企业级 Harness Engineering (驾驭工程) 落地实战指南
一、引言
在 2026 年的今天,软件工程正经历一场根本性的范式转变。OpenAI 内部的一个由 3 名工程师组成的小团队,在五个月内交付了一款包含约 100 万行代码的 Beta 级产品。令人震惊的是:这 100 万行代码中,没有一行是人类手工编写的。
支撑这一工程奇迹的底层方法论,正是 Harness Engineering(驾驭工程)。驾驭工程的介绍看这里
当 AI(如 Codex、GPT-5)编写代码的能力呈指数级爆发时,企业面临的最大瓶颈已经从“如何写代码”变成了“如何信任并管理 AI 写的代码”。本文将深度剖析 Harness Engineering 的核心理念,并为企业管理者、产品专家及研发团队提供一套切实可行的技术落地指南。
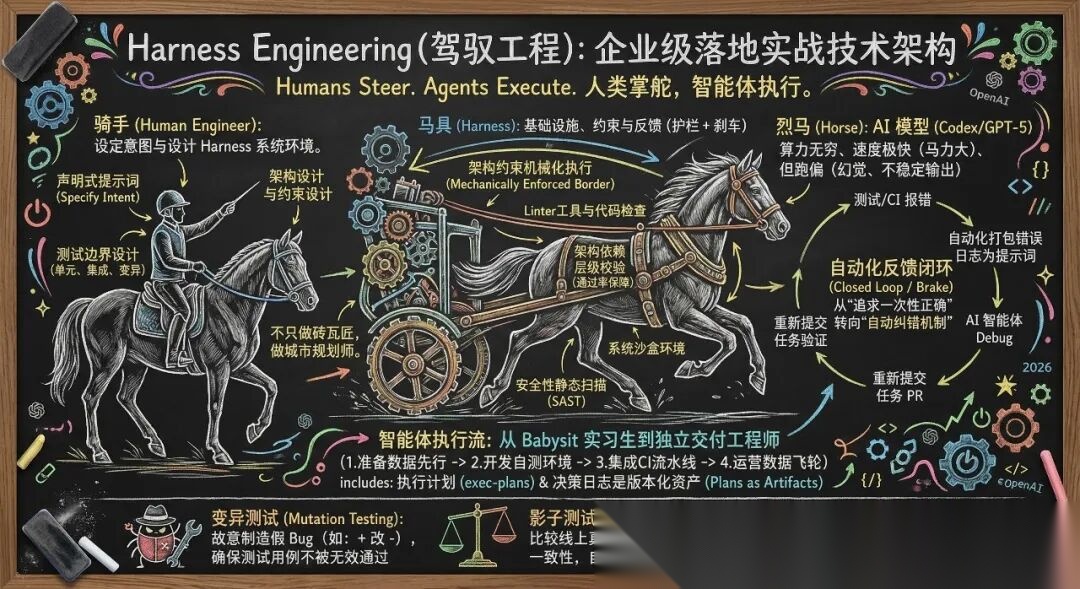
二、 核心理念:重新定义工程师的角色
理解 Harness Engineering,首先要理解“烈马、马具与骑手”的生产力模型:
- 烈马(AI 模型):算力强大、速度极快,但容易偏离方向或产生幻觉。
- 马具(Harness):基础设施、代码检查工具(Linters)、自动化测试、系统沙盒和反馈循环。
- 骑手(人类工程师):提供方向、设定意图,并设计好这套“马具”。
在智能体优先(Agent-first)的世界里,人类工程师的工作重心从“手动编写代码”转向“设计环境、明确意图,并构建自动化反馈循环”。我们不再为了让 AI “再试一次”而无休止地调整 Prompt,而是通过构建严密的约束系统,让 AI 即使犯错也能在系统内被自动拦截和纠正。
