OpenAI 工程师不写代码了?拆开 Harness Engineering 看看他们到底在干嘛
2 月 11 日,OpenAI 发了一篇工程博客《Harness engineering: leveraging Codex in an agent-first world》。
传播最广的当然是那句“5 个月、100 万行代码、0 行人工手写”。
不过把原文和四张图一起看完,你会发现它真正在讲的既不是“程序员以后不用写代码了”,也不是“AI 已经搞定软件工程了”。
它公开的其实是一套让 Agent 可以稳定参与开发的工程组织方式。
他们把这套方法叫做 Harness Engineering。
Harness 可以理解成“缰绳”或者“马具”。重点不在马跑得多快,而在你有没有一套东西把它稳稳驾住。
下面直接按原文和四张图往下拆。
太长不看版
- • OpenAI 这篇文章的核心,不是“AI 会写代码”,而是人类怎么给 Agent 搭环境、补能力、做约束、建反馈回路。
- • 原文真正反复强调的,是一句话:Humans steer. Agents execute.
- • 四张图分别对应四个关键动作:让 Agent 能看 UI、能看日志指标、能读仓库知识、能在刚性架构里工作。
- •
AGENTS.md在 OpenAI 这里不是总说明书,而是地图。真正的知识库在仓库里的docs/、计划、架构文档和规则系统。 - • Agent 的 review 已经做到 Agent 对 Agent,人类只在关键判断点介入。原文管这个闭环叫 Ralph Wiggum Loop。
- • Codex 现在已经能端到端完成:复现 Bug → 录视频 → 修复 → 验证 → 开 PR → 回应反馈 → 合并。但 OpenAI 也承认这高度依赖特定仓库的投入。
- • 从更大的视角看,Harness Engineering 本质上是控制论的最新实例:瓦特调速器 → Kubernetes → Agent 驾驭工程,同一个模式。
- • 这套方法的代价不小。没有文档、没有测试、没有结构约束的团队,直接照抄大概率只会更乱。
- • 对大多数团队来说,最值得学的第一步不是“禁止手写代码”,而是把代码仓库变成 Agent 真能读懂、真能验证、真能纠偏的地方。
先把原文里的几个事实对齐
原文发布时间是 2026 年 2 月 11 日。
OpenAI 说,这个实验从 2025 年 8 月下旬 的一个空 Git 仓库开始。初始脚手架,包括仓库结构、CI 配置、格式化规则、包管理器设置和应用框架,都是由 Codex CLI 在模板引导下生成的。连最初那份指导 Agent 如何在仓库中工作的 AGENTS.md,也是 Codex 写的。
五个月后,这个仓库长到了约 100 万行代码。覆盖范围不只是应用逻辑,还包括测试、CI、文档、可观测性和内部开发工具。期间累计大约 1500 个 PR,最初由 3 名工程师 驱动,后来扩到 7 人,吞吐量还在上升。产品已经给内部用户和外部 alpha 测试者使用,不是一个纯 demo。
顺便说一下,原文对“0 行手写代码”的定义非常彻底。Agent 产出的不仅仅是业务逻辑,还包括:测试、CI 配置和发布工具、内部开发者工具、文档和设计历史、评估框架、review 评论和回复、管理仓库本身的脚本、生产仪表盘定义文件。换句话说,连“管代码的代码”都是 Agent 写的。
这几个数字当然很抓眼球。
但原文真正想回答的问题其实是另一个:
当“写代码”不再是团队的主要工作时,软件工程剩下的核心工作是什么?
OpenAI 给出的答案不是“只要会提需求就行”,而是三件事:
- • 设计环境
- • 明确意图
- • 构建反馈回路
这也是整篇文章真正的主线。
第一层变化:工程师从写实现,转向给 Agent 补能力
原文里有一句话比“0 行手写代码”更值得记住:
早期进展慢,不是因为 Codex 不够强,而是因为环境定义得不够清楚。
这句话基本把 Harness Engineering 说透了一半。
过去我们遇到开发卡住,第一反应通常是自己下场多写一点、修一点、补一点。
OpenAI 这套做法不一样。因为他们给自己设了一个强约束:不手写代码。于是每次 Agent 卡住,他们只能反过来追问:
- • 它到底缺了什么能力?
- • 这个能力是缺工具、缺文档、缺抽象,还是缺规则?
