基于 YOLOv8 的人脸表情识别系统
·
项目简介
本项目以 YOLOv8 目标检测框架为核心,构建了一套完整的人脸表情识别系统,涵盖数据集处理、模型训练与调优、可视化分析以及交互式推理系统的全流程开发。系统能够在图片、视频及摄像头实时画面中同步完成人脸定位与表情分类,支持 7 种基础表情类别的端到端识别。
目录
深度学习开发流程
本项目完整复现了深度学习系统从零到部署的标准流程:
数据集构建与预处理
↓
预训练模型选型与配置
↓
多策略数据增强
↓
模型训练与实时监控
↓
指标评估与超参调优
↓
最优权重导出
↓
GUI 推理系统集成
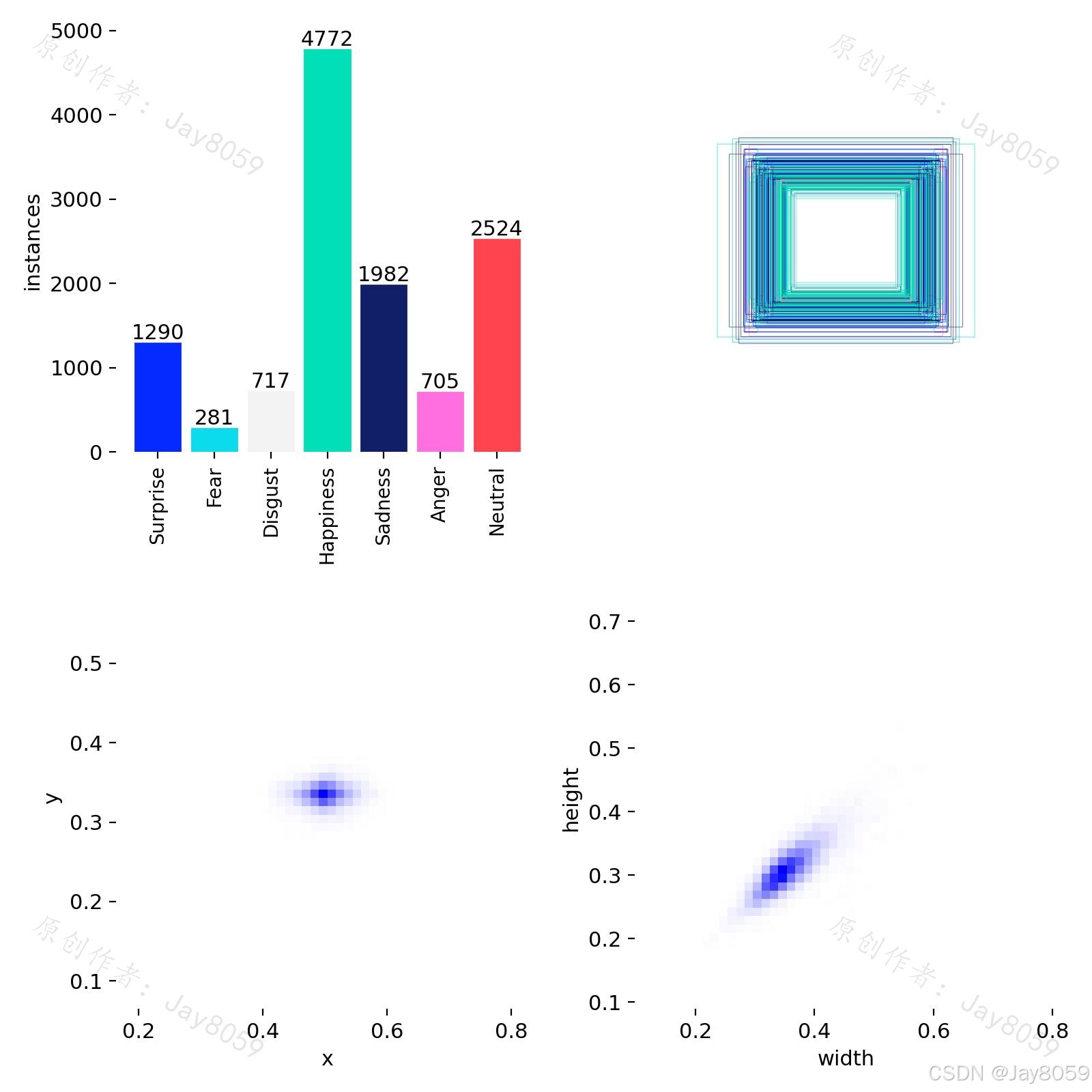
数据集说明
数据集概况
| 项目 | 内容 |
|---|---|
| 数据集名称 | FER(Facial Expression Recognition)YOLO 格式 |
| 标注格式 | YOLO txt(每行:类别ID cx cy w h,归一化坐标) |
| 训练集图片数 | 约 10,000 张 |
| 测试集图片数 | 约 3,068 张 |
| 总计 | 约 13,068 张 |
| 类别数量 | 7 类 |
表情类别
| ID | 英文标签 | 中文含义 | 说明 |
|---|---|---|---|
| 0 | Surprise | 惊讶 | 眉毛上扬、嘴巴张开 |
| 1 | Fear | 恐惧 | 眉毛皱起、眼神紧张 |
| 2 | Disgust | 厌恶 | 鼻子皱起、嘴角下撇 |
| 3 | Happiness | 高兴 | 嘴角上扬、面部舒展 |
