HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment

一、研究背景与问题提出
1. 传统 CLIP 模型的成就与局限
CLIP 等跨模态对比学习模型通过将图像和文本投影到共享嵌入空间,在零样本分类、图像 - 文本检索中取得了优异表现,但存在核心短板:
- 把文本输入当作扁平、无结构的序列处理,忽略自然语言固有的多层级语义组合性;
- 受限于 77-token 长度约束,长文本易被截断,关键的属性、空间关系等语义信息丢失或纠缠;
- 无法处理语义层次(多粒度语义的表示与对齐)和语义单调性(更完整、信息更丰富的文本应与对应图像实现更强的对齐)两大语言本质属性。
2. 现有长文本视觉 - 语言模型的不足
现有 Long-CLIP、TULIP、FineLIP 等方法虽尝试扩展 CLIP 的长文本能力,但仍存在缺陷:
- 多通过修改视觉侧(下采样、裁剪)适配长文本,降低了视觉保真度;
- 依赖静态子短语、固定截断或手工分割提取语义,无法适应批次上下文的动态语义焦点变化;
- 未解决长文本的语义冗余和结构扩散问题,文本细节增加时对齐性能不稳定,甚至出现 “细节越多、对齐越差” 的现象;
- 缺乏显式的语义单调性约束,无法保证文本完整性与对齐强度的正相关。
3. 核心挑战
要建模语义层次和单调性,需解决两个关键问题:
- 如何动态、上下文自适应地分解长文本的多粒度语义组件,而非静态分割;
- 如何在无额外监督的情况下,让模型学习 “文本越完整,图像 - 文本对齐越强” 的语义单调性规律。
二、核心概念定义
论文明确了跨模态对比学习中两个未被充分探索的基础属性:
- 语义层次:模型能够表示并对齐不同语义粒度的文本描述(如从 “福特 F250 卡车” 的类别级描述,到 “白色、升高底盘、熏黑车窗的福特 F250” 的细粒度属性描述);
- 语义单调性:信息更完整、描述更丰富的文本,应与对应图像产生更强的跨模态对齐信号,是符合人类认知的视觉 - 语言对齐基本规律。
三、HiMo-CLIP 框架设计
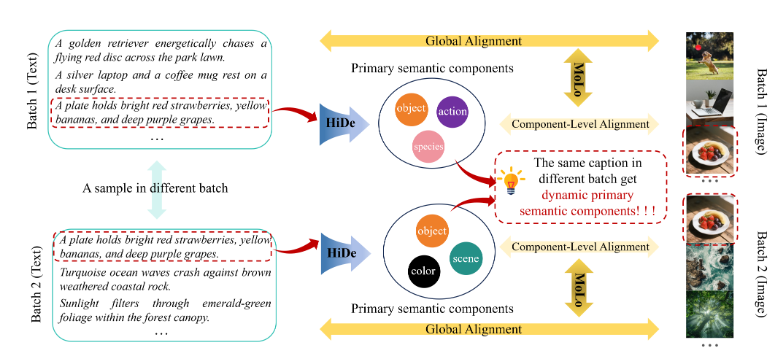
HiMo-CLIP 是表征层的轻量化框架,完全基于 CLIP 的双编码器范式(视觉编码器 + 文本编码器),不修改底层编码器架构,核心由 ** 层次分解模块(HiDe)和单调性感知对比损失(MoLo)** 两个编码器无关的组件构成,整体框架如下图所示:
- HiDe 模块:通过批次内 PCA 提取长文本的潜在语义组件,实现上下文自适应的多粒度语义分解;
- MoLo 损失:联合对齐全局图像 - 文本表征和组件级表征,隐式强化语义单调性。
1. 框架基础:CLIP 的双编码器嵌入
延续 CLIP 的核心设计,对图像I和文本T分别编码得到视觉嵌入和文本嵌入:
- 视觉嵌入:v=fv(I)∈Rd
- 文本嵌入:u=ft(T)∈Rd其中fv为视觉骨干网络(如 ViT),ft为文本编码器(如 Transformer),d为嵌入维度。
2. 层次分解模块(Hierarchical Decomposition, HiDe)
核心动机
自然语言的语义具有多层级性,且语义焦点随批次上下文动态变化(如批次以卡车为主时,“熏黑车窗” 是关键特征;批次含各类车辆时,“福特 F250” 的类别特征更重要)。HiDe 通过批次内主成分分析(PCA)实现数据驱动、上下文自适应的语义组件提取,替代静态的手工分割 / 截断。
实现步骤
针对包含N个图像 - 文本对的小批次B=(Ii,Ti)i=1N,步骤如下:
- 文本嵌入编码:将每个文本Ti编码为文本嵌入ui=ft(Ti)∈Rd;
- 均值中心化:计算批次文本嵌入的均值uˉ=N1∑j=1Nuj,对每个嵌入中心化得到u^i=ui−uˉ,消除批次内的公共语义偏差;
- PCA 分解(SVD 实现):对中心化后的嵌入集合u^ii=1N做奇异值分解(SVD),提取 ** 累计解释方差超过预设阈值(如 0.9)** 的前m个主成分,组成主成分矩阵P=[p1,...,pm]⊤∈Rm×d;