总之,Harness 工程 = 给 AI 搭建"自动纠错的基础设施"(测试+监控+安全边界),让它从"需要 babysit 的实习生"变成"能独立交付的工程师"。
三、 Harness Engineering 核心技术实践
在从零到一个空 Git 仓库,再到百万行代码的演进中,企业需要建立以下四大核心工程实践:
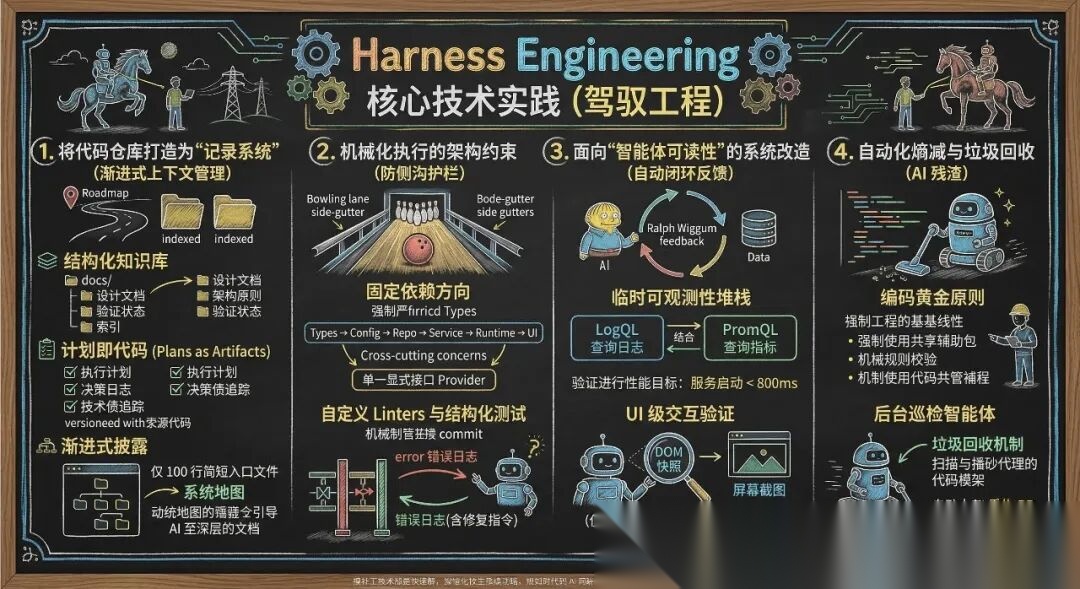
- 将代码仓库打造为“记录系统” (渐进式上下文管理)
不要试图用一个长达 1000 页的 AGENTS.md 文件来指导 AI,这会导致上下文溢出和规则腐烂。
- 结构化知识库:建立严格的 docs/ 目录。将设计文档、架构原则和验证状态编目索引。
AGENTS.md
ARCHITECTURE.md
docs/
├── design-docs/
│ ├── index.md
│ ├── core-beliefs.md
│ └── ...
├── exec-plans/
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
│ ├── index.md
│ ├── new-user-onboarding.md
│ └── ...
├── references/
│ ├── design-system-reference-llms.txt
│ ├── nixpacks-llms.txt
│ ├── uv-llms.txt
│ └── ...