| 4 | Sadness | 悲伤 | 眉毛下垂、嘴角下拉 |
| 5 | Anger | 愤怒 | 眉毛紧锁、目光锐利 |
| 6 | Neutral | 中性 | 面部无明显情绪特征 |
数据集目录结构
fer-dataset-yolo/
├── loopy.yaml # 数据集配置文件
├── train/
│ ├── images/ # 训练集图片
│ └── labels/ # 训练集标注(YOLO格式)
└── test/
├── images/ # 测试集图片
└── labels/ # 测试集标注
标注格式示例
# 格式:类别ID 中心点x 中心点y 宽度 高度(均为相对图片宽高的归一化值)
4 0.5097 0.3528 0.3948 0.3183
数据预处理与增强策略
训练时采用多种在线数据增强,增强模型对不同场景的鲁棒性:
| 增强方式 | 参数 | 作用 |
|---|---|---|
| HSV 色调抖动 | hsv_h=0.015 | 模拟不同光源色温 |
| HSV 饱和度抖动 | hsv_s=0.7 | 模拟低/高饱和场景 |
| HSV 明度抖动 | hsv_v=0.4 | 模拟亮度变化 |
| 随机水平翻转 | fliplr=0.5 | 增加左右对称样本 |
| Mosaic 拼接 | mosaic=1.0 | 4 图合并,扩充上下文 |
| MixUp 混合 | mixup=0.1 | 提升决策边界平滑性 |
模型训练
预训练模型
选用 YOLOv8s(Small)作为基础模型,在 COCO 数据集预训练权重上进行迁移学习。该规格在精度与推理速度之间取得最佳平衡,适合表情识别这类细粒度分类任务。