- 语义组件重构:将中心化嵌入投影到主成分空间并重构,得到文本的紧凑语义组件向量ui′:ui′=P⊤(Pu^i)+u该向量保留了长文本的核心高维语义,过滤了冗余噪声,且随批次上下文动态变化。
理论依据
HiDe 的 PCA 分解天然契合语义层次:高方差的主成分对应高等级语义(如物体类别),低方差成分对应低等级语义(如语法、次要属性),因此重构的ui′能精准捕捉批次内最具判别性的核心语义组件。
3. 单调性感知对比损失(Monotonicity-aware Contrastive Loss, MoLo)
核心动机
标准对比损失将每个输入视为独立单元,无语义单调性约束。MoLo 通过双分支对齐目标,联合优化全局表征和 HiDe 提取的组件级表征:组件级表征是全文本表征的子集语义,对齐两者能让模型学习 “全文本(完整语义)的对齐强度高于组件(部分语义)”,从而在无额外监督的情况下实现语义单调性。
损失构成
MoLo 损失由全局对比损失和组件级对比损失加权组成,均采用基于余弦相似度的 InfoNCE 损失(CLIP 的核心损失),保证与原框架的兼容性。
-
全局对比损失Lglobal:保留 CLIP 的全局图像 - 文本对齐,优化完整视觉嵌入和完整文本嵌入的对比关系:Lglobal=2N1∑i=1N[Linfo(vi,ui)+Linfo(ui,vi)]其中Linfo(a,b)为 InfoNCE 损失,兼顾图像到文本(I2T)和文本到图像(T2I)的双向检索。
-
组件级对比损失Lcomp:将视觉嵌入与 HiDe 提取的文本语义组件向量对齐,优化细粒度语义的跨模态匹配:Lcomp=2N1∑i=1N[Linfo(vi,ui′)+Linfo(ui′,vi)]
-
最终 MoLo 损失:通过超参数λ平衡全局和组件级损失的权重,论文中最优值为λ=1:LMoLo=Lglobal+λ⋅Lcomp
单调性实现逻辑
由于ui′是全文本嵌入ui的PCA 投影子集,包含的语义信息少于ui,模型在联合优化中会自然学习到:完整文本的对齐分数 > 语义组件的对齐分数,进而推广到 “文本越完整,对齐分数越高” 的语义单调性规律。
四、实验设置
1. 训练细节
- 训练数据集:ShareGPT4V(120 万图像 - 文本对,平均 143.6 个单词的多句注释,适配长文本训练);
- 模型初始化:基于原始 CLIP 初始化,微调 10 个 epoch;
- 硬件与优化器:8 张 NVIDIA H100,AdamW 优化器(学习率 1e-6,权重衰减 0.01,β1=0.9,β2=0.999),200 步暖启动,全局批次 1024;
- 数据预处理:图像 resize 至 224×224,文本填充 / 截断至 248-token 并采用插值位置嵌入;
- HiDe 超参数:累计解释方差阈值τ=0.9,MoLo 损失权重λ=1。
2. 评估任务与数据集
论文从长文本检索、短文本检索、语义层次与单调性、组合式推理四个维度开展评估,覆盖主流和专属基准数据集:
表格
| 评估维度 | 数据集 | 数据集特点 |
|---|---|---|
| 长文本图像 - 文本检索 | Urban1k、Docci、Long-DCI | 平均 128/136/200 个单词,长文本检索专属基准 |
| 短文本图像 - 文本检索 | Flickr30k、COCO | 经典短文本检索基准,验证模型的跨粒度兼容性 |
| 语义层次与单调性 | HiMo-Docci(论文自建)、Urban1k、Docci、Long-DCI | HiMo-Docci 为 1000 个 Docci 样本的人工分层标注,适配深度层次单调性评估 |
| 组合式推理 | COLA | 210 个人工验证的多物体查询,含细粒度属性变化,评估组合语义的对齐能力 |
3. 专属评估指标:HiMo@K
为量化语义单调性,论文提出 HiMo@K 指标,衡量文本完整性增加时,图像 - 文本对齐分数的增长一致性,分两种场景定义:
-