- • 怎么把这个能力变成 Agent 能看懂、能执行、还能被强制遵守的东西?
原文里把这个过程称为 depth-first working,也就是先把大目标拆成设计、代码、评审、测试这些更小的构件,再让 Agent 去逐步搭起来。
真正变的不是“Prompt 怎么写”,而是思路。
出了问题,不再先怪模型,而是先检查环境有没有把正确答案的边界表达清楚。
但现实中很多团队正好反过来——一边说 Agent 老犯错,一边又把关键上下文放在聊天记录、口头同步和个人经验里。这样做,模型不犯错才奇怪。
网上有一条评论说得很扎心:
“agent 反复犯错,不是能力问题,是你脑子里的判断力没写下来。你不写,它第一百次还犯同样的蠢。”
挺狠的,但确实是这么回事。
图 1 讲的是:先给 Agent 一双“看得见界面”的眼睛
原文的第一张图,对应的是“提高应用程序的可读性”。
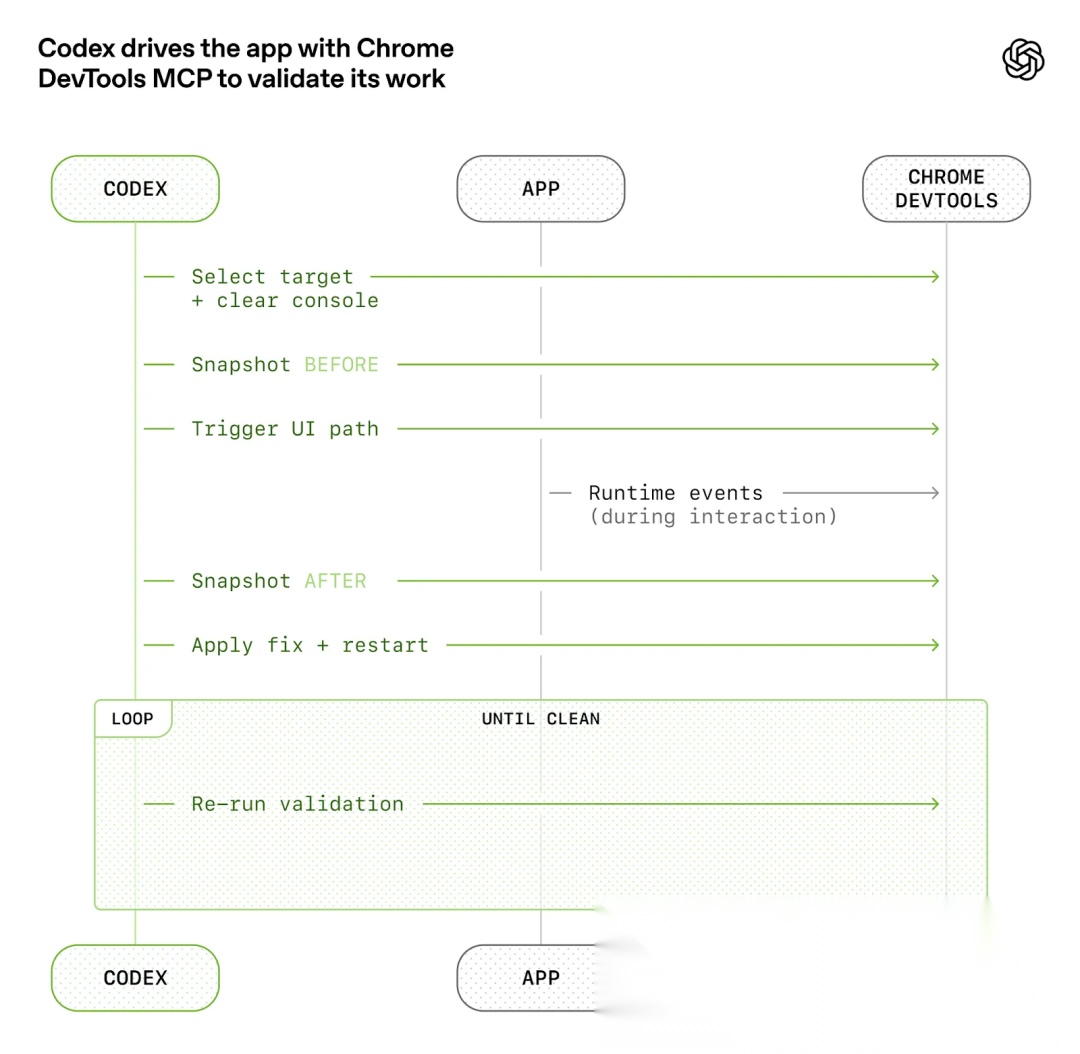
这张图里最重要的不是 Chrome DevTools 这个名词,而是这条验证链路:
- • 选定目标并清理控制台
- • 操作前做一次快照
- • 触发 UI 路径
- • 观察运行时事件
- • 操作后再做一次快照
- • 应用修复并重启
- • 循环验证,直到没有问题
背后要解决的问题很现实:代码生成速度上来之后,人类 QA 会先成为瓶颈。
原文说得很直接,随着代码吞吐量增加,团队的固定约束变成了 human time and attention,也就是人的时间和注意力。
所以他们做的不是继续扩大人工测试,而是让应用本身对 Codex 可读。应用支持按 git worktree 启动独立实例(之前聊过 Claude Code 的 worktree并行模式,思路一脉相承),再把 Chrome DevTools Protocol 接进 Agent 运行时。这样 Codex 就能直接操作页面、抓 DOM、截图、导航、观察运行时行为。