训练流程
- 加载
yolov8s.pt预训练权重,冻结骨干网络初期层 - 以小学习率预热(Warmup)3 轮,逐步适应新任务分布
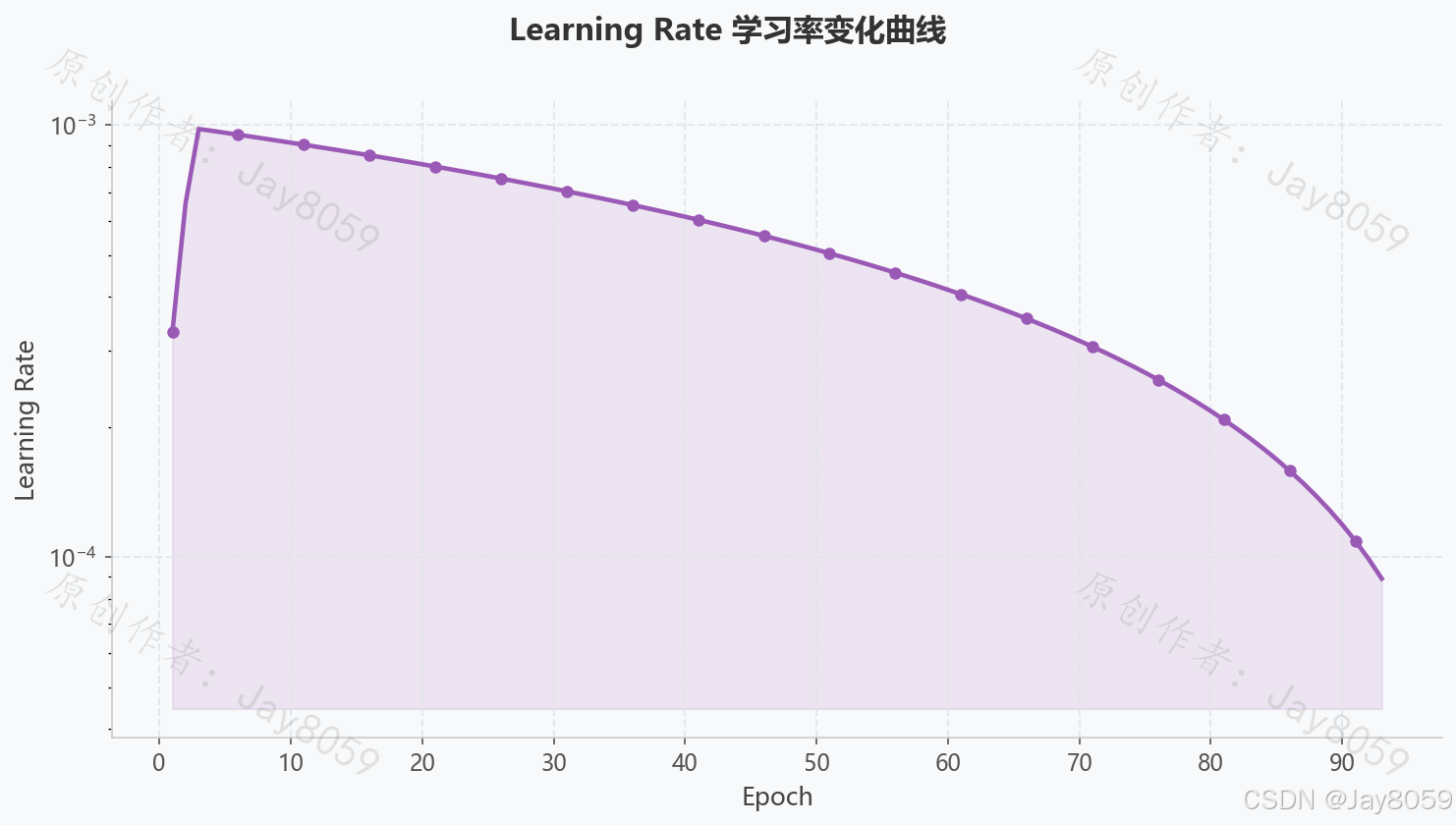
- 余弦退火(Cosine Annealing)调度器动态调整学习率
- 启用早停(Early Stopping)机制,patience=25,防止过拟合
- 每 10 轮保存一次检查点,最优验证 mAP 自动保存为
best.pt
运行训练
python train.py
所有训练产物(权重、曲线图、混淆矩阵等)自动保存至 train_result/fer_yolov8s/。
训练参数
| 参数名 | 值 | 说明 |
|---|---|---|
| 模型 | yolov8s | Small 规格,兼顾精度与速度 |
| 输入分辨率 | 640 × 640 | 标准 YOLO 输入尺寸 |
| 训练轮次 | 100(早停于第 93 轮) | patience=25 触发早停 |
| 批大小 | 16 | 适配 12 GB 显存 |
| 优化器 | AdamW | 自适应权重衰减优化 |
| 初始学习率 | 0.001 | 余弦退火衰减 |
| 终止学习率 | lr0 × 0.01 | 衰减至 0.00001 |
| 权重衰减 | 0.0005 | L2 正则化,抑制过拟合 |
| 预热轮次 | 3 | 稳定初期梯度 |
| 训练设备 | NVIDIA RTX 3060 12G | CUDA 加速 |
