多模态AIGC课程笔记
前置知识
pytorch
机器学习框架
机器学习
定义:
机器学习是人工智能的一个子领域,研究如何让计算机从数据中自动学习模式,并用学到的模式对未见过的数据进行预测或决策,而不是通过显式编程来完成特定任务。
形式化描述:
给定一个数据集 D={(xi,yi)}i=1ND={(xi,yi)}i=1N(有监督学习),目标是找到一个函数 f:X→Yf:X→Y,使得 f(x)f(x) 能够很好地逼近真实标签 yy。学习过程通常是最小化某个损失函数 L(f(x),y)L(f(x),y) 在训练集上的期望。
核心三要素:
-
模型:描述输入到输出的映射结构(如线性模型、决策树、神经网络)
-
学习准则:损失函数(如均方误差、交叉熵)
-
优化算法:如何更新模型参数(如梯度下降)
分类:
-
有监督学习:有标签
-
无监督学习:无标签,做聚类、降维
-
强化学习:通过奖励信号学习策略
模型映射结构
即模型如何把输入变成输出,映射结构就是模型的函数形式,它定义了输入 xx 到输出 yy 的对应关系。不同的结构决定了模型能表达什么样的函数。
1. 线性模型
形式:

几何意义:
-
二维时是一条直线
-
三维时是一个平面
-
高维时是一个超平面
表达能力:
只能表示输入与输出之间的线性关系。对于非线性问题(如 XOR 异或),线性模型无能为力。
优点:简单、可解释、训练快。
缺点:拟合能力有限。
2. 决策树
形式:
一棵树,内部节点是特征判断(如 x1>5x1>5),叶子节点是输出值(分类时是类别,回归时是数值)。
举例:判断是否打篮球
-
如果天气 = 晴天 → 去打
-
如果天气 = 雨天 → 不去
-
如果天气 = 阴天 → 再根据湿度判断
表达能力:
可以表示复杂的分段常数函数。每个叶子对应一个矩形区域,区域内的所有样本输出相同。
优点:
-
天然可解释(规则清晰)
-
不需要特征缩放
-
能处理非线性关系
缺点:
-
容易过拟合(可通过剪枝、随机森林缓解)
-
对数据微小变化敏感
3. 神经网络
形式:
多层非线性函数的复合。以最简单的多层感知机(MLP)为例:

表达能力:
-
通用近似定理:只要隐藏层足够宽,一个单隐藏层网络就能逼近任意连续函数。
-
深度网络可以用更少的参数表示更复杂的函数,且能自动学习分层特征。
优点:
-
强大的拟合能力
-
端到端学习,不需要手工特征
-
适合图像、语音、文本等高维数据
缺点:
-
需要大量数据
-
训练计算量大
-
可解释性差
4. 激活函数
在神经网络中,激活函数是连接层与层之间的“门禁系统”或“转换开关”。它接收上一层神经元输出的加权和(加上偏置),经过一个非线性变换,再输出给下一层。
如果没有激活函数,无论网络有多少层,最终都等价于一个线性变换(矩阵连乘),这会极大限制模型的表达能力。激活函数引入的非线性,正是神经网络能够拟合任意复杂函数的关键。
一、激活函数的核心作用
-
引入非线性
现实世界的问题(如图像、语音、文本)几乎都是非线性的。线性模型只能解决线性可分问题(如二维平面上的直线分割)。激活函数通过非线性映射,使神经网络能够逼近任何连续函数(万能近似定理)。 -
决定神经元的“是否激活”
生物神经元有“阈值”:输入超过一定强度才会放电。人工激活函数类似:输出值可以看作该神经元对后续网络的“贡献强度”。例如 ReLU 在输入为负时不激活(输出0),正时线性放大。 -
控制数值范围
某些激活函数(如 Sigmoid、Tanh)可以将输出压缩到固定区间(如 (0,1) 或 (-1,1)),有助于稳定训练、防止数值爆炸。现代激活函数(如 ReLU)则保持正区间线性,缓解梯度消失。 -
影响梯度流
激活函数的导数在反向传播中用来计算梯度。不同函数的导数特性(是否饱和、是否为零)直接影响深层网络的训练难度。
一、常见的激活函数
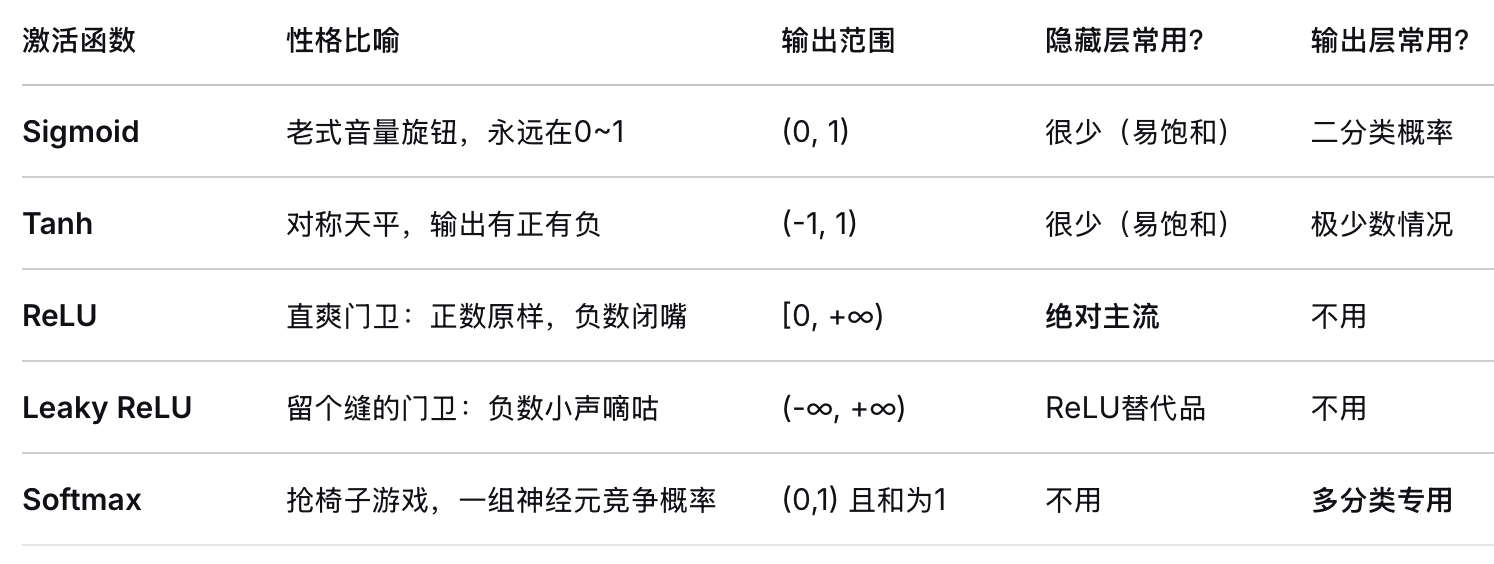
二、常见激活函数详解
1. Sigmoid(逻辑函数)
-
公式:$\sigma(x) = \frac{1}{1 + e^{-x}}$
-
输出范围:(0, 1)
-
特点:
-
平滑、可导,具有概率解释(适合输出层表示概率)。
-
输入很大或很小时,导数趋近于0 → 梯度消失。
-
输出不以零为中心(均值约0.5),可能导致梯度更新效率下降。
-
-
使用场景:早期流行,现在仅用于二分类输出层;隐藏层很少使用。
2. Tanh(双曲正切)
-