Agent 不再只是“生成代码的人”,而开始接手一部分原本由测试和前端联调兜底的工作。
很多“AI 写前端”的演示到这里就停了——能吐组件,但没法稳定验证 UI 行为。
OpenAI 这张图展示的恰恰是另一层:让 Agent 不只生成,还能自证。
图 2 讲的是:光会看界面还不够,还得看见系统内部
第二张图对应的是原文里的 observability 部分。
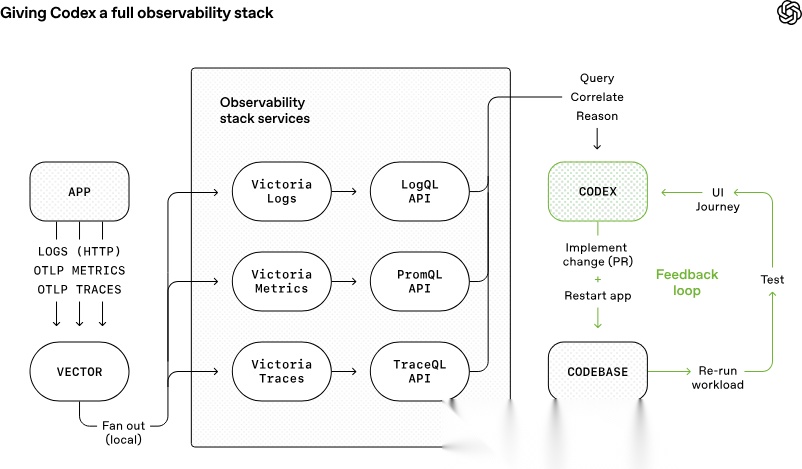
图里其实有两条线。
左边那条线,是应用把日志、指标、链路数据送到 Vector,再分发到 Victoria Logs、Victoria Metrics、Victoria Traces。
右边那条线,是 Codex 去查这些数据,做关联分析,改代码,重启应用,重跑 workload,再回到测试,形成反馈回路。
它把“Agent 怎么调系统”说得很具体。
过去工程师排问题,一般会看三类信号:
- • Logs
- • Metrics
- • Traces
OpenAI 做的事情,是把这三类信号直接开放给 Agent。于是像“确保服务在 800ms 内启动完成”“四条关键用户旅程里的 span 都不能超过两秒”这种要求,才变得可执行。
注意区别——这已经不是“帮我优化一下性能”这种泛指令了,而是把目标压成了 Agent 能查询、能对比、能迭代验证的工程任务。
原文还提到一个细节:这套可观测性栈是 ephemeral 的,也就是跟 worktree 绑定,任务结束后日志和指标一起销毁。
这说明他们在做的不是单点 demo,而是一套面向日常开发循环的本地基础设施。
这一段真正值钱的地方在于:OpenAI 没有把 Agent 当成更强的代码补全,而是把它当成一个需要观测面、验证面和执行面的开发参与者。
顺带提一句,原文说他们"经常看到单次 Codex 运行在单个任务上持续工作超过六个小时"——而且通常是在人类睡觉的时候。
这意味着开发流程已经不再是朝九晚五的线性过程,而是 7×24 的持续循环。
