【AI大模型前沿】Step3-VL-10B:阶跃星辰开源10B参数多模态大模型,以小博大实现SOTA性能,支持PaCoRe并行推理
系列篇章💥
前言
阶跃星辰(StepFun)最新开源的 Step3-VL-10B ,一款仅 100 亿参数的轻量级模型,凭借创新的 Parallel Coordinated Reasoning(PaCoRe)技术,在视觉感知、复杂推理和 GUI 交互等任务上,不仅碾压同规模竞品,更与参数量 10-20 倍的 GLM-4.6V(106B)、Qwen3-VL(235B)等旗舰模型正面抗衡。本文将深度解析 Step3-VL-10B 的技术架构、核心能力及部署实践,探索小模型如何释放大能量。
一、项目概述
Step3-VL-10B 是由阶跃星辰(StepFun)于 2025 年 1 月开源的紧凑型多模态基础模型,采用 1.8B 参数的视觉编码器(PE-lang)与 Qwen3-8B 语言解码器的组合架构,总参数量仅 10B。该模型通过 1.2T tokens 的高质量多模态语料统一预训练,结合超过 1400 次迭代的规模化强化学习(RLVR+RLHF),在 STEM 推理、OCR、GUI Grounding、空间理解等 40 余项基准测试中全面领先 7-10B 规模模型,并在 AIME 2025、MathVision、LiveCodeBench 等任务上超越 Gemini 2.5 Pro 等闭源旗舰,重新定义了"小模型大能力"的技术边界。
二、核心功能
(一)、多维度视觉感知
Step3-VL-10B 具备业界领先的视觉理解能力,MMBench 得分 92.05%,支持通用视觉问答、细粒度物体识别、场景理解等任务。模型采用多裁剪策略处理高分辨率图像,平衡全局语义与局部细节,在复杂视觉场景中表现稳定可靠。
(二)、深度推理与数学能力
模型在 STEM 推理任务上表现卓越,AIME 2025 得分 87.66%,PaCoRe 模式提升至 94.43%。支持数学竞赛题求解、科学图表分析、逻辑推理等复杂认知任务,推理能力超越多数百亿级模型。
(三)、OCR 与文档理解
OCRBench 得分 86.75%,支持多语言混合识别、表格结构解析、手写体识别。可处理扫描文档、PDF、白板内容等,精准提取结构化信息,适用于金融、法律、教育等文档密集型场景。
(四)、GUI 感知与交互
针对 AI Agent 场景优化,ScreenSpot-V2 得分 92.61%,OSWorld-G 达 59.02%。模型可精准定位界面元素、理解交互逻辑,支持跨应用自动化操作,为 RPA 和智能助手提供坚实底座。
(五)、空间理解与具身智能
BLINK 得分 66.79%,All-Angles-Bench 达 57.21%,展现超越参数规模的空间认知能力。支持视觉导航、物体定位、三维场景理解,适用于机器人、自动驾驶、AR/VR 等具身智能应用。
(六)、代码生成与理解
LiveCodeBench 得分 75.77%,HumanEval-V 达 66.05%。支持视觉引导的代码生成、GUI 自动化脚本编写、编程题求解,结合多模态输入实现"看图写代码"的智能化开发辅助。
三、技术揭秘
(一)、模型架构设计
采用视觉编码器-投影层-语言解码器架构。视觉编码器 PE-lang 参数量 1.8B,针对文本与 UI 元素优化;投影层实现 16 倍空间下采样;语言解码器基于 Qwen3-8B,具备强大推理与生成能力,总参数量仅 10B。
(二)、多裁剪视觉处理