公式:$\tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}$
-
输出范围:(-1, 1)
-
特点:
-
零中心对称(均值为0),比 Sigmoid 稍优。
-
同样存在饱和区(|x|大时导数→0),梯度消失问题依旧。
-
-
使用场景:RNN 中有时作为单元内激活函数;隐藏层已较少用。
3. ReLU(Rectified Linear Unit,线性整流单元)
-
公式:$\text{ReLU}(x) = \max(0, x)$
-
输出范围:[0, +∞)
-
特点:
-
计算极简单(一次比较),正区间导数为1 → 缓解梯度消失。
-
负区间完全抑制,引入稀疏性(部分神经元输出0),可能提升效率。
-
缺点:负区间梯度为0,如果某神经元一直输出负值,其权重将永不更新(死亡 ReLU 问题)。
-
-
使用场景:目前最主流的隐藏层默认激活函数,尤其卷积网络、全连接网络。
4. Leaky ReLU / PReLU / ELU 等变体
为了解决“死亡 ReLU”问题,允许负区间有一个小的非零梯度。
-
Leaky ReLU:$\text{LeakyReLU}(x) = \max(\alpha x, x)$,其中 $\alpha$ 是小常数(如0.01)。
-
PReLU:$\alpha$ 作为可学习参数,由数据自适应调整。
-
ELU:负区间使用指数函数,输出趋近于 $-\alpha$,使均值更接近零。
-
使用场景:当发现大量神经元死亡(输出多为0)时尝试替换 ReLU。
5. Swish(自门控)
-
公式:$\text{Swish}(x) = x \cdot \sigma(x) = \frac{x}{1+e^{-x}}$
-
特点:平滑、非单调,在深层网络上常优于 ReLU。Google 提出,计算稍贵。
-
使用场景:高级模型(如 EfficientNet)中可选。
6. 输出层专用激活函数
-
Sigmoid:二分类概率(单个神经元)。
-
Softmax:多分类概率分布(输出向量,和为1)。
-
线性(无激活):回归任务(预测任意实数)。
-
Tanh:生成任务(如生成图像像素值范围在 -1 到 1)。
5. 其他概念(分类和回归)
1. 分类(Classification)
目标:预测输入样本所属的离散类别。
输出:有限个类别标签,如“猫/狗”“垃圾邮件/非垃圾邮件”“数字 0~9”。
数学形式:
学习一个函数 f:X→Yf:X→Y,其中 YY 是一个离散集合。
对于二分类,通常输出一个概率 p(y=1∣x)p(y=1∣x),再通过阈值(如 0.5)判定类别;对于多分类,输出一个概率分布,取最大概率对应的类别。
常用模型:逻辑回归、支持向量机(SVM)、决策树、神经网络(Softmax 输出层)
损失函数:交叉熵损失(Cross-Entropy Loss)是最常用的,它衡量预测概率分布与真实类别的差异。
评价指标:准确率、精确率/召回率、F1 分数、AUC-ROC 曲线等。
我们通过一个**疾病筛查**的例子来解释这几个概念,这样更容易理解。
假设有一个检测某种罕见病的试剂盒,我们用它检测了 **100 个人**,其中实际有病的 **10 人**,没病的 **90 人**。检测结果出来后,我们可以整理成下面这个表(混淆矩阵):
| 真实 \ 预测 | 预测有病 | 预测无病 |
|------------|---------|---------|
| 实际有病 | TP = 8 | FN = 2 |
| 实际无病 | FP = 10 | TN = 80 |
- **TP(真阳性)**:实际有病,检测出来有病 → 8 人
- **FN(假阴性)**:实际有病,却没检测出来 → 2 人
- **FP(假阳性)**:实际没病,却被检测成有病 → 10 人
- **TN(真阴性)**:实际没病,检测也无病 → 80 人
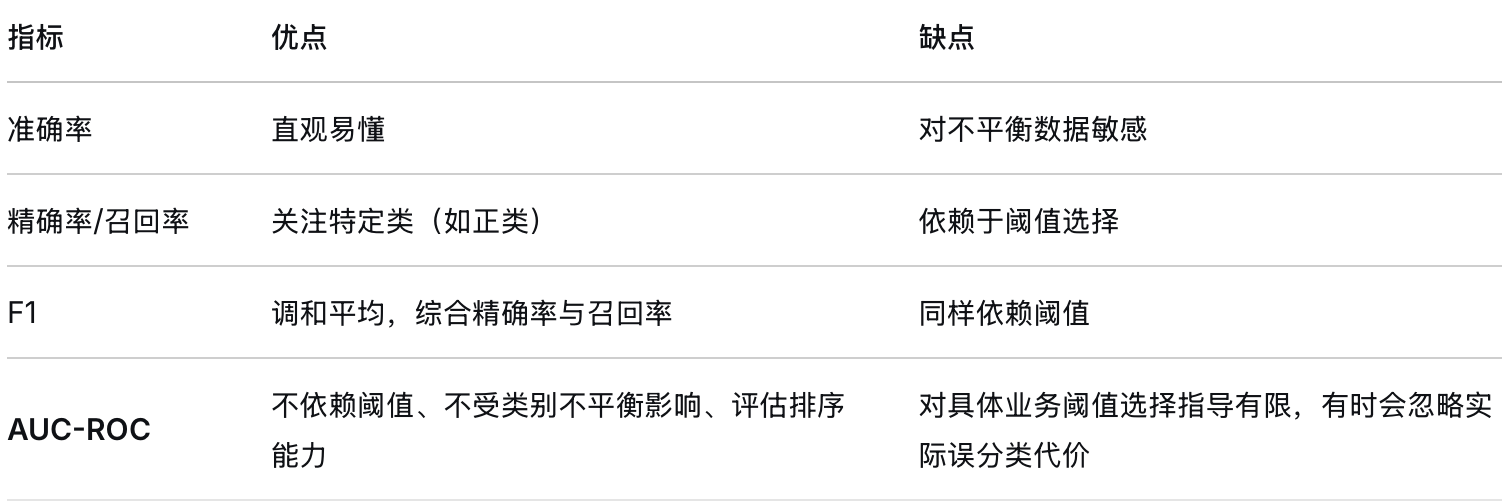
## 1. 准确率(Accuracy)
准确率是**所有判断正确的样本**占**总样本**的比例。
![]()
它告诉我们整体上模型判断得有多准。但有个问题:如果样本极度不平衡(比如 1000 人中只有 1 个病人),即使模型全部猜“无病”,准确率也能达到 99.9%,但它其实一个病人都没找出来。所以准确率有时会“欺骗”人,这时就需要其他指标。