| 数据加载线程 | 4 | DataLoader workers |
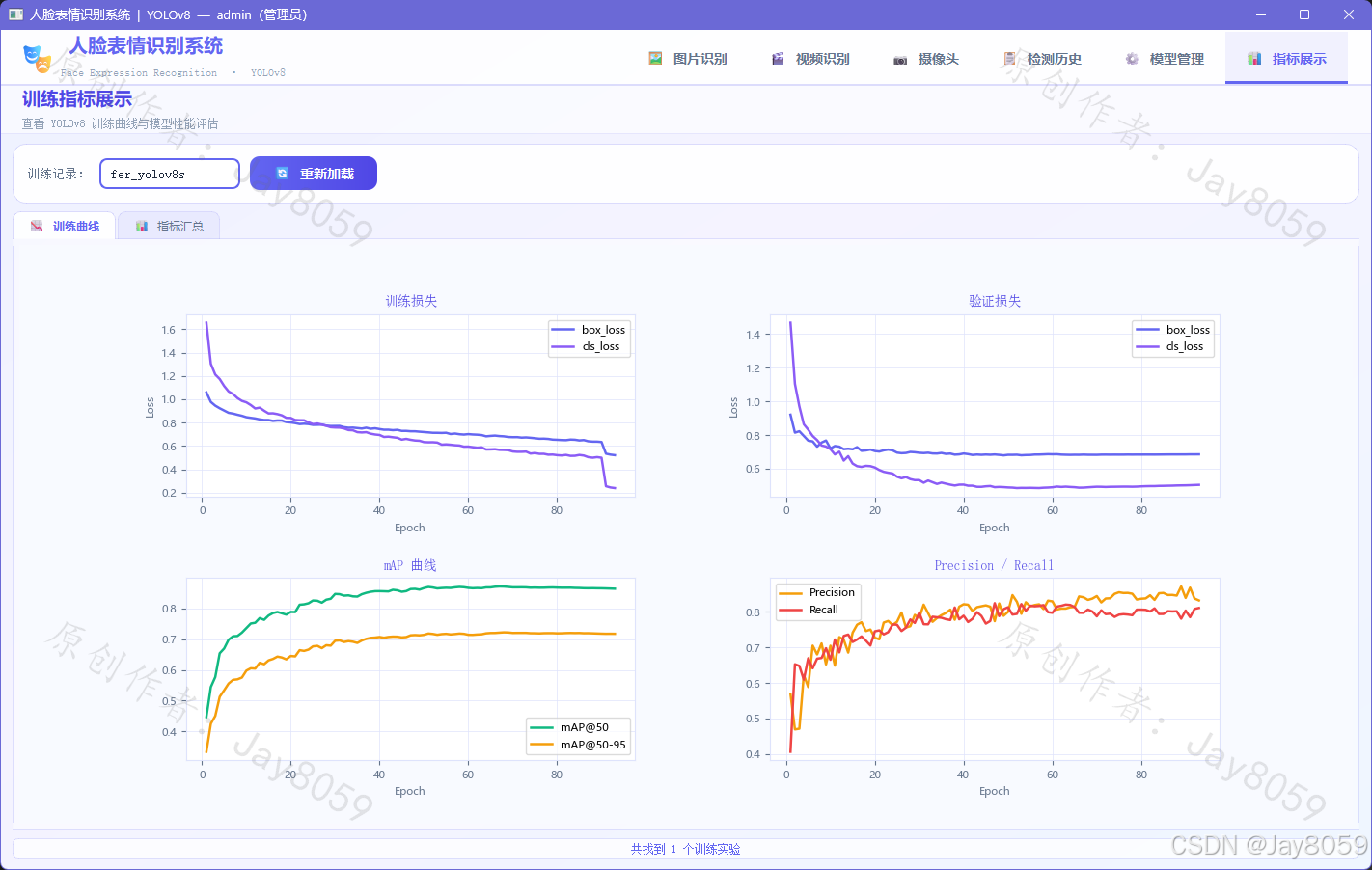
训练指标与可视化
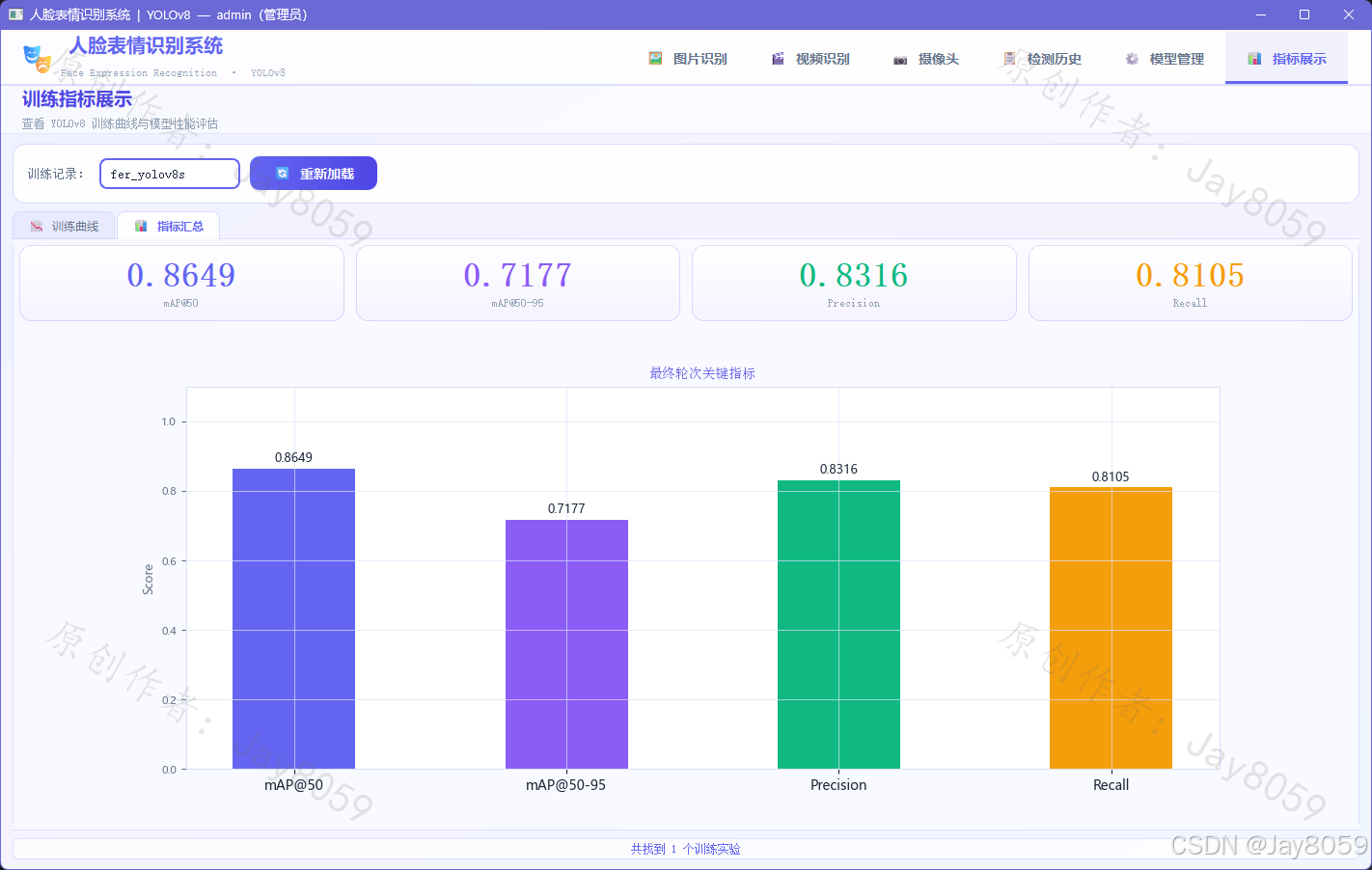
最终评估指标(测试集)
| 指标 | 数值 | 含义 |
|---|---|---|
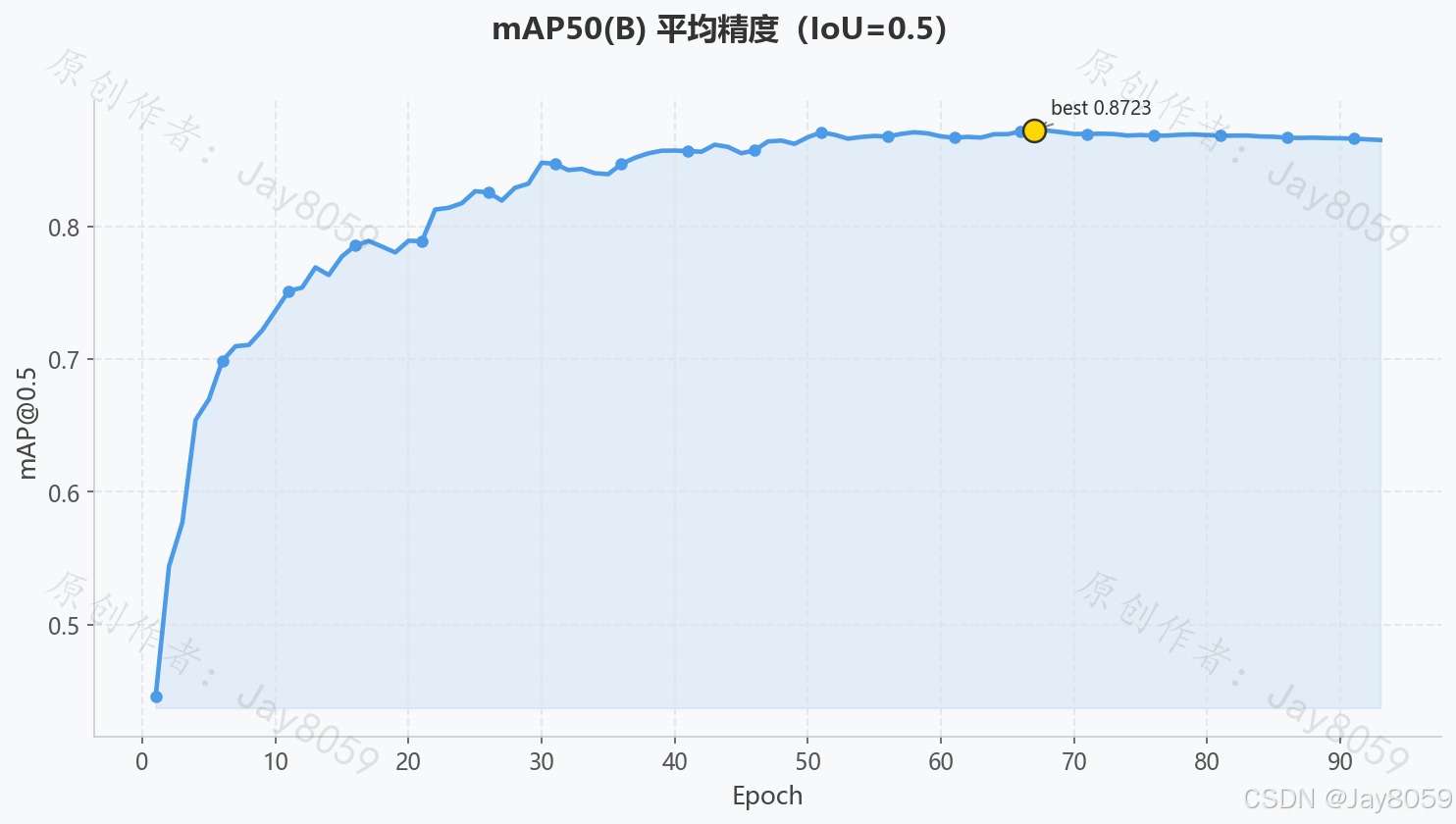
| mAP@50 | 0.8649 | IoU 阈值 0.5 下的平均精度均值 |
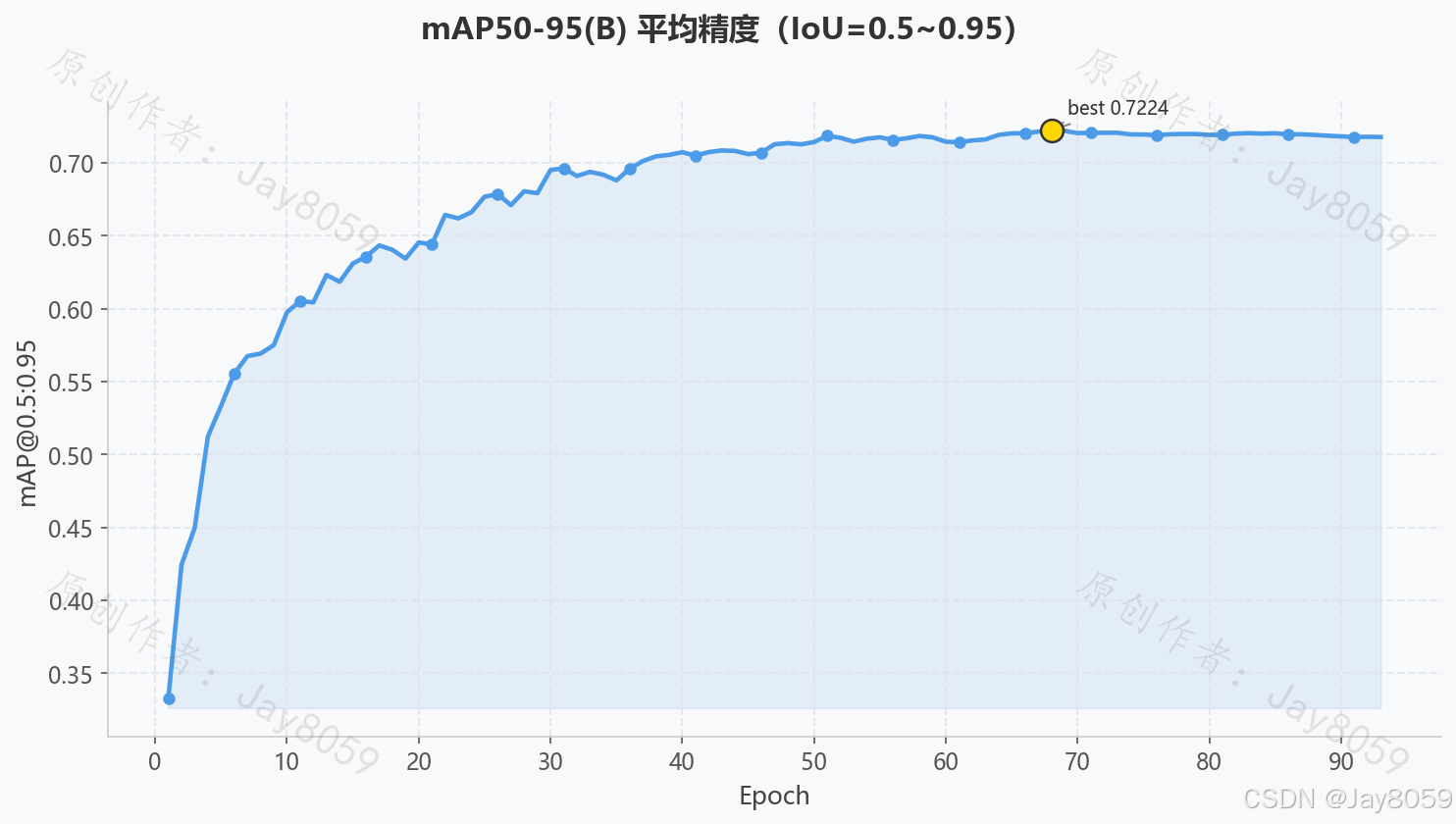
| mAP@50-95 | 0.7177 | IoU 从 0.5~0.95 步长 0.05 的综合均值 |
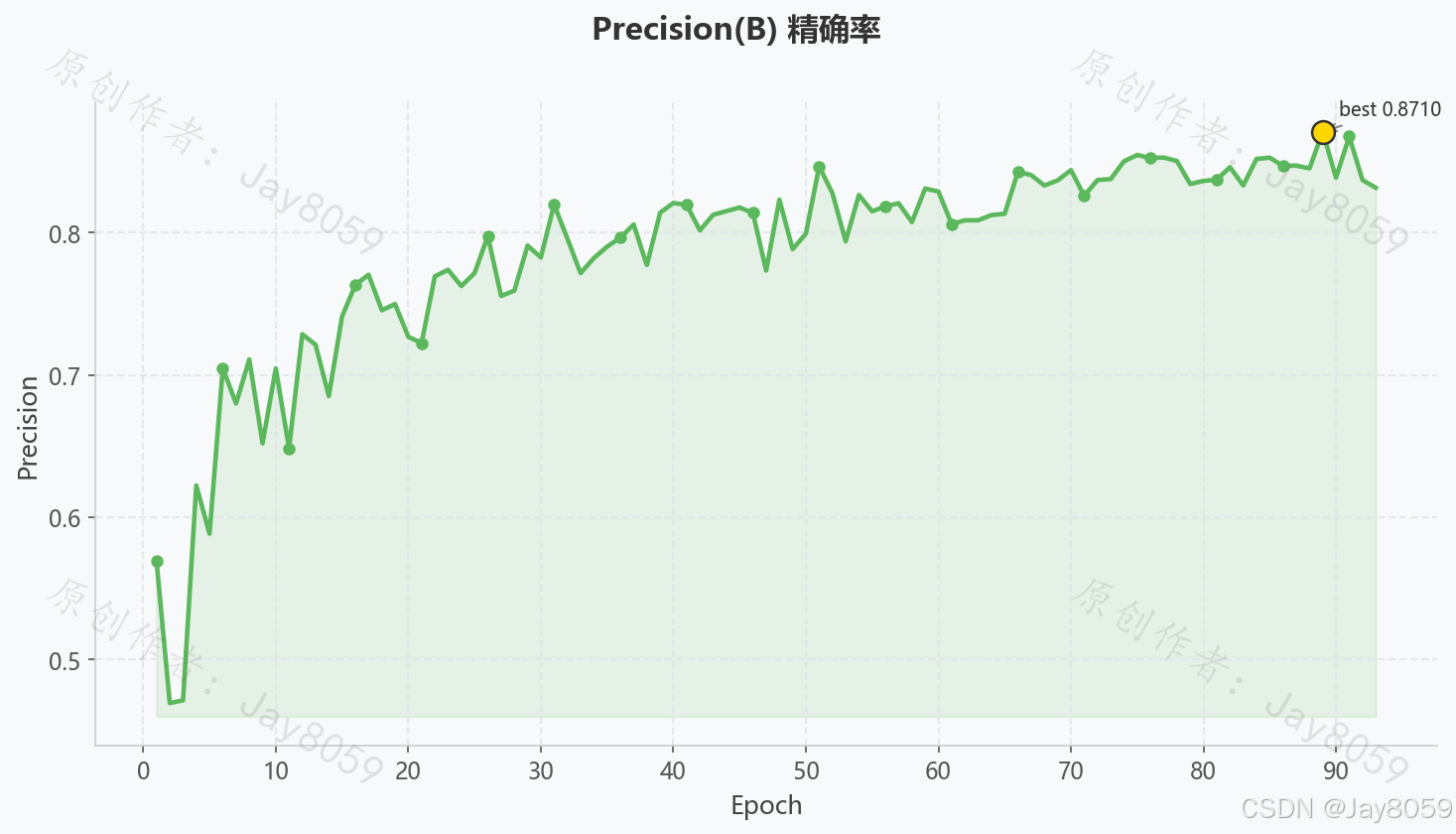
| Precision | 0.8316 | 预测为正类中真正正类的比例 |
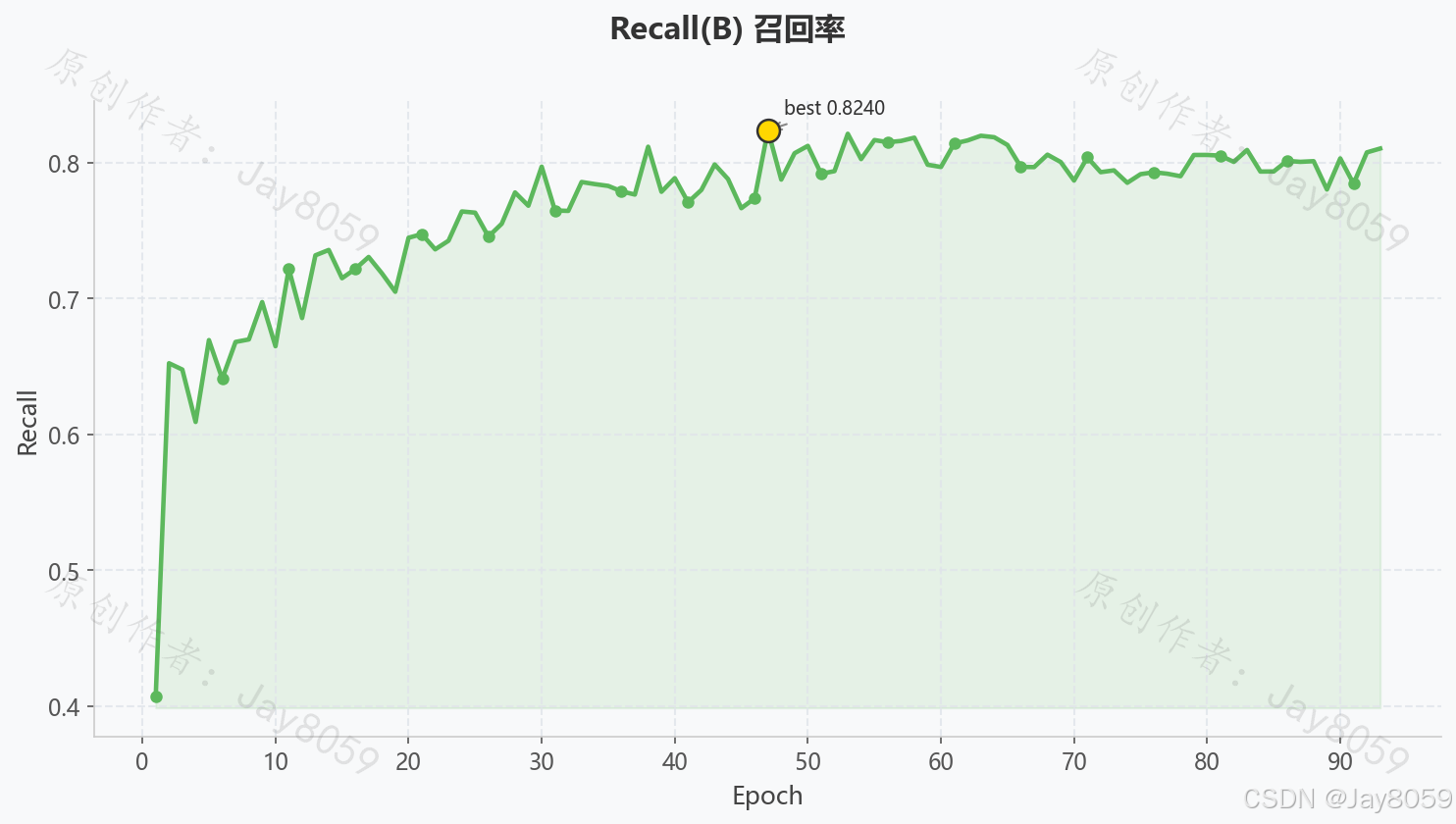
| Recall | 0.8105 | 实际正类中被正确预测的比例 |
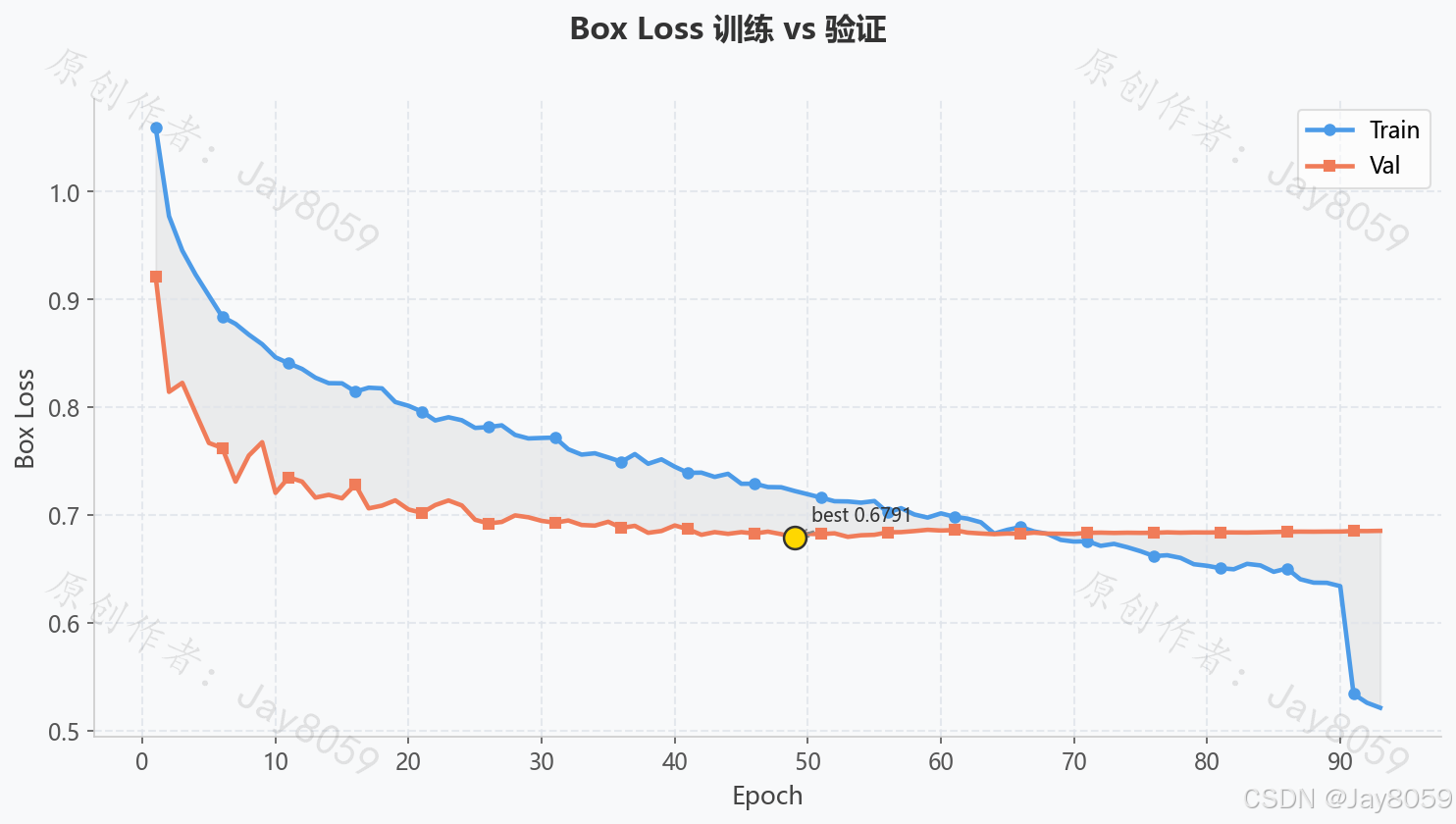
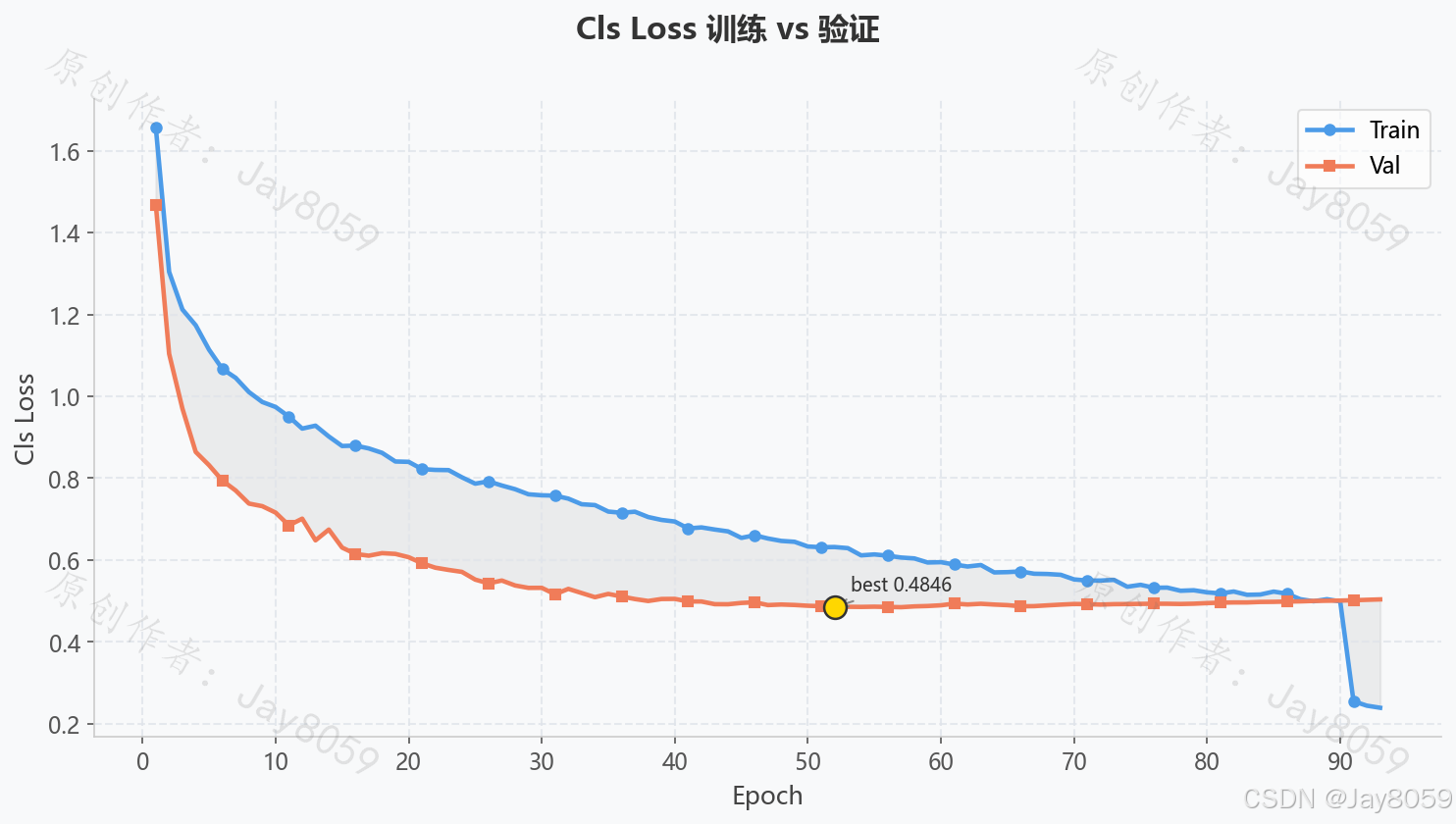
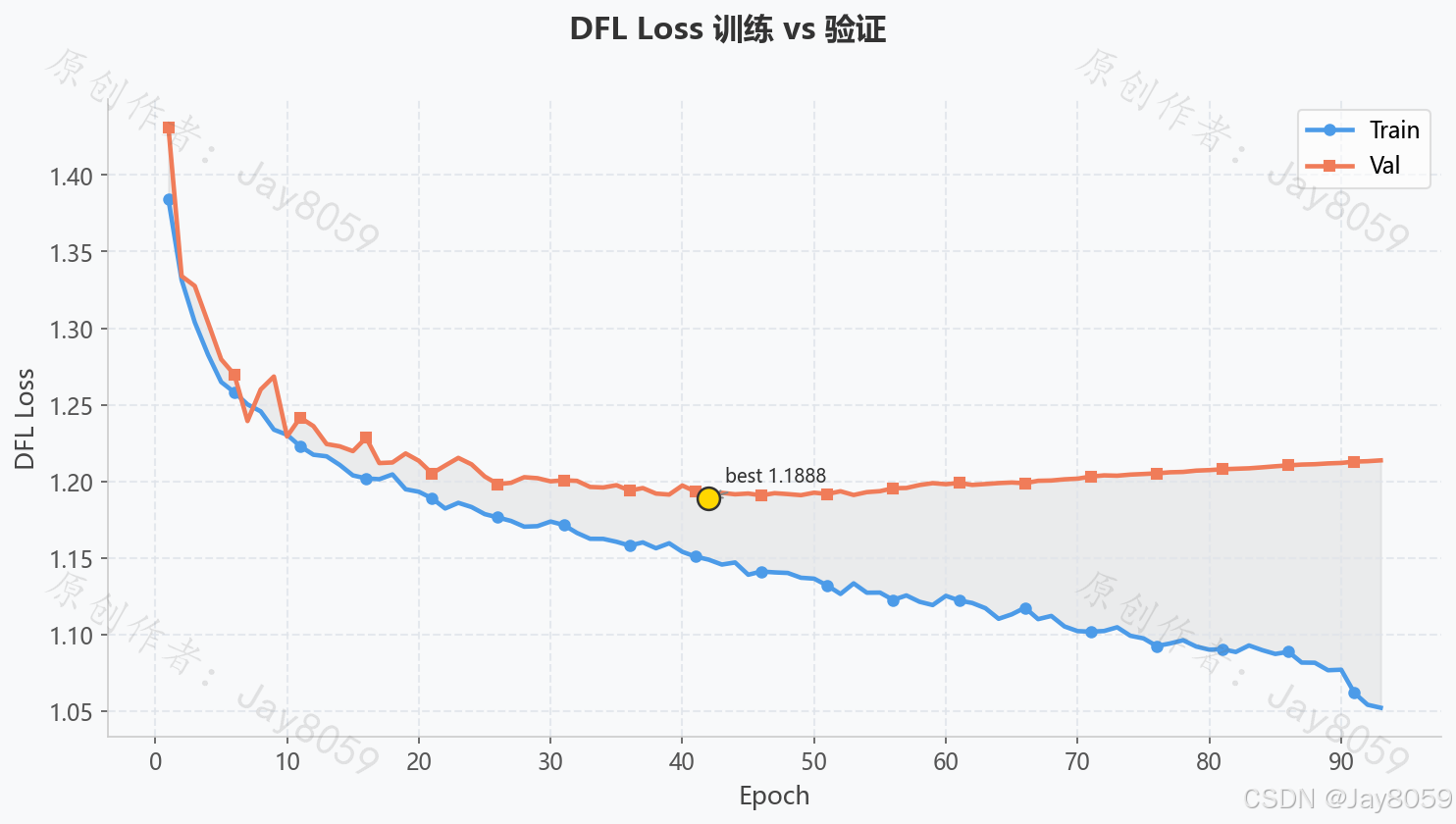
损失曲线说明
训练过程中记录三类损失,均保存于 train_result/fer_yolov8s/results.csv:
| 损失类型 | 含义 | 正常趋势 |
|---|---|---|
