基于高通跃龙IQ-9100的图像检测半自动化标注系统搭建实践(1): 系统背景、架构设计与模型选型
💡摘要
在计算机视觉项目中,高质量的标注数据是模型训练的基石,但传统的人工标注方式存在成本高、效率低、一致性差等痛点。本文介绍了一种基于高通跃龙IQ-9100边缘计算平台搭建的半自动化图像检测标注系统。该系统利用跃龙IQ-9100强大的100 TOPS NPU算力,在边缘端部署轻量化目标检测模型(YOLOv8-Nano)与分割辅助模型(EdgeSAM),实现“机器预标注 + 人工精修”的高效标注工作流。实测结果表明,相较于纯人工标注,该系统将标注效率提升了3~5倍,同时保持了95%以上的标注精度,为工业质检、安防监控等场景下的数据闭环建设提供了可落地的边缘解决方案。
1. 引言:为什么需要边缘端的半自动化标注?
1.1 数据标注的困境
深度学习模型的性能高度依赖于训练数据的规模和质量。在目标检测领域,一个典型的工业质检项目往往需要数万甚至数十万张标注图像。传统的纯人工标注面临三大核心挑战:
- 成本高昂:专业标注人员的人力成本持续上升,单张图像的多目标标注耗时2~5分钟,大规模数据集的标注周期可达数月。
- 质量波动:人工标注受疲劳、主观判断等因素影响,不同标注员之间的一致性(Inter-Annotator Agreement)往往不理想,IoU偏差可达10%~20%。
- 数据孤岛:在工厂产线、户外监控等场景中,原始图像数据量巨大,上传至云端标注面临带宽瓶颈和数据安全隐患。
1.2 边缘标注的价值主张
将标注系统部署到数据产生的源头——边缘设备上,能够实现“数据就地处理”的闭环。边缘端半自动化标注的核心思路是:利用已有的预训练模型或迭代训练的检测模型,在边缘设备上进行实时推理,自动生成初始标注结果(预标注),然后由人工进行快速审核和修正,最终输出高质量的标注数据。这种方式的优势在于:
- 就近处理:数据不出场,满足数据安全和隐私合规要求。
- 效率倍增:人工只需“审核+微调”而非“从零标注”,效率提升3~5倍。
- 持续迭代:标注数据可直接用于边缘端模型的增量训练,形成“标注 → 训练 → 部署 → 再标注”的正向循环。
1.3 为什么选择高通跃龙IQ-9100?
高通跃龙IQ-9100是高通面向工业机器人、智能视觉和边缘AI盒子推出的旗舰级边缘计算平台。它具备以下使其成为半自动化标注系统理想载体的关键特性:
- 100 TOPS NPU算力:Hexagon张量处理器提供高达100 INT8 TOPS的密集算力,可同时运行检测模型和分割辅助模型。
- 强大的ISP与多路摄像头支持:最高支持16路摄像头(4-lane CSI-2),适用于多工位、多视角的工业场景。
- 高性能CPU/GPU:八核Kryo Gold Prime @ 2.36GHz CPU与Adreno GPU,为标注界面渲染和数据预处理提供充足算力。
- 完善的AI工具链:支持Qualcomm AI Runtime(QAIRT/QNN)和SNPE,提供从PyTorch/ONNX到边缘部署的完整工具链。