## 2. 精确率(Precision)与召回率(Recall)
**精确率**:在**所有被模型预测为有病的人**中,**真正有病的人**占多少。
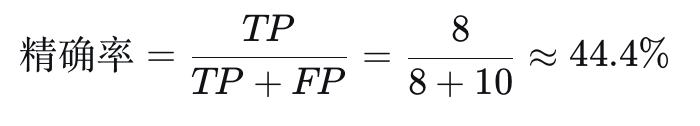
精确率高,意味着模型“说你有病”时,你大概率真的有病,误报少。这个指标关心的是**预测结果的可靠性**。
**召回率**:在**所有真正有病的人**中,**模型找出来了多少**。
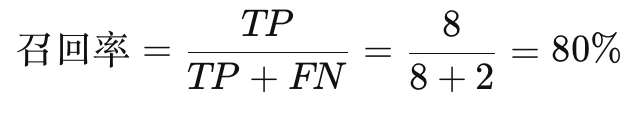
召回率高,意味着模型能把大多数病人都揪出来,漏诊少。这个指标关心的是**对阳性样本的覆盖程度**。
这两个指标往往是相互制约的:如果你想把所有病人都找出来(提高召回率),就容易把更多健康人误判为病人(降低精确率)。反之,如果你只挑最有把握的人说有病(提高精确率),就会漏掉一些病人(降低召回率)。
## 3. F1 分数(F1 Score)
F1 分数是精确率和召回率的**调和平均数**,用来综合评估模型性能:
![]()
为什么用调和平均数而不是算术平均数?因为调和平均对极端值更敏感,只有当精确率和召回率都较高时,F1 才会高。如果其中一项很低,F1 也会被拉低。因此 F1 常用来在精确率和召回率之间寻求平衡。
## 4. AUC-ROC 曲线
很多模型输出的不是“有病/无病”的二值结果,而是一个**概率值**(比如 0.3、0.9)。我们需要选一个**阈值**(比如 0.5),大于阈值判为有病,否则无病。但阈值选多少会影响精确率和召回率。
**ROC 曲线**就用来展示模型在所有可能阈值下的表现。它画的是两个指标:
- **真正率(TPR)** = 召回率
- **假正率(FPR)** = \(\frac{FP}{FP + TN}\),即所有健康人中,被误判为有病的比例。
每选一个阈值,就得到一对(FPR, TPR)。把这些点连起来,就得到 ROC 曲线。
**AUC** 是 ROC 曲线下的面积(Area Under the Curve)。AUC 越接近 1,说明模型越好——在相同假正率下,它的真正率更高;或者说,无论你选哪个阈值,模型都能保持很好的区分能力。AUC = 0.5 时,模型相当于随机猜,没有区分能力。
> 在上面的例子中,如果我们改变阈值,就可以画出 ROC 曲线。AUC 作为一个单一数值,能直观告诉我们模型“把正负样本分开”的能力有多强,且不受阈值选择的影响,尤其适合比较不同模型的优劣。
### 一句话总结
- **准确率**:整体判断正确的比例(但对不平衡数据不敏感)。
- **精确率**:预测为阳性的人里,有多少是真的。
- **召回率**:真的阳性里,有多少被预测出来了。
- **F1 分数**:精确率和召回率的调和平均,兼顾两者。
- **AUC-ROC**:衡量模型在不同阈值下区分正负类的能力,值越大越好。
2. 回归(Regression)
目标:预测输入样本对应的连续数值。
输出:实数,可以是任意范围内的值,如房价、温度、股票价格。
数学形式:
学习一个函数 f:X→Rf:X→R,输出一个连续值。
常用模型:线性回归、决策树回归、神经网络(输出层无激活函数或恒等激活)
损失函数:均方误差(MSE,Mean Squared Error)是最常见的,还有平均绝对误差(MAE)、Huber 损失等。
评价指标:MSE、MAE、均方根误差(RMSE)、R² 决定系数等。
好的,我逐个解释这四个评估指标。它们通常用来衡量**模型预测值**与**真实值**之间的差距,在回归问题中非常常用。
### 1. MSE(均方误差,Mean Squared Error)
**定义**:
MSE 是预测值与真实值之差的平方,再求平均值。
**公式**:
**通俗理解**:
想象你猜了 n个人的身高,每次猜错的距离(误差)都取平方(这样大的误差会被放大),然后把这些平方加起来,再平均。平方的作用是**让误差都变成正数**,并且**对大的误差惩罚更重**。
**特点**:
- 结果单位是“真实值的平方”,比如身高误差的 MSE 单位是“厘米²”,不容易直接理解。
- 对异常值(离群点)敏感,因为平方会放大它们的影响。
**使用场景**:
当希望模型**避免大误差**(即惩罚大的偏差)时,常用 MSE 作为损失函数(例如线性回归的优化目标)。
### 2. MAE(平均绝对误差,Mean Absolute Error)
**定义**:
MAE 是预测值与真实值之差的绝对值,再求平均值。