├── DESIGN.md
├── FRONTEND.md
├── PLANS.md
├── PRODUCT_SENSE.md
├── QUALITY_SCORE.md
├── RELIABILITY.md
└── SECURITY.md
-
计划即代码 (Plans as Artifacts):将 AI 解决复杂任务的“执行计划 (Execution Plans)”、决策日志和技术债追踪与源码一起进行版本控制。
-
渐进式披露:为 AI 提供一个仅 100 行左右的简短入口文件,作为系统地图。指导 AI 根据当前任务,动态、按需地去检索更深层次的文档,而不是一开始就淹没在信息中。
- 机械化执行的架构约束 (防侧沟护栏)
AI 在具有严格边界和可预测结构的环境中最为高效。必须通过物理手段拦截 AI 的“越界”行为。
-
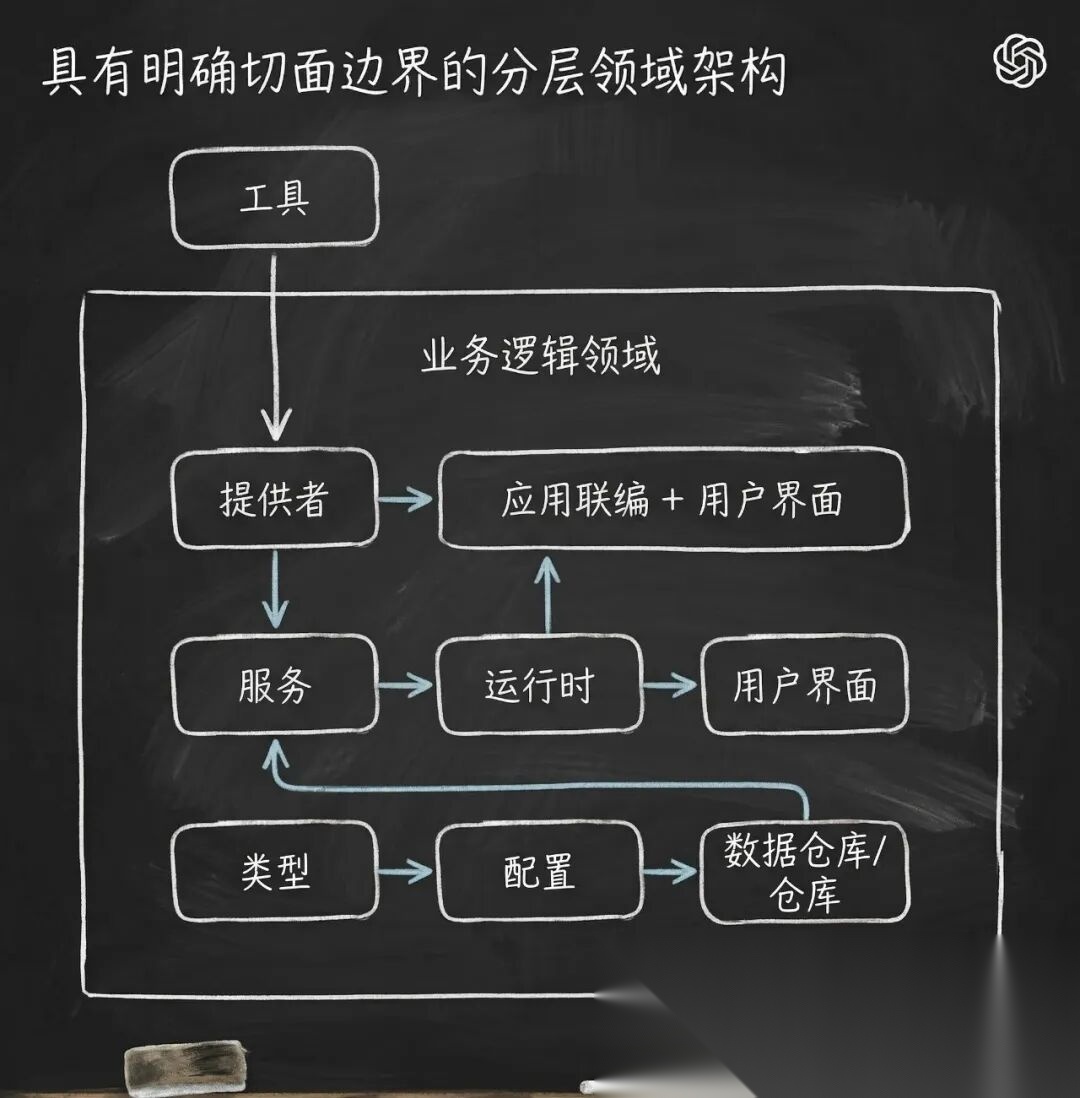
固定依赖方向:在业务域内强制执行严格的层级流转(例如:Types → Config → Repo → Service → Runtime → UI)。横切关注点(认证、连接器、遥测、功能标志)必须通过单一显式接口进入。
-