- 工业级可靠性:SIL3安全岛、宽温工作范围,满足工业部署的严苛要求。
| 特性 | IQ-9100 | 某平台 | 优势对比 |
|---|---|---|---|
| NPU算力 | 100 TOPS (INT8) | 100 TOPS (INT8/Sparse) | NPU算力对等,密集算力持平 |
| CPU | 8核 Kryo @ 2.36GHz | 8核 Arm Cortex-A78AE | Kryo架构单核性能更优 |
| 摄像头支持 | 最多16路 | 最多6路(CSI) | IQ-9100多路支持更强 |
| 功耗 | ~15W TDP | 10~25W | 功耗控制更精细 |
| 安全等级 | SIL3安全岛 | 功能安全可选 | IQ-9100原生工业安全 |
| AI工具链 | QAIRT/QNN/SNPE | TensorRT/CUDA | 两者均成熟完善 |
2. 系统架构设计
2.1 整体架构概览
本系统采用分层架构设计,从底到顶分为硬件层、推理引擎层、标注服务层和交互层四个层次。各层职责明确、接口清晰,便于独立开发和迭代升级。
整体数据流如下:
- 图像采集 → 预处理 → AI推理(检测+分割) → 预标注生成 → 人工审核/修正 → 标注导出 → 模型增量训练
系统架构分层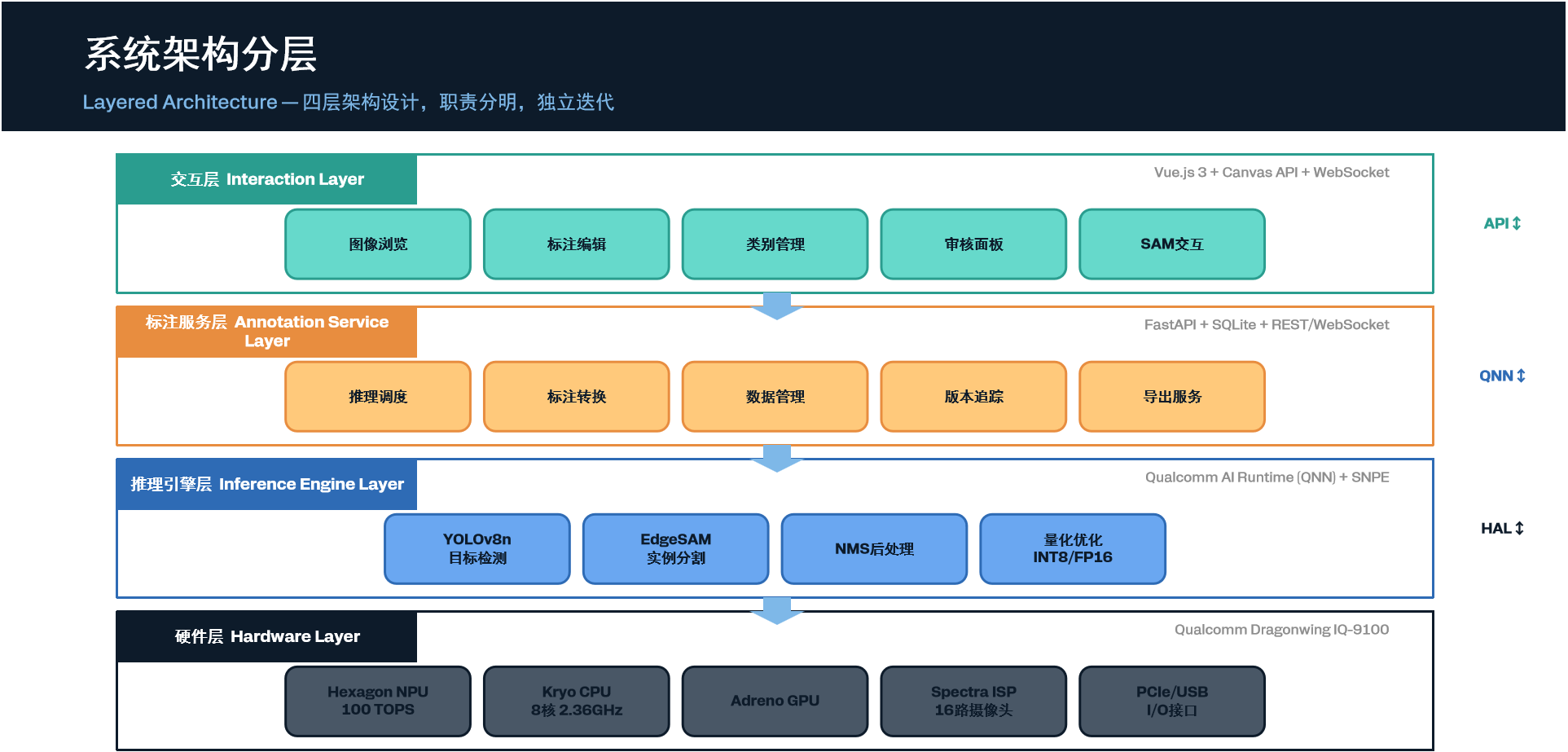
四层架构自顶向下:交互层负责人机交互,标注服务层负责业务逻辑,推理引擎层负责AI推理加速,硬件层提供算力基础。各层通过标准化接口通信,支持独立升级与替换。
- 硬件层(Hardware Layer):IQ-9100开发板 + 工业摄像头 + 本地存储。负责图像采集和算力供给。
- 推理引擎层(Inference Engine Layer):基于Qualcomm AI Runtime(QNN后端),运行YOLOv8n检测模型和EdgeSAM分割模型,输出检测框和实例掩码。
- 标注服务层(Annotation Service Layer):Python后端(FastAPI),负责推理结果后处理、标注格式转换(COCO/VOC/YOLO)、标注存储和版本管理。
- 交互层(Interaction Layer):基于Vue.js的Web前端标注界面,支持框选修正、类别切换、标注审核等操作,通过WebSocket与后端实时通信。
2.2 核心工作流详解
半自动化标注的核心是“AI预标注 + 人工精修”的协作流程。以下是单张图像的完整处理链路:
第一阶段:自动预标注
- 图像通过摄像头采集或批量导入后,首先经过ISP预处理(白平衡、去噪、畸变校正),调整为模型输入尺寸(640×640)。
- YOLOv8n检测模型在NPU上运行推理,输出目标的边界框(Bounding Box)、类别和置信度。推理延迟约8~12ms/帧。
