”!DataChef 开源: 用强化学习自动生成 LLM 数据配方
大模型时代迈入 Scaling Law 深水区,数据越来越决定模型能力上限。然而,当前的“数据工程”依然高度依赖人工经验:“该选哪些数据?比例怎么配?要不要重写?如何过滤与验证?”
近日,上海人工智能实验室联合复旦大学正式推出并开源了 DataChef,一个面向大模型适配任务 (LLM Adaptation) 的数据配方 (Data Recipe) 生成模型。DataChef 首次将端到端数据配方生成建模为一个全局决策问题,并通过在线强化学习 (Online RL) 形成自动优化闭环。只需输入目标任务,AI 就能自动生成完整、可执行的数据处理代码与数据配方。
实验显示,在 6 个 held-out 测试任务 (物理、数学、代码、金融、气象、中文成语) 中,DataChef-32B 数据配方生成能力已逼近闭源顶级模型 Gemini-3-Pro,其生成的数据配方不仅超越了 DEITA 等人类专家设计的 SOTA 筛选算法,更在部分复杂任务上达到了工业级专家数据配方的水平。
相关代码、数据与模型现已开源,欢迎体验探索!
Github 链接: https://github.com/yichengchen24/DataChef
HuggingFace 链接: https://huggingface.co/yichengchen24/DataChef-32B
Paper 链接: https://arxiv.org/abs/2602.11089
Demo 链接: https://huggingface.co/spaces/yichengchen24/DataChef
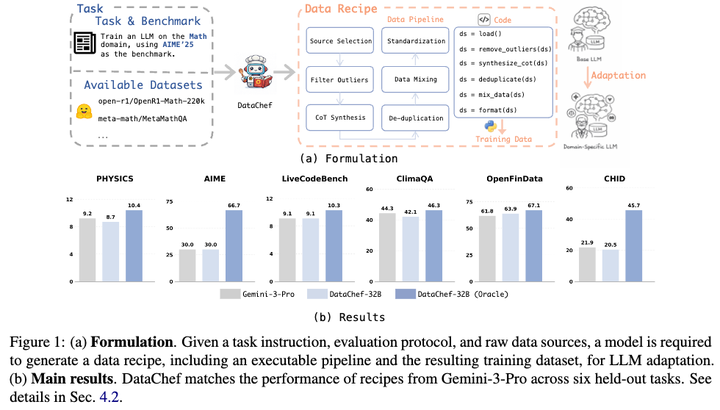
(a) 范式定义: 给定一个任务描述 (训练一个 LLM,使其适配到数学领域),评测标准 (AIME'25),可用的原始数据集 (一个 数学相关的 Huggingface 的数据集列表),模型输出数据配方,包括可以执行的数据处理管线以及得到的训练数据,用于适配 Base LLM 到目标领域
(b) 主要结果: 在 6 个 held-out 测试任务 (PHYSICS, AIME, LiveCodeBench, ClimaQA, OpenFinData, and CHID) 中,DataChef 数据配方生成能力已逼近闭源顶级模型 Gemini-3-Pro
核心突破:把“数据炼丹”变成可进化的自动化系统
传统数据工程面临着三大难题:
-