**公式**: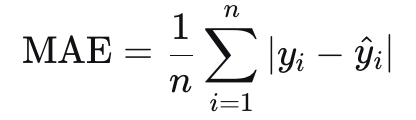
**通俗理解**:
还是猜身高的例子,这次不平方,只取误差的绝对值,然后平均。结果就是“平均每次猜错了多少厘米”。
**特点**:
- 单位与原始数据一致(比如厘米、元),更直观。
- 对异常值不那么敏感,因为绝对值不会像平方那样放大异常误差。
**使用场景**:
当需要**直观解释平均误差**,或数据中可能存在异常值、不希望异常值主导评价时,MAE 更合适。
### 3. RMSE(均方根误差,Root Mean Squared Error)
**定义**:
RMSE 就是 MSE 的平方根。
**公式**: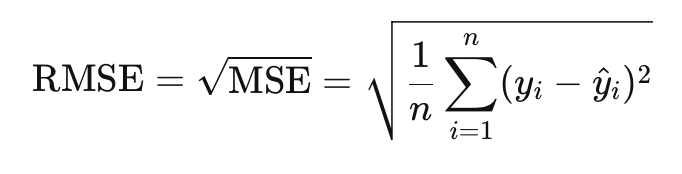
**通俗理解**:
它和 MSE 一样,对大的误差敏感,但开方后**单位回到了原始数据的单位**(比如厘米)。所以 RMSE 可以理解为“平均误差的大约大小”,但因为是平方后再开方,它实际上相当于**误差的“标准偏差”**。
**特点**:
- 单位直观,与原始数据一致。
- 保留了 MSE 对异常值的敏感性。
- 比 MAE 更倾向于反映较大误差的影响。
**使用场景**:
在需要同时**保持单位可解释**且**惩罚大误差**时,RMSE 是常用指标。
### 4. R² 决定系数(Coefficient of Determination)
**定义**:
R² 衡量模型预测值与真实值之间的**拟合优度**,表示模型解释了目标变量多大比例的方差。
**公式**: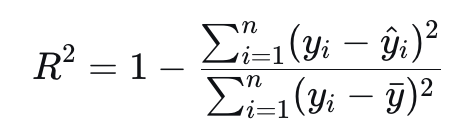
**通俗理解**:
分子是模型预测的残差平方和(即模型没解释的部分),分母是总平方和(即真实值自身的波动)。用 1 减去“没解释的比例”,就得到“模型解释的比例”。
**取值范围**: 
**特点**:
- 无量纲,可以用于比较不同模型的相对优劣。
- 不直接反映预测误差的大小(比如预测值整体偏大但趋势一致,R² 可能依然很高)。
- 增加更多特征时,R² 不会减少(除非用调整后的 R²)。
**使用场景**:
需要**解释模型对数据的拟合程度**,或在不同模型之间进行相对比较时,常用 R²。例如回归分析中报告 R² 说明模型解释力。
### 总结对比
| 指标 | 公式 | 优点 | 缺点 | 常用场景 |
|------|------|------|------|----------|
| MSE | 误差平方平均 | 数学性质好,可导,适合作为损失函数 | 单位平方,对大误差敏感 | 优化目标 |
| MAE | 误差绝对值平均 | 单位直观,鲁棒性好 | 在零点不可导,对大误差不敏感 | 结果解释 |
| RMSE | MSE 平方根 | 单位直观,保留对大误差的敏感 | 对异常值敏感 | 评价模型 |
| R² | 1 - 残差平方/总平方 | 无量纲,直观反映解释程度 | 不直接反映误差大小 | 模型解释力比较 |
深度学习
定义:
深度学习是机器学习的一个分支,核心是使用深层神经网络(通常 ≥ 3 层非线形变换)来进行表示学习。它通过分层特征提取,从原始数据中逐层抽象出高层语义。
与浅层学习的区别:
-
浅层模型(如 SVM、逻辑回归)往往需要手工设计特征,特征工程是关键瓶颈。
-
深度学习通过端到端学习,自动从原始数据中学习特征表示,特征层次随着层数增加而抽象化。
数学基础:
一个前馈神经网络(多层感知机)的层可以表示为:
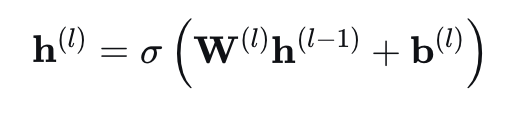
其中 σ是非线性激活函数(ReLU、sigmoid 等)。深度学习的“深度”体现在 L 较大。
关键能力:
-
层次化特征:图像识别中,浅层学边缘 → 中层学纹理/部件 → 高层学物体
-
通用近似定理:足够宽的神经网络可以逼近任意函数,深度网络则用更少的参数实现更复杂的函数
挑战:
-
梯度消失/爆炸(通过残差连接、BatchNorm、合适的初始化缓解)
1. 什么是梯度消失与梯度爆炸?
在深度神经网络中,我们通过反向传播计算损失函数对每个参数的梯度,然后利用梯度更新参数。当网络很深时(比如几十上百层),梯度在反向传播过程中可能指数级衰减(接近0)或指数级增长(变得极大),这就是梯度消失和梯度爆炸。
-
梯度消失:靠近输入层的梯度变得非常小,导致这些层的参数几乎不更新,网络无法学习到底层特征。
-
梯度爆炸:梯度变得极大,参数更新步长过大,导致损失剧烈震荡,甚至数值溢出。
2. 如何缓解?