支持 728×728 全局视图与多个 504×504 局部裁剪的组合策略,有效平衡全局语义理解与局部细节捕捉。通过动态分辨率适配,模型可处理高分辨率文档、复杂图表与高清照片,提升视觉信息利用率。
(三)、统一预训练策略
采用单阶段全解冻训练,在 1.2T tokens 多模态语料上端到端优化。900B tokens 聚焦推理能力培养,300B tokens 强化感知技能,视觉编码器与语言解码器联合更新,建立内在模态协同。
(四)、规模化强化学习
后训练包含 1400 余次 RL 迭代:600 次 RLVR 基于可验证奖励优化数学与感知任务,300 次 RLHF 对齐人类偏好,500 次专门训练 PaCoRe 并行推理能力,系统性提升模型输出质量。
(五)、PaCoRe 并行推理
创新性的测试时计算扩展技术,通过 16 个独立 rollout 并行探索视觉证据,经注意力机制聚合多路径推理结果。支持 128K 长上下文,在复杂数学与逻辑任务中显著提升准确率与鲁棒性。
(六)、高效推理优化
仅支持 bf16 精度推理,确保数值稳定性与计算效率。兼容 Transformers、vLLM、SGLang 等主流框架,支持量化压缩与分布式部署,降低硬件门槛,适配云端与边缘多种场景。
四、基准评测
(一)、与同规模模型对比(7B-10B)
在 7-10B 参数区间,Step3-VL-10B 展现全面统治力: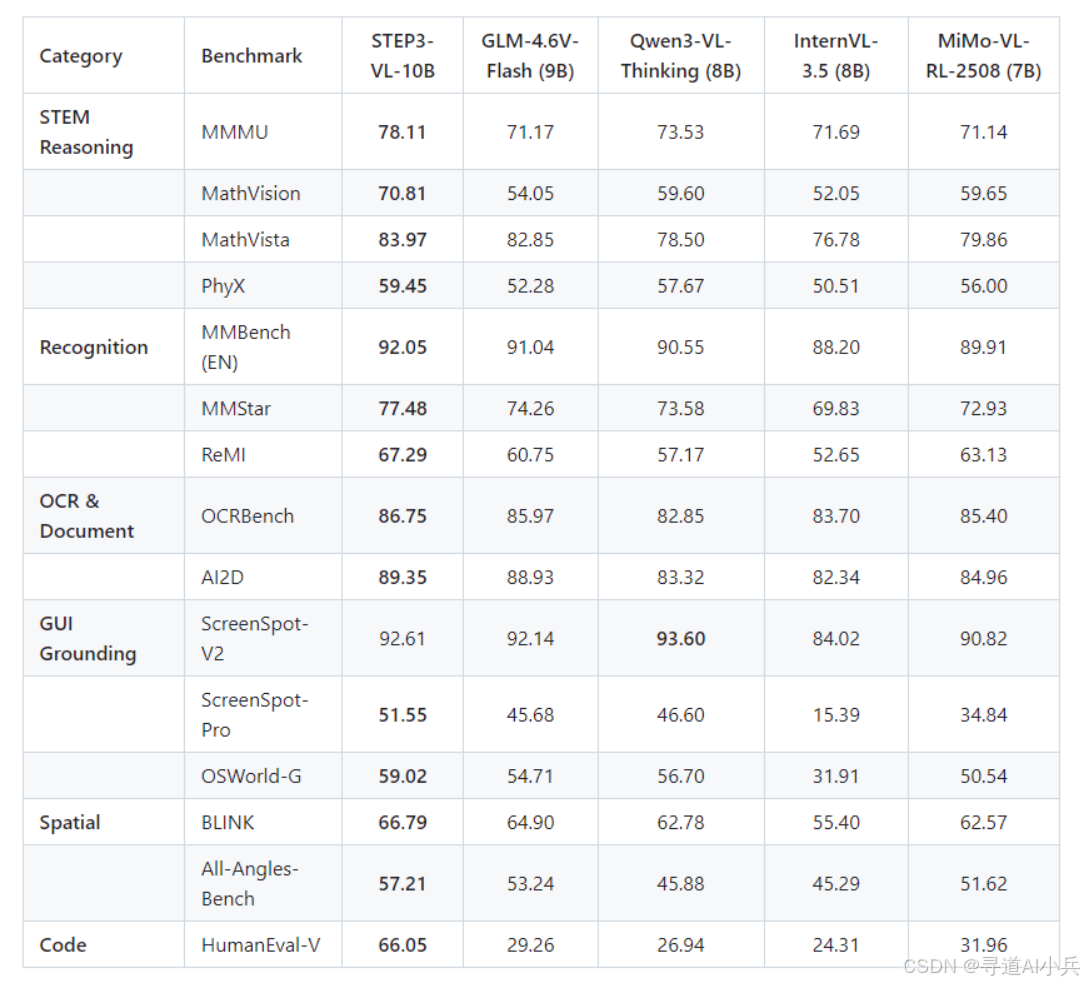
表 1:Step3-VL-10B 与同规模开源模型性能对比(SeRe 模式)
(二)、与超大模型对比(10×-20× 参数量)
Step3-VL-10B 在多项任务上挑战甚至超越百亿级旗舰模型: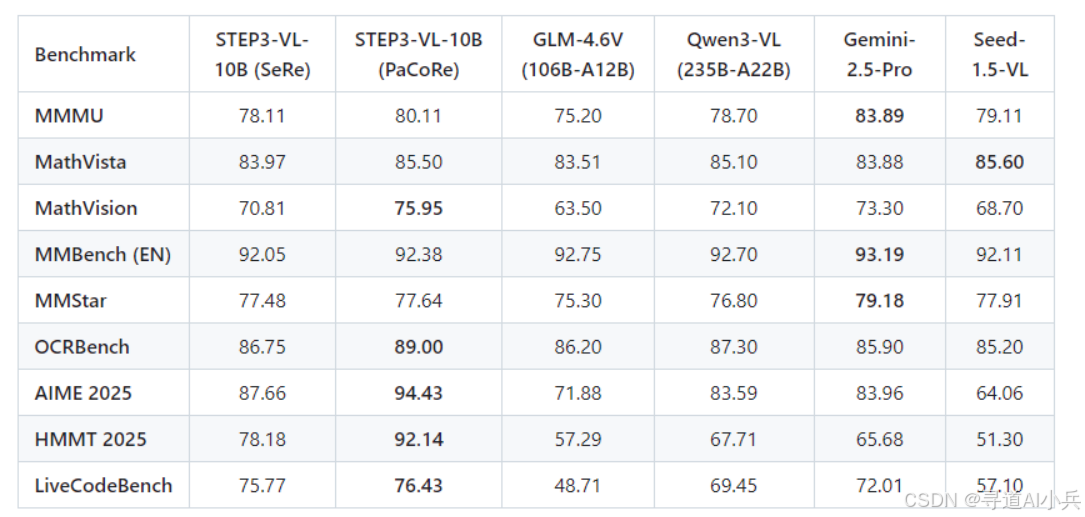
五、快速使用
(一)、环境准备
1. 硬件要求
- GPU:推荐 NVIDIA A100/H100(80GB 显存),支持单卡或双卡部署;消费级显卡如 RTX 4090(24GB)可通过量化运行
- 内存:≥ 64GB 系统内存
- 存储:≥ 50GB 可用空间(模型权重约 20GB,预留缓存与日志空间)
2. 软件环境配置
# 创建 Python 3.10 虚拟环境
conda create -n step3vl python=3.10 -y
conda activate step3vl
# 安装核心依赖(版本需严格匹配)
pip install torch>=2.1.0
pip install transformers==4.57.0
pip install accelerate bitsandbytes
pip install pillow requests
(二)、模型下载与加载
1. Hugging Face 下载
from huggingface_hub import snapshot_download
# 下载 Chat 模型(推荐,已针对对话优化)
snapshot_download(
repo_id="stepfun-ai/Step3-VL-10B",
local_dir="./Step3-VL-10B",
local_dir_use_symlinks=False
)
2. ModelScope 国内镜像下载
from modelscope import snapshot_download
model_dir = snapshot_download(
"stepfun-ai/Step3-VL-10B",
cache_dir="./models"
)
3. 模型加载与初始化
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
