一文搞懂训练大模型的数据怎么存储!
在大模型时代,AI 的训练与推理已经不再是单纯的算力问题。随着模型参数规模进入百亿级、数据量级扩展到 TB~PB,数据管线与存储架构往往成为影响训练速度的决定性因素。算力再强,如果数据加载跟不上,也会出现 GPU 空闲等待 I/O 的情况,训练效率大打折扣。
1. 分层存储与数据组织
在实际落地中,数据通常采用“热、温、冷”三层架构。
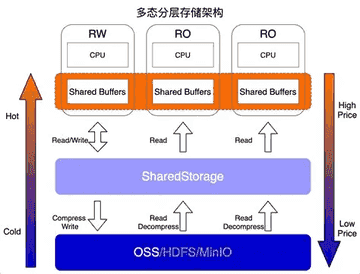
Hot 层存放的是训练时活跃的数据和索引,对 IOPS 和吞吐有极高要求,常见部署方式是本地 NVMe 或高性能分布式文件系统;Warm 层承担团队共享和版本管理,一般使用对象存储(如 Ceph、MinIO)或分布式文件系统;Cold 层则存放历史快照、原始数据和中间产物,用于后续再加工或追溯。
这样的分层方式既能保证训练高效运行,又能合理控制存储成本。
在文件格式上,顺序可流式读取的容器化分片是主流选择,如 WebDataset(tar 分片)、TFRecord、Parquet 或 LMDB。合理的分片大小(通常在 100MB~2GB 之间)既能降低元数据开销,又能兼顾网络带宽与节点内存。为了支持可重复、可恢复训练,还需要建立样本级索引和全局 shuffle map。数据清洗与去重同样重要,文本可以使用 MinHash/SimHash,图像可用感知哈希,避免无效数据放大。
数据的版本管理也不可忽视。通过打标签和语义化版本号(如 imagenet-1.0.3),配合 DVC 或 LakeFS 等工具,可以让“数据—代码—模型”保持一致性和可追溯性。
2. 预处理与增广:离线 vs 在线
预处理和数据增强是训练效率的另一大关键。一个普遍的原则是:能离线就离线。
离线阶段适合完成解码、标准化、分词、图像 resize 或裁剪等固定流程,这样能显著降低训练时的 CPU 压力,并保证数据吞吐稳定。其优势是吞吐高、复用性强,缺点是灵活性略差、存储空间消耗稍多。
而在线处理则更适合需要随机性或多样化的增强手段,比如随机裁剪、颜色抖动、MixUp/CutMix、SpecAugment 等。这类操作对模型泛化能力帮助明显,且往往轻量、可矢量化,因此保留在 DataLoader 阶段即可。
对于 NLP,可以提前完成分词、分块,生成按上下文长度拼接的 packed samples;对于图像或视频,可以提前建立帧索引和 clip manifest,实现训练时的零拷贝读取。
3. 缓存策略
为了避免 GPU 因 I/O 停摆,缓存设计至关重要。
在本地机器层面,可以充分利用 Page Cache 和 mmap,大块顺序读能极大提升缓存命中率;
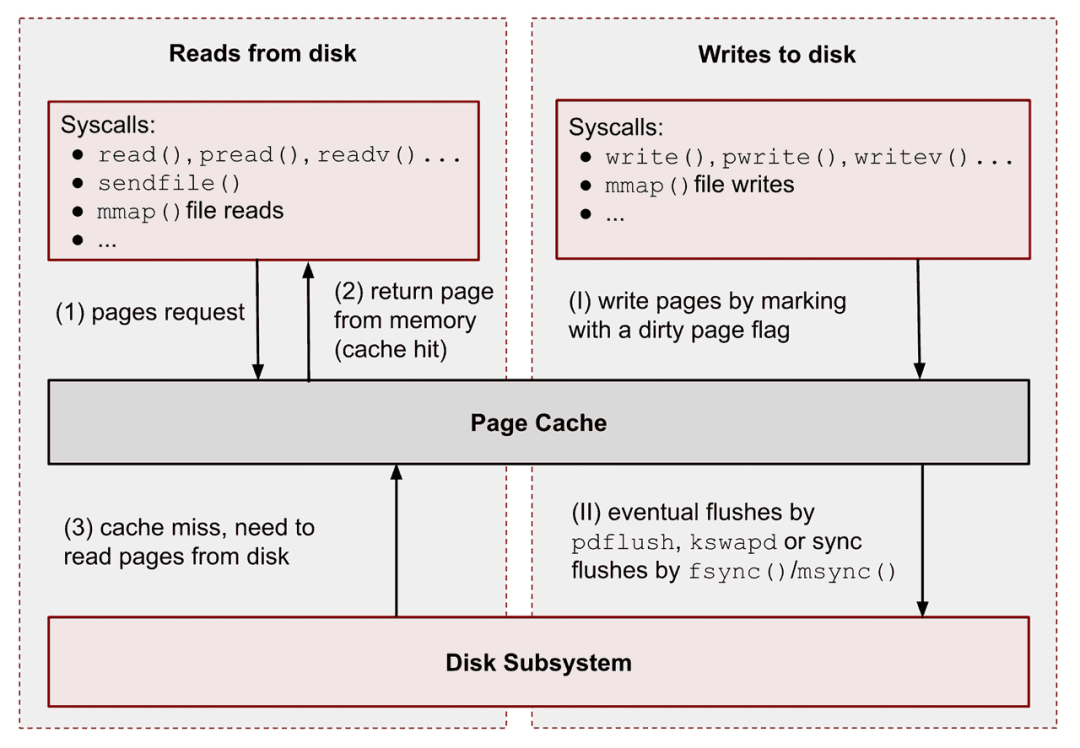
同时,将对象存储中的分片预拉取到本地 NVMe,作为短期缓存使用,也能明显提升首轮训练效率。常见做法是训练前做 warm-up,提前拉取头几个 epoch 所需数据,避免初期吞吐波动。
