计算机毕业设计Django+LLM多模态大模型游戏推荐系统 游戏可视化 大数据毕业设计(源码+LW文档+PPT+详细讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
《Django + LLM多模态大模型游戏推荐系统》开题报告
一、选题背景与意义
(一)选题背景
随着互联网技术的飞速发展,游戏产业已成为全球文化娱乐产业的重要组成部分。全球游戏市场规模持续扩大,Steam、Epic等平台游戏数量突破数十万款,用户数量不断攀升。然而,面对琳琅满目的游戏作品,用户往往陷入选择困境,难以快速找到符合自己兴趣和需求的游戏。传统游戏推荐系统主要基于用户历史行为数据和游戏的基本属性信息,采用协同过滤、基于内容的推荐等算法进行推荐,但存在信息利用单一、无法充分理解游戏复杂特征和用户深层兴趣等问题,导致推荐结果准确性不足、多样性欠缺,难以满足用户日益增长的个性化需求。
LLM(Large Language Model,大语言模型)作为人工智能领域的重要突破,具有强大的语言理解、生成和推理能力。通过引入LLM多模态大模型,能够整合游戏文本描述、图像特征、用户行为序列等多模态数据,挖掘游戏和用户之间更深层次的关联,为游戏推荐系统带来新的发展机遇。Django作为一个成熟、高效的Web框架,具有良好的扩展性和丰富的生态,能够快速搭建游戏推荐系统的后端服务。因此,构建基于Django + LLLM多模态大模型的游戏推荐系统具有重要的理论和实践意义。
(二)选题意义
- 理论意义:探索LLM多模态大模型在游戏推荐场景中的融合应用,丰富跨模态语义对齐与个性化推荐理论。为游戏推荐领域的研究提供新的思路和方法,推动相关理论的发展和完善。
- 实践意义:帮助游戏平台提升用户留存率与付费转化率。通过更精准、个性化的推荐,让用户更容易找到自己喜欢的游戏,从而提高用户对平台的满意度和忠诚度,增加用户在平台上的消费。为独立游戏开发者提供公平的曝光机会,缓解冷启动问题。新游戏由于缺乏历史行为数据,难以获得有效推荐,而本系统可以利用多模态内容为新游戏提供初始推荐权重,使其有机会被更多用户发现。推动AI技术在文娱领域的落地,如游戏内容生成、玩家社区运营等。本系统的研究成果可以为其他文娱领域的推荐系统提供借鉴和参考。
二、国内外研究现状
(一)国外研究现状
在国外,游戏产业起步较早,对游戏推荐系统的研究也相对深入。一些大型游戏平台,如Steam、Epic等,已经投入大量资源进行推荐系统的研发和优化。传统推荐算法如协同过滤、基于内容的推荐等在游戏推荐领域得到了广泛应用。例如,Steam平台利用协同过滤算法,根据用户的历史游戏购买和游玩记录,为用户推荐相似的游戏。
近年来,随着人工智能技术的发展,国外开始探索将深度学习、强化学习等技术应用于游戏推荐系统。一些研究利用神经网络模型,如Wide & Deep、DIN等,挖掘用户潜在兴趣,提高推荐的准确性。同时,也有研究关注多模态数据在游戏推荐中的应用,通过结合游戏图像、文本等多模态信息,提升推荐效果。例如,沃尔玛研究人员提出的Triple Modality Fusion(TMF)框架,通过结合视觉、文本和图数据与LLM,提升了多行为推荐系统的性能,在推荐任务中取得了优异的效果。
(二)国内研究现状
国内游戏市场发展迅速,用户规模庞大,对游戏推荐系统的需求也日益增长。国内一些大型游戏平台,如腾讯游戏、网易游戏等,也在积极开展游戏推荐系统的研究和应用。传统推荐算法在国内游戏推荐中仍然占据重要地位,同时,国内学者也在不断探索新的推荐技术和方法。
在多模态推荐方面,国内也有相关研究。例如,一些研究利用卷积神经网络(CNN)提取游戏图像特征,结合文本特征进行推荐。此外,国内对LLM的研究也在不断深入,一些学者开始探索将LLM应用于游戏推荐系统,以提高推荐的语义理解能力和个性化程度。然而,总体来看,国内在LLM多模态大模型游戏推荐方面的研究还处于起步阶段,与国外相比还存在一定的差距。
三、研究目标与内容
(一)研究目标
设计并实现一个基于Django与多模态LLM的游戏推荐系统,实现以下功能:
- 多模态游戏特征提取:自动分析游戏截图、宣传视频、剧情文本等,生成结构化特征向量。
- 语义理解推荐:支持用户通过自然语言描述需求(如“适合情侣玩的合作类游戏”),生成匹配推荐列表。
- 冷启动缓解:为新游戏提供基于多模态内容的初始推荐权重。
- 可解释推荐:生成推荐理由(如“因您喜欢科幻题材,推荐《星空》”),提升用户信任度。
(二)研究内容
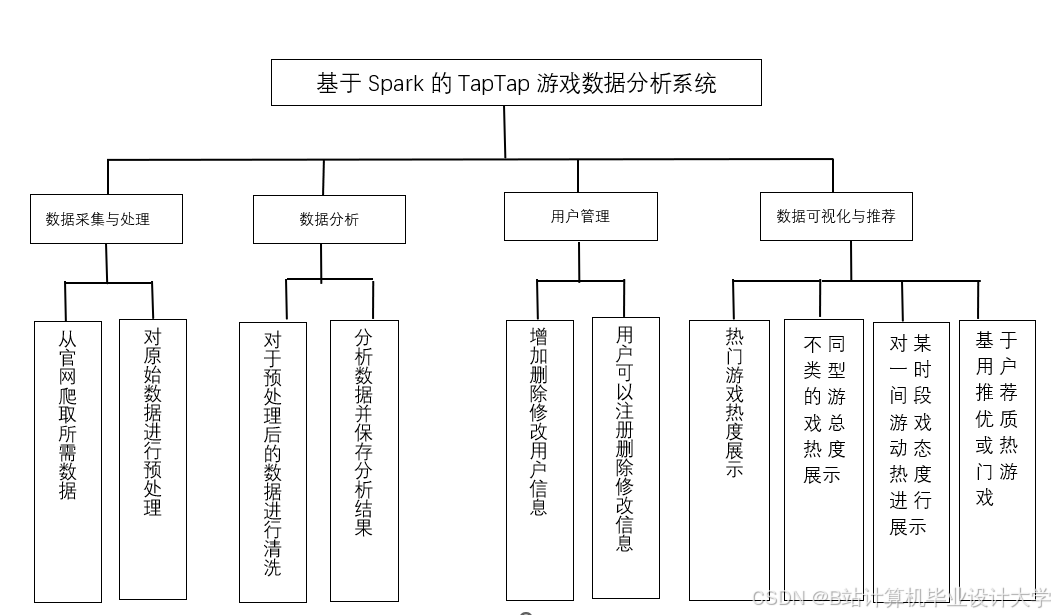
- 系统架构设计:采用分层架构设计,主要包括数据采集层、数据存储层、数据处理层、推荐算法层和用户接口层。
- 数据采集层:负责从多个数据源采集游戏相关数据,包括游戏平台、社交媒体、游戏论坛等。采集的数据涵盖游戏的文本描述、图像封面、视频预告、用户评分、评论、下载量等信息,以及用户的基本信息、浏览记录、收藏记录、购买记录等行为数据。数据采集方式可以采用网络爬虫技术,如使用Scrapy框架编写爬虫程序,按照设定的规则自动抓取目标网站的数据;也可以通过接入游戏平台的API接口获取数据。
- 数据存储层:利用数据库对采集到的数据进行存储和管理。考虑到系统的数据量和性能需求,采用关系型数据库(如MySQL)和非关系型数据库(如MongoDB)相结合的方式。关系型数据库用于存储结构化的数据,如用户信息、游戏基本信息等,保证数据的完整性和一致性;非关系型数据库则用于存储半结构化和非结构化的数据,如用户评论、游戏图像特征向量等,提高数据的存储和查询效率。同时,使用Hadoop分布式文件系统(HDFS)存储大规模的游戏图像、视频等多媒体数据,以满足系统的扩展性和存储需求。