浅层层次(K=2/3):采用严格单调准确率,统计 “对齐分数随文本段数递增” 的样本占比:HiMo@K=N1∑i=1NI[st1(i)<st2(i)(<st3(i))]×100%其中I(⋅)为指示函数,stk为第k个文本段与图像的对齐分数。
-
深层层次(K>3):采用皮尔逊相关系数,衡量文本段索引k与对齐分数stk的正相关性,系数越接近 1,单调性越强:HiMo@K=ρ(k,stk)=∑k=1K(k−k)2∑k=1K(stk−s)2∑k=1K(k−k)(stk−s)
此外,论文还提出语义稳定性指数(SSI),衡量模型对长文本语义噪声的鲁棒性,SSI 值越低,模型抗噪声能力越强。
4. 对比基线模型
选取 CLIP 类主流模型,覆盖基础版、长文本优化版、细粒度对齐版:
- 基础模型:CLIP、EVA-02-CLIP、SigLIP、BLIP、MetaCLIP;
- 长文本优化模型:Long-CLIP、TULIP、LoTLIP;
- 细粒度对齐模型:FineLIP、FG-CLIP、Action-CLIP。
五、实验结果与分析
1. 长文本图像 - 文本检索:SOTA 性能
HiMo-CLIP 在 Urban1k、Docci、Long-DCI 三大长文本基准上全面超越所有基线,且仅使用 1M 训练样本(远少于 LoTLIP 的 100M),体现了框架的高效性。
- ViT-L/14 骨干下,HiMo-CLIP 在 Urban1k 实现 I2T/T2I=93.0%/93.1%,Docci 实现 82.4%/84.4%,Long-DCI 实现 62.2%/61.9%,较最强基线 FineLIP 有显著提升;
- 对比 Long-CLIP,HiMo-CLIP 在 Docci T2I 上提升 5.8%,Urban1k/Long-DCI 提升超 7%,核心原因是 HiDe 的动态语义分解替代了 Long-CLIP 的静态图像分解,更适配长文本的语义冗余特性。
2. 短文本检索:跨粒度兼容性
与其他长文本模型牺牲短文本性能不同,HiMo-CLIP 在 Flickr30k 和 COCO 短文本基准上仍保持SOTA 或竞争性性能,验证了层次化设计的泛化性:
- ViT-L/14 骨干下,Flickr30k I2T R@1 达 92.5%,COCO T2I R@1 达 47.2%,均为新 SOTA;
- 避免了 Long-CLIP 在 Flickr30k T2I 上的性能退化,证明 HiMo-CLIP 的语义层次建模不会过拟合长文本。
3. 语义层次与单调性:显著优势
HiMo-CLIP 在 HiMo@K 指标上表现出近乎完美的语义单调性,远超所有基线,验证了 MoLo 损失和 HiDe 模块的核心作用:
- 浅层层次:HiMo@2 平均达 97.9%(Urban1k/Docci/Long-DCI),HiMo@3 平均达 64.2%,较 FineLIP 分别提升 1.5% 和 4.5%;
- 深层层次:HiMo-Docci 上 HiMo@K 皮尔逊相关系数达 0.88,而 Long-CLIP 为 - 0.55(呈负相关,细节越多对齐越差);
- 定性结果显示,HiMo-CLIP 在 HiMo@4/7/10 等深层层次中,对齐分数始终稳定递增,而基线模型频繁出现分数下降。
4. 组合式推理:COLA 任务提升
在 COLA 多物体组合推理任务中,HiMo-CLIP 的 top-1 准确率达 38.6%,较 TULIP(34.8%)、FineLIP(34.3%)提升约 4%,证明 HiDe 能有效提取细粒度的属性 - 物体绑定语义,解决了扁平序列模型的组合语义纠缠问题。
5. 消融实验:验证组件有效性
论文通过大量消融实验,验证了 HiDe 模块、MoLo 损失各组件的必要性和超参数的最优选择:
- HiDe 解释方差阈值τ:τ=0.9时取得最优权衡,检索性能和单调性指标均达峰值;阈值过小丢失核心语义,过大保留冗余噪声,均会导致性能下降;
- MoLo 损失分支:仅全局 + 组件级双分支联合优化能实现最优性能,HiMo@K 较单独全局损失提升 0.19,证明组件级对齐是语义单调性的核心;