插一段:Ralph Wiggum Loop——Agent 怎么推 PR 到底
原文里有一个被很多解读忽略的工作流细节,叫 Ralph Wiggum Loop。
人类工程师几乎完全通过 Prompt 与系统交互:描述任务,启动 Agent,让它开 PR。
然后 Codex 会进入一个自我驱动的循环:
- 在本地对自己的改动做自审
- 请求其他 Agent(本地和云端)做专项 review
- 对人类或 Agent 给出的反馈做回应
- 继续改,继续审,直到所有 reviewer 满意
人类可以参与 PR review,但不是必须。原文说,随着项目推进,几乎所有 review 工作都已经变成了 Agent 对 Agent。
这件事的意义不在于"省了多少 review 时间",而在于它说明了一个新现实:
当 Agent 的吞吐量远超人类的注意力带宽时,人对人的 review 模式本身就会成为瓶颈。
所以 OpenAI 不是在偷懒,而是在解决一个结构性的效率矛盾。
图 3 讲的是:Codex 看不见的东西,就等于不存在
第三张图大概是整篇文章里最该认真看的一张。
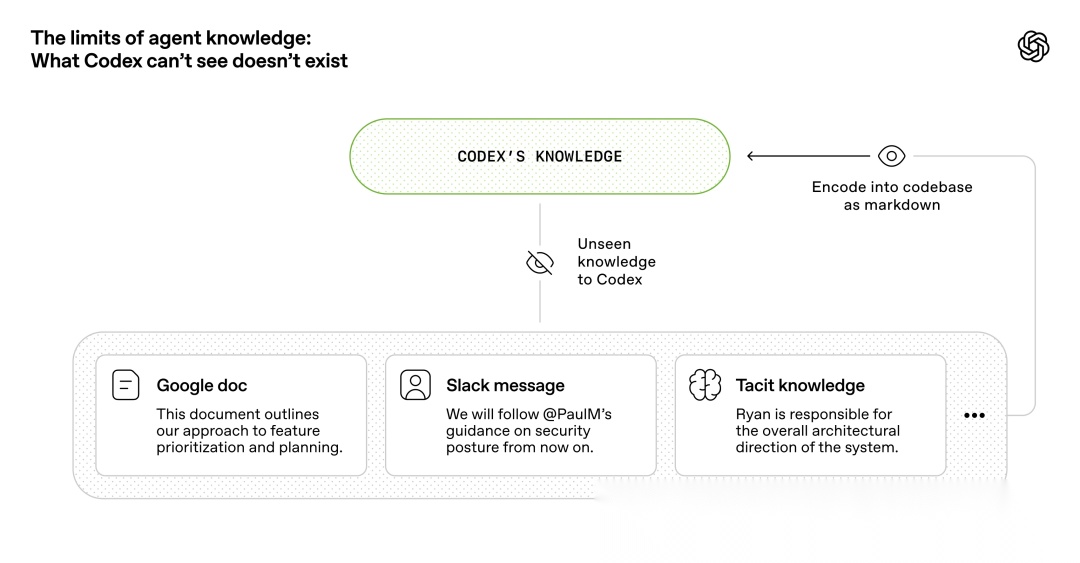
图很简单。
上面是 Codex 的知识边界。
下面是 Google Docs、Slack 消息、隐性经验这些“它看不见的东西”。
右边那条箭头写得更直白:要让它看见,就得 encode into codebase as markdown。
原文在这一段给了一个很硬的判断:
给 Codex 的应该是一张地图,而不是一本 1000 页说明书。
背后有两层意思。
第一层,是大而全的 AGENTS.md 不行。
原因很现实:
- • 上下文窗口是稀缺资源
- • 什么都重要,等于什么都不重要
- • 超大文档很快腐烂
- • 单个大文件难以机械校验
第二层,是知识必须变成仓库内、版本化、可链接、可维护的工件。
所以 OpenAI 后来怎么做?