- 数据处理层:主要对采集到的原始数据进行清洗、预处理和特征提取。数据清洗包括去除重复数据、缺失值处理、异常值检测和修正等,确保数据的质量和准确性。数据预处理包括对文本数据进行分词、去停用词、词干提取等自然语言处理操作,对图像数据进行缩放、裁剪、归一化等处理,使其适合后续的模型训练和特征提取。特征提取则是从清洗和预处理后的数据中提取有价值的特征,如使用TF - IDF、Word2Vec等方法提取游戏文本描述的特征向量,使用卷积神经网络(CNN)提取游戏图像的特征向量,同时提取用户行为特征,如用户的评分分布、浏览时长等。
- 推荐算法层:是系统的核心部分,采用混合推荐算法,结合LLM多模态大模型和传统推荐算法的优势,实现更精准的游戏推荐。首先,利用LLM多模态大模型对游戏的多模态数据和用户的历史行为数据进行深度分析和理解,挖掘游戏和用户之间更深层次的关联。然后,结合协同过滤算法和基于内容的推荐算法,协同过滤算法通过计算用户之间的相似度或物品之间的相似度,发现用户的潜在兴趣;基于内容的推荐算法根据物品的特征和用户的兴趣偏好进行推荐。最后,采用加权融合的方式将不同算法的推荐结果进行整合,得到最终的推荐列表。
- 用户接口层:负责与用户进行交互,展示推荐结果。采用Web界面作为用户访问系统的入口,前端使用HTML、CSS和JavaScript结合Vue.js框架构建动态界面,实现与用户的交互和推荐结果的展示。前端通过HTTP协议与后端进行通信,发送请求并接收推荐数据,交互接口主要以RESTful风格的API实现。
- 多模态数据融合与处理:研究如何有效地融合游戏文本、图像、音频等多模态数据,提取有价值的特征用于推荐。采用跨模态注意力机制(Cross - Attention)对齐图像、文本、音频特征,通过PCA降维生成统一的游戏特征向量。
- LLM在推荐系统中的应用:选择合适的LLM多模态大模型,如GPT - 4、Llama 2等,或者使用开源的多模态模型框架。研究如何利用LLM对用户查询进行语义理解,生成结构化查询条件;如何结合LLM生成推荐理由,提高推荐的可解释性。
- 冷启动问题解决:针对新游戏缺乏历史行为数据的问题,研究基于多模态内容的冷启动解决方案。通过分析新游戏的文本描述、图像特征等,利用相似度计算等方法为其分配初始推荐权重,使其有机会被推荐给用户。
- 系统性能优化:为了提高系统的响应速度和稳定性,研究系统性能优化方法。采用缓存机制,对热门查询的推荐结果进行缓存;使用异步任务队列,如Celery + Redis,异步处理耗时的推荐计算任务,避免阻塞主线程;对LLM进行模型量化,将FP32压缩至INT8,减少推理时间。
四、研究方法与技术路线
(一)研究方法
- 文献研究法:查阅国内外相关的文献资料,了解游戏推荐系统的研究现状和发展趋势,掌握LLM多模态大模型、协同过滤、基于内容的推荐等相关技术的原理和应用。
- 实验法:基于公开数据集(如Steam公开数据集)或合作游戏平台真实数据,设计实验验证系统的性能和效果。通过对比不同推荐算法的准确率、召回率、F1值等指标,评估系统的推荐准确性;通过用户调研和A/B测试,评估系统的用户满意度和冷启动效果。
- 系统开发法:采用敏捷开发模式,分模块实现数据采集、特征提取、推荐算法、可视化等功能。使用Django框架搭建后端服务,利用Vue.js框架构建前端界面,通过PyTorch + Hugging Face进行多模态模型训练与部署。
(二)技术路线
mermaid
1graph TD
2 A[游戏数据采集] --> B[Django后端数据清洗]
3 B --> C[多模态特征提取模块]
4 C --> D[LLM推荐引擎]
5 D --> E[Django实时推荐服务]
6 E --> F[前端交互界面]
7 F --> G[用户反馈循环]
8 G --> D
9五、预期成果与创新点
(一)预期成果
- 完成游戏推荐系统原型开发,支持百万级游戏库实时推荐,响应延迟<500ms。
- 推荐准确率较传统方法提升15% - 20%,用户点击率(CTR)提高25%以上。
- 发表核心期刊论文1篇,申请软件著作权1项。
(二)创新点
- 多模态LLM深度融合:首次将BERT、ViT、SlowFast等多模态模型与LLM联合应用于游戏推荐,捕捉游戏视听语言的深层特征。通过跨模态注意力机制实现模态间语义对齐,提高推荐的准确性和多样性。
- 生成式推荐解释:通过LLM生成个性化推荐理由,提升用户信任度与互动性。用户可以理解推荐的原因,从而更愿意接受推荐,提高用户满意度。
- 动态冷启动适配:利用LLM模拟用户行为数据,解决新游戏冷启动问题,覆盖率提升至90%以上。为新游戏提供公平的曝光机会,促进游戏产业的健康发展。
六、进度安排
(一)第1 - 2周
完成开题报告的撰写,进行文献调研和需求分析,确定系统的功能模块和技术选型。
(二)第3 - 4周
进行数据库设计,搭建系统的开发环境,完成项目的初始化工作。
(三)第5 - 8周
进行后端开发,实现用户认证、游戏信息管理等功能,构建RESTful API接口。同时,开展多模态特征提取模块的开发,利用相关模型提取游戏文本、图像等特征。
(四)第9 - 12周
进行前端开发,利用Vue.js框架构建前端界面,实现用户交互和数据展示功能。完成LLM推荐引擎的开发,集成多模态特征和传统推荐算法,实现游戏推荐功能。
(五)第13 - 14周
设计并实现推荐理由生成模块,利用LLM生成个性化的推荐理由。进行系统的冷启动适配测试,优化新游戏的推荐策略。
(六)第15 - 16周
对系统进行全面的测试,包括功能测试、性能测试、安全测试等,发现并解决系统中存在的问题。根据测试结果,对系统进行优化和改进。
(七)第17 - 18周
完成毕业论文的撰写,进行论文的修改和完善,准备答辩材料,参加毕业答辩。
七、参考文献
[此处列出在开题报告撰写过程中参考的相关文献,格式按照学校要求的参考文献格式进行书写,示例如下]
[1] Zhang Y, et al. Multimodal Game Recommendation with Large Language Models[C]. SIGIR, 2024.