- 损失权重λ:λ=1时平衡全局和组件级对齐,λ>1会过度侧重组件导致检索性能下降,λ<1会弱化单调性约束;
- 批次大小对 HiDe 的影响:批次越大(语义多样性越丰富),HiDe 提取的语义组件越稳定,模型性能越好,1024 批次为最优(硬件约束下),且 512 批次已接近最优性能,体现 HiDe 的鲁棒性。
6. 鲁棒性实验:抗语义噪声
在长文本中注入无关语义噪声(如在卡车描述中加入 “长颈鹿身高”)后,HiMo-CLIP 的语义稳定性指数(SSI)仅为 4.63,远低于 FineLIP(8.72)、TULIP(12.99)、Long-CLIP(11.45),证明 HiDe 的动态语义分解能有效过滤无关噪声,保留核心对齐语义,鲁棒性显著优于基线。
7. 失败案例分析
HiMo-CLIP 虽能保证整体语义单调性,但在K=10 等超深层层次中,偶尔会因视觉模糊的细粒度细节(如被遮挡的桶身标签 “ULTRA”)出现轻微的分数波动;但相比基线模型的大幅分数下降,HiMo-CLIP 仍能保持整体稳定递增,体现了框架的鲁棒性。
六、理论分析与补充讨论
1. HiMo-CLIP 的理论合理性
论文在附录中从理论上证明了 HiMo-CLIP 建模语义层次和单调性的必然性:
- HiDe 的语义组件提取:基于 “语义层次组合” 和 “高等级语义主导方差” 两个假设,PCA 提取的主成分天然对应高等级核心语义,重构的ui′能过滤噪声、保留关键语义;
- 单调性的数学推导:将全文本嵌入视为 “核心语义组件 + 逐步语义增量”,由于语义增量与图像嵌入的余弦相似度为正,且分母增长慢于分子,对齐分数会随文本完整性严格单调递增。
2. HiMo-CLIP 与 Long-CLIP 的核心差异
两者均为 CLIP 的长文本优化版,但设计理念和效果存在本质区别,HiMo-CLIP 在语义建模、实现复杂度、性能上全面占优:
表格
| 对比维度 | Long-CLIP | HiMo-CLIP |
|---|---|---|
| 模态处理思路 | 分解图像特征适配短文本,忽略视觉紧凑性 | 压缩长文本特征,适配图像的紧凑语义 |
| 语义分解逻辑 | 图像 PCA 组件与手工短文本对齐,易丢失语义 | 文本 PCA 组件动态提取,适配批次上下文 |
| 单调性约束 | 无显式机制,HiMo@K=-0.55 | MoLo 双分支隐式约束,HiMo@K=0.88 |
| 训练输入 | 需长文本 + 手工短文本,标注成本高 | 仅需原始长文本,无额外标注 |
| 计算成本 | 双文本类型编码,成本高 | 单文本编码,PCA 成本可忽略 |
| 长文本检索性能 | Docci T2I=78.6%(ViT-L/14) | Docci T2I=84.4%(ViT-L/14) |
3. 推理阶段的简化
HiMo-CLIP 的推理阶段无需使用 HiDe 和 MoLo,直接沿用 CLIP 的标准流程:独立编码图像和文本→归一化特征→计算余弦相似度,相比 FineLIP 的复杂加权推理,HiMo-CLIP 实现了推理高效性与性能优越性的兼顾。
七、研究贡献
论文的核心贡献可总结为三点:
- 概念定义:首次将语义层次和语义单调性正式定义为跨模态对比学习的两个基础属性,明确了其对多粒度、完整性敏感的图像 - 文本对齐的必要性;
- 框架设计:提出 HiMo-CLIP,一个自监督、编码器无关的表征层框架,通过 HiDe 和 MoLo 组件,在不修改编码器架构、无额外标注的情况下,实现了上下文自适应的语义层次分解和显式的语义单调性约束;
- 实验验证:在多个图像 - 文本检索基准上验证了 HiMo-CLIP 的 SOTA 性能,尤其在长文本 / 组合式文本场景中优势显著;同时提出 HiMo@K、SSI 等专属指标,为语义层次和单调性的评估提供了标准化方法,并自建 HiMo-Docci 数据集填补了深度层次评估的空白。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)