| Box Loss | 预测框与标注框的位置偏差(CIoU Loss) | 持续下降并趋于平稳 |
| Cls Loss | 表情分类交叉熵损失 | 快速下降后趋于平稳 |
| DFL Loss | 分布式焦点损失,优化边界框回归精度 | 缓慢下降 |
验证集损失(val/box_loss、val/cls_loss)与训练损失同步下降且差距不大,说明模型未出现明显过拟合。
指标曲线说明
| 曲线 | 含义 |
|---|---|
| Precision 曲线 | 随训练轮次提升,代表误检率下降 |
| Recall 曲线 | 随训练轮次提升,代表漏检率下降 |
| mAP@50 曲线 | 综合精度指标,早期快速爬升后趋于收敛 |
| mAP@50-95 曲线 | 更严格的定位精度指标,收敛更慢但更能体现模型质量 |
系统功能
系统基于 PyQt6 构建可视化交互界面,采用浅色渐变主题,顶部导航栏设计,包含六大功能模块:
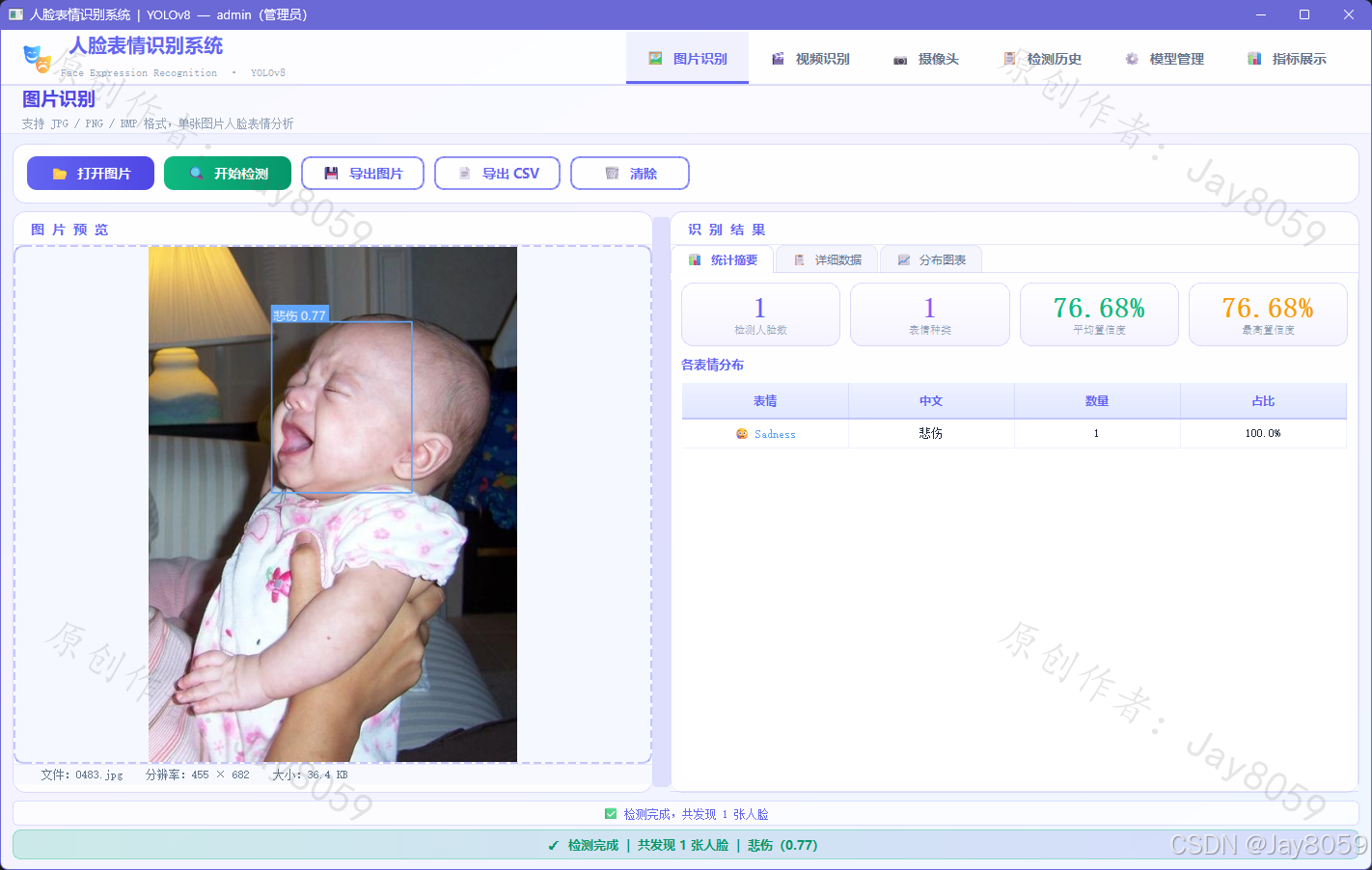
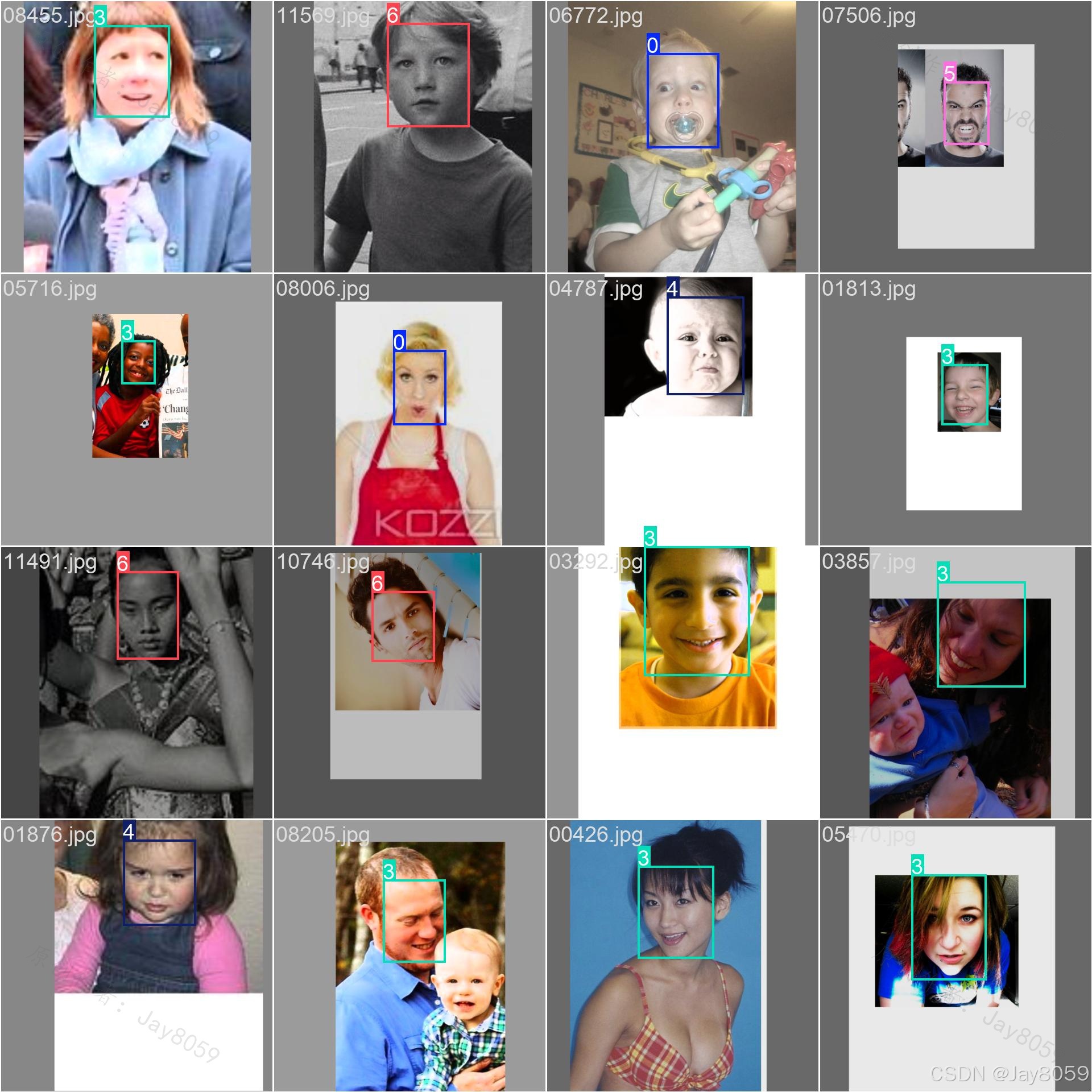
图片识别
- 支持 JPG / PNG / BMP / WebP 格式
- 一键加载图片,YOLOv8 推理检测人脸区域并输出表情类别
- 带标注的结果图实时展示(彩色检测框 + 中文标签)
- 统计摘要:检测人脸总数、表情种类、平均置信度、最高置信度
- 表情分布可视化(Matplotlib 横向条形图)
- 支持导出标注图片、导出 CSV 检测明细
视频识别
- 支持 MP4 / AVI / MOV / MKV 等主流视频格式