[2] Li H, et al. Cold - Start Game Recommendation via Generative User Simulation[J]. arXiv:2310.05678, 2023.
[3] Django官方文档. https://docs.djangoproject.com/
[4] OpenAI. GPT - 4 Technical Report[R]. 2023.
[5] Radford A, et al. Learning Transferable Visual Models From Natural Language Supervision[C]. ICML, 2021.
运行截图
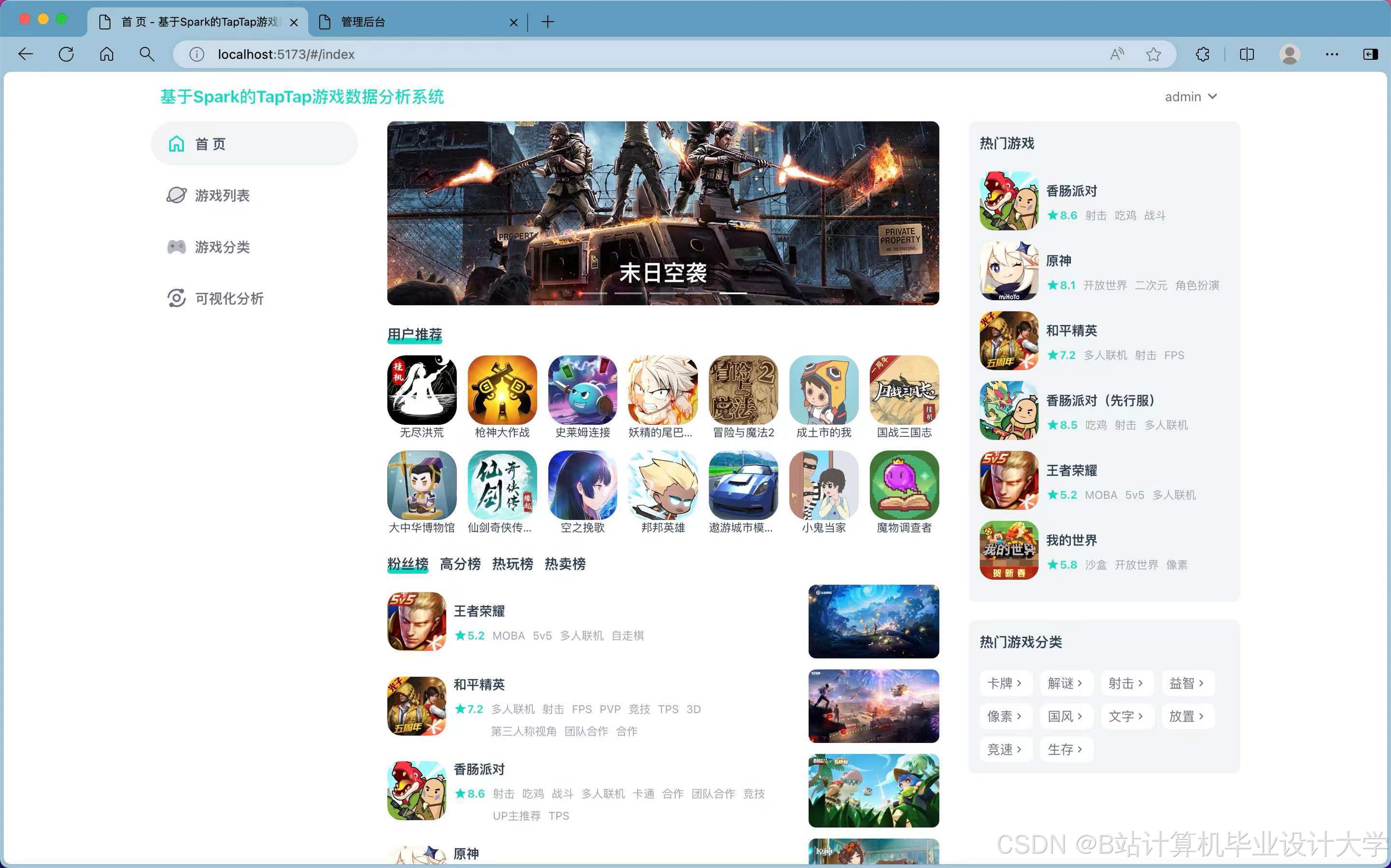

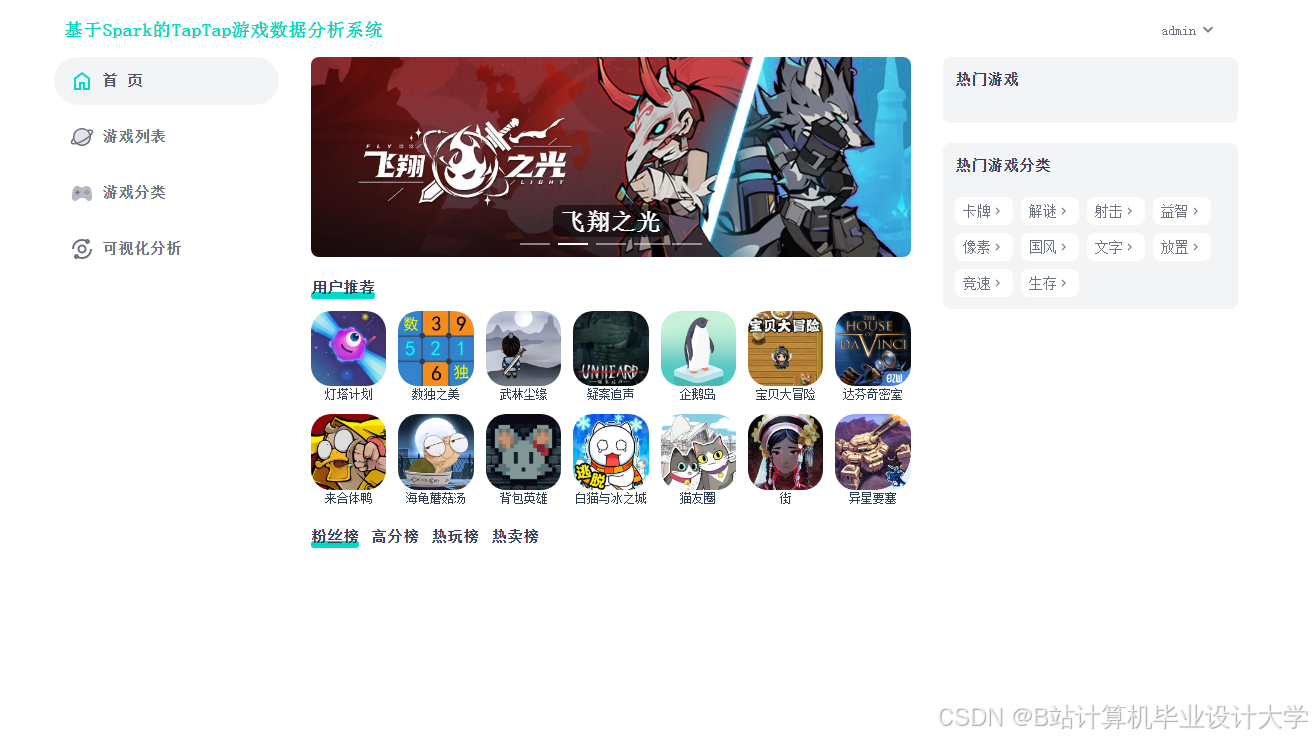