model_path = "./Step3-VL-10B"
# 关键参数映射(适配 Transformers 库)
key_mapping = {
"^vision_model": "model.vision_model",
r"^model(?!\.(language_model|vision_model))": "model.language_model",
"vit_large_projector": "model.vit_large_projector",
}
# 加载处理器
processor = AutoProcessor.from_pretrained(
model_path,
trust_remote_code=True
)
# 加载模型(自动分配设备与精度)
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
device_map="auto",
torch_dtype=torch.bfloat16,
key_mapping=key_mapping
).eval()
(三)、基础推理实践
1. 单张图片问答(SeRe 模式)
# 构建对话消息
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://example.com/sample.jpg"
},
{
"type": "text",
"text": "请详细描述这张图片的内容。"
}
]
}
]
# 应用对话模板
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
# 生成输出(SeRe 模式:贪婪解码)
with torch.no_grad():
generate_ids = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=False,
temperature=1.0,
top_p=1.0
)
# 解码结果
output = processor.decode(
generate_ids[0, inputs["input_ids"].shape[-1]:],
skip_special_tokens=True
)
print(output)
2. 本地图片加载与处理
from PIL import Image
# 加载本地图片
image = Image.open("./local_image.png").convert("RGB")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image}, # 直接传入 PIL Image
{"type": "text", "text": "分析这张图表的数据趋势。"}
]
}
]
# 后续处理逻辑同上
3. 多轮对话与上下文保持
# 多轮对话历史
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "doc_page1.jpg"},
{"type": "text", "text": "总结这页文档的核心内容。"}
]
},
{
"role": "assistant",
"content": "这页文档主要介绍了..."
},
{
"role": "user",
"content": [
{"type": "image", "url": "doc_page2.jpg"},
{"type": "text", "text": "结合上一页,分析两页内容的关联性。"}