自定义 Linters 与结构化测试:将架构规范转化为机械化验证工具。如果 AI 破坏了依赖关系或未按规矩解析数据,系统会在本地直接阻断提交,并将带有修复指令的错误日志打回给 AI。
- 面向“智能体可读性”的系统改造
人类的瓶颈在于 QA 精力和注意力。必须让系统的运行状态对 AI 直接可读,从而建立自动化的闭环反馈(Ralph Wiggum 循环)。
-
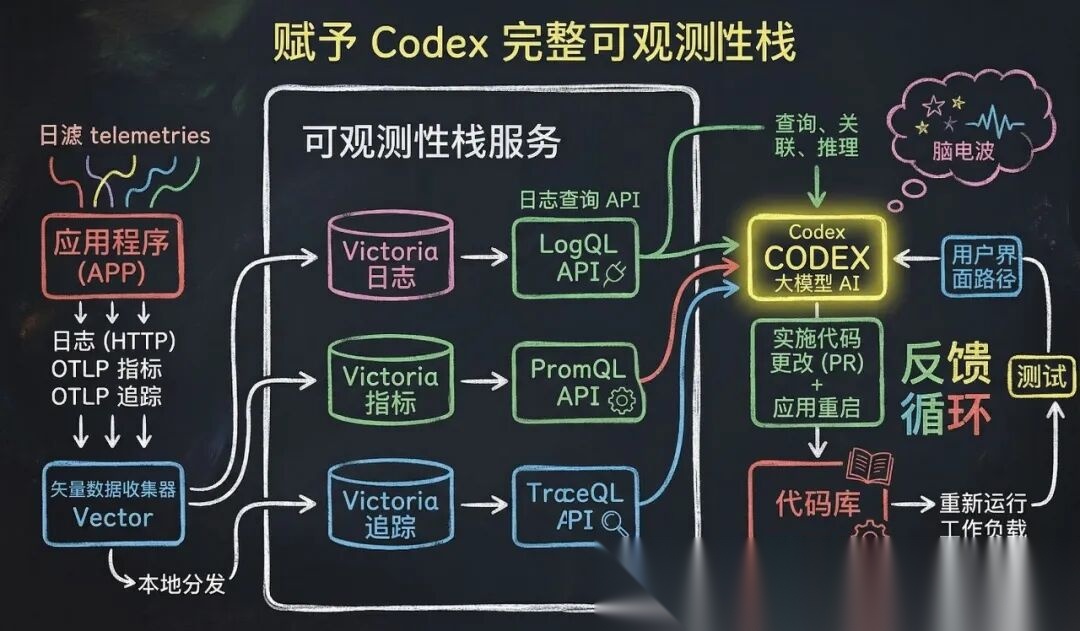
临时可观测性堆栈:允许 AI 根据独立的 Git 工作树启动应用实例。通过集成 LogQL 和 PromQL,让 AI 能够直接查询日志和指标,从而验证“服务启动是否在 800ms 内”等性能目标。
-
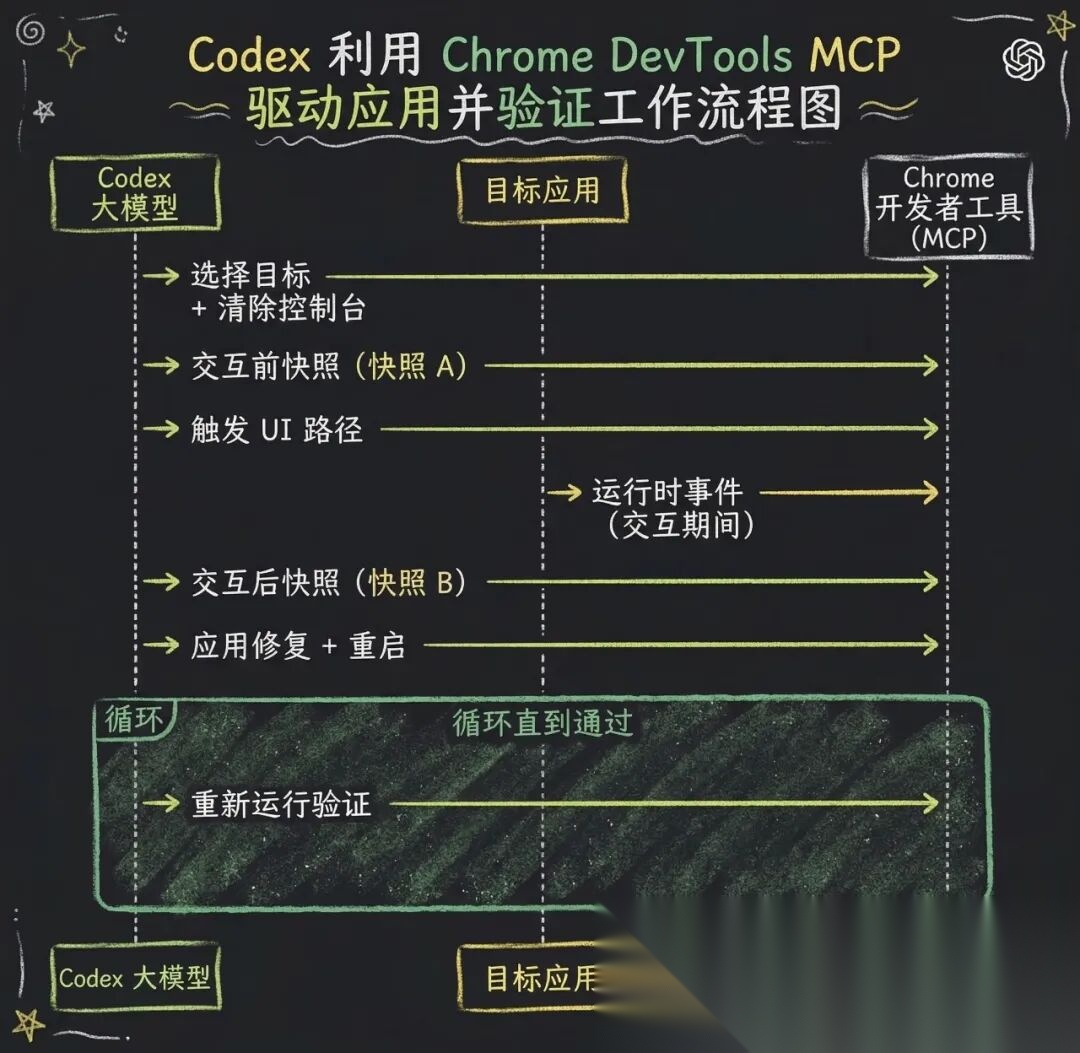
UI 级交互验证:将 Chrome DevTools 协议接入智能体运行时,赋予 AI 处理 DOM 快照和屏幕截图的能力,使其能够自主复现前端 Bug 并验证修复结果。
- 自动化熵减与垃圾回收
完全自主的智能体也会带来技术债(“AI 残渣”),它们可能会复制仓库中不理想的代码模式。
- 编码“黄金原则”:确立主观的工程底线(如:强制使用共享实用程序包而非手写辅助工具),并将其转化为可执行的机械规则。
- 后台巡检智能体:定期运行 Codex 任务,扫描代码库中的模式偏差,自动发起有针对性的重构 Pull Request。将其视为代码库的“垃圾回收”机制,防止不良模式在系统中蔓延。
四、 企业级高价值应用场景
在真实商业环境中,Harness Engineering 能够大幅降低试错成本,建立对 AI 生成代码的信任。以下是四种典型的企业落地场景:

五、 总结
Harness Engineering 并不是剥夺软件工程师的价值,而是将其提升到了更高的维度。纪律和严谨依然是软件开发的核心,只是这种纪律不再体现为对每一行代码的手工雕琢,而是体现在对支撑结构、测试边界和反馈回路的精心设计上。
当你的 Harness 系统足够坚固时,你就可以放心地让 AI 这匹算力无边的“烈马”在你的业务赛道上一路狂奔。
你团队目前最希望利用 AI 解决研发链路中的哪一个痛点(例如:清理老旧代码、提升测试覆盖率,或是加速日常业务开发)?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献151条内容
已为社区贡献151条内容

所有评论(0)