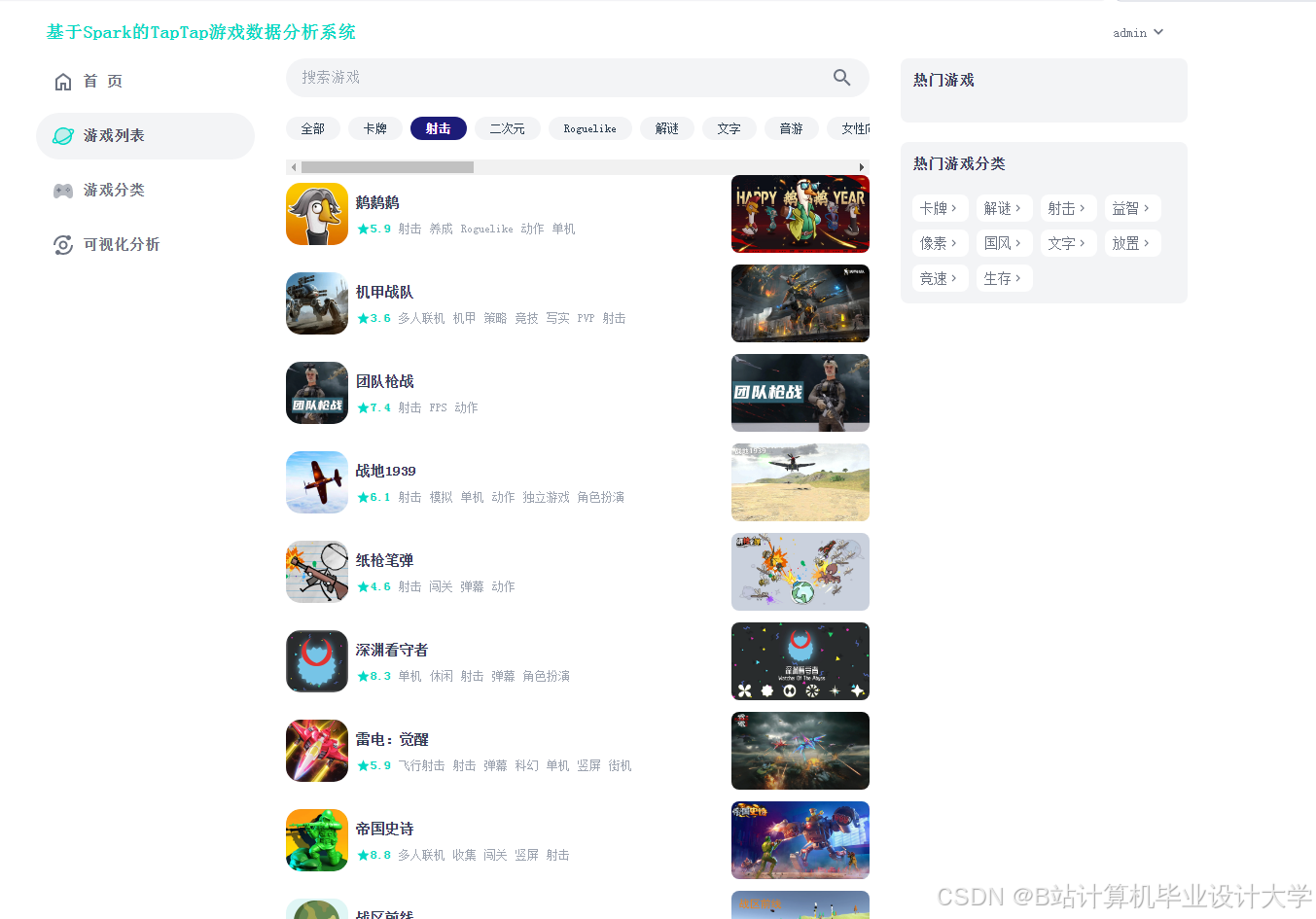
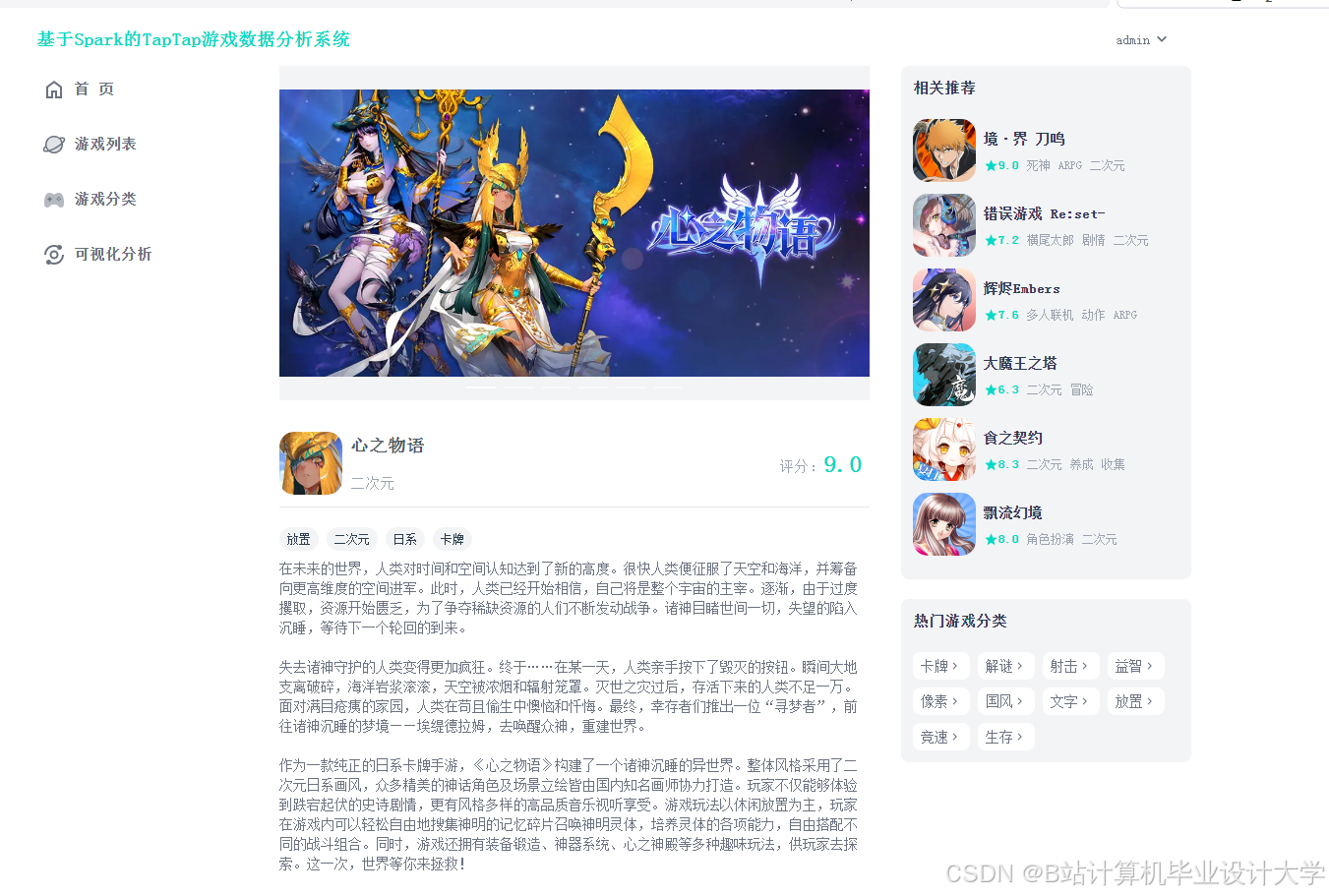

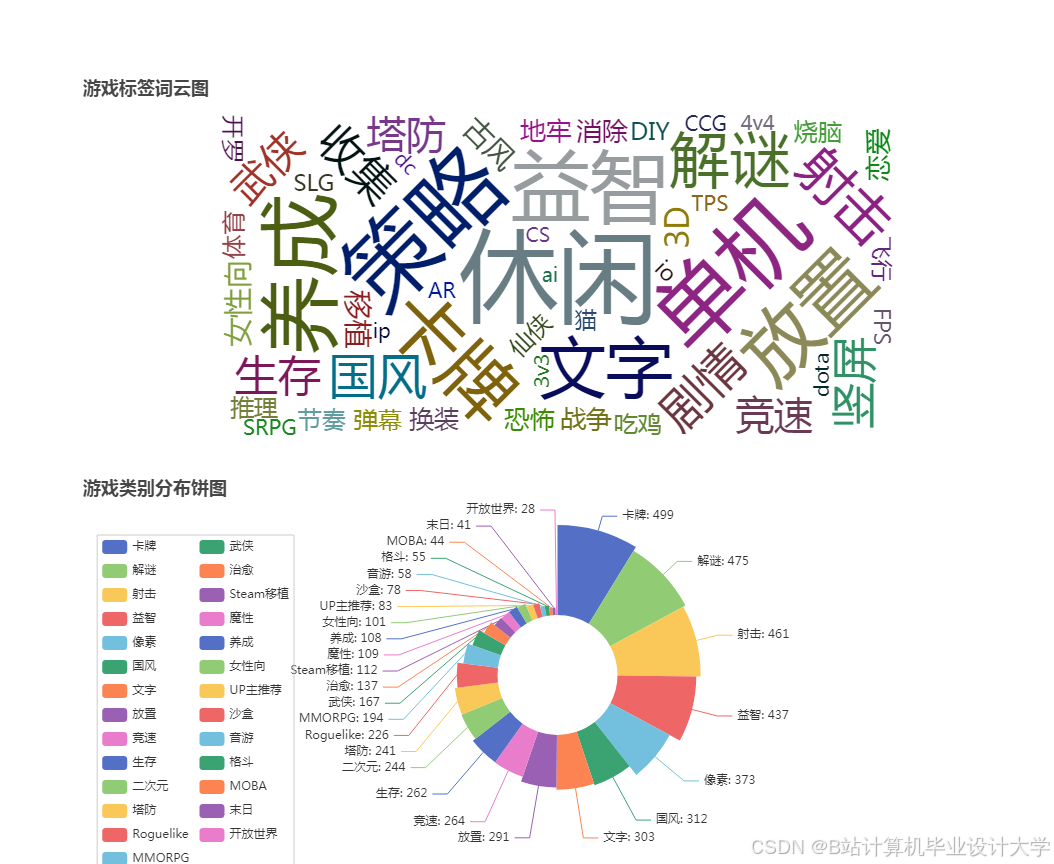