- • 用一个大约 100 行的
AGENTS.md当目录 - • 把设计文档、产品规范、执行计划、技术债记录、参考材料放进结构化
docs/ - • 用 linter 和 CI 校验这些知识是不是新鲜、是不是交叉链接、是不是结构正确
- • 用一个 recurring 的 doc-gardening agent 去扫过期文档,再发修复 PR
原文把这种设计叫做 progressive disclosure(渐进式披露):Agent 从一个小而稳定的入口点开始,被教会下一步该去哪里找更深的信息,而不是一上来就被淹没。
另外一个容易忽略的细节:原文提到他们在技术选型上刻意偏向“boring”技术——那些文档齐全、API 稳定、在训练集里有大量表征的技术。有时候甚至宁可让 Agent 重新实现一个功能子集,也不要引入一个对 Agent 来说不透明的第三方库。比如他们没有用通用的 p-limit 并发控制包,而是让 Codex 自己实现了一个专属的并发映射工具,100% 测试覆盖,和 OpenTelemetry 深度集成。
逻辑很简单:对 Agent 来说,“能完全理解”比“功能更强”重要得多。
说实话,这一段比“0 行手写代码”更颠覆。它把一件事说透了:
以前知识不落库,代价可能只是新人上手慢一点;到了 Agent 时代,知识不落库,代价会变成系统性失明。
图 4 讲的是:有了 Agent 之后,架构约束反而要更早、更硬
第四张图对应的是原文的 “Enforcing architecture and taste”。
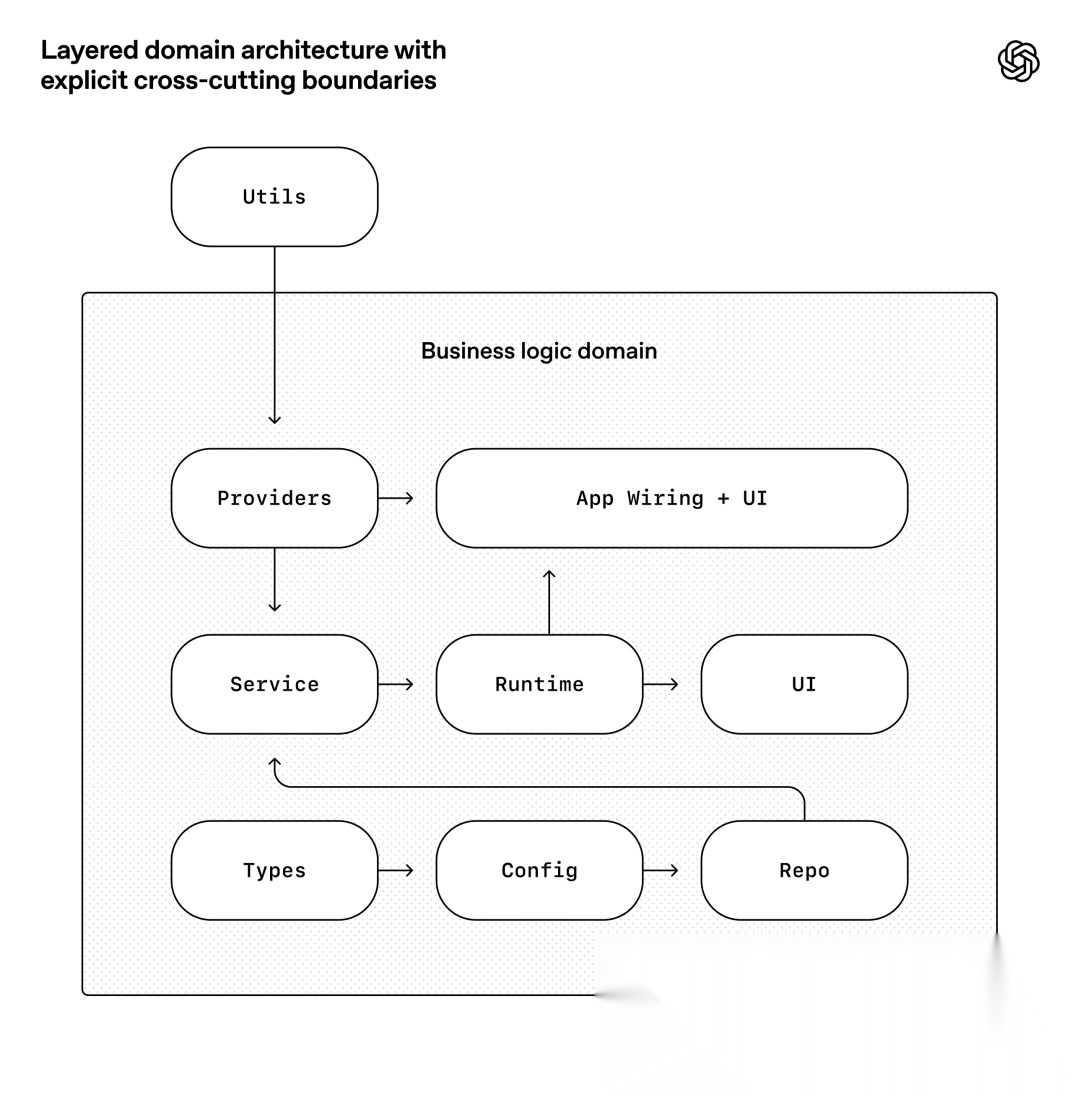
、
这张图的信息量很大,但核心只有一句:
OpenAI 不是因为有了 Agent,才把架构做松;恰恰相反,他们把架构做得更硬了。
图里可以看到,他们把业务域切成固定层:
- • Types
- • Config
- • Repo
- • Service
- • Runtime
- • UI
横切能力,比如 auth、connectors、telemetry、feature flags,不允许到处乱进,而是通过一个明确的 Providers 接口进入。