在集群层面,可以部署 Redis、RocksDB 或 Alluxio 作为热点数据和索引的共享缓存层。缓存一致性可通过数据版本号来管理,训练任务完成后再异步清理或逐版本淘汰,保证资源利用率。
一个小技巧是尽量使用顺序读和大批量 prefetch,而不是频繁的小块随机 I/O,这对分布式训练尤其重要。
4. 加速数据加载与管线并行
除了存储与缓存,数据加载和训练管线的并行优化同样重要。
在 PyTorch 中,可以通过调整 DataLoader 参数来提升效率:合理设置 num_workers(通常为 CPU 核数的一半到等于核数)、开启 pin_memory 与 prefetch_factor,并启用持久化 worker 避免频繁 fork。此外,结合 non_blocking=True 和混合精度训练,还能让计算与 HtoD 拷贝并行,减少等待。
loader = torch.utils.data.DataLoader( dataset, batch_size=global_bs_per_rank, num_workers=os.cpu_count() // 2, pin_memory=True, prefetch_factor=4, persistent_workers=True, shuffle=False,)
在 TensorFlow 中,tf.data 的自动调优功能可以简化并行与预取配置。
ds = (tf.data.TFRecordDataset(files, num_parallel_reads=tf.data.AUTOTUNE) .map(parse_fn, num_parallel_calls=tf.data.AUTOTUNE) .shuffle(buffer_size=1<<16, reshuffle_each_iteration=True) .batch(batch_size, drop_remainder=True) .prefetch(tf.data.AUTOTUNE))
对于远程对象存储,推荐配合 fsspec/s3fs/gcsfs 等工具,结合分片大对象和范围读取,避免频繁小文件访问。WebDataset 或 Hugging Face Datasets 的流式模式,也能很好地缓解本地存储压力。
另外,大模型训练常常采用 packed samples 技术,将多个短序列拼接为接近目标上下文长度的长序列,提高 GPU/TPU 的利用率。跨 epoch 时,通过多份 shuffle map 保证随机性与可复现性。
- 网络与调度
最后,网络与调度层面对训练吞吐的影响不容忽视。拓扑感知调度可以让训练节点尽量靠近数据存储网关,减少跨机架或跨可用区的延迟和费用。高速互联(如 RDMA、InfiniBand、RoCE)则能保证梯度通信和数据 I/O 不相互抢占带宽。
在做带宽预算时,可以先估算公式:每 GPU 样本大小 × QPS × 节点数,并预留 20%~30% 的余量。如果发现瓶颈,可以在数据入口增加节流与回压机制,防止集群过载。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)