(1)残差连接(Residual Connection)
思想:让网络学习一个残差映射,而不是直接学习原始映射。
设期望的映射为 F(x),传统网络直接拟合 y=F(x)。残差网络则让若干层拟合残差:
y=F(x)+x
这样梯度可以跨层直接传播,而不必经过多个非线性变换。
(2)批量归一化(Batch Normalization, BN)
思想:对每一层的输入进行标准化,使其均值为0、方差为1,然后学习缩放和平移参数。
作用:
-
将激活值控制在非线性函数的非饱和区(如ReLU的线性区),避免导数过小或过大。
-
减少内部协变量偏移,使训练更稳定。
-
允许使用更大的学习率,加快收敛,也间接缓解梯度爆炸。
BN 能有效抑制梯度消失/爆炸,但它并非为梯度问题专门设计,而是通过稳定分布达到效果。
(3)合适的初始化
初始化权重时,需要使各层激活值的方差和梯度的方差保持稳定,避免连乘后指数级变化。

-
过拟合(通过 Dropout、正则化、数据增强)
1. 什么是过拟合?
过拟合指模型在训练数据上表现极好(损失很低,准确率很高),但在未见过的测试数据上表现较差。本质是模型过度学习了训练数据中的噪声和特定模式,导致泛化能力差。
2. 为什么会过拟合?
-
模型复杂度过高:参数数量远超数据规模,模型可以“记住”训练样本。
-
训练数据不足或分布单一:缺乏足够多样的样本,模型只能拟合有限的模式。
-
训练时间过长:在优化过程中,模型先学习一般规律,后期开始拟合噪声。
(1)Dropout
思想:在训练过程中,以概率 pp(通常0.5)随机将某些神经元的输出置为0,相当于每次迭代都训练一个不同的子网络。
作用:
-
防止神经元之间产生复杂的共适应关系,迫使网络学习更鲁棒的特征。
-
相当于一种模型集成(每次子网络的平均),提高泛化能力。
(2)正则化(L1 / L2)
在损失函数中添加对权重的惩罚项,限制权重的幅值。
-
L2 正则化(权重衰减):
-
相当于每次更新时对权重进行衰减,迫使权重保持较小值,从而降低模型复杂度。
-
L1 正则化:
会使权重变得稀疏(部分权重为0),起到特征选择的作用。
直觉:权重越小,函数越平滑,对输入的变化不敏感,从而减少过拟合。
(3)数据增强(Data Augmentation)
思想:通过对训练数据进行随机变换,生成更多样化的样本,让模型看到更多变体,从而学习到更本质的特征。
常见方法(以图像为例):
几何变换:随机旋转、裁剪、翻转、缩放
颜色变换:亮度、对比度、色调的随机调整
添加噪声:高斯噪声、模糊
更高级的:MixUp、CutMix、自动增强(AutoAugment)
作用:
变相扩大数据集,提高数据多样性。
迫使模型关注内容而非局部纹理或位置,提高鲁棒性。
(4)其他常用方法
-
早停法(Early Stopping):在验证集性能不再提升时停止训练,防止过度拟合噪声。
-
减小模型容量:减少层数、神经元数量,或使用更简单的网络结构。
-
集成方法:训练多个模型并平均预测,降低过拟合风险。
- 计算资源需求大(通过 GPU/TPU 并行计算)
神经网络基础
梯度下降
如何更新模型参数——梯度下降

1. 损失函数

2. 梯度:函数“下降最快”的方向

3. 梯度下降更新公式

4. 几种梯度下降变体

前向/反向传播
神经网络中的梯度计算:反向传播
神经网络的参数非常多(成千上万甚至亿级),如何高效计算所有参数的梯度?答案是反向传播(Backpropagation),它利用链式法则,从输出层向输入层逐层计算梯度,避免了重复计算。
反向传播的核心是:
-
前向传播:计算每层的输出和最终的损失
-
反向传播:从损失开始,逐层计算梯度
-
更新参数:用梯度下降更新所有参数
全连接网络
1. 是什么?
全连接网络(Fully Connected Network,也叫 Dense Network)是最基本的神经网络结构。它由若干层组成,每一层的每个神经元都与上一层的所有神经元相连,就像一张密集的网,所以叫“全连接”。
2. 结构
假设输入有 100 个数字(比如一张 10×10 灰度图的像素),第一层有 50 个神经元。那么每个神经元都要接收全部 100 个输入,然后通过一个线性变换(加权求和 + 偏置)和非线性激活函数,产生输出。第二层同理,每个神经元再连接上一层的 50 个输出。
参数数量 = 上一层节点数 × 当前层节点数 + 当前层偏置数,随着层数和节点数增加,参数量非常庞大。
3. 比喻
全连接网络就像一个“全员开大会”:每个人都要和所有人交换信息,信息量大但缺乏针对性。它能学习任意复杂的函数,但需要大量数据,且容易过拟合。
4. 应用
-
作为分类器的最后一层(比如把 CNN 提取的特征映射到类别)。
-
处理没有空间结构的数据,如房价预测(输入是面积、卧室数等表格数据)。
-
在小规模、低维数据上效果不错。
CNN(卷积神经网络)
1. 是什么?
CNN 是一种专门为处理具有空间结构的数据(如图像、语音、文本)而设计的神经网络。它通过卷积核(一个小的过滤器)在输入上滑动,提取局部特征,并利用参数共享和稀疏连接大幅减少参数。
2. 核心操作
-
卷积:一个小的权重矩阵(如 3×3)在输入图像上滑动,每次计算窗口内像素的加权和,生成一张特征图。这个过程相当于用同一个“模板”扫描全图,检测某种模式(如边缘、纹理)。
-
池化(可选):对特征图进行下采样(如取最大值或平均值),缩小尺寸,提高计算效率,增强平移不变性。
-
多层堆叠后,浅层学到简单特征(边缘、颜色),深层学到复杂特征(眼睛、鼻子、物体部件)。
3. 为什么比全连接更适合图像?