- 可设定每隔 N 帧检测一次,兼顾速度与密度
- 实时播放标注画面 + 帧进度条
- 当前帧与累计检测统计同步展示
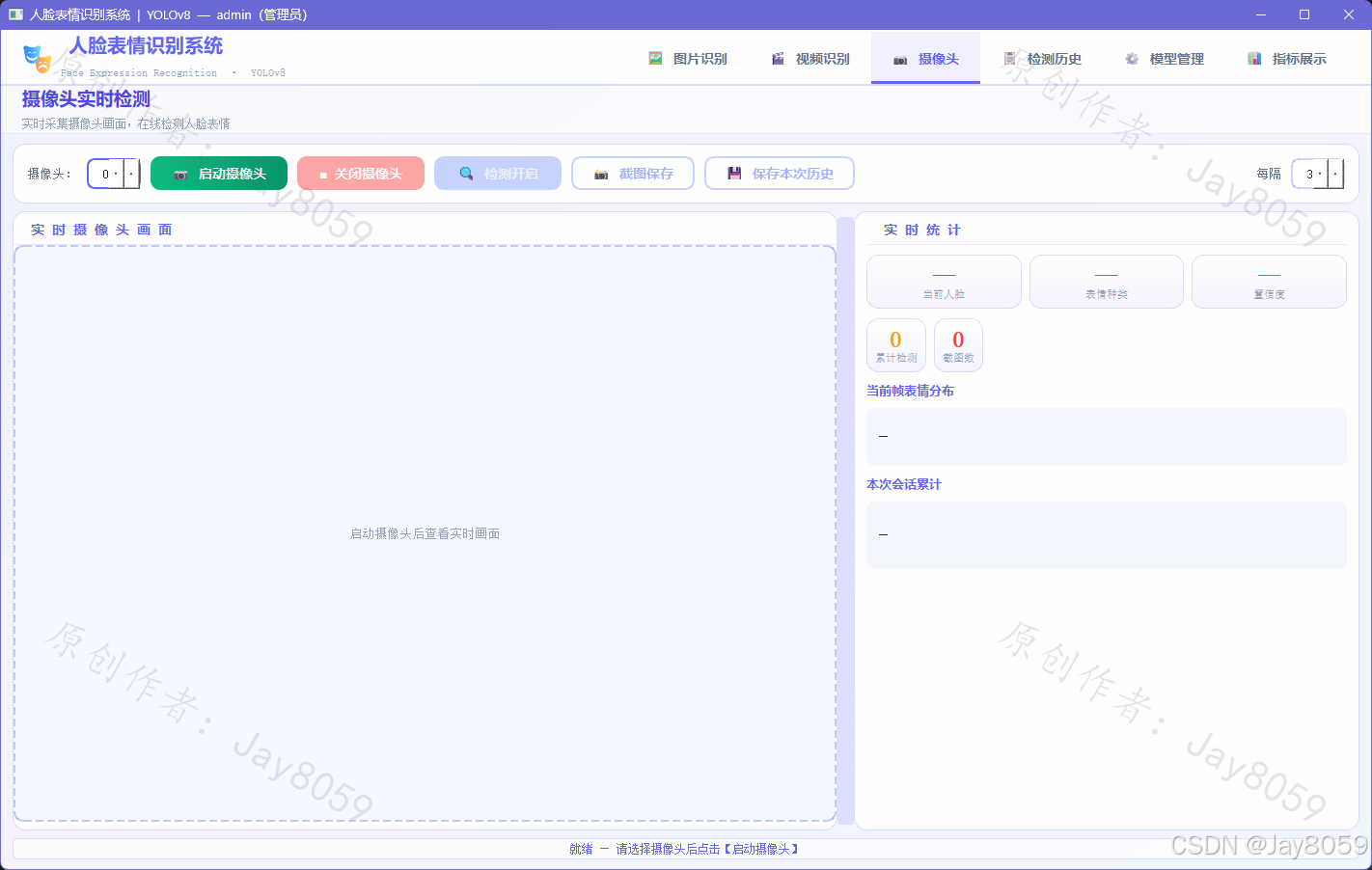
摄像头实时检测
- 支持多摄像头设备切换(设备号 0~10)
- 实时推流 + 表情检测,可随时开启/暂停检测
- 截图保存功能(保存至
train_result/screenshots/) - 本次会话累计统计一键存入历史记录
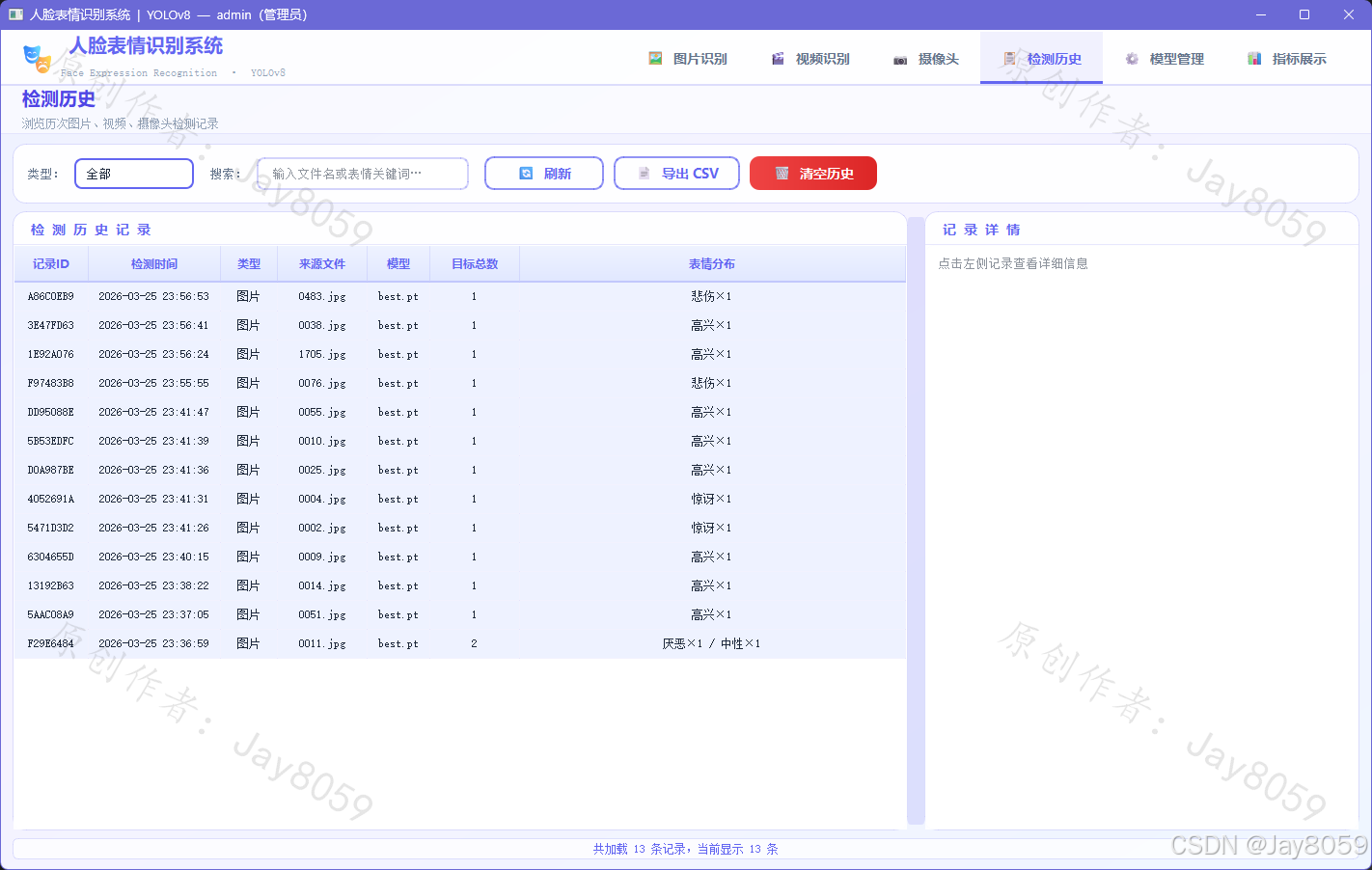
检测历史
- 自动记录每次图片、视频、摄像头检测结果
- 支持按类型筛选(图片 / 视频 / 摄像头)及关键词搜索
- 点击记录查看详细检测信息
- 支持历史数据导出为 CSV
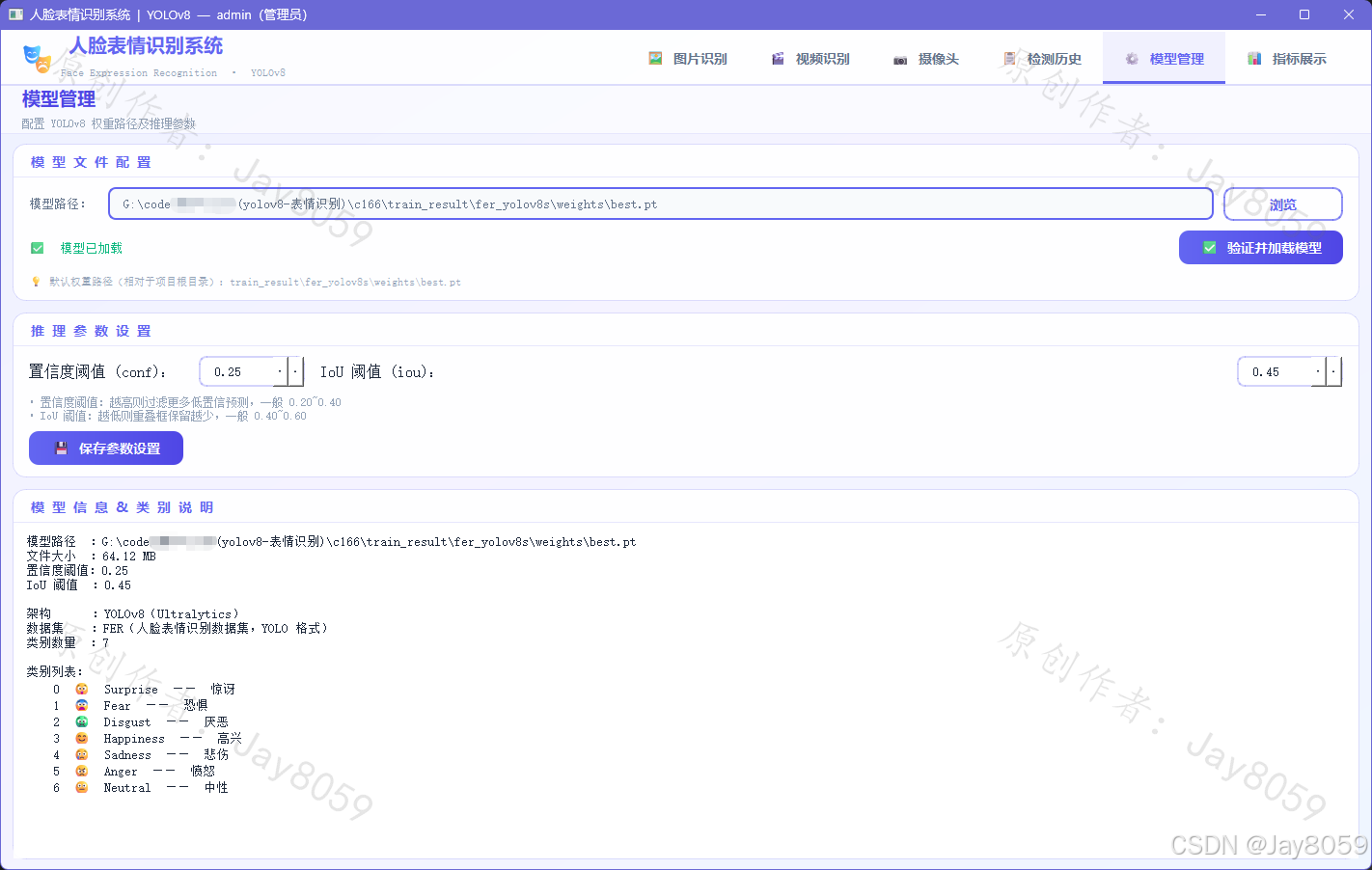
模型管理
- 默认加载
train_result/fer_yolov8s/weights/best.pt - 支持浏览加载任意 YOLOv8 权重文件
- 可动态调节置信度阈值(conf)与 IoU 阈值,实时生效
- 展示模型基本信息、文件大小及全部类别说明
训练指标展示
- 自动扫描
train_result/下所有实验目录 - 绘制训练/验证损失曲线、mAP 曲线、Precision/Recall 曲线
- 展示最终轮次四项核心指标的汇总柱状图
技术栈
| 层次 | 技术 | 用途 |
|---|---|---|
| 深度学习框架 | PyTorch | 模型训练底层计算 |