]
}
]
# 完整上下文自动处理
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
(四)、PaCoRe 并行推理模式
1. 启用 PaCoRe 高级推理
# PaCoRe 模式配置(需更长上下文与采样)
generate_ids = model.generate(
**inputs,
max_new_tokens=4096, # 支持更长输出
do_sample=True, # 启用采样生成多样路径
temperature=0.7,
top_p=0.95,
num_beams=16, # 16 个并行 rollout
use_cache=True,
paco_re=True # 启用 PaCoRe 模式标识
)
2. 手动实现并行推理聚合
import torch
from collections import Counter
def parallel_coordinated_reasoning(model, processor, messages, num_paths=16):
"""自定义 PaCoRe 实现:多路径生成与投票聚合"""
candidates = []
for i in range(num_paths):
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.8,
top_p=0.9
)
response = processor.decode(
outputs[0, inputs["input_ids"].shape[-1]:],
skip_special_tokens=True
)
candidates.append(response)
# 基于答案一致性投票(实际应用可使用语义相似度)
final_answer = Counter(candidates).most_common(1)[0][0]
return final_answer, candidates
结语
Step3-VL-10B 的发布标志着多模态大模型进入"效率优先"的新阶段。通过创新的 PaCoRe 并行推理技术、高质量多模态预训练与规模化强化学习的有机结合,这款 10B 参数的轻量级模型成功打破了"参数即正义"的行业迷思,在数学推理、代码生成、GUI 交互等关键领域实现了对百亿级模型的超越。
对于开发者而言,Step3-VL-10B 提供了可负担的部署成本(单卡 A100 即可运行)与开放的模型权重,降低了多模态 AI 应用的准入门槛;对于研究者而言,其技术报告揭示了测试时计算扩展与多模态强化学习的巨大潜力,为下一代模型设计提供了重要参考。
随着 AI Agent、具身智能等应用场景的爆发,Step3-VL-10B 所代表的高效多模态模型将成为连接云端智能与边缘设备的关键桥梁。我们期待阶跃星辰持续开源更多创新成果,推动多模态大模型技术的民主化进程。
项目地址
- 项目官网:https://stepfun-ai.github.io/Step3-VL-10B/
- GitHub 仓库:https://github.com/stepfun-ai/Step3-VL-10B
- Hugging Face 模型库:https://huggingface.co/stepfun-ai/Step3-VL-10B
- 技术论文:https://arxiv.org/pdf/2601.09668

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)