-
参数共享:同一个卷积核在全图共用,参数量大大减少。例如,一张 224×224 的图像,如果用全连接第一层 1000 个神经元,参数达 5000 万;而一个 3×3 卷积核只有 9 个参数(外加偏置)。
-
局部连接:每个神经元只连接到输入的局部区域(感受野),符合图像“邻近像素相关性高”的特点。
-
平移不变性:卷积核在图像任何位置检测到相同的特征都会响应,因此物体位置移动不影响识别。
4. 比喻
CNN 就像“用放大镜扫描图片”:你用一个小的模式(比如“猫耳朵的形状”)在整个画面上滑来滑去,看到符合的地方就标记出来。然后第二层再用更大的模式(比如“耳朵+眼睛”)去组合,最终认出整个猫。这样你不需要记住每个像素,只记住少量模板,高效且通用。
5. 应用
-
图像分类、目标检测、人脸识别
-
语音识别(将音频转为频谱图作为输入)
-
文本分类(将句子视为一维序列,用一维卷积提取局部短语特征)
RNN(循环神经网络)
定义:
RNN 是一类用于处理序列数据的神经网络,它在隐藏层引入了循环连接,使得网络具有“记忆”能力,能够捕捉序列中的时间依赖关系。
想象你正在读一本小说。你一边读,一边会在脑子里记住前面发生的情节,这样读到后面时,你才能理解“他”指的是谁、“那个地方”是哪里。RNN 就是这样:它在处理一个序列(比如一句话)时,会维护一个“记忆”状态,每读一个新词,就把这个新词和之前的记忆结合起来,更新记忆,然后输出对当前词的理解。
它的工作流程:
-
有一个“记忆盒”(隐藏状态),一开始是空的。
-
每读一个词,就把这个词和当前记忆盒里的内容一起处理,得出新的记忆,同时可能输出一个结果(比如预测下一个词)。
-
然后继续读下一个词,重复以上步骤。
但 RNN 有一个问题:如果句子很长,读到后面时,记忆盒里最初的信息早就被后来的信息“冲淡”了,它会忘记很久以前的内容。这就像你看一本几百页的小说,读到最后一章时,已经记不清第一章的细节了。
梯度消失与爆炸 —— 为什么 RNN 难训练
训练 RNN 时,我们通过反向传播调整参数。但 RNN 的参数在时间步上是共享的,所以误差要沿着时间轴反向传播很多步。如果每一步的梯度都小于 1,连乘之后就会越来越小,最终趋近于 0(梯度消失),导致模型学不到远距离的依赖关系。反过来,如果每一步的梯度都大于 1,连乘后会指数级增长(梯度爆炸),参数更新过大,模型直接崩溃。
LSTM 和 GRU 通过门控机制让梯度可以在细胞状态上流畅传递(“高速通道”),从而缓解了梯度消失问题,让模型能学到更长的依赖关系。
BPTT(随时间反向传播)—— RNN 的训练方法
RNN 的训练方法叫“随时间反向传播”。你可以想象成把 RNN 在时间上“展开”成一个很深的共享参数的前馈网络,然后对这个展开的网络进行反向传播。因为时间步长可能很长,所以反向传播的路径也很长,这就是梯度消失/爆炸产生的根本原因。
LSTM(长短期记忆网络)
—— 给记忆加上“门”
为了解决 RNN 记不住长距离信息的问题,科学家发明了 LSTM。它给记忆盒装上了三个“门”:
-
遗忘门:决定哪些旧记忆要丢掉(比如读到新章节,旧的人物关系可能不再重要)。
-
输入门:决定哪些新信息要存入记忆(比如新出现的关键情节)。
-
输出门:决定当前要输出哪些信息(比如根据记忆回答当前问题)。
这样一来,LSTM 可以决定保留重要的长期信息,忽略无关的短期信息,因此能记住很久以前的关键内容。这就是“长短期记忆”名字的由来:它既有短期处理能力,又能保留长期信息。
GRU(门控循环单元)—— LSTM 的简化版
GRU 是 LSTM 的一个简化版本,把遗忘门和输入门合并成一个“更新门”,还少了一个输出门,结构更简单,参数更少,但效果通常和 LSTM 差不多。如果 LSTM 像一台功能齐全的相机,GRU 就像一台简化版傻瓜相机,操作更轻便,在很多任务中表现也足够好。
transformer
自注意力机制
定义:
自注意力是一种序列建模机制,它通过计算序列中每个元素与其他所有元素之间的相关性权重,来聚合全局信息,生成每个元素的新表示。与 RNN 不同,它不依赖时间顺序,而是并行计算所有位置的关系。

多头注意力(Multi-Head Attention):

位置编码:

与RNN对比:

QKV
QKV 是 Transformer 自注意力机制中的三个核心角色:查询(Query)、键(Key)、值(Value)。