| 目标检测 | Ultralytics YOLOv8 | 人脸定位 + 表情分类 |
| 图形界面 | PyQt6 | 桌面 GUI 框架 |
| 样式系统 | QSS(Qt Style Sheets) | 浅色渐变主题 |
| 图表绘制 | Matplotlib | 训练曲线、分布图 |
| 图像处理 | OpenCV | 视频读写、帧处理 |
| 中文标注 | Pillow | 检测框中文标签渲染 |
| 数据处理 | NumPy | 矩阵运算与图像转换 |
| 历史存储 | JSON | 轻量级本地检测历史 |
| 编程语言 | Python 3.9 | — |
项目结构
c166/
│
├── app.py # 系统启动入口
├── train.py # 模型训练入口
│
├── fer-dataset-yolo/ # 数据集
│ ├── loopy.yaml # 数据集配置
│ ├── train/ # 训练集(图片 + 标注)
│ └── test/ # 测试集(图片 + 标注)
│
├── config/
│ └── train_config.py # 训练超参数配置
│
├── core/ # 核心逻辑层
│ ├── detector.py # YOLOv8 推理封装 + 标注绘制
│ ├── workers.py # QThread 后台检测线程
│ └── trainer.py # 训练器封装
│
├── ui/ # 界面层
│ ├── main_window.py # 主窗口(顶部导航 + 页面堆栈)
│ ├── utils/
│ │ ├── styles.py # 全局 QSS 样式表
│ │ ├── history.py # 检测历史读写管理
│ │ └── image_utils.py # 图像格式转换工具
│ └── pages/
│ ├── image_page.py # 图片识别页
│ ├── video_page.py # 视频识别页
│ ├── camera_page.py # 摄像头实时检测页
│ ├── history_page.py # 检测历史页
│ ├── model_page.py # 模型管理页
│ └── metrics_page.py # 训练指标展示页
│
└── train_result/ # 训练产物(自动生成)
└── fer_yolov8s/
├── weights/
│ ├── best.pt # 最优模型权重
│ └── last.pt # 最终轮次权重
├── results.csv # 逐轮训练指标
├── confusion_matrix.png # 混淆矩阵
└── ... # PR 曲线、F1 曲线等
快速开始
环境安装
pip install -r requirements.txt
启动训练
python train.py
训练完成后权重自动保存至 train_result/fer_yolov8s/weights/best.pt。
启动系统
python app.py
系统会自动加载默认最优权重,若权重不存在,可在【模型管理】页手动选择。
开发信息
- 作者:Jay
- 定制联系:vx:Jay8059
- 开发年份:2026

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)