原文直接说,很多团队通常要到“几百个工程师”的阶段,才会认真上这种强约束架构;但对 coding agents 来说,这反而是早期前提。
因为 Agent 最擅长的不是在无限开放的空间里凭空悟出你的系统边界,而是在边界清晰、依赖方向固定、错误可以机械发现的环境里高速工作。
原文这段还提到了一个很细的词:taste invariants。
可以理解为“品味不变量”。
OpenAI 把很多原本要靠资深工程师口头传授的东西,写成了自定义 lint 和结构测试,比如:
- • 结构化日志
- • schema 和 type 的命名约定
- • 文件大小限制
- • 平台可靠性要求
甚至连报错信息都带修复指引,目的是让 Agent 在失败时,不只是知道“这里不对”,还知道“应该怎样改对”。
这件事特别像平台工程,只不过服务对象从人类开发者扩展到了 Agent。原文没有把“自由生成”浪漫化,而是明确站在了“刚性边界 + 本地自治”这一侧。
还有两段话,让这篇文章不是宣传稿
光看四张图,你可能觉得 OpenAI 在讲“如何让 Agent 更强”。但原文还有两段话,味道不太一样。
1|吞吐量改变了合并哲学
原文说,随着 Codex 吞吐量提升,很多传统工程规范开始变得适得其反。
他们的仓库尽量减少阻塞式 merge gate,PR 生命周期很短,偶发测试失败更多靠后续重跑解决,而不是无限期卡住进度。
原因很简单:
在一个 Agent 吞吐量远高于人类注意力的系统里,纠错成本低,等待成本高。
这不是通用真理,但它准确描述了 Agent-first 环境下的一个新取舍。很多团队今天讨论 AI coding,还停留在“模型能力变强了没有”,但真正的组织冲击其实发生在 review、merge、QA、回归、技术债治理这些后半段流程。之前拆 Anthropic 那份[2026 Agentic Coding 趋势]报告时就提过,“编排与协作”会比“生成能力”更早成为瓶颈——OpenAI 这篇文章算是从实践端验证了那个判断。
2|熵与垃圾回收
原文最坦诚的一段,是最后的 entropy and garbage collection。
OpenAI 直接承认,完全自主的 Agent 会复制仓库里已有的模式,好的坏的都会复制。时间一长,一定会漂移。
他们最开始怎么处理?