- 对于置信度高于阈值(默认0.6)的检测结果,系统同时调用EdgeSAM模型,以检测框作为Prompt输入,生成精细的实例分割掩码。
- 将检测框、分割掩码、类别信息整合为预标注结果,写入标注数据库。
第二阶段:人工审核精修
- 标注员通过Web界面加载预标注结果,逐张或批量审核。
- 对于正确的标注,一键确认即可;对于有偏差的标注,可拖拽调整边界框、修改类别、补充遗漏目标。
- 系统记录每次人工修改的diff信息,用于后续分析模型薄弱环节和指导增量训练。
第三阶段:数据导出与模型迭代
- 审核完成的标注数据支持导出为COCO JSON、Pascal VOC XML、YOLO TXT等主流格式。
- 导出的数据可直接用于边缘端的增量微调训练,或上传至云端进行全量训练。
- 更新后的模型重新部署到IQ-9100,预标注精度进一步提升,形成正向循环。
2.3 系统全景视图
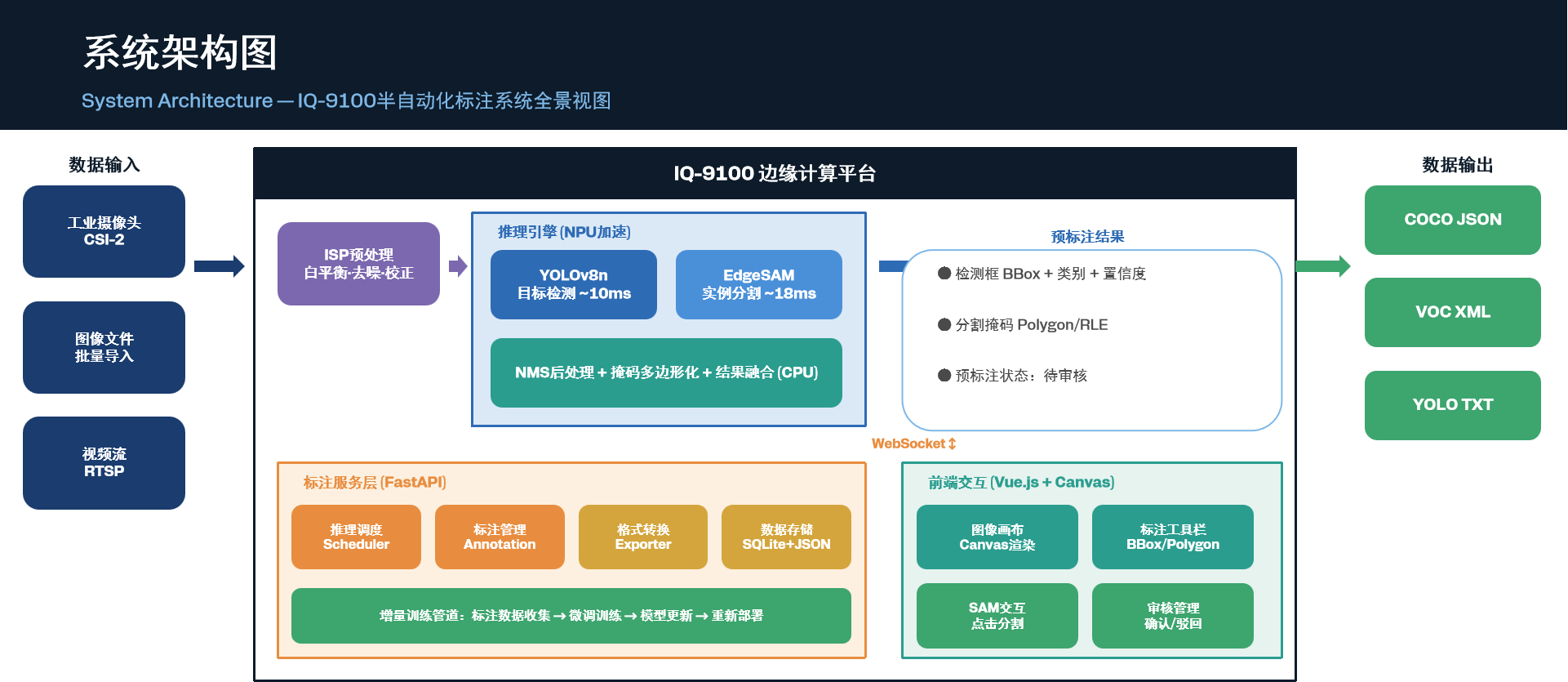
架构要点:
- 数据从左侧输入,经IQ-9100平台处理后从右侧输出标注结果;
- 推理引擎利用NPU加速,端到端延迟~42ms;
- 标注服务通过WebSocket与前端实时通信;
- 增量训练管道实现模型自进化闭环。
3. 模型选型与边缘部署优化
3.1 目标检测模型:YOLOv8-Nano
YOLOv8-Nano(YOLOv8n)是Ultralytics YOLO系列中最轻量的变体,参数量仅3.2M,FLOPs约8.7G,在保持较高检测精度的同时,非常适合边缘设备部署。选择YOLOv8n作为预标注的主检测模型,基于以下考量:
- 速度优先:预标注场景下,推理速度直接影响标注效率。YOLOv8n在IQ-9100 NPU上可实现80~120 FPS的推理速度,远超实时需求。
- 精度足够:预标注不要求完美精度(人工会修正),YOLOv8n在COCO数据集上的mAP@0.5约为37.3%,在特定领域微调后通常可达60%~80%。
- 灵活扩展:Ultralytics框架支持便捷的迁移学习和增量训练,适合“标注 → 训练 → 更新”的迭代闭环。
模型导出流程:
# 1. PyTorch → ONNX
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(format="onnx", imgsz=640, opset=13, simplify=True)
# 2. ONNX → QNN(使用QAIRT工具链)
# qnn-onnx-converter -i yolov8n.onnx -o yolov8n.cpp
# qnn-model-lib-generator -c yolov8n.cpp -b yolov8n.bin
# qnn-context-binary-generator --model yolov8n.bin \
# --backend libQnnHtp.so --output_dir ./qnn_model
3.2 分割辅助模型:EdgeSAM