重度依赖专家经验:数据选择、配比与清洗规则,往往依靠人工反复试错(Trial and error)。
-
效果验证成本极高:想评估一套数据配方的好坏,通常需要跑完昂贵的模型训练才能看到结果。
-
搜索空间无限爆炸:多数据源 × 多处理算子 × 多任务目标的组合,人工根本无法进行高效遍历。
针对这些行业瓶颈,DataChef 给出了全新的破局解法。
范式创新:首次定义端到端数据配方生成
DataChef 跳出了传统的局部启发式规则,将“数据配方生成”提升为端到端任务。模型只需接收目标基准(Benchmark)与可用数据源作为输入,就能直接输出完整的 Python 数据处理流水线代码,真正实现“所想即所得”。
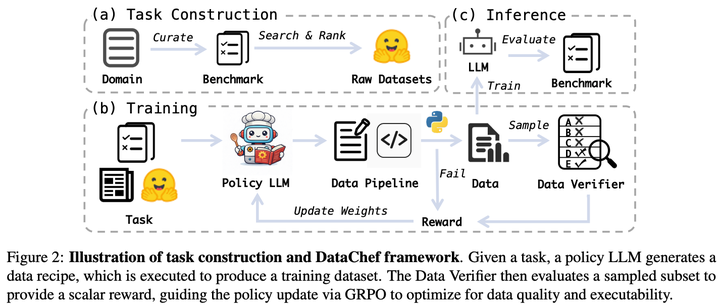
范式: 给定一个任务描述,评测标准,可用的原始数据集,模型输出数据配方,包括可以执行的数据处理管线以及得到的训练数据。在训练过程中,代码的可执行性和数据的质量作为 Reward。在推理过程中,得到的训练数据直接用于 LLM 适配。
基础设施:构建海量多领域数据集
为了支撑这一全新范式,研究团队构建了庞大的数据基座:覆盖数学、代码、金融、医学等 19 个核心领域,包含 31 个评测集以及 257 个源数据集,为开源社区提供了系统化的训练与评测基础设施。
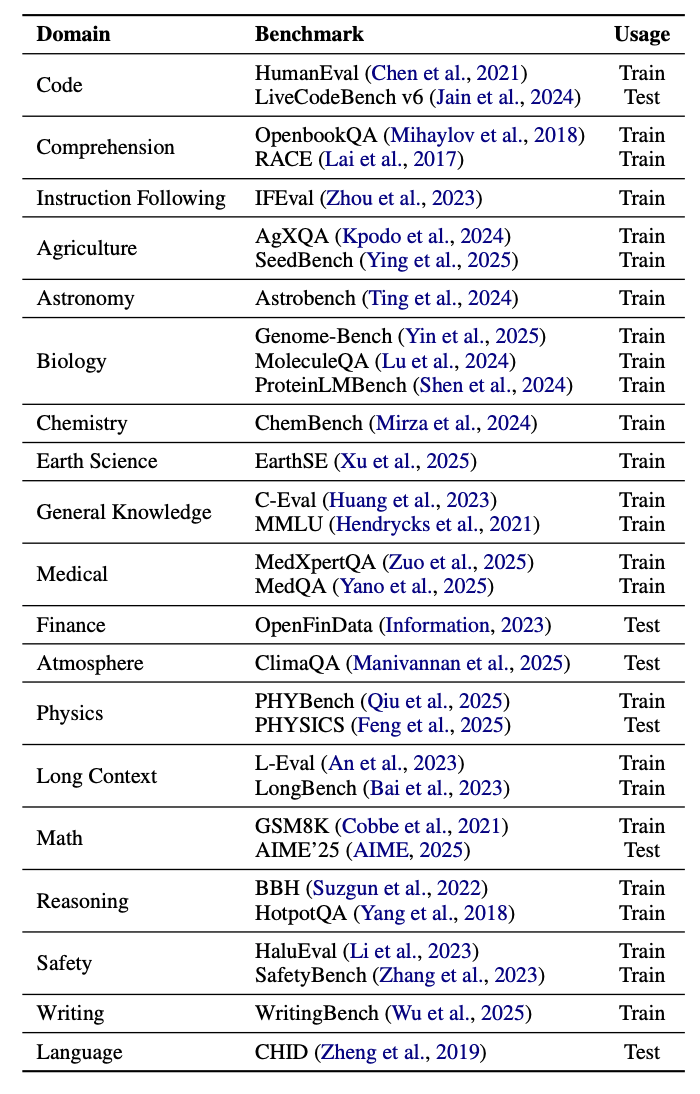
数据集概览: 详细展示领域信息,benchmark 和具体用途
机制进化:在线强化学习驱动 AI 自我进化
研究团队引入了 Data Verifier(数据验证器)机制,它能低成本、实时地预测数据在下游任务上的表现,并以此作为强化学习的“奖励(Reward)”信号。这使得模型能在庞大的代码组合空间中快速探索,彻底解决了传统方案“训练反馈周期长、试错成本昂贵”的致命痛点。
实验证明,Data Verifier 相比传统数据评价指标 (IFD, RewardModel, VendiScore),具备更卓越的相关性与鲁棒性。
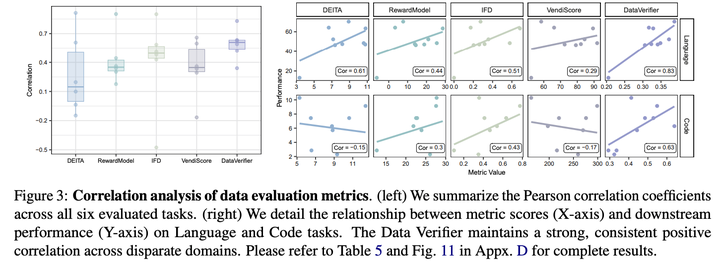
数据评价指标相关性分析: 相比于 DEITA、RewardModel、IFD、VendiScore 等现有方法,Data Verifier 展现出了更显著的相关性与鲁棒性。(左) 6 个评测任务上相关性系数箱线图;(右) 语言与代码任务中,各指标得分与下游实际表现的相关性散点图。
开源小模型,展现越级战斗力
效果接近 Gemini-3-Pro