每周五花 20% 的时间清理 “AI slop”。
后来发现这完全不具备扩展性,于是把“黄金原则”(golden principles)直接编码进仓库。
原文给了两个具体例子:
- • 优先使用共享工具包,而不是到处手写 helper,让约束集中化
- • 不要“猜着写”(原文叫 YOLO-style probing),要么在边界验证数据形状,要么依赖类型化 SDK
然后让后台 Codex 任务定期扫描偏差、更新质量等级、发起针对性重构 PR。这些 PR 大部分一分钟内就能审完,自动合并。
这个比喻也很准确:垃圾回收。
技术债如果不断小额偿还,代价可控;如果任由它滚起来,最后会变成高利贷。
OpenAI 没有说“Agent 写出来的代码天然更好”。他们说的是:要想让 Agent 写出来的系统长期还能用,得持续做规则编码和偏差回收。
原文还藏了一张能力清单:Agent 现在到底能自主做到什么程度
很多解读只讲了四张图,但原文还有一段很硬的描述——Codex 现在已经能端到端跑完的完整流程。
给定一个 Prompt,Agent 现在可以:
- 验证代码库的当前状态
- 复现一个已上报的 Bug
- 录制一段演示故障的视频
- 实现修复
- 通过驱动应用来验证修复
- 录制第二段视频,演示问题已解决
- 开一个 PR
- 回应 Agent 和人类的反馈
- 检测并修复构建失败
- 只在需要人类判断时才上报
- 合并改动
请注意,这不是一个"未来展望",原文用的是现在时态。
但 OpenAI 也很克制地加了一句:这套行为高度依赖这个特定仓库的结构和工具链,不应假设它可以不经类似投入就直接复制到别的项目。
这大概是全文最诚实的注脚之一。
换个角度:Harness Engineering 本质上是控制论
拆完工程细节,退一步看看更大的图。
有一篇很精彩的评论文章把 Harness Engineering 直接定位为 控制论(Cybernetics)的最新实例。
控制论这个词来自希腊语 κυβερνήτης,意思是"舵手"。诺伯特·维纳在 1948 年就提出了这个概念。
这篇评论指出,这个模式在历史上出现过三次:
- 18 世纪的瓦特离心式调速器:工人不再亲手拧阀门,而是设计一个能自动感知转速并调节阀门的机械装置。
- Kubernetes 的声明式控制器:你声明期望状态,控制器持续观察实际状态,偏差出现时自动协调。
- 现在的 Harness Engineering:工程师不再写代码,而是设计环境、构建反馈回路、将架构约束编成规则,由 Agent 来执行。
三次,同一个模式:人的角色从执行者变成系统的设计者和校准者。
文章还有一个判断很到位:
智能体失败不是因为能力不够,而是因为它需要的知识——什么叫"好"、你的架构鼓励哪些模式、回避哪些模式——锁在你脑子里,你从没把它外化出来。
换句话说,Harness Engineering 要求你做的那些事——文档、测试、编码化的架构决策、快速反馈回路——一直都是正确的。过去三十年的软件工程书都在推荐。大多数人跳过了,因为跳过的代价是缓慢而弥散的。
但到了 Agent 时代,跳过的代价变得即时且剧烈:Agent 会以机器的速度,全天候地复制你的每一个坏习惯。
收一收:原文真正留下来的三个判断
看完全文,OpenAI 真正说的不是“以后都别写代码了”,而是三件事。
第一,软件工程的纪律没有消失,只是从代码层,前移到了脚手架层。
原文最后一句说得很清楚:最难的挑战正在集中到 designing environments, feedback loops, and control systems。
纪律还在,甚至更重了。只是它更多体现在环境、工具、抽象和反馈回路上,而不是代码风格。
第二,Agent-first 工程的前提不是更强的模型,而是更强的仓库。
仓库必须是知识系统,是规则系统,是验证系统,也是回收系统。
如果你的仓库本来就缺文档、缺测试、缺边界、缺计划,那 Agent 只会更快复制混乱。
第三,人类并没有退出环路,只是站到了更上游的抽象层。
原文没有说 human disappears,它说的是 humans steer。
人类仍然在:
- • 设优先级
- • 把用户反馈翻译成验收标准
- • 判断哪里需要规则、哪里需要工具、哪里需要升级约束
- • 在确实需要 judgment 的地方接管
跟“以后只要会提需求就够了”完全不是一回事。
想抄 OpenAI?先从这 6 件事开始
原文不是让普通团队今天就去追“0 行人工代码”。更现实的做法是:
- 先把知识搬进仓库,把口头约定、聊天结论、关键设计决策沉到 Markdown、计划、schema 和规则里。
- 把
AGENTS.md写短,写成目录,不要写成百科全书。 - 给核心任务补可机械验证的反馈面:测试、lint、类型检查、结构校验、必要的 UI 验证。
- 把日志、指标、链路这些排障信号尽可能暴露给 Agent,而不是只暴露给人。
- 把架构边界和代码品味编码成规则,不要全靠 senior review 兜底。
- 建立持续回收机制,别让 Agent 把坏模式复制几百次以后才统一清理。
先把这些做好,再谈更高自治。不然“让 Agent 多做一点”大概率只会变成“让系统更快失控一点”。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)