你可以想象一个图书馆查资料的过程:
-
Q(查询):你在检索系统里输入的关键词,代表“我想找什么”。
-
K(键):每本书的标签或索引,代表“我有什么特征被检索”。
-
V(值):书里的实际内容,代表“我真正包含的信息”。
计算注意力时,系统会把你的 Q 和所有书的 K 做匹配,算出相关度(比如点积),然后按相关度高低,把对应 V 的内容加权组合起来,得到最终结果。
在 Transformer 里,每个词都会同时扮演这三种角色:它用自己的 Q 去匹配所有词的 K,再聚合所有词的 V,从而更新自己的表示。
Transformer 的编码器-解码器完整架构
编码器:多层的多头自注意力机制
解码器:
需要前后信息对齐的模型就是又有编码又有解码,如bert;但是有的纯生图模型可能就只有解码
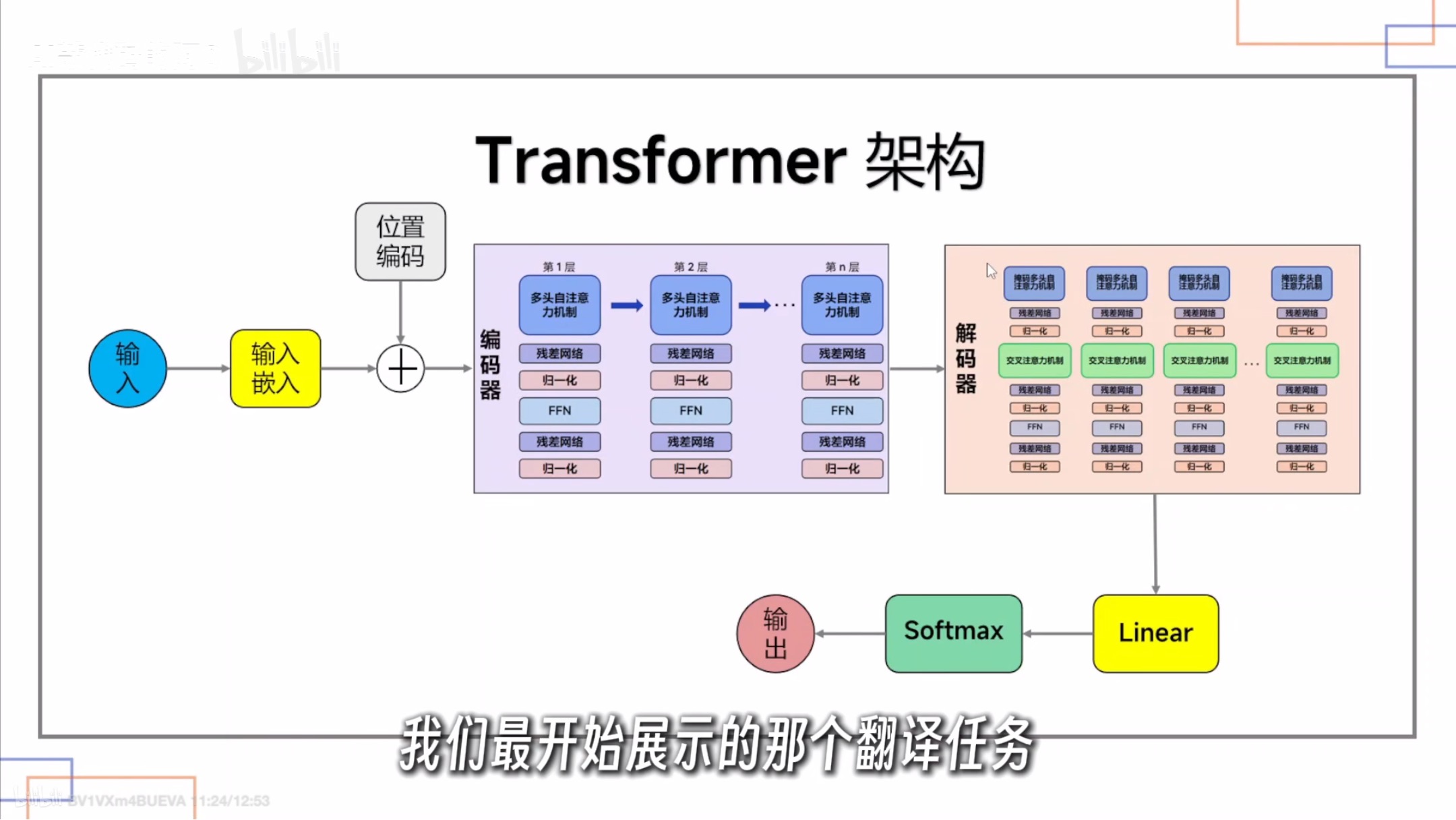
-
编码器(Encoder):负责“阅读理解”输入句子(比如中文)。
它由多个相同的层堆叠而成,每层包含两个子层:-
多头自注意力:让每个词都能看到整个句子中所有词,学习词与词之间的关系。
-
前馈网络FFN:对每个词独立做非线性变换,增强表达能力。前馈网络(FFN)都是一个全连接前馈网络,它是逐位置独立的(position-wise),即对序列中每个位置的向量做相同的变换,不同位置之间不共享信息
-
每个子层后面都加一个 残差连接(把输入直接加到输出上)和 层归一化,让训练更稳定。
-
-
解码器(Decoder):负责“逐词生成”输出句子(比如英文)。
它也是多层堆叠,但每层比编码器多一个子层:-
带掩码的多头自注意力:生成当前词时,只能看到已生成的左边部分,不能看到未来的词(掩码就是遮住未来)。
-
编码器-解码器注意力:用解码器当前的状态作为 Q,去编码器的输出中寻找 K 和 V,实现“一边生成,一边参考输入句子”。
-
前馈网络(同上)。
最后经过一个线性层和 softmax,输出每个位置最可能的下一个词。
-
-
模型选型考量
-
任务类型
-
机器翻译、文本摘要、对话生成等输入输出都是序列的任务 → Transformer(或基于 Transformer 的模型如 BART、T5)是首选,因为它的编码器-解码器结构天然适合。
-
文本分类、情感分析、命名实体识别等只理解输入的任务 → 通常用 BERT 等只用编码器的预训练模型,效果好且简单。
-
文本续写、故事生成、代码生成等单向生成任务 → 用 GPT 系列(只用解码器),它擅长从左到右自回归生成。
-
时间序列预测、小规模序列建模 → 如果数据量不大或需要低延迟,LSTM 或 GRU 仍然实用,比 Transformer 更轻量。
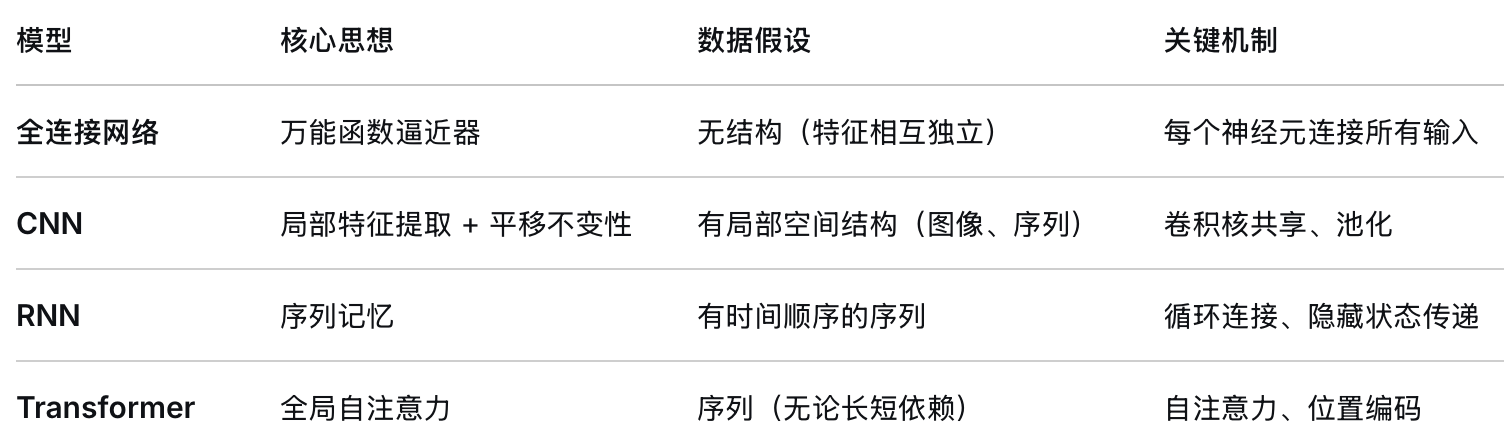
几种神经网络模型对比
1. 全连接网络
设计哲学:
认为输入的所有特征都可能相互影响,因此每个神经元都要考虑全部输入。这是一种无先验假设的结构,理论上可以拟合任何函数(通用近似定理)。
结构特点:
-
每层神经元与上一层所有神经元相连
-
参数数量 = 输入维度 × 输出维度 + 偏置,增长极快
-
输入必须展平为一维向量,丢弃空间结构
优点:
-
简单、通用,适合处理表格数据
-
作为其他模型的输出层(分类头)广泛使用
缺点:
-
参数爆炸,易过拟合
-
无法利用数据中的局部结构(如图像的邻近像素相关性)
应用场景:
-
表格数据预测(房价、用户画像)
-
作为分类/回归任务的最后一层(接在 CNN、Transformer 后面)
-
小规模、低维数据建模
2. CNN(卷积神经网络)
设计哲学:
利用局部性和平移不变性这两个自然图像的固有属性。图像中相邻像素关系密切,且同一模式(如边缘)可能在任意位置出现。
结构特点:
-
卷积层:小卷积核(如 3×3)在输入上滑动,参数共享,提取局部特征
-
池化层:下采样,增加感受野,提高平移不变性
-
层级化特征:浅层学边缘/纹理,深层学物体部件/整体
优点:
-
参数远少于全连接网络
-
天然适应图像、视频等网格状数据
-
训练稳定,易于优化
缺点:
-
感受野增长需要堆叠多层,对极长距离依赖(如整段文本)仍有限
-
对旋转、缩放等变换不够鲁棒(需要数据增强)
应用场景:
-