Segment Anything Model(SAM)是Meta提出的通用分割基础模型,但原版SAM的ViT-H编码器参数量高达632M,无法直接在边缘设备上运行。EdgeSAM通过“Prompt-in-the-Loop”知识蒸馏技术,将SAM的ViT编码器蒸馏为轻量级的CNN架构(基于RepViT),在保持分割质量的同时实现了37倍加速。
EdgeSAM在本系统中的核心作用:
- 精细边界辅助:当YOLOv8n输出检测框后,以框坐标作为Prompt传入EdgeSAM,生成像素级实例掩码,为标注员提供精确的目标边界参考。
- 交互式分割:标注员可通过点击前景/背景点,交互式地调用EdgeSAM生成或修正分割掩码,实现精细标注。
- 边缘可运行:EdgeSAM编码器参数约5M,在IQ-9100 NPU上推理延迟约15~25ms,满足交互式标注的实时性要求。
| 模型 | 参数量 | 编码器延迟(IQ-9100 NPU) | 适用场景 |
|---|---|---|---|
| EdgeSAM | ~5M | 15~25ms | 边缘端实时分割辅助 |
3.3 模型量化与优化策略
为了充分利用IQ-9100 Hexagon NPU的INT8/INT16算力,模型部署前需要进行量化优化。本系统采用训练后量化(Post-Training Quantization, PTQ)结合量化感知训练(Quantization-Aware Training, QAT)的两阶段策略。
PTQ快速量化(首次部署):
- 使用QAIRT工具链对ONNX模型进行INT8量化,提供500~1000张校准集图像。
- 量化后模型大小缩减约4倍(YOLOv8n: 6.3MB → 1.6MB),推理速度提升2~3倍。
- 精度损失通常在1~2% mAP以内,对预标注精度影响可忽略。
QAT精细量化(迭代优化):
- 当PTQ量化导致某些类别精度显著下降时,采用QAT在训练过程中模拟量化误差。
- 使用已标注数据的子集(约10%~20%)进行几个epoch的微调,可恢复大部分精度损失。
# QAIRT量化命令示例
# qnn-onnx-converter \
# --input_network yolov8.onnx \
# --input_list calibration_list.txt \
# --act_bitwidth 8 \
# --weight_bitwidth 8 \
# --bias_bitwidth 32 \
# --use_per_channel_quantization
下篇预告
在系列文章的下篇中,我们将继续深入IQ-9100边缘部署实践,包括开发环境搭建、模型部署流水线、推理服务封装、标注系统功能实现、性能优化、实战效果与踩坑经验等内容,敬请期待。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)