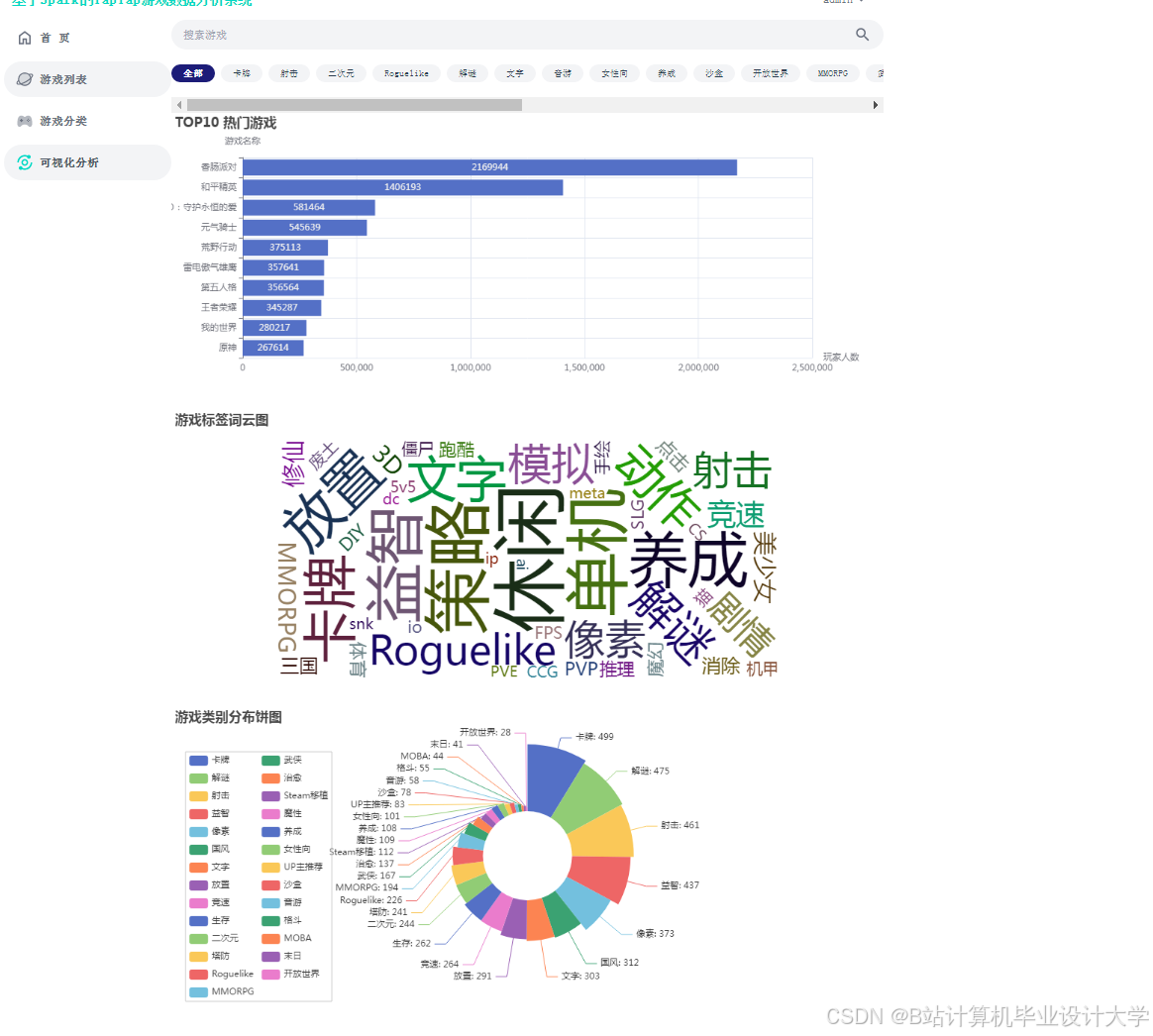
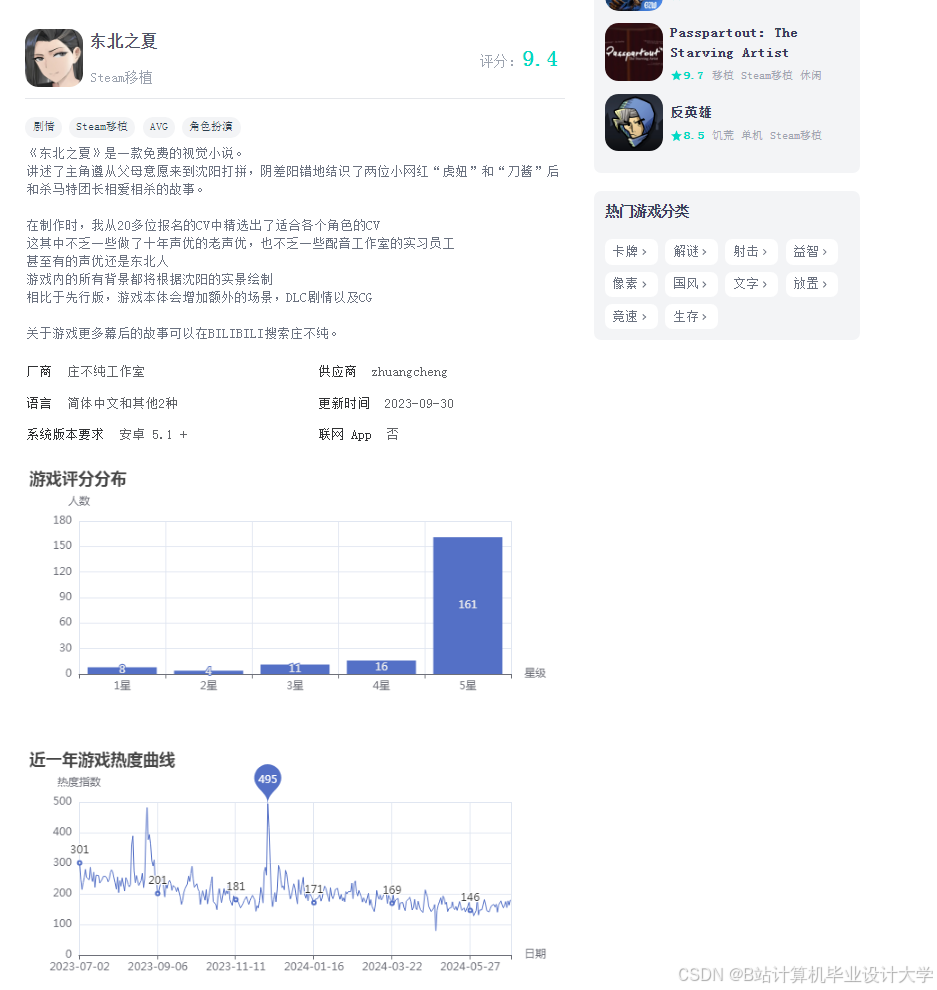
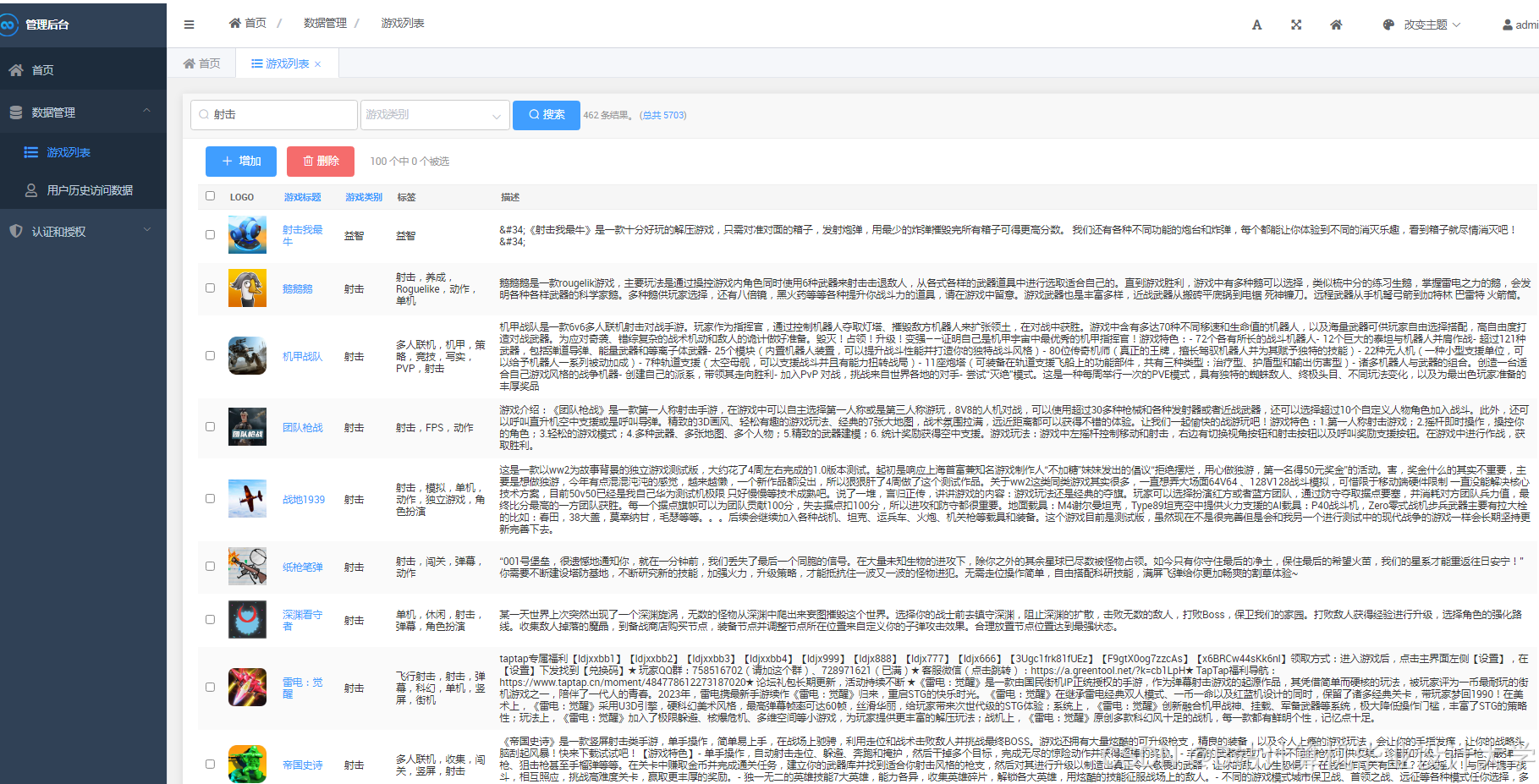
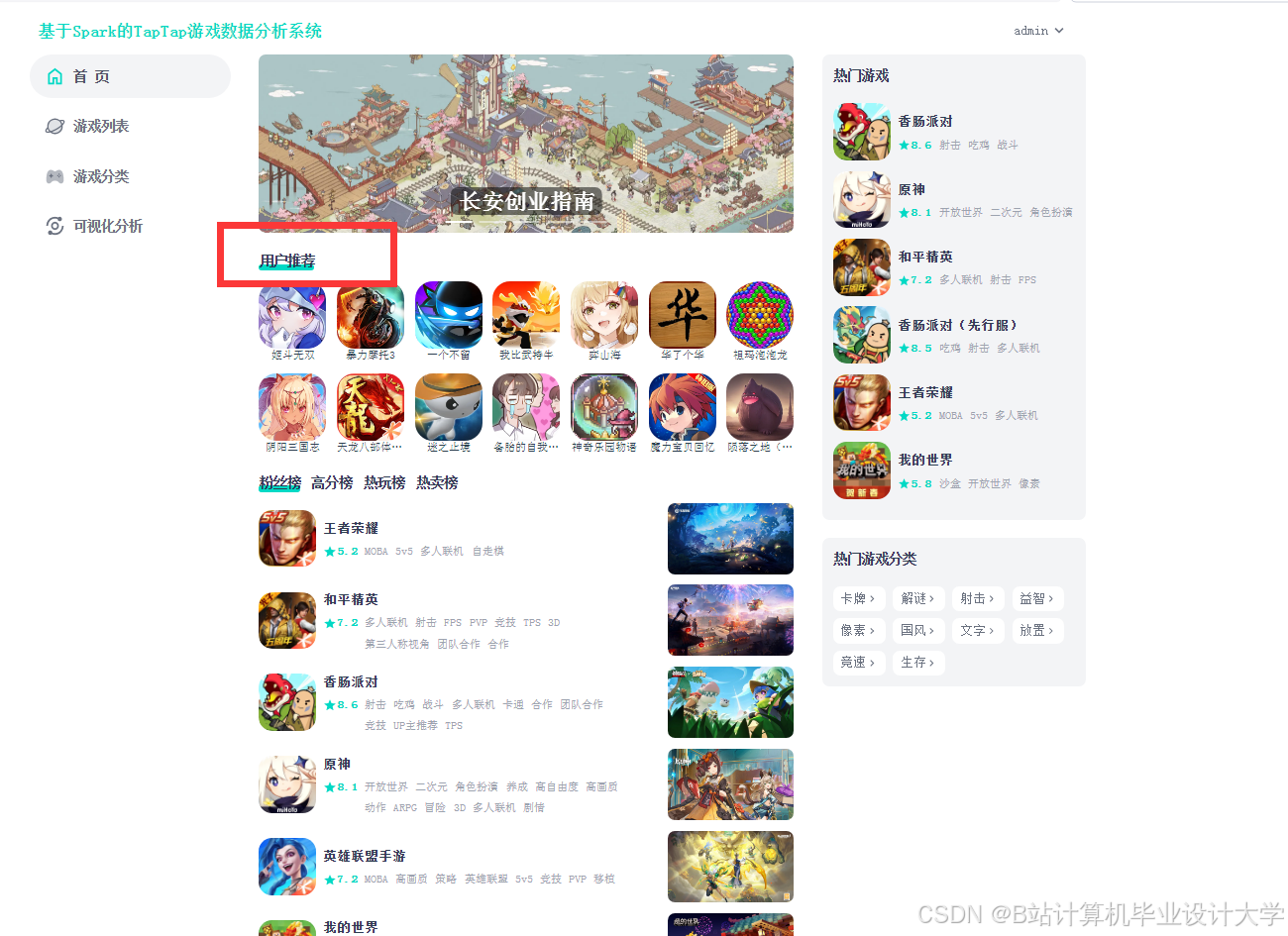