图像分类(ResNet、VGG)
-
目标检测(YOLO、Faster R-CNN)
-
语音识别(将音频转为频谱图作为输入)
-
文本分类(一维卷积提取 n-gram 特征)
3. RNN(循环神经网络)
设计哲学:
假设数据是序列,且当前时刻的信息依赖于历史。通过隐藏状态传递信息,模拟“记忆”过程。
结构特点:
-
循环连接:隐藏状态 htht 同时依赖于当前输入 xtxt 和上一时刻 ht−1ht−1
-
参数共享:所有时间步使用相同的权重矩阵
-
变体 LSTM/GRU:引入门控机制,解决长序列梯度消失问题
优点:
-
天然适合变长序列
-
理论上的无限记忆(通过状态传递)
-
推理时内存占用固定
缺点:
-
顺序计算:无法并行,训练慢
-
长期依赖仍有限:即使 LSTM,面对超长序列(>500步)仍会衰减
-
反向传播通过时间(BPTT)易梯度爆炸
应用场景:
-
时间序列预测(股票、天气)
-
小规模语言模型(早期机器翻译)
-
实时处理场景(嵌入式设备、低延迟要求)
-
序列标注(如命名实体识别,虽然后来被 BERT 取代
4. Transformer
设计哲学:
放弃循环和卷积,完全依赖自注意力来捕捉序列中任意两个位置的关系。核心假设是:序列中的依赖关系应该直接建模,而不是通过逐步传递。
结构特点:
-
自注意力:每个位置同时与所有位置计算相关性,复杂度 O(n2)O(n2)
-
多头机制:从多个子空间学习不同关系
-
位置编码:注入顺序信息(因为自注意力本身是置换不变的)
-
编码器-解码器 或 仅编码器/仅解码器 三种变体
优点:
-
并行计算:训练速度远超 RNN
-
长距离依赖:一步到位,无衰减
-
可扩展性:通过堆叠层数、扩大模型尺寸,能利用海量数据
缺点:
-
O(n2)O(n2) 复杂度,处理超长序列(>10k token)时显存和计算开销大
-
需要海量数据训练(小数据集上不如 RNN)
-
推理时自回归生成(GPT 类)仍需顺序执行
应用场景:
-
编码器-解码器:机器翻译、文本摘要(T5、BART)
-
仅编码器:文本理解、分类(BERT、RoBERTa)
-
仅解码器:文本生成、对话(GPT 系列)
-
扩展到图像(ViT)、音频(Whisper)、多模态(CLIP)
它们的联系
-
都是神经网络:由可微分的层堆叠而成,通过反向传播优化。
-
层级化特征提取:CNN 在空间上分层,RNN 在时间上分层,Transformer 在抽象层次上分层。
-
RNN → Transformer:Transformer 可以看作 RNN 的“并行化”版本,用自注意力替代循环传递。
-
CNN 与 Transformer:CNN 是局部连接 + 参数共享,Transformer 是全局连接 + 参数不共享(但通过多头可以学习局部性)。
-
全连接作为通用组件:在 CNN、RNN、Transformer 的最后一层通常都接全连接层做输出。
应用场景总结
| 任务类型 | 首选模型 | 原因 |
|---|---|---|
| 图像分类、目标检测 | CNN | 局部性、平移不变性、参数效率 |
| 图像生成(如扩散模型) | CNN + Transformer 混合 | CNN 提供局部细节,Transformer 捕捉全局关系 |
| 语音识别(实时) | RNN/LSTM | 低延迟、流式处理 |
| 语音识别(离线) | Transformer | 高精度、可并行训练 |
| 文本分类、情感分析 | BERT(Transformer 编码器) | 双向上下文理解 |
| 文本续写、对话生成 | GPT(Transformer 解码器) | 自回归生成能力 |
| 机器翻译、摘要 | Transformer(编码器-解码器) | 输入输出结构匹配 |
| 时间序列预测(小数据) | LSTM/GRU | 轻量、不易过拟合 |
| 时间序列预测(大数据) | Transformer 变体(如 Informer) | 捕捉长期依赖 |
| 表格数据 | 全连接网络 或 树模型 | 无空间结构,简单直接 |
| 多模态(图文理解) | Transformer(如 CLIP) | 统一处理不同模态的序列 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)