试,自动验收代码是否符合需求,发现错误后自动修正,形成闭环
- 开发者只Review:改了什么、测试覆盖是否完整、稳定性是否达标——不需要逐行Review代码,只关注最终交付结果和核心指标
不用再看一行代码,解放全部注意力。
周晓老师现场举例:“前两周,我们需要对齐Claude Code的Skill斜线触发功能——之前我们是通过多符号自动触发Skill,现在要改成斜线触发。我只给AI下达了需求,让它完成改造并产出详细报告,AI直接把多符号交互改成了‘/skill’触发,我只需要Review最终结果,不需要看一行代码,节省了大量时间。” 他还坦言,自己过去每天要Review两三个PR,经常熬夜,现在通过这种模式,彻底解放了注意力,不再被重复工作困扰。
标杆案例:Midscene.js
周晓老师现场详细拆解了开源的Midscene.js,给大家刨析了真正的AI Native工具:“传统网页自动化工具,需要把DOM信息、截图解析全部放入上下文,还没开始干活,就消耗了几万Token,不仅成本高,稳定性还差——一旦DOM结构变化,AI就无法识别。”
传统网页自动化:DOM+截图塞满上下文,动辄几万Token,成本高、稳定性差,依赖DOM结构,灵活性低
Midscene.js:Agent只发自然语言指令(如“点击登录按钮”“输入账号密码”),所有操作逻辑(如元素定位、DOM解析)都收敛在工具内部,AI不需要关注底层实现,只需要下达指令即可
Token消耗暴跌,稳定性大幅提升,而且不受DOM结构变化影响,灵活性极高。周晓老师补充:“Midscene.js的设计,完全遵循了AI友好工具的三大标准,也是我践行Harness Engineering的核心实践——为Agent打造专属工具,让它能更高效、更稳定地执行任务。”
给所有技术人的落地建议
停止做「编码工」
“如果你只作为一个编码者,那在今天AI一个Agent就能顶10个开发者编码工作量的时候,你写代码的价值确实在急速下降,我们必须要做转变。” 这个转变,就是从“写代码的人”,转向Harness Engineer——设计环境、明确意图、驾驭模型,为AI打造专属的“工作室”。
逼自己做端到端AI开发
“真正的AI开发,不能让AI写完代码后,你再做人肉验证。” 周晓老师建议大家:“不妨逼自己一把,暂时去掉IDE,让AI完成从需求到上线的端到端开发,你只做最终的结果验收。这样才能真正体会到Harness Engineering的价值,也能更快适应AI时代的研发模式。”
设计工具只问两句话
- 有没有减少Token消耗?
- 有没有提供清晰的错误反馈?
“这两句话,是AI友好工具设计的核心准则。只要想清楚这两点,你的工具给AI使用的效率,会大幅提升,也能更好地支撑Agent完成长闭环任务。”
不必过度焦虑
“模型它是有物理上限的,它有物理边界,它并不是大家想象中的背后有一个神奇存在,它只是一个巨大的函数,它只是一个权重。” “它能解决什么问题,完全取决于你给它提供什么状态、什么工具。只要你掌握了Harness Engineering的思路,学会驾驭模型,就能在AI时代站稳脚跟,甚至实现弯道超车。”
写在最后
AI时代,工程师的终极竞争力,不再是「写得多快」,而是「驾驭得多好」。
“不要只把大模型看作大脑,必须为它打造专属的工作室。” 这是Harness Engineering的核心精髓。
我们正处在一个范式转移的时代——从“编写代码”到“设计环境”,从“使用模型”到“驾驭模型”,AI正在重塑研发的全流程。OpenAI也在强调,软件工程团队的核心工作,已不再是写代码,而是设计环境、明确意图、构建反馈循环,让AI智能体能够自主、可靠地完成工作。
从今天起,停止用AI补全代码,开始用Harness Engineering重构整个研发流程;停止焦虑“AI会取代自己”,开始专注于提升“驾驭AI的能力”。
这不是未来,就是现在。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)