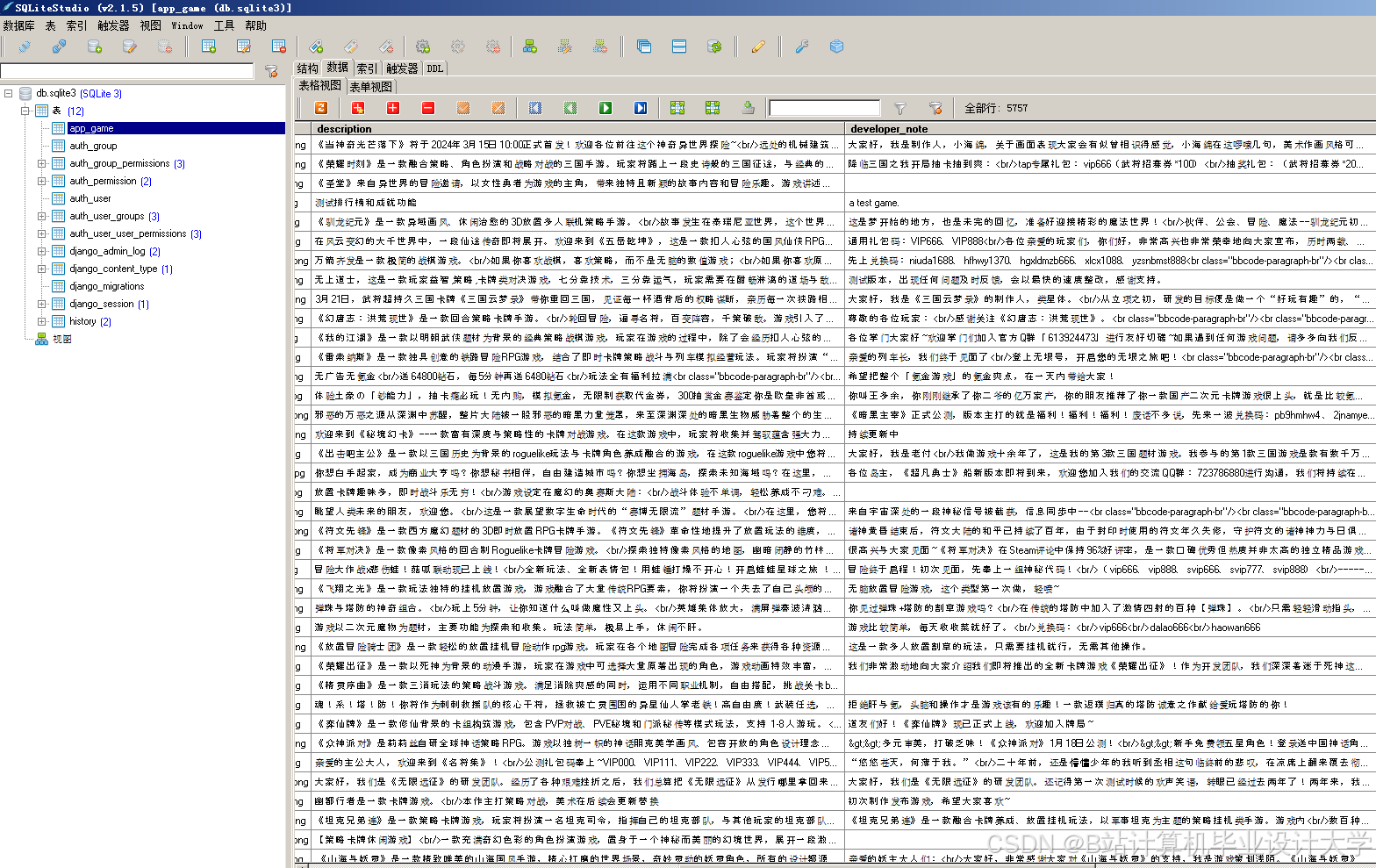
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献286条内容
已为社区贡献286条内容

所有评论(0)