在多项严苛的测试中,仅有 32B 参数的 DataChef 展现出了极强的鲁棒性与有效性,其整体表现已接近闭源顶级模型 Gemini-3-Pro 的水准。具体来说,在 In-domain 与 Out-of-domain 的平均得分上,DataChef-32B 分别斩获 89.3 和 75.4 高分,超过 1T 参数的开源模型 Kimi-K2-Instruct-0905 (83.7 / 58.2),比肩 Gemini-3-Pro (91.2 / 76.6)。
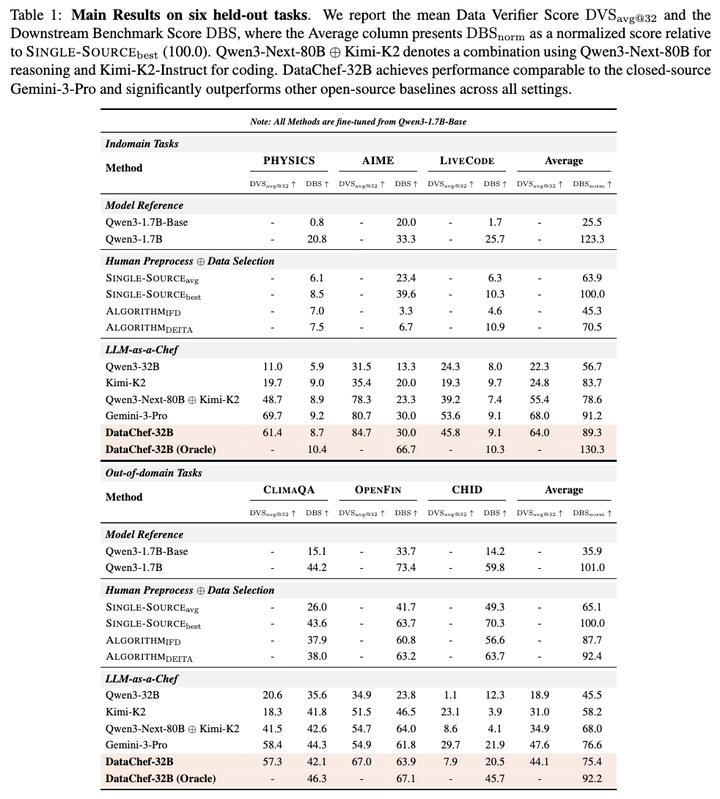
在 6 个 held-out 测试任务上的主实验结果: 无论是在 In-domain 还是 Out-of-domain 任务中,DataChef-32B 均展现出了卓越的数据配方生成能力。其整体表现逼近了闭源顶级模型 Gemini-3-Pro 的水准。
超越人类专家数据配方
DataChef 不再局限于从已有数据中挑最好的子集,而是通过自动生成任意代码构建全新的处理逻辑。
-
超越人工启发式数据筛选 SOTA: 相比于 SINGLE-SOURCE、IFD、DEITA 等传统数据选择方法,DataChef 取得了极具竞争力的表现。
-
击败工业配方: 在极具挑战性的 AIME’25 和 ClimaQA 评测基准上,DataChef-32B 产出的数据配方,甚至超越了 Qwen 官方后训练模型所采用的工业级专家配方!
这证明了 AI 完全有能力在大规模代码空间中,学到更优的数据方案。
真实 Case 还原自动化管线
以 ClimaQA 任务为例,DataChef 能够精准洞察目标需求,自动生成高效的数据处理管线:
-
智能数据增强:自动调用 LLM 进行任务特定格式的样本合成与增强,定点拔高模型目标能力;
-
精准特征提取:通过自生成关键词逻辑,抽取最匹配、最相关的数据子集,大幅提升数据有效性。


Case Study: DataChef 在 ClimaQA 任务中生成数据处理管线
总结
DataChef 的出现,首次将端到端数据配方生成建模为可优化的全局决策任务。这标志着大模型数据工程正告别高度依赖人工经验的“手工作坊”时代,迈向自动化、规模化与智能化的工业化新范式。随着相关能力的全面开源,DataChef 将为自动化数据工程、LLM 前沿训练、自动化 AI 研究(Automated AI Research)及自我进化 AI(Self-evolving AI)等领域提供极具价值的新思路与工具支撑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)